
Spark UI
倍率与中签率分析”案例用到的资源如下所示:

接下来是代码,我们一步步地实现了“倍率与中签率分析”的计算逻辑

import org.apache.spark.sql.DataFrame val rootPath: String = _ // 申请者数据 val hdfs_path_apply: String = s"${rootPath}/apply" // spark是spark-shell中默认的SparkSession实例 // 通过read API读取源文件 val applyNumbersDF: DataFrame = spark.read.parquet(hdfs_path_apply) // 中签者数据 val hdfs_path_lucky: String = s"${rootPath}/lucky" // 通过read API读取源文件 val luckyDogsDF: DataFrame = spark.read.parquet(hdfs_path_lucky) // 过滤2016年以后的中签数据,且仅抽取中签号码carNum字段 val filteredLuckyDogs: DataFrame = luckyDogsDF.filter(col("batchNum") >= "201601").select("carNum") // 摇号数据与中签数据做内关联,Join Key为中签号码carNum val jointDF: DataFrame = applyNumbersDF.join(filteredLuckyDogs, Seq("carNum"), "inner") // 以batchNum、carNum做分组,统计倍率系数 val multipliers: DataFrame = jointDF.groupBy(col("batchNum"),col("carNum")) .agg(count(lit(1)).alias("multiplier")) // 以carNum做分组,保留最大的倍率系数 val uniqueMultipliers: DataFrame = multipliers.groupBy("carNum") .agg(max("multiplier").alias("multiplier")) // 以multiplier倍率做分组,统计人数 val result: DataFrame = uniqueMultipliers.groupBy("multiplier") .agg(count(lit(1)).alias("cnt")) .orderBy("multiplier") result.collect
为了展示StorageTab页面内容,“强行”给applyNumbersDF 和luckyDogsDF这两个DataFrame都加 Cache。对于引用数量为1的数据集,实际没有必要加Cache的。
看下配置项。为了让Spark UI能够展示运行中以及执行完毕的应用,我们还需要设置如下配置项并启动 History Server。

// SPARK_HOME表示Spark安装目录 ${SPAK_HOME}/sbin/start-history-server.sh
好啦,到此为止,一切准备就绪。接下来,让我们启动spark-shell,并提交“倍率与中签率分析”的代码,然后把目光转移到Host1的8080端口,也就是Driver所在节点的8080端口。
一级入口
打开Spark UI,首先映入眼帘的是默认的Jobs页面。Jobs页面记录着应用中涉及的Actions动作,以及与数据读取、移动有关的动作。其中,每一个Action都对应着一个Job,而每一个Job都对应着一个作业。我们一会再去对Jobs页面做展开,现在先把目光集中在
Spark UI最上面的导航条,这里罗列着Spark UI所有的一级入口,如下图所示。

