
规划问题
1. 常见规划问题
线性规划、整数规划、混合整数规划
pulp工具
Google ortools
Project A: Santa的接待安排
规划问题:
- LP:Linear Programming 线性规划,研究线性约束条件下线性目标函数的极值问题
- ILP:Integer Linear Programming 整数线性规划,全部决策变量必须为整数
- MIP:Mixed Integer Programming 混合整数规划,混合整数规划是LP的一种,其中部分的决策变量是整数(不要求全部都是整数)
- VRP:Vehicle Routing Problem 车辆路径问题
规划工具:
- pulp,只用于线性模型,包括如整数规划、01规划,还是混合,整数线性规划 MILP
- ortools
- Google开发,用于优化的开源软件,可以解决车辆路径、流程、整数和线性规划等问题,提供了C++,Python,Java,.NET接口
线性规划
求解普通的线性规划
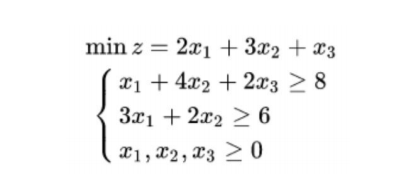
# 默认求最小值 z = np.array([2, 3, 1]) a = np.array([[1, 4, 2], [3, 2, 0]]) b = np.array([8, 6]) # 取值范围 x1_bound = x2_bound = x3_bound =(0, None) from scipy import optimize # 默认约束条件都为 <=,如果要求大于等于,则取反 res = optimize.linprog(z, A_ub=-a, b_ub=- b,bounds=(x1_bound, x2_bound, x3_bound)) print(res)
pulp调包: import pulp #目标函数的系数 z = [2, 3, 1] #约束 a = [[1, 4, 2], [3, 2, 0]] b = [8, 6] #确定最大化最小化问题,最大化只要把Min改成 Max即可 m = pulp.LpProblem(sense=pulp.LpMinimize) #定义三个变量放到列表中 x = [pulp.LpVariable(f'x{i}', lowBound=0) for i in [1,2,3]] #定义目标函数,lpDot可以将两个列表的对应位相乘再加和 #相当于z[0]*x[0]+z[1]*x[0]+z[2]*x[2] m += pulp.lpDot(z, x) #设置约束条件 for i in range(len(a)): m += (pulp.lpDot(a[i], x) >= b[i]) m.solve() #求解 #输出结果 print(f'优化结果:{pulp.value(m.objective)}') print(f'参数取值:{[pulp.value(var) for var in x]}')
求解步骤:
- Step1,列出约束条件及目标函数
- Step2,画出约束条件所表示的可行域
- Step3,在可行域内求目标函数的最优解及最优值
pulp工具:
- LpProblem类,用来构造LP问题实例
- LpProblem(name='NoName', sense=LpMinimize),Name,指定问题名,输出信息用; Sense,LpMinimize或LpMaximize,代表目标是极大值还是极小值
- solve()函数,在对LpProblem添加完约束条件后,调用solve进行求解
- lpSum(vector)
- 用于计算序列的求和,执行比sum函数快
- LpVariable类 ,用来构造LP问题中的变量
- LpVariable(name, lowBound=None, upBound=None, cat='Continuous', e=None),
- name指定变量名,lowBound(默认负无穷)和upBound(默认正无穷)是下界和上界,cat用来指定变量是离散(Integer,Binary) 还是连续(Continuous)
- dicts(name, indexs, lowBound=None, upBound=None, cat='Continuous', indexStart=[])
- 用来构造变量字典,批量创建Lp变量实例,name指定所有变量的前缀, index是列表,会用来构成变量名,参数lowBound, upbound, cat和LbVariable一样
生产问题:
- 一个猫粮生产公司,猫粮配料主要有chicken, beef, mutton,rice, wheat, gel,营养成分如下
