
时间序列
时间序列分析
时间序列
时间序列:
- 建立了观察结果与时间变化的关系,能帮预测未来一段时间内的结果变化情况;(时间序列只跟时间相关)
时间序列分析与回归分析的区别:
- 在选择模型前,我们需要确定结果与变量之间的关系。回归分析训练得到的是目标变量y与自变量x(一个或多个)的相关性,然后通过新的自变量x来预测目标变量y。而时间序列分析得到的是目标变量y与时间的相关性
- 回归分析擅长的是多变量与目标结果之间的分析,即便是单一变量,也往往与时间无关。而时间序列分析建立在时间变化的基础上,它会分析目标变量的趋势、周期、时期和不稳定因素等。这些趋势和周期都是在时间维度的基础上,是我们要观察的重要特征
时间序列:
- 按照时间顺序组成的数字序列
- 历史悠久,在中国古代的农业社会中,人们就将一年中不同时间节点和天气的规律总结了下来,形成了二十四节气,也就是从时间序列中观察天气和太阳的规律(只是当时没有时间序列模型和相应工具)
- 时间序列在金融、经济、商业领域拥有广泛的应用
- 机器学习模型,包括AR、MA、ARMA、ARIMA
- 神经网络模型,用LSTM进行时间序列预测
时间序列及分解:
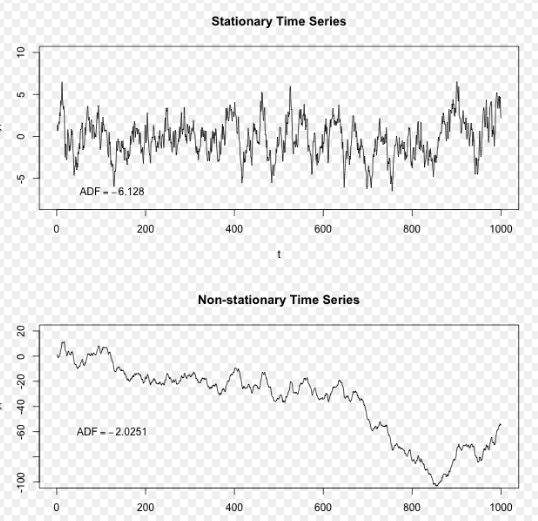
- 平稳序列,stationary series
- 基本上不存在趋势(Trend)的序列,各观察值基本上在某个固定的水平上波动
- 非平稳序列,non-stationary series
- 包含趋势、季节性或周期性的序列,可以只有一种成分,也可能是多种成分的组合
时间序列及分解:
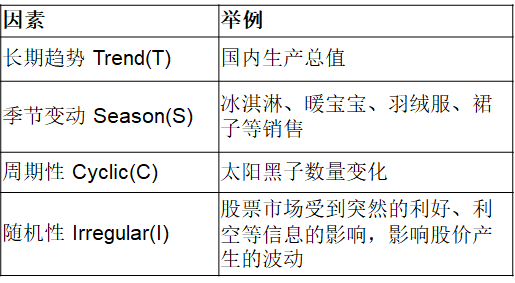
- 趋势(trend):时间序列在长时期内呈现出来的某种持续上升或持续下降的变动,也称长期趋势
- 季节性(seasonality):时间序列在一年内重复出现的周期波动。销售旺季,销售淡季,旅游旺季、旅游淡季
- 季节,可以是任何一种周期性变化,不一定是一年中的四季; 含有季节成分的序列可能含有趋势,也可能不含有趋势
- 周期性(cyclicity):通常是由经济环境的变化引起
- 不同于趋势变动,不是朝着单一方向的持续运动,而是涨落相间的交替波动
- 不同于季节变动,季节变动有比较固定的规律,变动周期大多为一年。周期性的循环波动无固定规律,变动周期多在一年以上,且周期长短不一
- 随机性(Irregular),指受偶然因素影响所形成的的不规则波动,在时间序列中无法预估
- 随机性是不规则波动,除去趋势、周期性、季节性的偶然性波动
时间序列模型
AR模型
- Auto Regressive,中文叫自回归模型
- 认为过去若干时刻的点通过线性组合,再加上白噪声就可以预测未来某个时刻的点
- 日常生活环境中就存在白噪声,在数据挖掘的过程中,可以把它理解为一个期望为0,方差为常数的纯随机过程
- AR模型存在一个阶数p,称为AR(p)模型,也叫作p阶自回归模型。指的是通过这个时刻点的前p个点,通过线性组合再加上白噪声来预测当前时刻点的值;
- AR是线性时间序列分析模型中最简单的模型,通过前面部分的数据与后面部分的数据之间的相关关系来建立回归方程:
-
- AR(p),表示p阶的自回归过程,φ为自回归系数;
- Ut表示白噪声,是时间序列中的数值的随机波动。这些波动会相互抵消,即累计为0
- 如果只有一个时间记录点时,则为AR(1),即一阶自回归过程:
-
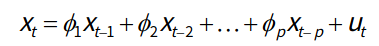
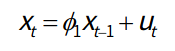
MA模型
- Moving Average,中文叫做滑动平均模型
- 与AR模型大同小异,AR模型是历史时序值的线性组合,MA是通过历史白噪声进行线性组合来影响当前时刻点
- MA模型中的历史白噪声是通过影响历史时序值,从而间接影响到当前时刻点的预测值
- MA模型存在一个阶数q,称为MA(q)模型,也叫作q阶移动平均模型