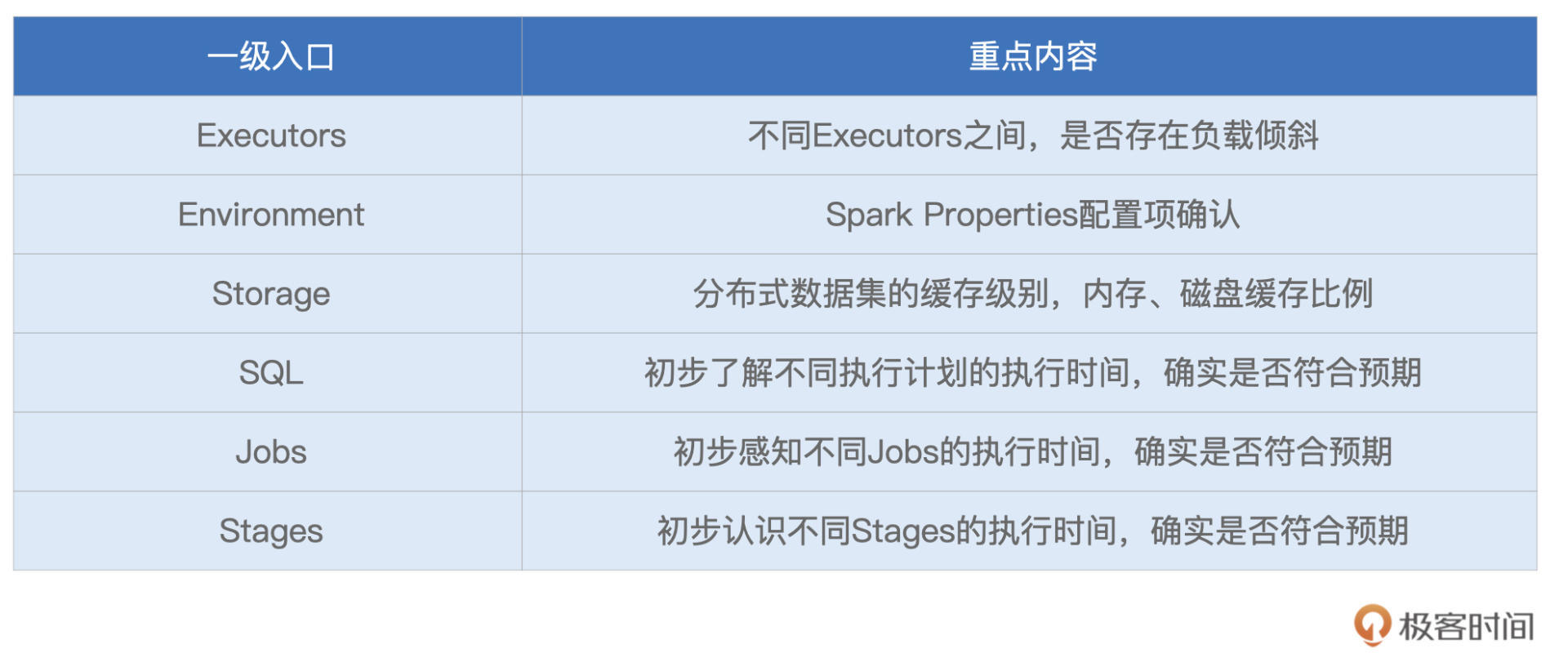
导航条最左侧是Spark Logo以及版本号,后面则依次罗列着6个一级入口,每个入口的功能与作用我整理到了如下的表格中,你可以先整体过一下,后面我们再挨个细讲。

形象点说,这6个不同的入口,就像是体检报告中6大类不同的体检项,比如内科、外科、血常规,等等。接下来,让我们依次翻开“体检报告”的每一个大项,去看看“倍率与中签率分析”这个家伙的体质如何。
不过,本着由简入难的原则,咱们并不会按照Spark UI罗列的顺序去查看各个入口,而是按照Executors > Environment > Storage > SQL > Jobs > Stages的顺序,去翻看“体检报告”。
其中,前3个入口都是详情页,不存在二级入口;而后3个入口都是预览页,都需要访问二级入口,才能获取更加详细的内容。显然,相比预览页,详情页来得更加直接。接下来,让我们从Executors开始,先来了解一下应用的计算负载。
Executors
Executors Tab的主要内容如下,主要包含“Summary”和“Executors”两部分。这两部分所记录的度量指标是一致的,其中“Executors”以更细的粒度记录着每一个Executor的详情,而第一部分“Summary”是下面所有Executors度量指标的简单加和。

我们一起来看一下,Spark UI都提供了哪些Metrics,来量化每一个Executor的工作负载(Workload)。为了叙述方便,我们以表格的形式说明这些Metrics的含义与作用。

