
第二章| python数据类型| 基本数据类型| 数据集列表元组字典集合
python数据类型
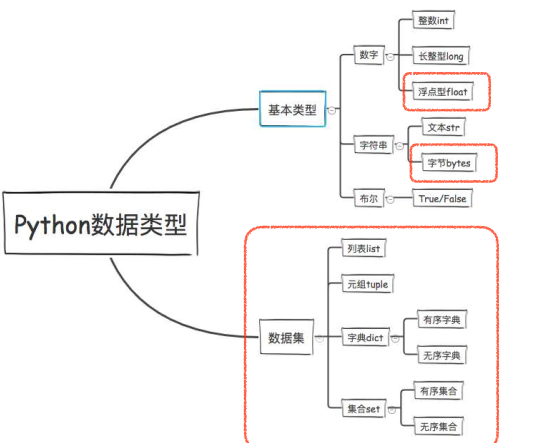
1. 基本类型
五种基本数据类型:字符串str、整型 int、浮点数 float、布尔bool True/ False、复数 1+1j
为什么区分不同类型?
不同类型的运算规则不同(如整数的加法和 字符串的加法含义不同)
不同类型对象在计算机内表示方式不同(5 —> 101, '5' —> 1001101)
为何区分整数与浮点数?
- 浮点数表示能力更强;
- 浮点数有精度损失(1.1+1.1+1.1 = 3.3000000000000003,因为有些浮点数是无法用二进制来表示,比如3.3);
- CPU有专门的浮点数运算部件;
① 数字类型Number
整型 int、 长整型 long、浮点型 float 、复数complex
Python3中没有long了,只有int。
#整型 v = 521 v = -1111 #浮点型, v = 3.1415926 v = 0x10 # 十六进制 varn = 5+6j # complex 复数
② Bool值
bool布尔型:True,False,用于做判断;
布尔型的本质:True的值等于1,False的值等于0
bool( )函数:将值转换为布尔型,其中只有以下情况bool()返回False:0, 0.0, None,'', [] , {}
>>> print(bool(0), bool(3), bool(-1), bool([1, 2,3]), bool(''), bool({}))
False True True True False False
>>> print(bool(()))
False
③ 字符串
只要加了引号(单、双、三)都是字符串;比较长的、多行才用三引号;单双引号没有区别。
字符串的拼接,相加、相乘
布尔值:True和False
特性:有序、不可变
文本str、 字节bytes
v = b'001100111' # bytes
字符串是 Python 中最常用的数据类型。我们可以使用引号('或")来创建字符串;
字符串也是序列:文本序列;
双引号单引号无区别,但文本中有引号的时候要相互交替使用;需要多行字符串时候用三引号 ''' ''',""" """;
# 字符串引号
str1 = "abc"
str2 = 'abc'
str3 = 'my name is "fatbird"' # 双引号单引号无区别,但文本中有引号的时候要相互交替使用
str4 = '''hello! how are you?
I`m fine, thank you.'''
# 需要多行字符串时候用三引号 ''' ''' 或者 """ """
# 转义字符:\ print('\'', '\"') # \',\" :分别输出单引号,双引号 print('hello\nhow do you \tdo?') # \n:换行 ,\t表示一个制表符
s = r'取消\n转移字符' #r 表示取消转义 print('\\') # 输出\,所以文件路径用“/”或者“\\”
字符串的各种方法:
- swapcase是大写变小写,小写变大写;
- capitalize是首字符大写,其他小写;
- casefold把大小写去掉变成统一的小写;
- center见下用法;
- count统计有几个;
- endswith是以什么结尾;
- expandtabs是tab键;
- find是查找;
- format格式化,用%s或者这个都一样,见下面两种用法;
- index是返回列表的索引值;
- isalnum是否是阿拉伯字符(数字和字母);
- isidentifier是否是合法的变量名;
- islower是否都是小写;
- isprintable是否可以打印,文本文件或者字节格式的可以打印;
- isspace是否是空格;
- istitle大写(类似新闻标题)、isupper也是大写;join见下;
- s.ljust()从左边开始加东西;
- lower()是全部小写、upper()是全部大写;
- strip空格、换行、tap键都去掉;
- lstrip只脱左边不脱右边,rstrip只脱右边不脱左边;
- translate翻译,对应关系对应表;partition见下;replace替换;
- rfind从右边开始找;rindex从右边索引;rjust和ljust正好相反;
- split把字符串分成了列表;splitlines()按行来分;zfill见下;
s.swapcase() 大写变小写,小写变大写
>>> s = 'Hello World!'
>>> print(s.swapcase())
hELLO wORLD!
>>>
s.center(50,'-')、 s.count('0')
>>> s.center(50, '-')
'-------------------Hello World!-------------------'
>>> s.center(50, '*')
'*******************Hello World!*******************'
>>>
>>> s.count('o')
2
>>> s.count('o',0,5)
1
endswish判断是否是以 结尾
>>> s.endswith('!')
True
>>> s.endswith('!sdf')
False
>>>
expandtabs
>>> s2 = 'a\tb'
>>> s2
'a\tb'
>>> print(s2)
a b
>>> s2.expandtabs()
'a b'
>>> s2.expandtabs(20) #20个空格
'a b'
find
find(str, pos_start, pos_end)解释:
- str:被查找“字串”
- pos_start:查找的首字母位置(从0开始计数。默认:0)
- pos_end: 查找的末尾位置(默认-1)
返回值:如果查到:返回查找的第一个出现的位置。否则,返回-1。
>>> s = 'Hello World!'
>>> s.find('o')
4
>>> s.find('osd')
-1
>>> s.find('o',0,3)
-1
>>> s.find('o',0,5)
4
format
>>> s3 = 'My name is {0}, I am {1} years old'
>>> s3
'My name is {0}, I am {1} years old'
>>> s3.format('kris',22)
'My name is kris, I am 22 years old'
>>> s3 = 'My name is {name}, I am {age} years old'
>>> s3.format(name='alex',age=32)
'My name is alex, I am 32 years old'
isalnum()
isalpha()
isdigist()
isdecimal()
>>> '22d'.isalnum()
True
>>> '22d!'.isalnum()
False
>>>
>>> '22'.isalpha()
False
>>> 'dd'.isalpha()
True
>>>
>>> '33'.isdecimal() #只能是整数,是否是数字
True
>>> '33s'.isdecimal() #跟isdigist是一样的
False
>>> '33.3'.isdecimal() #跟isnumeric是一样的
False
>>> '333'.isidentifier()
False
>>> 'd333'.isidentifier()
True
>>>
'-' . join( names ) 把列表转换成字符串
str.join():连接字符串,对象为序列
>>> lst = ['poi01', '116.446238', '39.940166']
>>> st = '-'.join(lst)
>>> print(st)
poi01-116.446238-39.940166
join
ljust
lstrip()
partition()
maketrans
>>> names = ['alex','jack','rain']
>>> ''.join(names)
'alexjackrain'
>>> ' '.join(names)
'alex jack rain'
>>> ','.join(names)
'alex,jack,rain'
>>> '-'.join(names)
'alex-jack-rain'
>>>
>>> s
'Hello World!'