- AR和MA模型都存在阶数,在AR模型中,用p表示,在MA模型中用q表示,这两个模型大同小异,与AR模型不同的是MA模型是历史白噪声的线性组合
- MA模型,通过前面通过将一段时间序列中白噪声序列进行加权和,可以得到移动平均方程:
-
- MA(q)表示q阶移动平均过程, 为移动回归系数, 为不同时间点的白噪声
- Xt 为第t天的股票价格,而Ut为第t天的新闻影响,当天的股票价格受当天的新闻影响,也受昨天的新闻影响(但影响力要弱些,所以要乘上系数)
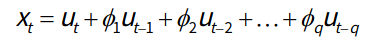
ARMA模型
- Auto Regressive Moving Average,中文叫做自回归滑动平均模型
- AR模型和MA模型的混合,相比AR模型和MA模型,它有更准确的估计
- ARMA模型存在p和q两个阶数,称为ARMA(p,q)模型:
- 自回归模型结合了两个模型的特点,AR解决当前数据与后期数据之间的关系,MA则可以解决随机变动,即噪声问题
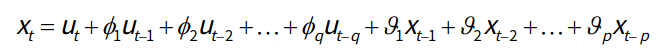
ARIMA模型
- Auto Regressive Integrated Moving Average模型,中文叫差分自回归滑动平均模型,也叫求合自回归滑动平均模型
- 相比于ARMA,ARIMA多了一个差分的过程,作用是对不平稳数据进行差分平稳,在差分平稳后再进行建模
- ARIMA的原理和ARMA模型一样。相比于ARMA(p,q)的两个阶数,ARIMA是一个三元组的阶数(p,d,q),称为ARIMA(p,d,q)模型,其中d是差分阶数
- AR,MA是ARMA的特殊形式,而ARMA是ARIMA的特殊形式
ARIMA模型步骤:
- Step1,观察时间序列数据,是否为平稳序列
- Step2,对于非平稳时间序列要先进行d阶差分运算,化为平稳时间序列
- Step3,使用ARIMA(p, d, q)模型进行训练拟合,找到最优的(p, d, q),及训练好的模型
- Step4,使用训练好的ARIMA模型进行预测,并对差分进行还原
ARIMA 用差分将不平稳数据先变得平稳,再用ARMA模型
关于差分:
- 差分=序列之间做差值,目的是为了得到平稳的序列,也就是去掉前面数值的影响
- 一次差分为序列之间做一次差值,二次差分为在一次差分的基础上在做一次差分
- f(x) = x2 若x=[1,4,9,16,25….](x有二次趋势)
一次差分的结果为[4-1,9-4,16-9,25-16…] = [3,5,7,9,11…],此时x序列仍不平稳,有一次上升的趋势
再做一次差分为[2,2,2,2…] ,此时x为平稳序列
时间序列工具
statsmodels工具:
- statsmodels工具包提供统计计算,包括描述性统计以及统计模型的估计和推断
statsmodels主要包括如下子模块:
- 回归模型:线性回归,广义线性模型,线性混合效应模
- 方差分析(ANOVA)
- 时间序列分析:AR,ARMA,ARIMA等
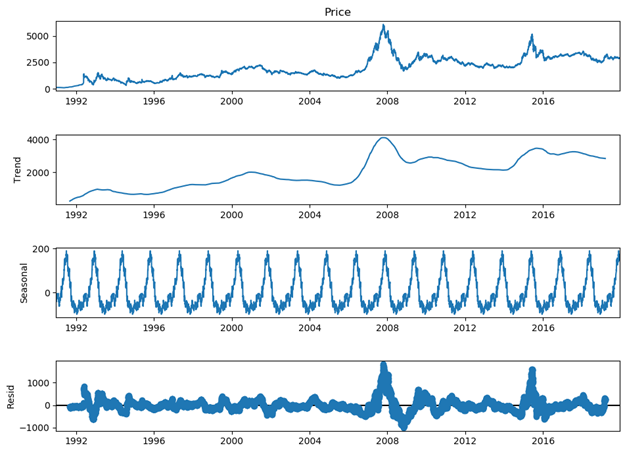
import statsmodels.api as sm # 数据加载 data = pd.read_csv('shanghai_index_1990_12_19_to_2019_12_11.csv', usecols=['Timestamp', 'Price']) data.Timestamp = pd.to_datetime(data.Timestamp) data = data.set_index('Timestamp') data['Price'] = data['Price'].apply(pd.to_numeric, errors='ignore') # 进行线性插补缺漏值 data.Price.interpolate(inplace=True) # 返回三个部分 trend(趋势),seasonal(季节性)和residual (残留) result = sm.tsa.seasonal_decompose(data.Price, freq=288) result.plot() plt.show()