不难发现,Executors页面清清楚楚地记录着每一个Executor消耗的数据量,以及它们对CPU、内存与磁盘等硬件资源的消耗。基于这些信息,我们可以轻松判断不同Executors之间是否存在负载不均衡
的情况,进而判断应用中是否存在数据倾斜的隐患。
对于Executors页面中每一个Metrics的具体数值,它们实际上是Tasks执行指标在Executors粒度上的汇总。因此,对于这些Metrics的释义,咱们留到Stages二级入口再去展开,这里暂时不做一一深入。
你不妨结合“倍率与中签率分析”的应用,去浏览一下不同
Metrics的具体数值,先对这些数字有一个直观上的感受。
实际上,这些具体的数值,并没有什么特别之处,除了RDD Blocks和Complete Tasks这两个Metrics。细看一下这两个指标,你会发现,RDD Blocks是51(总数),而Complete Tasks(总数)是862。
之前讲RDD并行度的时候,我们说过,RDD并行度就是RDD的分区数量,每个分区对应着一个Task,因此RDD并行度与分区数量、分布式任务数量是一致的。可是,截图中的51与862,显然不在一个量
级,这是怎么回事呢?
在Executors 页面,为什么 RDD Blocks 与 Complete Tasks 的数量不一致。
数量不一致是由于Executors在处理这个application下的所有job(一个job由action算子来触发, 每个job又会根据shuffle情况划分出多个stage,每个stage中又会划分出多个task,再根据taskScheduler分配到
各个Excecutor) 得出来的Complete Tasks。
每个rdd经过处理后,又可能生成其他rdd,这里的tasks应该是显示整个executors处理过的任务数,跟rdd的blocks无关。
Environment
接下来,我们再来说说Environment。顾名思义,Environment页面记录的是各种各样的环境变量与配置项信息,如下图所示。

为了让你抓住主线,我并没有给你展示Environment页面所包含的全部信息,就类别来说,它包含5大类环境信息,为了方便叙述,我把它们罗列到了下面的表格中。

显然,这5类信息中,Spark Properties是重点,其中记录着所有在运行时生效的Spark配置项设置。通过Spark Properties,我们可以确认运行时的设置,与我们预期的设置是否一致,从而排除因配置项
设置错误而导致的稳定性或是性能问题。
Storage
说完Executors与Environment,来看一级入口的最后一个详情页:Storage。

Storage详情页,记录着每一个分布式缓存(RDD Cache、DataFrame Cache)的细节,包括缓存级别、已缓存的分区数、缓存比例、内存大小与磁盘大小。
我们介绍过Spark支持的不同缓存级别,它是存储介质(内存、磁盘)、存储形式(对象、序列化字节)与副本数量的排列组合。对于DataFrame来说,默认的级别是单副本的Disk Memory Deserialized,如上图所示,也就是存储介质为内存加磁盘,存储形式为对象的单一副本存储方式。

Cached Partitions与Fraction Cached分别记录着数据集成功缓存的分区数量,以及这些缓存的分区占所有分区的比例。当Fraction Cached小于100%的时候,说明分布式数据集并没有完全缓存到内存
(或是磁盘),对于这种情况,我们要警惕缓存换入换出可能会带来的性能隐患。
后面的Size in Memory与Size in Disk,则更加直观地展示了数据集缓存在内存与硬盘中的分布。从上图中可以看到,由于内存受限(3GB/Executor),摇号数据几乎全部被缓存到了磁盘,只有584MB的
数据,缓存到了内存中。坦白地说,这样的缓存,对于数据集的重复访问,并没有带来实质上的性能收益。
基于Storage页面提供的详细信息,我们可以有的放矢地设置与内存有关的配置项,如spark.executor.memory、spark.memory.fraction、spark.memory.storageFraction,从而有针对性对Storage Memory
进行调整。
SQL
接下来,一级入口的SQL页面。当我们的应用包含DataFrame、Dataset或是SQL的时候,Spark UI的SQL页面,就会展示相应的内容,如下图所示。

