
评分卡模型
1. 评分卡模型
评分卡模型是常用的金融风控手段之一
风控,就是风险控制,我们采取各种措施和方法,减少风险发生的可能性,或风险发生时造成的损失
根据客户的各种属性和行为数据,利用信用评分模型,对客户的信用进行评分,从而决定是否给予授信,授信的额度和利率,减少在金融交易中存在的交易风险
按照不同的业务阶段,可以划分为三种:
- 贷前:申请评分卡(Application score card),称为A卡
- 贷中:行为评分卡(Behavior score card),称为B卡
- 贷后:催收评分卡(Collection score card),称为C卡
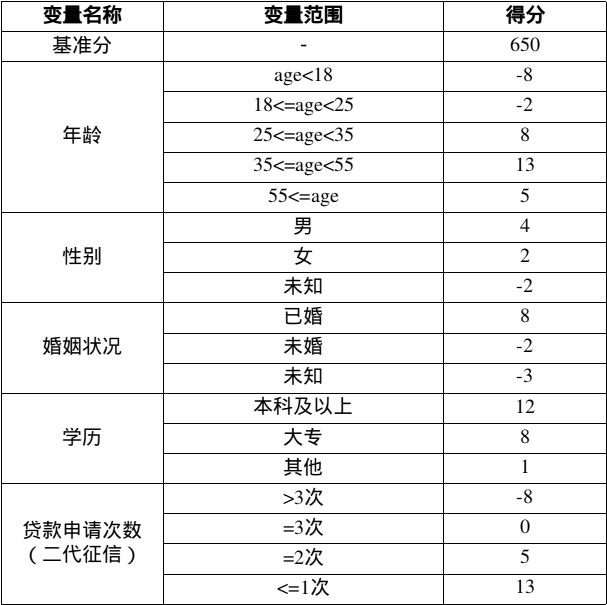
评分卡模型:
客户评分 = 基准分 + 年龄评分 + 性别评分 + 婚姻状况评分 + 学历评分 + 贷款申请次数
Thinking: 某客户年龄为27岁,性别为男,婚姻状况为已婚,学历为本科,贷款申请次数为1次,那么他的评分=?
650 (基准分) + 8(年龄评分) + 4(性别评分) + 8(婚姻评分) + 12(学历评分) + 13(贷款申请次数) = 695
Thinking:评分卡的最高分和最低分是多少?
最低分:650-8-2-3+1-8=630
最高分:650+13+4+8+12+13=700
- 评分卡模型使用的字段属性通常不超过30个,但是可以使用的属性有很多,如何挑选这些字段?
- 评分卡模型是基于每个字段的分段进行的评分,那么该如何对这些字段进行有效的分段及评分?
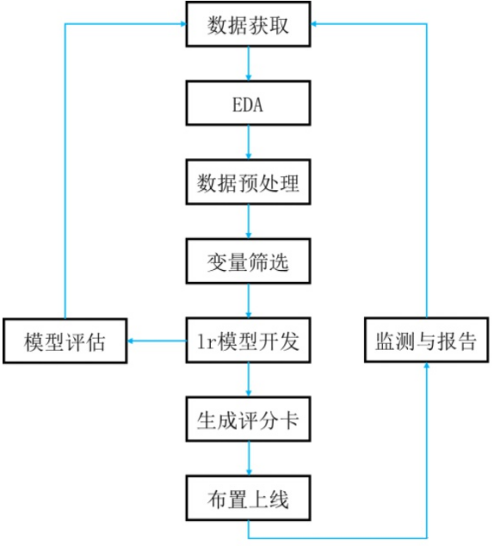
评分卡模型开发步骤:
- Step1,数据获取,包括获取存量客户及潜在客户的数据,存量客户,已开展融资业务的客户,包括个人客户和机构客户;潜在客户,将要开展业务的客户
- Step2,EDA,获取样本整体情况,进行直方图、箱形图可视化
- Step3,数据预处理,包括数据清洗、缺失值处理、异常值处理
- Step4,变量筛选,通过统计学的方法,筛选出对违约状态影响最显著的指标。主要有单变量特征选择和基于机器学习的方法
- Step5,模型开发,包括变量分段、变量的WOE(证据权重)变换和逻辑回归估算三个部分
- Step6,模型评估,评估模型的区分能力、预测能力、稳定性,并形成模型评估报告,得出模型是否可以使用的结论
- Step7,生成评分卡(信用评分),根据逻辑回归的系数和WOE等确定信用评分的方法,将Logistic模型转换为标准评分的形式
- Step8,建立评分系统(布置上线),根据生成的评分卡,建立自动信用评分系统
WOE编码:
- Weight of Evidence,证据权重
- 是自变量的一种编码,常用于特征变换用来衡量自变量与因变量的相关性
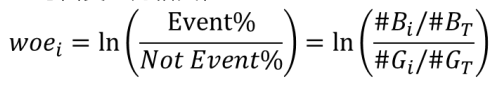
B代表风险客户,G代表正常客户
对于某一变量某一分组的WOE,衡量了这组里面的好坏客户的占比与整体样本好坏样本占比的差异
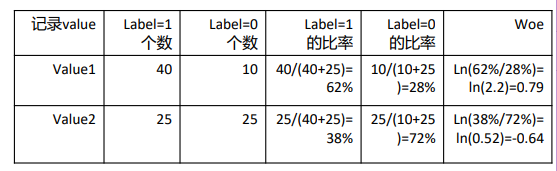
Thinking:对于二分类问题共100条记录,一个自变量只有两个值value1, value2,如何计算value1, value2对应的woe1,woe2?