>>> s.ljust(50)
'Hello World! '
>>> s.ljust(50,'-')
'Hello World!--------------------------------------'
>>> len(s.ljust(50,'-'))
50
>>>
>>> s = '\n Hello World! '
>>> s.lstrip()
'Hello World! '
>>> s.rstrip()
'\n Hello World!'
>>> s
'\n Hello World! '
>>> s.partition('o')
('\n Hell', 'o', ' World! ')
>>>
>>>
>>> str_in = 'abcdef'
>>> str_out = '!@#$%^'
>>> str.maketrans(str_in,str_out)
{97: 33, 98: 64, 99: 35, 100: 36, 101: 37, 102: 94}
replace rdind rindex rpartition
str.replace(old,new,count):修改字符串, count:更换几个;
>>> s
'Hello World'
>>> s.replace('H','h')
'hello World'
>>> s.replace('H','h') #把大写H 替换为小写 h
'hello World'
>>> s.rfind('o') #从右往左开始查找
7
>>> s.rindex('o')
7
>>> s.rpartition('o')
('Hello W', 'o', 'rld')
split、rsplit #split 函数默认分割:空格,换行符,TAB
str.split(obj):拆分字符串,生成列表
>>> st = "police,110,112,114"
>>> st.split(',')
['police', '110', '112', '114']
>>> s
'Hello World'
>>> s.split()
['Hello', 'World']
>>> s.split('o')
['Hell', ' W', 'rld']
>>> s.split('o',1)
['Hell', ' World']
>>> s.rsplit('o',1) #从右边开始分
['Hello W', 'rld']
splitlines、startswith、endswith
str.startswith(“str”) 判断是否以“str”开头;str.endswith (“str”) 判断是否以“str”结尾
st = 'abcdefg'
print(st.startswith('a'), st.endswith('f'))
打印:
True False
>>> s
'Hello World'
>>> s.splitlines()
['Hello World']
>>> s.startswith('He')
True
>>> s.endswith('He')
False
>>> s.zfill(40)
'00000000000000000000000000000Hello World'
st = 'aBDEAjc kLM'
print(st.upper()) # 全部大写
print(st.lower()) # 全部小写
print(st.swapcase()) # 大小写互换
print(st.capitalize()) # 首字母大写
st = '1234567'
print(st.isnumeric()) # 如果 string 只包含数字则返回 True,否则返回 False.
st = 'DNVAK'
print(st.isalpha()) # 如果 string 至少有一个字符并且所有字符都是字母则返回 True,否则返回 False
st = 'avd '
print(st.rstrip()) # 删除字符末尾的空格
常用的有:isdigit、replace、find、count、strip、center、split、format、join
2. 数据集
列表
元组
字典
集合
序列通用功能
在Python中,最基本的数据结构是序列(sequence)。序列中的每个元素被分配一个序号——即元素的位置,也称为索引。
第一个索引是 0,第二个则是 1,以此类推。序列中的最后一个元素标记为 -1,倒数第二个元素为 -2,依次类推。
Python中内建的序列,包括列表、元组、字符串、Unicode字符串、buffer对象和xrange对象。列表和元组的主要区别在于,列表可以修改,元组则不能。
序列分类:可变序列list, 不可变序列tuple、str
判断值是否属于序列
>>> print('a' in 'abc') # in/not in :判断是否存在
True
>>> print('我很帅' + "没错") # 文本连接
我很帅没错
>>> print('handsome '*4) # 文本复制
handsome handsome handsome handsome
>>>
>>> lst = [1, 2, 3, 4, 5, 6]
>>> a, b = 1, 10
>>> print(a in lst)
True
>>> print(b not in lst)
True
序列连接与重复
>>> lst1 = [1,2,3]
>>> lst2 = ['a','b','c']
>>> print(lst1 + lst2) #"+":序列的链接
[1, 2, 3, 'a', 'b', 'c']
>>> print(lst1*3, lst2*2) #"*":序列的重复
[1, 2, 3, 1, 2, 3, 1, 2, 3] ['a', 'b', 'c', 'a', 'b', 'c']
下标索引
>>> lst = [1,2,3,4,5,6,7,8,9,0]
>>> print(lst[0],lst[2],lst[9]) # 索引从0开始,eg lst[2]中,下标索引是2,指向lst的第3个值
1 3 0
>>> print(lst[-1]) # 索引-1代表最后一个值
0
#print(lst[10]) # 这里一共有10个值,所以最大索引是9
切片
>>> lst = [1,2,3,4,5,6,7,8,9,0]
>>> print(lst[2:5]) # 切片可以理解成列表的值区间,且是一个左闭右开区间,这里lst[2:5]代表的区间是:索引2的值 - 索引4的值
[3, 4, 5]
>>> print(lst[:5]) # 左边无索引,代表从索引0开始
[1, 2, 3, 4, 5]
>>> print(lst[4:]) # 右边无索引,代表以最后一个值结束
[5, 6, 7, 8, 9, 0]
>>> print(lst[5:-1]) # 索引5的值 - 倒数第二个值 (切片是右闭区间,注意了)
[6, 7, 8, 9]
>>>
步长
# 步长
>>> lst = [1,2,3,4,5,6,7,8,9,0]
>>> print(lst[0:5:2]) # List[i:j:n]代表:索引i - 索引j,以n为步长
[1, 3, 5]
>>> print(lst[::2]) # 按照2为步长,从第一个值开始截取lst数据
[1, 3, 5, 7, 9]
>>> print(lst[1::2]) # 按照2为步长,从第二个值开始截取lst数据
[2, 4, 6, 8, 0]
st = 'abcdefg'
print(st[2],st[-1])
print(st[:2])
print(st[::2])
# 索引、切片、步长
print(st.index('g')) # .index()方法
print('st长度为:',len(st)) # 计算字符串长度(思考这里能否把逗号换为"+") 不能,必须是str,不能是int
序列的基本内置全局函数
lst = [1,2,3,4,5,6,7,8,9,0]
print(len(lst)) # 列表元素个数
print(len(tup1))