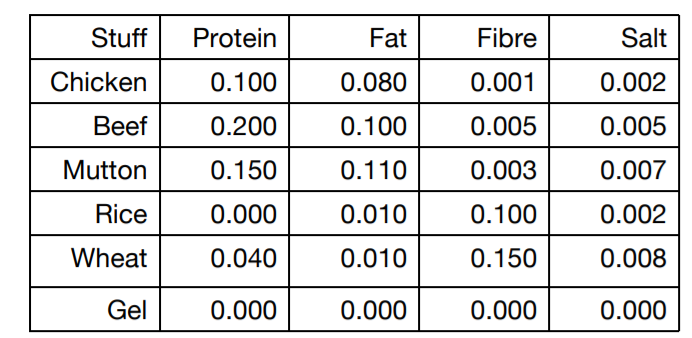
这些饲料的成本为:

- 成品约束条件:
- 每100g成品必须至少有8gProtein,6gfat,但是不超过2g的 fibre以及0.4g的salt,如何安排猫粮的成分,使得在满足成品的条件下,成本最小?
- 查看解的状态,LpStatus[prob.status],状态包括 Not Solved, Infeasible, Unbounded, Undefined,Optimal
- To Do 使用pulp建立线性规划,通过调整upBound=10 和 100,查看解的状态
运输问题:
某商品有m个产地、n个销地,各产地的产量分别为a1, ..., am,各销地的 需求量分别为b1,...,bn。若该商品由i产地运到j销地的单位运价为c{ij},请
问该如何调配才能使总运费最省?变量x{ij},代表由i产地运往j销地的商品数量,所以模型为:
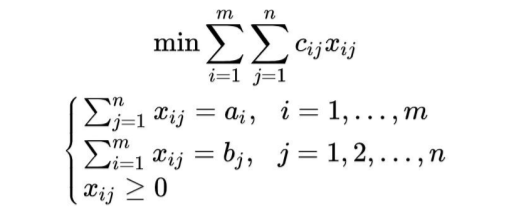
# 定义初始问题 prob = pulp.LpProblem('Transportation', sense=pulp.LpMaximize) # 定义相关变量 var = [[pulp.LpVariable(f'x{i}{j}', lowBound=0, cat=pulp.LpInteger) for j in range(col)] for i in range(row)] …… # 使用f 进行格式化字符串 print(f'最大值为{result["objective"]}’)
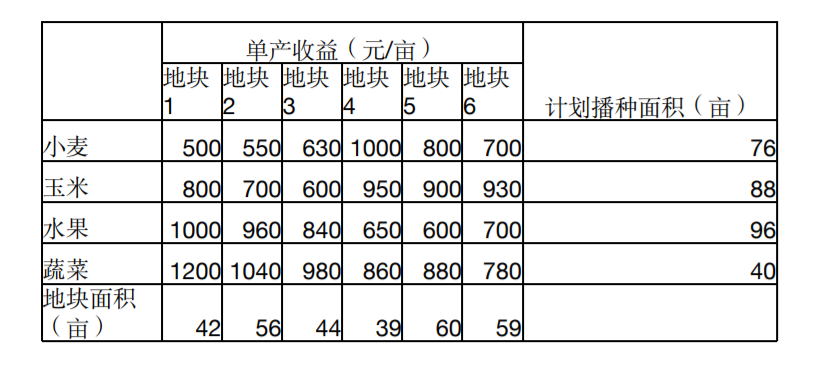
一个农民承包了6块耕地共300亩,准备播种小麦,玉米,水果和蔬菜四种农产品,各种农产品的计划播种面积、每块土地种植不同农产品的单产收益如下:
求解最高的收益值,以及不同农产品在不同地块上的种植安排
可以采用任何优化工具,比如scipy, pulp, ortools
Ortools使用
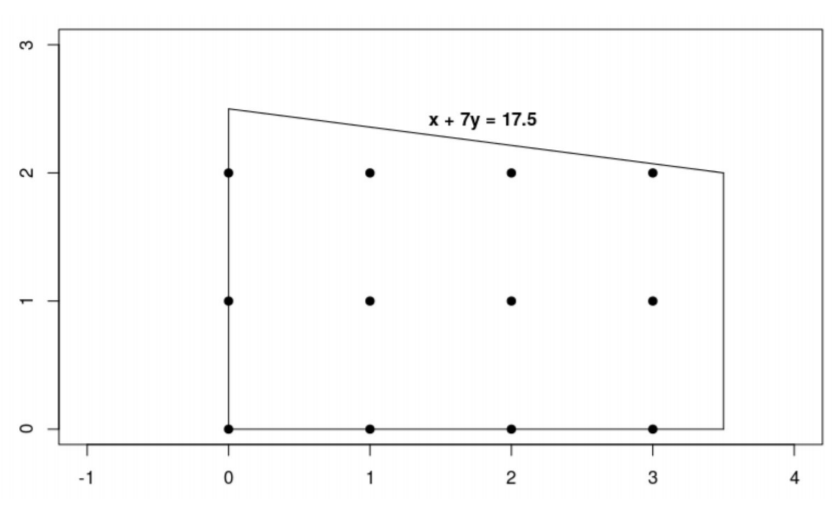
MIP问题:
有4个约束条件,x y 均为整数,即:

目标函数(最大值): x +10y
Ortools求解器:
• 线性规划,默认使用GLOP
• 整数规划,默认使用CBC(Coin-or branch andcut),还包括SCIP、GLPK、Gurobi等
• 开源求解器,在计算性能和规模上弱于商业求解器,适用于中小企业及普通问题
# 求解器定义
solver = pywraplp.Solver.CreateSolver('SCIP')
solver= pywraplp.Solver('AssignmentProblem',pywraplp.Solver.GLOP_LINEAR_PROGRAMMING)
solver = pywraplp.Solver('AssignmentProblem',pywraplp.Solver.CBC_MIXED_INTEGER_PROGRAMMING)
整数规划求解器,默认使用CBC(Coin-or branch andcut),还包括SCIP、GLPK、Gurobi等
- Solver创建,solver = pywraplp.Solver.CreateSolver('SCIP')
- 变量设置
solver.NumVar:创建普通变量 solver.IntVar:创建整数变量 infinity = solver.infinity() # 正无穷 x = solver.IntVar(0.0, infinity, 'x') print('变量数量:', solver.NumVariables())
- 添加约束条件
solver.Add(x + 7 * y <= 17.5) print('约束的数量:', solver.NumConstraints())
- Solve求解
# 求解最大值问题 solver.Maximize(x + 10 * y) status = solver.Solve()
- Solve的结果
print('目标值 =', solver.Objective().Value()) print('x =', x.solution_value()) print('y =', y.solution_value())
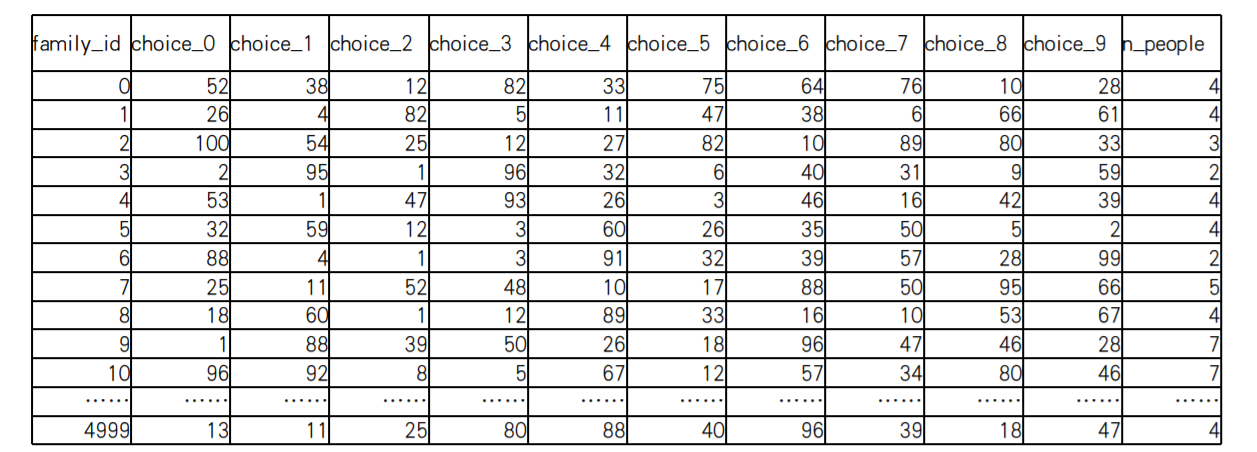
Project A:Santa的接待安排
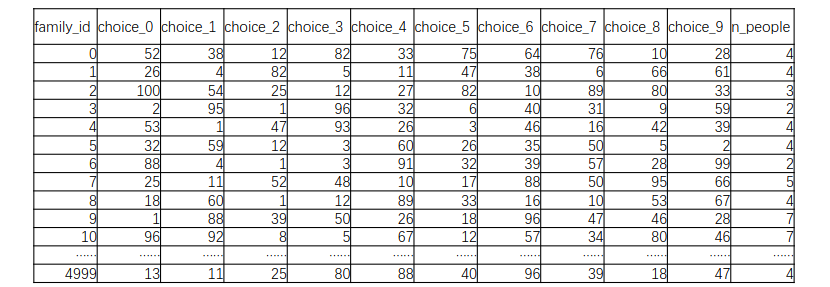
圣诞节前100天,Santa开放了workshop,欢迎以家庭单位的参观,如何更合理的安排这些家庭参观?