- value1有50条记录,其中40条对应label 1,另外10条对应label 0
- value2有50条记录,其中25条对应label 1,另外25条对应label 0
Thinking:WOE差异越大,对风险区分能力=? 差异越大,对风险区分越明显
WOE计算:
- 对于连续型变量,分成N个bins
- 对于分类型变量保持类别group不变
- 计算每个bin or group中event和non-event的百分比
WOE的作用:
- 可以将连续型变量转化为woe的分类变量
- 可以对相似的bin或group进行合并(woe相似)
计算woe需要注意:
- 每个bin or group记录不能过少,至少有5%的记录
- 不要用过多的bin or group,会导致不稳定性
- 对bin or group中全为0或者1的特列,用 修正的woe
防止分母为0的情况
IV(Information Value):
- woe只考虑了风险区分的能力,没有考虑能区分的用户有多少
- IV衡量一个变量的风险区分能力,即衡量各变量对y的预测能力,用于筛选变量
IV的计算,可以认为是WOE的加权和
IV是与WOE密切相关的一个指标,在应用实践中,评价标准可参考如下:
Thinking:怎样使用IV值进行特征变量的筛选? 比如筛选掉IV < 0.1的变量,因为该特征对于y的预测能力很弱
WOE和IV计算步骤:
- Step1,对于连续型变量,进行分箱(binning),可以选择等频、等距,或者自定义间隔,对于离散型变量,如果分箱太多,则进行分箱合并
- Step2,统计每个分箱里的好人数(bin_goods)和坏人数(bin_bads)
- Step3,分别除以总的好人数(total_goods)和坏人数(total_bads),得到每个分箱内的边际好人占比margin_good_rate和边际坏人比margin_bad_rate
- Step4,计算每个分箱的WOE, WOE = ln (margin_bad_rate/ margin_good_rate)
-
Step5,检查每个分箱(除null分箱外)里WOE值是否满足单调性,若不满足,返回step1; 说明:null分箱由于有明确的业务解释,因此不需要考虑满足单调性;
- Step6,计算每个分箱里的IV,最终求和,即得到最终的IV
Thinking:如何计算每个bucket中的WOE和IV?