print(max(lst),min(lst),sum(lst)) # 返回列表的最大值、最小值、求和,这三个函数都只针对数字的list
print(max(tup1),min(tup1))
print(lst.index(3)) # .index(obj)方法:从列表中找出某个值第一个匹配项的索引位置
lst = [1,1,2,3,3,4,4,4,4,5,6]
print(lst.count(4)) # .count(obj)方法:计算值的出现次数
打印:
10
9 0 45
2
4
>>> x=[1,2,3,1,[1],[1,1]]
>>> x.count(1)
2
1、列表(可变列表)
列表功能
创建:
#方法一
>>> L1 = [] #定义空列表
>>> L2 = ['a','b','c','d'] #存4个值,索引0-3
>>> L3 = ['abc', ['def', 'ghi']] #嵌套列表
>>>
#方法二
>>> L4 = list()
>>> L4
[]
列表的特征:
>>> lst1 = [1,2,3,'a','b','c',[1,2,3]]# 可包含任意类型的对象:数值、字符串、列表等
>>> lst2 = [143,56,894,67,43]
>>> print(lst2[0],lst2[4],lst2[-1])# 通过下标索引访问序列中的值 → 序列的顺序是不能改变的,通过索引来定位列表的元素
143 43 43
>>> lst3 = [1,2,3]
>>> lst3 = lst3 * 3 # 可随意变换列表长度,相当于随意指定新的列表
>>> print(lst3)
[1, 2, 3, 1, 2, 3, 1, 2, 3]
>>> lst4 = [1,2,['a','b']] # 可嵌套
>>> lst5 = [100,101,102]
>>> lst5[0] = 10 # 可原位改变
>>> print(lst5)
[10, 101, 102]


索引: n2[ ] n2.index( )
>>> names = ['Shanshan', 'LongTing', 'Alex']
>>> n2 = ['Shanshan', 'LongTing', 'Alex', 1,2,4,4,5,7,6,9,8,0,0,4,4]
>>> n2
['Shanshan', 'LongTing', 'Alex', 1, 2, 4, 4, 5, 7, 6, 9, 8, 0, 0, 4, 4]
>>> n2[-1]
4
>>> n2[-2]
4
>>> n2[-3]
0
>>> n2.index(6)
9
>>> n2[9]
6
>>> n2.index(4)
5
查询
n2.index(4) 查询列表中数值4的下标 n2[n2.index(4) ]
n2.count(4) 查询列表中有几个4
>>> n2
['Shanshan', 'LongTing', 'Alex', 1, 2, 4, 4, 5, 7, 6, 9, 8, 0, 0, 4, 4]
>>> names
['Shanshan', 'LongTing', 'Alex']
>>> n2.count(4)
4
>>> n2[n2.index(4)]
4
>>> names.index('Alex') #返回一个索引值
2
切片 (顾头不顾尾)
Python中符合序列的有序序列都支持切片(slice),例如列表,字符串,元组。
格式:[start: end: step]
start:起始索引,从0开始,-1表示结束
end:结束索引
step:步长,end - start,步长为正时,从左向右取值。步长为负时,反向取值。步长默认是1(可不写)
n2[0:3] n2[-5:-1] n2[-5:] n2[:3]和n2[0:3]一样的
>>> n2 = ['Shanshan', 'LongTing', 'Alex', 1, 2, 4, 4, 5, 7, 6, 9, 8, 0, 0, 4, 4]
>>> n2[0:3]
['Shanshan', 'LongTing', 'Alex']
>>> n2[:3]
['Shanshan', 'LongTing', 'Alex']
>>> n2[:]
['Shanshan', 'LongTing', 'Alex', 1, 2, 4, 4, 5, 7, 6, 9, 8, 0, 0, 4, 4]
>>> n2
['Shanshan', 'LongTing', 'Alex', 1, 2, 4, 4, 5, 7, 6, 9, 8, 0, 0, 4, 4]
>>> n2[7]
5
>>> n2[:7]
['Shanshan', 'LongTing', 'Alex', 1, 2, 4, 4]
>>> n2[:7:2]
['Shanshan', 'Alex', 2, 4]
>>> n2[:7:-2] 反向查找,从右边到左边开始数
[4, 0, 8, 6]
>>> n2
['Shanshan', 'LongTing', 'Alex', 1, 2, 4, 4, 5, 7, 6, 9, 8, 0, 0, 4, 4]
>>> n2[:7:1]
['Shanshan', 'LongTing', 'Alex', 1, 2, 4, 4]
>>> n2[:-1]
['Shanshan', 'LongTing', 'Alex', 1, 2, 4, 4, 5, 7, 6, 9, 8, 0, 0, 4]
>>> n2
['Shanshan', 'LongTing', 'Alex', 1, 2, 4, 4, 5, 7, 6, 9, 8, 0, 0, 4, 4]
>>> n2[:-1:3]
['Shanshan', 1, 4, 6, 0]
>>> n2[:-1:4]
['Shanshan', 2, 7, 0]
>>> n2[-8:-1]
[7, 6, 9, 8, 0, 0, 4]
>>> n2[-8:-1:-2]
[]
>>> n2[-1:-8] 从右往左查,就是空的
[]
>>> n2[-2:-4]
[]
增加、插入、修改 、扩展
append追加到最后面;
修改 n2[2] = 'peiqi' ;
n2.insert(3,"abc")插入,在下标为3的位置插入"abc",不是替换,是插入一个值;
n.extend( n2 )扩展
>>> lst = list(range(10))
>>> lst.append('hello')
>>> print(lst)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 'hello']
修改
>>> n2
['Shanshan', 'LongTing', 'Alex', 1, 2, 4, 4, 5, 7, 6, 9, 8, 0, 0, 4, 4]
>>> n2[3]
1
>>> n2[3] = 'kris' #修改
>>> n2
['Shanshan', 'LongTing', 'Alex', 'kris', 2, 4, 4, 5, 7, 6, 9, 8, 0, 0, 4, 4]
>>> n2[3:4] 一个类型是列表,切片
['kris']
>>> n2[3] 一个类型是字符串,索引
'kris'
>>> n2[4:6]
[2, 4]
>>> n2[4:6] = 'Jack Ma' 批量修改 ,以字符串的形式修改
>>> n2
['Shanshan', 'LongTing', 'Alex', 'kris', 'J', 'a', 'c', 'k', ' ', 'M', 'a', 4, 5, 7, 6, 9, 8, 0, 0, 4, 4]
>>> n2[4:6]
['J', 'a']
>>> n2[1:4] = ['peiqi', 'egon','xka'] #列表形式修改
>>> n2
['Shanshan', 'peiqi', 'egon', 'xka', 'J', 'a', 'c', 'k', ' ', 'M', 'a', 4, 5, 7, 6, 9, 8, 0, 0, 4, 4]
>>> n2[1:4] = ('alex','kris',0) #以元组形式修改;
>>> n2
['Shanshan', 'alex', 'kris', 0, 'J', 'a', 'c', 'k', ' ', 'M', 'a', 4, 5, 7, 6, 9, 8, 0, 0, 4, 4]