ARMA工具
• from statsmodels.tsa.arima_model import ARMA
• ARMA(endog,order,exog=None)
• endog:endogenous variable,代表内生变量,又叫非政策性变量,它是由模型决定的,不被政策左右,可以说是我们想要分析的变量,或者说是我们这次项目中需要用到的变量
• order:代表是p和q的值,也就是ARMA中的阶数
• exog:exogenous variables,代表外生变量。外生变量和内生变量一样是经济模型中的两个重要变量。相对于内生变量而言,外生变量又称作为政策性变量,在经济机制内受外部因素的影响,不是我们模型要研究的变量
如果我们想要创建ARMA(7,0)模型,可以写成:
ARMA(data,(7,0)),其中data是我们想要观察的变量,(7,0)代表(p,q)的阶数。
fit函数进行拟合, predict(start, end)函数进行预测,其中start为预测的起始时间,end为预测的终止时间
# 用ARMA进行时间序列预测 from statsmodels.tsa.arima_model import ARMA # 创建数据 data = [3821, 4236, 3758, 6783, 4664, 2589, 2538, 3542, 4626, 5886, 6233, 4199, 3561, 2335, 5636, 3524, 4327, 6064, 3912, 1356, 4305, 4379, 4592, 4233, 4281, 1613, 1233, 4514, 3431, 2159, 2322, 4239, 4733, 2268, 5397, 5821, 6115, 6631, 6474, 4134, 2728, 5753, 7130, 7860, 6991, 7499, 5301, 2808, 6755, 6658, 6944, 6372, 8380, 7366, 6352, 8333, 8281, 11548, 10823, 13642, 9973, 6723, 13416, 12205, 13942, 9590, 11693, 9276, 6519, 6863, 8237, 10122, 8646, 9749, 5346, 4836, 9806, 7502, 9387, 11078, 9832, 6886, 4285, 8351, 9725, 11844, 12387, 10666, 7072, 6429] data=pd.Series(data) data_index = sm.tsa.datetools.dates_from_range('1901','1990') # 绘制数据图 data.index = pd.Index(data_index) data.plot(figsize=(12,8)) plt.show() # 创建ARMA模型# 创建ARMA模型 arma = ARMA(data,(7,0)).fit() print('AIC: %0.4lf' %arma.aic) # 模型预测 predict_y = arma.predict('1990', '2000') # 预测结果绘制 fig, ax = plt.subplots(figsize=(12, 8)) ax = data.ix['1901':].plot(ax=ax) predict_y.plot(ax=ax) plt.show()
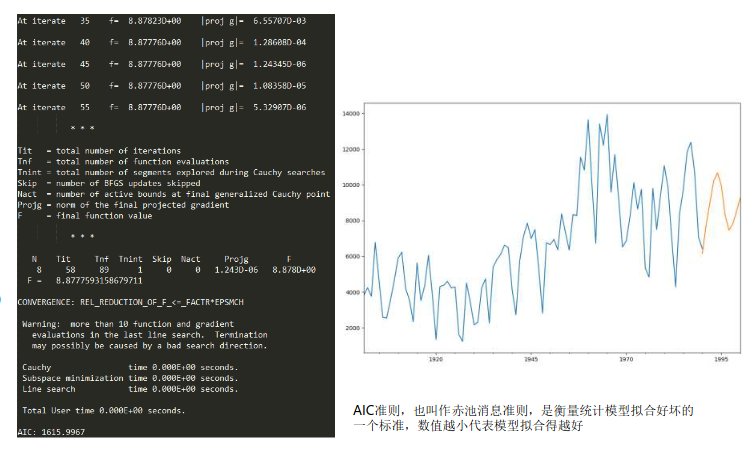
Project A:沪市指数预测(ARMA)
使用ARMA工具对沪市指数进行预测:
• Step1,数据加载&探索
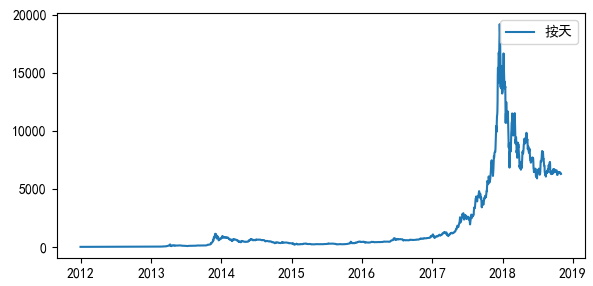