每个家庭有10个选择choice0-9,数字代表了距离圣诞节的天数,比如 1代表12月24日,每个家庭必须并且只安排一次参观
家庭数量 5000,即family_id 为[0, 4999],每天访问的人数需要在125-300人
Project A:Santa的接待安排
为了更合理的计算Santa的安排能力,我们使用preference,cost和accounting penalty两个指标
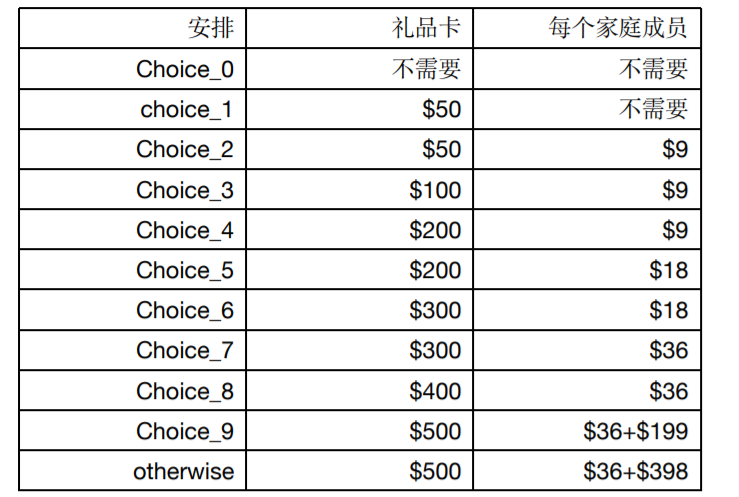
1)preference cost,代表Santa的个性化安排能力
2)accounting penalty,代表Santa安排的财务成本
每天接待的人员数N(d)如果大于125,就会拥挤,产生过多的清洁成本,计算公式为
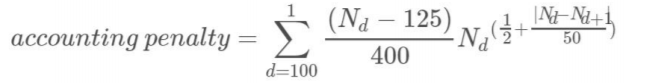
其中 N(d)代表当天,N(d+1)代表前一天(因为N代表距离圣诞节的天数)
最终的 Score = preference cost + accounting penalty
最终提交每个家庭的安排 submission.csv

Step1, 数据加载
Step2,数据预处理
- 1)计算Perference Cost矩阵 pcost_mat
- 2)计算Accounting Cost矩阵 acost_mat
- 3)计算每个家庭的人数 FAMILY_SIZE
- 4)每个家庭的倾向选择(choice_) DESIRED
Step3,使用LP和MIP求解 规划方案
- 1)先使用LP 对绝大部分家庭进行规划
- 2)再使用MIP 对剩余家庭进行规划
- 3)汇总两边的结果 => 最终规划方案
Step4, 结果评估
按照evaluation标准,计算
Score = preference cost + accounting
penalty
Step5,方案优化
通过更换family_id的选择,查找更好的score
每次更换后,都对方案进行评估,选择更小的
score方案
%%time 在jupyter中可以给出cell代码运行一次的时间
- np.sort(a),对a按从小到大的顺序排序
- np.argsort(a),返回数组从小到大的索引
@njit(fastmath=True)
- numba是python的即时编译器,当调用python函数时,
- 代码会替换为机器码执行
- numba可以加速计算负载比较大的python函数
@njit 表示全部使用加速,fastmath=True,启用函数的快速数学行为
Summary
运筹学求解思路简单,但要找到满意的结果却很难
- 现在的求解思路类似暴力穷举,而求解的空间又是非常巨大的 => 不能在约束的时间内得到较好结果
- 针对凸优化问题(比如线性规划)可直接得到最优解
- 如果是非凸优化,无法判定是全局最优解还是局部最优解,在业界一般使用启发式算法,比如遗传算法
- 分支定界法,启发式算法核心原理是暴力穷举的改进,尽可能减少搜索空间,更快得到可行解
Thinking1:常见的规划问题都包括哪些?
Thinking2:常用的规划工具包都有哪些?
Thinking3:TSP与VRP问题的关系是怎样的?
2. 启发式算法
启发式算法 相对于最优化算法提出的,一个问题的最优算法求得该问题
每个实例的最优解
• 启发式算法可以这样定义:一个基于直观或经验构造的算法,在可接受的花费(指计算时间和空间)下给出待解决组合优化问题每一个实例的一个可行解,该可行解与最优解的偏离程度一般不能被预计
• 一般用于解决NP-hard问题,其中NP是指非确定性多项式
• 常用的算法有:模拟退火算法(SA)、遗传算法(GA)、蚁群算法(ACO)、人工神经网络(ANN)
• 对于NP Hard问题,可行时间内在各空间中找到全局最优解的可能性很小,需要使用近似算法(Approximate Method)在有限时间内寻找一个近似最
优解
• 近似方法分成:近似算法 和 启发式算法
• 近似算法,可以得到一个有质量保证的解,而启发式算法可以在可行时间内找到一个相对比较好的解,但对解的质量没有保证
遗传算法
• 通过模拟自然进化过程(达尔文生物进化论)搜索最优解的方法,遗传操作包括:选择、交叉和变异
• 算法核心:参数编码、初始群体的设定、适应度函数、遗传操作设计、控制参数设定
• 以一种群体中的所有个体为对象,利用随机化技术指导对一个被编码的参数空间进行高效搜索
遗传算法特点:
• 直接对结构对象进行操作,不存在求导和函数连续性的限定
• 具有内在的隐并行性和更好的全局寻优能力
• 采用概率化的寻优方法,不需要确定的规则就能自动获取和指导优化的搜索空间,自适应地调整搜索方向
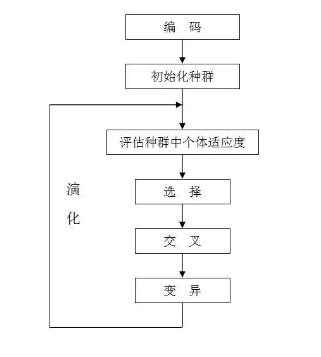
遗传算法
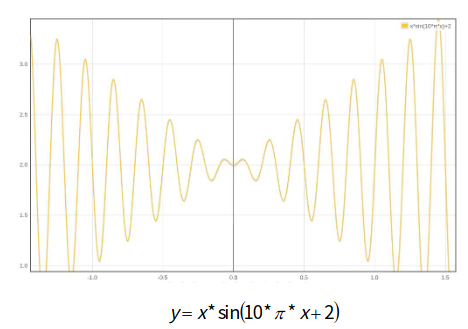
在既定的区间内找出函数的最大值
相当于袋鼠蹦跳的过程,需要设计一种编码方式,二进制编码法1110001010111
- Step1,随机初始化一个种群,即第一批袋鼠
- Step2,通过解码过程,得到袋鼠的位置,用适应性函数对每一个基因个体作评估(适应度越高越好)
- Step3,用选择函数按照某个规则择优选择(每隔一段时间,kill适应度差的袋鼠,保证总体数目持平)
- Step4,让个体基因变异,产生子代
二进制编码序列:
比如x的范围是[-1, 2],需要保留小数点后6位的精度,那么空间会分成3*10^6份, 因为2^31=2097152 <3*10^6 <2^22=4194304 ,所以编码的二进制为22位
Thinking:如何将一个22位的二进制转化为对应区间的数值
先将22位的二进制转化为10进制数x
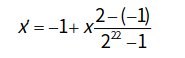
比如 1001110010000101010101进行换算后为0.834229
print(0b1001110010000101010101)
print(2564437*3/(4194304-1)-1)
适应度函数(fitness function):
也称评价函数,用于区分群体中个体好坏的标准,适应度函数总是非负的
选择函数(selection):
轮盘赌选择,一种回放式随机采样方法。每个个体进入下一代的概率等于它的适应度值与整个种群中个体适应度值和的比例
随机竞争选择,每次按轮盘赌选择一对个体,然后让这两个体进行竞争,适应度高的被选中
假如有5条染色体,适应度分别为1、2、3、1、3
那么个体的被选中的概率为:10%, 20%, 30%, 10%, 30%
(选择函数有多种方式)
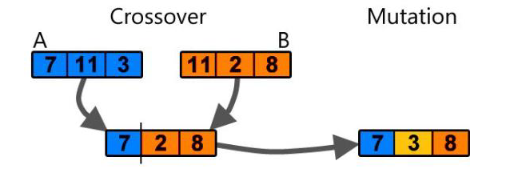
染色体交叉(crossover):