>>>
insert 插入 n.insert( 3 , '-' ) 这里索引3代表第四个值,即 '-' 的索引为3; x.insert( i, m )方法:在索引i处插入m;
列表是有序的,通过索引取值。
>>> n2
['Shanshan', 'alex', 'a', 4, 5, 7, 6, 9, 8, 0, 0, 4]
>>> n2.insert(2,'#')
>>> n2
['Shanshan', 'alex', '#', 'a', 4, 5, 7, 6, 9, 8, 0, 0, 4]
>>> n2.insert(3,'-')
>>> n2
['Shanshan', 'alex', '#', '-', 'a', 4, 5, 7, 6, 9, 8, 0, 0, 4]
>>>
extend扩展 n.extend( n2 ) 添加多个元素用.extend()方法:用新列表扩展原来的列表,注意和append()方法的区别
>>> n = ['z','y','e','c','b','a','A','*','&']
>>> n2 = [1,2,4]
>>> n + n2
['z', 'y', 'e', 'c', 'b', 'a', 'A', '*', '&', 1, 2, 4]
>>> n.extend(n2)
>>> n
['z', 'y', 'e', 'c', 'b', 'a', 'A', '*', '&', 1, 2, 4]
>>>
>>> list(range(10))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> lst = list(range(10))
>>> lst.append('Hello')
>>> print(lst)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 'Hello']
>>> lst.append(['a','b','c'])
>>> print(lst)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 'Hello', ['a', 'b', 'c']]
>>> lst.extend(['a','b','c'])
>>> print(lst)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 'Hello', ['a', 'b', 'c'], 'a', 'b', 'c']
>>>
删除
n2.pop()默认是删除最后一个,( )里边是填你要删除的索引,索引必须是int类型不能是str;
n2.remove( ' ' )必须是具体要删除哪个;remove方法:移除列表中某个值的第一个匹配项;
del n2[ ]是根据索引来删除的,del语句:删除list的相应索引值;del n2是删除整个列表。
n2.clear() 移除所有值
####.pop( )
>>> n2 ['Shanshan', 'alex', 'kris', 0, 'J', 'a', 'c', 'k', ' ', 'M', 'a', 4, 5, 7, 6, 9, 8, 0, 0, 4, 4] >>> n2.pop() 4 >>> n2 ['Shanshan', 'alex', 'kris', 0, 'J', 'a', 'c', 'k', ' ', 'M', 'a', 4, 5, 7, 6, 9, 8, 0, 0, 4]>>> n2.pop(2) 'kris' >>> n2 ['Shanshan', 'alex', 0, 'J', 'a', 'c', 'k', ' ', 'M', 'a', 4, 5, 7, 6, 9, 8, 0, 0, 4]
###.remove( ) >>> n2.remove('J') >>> n2 ['Shanshan', 'alex', 0, 'a', 'c', 'k', ' ', 'M', 'a', 4, 5, 7, 6, 9, 8, 0, 0, 4] >>> n2.remove(0) >>> n2 ['Shanshan', 'alex', 'a', 'c', 'k', ' ', 'M', 'a', 4, 5, 7, 6, 9, 8, 0, 0, 4] >>> n2.remove() 必须要有个索引值 TypeError: remove() takes exactly one argument (0 given)
###del
>>> del n2[2:6] >>> n2 ['Shanshan', 'alex', 'M', 'a', 4, 5, 7, 6, 9, 8, 0, 0, 4] >>> del n2[2] >>> n2 ['Shanshan', 'alex', 'a', 4, 5, 7, 6, 9, 8, 0, 0, 4] >>> del n2 把整个列表都删除了
###clear( ) >>> n2 = ['Shanshan', 'alex', 'a', 4, 5, 7, 6, 9, 8, 0, 0, 4] >>> n2.clear() 清除列表内的所有值 >>> n2 [] >>> n2 = ['Shanshan', 'alex', 'a', 4, 5, 7, 6, 9, 8, 0, 0, 4]
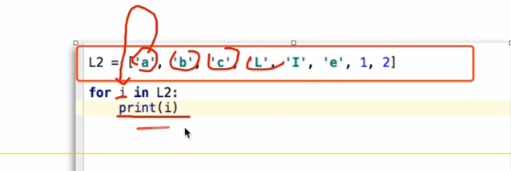
循环
for i in L2: range(10) for i in range(10) ----print(i)
列表与 range生成器
>>> print(range(5),type(range(5))) # range()是生成器,指向了一个范围
range(0, 5) <class 'range'>
# range(5)代表指向了0,1,2,3,4这几个值
# range(2,5)代表指向了2,3,4这几个值,注意这里不是使用:
# range(0,10,2)代表指向了0,2,4,6,8这几个值,最后的2代表步长
>>> lst = list(range(5)) # 通过list()函数生成列表
>>> print(lst)
[0, 1, 2, 3, 4]
while和for的区别:while可以是死循环(while True: print(1)),for循环是有边界的。
reverse()倒转 n.reverse( )
参数reverse:反向排序,针对数字; lst1.sort(reverse=True)
排序 sort()默认升序排序/字母顺序。sort不支持‘int’和‘str’一块排序;
lst1.sort( )默认升序 、lst.sort( reverse=True )反向排序
函数sorted( ):排序并复制 lst3 = sorted( lst1 )
>>> n = ['A', '!', 'a', 'b', '#', '*', 'c', 'y', 'e']
>>> n.sort() 按照ASCII表进行排序的
>>> n
['!', '#', '*', 'A', 'a', 'b', 'c', 'e', 'y']
>>> n = ['A', '!', 'a', 'b', '#', '*', 'c', 'y', 'e', 4, 0]
>>> n.sort()
TypeError: '<' not supported between instances of 'int' and 'str'
>>> lst1 = [12,45,36,28,90]
>>> lst2 = ['adf','csb','gty']
>>> lst1.sort()
>>> lst2.sort()
>>> print(lst1,lst2)
[12, 28, 36, 45, 90] ['adf', 'csb', 'gty']
>>>
>>> lst1.sort(reverse=True) #反向排序
>>> lst2.sort(reverse=True)
>>> print(lst1,lst2)
[90, 45, 36, 28, 12] ['gty', 'csb', 'adf']