按照不同的时间尺度(天,月,季度,年)可以将数据压缩,得到不同尺度的数据,然后做可视化呈现。这4个时间尺度上,我们选择“月”作为预测模型的时间尺度
df_month = df.resample('M').mean()
• Step2,模型选择&训练,在给定范围内,选择最优的超参数;
创建ARMA时间序列模型。我们并不知道p和q取什么值时,模型最优,因此可以给它们设置一个区间范围,比如都是range(0,3),然后计算不同模型的AIC数值,选择最小的AIC数值对应的那个
ARMA模型
• Step3,模型预测,可视化呈现;
用这个最优的ARMA模型预测未来3个月的沪市指数走势,并将结果做可视化呈现。
# 数据加载 df = pd.read_csv('./shanghai_index_1990_12_19_to_2020_03_12.csv') df = df[['Timestamp', 'Price']] # 将时间作为df的索引 df.Timestamp = pd.to_datetime(df.Timestamp) df.index = df.Timestamp # 数据探索 print(df.head()) # 按照月,季度,年来统计 df_month = df.resample('M').mean() print(df_month) df_Q = df.resample('Q-DEC').mean() df_year = df.resample('A-DEC').mean() # 按照天,月,季度,年来显示沪市指数的走势 fig = plt.figure(figsize=[15, 7]) plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 plt.suptitle('沪市指数', fontsize=20) plt.subplot(221) plt.plot(df.Price, '-', label='按天') plt.legend() plt.subplot(222) plt.plot(df_month.Price, '-', label='按月') …… plt.plot(df_Q.Price, '-', label='按季度') …… plt.plot(df_year.Price, '-', label='按年') plt.legend() plt.show() # 设置参数范围 ps = range(0, 3) qs = range(0, 3) parameters = product(ps, qs) parameters_list = list(parameters) # 寻找最优ARMA模型参数,即best_aic最小 results = [] best_aic = float("inf") # 正无穷 for param in parameters_list: try: model = ARMA(df_month.Price,order=(param[0], param[1])).fit() except ValueError: print('参数错误:', param) continue aic = model.aic if aic < best_aic: best_model = model best_aic = aic best_param = param results.append([param, model.aic]) print('最优模型: ', best_model.summary()) # 设置future_month,需要预测的时间date_list future_month = 3 last_month = pd.to_datetime(df_month2.index[len(df_month2)-1]) date_list = [] for i in range(future_month): # 计算下个月有多少天 year = last_month.year month = last_month.month