- 两个相互配对的染色体按某种方式相互交换其部分基因,从而形成两个新的个体
- 单点交叉
对应的二进制交换
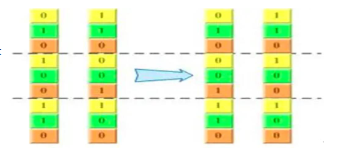
- 两点交叉与多点交叉
- 均匀交叉
- 算术交叉
基因突变(Mutation):
- 基本位变异,对个体编码串中以变异概率、随机指定的某一位或某几位仅因座上的值做变异运算。
- 101101001011001
- 101101011011000
- 均匀变异,用符合某一范围内均匀分布的随机数,以某一较小的概率替换个体编码串中各个基因位上的原有基因值
- 边界变异,随机的取基因座上的两个对应边界基因值之一去替代原有基因值
- 非均匀变异:对原有的基因值做一随机扰动,以扰动后的结果作为变异后的新基因值
- 高斯近似变异:进行变异操作时用符号均值为P的平均值,方差为P平方的正态分布的一个随机数来替换原有的基因值
遗传算法与神经网络:
- 遗传算法是一种最优化的算法,可以参与网络参数的学习,网络结构的设计等
- 网络参数学习:
- 假设神经网络有100个随机权重集合,评估对应每个权重集合的神经网络。基于评估,只保留最佳的20个权重集合,然后从这20个集合中进行随机选择,取代剩余的80个权重集合(应用简单的交叉和突变)
- 网络结构学习:
- 增强拓扑神经演化(Neuroevolution of Augmenting Topologies,NEAT)是一种基于遗传算法演化新型神经网络的方法
- http://www.cs.ucf.edu/~kstanley/neat.html
遗传算法工具
scikit-opt算法工具:
- 算法库,对遗传算法、粒子群算法、模拟退火、蚁群算法较好的封装
- 文档:https://scikit-opt.github.io/scikit-opt/#/zh/
pip install scikit-opt
from sko.GA import GA, GA_TSP
Geatpy工具:
一个高性能实用的Python遗传算法工具箱,提供一个面向对象的进化算法框架
提供了遗传和进化算法相关算子的库函数,如初始化种群、选择、交叉、变异、重插入、多目标优化非支配排序等,并且提供进化算法模板来实现多样化的进化算法
遗传算法使用:
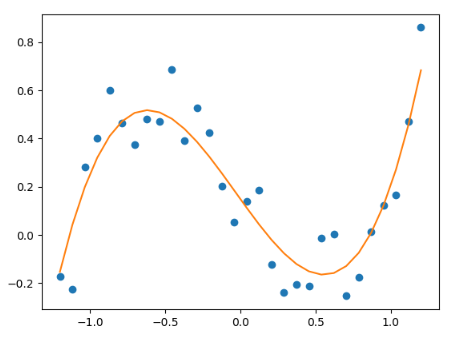
假设 x在[-1.2, 1.2]之间,实际的 y = x^3 - x + b ,这里b为随机的数值(不超过0.5)
我们想要创建一个Model, y = ax^3 + bx^2 + cx + b ,来拟合实际的(x, y),这里我们采用MSE作为损失函数,即
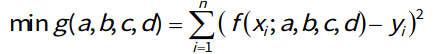
遗传算法可以作为优化方法,帮我们求解a,b,c,d
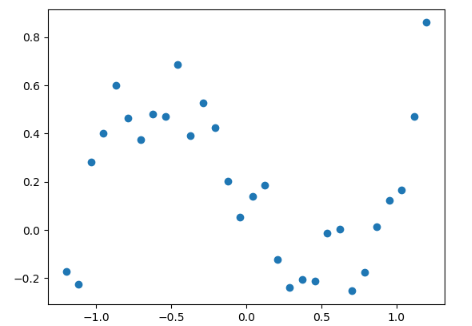
# 生成数据 x_true = np.linspace(-1.2, 1.2, 30) # 3阶的y y_true = x_true ** 3 - x_true + 0.5 * np.random.rand(30) # 可视化 plt.plot(x_true, y_true, 'o') # 计算预测结果 def f_fun(x, a, b, c, d): return a * x ** 3 + b * x ** 2 + c * x + d # 计算loss def obj_fun(p): a, b, c, d = p # 计算残差 loss loss = np.square(f_fun(x_true, a, b, c, d) - y_true).sum() return loss # 使用 scikit-opt 做最优化 ga = GA(func=obj_fun, n_dim=4, size_pop=100, max_iter=500, lb=[-2] * 4, ub=[2] * 4) best_params, loss = ga.run() print('best_x:', best_params, '\n', 'best_y:', loss) # 画出拟合效果图 # 计算预测值 y_predict = f_fun(x_true, *best_params) fig, ax = plt.subplots() ax.plot(x_true, y_true, 'o') ax.plot(x_true, y_predict, '-') plt.show()
GA工具使用:
GA(func=obj_fun, n_dim=4, size_pop=100, max_iter=500, lb=[-2]* 4, ub=[2] * 4)
- obj_fun,定义你的目标函数
- n_dim,决策变量维数, 这里是4个决策变量 a, b, c, d
- lb,决策变量下界
- ub,决策变量上界
- precision,精度
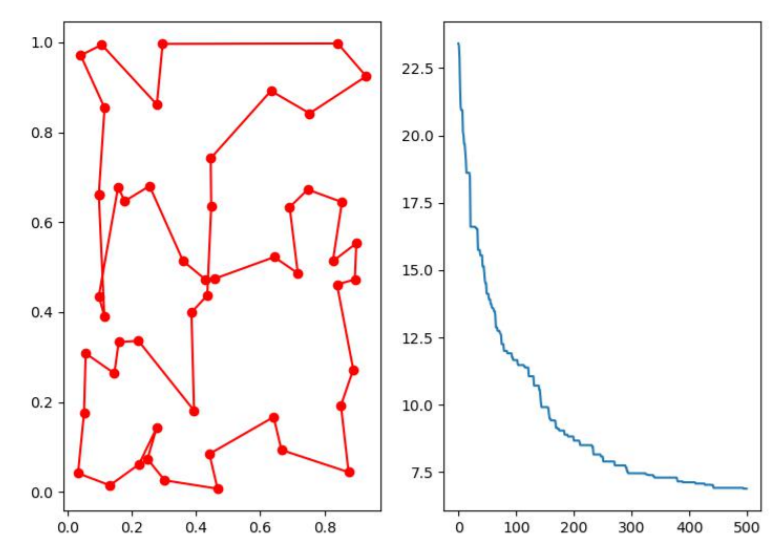
使用遗传算法求解旅行商问题
旅行商问题(TSP):
- Travelling Salesman Problem,一个旅行商想去拜访若干城市,然后回到他的出发地,给定各个城市之间所需的旅行时间后,怎样计划他的路线,使得他能对每个城市恰好进行一次访问,而且总时间最短
- from sko.GA import GA_TSP
- ga_tsp = GA_TSP(func=compute_distance, n_dim=num_points,size_pop=50, max_iter=500, prob_mut=0.2)
- 编写compute_distance函数,计算城市的距离
# 城市的数量 num_points = 50 # 生成点坐标 ...... # 目标函数,输入路径 返回总距离 def compute_distance(routine): ...... # 使用遗传算法 ...... # 画图 fig, ax = plt.subplots(1, 2) best_points_ = np.concatenate([best_points, [best_points[0]]]) best_points_coordinate = points_coordinate[best_points_, :] ax[0].plot(best_points_coordinate[:, 0], best_points_coordinate[:, 1],'o-r') ax[1].plot(ga_tsp.generation_best_Y) plt.show()
Santa的接待安排
圣诞节前100天,Santa开放了workshop,欢迎以家庭单位的参观,如何更合理的安排这些家庭参观?