>>>
>>> lst3 = sorted(lst1) #排序并复制
>>> lst3.append('Hello')
>>> print(lst1,lst3)
[90, 45, 36, 28, 12] [12, 28, 36, 45, 90, 'Hello']
copy
n2.copy()
>>> n2
[1, 2, 4]
>>> n3=n2.copy()
>>> n2
[1, 2, 4]
>>> n3
[1, 2, 4]
>>> a = 1
>>> b = 2
>>> b = a
>>> a
1
>>> b
1
>>>
>>>
>>> n = [3,4,5]
>>> n4 = n
>>> n
[3, 4, 5]
>>> n4
[3, 4, 5]
>>> n[1] = 'kris'
>>> n
[3, 'kris', 5]
>>> n4
[3, 'kris', 5]
>>>
>>>
>>> n5=n.copy() #copy是让它完全独立,独立的内存地址,n再做修改不影响n5
>>> n5
[3, 'kris', 5]
>>>
>>> n[2]='jack'
>>> n
[3, 'kris', 'jack']
>>> n5
[3, 'kris', 5]
copy,它的内存地址就会发生改变,会独立
赋值语句b = a,变量a和变量b指向了同一个对象的内存空间; 1和2都是对象或说叫内存。
>>> a = 1
>>> b = 2
>>> id(a);id(b)
1365423168
1365423200
>>> b = a
>>> a
1
>>> b
1
>>> id(a);id(b)
1365423168
1365423168
>>> n = [1,2,3,4] >>> n2 = n >>> id(n);id(n2) #共享引用一个可变对象,内存地址是一样的 37157704 37157704
>>>n[0] = 200 #因为列表可变,改变n中第一个元素的值
>>>n;n2 #改变后,n,n2同时改变,因为对象本身值变了;n,n2指向同一个列表。
>>>[200,2,3,4]
>>>[200,2,3,4]
#############如果不想改变n2的值,有两种方法:切片和copy模块。###############
############切片技术应用于所有的序列,包括:列表、字符串、元组。但切片不能应用于字典###
>>> n2 = n[:] #切片操作 >>> id(n);id(n2) #切片后对象就不一样了 37157704 37157512 >>> n[0] = 100 >>> n;n2 #n发生改变,n2没有变化; [100, 2, 3, 4] [1, 2, 3, 4] >>>
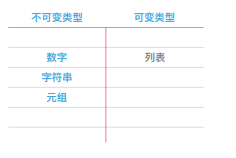
在python中不可变对象指:一旦创建就不可修改的对象,包括字符串、元组、数字; 可变对象是指:可以修改的对象,包括列表、字典。
深浅copy 深浅拷贝,即可用于序列也可用于字典。
- 浅拷贝只拷贝顶级对象(父级对象);
- 深拷贝是拷贝所有对象,顶级对象及其嵌套对象(父级对象及其子对象)
列表里每个元素都是有独立内存地址的
浅copy names.copy copy()是把内存地址copy了。copy是修改列表嵌套里边的内容,被copy的会发生改变;修改外层的内容,被copy的不会发生改变。
>>> names = ['Alex Li', 'jack', '-2', ['LT', 24]]
>>> n3 = names.copy() ##names.copy( )复制一个新列表,names和n3指向两个列表(虽然两个列表值相同)
>>> names
['Alex Li', 'jack', '-2', ['LT', 24]]
>>> n3
['Alex Li', 'jack', '-2', ['LT', 24]]
>>> id(names)
43503240
>>> id(n3)
43516424
>>> id(names[-1][0])
43524928
>>> id(n3[-1][0])
43524928
>>> names[-1][0] = 'kris'
>>> names
['Alex Li', 'jack', '-2', ['kris', 24]]
>>> n3
['Alex Li', 'jack', '-2', ['kris', 24]] #修改列表嵌套里边的内容,被copy的也会发生改变;
>>> id(names[-1][0])
43524704
>>> id(n3[-1][0])
43524704
>>> id(names)
43503240
>>>
>>> id(names[2])
43524872
>>> id(n3[2])
43524872
>>> names[2] = 3
>>> names
['Alex Li', 'jack', 3, ['kris', 24]]
>>> n3
['Alex Li', 'jack', '-2', ['kris', 24]] #修改列表外边的内容,被copy的不会发生改变
>>> id(names[2])
504018048
>>> id(n3[2])
43524872
>>>
深copy是完全克隆了一份,是放在工具箱里的(不建议使用,因为会增加内存)
copy.deepcopy(names) 修改列表里边嵌套的内容,deepcopy后的不会改变;修改外层的也不会改变。
>>> import copy
>>> n4 = copy.deepcopy(names)
>>> names
['Alex Li', 'jack', 3, ['kris', 24]]
>>> n4
['Alex Li', 'jack', 3, ['kris', 24]]
>>> id(names)
43383432 ##可以看出它们的内存空间对象是不一样的
>>> id(n4)
43383112
>>> names[-1][0] = 'windy' #改变names值的子对象,n4不变;
>>> names
['Alex Li', 'jack', 3, ['windy', 24]]
>>> n4
['Alex Li', 'jack', 3, ['kris', 24]]
>>> names[2] = 9 #改变names值的源对象,n4不变。
>>> names
['Alex Li', 'jack', 9, ['windy', 24]]
>>> n4
['Alex Li', 'jack', 3, ['kris', 24]]
>>>
结论:
深浅拷贝都是对源对象的复制,占用不同的内存空间。如果源对象只有一级目录的话,源做任何改动,不影响深浅拷贝对象;如果源对象不止一级目录的话,子对象做任何改动,都要
影响浅拷贝,但不影响深拷贝。序列对象的切片其实是浅拷贝,即只拷贝顶级的对象。
# 列表的特征
- 可包含任意类型的对象:数值、字符串、列表等;
- 通过下标索引访问序列中的值 → 序列的顺序是不能改变的,通过索引来定位列表的元素;
- 可随意变换列表长度,相当于随意指定新的列表;
- 可嵌套;可原位改变。
2、元组 tuple (不可变列表)
有序、不可变(但如果元组中包含其他可变元素,这些元素是可变的),就像只读列表不能修改。
#print(t[0]="one") #SyntaxError: keyword can't be an expression #不能删除; 保护只读数据
定义:与列表类似,只不过[]改成()
tup3 = "a", "b", "c", "d" # 可以不加括号
tup4 = (50,) # 元组中只包含一个元素时,需要在元素后面添加逗号
索引、切片和list一样;
元祖不能单独删除内部元素(不可变性),但可以del语句来删除整个元祖;
特性:
1.可存放多个值
2.不可变
3.按照从左到右的顺序定义元组元素,下标从0开始顺序访问,有序
功能:index、count、切片(获取数据并不是修改)。使用场景:显示的告诉别人,此处数据不可修改。如数据库连接配置信息。
tup1 = ('physics', 'chemistry', 1997, 2000);
tup2 = (1, 2, 3, 4, 5 );