if month == 12: month = 1 year = year+1 else: month = month + 1 next_month_days = calendar.monthrange(year, month)[1] #print(next_month_days) last_month = last_month + timedelta(days=next_month_days) date_list.append(last_month) print('date_list=', date_list) date_list= [Timestamp('2020-04-30 00:00:00', freq='M'), Timestamp('2020-05-31 00:00:00', freq='M'), Timestamp('2020-06-30 00:00:00', freq='M')] # 添加未来要预测的3个月 future = pd.DataFrame(index=date_list, columns= df_month.columns) df_month2 = pd.concat([df_month2, future]) df_month2['forecast'] = best_model.predict(start=0, end=len(df_month2)) # 第一个元素不正确,设置为NaN df_month2['forecast'][0] = np.NaN print(df_month2) # 沪市指数预测结果显示 plt.figure(figsize=(30,7)) df_month2.Price.plot(label='实际指数') df_month2.forecast.plot(color='r', ls='--', label='预测指数') plt.legend() plt.title('沪市指数(月)') plt.xlabel('时间') plt.ylabel('指数') plt.show()
Project A:沪市指数预测(ARIMA)
# 设置参数范围 ps = range(0, 5) qs = range(0, 5) ds = range(1, 2) #使用1阶差分 for param in parameters_list: try: model = sm.tsa.statespace.SARIMAX(df_month.Price, order=(param[0], param[1], param[2]), enforce_stationarity=False, enforce_invertibility=False).fit() except ValueError: print('参数错误:', param) continue aic = model.aic if aic < best_aic: …… # 输出最优模型 print('最优模型: ', best_model.summary()) # 添加未来要预测的3个月 future = pd.DataFrame(index=date_list, columns= df_month.columns) df_month2 = pd.concat([df_month2, future]) # get_prediction得到的是区间,使用predicted_mean df_month2['forecast'] = best_model.get_prediction(start=0, end=len(df_month2)).predicted_mean # 沪市指数预测结果显示 plt.figure(figsize=(30,7)) df_month2.Price.plot(label='实际指数') df_month2.forecast.plot(color='r', ls='--', label='预测指数') plt.legend() plt.title('沪市指数(月)') plt.xlabel('时间') plt.ylabel('指数') plt.show()
使用LSTM进行时间序列预测