- margin_bad_rate = bad/total_bads
- margin_good_rate = good/total_goods
- WOE=ln(margin_bad_rate/margin_good_rate)
- IV=(bad/total_bads - good/total_goods)*WOE
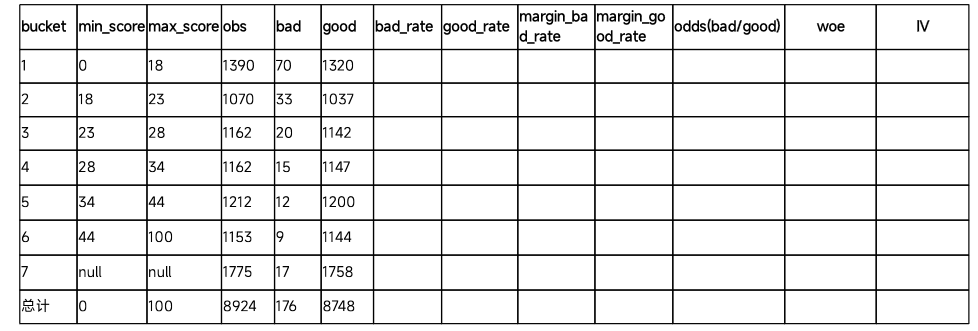
计算每个分箱里的WOE和IV
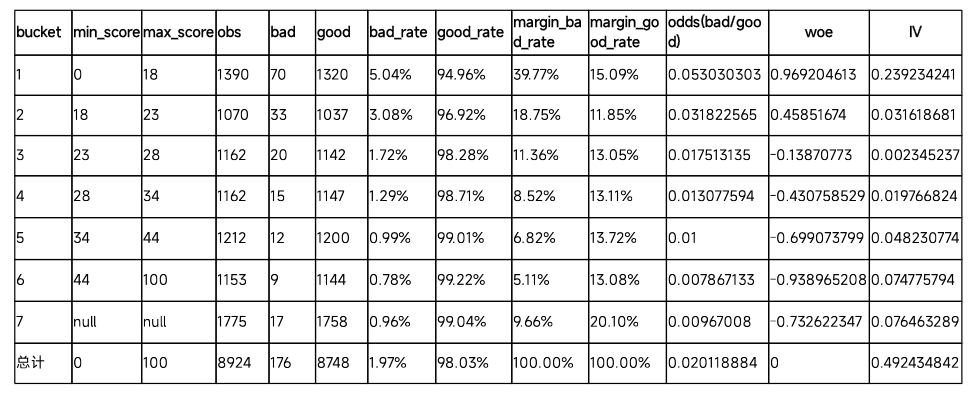
WOE编码计算:
假设,我们对Age字段,计算相关的woe
Step1,首先对每个level进行分层统计
Step2,计算每层的好坏占比
Step3,通过好坏占比 => 计算WOE
2. Project:基于评分卡的风控模型开发
数据集GiveMeSomeCredit,15万样本数据
https://www.kaggle.com/c/GiveMeSomeCredit/data
– 基本属性:包括了借款人当时的年龄
– 偿债能力:包括了借款人的月收入、负债比率
– 信用往来:两年内35-59天逾期次数、两年内60-89天逾期次数、两年内90天或高于90天逾期的次数
– 财产状况:包括了开放式信贷和贷款数量、不动产贷款或额度数量。
– 其他因素:包括了借款人的家属数量
– 时间窗口:自变量的观察窗口为过去两年,因变量表现窗口为未来两年
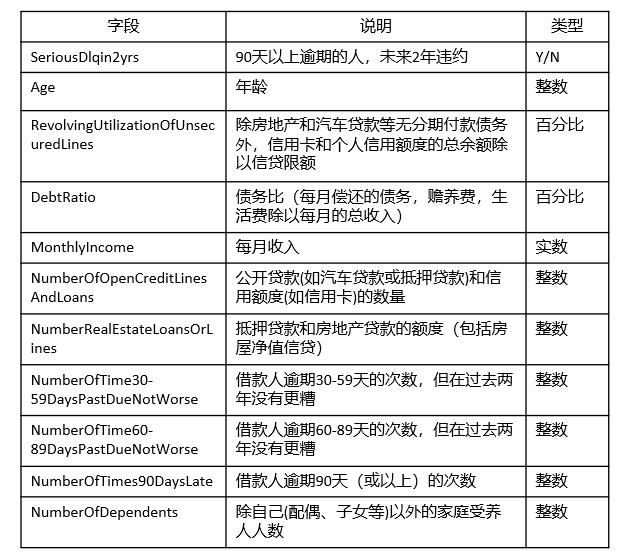
针对字段X,存在缺失值的处理:
- 直接删除含有缺失值的样本
- 如果缺失的样本占总数很大,可以直接舍弃字段X(如果将X作为特征加入,噪音会很大)
- 采用简单规则进行补全
删除:删除数据缺失的记录;
均值:使用当前列的均值;
高频:使用当前列出现频率最高的数据。
采用预测进行补全:
- 根据样本之间的相似性填补缺失值
- 根据变量之间的相关关系填补缺失值
To Do:采用随机森林对Titanic乘客生存预测中的Embarked, Age进行补全
1)通过Survived,Pclass, Sex, SibSp, Parch, Fare字段预测Embarked字段中的缺失值
2)通过Survived,Pclass, Sex, SibSp, Parch, Fare,Embarked字段,预测Age字段中的缺失值
Step1,数据探索性分析
- 违约率分析
- 缺失值分析
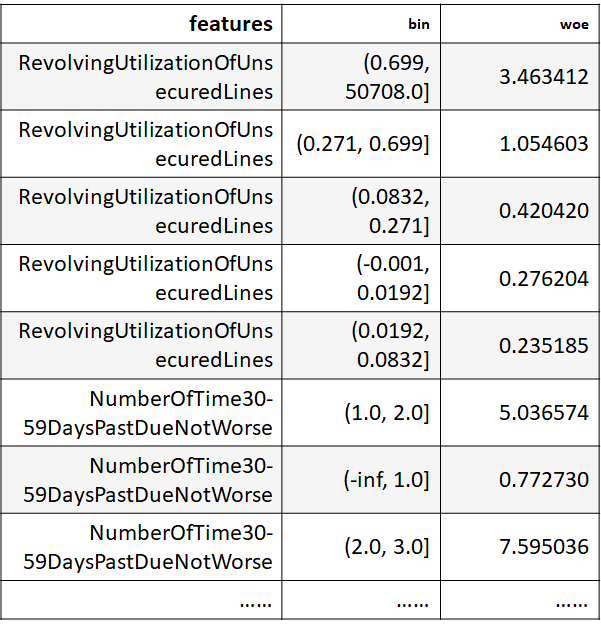
- 对于某个字段的统计分析(比如RevolvingUtilizationOfUnsecuredLines)
Step2,数据缺失值填充,采用简单规则,如使用中位数进行填充