tup3 = "a", "b", "c", "d" # 可以不加括号
tup4 = (50,) # 元组中只包含一个元素时,需要在元素后面添加逗号
print(tup1[2],tup3[:2]) # 索引、切片和list一样
del tup3 # 元祖不能单独删除内部元素(不可变性),但可以del语句来删除整个元祖
#print(tup3)
print(len(tup1))
print(tup1 + tup2)
print(tup4 * 3)
print(max(tup2),min(tup2))
# 序列通用函数
lst = list(range(10))
tup5 = tuple(lst) # tuple()函数:将列表转换为元组
print(tup5)
>>> n2 = (1,2,4,5,6,6,7,78)
>>> n2[2:5]
(4, 5, 6)
>>> n2=(1,2,3,['a','b','c'],5)
>>> n2[3]
['a', 'b', 'c']
>>> n2[3][1]
'b'
>>> n2[3][1] = 'B'
>>> n2
(1, 2, 3, ['a', 'B', 'c'], 5)
3、字典
如何在一个变量里存储公司每个员工的个人信息。
字典 key-value
- 键值对,一定共同出现,不能只有一个;
- 不允许同一个键出现两次:创建时如果同一个键被赋值两次,后一个值会被记住;
- key必须是不可变的对象,value则可以是任意对象:数值,字符串,序列,字典;
- 字典是一个无序集合,序列由于没有key来做对应,所以以顺序来对应值;序列有顺序,字典没有!
申明字典的方式:
- 手写一个;
- dict()函数,dict()由序列生成一个字典,嵌套序列可以是list或者tuple;
>>> lst1 = [("a", "fff"),("b", "ggg")]
>>> dic1 = dict(lst1)
>>> dic1
{'a': 'fff', 'b': 'ggg'}
>>> lst2 = [["c",1],["d",2]]
>>> dic2 = dict(lst2)
>>> dic2
{'c': 1, 'd': 2}
>>> lst3 = (("e",[1,2]), ("f",[3,4]))
>>> dic3 = dict(lst3)
>>> dic3
{'e': [1, 2], 'f': [3, 4]}
>>> keys = ["a", "b", "c"]
>>> dic1 = dict.fromkeys(keys)
>>> dic2 = dict.fromkeys(keys, "Hello")
>>> dic1
{'a': None, 'b': None, 'c': None}
>>> dic2
{'a': 'Hello', 'b': 'Hello', 'c': 'Hello'}
>>>
>>> info = {
... 'smile':[24,'design','UI',134778],
... 'kris':[22,'PR','wild model',134552]
... }
>>> info
{'smile': [24, 'design', 'UI', 134778], 'kris': [22, 'PR', 'wild model', 134552]}
>>> info['smile'] #####查询
[24, 'design', 'UI', 134778]
>>> info['smile'][1]
'design'
>>> info['smile'][1] = "设计部" ###修改
>>> info
{'smile': [24, '设计部', 'UI', 134778], 'kris': [22, 'PR', 'wild model', 134552]}
>>> info['windy'] = "HK" #增加
>>> info
{'smile': [24, '设计部', 'UI', 134778], 'kris': [22, 'PR', 'wild model', 134552], 'windy': 'HK'}
特性:
1.key-value结构
2.key必须可hash、且必须为不可变数据类型、必须唯一
3.可存放任意多个值、可修改、可以不唯一
4.无序字典没有索引没有顺序,有key就可以了;字典查找速度快,
查找 获取的两种方法,见下
>>> info {'smile': [24, '设计部', 'UI', 134778], 'kris': [22, 'PR', 'wild model', 134552], 'windy': 'HK'} >>> "smile" in info ###标准用法 True >>> info.get("smile") ###获取 [24, '设计部', 'UI', 134778] >>> info["smile"] ###同上,如果一个key不存在就会报错; get不会,不存在只返回None [24, '设计部', 'UI', 134778]
删除(三种方法)
- dic.clear() 清空字典所有条目;
- del dic删除字典;
>>> info
{'smile': [24, '设计部', 'UI', 134778], 'kris': [22, 'PR', 'wild model', 134552], 'windy': 'HK'}
>>> info.pop('windy')
'HK'
>>> info
{'smile': [24, '设计部', 'UI', 134778], 'kris': [22, 'PR', 'wild model', 134552]}
>>> pop_kk=info.pop('kk',None) ###删除一个不存在的key,不存在就输出为None;>>> print(pop_kk)
None
删除字典中键 ‘k5’ 对应的键值对,如果字典中不存在键'k5',则不报错,并且让其返回none;
if 'k5' in info:
info.pop('k5')
else:
print(info.get('k5')) ##没有就输出None
>>> info {'smile': [24, '设计部', 'UI', 134778], 'kris': [22, 'PR', 'wild model', 134552]} >>> info[4]=2 ####添加 >>> info[3]=2 >>> info[2]=2 >>> info[1]=2 >>> info {'smile': [24, '设计部', 'UI', 134778], 'kris': [22, 'PR', 'wild model', 134552], 4: 2, 3: 2, 2: 2, 1: 2} >>> info.popitem() ###随机删除 (1, 2) >>> info {'smile': [24, '设计部', 'UI', 134778], 'kris': [22, 'PR', 'wild model', 134552], 4: 2, 3: 2, 2: 2} >>> info.popitem() (2, 2) >>> info {'smile': [24, '设计部', 'UI', 134778], 'kris': [22, 'PR', 'wild model', 134552], 4: 2, 3: 2}
多级字典嵌套
>>> catlog={ ... "家电":{ ... "www.xiaomi.com":["全屋智能"], ... "www.haier.com":["洗衣机冰箱"], ... "www.geli.com":["空调"] ... }, ... "书籍":{ ... "www.dangdang.com":["物美价廉好书"] ... }, ... "美妆":{ ... "www.beautiful.com":["雅诗兰黛"] ... } ... } >>> catlog {'家电': {'www.xiaomi.com': ['全屋智能'], 'www.haier.com': ['洗衣机冰箱'], 'www.geli.com': ['空调']}, '书籍': {'www.dangdang.com': ['物美价廉好书']}, '美妆': {'www.beautiful.com': ['雅诗兰黛']}} >>> catlog["美妆"]["www.beautiful.com"][1] += ",buy buy buy" #修改 >>> catlog["美妆"]["www.beautiful.com"][0] += ",buy buy buy" >>> catlog["美妆"]["www.beautiful.com"] ['雅诗兰黛,buy buy buy']