LSTM:
• LSTM,Long Short-Term Memory,长短记忆网络
• 可以避免常规RNN的梯度消失,在工业界有广泛应用
• 引入了三个门函数:输入门(Input Gate)、遗忘门(Forget Gate)和输出门(Output Gate)来控制输入值、记忆值和输出值
• 输入门决定了当前时刻网络的状态有多少信息需要保存到内部状态中,遗忘门决定了过去的状态信息有多少需要丢弃 => 输入门和遗忘门是LSTM能够记忆长期依赖的关键
• 输出门决定当前时刻的内部状态有多少信息需要输出给外部状态
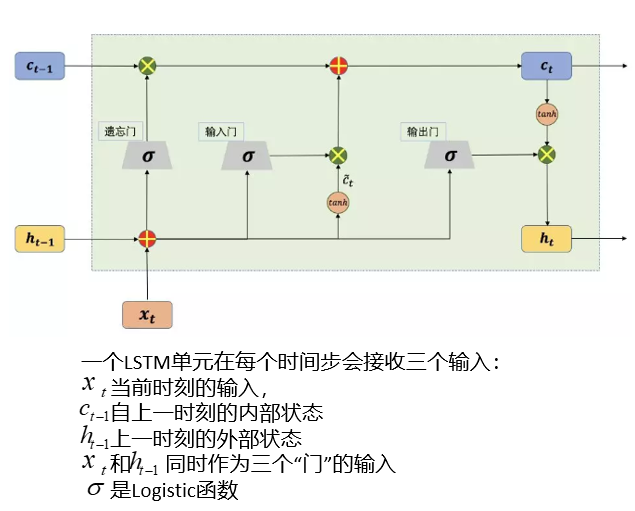
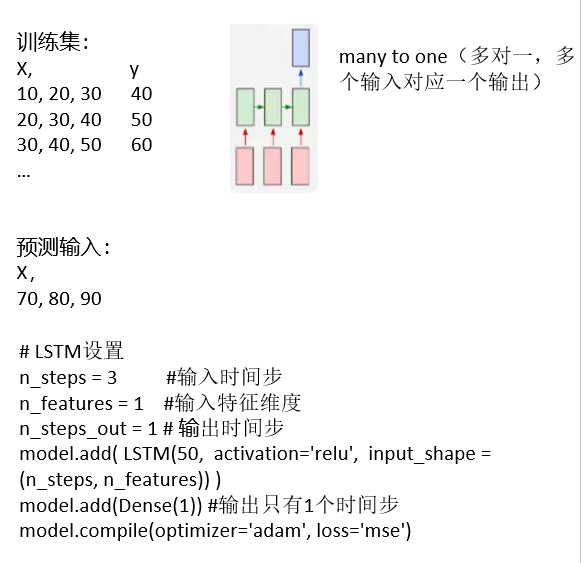
Keras的LSTM层:
• keras.layers.recurrent.LSTM(units, activation, return_sequences,input_shape)
• units,输出维度
• activation,激活函数
• return_sequences,默认False,若为True则返回整个序列,否则仅返回输出序列的最后一个输出
• input_shape,是一个二元组(n_steps_in, n_features),n_steps_in 为输入的 X 每次考虑的时间步,n_features 为输入
有几个序列

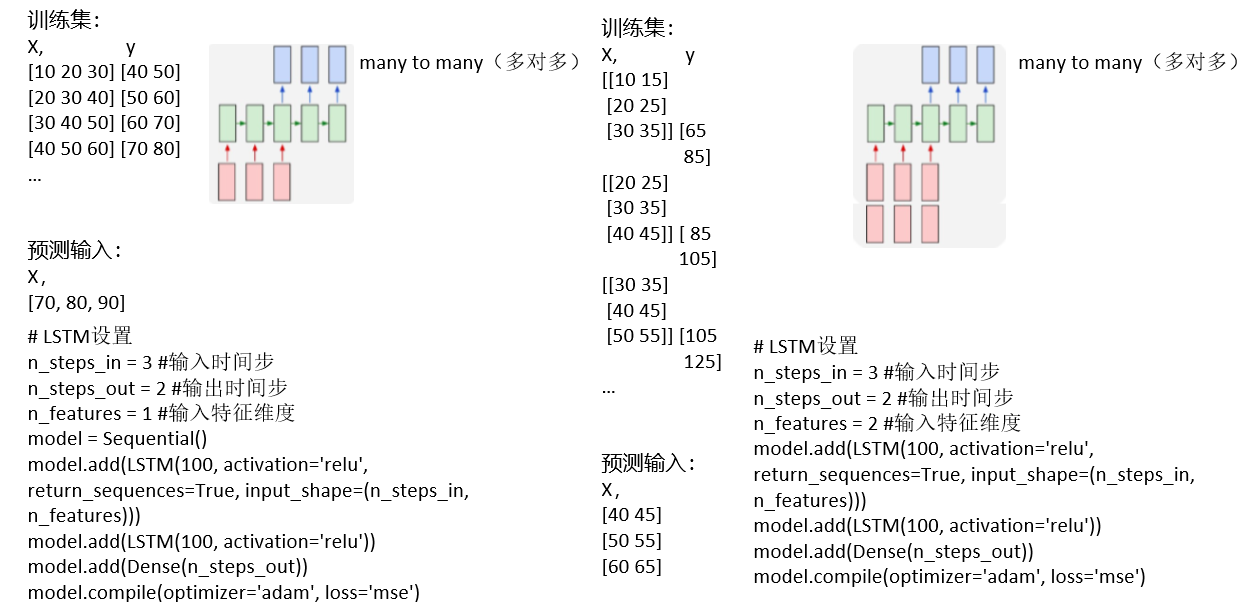
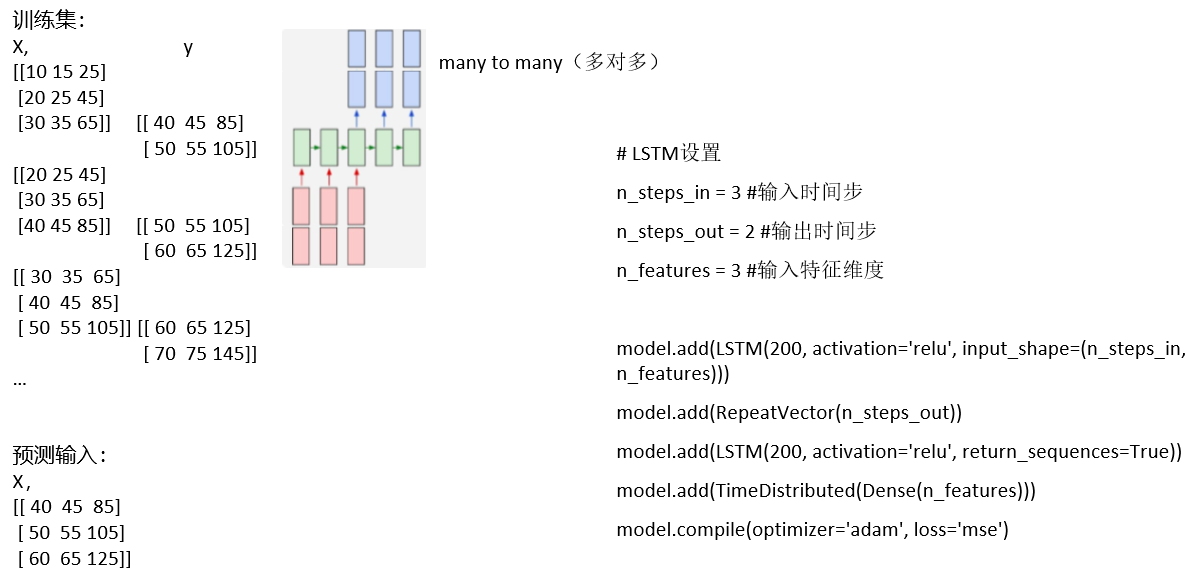
TimeDistributed的使用:
- TimeDistributed是Keras中的包装器
- model = Sequential()
- # 将模型的shape由(None, 10,16) 变成 (None, 10, 8)
- model.add(TimeDistributed(Dense(8), input_shape=(10, 16)))
- TD层和Dense配合使用,主要应用于一对多,多对多的情况
- input_shape = (10,16),表示步长是10,特征维度为16,
- 首先使用TimeDistributed(Dense(8), input_shape = (10,16)) 把每一步的维度为16变成8,不改变步长的大小
- 若该层的batch输入shape为(50, 10, 16),则这一层之后的输出shape为(50, 10, 8)
RepeatVector的使用:
- RepeatVector(n) 将输入重复n次
- model = Sequential()
- # 原来模型的output_shape = (None, 32),`None` 是batch 维度
- model.add(Dense(32, input_dim=32))
- # 使用RepeatVector,将模型output_shape 设置为 (None, 3, 32)
- model.add(RepeatVector(3))
- 如果输入的形状为(None,32),经过添加RepeatVector(3)层之后,输出变为(None,3,32), RepeatVector不改变我们的步长,改变我们的每一步的维数(即:属性长度)
Project A:沪市指数预测(LSTM)