具体来说,一级入口页面,以Actions为单位,记录着每个Action对应的Spark SQL执行计划。我们需要点击“Description”列中的超链接,才能进入到二级页面,去了解每个执行计划的详细信息。这部分内
容,我们留到下一讲的二级入口详情页再去展开。
Jobs
同理,对于Jobs页面来说,Spark UI也是以Actions为粒度,记录着每个Action对应作业的执行情况。我们想要了解作业详情,也必须通过“Description”页面提供的二级入口链接。你先有个初步认识就好,
下一讲我们再去展开。

相比SQL页面的3个Actions:save(保存计算结果)、count(统计申请编号)、count(统计中签编号),结合前面的概览页截图你会发现,Jobs页面似乎凭空多出来很多Actions。
主要原因在于,在Jobs页面,Spark UI会把数据的读取、访问与移动,也看作是一类“Actions”,比如图中Job Id为0、1、3、4的那些。这几个Job,实际上都是在读取源数据(元数据与数据集本身)。
至于最后多出来的、Job Id为7的save,你不妨结合最后一行代码,去想想问什么。这里我还是暂时卖个关子,留给你足够的时间去思考,咱们评论区见。
result05_01.write.mode("Overwrite").format("csv").save(s"${rootPath}/results/result05_01")
代码最后一个是save,会生成一个save的action;
Stages
我们知道,每一个作业,都包含多个阶段,也就是我们常说的Stages。在Stages页面,Spark UI罗列了应用中涉及的所有Stages,这些Stages分属于不同的作业。要想查看哪些Stages隶属于哪个Job,还需要从Jobs的Descriptions二
级入口进入查看。

Stages页面,更多地是一种预览,要想查看每一个Stage的详情,同样需要从“Description”进入Stage详情页。
好啦,到此为止,对于导航条中的不同页面,我们都做了不同程度的展开。简单汇总下来,其中Executors、Environment、Storage是详情页,开发者可以通过这3个页面,迅速地了解集群整体的计算负
载、运行环境,以及数据集缓存的详细情况;而SQL、Jobs、Stages,更多地是一种罗列式的展示,想要了解其中的细节,还需要进入到二级入口。
按照“Executors -> Environment -> Storage -> SQL -> Jobs -> Stages”的顺序,先后介绍了一级入口的详情页与概览页。对于这些页面中的内容,需要重点掌握的部分,整理到了如下表格,
供参考。
二级入口
二级入口,它指的是,通过一次超链接跳转才能访问到的页面。对于SQL、Jobs和Stages这3类入口来说,二级入口往往已经提供了足够的信息,基本覆盖了“体检报告”的全部内容。因此,尽管Spark UI
也提供了少量的三级入口(需要两跳才能到达的页面),但是这些隐藏在“犄角旮旯”的三级入口,往往并不需要开发者去特别关注。
接下来,我们就沿着SQL -> Jobs -> Stages的顺序,依次地去访问它们的二级入口,从而针对全局DAG、作业以及执行阶段,获得更加深入的探索与洞察。
SQL详情页
在SQL Tab一级入口,我们看到有3个条目,分别是count(统计申请编号)、count(统计中签编号)和save。前两者的计算过程,都是读取数据源、缓存数据并触发缓存的物化,相对比较简单,因此,
我们把目光放在save这个条目上。
点击图中的“save at:27”,即可进入到该作业的执行计划页面,如下图所示。
")
为了聚焦重点,这里我们仅截取了部分的执行计划,想要获取完整的执行计划,你可以通过访问这里来获得。为了方便你阅读,这里我手绘出了执行计划的示意图,供你参考,如下图所示。