其他
update items
dict.update()方法:更新/合并一个字典,把第二个字典合并到第一个字典,改变了第一个字典;
和序列的原理一样,a和b指向同一个字典,所以会一起更新;
>>> a = {'m':1 , 'n':2 , 'p':3}
>>> b = a.copy() ###通过.copy方法复制一个新字典
>>> a
{'m': 1, 'n': 2, 'p': 3}
>>> b
{'m': 1, 'n': 2, 'p': 3}
>>> a.update({'q':4}) ###
>>> a,b
({'m': 1, 'n': 2, 'p': 3, 'q': 4}, {'m': 1, 'n': 2, 'p': 3})
>>> id(a),id(b)
(140577839609088, 140577839153552)
>>>
>>> print(len(a))
4
>>> print('m' in a)
True
>>> print('l' in a)
False
## in / not in :判断是否包含,这里的判断对象是key
>>> info
{'smile': [24, '设计部', 'UI', 134778], 'kris': [22, 'PR', 'wild model', 134552], 4: 2, 3: 2}
>>> info.keys()
dict_keys(['smile', 'kris', 4, 3])
>>> info.values()
dict_values([[24, '设计部', 'UI', 134778], [22, 'PR', 'wild model', 134552], 2, 2])
>>> info.items() ###把字典转换为一个列表
dict_items([('smile', [24, '设计部', 'UI', 134778]), ('kris', [22, 'PR', 'wild model', 134552]), (4, 2), (3, 2)])
>>>
>>> dic2 = {1:2, 2:3, 4:44, 'kris':[18,'stu',13456]}
>>> info.update(dic2
dic2
>>> info.update(dic2) ###有就覆盖,没有就创建。
>>> info
{'smile': [24, '设计部', 'UI', 134778], 'kris': [18, 'stu', 13456], 4: 44, 3: 2, 1: 2, 2: 3}
>>>
.get(key)方法 :直接查看key的value,如果没有相应key则返回None,添加print参数可以多返回一个值
>>> poi = {'name':'shop', 'city':'shanghai', 'information':{'address':'somewhere', 'num':66663333}} >>> print(poi.get('name')) shop >>> print(poi.get('type',print('nothing'))) nothing None
.keys()方法:输出字典所有key,注意这里的输出内容格式是视图,可以用list()得到key的列表,类似range();
.values()方法:输出字典所有values,原理同.keys()方法
>>> print(poi.keys(),type(poi.keys())) dict_keys(['name', 'city', 'information']) <class 'dict_keys'> >>> print(poi.values(),type(poi.values())) dict_values(['shop', 'shanghai', {'address': 'somewhere', 'num': 66663333}]) <class 'dict_values'> >>> print(list(poi.values())) ['shop', 'shanghai', {'address': 'somewhere', 'num': 66663333}] >>>
.items()方法:输出字典所有items(元素),原理同.keys()方法
>>> print(poi.items(),type(poi.items())) dict_items([('name', 'shop'), ('city', 'shanghai'), ('information', {'address': 'somewhere', 'num': 66663333})]) <class 'dict_items'> >>> print(list(poi.items())) [('name', 'shop'), ('city', 'shanghai'), ('information', {'address': 'somewhere', 'num': 66663333})] >>>
setdefault
>>> info {'smile': [24, '设计部', 'UI', 134778], 'kris': [18, 'stu', 13456], 4: 44, 3: 2, 1: 2, 2: 3} >>> info.setdefault(4,'new4') ###如果有4,就把它拿过来,如果没有就把它赋值为new4 44 >>> info {'smile': [24, '设计部', 'UI', 134778], 'kris': [18, 'stu', 13456], 4: 44, 3: 2, 1: 2, 2: 3} >>> info.setdefault(44,'new4') 'new4' >>> info {'smile': [24, '设计部', 'UI', 134778], 'kris': [18, 'stu', 13456], 4: 44, 3: 2, 1: 2, 2: 3, 44: 'new4'}
fromkeys
>>> info {'smile': [24, '设计部', 'UI', 134778], 'kris': [18, 'stu', 13456], 4: 44, 3: 2, 1: 2, 2: 3, 44: 'new4'} >>> info.fromkeys(['A','B','C']) ###先生成一个空字典,往里边填信息即可。 {'A': None, 'B': None, 'C': None} >>> info {'smile': [24, '设计部', 'UI', 134778], 'kris': [18, 'stu', 13456], 4: 44, 3: 2, 1: 2, 2: 3, 44: 'new4'} >>> info.fromkeys(['A','B','C'],'alex') {'A': 'alex', 'B': 'alex', 'C': 'alex'} >>> info {'smile': [24, '设计部', 'UI', 134778], 'kris': [18, 'stu', 13456], 4: 44, 3: 2, 1: 2, 2: 3, 44: 'new4'} >>> >>> info.fromkeys(['A','B','C']) {'A': None, 'B': None, 'C': None}
循环
poi = {'name':'shop', 'city':'shanghai', 'information':{'address':'somewhere', 'num':66663333}}
for key in poi.keys():