# 使用LSTM预测沪市指数 import numpy as np import pandas as pd from keras.models import Sequential from keras.layers import Dense from keras.layers import LSTM from keras.layers import Dropout from pandas import DataFrame from pandas import concat from itertools import chain from sklearn.metrics import mean_squared_error import matplotlib.pyplot as plt # 转化为可以用于监督学习的数据 def get_train_set(data_set, timesteps_in, timesteps_out=1): train_data_set = np.array(data_set) reframed_train_data_set = np.array(series_to_supervised(train_data_set, timesteps_in, timesteps_out).values) print(reframed_train_data_set) print(reframed_train_data_set.shape) train_x, train_y = reframed_train_data_set[:, :-timesteps_out], reframed_train_data_set[:, -timesteps_out:] # 将数据集重构为符合LSTM要求的数据格式,即 [样本数,时间步,特征] train_x = train_x.reshape((train_x.shape[0], timesteps_in, 1)) return train_x, train_y """ 将时间序列数据转换为适用于监督学习的数据 给定输入、输出序列的长度 data: 观察序列 n_in: 观测数据input(X)的步长,范围[1, len(data)], 默认为1 n_out: 观测数据output(y)的步长, 范围为[0, len(data)-1], 默认为1 dropnan: 是否删除NaN行 返回值:适用于监督学习的 DataFrame """ def series_to_supervised(data, n_in=1, n_out=1, dropnan=True): n_vars = 1 if type(data) is list else data.shape[1] df = DataFrame(data) cols, names = list(), list() # input sequence (t-n, ... t-1) for i in range(n_in, 0, -1): cols.append(df.shift(i)) names += [('var%d(t-%d)' % (j + 1, i)) for j in range(n_vars)] # 预测序列 (t, t+1, ... t+n) for i in range(0, n_out): cols.append(df.shift(-i)) if i == 0: names += [('var%d(t)' % (j + 1)) for j in range(n_vars)] else: names += [('var%d(t+%d)' % (j + 1, i)) for j in range(n_vars)] # 拼接到一起 agg = concat(cols, axis=1) agg.columns = names # 去掉NaN行 if dropnan: agg.dropna(inplace=True) return agg # 使用LSTM进行预测 def lstm_model(source_data_set, train_x, label_y, input_epochs, input_batch_size, timesteps_out): model = Sequential() # 第一层, 隐藏层神经元节点个数为128, 返回整个序列 model.add(LSTM(128, return_sequences=True, activation='tanh', input_shape=(train_x.shape[1], train_x.shape[2]))) # 