每个家庭有10个选择choice0-9,数字代表了距离圣诞节的天数,比如 1代表12月24日,每个家庭必须并且只安排一次参观家庭数量 5000,即family_id 为[0, 4999],每天访问的人数需要在125-300人
Action1:Santa的接待安排
为了更合理的计算Santa的安排能力,我们使用preference cost和accounting penalty两个指标
1)preference cost,代表Santa的个性化安排能力
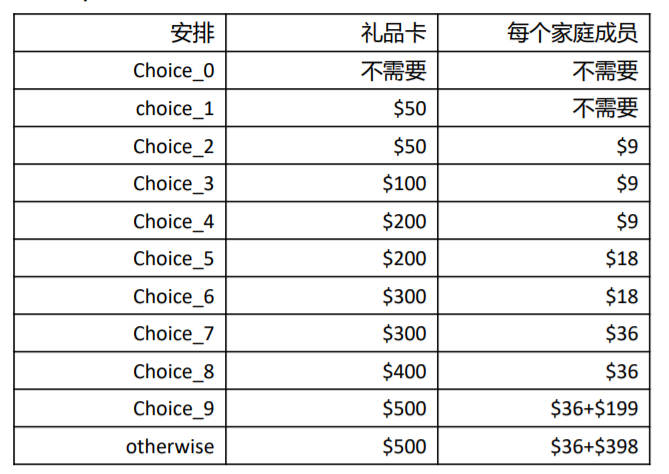
2)accounting penalty,代表Santa安排的财务成本
每天接待的人员数N(d)如果大于125,就会拥挤,产生过多的清洁成本,计算公式为
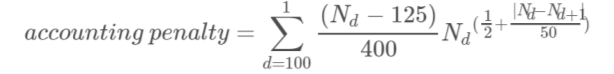
其中 N(d)代表当天,N(d+1)代表前一天(因为N代表距离圣诞节的天数)
最终的 Score = preference cost + accounting penalty
最终提交每个家庭的安排 submission.csv
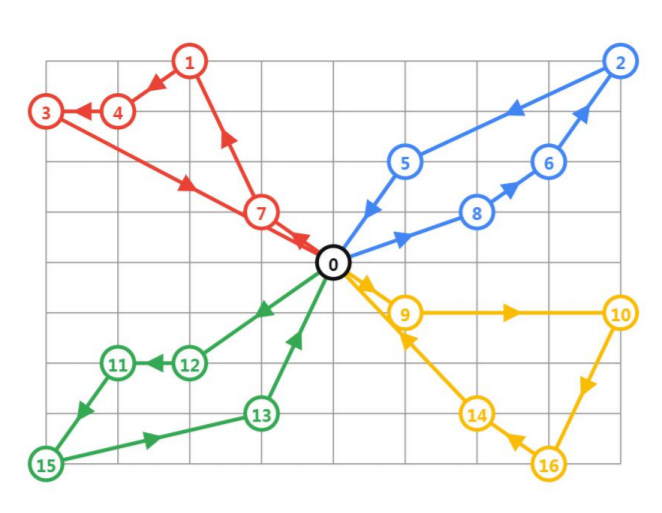
VRP(Vehicle Routing Problem)
车辆路径问题,可以看成旅行商问题的推广
有N辆车,都从原点出发,每辆车访问一些点后回到原点,要求所有的点都要被访问到,求最短的车辆行驶距离或最少需要的车辆数
Thinking:有哪些应用领域,适用于VRP问题
- 快递公司,给司机分配送货线路
- 拼车软件,为司机分配接送乘客的路线
常见的限制要求:
- 车辆具有可携带的最大重量或数量
- 司机需要在指定时间窗口内访问某位置
- 点的访问顺序等
Project:旅行商问题
美国的13个主要城市,包括:New York, Los Angeles, Chicago, Minneapolis, Denver, Dallas, Seattle, Boston, San Francisco, St. Louis, Houston, Phoenix, Salt Lake City
车的数量为1,从0出发后再回到0点 [ 0, 2451, 713, 1018, 1631, 1374, 2408, 213, 2571, 875, 1420, 2145, 1972], # New York [2451, 0, 1745, 1524, 831, 1240, 959, 2596, 403, 1589, 1374, 357, 579], # Los Angeles [ 713, 1745, 0, 355, 920, 803, 1737, 851, 1858, 262, 940, 1453, 1260], # Chicago [1018, 1524, 355, 0, 700, 862, 1395, 1123, 1584, 466, 1056, 1280, 987], # Minneapolis [1631, 831, 920, 700, 0, 663, 1021, 1769, 949, 796, 879, 586, 371], # Denver [1374, 1240, 803, 862, 663, 0, 1681, 1551, 1765, 547, 225, 887, 999], # Dallas [2408, 959, 1737, 1395, 1021, 1681, 0, 2493, 678, 1724, 1891, 1114, 701], # Seattle [ 213, 2596, 851, 