可以看到,“倍率与中签率分析”应用的计算过程,非常具有代表性,它涵盖了数据分析场景中大部分的操作,也即过滤、投影、关联、分组聚合和排序。图中红色的部分为Exchange,代表的是Shuffle操
作,蓝色的部分为Sort,也就是排序,而绿色的部分是Aggregate,表示的是(局部与全局的)数据聚合。
无疑,这三部分是硬件资源的主要消费者,同时,对于这3类操作,Spark UI更是提供了详细的Metrics来刻画相应的硬件资源消耗。接下来,咱们就重点研究一下这3类操作的度量指标。
Exchange
下图中并列的两个Exchange,对应的是示意图中SortMergeJoin之前的两个Exchange。它们的作用是对申请编码数据与中签编码数据做Shuffle,为数据关联做准备。
:申请编码数据Shuffle,Exchange(右):中签编码数据Shuffle")
可以看到,对于每一个Exchange,Spark UI都提供了丰富的Metrics来刻画Shuffle的计算过程。从Shuffle Write到Shuffle Read,从数据量到处理时间,应有尽有。为了方便说明,对于Metrics的解释与释
义,我以表格的方式进行了整理,供你随时查阅。

结合这份Shuffle的“体检报告”,我们就能以量化的方式,去掌握Shuffle过程的计算细节,从而为调优提供更多的洞察与思路。
为了让你获得直观感受,我还是举个例子说明。比方说,我们观察到过滤之后的中签编号数据大小不足10MB(7.4MB),这时我们首先会想到,对于这样的大表Join小表,Spark SQL选择了
SortMergeJoin策略是不合理的。
基于这样的判断,我们完全可以让Spark SQL选择BroadcastHashJoin策略来提供更好的执行性能。至于调优的具体方法,想必不用我多说,你也早已心领神会:要么用强制广播,要么利用Spark 3.x版本
提供的AQE特性。
你不妨结合本讲开头的代码,去完成SortMergeJoin到BroadcastHashJoin策略转换的调优,期待你在留言区分享你的调优结果。
Sort
接下来,我们再来说说Sort。相比Exchange,Sort的度量指标没那么多,不过,他们足以让我们一窥Sort在运行时,对于内存的消耗,如下图所示。
:申请编码数据排序,Sort(右):中签编码数据排序")
按照惯例,我们还是先把这些Metrics整理到表格中,方便后期查看。

可以看到,“Peak memory total”和“Spill size total”这两个数值,足以指导我们更有针对性地去设置spark.executor.memory、spark.memory.fraction、spark.memory.storageFraction,从而使得Execution Memory区域得到充分的保障。
以上图为例,结合18.8GB的峰值消耗,以及12.5GB的磁盘溢出这两条信息,我们可以判断出,当前3GB的Executor Memory是远远不够的。那么我们自然要去调整上面的3个参数,来加速Sort的执行性
能。
Aggregate
与Sort类似,衡量Aggregate的度量指标,主要记录的也是操作的内存消耗,如图所示。

可以看到,对于Aggregate操作,Spark UI也记录着磁盘溢出与峰值消耗,即Spill size和Peak memory total。这两个数值也为内存的调整提供了依据,以上图为例,零溢出与3.2GB的峰值消耗,证明当前
3GB的Executor Memory设置,对于Aggregate计算来说是绰绰有余的。
到此为止,我们分别介绍了Exchange、Sort和Aggregate的度量指标,并结合“倍率与中签率分析”的例子,进行了简单的调优分析。
纵观“倍率与中签率分析”完整的DAG,我们会发现它包含了若干个Exchange、Sort、Aggregate以及Filter和Project。结合上述的各类Metrics,对于执行计划的观察与洞见,我们需要以统筹的方式,由点
到线、由局部到全局地去进行。
Jobs详情页
接下来,我们再来说说Jobs详情页。Jobs详情页非常的简单、直观,它罗列了隶属于当前Job的所有Stages。要想访问每一个Stage的执行细节,我们还需要通过“Description”的超链接做跳转。

Stages详情页
实际上,要访问Stage详情,我们还有另外一种选择,那就是直接从Stages一级入口进入,然后完成跳转。因此,Stage详情页也归类到二级入口。接下来,我们以Id为10的Stage为例,去看一看详情页都
记录着哪些关键信息。
在所有二级入口中,Stage详情页的信息量可以说是最大的。
点进Stage详情页,可以看到它主要包含3大类信息,分别是Stage DAG、Event Timeline与Task Metrics。
其中,Task Metrics又分为“Summary”与“Entry details”两部分,提供不同粒度的信息汇总。而Task Metrics中记录的指标类别,还可以通过“Show Additional Metrics”选项进行扩展。