第二层,隐藏层神经元节点个数为128, 只返回序列最后一个输出 model.add(LSTM(128, return_sequences=False)) model.add(Dropout(0.5)) # 第三层 因为是回归问题所以使用linear model.add(Dense(timesteps_out, activation='linear')) model.compile(loss='mean_squared_error', optimizer='adam') # LSTM训练 input_epochs次数 res = model.fit(train_x, label_y, epochs=input_epochs, batch_size=input_batch_size, verbose=2, shuffle=False) # 模型预测 train_predict = model.predict(train_x) #test_data_list = list(chain(*test_data)) train_predict_list = list(chain(*train_predict)) plt.plot(res.history['loss'], label='train') plt.show() print(model.summary()) plot_img(source_data_set, train_predict) # 呈现原始数据,训练结果,验证结果,预测结果 def plot_img(source_data_set, train_predict): plt.figure(figsize=(24, 8)) # 原始数据蓝色 plt.plot(source_data_set[:, -1], c='b') # 训练数据绿色 plt.plot([x for x in train_predict], c='g') plt.legend() plt.show() # 设置观测数据input(X)的步长(时间步),epochs,batch_size timesteps_in = 3 timesteps_out = 3 epochs = 500 batch_size = 100 data = pd.read_csv('./shanghai_index_1990_12_19_to_2020_03_12.csv') data_set = data[['Price']].values.astype('float64') # 转化为可以用于监督学习的数据 train_x, label_y = get_train_set(data_set, timesteps_in=timesteps_in, timesteps_out=timesteps_out) # 使用LSTM进行训练、预测 lstm_model(data_set, train_x, label_y, epochs, batch_size, timesteps_out=timesteps_out)
Project B:预测北京PM2.5值
Summary
时间序列是结构化数据,每个时间戳就有一个数值
• 研究时间序列可以方便我们对未来进行预测,或者异常检测
应用场景:
• 金融股票价格预测,资金流入流出预测
• 运维中的异常检测,日活月活时间序列异常检测
预测方法:
• 统计学方法 ARMA, ARIMA
from statsmodels.tsa.arima_model import ARMA
statsmodels提供统计计算,包括描述性统计、统计模型的估计和推断
• 使用RNN/LSTM进行预测
keras.layers.recurrent.LSTM(units, activation, return_sequences, input_shape)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号