1123, 1769, 1551, 2493, 0, 2699, 1038, 1605, 2300, 2099], # Boston [2571, 403, 1858, 1584, 949, 1765, 678, 2699, 0, 1744, 1645, 653, 600], # San Francisco [ 875, 1589, 262, 466, 796, 547, 1724, 1038, 1744, 0, 679, 1272, 1162], # St. Louis
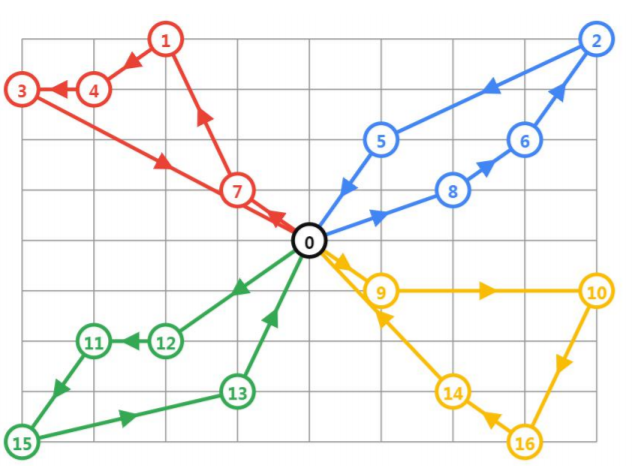
VRP问题的流程
使用RoutingModel进行路径规划管理
1)设置城市个数,车辆数,起点下标
2)设置距离回调函数 distance_callback
3)设置初始可行解算法
PATH_CHEAPEST_ARC,从start节点开始,找到CHEAPEST的路径
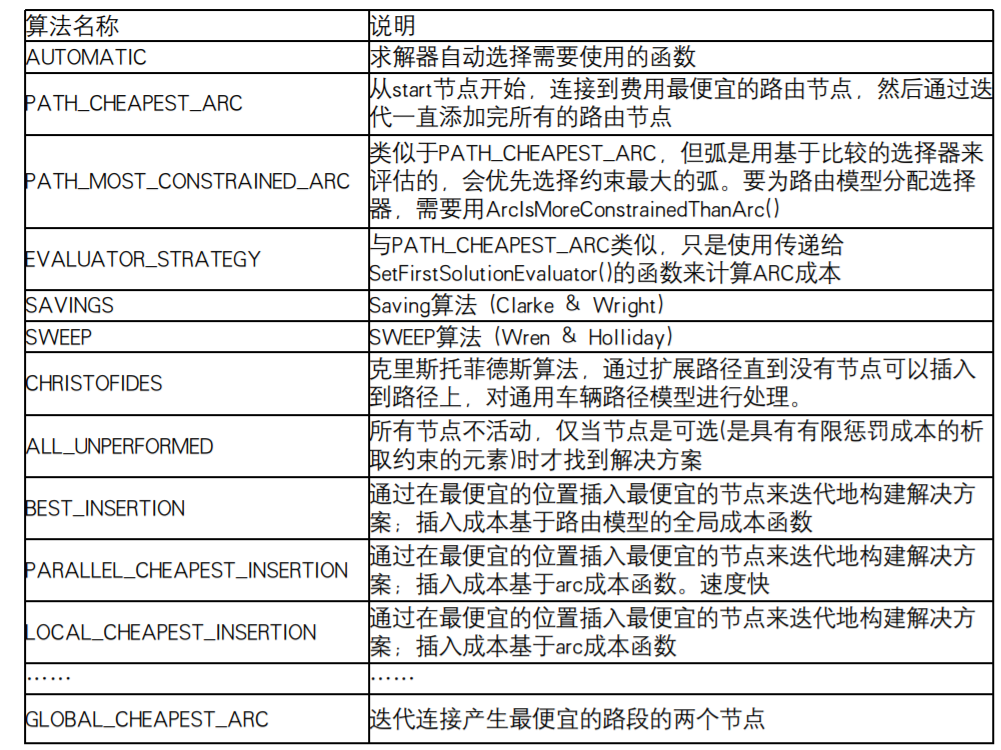
返回值的情况:
4)在初始可行解的基础上进行优化(使用local search)
search_parameters.local_search_metaheuristic = (
routing_enums_pb2.LocalSearchMetaheuristic.GUIDED_LOCAL_SEARCH)
#搜索时间限制
search_parameters.time_limit.seconds = 120
自动钻孔机路线规划
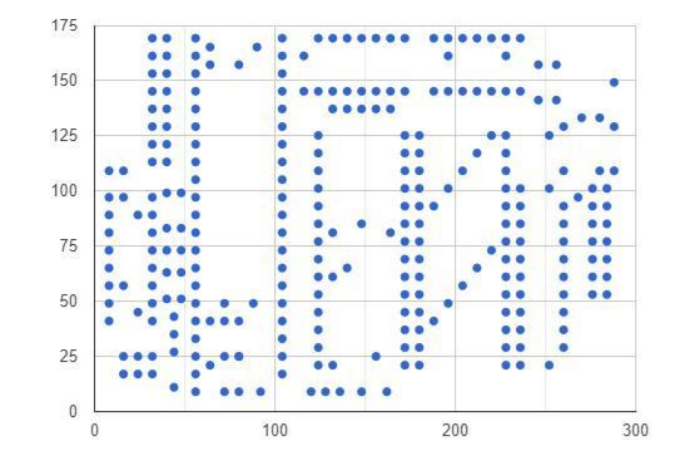
电路板上钻孔,请你找到钻头在板上的最短路线
Drilling.csv 包含了平面中的 280 个点(x, y)
Project B:指定城市的旅行商问题
从指定的城市(北京)出发,经过且所有城市一次,回到原点(北京),求如何安排距离最短?
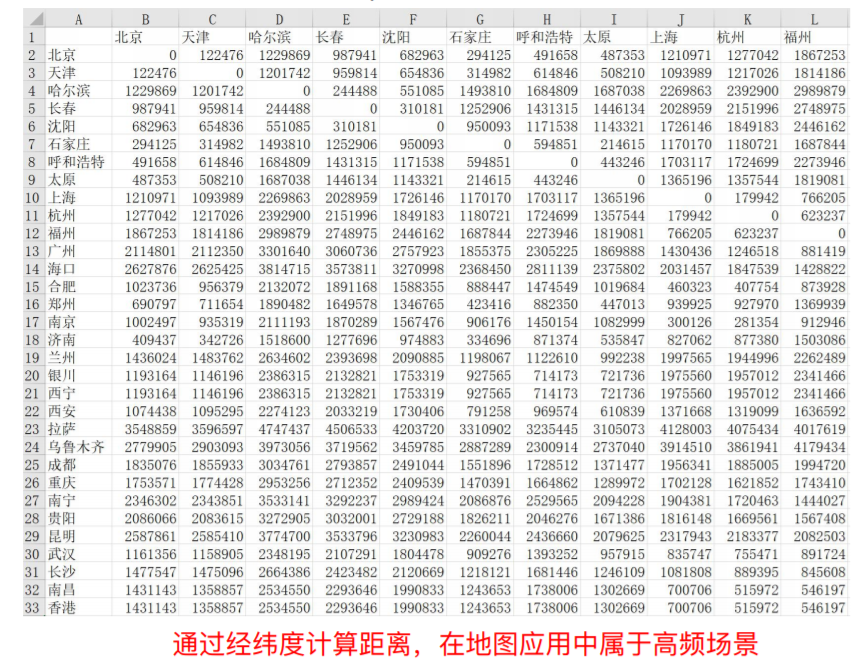
假设经过中国的省会及直辖市,包括:北京,天津,哈尔滨,长春,沈阳,石家庄,呼和浩特,太原,上海,杭州,福州,
广州,海口,合肥,郑州,南京,济南,兰州,银川,西宁,西安,拉萨,乌鲁木齐,成都,重庆,南宁,贵阳,昆明,武汉,长沙,南昌,香港,澳门
Thinking:求解问题的思路是怎样的?
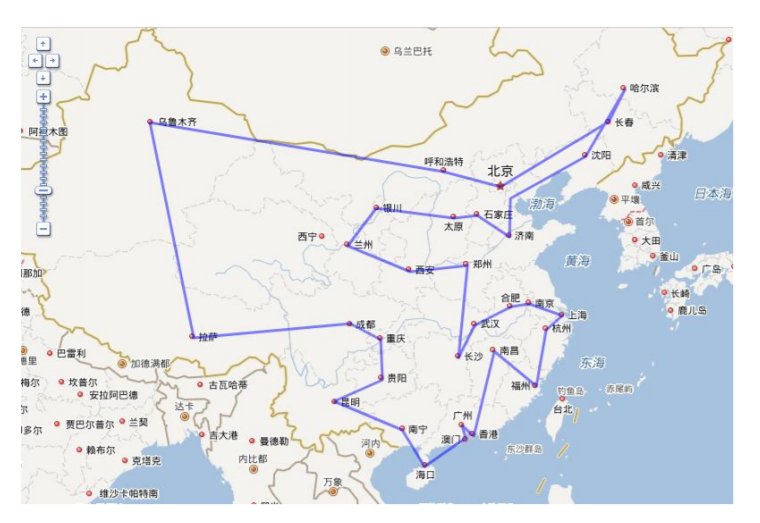
• Step1,数据预处理
- 1)所有城市的位置(经度、维度)
- 2)城市之间的距离矩阵
• Step2,根据指定的城市,计算TSP,得到路径route
• Step3,可视化交互
- 1)选择指定的城市
- 2)画出车辆行驶路径(基于百度地图API)
数据源:
1)cities.xlsx,需要指定地点的经度、纬度
2)distance.xlsx,通过compute_distance计算得到
• Step1,数据预处理
1)所有城市的位置(经度、维度)
2)城市之间的距离矩阵
# 针对常用的功能,可以封装为自己的工具包 from cylearn import common_tools # 读取,写入指定的pickle result = common_tools.load_pickle('result.pkl') common_tools.save_pickle(result, 'result.pkl') # 计算两点之间的距离 dist = common_tools.compute_distance(longitude1, latitude1,longitude2, latitude2)
• Step2,根据指定的城市,计算TSP,得到路径route