Stage DAG
接下来,我们沿着“Stage DAG -> Event Timeline -> Task Metrics”的顺序,依次讲讲这些页面所包含的内容。
首先,我们先来看最简单的Stage DAG。点开蓝色的“DAG Visualization”按钮,我们就能获取到当前Stage的DAG,如下图所示。

之所以说Stage DAG简单,是因为咱们在SQL二级入口,已经对DAG做过详细的说明。而Stage DAG仅仅是SQL页面完整DAG的一个子集,毕竟,SQL页面的DAG,针对的是作业(Job)。因此,只要
掌握了作业的DAG,自然也就掌握了每一个Stage的DAG。
Event Timeline
与“DAG Visualization”并列,在“Summary Metrics”之上,有一个“Event Timeline”按钮,点开它,我们可以得到如下图所示的可视化信息。

Event Timeline,记录着分布式任务调度与执行的过程中,不同计算环节主要的时间花销。图中的每一个条带,都代表着一个分布式任务,条带由不同的颜色构成。其中不同颜色的矩形,代表不同环节的
计算时间。
为了方便叙述,我还是用表格形式帮你梳理了这些环节的含义与作用,你可以保存以后随时查看。

理想情况下,条带的大部分应该都是绿色的(如图中所示),也就是任务的时间消耗,大部分都是执行时间。不过,实际情况并不总是如此,比如,有些时候,蓝色的部分占比较多,或是橙色的部分占
比较大。
在这些情况下,我们就可以结合Event Timeline,来判断作业是否存在调度开销过大、或是Shuffle负载过重的问题,从而有针对性地对不同环节做调优。
比方说,如果条带中深蓝的部分(Scheduler Delay)很多,那就说明任务的调度开销很重。这个时候,我们就需要参考公式:D / P ~ M / C,来相应地调整CPU、内存与并行度,从而减低任务的调度开
销。其中,D是数据集尺寸,P为并行度,M是Executor内存,而C是Executor的CPU核数。波浪线~表示的是,等式两边的数值,要在同一量级。
再比如,如果条带中黄色(Shuffle Write Time)与橙色(Shuffle Read Time)的面积较大,就说明任务的Shuffle负载很重,这个时候,我们就需要考虑,有没有可能通过利用Broadcast Join来消除
Shuffle,从而缓解任务的Shuffle负担。
Task Metrics
说完Stage DAG与Event Timeline,最后,我们再来说一说Stage详情页的重头戏:Task Metrics。
之所以说它是重头戏,在于Task Metrics以不同的粒度,提供了详尽的量化指标。其中,“Tasks”以Task为粒度,记录着每一个分布式任务的执行细节,而“Summary Metrics”则是对于所有Tasks执行细节的
统计汇总。我们先来看看粗粒度的“Summary Metrics”,然后再去展开细粒度的“Tasks”。
Summary Metrics
首先,我们点开“Show Additional Metrics”按钮,勾选“Select All”,让所有的度量指标都生效,如下图所示。这么做的目的,在于获取最详尽的Task执行信息。

可以看到,“Select All”生效之后,Spark UI打印出了所有的执行细节。老规矩,为了方便叙述,我还是把这些Metrics整理到表格中,方便你随时查阅。其中,Task Deserialization Time、Result Serialization Time、Getting Result Time、Scheduler Delay与刚
刚表格中的含义相同,不再赘述,这里我们仅整理新出现的Task Metrics。