print(key)
print('-------')
for value in poi.values():
print(value)
print('-------')
for (k,v) in poi.items(): ###迭代器
print('key为 %s, value为 %s' %(k,v))
print('-------')
# for函数遍历
for k in info:
print(k)
for k in info:
print(k, info[k])
for k,v in info.items(): ###把字典转换成列表再循环,比较低效
print(k, v)
#socket + IO,只支持字节、字符传输 str(d) ---Http rest-->>> ES的json字符
#######Set ##不支持切片
4、集合/set
集合是一个数学概念:由一个或多个确定的元素所构成的整体叫做集合。
集合中的元素有三个特征:
- 1.确定性(元素必须可hash)
- 2.互异性(去重)
- 3.无序性(集合中的元素没有先后之分),如集合{3,4,5}和{3,5,4}算作同一个集合。
iphone7 = ['alex', 'alex', 'rain', 'jack', 'old_driver']
iphone8 = ['alex', 'shang', 'jack', 'old_boy']
#### 比较繁琐的去重方式
both_list = []
for name in iphone8:
if name in iphone7:
both_list.append(name)
print(both_list) # ['alex', 'jack']
去重
>>> s = {1,2,3,4,2,3,6} ##集合s 的定义
>>> s
{1, 2, 3, 4, 6}
>>> l = [1,2,3,4,5,2,3]
>>> l
[1, 2, 3, 4, 5, 2, 3]
>>> set(l) #列表转换为set集合进行去重
{1, 2, 3, 4, 5}
>>> s = set(l) #列表转成集合。
>>> s
{1, 2, 3, 4, 5}
增删改查
>>>#增
>>> s.add(6)
>>> s
{1, 2, 3, 4, 5, 6}
>>> s.update(['a','b',3,4])
>>> s
{1, 2, 3, 4, 'a', 6, 'b'}
>>>
#删
s = {1,2,3,4,6}
>>> s.pop() #随机删
1
>>> s.remove(6)
>>> s
{3, 4, 5}
>>> s.discard(5)
>>> s
{3, 4}
>>> s.clear()
>>> s
set()
>>>
关系测试:交差并
>>> iphone7
{'rain', 'jack', 'alex', 'old_driver'}
>>> iphone8
{'jack', 'alex', 'old_boy', 'shang'}
#取交集
>>> iphone7.intersection(iphone8)
{'jack', 'alex'}
>>> iphone7&iphone8
{'jack', 'alex'}
#取差集
>>> iphone7.difference(iphone8)
{'rain', 'old_driver'}
>>> iphone7 - iphone8
{'rain', 'old_driver'}
#取并集
>>> iphone7.union(iphone8)
{'old_driver', 'shang', 'alex', 'old_boy', 'jack', 'rain'}
>>> iphone7 | iphone8
{'old_driver', 'shang', 'alex', 'old_boy', 'jack', 'rain'}
#取交集相反的:对称差集
>>> iphone7.symmetric_difference(iphone8)
{'old_driver', 'shang', 'old_boy', 'rain'}
>>> iphone7^iphone8
{'old_driver', 'shang', 'old_boy', 'rain'}
包含关系
in,not in 判断某元素是否在集合内 ==, != 判断两个集合是否相等
两个集合之间一般有三种关系: 相交、 包含、 不相交,在python中分别用如下方法判断:
>>> s.isdisjoint(s2) #判断两个集合是不是不相交
False
>>> s.issuperset(s2) #判断集合是不是包含其他集合, 等同于 a >= b
False
>>> s.issubset(s2) #判断集合是不是被其他集合包含,等同于 a <= b
True
数据类型转换
# 数据类型总结
- 字符串 string
- 数字类型 Number
- 整型 int
- 浮点 float
- 复数
- 布尔 bool
- 列表 list
- 元组 tuple
- 字典 dict
- 集合 set
可变数据类型:列表,字典,集合
不可不数据类型: 字符串,数字,元组
容器类型数据 : 字符串,列表,元组,集合,字典
非容器类型数据: 数字,布尔类型
什么是数据类型转换? 把一个数据类型转换为另一个数据类型,例如 字符串转为数字
为什么需要数据类型转换? 因为不同的数据类型之间不能运算
基础数据类型转换
数据类型转换的形式?
- 自动类型转换
- 强制类型转换
# 自动类型转换
当两个不同的值进行运算时,结果会向更高的精度进行计算
True ==> 整型 ==> 浮点 ==> 复数
# 强制类型转换
下面的函数,可以把其它类型的数据,转换为对应的数据类型
str() 可以把所有的其它数据类型转换为字符串类型;字符串转数字类型时,如果字符串中时纯数字,可以转换
int() 其它容器类型不能转为数字int类型
float() 浮点类型的转换和int类型一样,不过转换的结果是浮点类型
bool() bool可以把其它类型转换布尔类型的True或False
list()
tuple()
dict()
set()
容器类型转换
# list 列表 ''' 数字类型是 非容器类型,不能转换为列表 字符串 转换为列表时 会把字符串中的每一个字符当做列表的元素 集合 可以转换为 list列表类型 元组 可以转换为 list列表类型 字典 可以转换为 list列表类型,只保留了字典中的键 ''' # n = {'name':'zhangsan','age':20} # res = list(n) # print(n,type(n),res,type(res))
# tuple 元组 ''' 数字类型 非容器类型,不能转换为元组 其它容器类型的数据进行转换时,和列表一样 ''' # n = {'name':'zhangsan','age':20} # res = tuple(n) # print(n,type(n),res,type(res))
# set 集合 ''' 数字类型 非容器类型,不能转换为 集合 字符串,列表,元组 可以转为 集合 结果是无序的 字典转换为集合时,只保留了字典的键 key ''' # n = {'a':1,'b':2} # res = set(n) # print(n,type(n),res,type(res))
# dict 字典 ''' 数字类型 非容器类型,不能转换为 字典 字符串不能直接转换为 字典 列表可以转换为字典,要求是一个二级列表,并且每个二级元素只能有两个值 元组可以转换为字典,要求是一个二级元组,并且每个二级元素只能有两个值 '''
hash(哈希)函数
简单来说就是将任意长度的的消息压缩到某一固定长度的消息摘要的函数。
hash值的计算过程是依据这个值的一些特征计算的,这就要求被hash的值必须固定,因此被hash的值必须是不可变的。
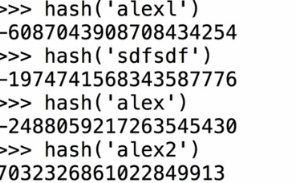
用途:文件签名、md5加密(不能反解)、密码验证。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号