创建tsp类
1)def __init__(self, city_names=None):
类初始化 __init__,定义常用的变量
2)def create_data_model(self):
初始化data,得到data字典,记录distance_matrix,num_vehicles,depot等数据
3)def get_solution(self, routing, solution):
返回路径(这里为index list,比如[0, 1, 2]) 以及 总距离
4)def work(self):
# 定义路由,比如10个节点,1辆车 manager = RoutingIndexManager(10, 1, starts_ends) # 创建 Routing Model. routing = pywrapcp.RoutingModel(manager) # 计算两点之间的距离 def distance_callback(from_index, to_index): # 将路由变量Index转化为 距离矩阵ditance_matrix的节点index from_node = manager.IndexToNode(from_index) to_node = manager.IndexToNode(to_index) return data['distance_matrix'][from_node][to_node] t r a n s i t _ c a l l b a c k _ i n d e x = routing.RegisterTransitCallback(distance_callback) # 定义每条边arc的代价 routing.SetArcCostEvaluatorOfAllVehicles(transit_callback_index) # 设置启发式搜索 search_parameters = pywrapcp.DefaultRoutingSearchParameters() search_parameters.first_solution_strategy = ( routing_enums_pb2.FirstSolutionStrategy.PATH_CHEAPEST_ARC) # 求解路径规划 solution = routing.SolveWithParameters(search_parameters)
Step2,根据指定的城市,计算TSP,得到路径route
TSP类编写完后,可以进行测试
测试1:使用全量的城市,不对city_names进行筛选
测试2:city_names = ['北京', '天津', '南京']
• Step3,可视化交互
1)选择指定的城市
// 表单提交
<form action="tsp_china" method="POST">
// checkbox使用
<input type="checkbox" name="city" value=" {{ city }} " checked="checked"/>
2)画出车辆行驶路径(基于百度地图API)
基于 map_line1.html 进行改写
Project C:多辆车的路径规划 VRP
• 条件:经过中国33个城市,一共4辆车,每辆车最大行驶10000公里
• 目标:1) 每辆车的行驶里程数更接近 2)总里程数更少
• 数据预处理:
1)设置 num_vehicles,代表一共多少量车
2)设置 depot,代表所有车的起始出发点一样,都是从节点depot开始