Step3,变量分箱
1)对于age字段,分成6段 [-math.inf, 25, 40, 50, 60, 70, math.inf]
2)对于NumberOfDependents(家属人数)字段,分成6段 [-math.inf,2,4,6,8,10,math.inf]
3)对于3种逾期次数,即NumberOfTime30-59DaysPastDueNotWorse,NumberOfTime60-89DaysPastDueNotWorse,NumberOfTimes90DaysLate,分成10段 [-math.inf,1,2,3,4,5,6,7,8,9,math.inf]
4)对于其余字段,即RevolvingUtilizationOfUnsecuredLines, DebtRatio, MonthlyIncome, NumberOfOpenCreditLinesAndLoans, NumberRealEstateLoansOrLines 分成5段
Step4,特征筛选,使用IV值衡量自变量的预测能力,筛选IV值>0.1的特征字段
Step5,对于筛选出来的特征,计算每个bin的WOE值
Step6,使用逻辑回归进行建模
训练集、测试集切分
计算LR的准确率
Step7,评分卡模型转换
设p为客户违约的概率,那么正常的概率为1-p,Odds = p / (1-p) ,
客户违约概率p可以表示: p = Odds / (1+Odds)
评分卡的分值计算,可以通过 分值表示为比率对数的 线性表达式来定义,即 Score = A - B * In(Odds)
Score计算公式类似 y=kx + b ,A和B是常数,A称为“补偿”,B称为“刻度”,公式中的负号可以使得违约概率越低,得分越高;
常数A、B可以通过将两个假设的分值带入计算得到:
1)基准分,即给某个特定的比率𝜃0时,预期的分值P0; 通常,业内的基准分为500/600/650
2)PDO( point of double odds ),即比率翻倍的分数
比如,odds翻倍时,分值减少50;
比率为2𝜃"0 "的点的分值应该为P"0" -PDO
代入式中,可以得到:

Step7,评分卡模型转换
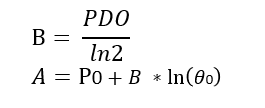
假设odds=1的时候,特定的分数为650分
Thinking A 和 B=?
B = 50/ln(2) = 72.13
A = 650 + 72.13 * ln(1/1) = 650
𝑆𝑐𝑜𝑟𝑒=𝐴 −𝐵 ∗ ln(𝑂𝑑𝑑𝑠)
Score = 650 – 72.13 * ln(Odds)
Thinking:在评分卡模型中,不直接使用违约率p,而是使用odds?