对于这些详尽的Task Metrics,难能可贵地,Spark UI以最大最小(max、min)以及分位点(25%分位、50%分位、75%分位)的方式,提供了不同Metrics的统计分布。这一点非常重要,原因在于,这
些Metrics的统计分布,可以让我们非常清晰地量化任务的负载分布。
换句话说,根据不同Metrics的统计分布信息,我们就可以轻而易举地判定,当前作业的不同任务之间,是相对均衡,还是存在严重的倾斜。如果判定计算负载存在倾斜,那么我们就要利用AQE的自动倾
斜处理,去消除任务之间的不均衡,从而改善作业性能。
在上面的表格中,有一半的Metrics是与Shuffle直接相关的,比如Shuffle Read Size / Records,Shuffle Remote Reads,等等。
这些Metrics我们在介绍SQL详情的时候,已经详细说过了。另外,Duration、GC Time、以及Peak Execution Memory,这些Metrics的含义,要么已经讲过,要么过于简单、无需解释。因此,对于这3个
指标,咱们也不再多着笔墨。
这里特别值得你关注的,是Spill(Memory)和Spill(Disk)这两个指标。Spill,也即溢出数据,它指的是因内存数据结构(PartitionedPairBuffer、AppendOnlyMap,等等)空间受限,而腾挪出去的数
据。Spill(Memory)表示的是,这部分数据在内存中的存储大小,而Spill(Disk)表示的是,这些数据在磁盘中的大小。
因此,用Spill(Memory)除以Spill(Disk),就可以得到“数据膨胀系数”的近似值,我们把它记为Explosion ratio。有了Explosion ratio,对于一份存储在磁盘中的数据,我们就可以估算它在内存中的存
储大小,从而准确地把握数据的内存消耗。
Tasks介绍完粗粒度的Summary Metrics,接下来,我们再来说说细粒度的“Tasks”。实际上,Tasks的不少指标,与Summary是高度重合的,如下图所示。同理,这些重合的Metrics,咱们不再赘述,你可
以参考Summary的部分,来理解这些Metrics。唯一的区别,就是这些指标是针对每一个Task进行度量的。

按照惯例,咱们还是把Tasks中那些新出现的指标,整理到表格中,以备后续查看。

可以看到,新指标并不多,这里最值得关注的,是Locality level,也就是本地性级别。在调度系统中,我们讲过,每个Task都有自己的本地性倾向。结合本地性倾向,调度系统会把Tasks调度到合适的
Executors或是计算节点,尽可能保证“数据不动、代码动”。
Logs与Errors属于Spark UI的三级入口,它们是Tasks的执行日志,详细记录了Tasks在执行过程中的运行时状态。一般来说,我们不需要深入到三级入口去进行Debug。Errors列提供的报错信息,往往足
以让我们迅速地定位问题所在。
今天我们分别学习了二级入口的SQL、Jobs与Stages。每个二级入口的内容都很丰富,提前知道它们所涵盖的信息,对我们寻找、启发与探索性能调优的思路非常有帮助。
到此为止,关于Spark UI的全部内容就讲完啦。Spark UI涉及的Metrics纷繁而又复杂,一次性记住确实有难度,所以通过这一讲,你只要清楚各级入口怎么找到,知道各个指标能给我们提供什么信息就好了。当然,仅仅跟着我去用“肉眼”学习一遍只是第一步,之后还需要你结合日常的开发,去多多摸索与体会,加油!
最后的最后,还是想提醒你,由于我们的应用是通过spark-shell提交的,因此节点8080端口的Spark UI会一直展示应用的“体检报告”。在我们退出spark-shell之后,节点8080端口的内存也随即消失(404 Page not found)。
要想再次查看应用的“体检报告”,需要移步至节点的18080端口,这里是Spark History Server的领地,它收集了所有(已执行完毕)应用的“体检报告”,并同样使用Spark UI的形式进行展示,切记切记。
今天的思考题,需要你发散思维。学习过Spark UI之后,请你说一说,都可以通过哪些途径,来定位数据倾斜问题?



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2019-09-20 Hive-06 Hive和HBase的集成