3)添加距离约束,即每辆车的最大行驶距离
• 需要注意:
1)在VRP问题中,路径上给点赋的index和点实际的index不一样,需要使用IndexToNode方法进行转换才能得到实际的index
# 添加距离约束 dimension_name = 'Distance' routing.AddDimension( transit_callback_index, 0, # no slack 10000, # 车辆最大行驶距离 True, # start cumul to zero dimension_name) distance_dimension = routing.GetDimensionOrDie(dimension_name) # 尽量减少车辆之间的最大距离 distance_dimension.SetGlobalSpanCostCoefficient(100) 说明:车辆之间最大距离,最小化 global_span_cost = coefficient * (Max(dimension end value) - Min(dimension start value))
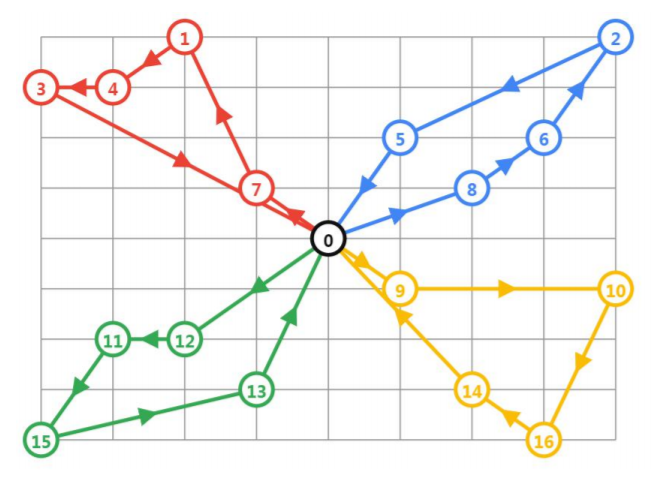
Project D: 带有容量约束的VRP问题
现在有4辆车,均从原点出发,他们需要收16个客户点的货,如何安排使得总距离最短
1)从起始仓库出发,回到起始仓库
2)每辆车都有容量限制,每个客户点也有货物容量
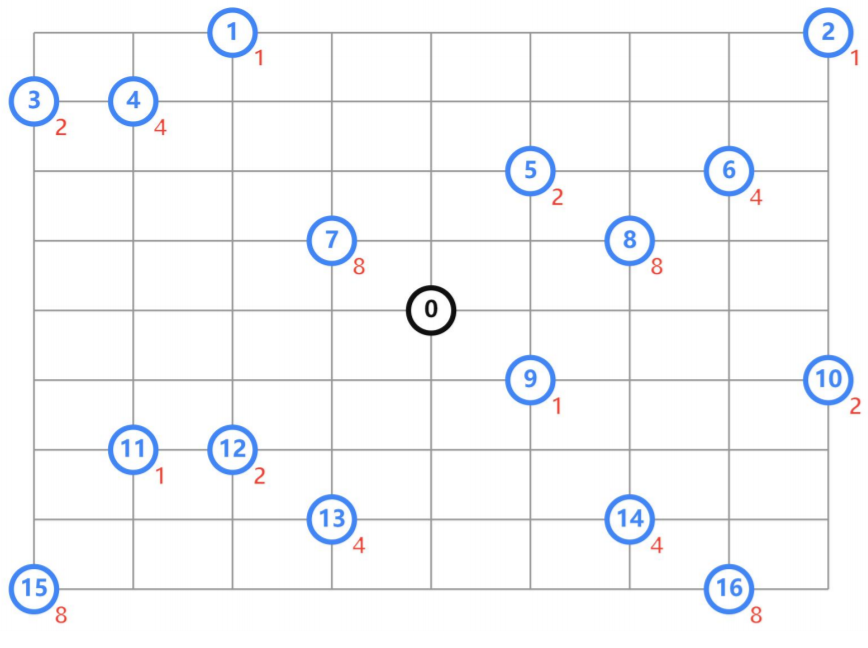
distance_matrix,两点之间的距离
demands,每个客户点需要配送的货物量
num_vehicles,一共多少量车
vehicle_capacities,每辆车的容量
depot,起始原点的下标
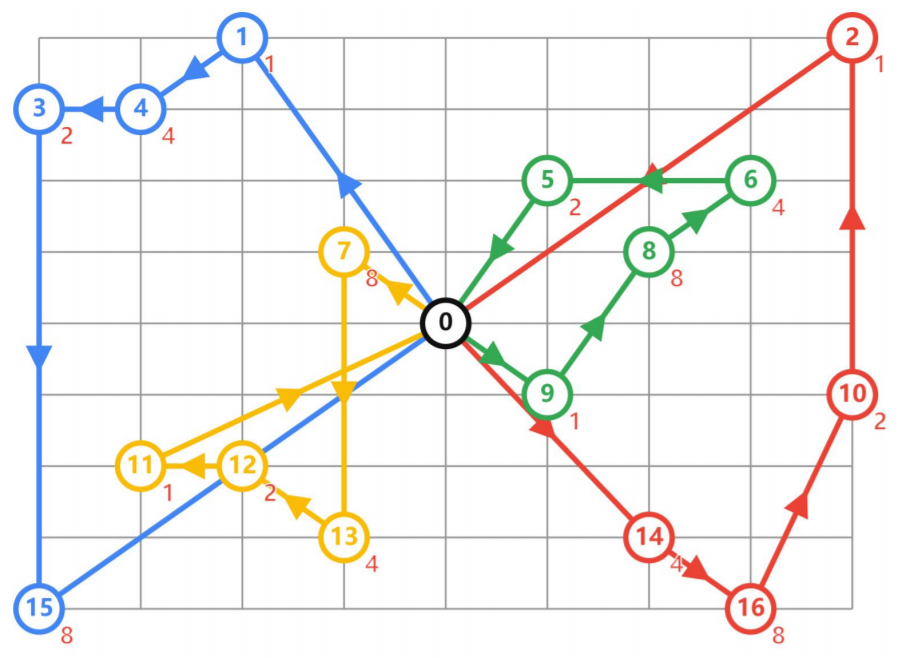
带有时间窗口约束的VRP问题
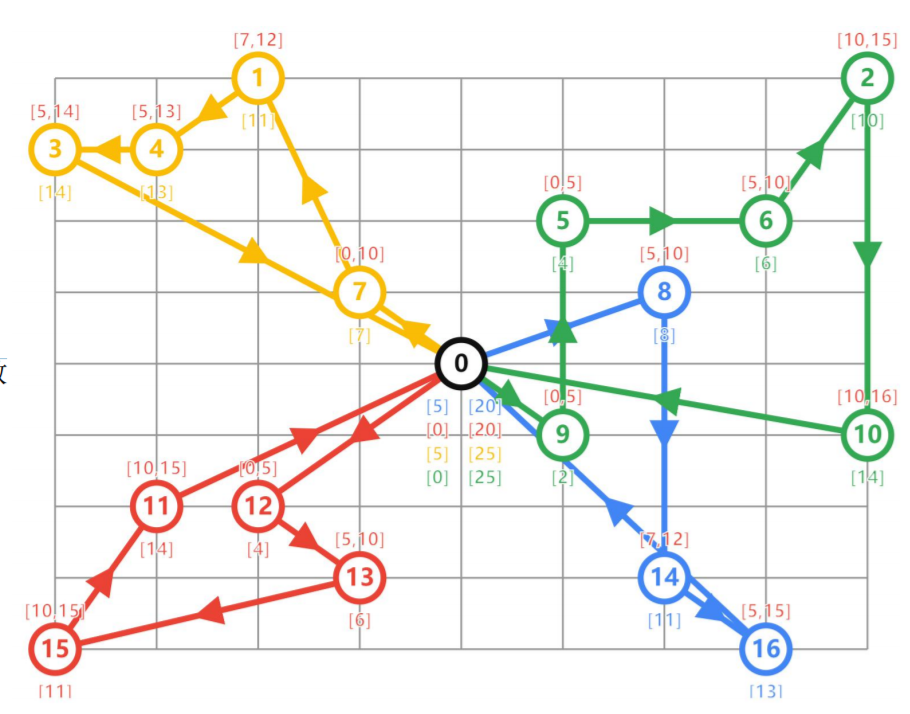
现在有4辆车,均从原点出发,他们需要去16个配送点送货,如何安排使得总时间最短
1)起始出发仓库,最多只能同时装载/卸载 两辆车
2)每个配送点需要在指定时间窗口内完成
比如 点8 [5, 10],需要在第5-10分钟内完成配送
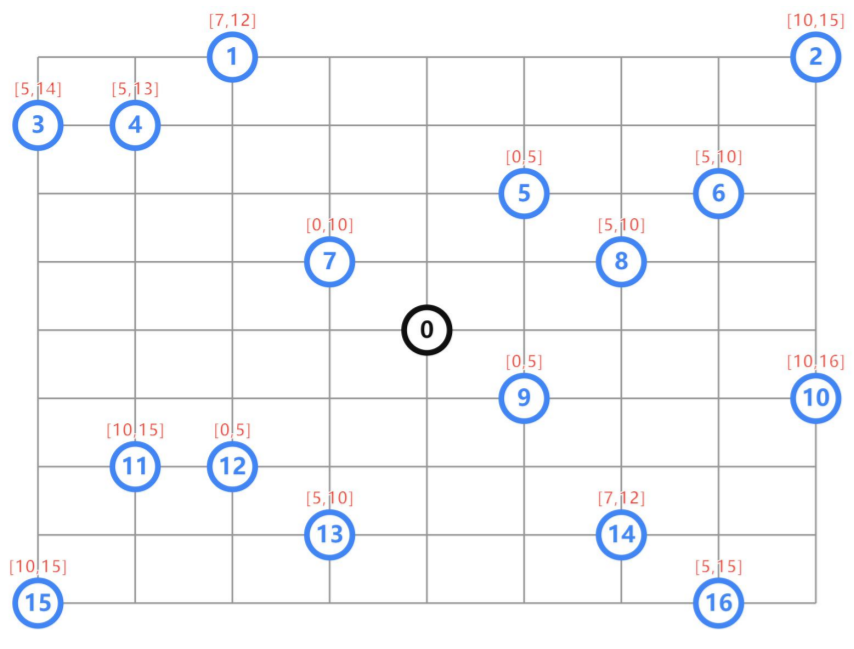
time_matrix,两点之间的行驶时间
time_windows,每个配送点的时间窗口
num_vehicles,一共多少量车
vehicle_load_time,车的装载所需时间
vehicle_unload_time,车的卸载所需时间
depot_capacity,起始仓库容量,同时装载/卸载的车数
depot,起始原点的下标
Project F:带有指定拿起放下约束的VRP
带有指定拿起放下约束的VRP问题
现在有4辆车,均从原点出发,他们需要完成指定的任务,即帮指定的商家,送给指定的客户
1)一共8项任务,每项任务都有指定的(商家、客户),比如[1, 6],即为 商家1给客户6进行配送
2)所有车辆的总距离最小
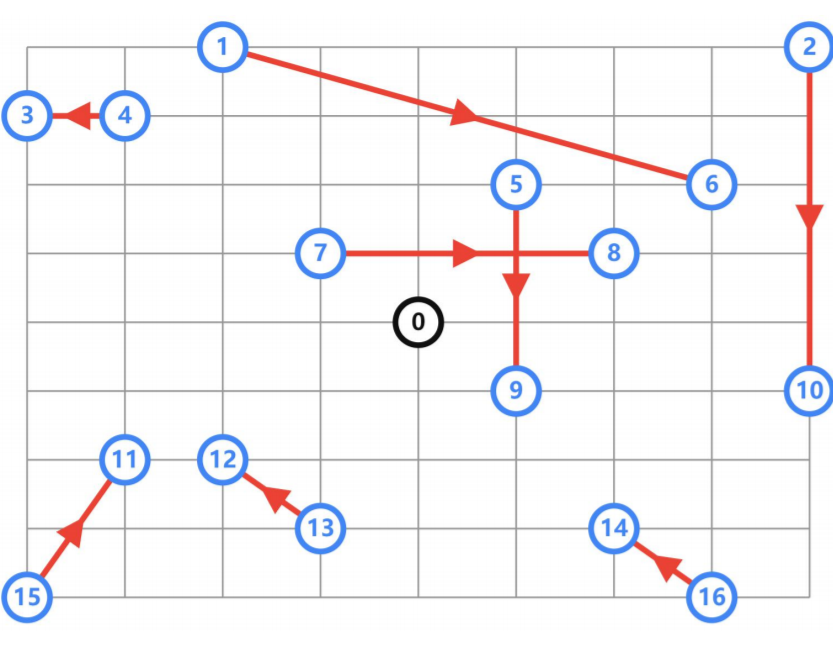
distance_matrix,两点之间的行驶距离
num_vehicles,一共多少量车
pickups_deliveries,需要配送的商家、客户
depot,起始原点的下标

 浙公网安备 33010602011771号
浙公网安备 33010602011771号