所以,Odds可以和逻辑回归无缝结合
评分卡的逻辑是Odds的变动与评分变动的映射,即把Odds映射为评分
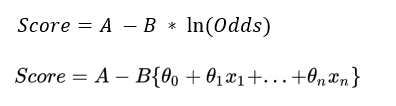
qcut使用
使用qcut可以对一组数据分成几个区间
比如,我们有11家公司,他们的年销售额分别为: [1000,856,123,523,33,71,223,699,103,456,923]
请你对这11家公司的年销售额进行分箱
1)按照 高/低,两个等级
2)按照 first 10%, second 10%, third 10% 以及 last 70% 四个等级
# 随机销售额 sales = pd.Series([1000,856,123,523,33,71,223,699,103,456,923]) print(len(sales)) # 将销售额分成 低/高 两个等级 print(pd.qcut(sales,[0,0.5,1],labels=['small sales','large sales'])) # 将销售额分成 first 10%, second 10%, third 10% 以及 后70% 四种等级 print(pd.qcut(sales,[0, 0.7, 0.8, 0.9, 1],labels=['last 70%','third 10%','second 10%','first 10%']))
qcut使用
比如,我们有11家公司,他们的年销售额分别为: [1000,856,123,523,33,71,223,699,103,456,923]
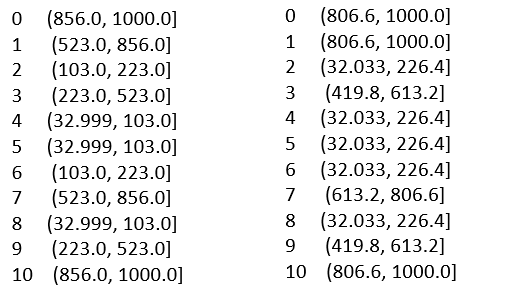
Thinking:自动将这11家公司的销售额按照5组进行划分
print(pd.qcut(sales, q=5))
这里q为参数,表示要分组的个数
qcut与cut的区别
# 根据数值的频率来选择分箱,使得区间内的频率是均匀的
print(pd.qcut(sales, q=5))
# 根据数值本身来选择分箱,使得区间是均匀的间隔
print(pd.cut(sales, 5))
Thinking:特征分箱(离散)后的优势?
- 变量分箱是对连续变量进行离散化,分箱后的特征对异常数据有很强的鲁棒性
比如 age>30 为1,否则0,如果特征没有离散化,杜宇异常数据“年龄300岁”会给模型造成很大的干扰
- 逻辑回归属于广义线性模型,表达能力受限,单变量离散化为N个后,相当于为模型引入了非线性,能够提升模型表达能力
- 离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力
- 可以将缺失作为独立的一类带入模型
- 将所有变量变换到相似的尺度上
评估指标
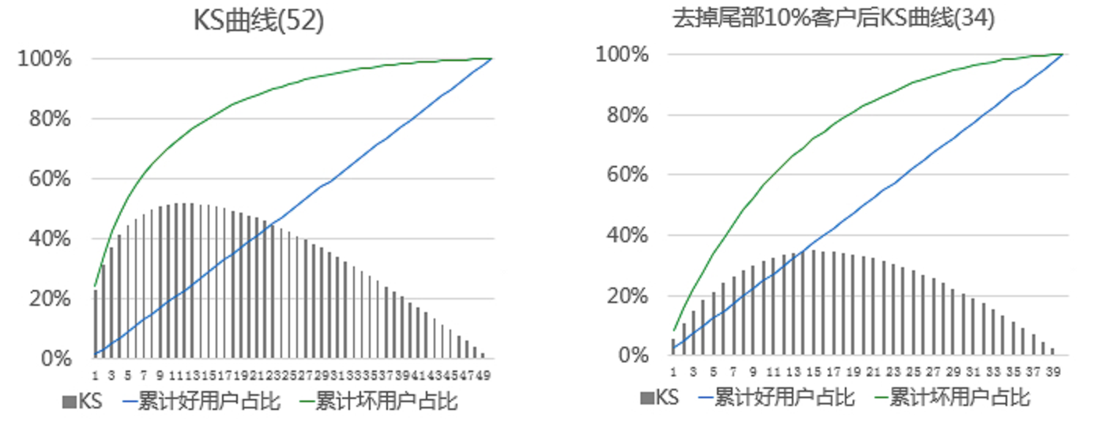
评估指标KS( Kolmogorov-Smirnov ):
由两位苏联数学家A.N. Kolmogorov和N.V. Smirnov提出
在风控中,KS常用于评估模型区分度。区分度越大,说明模型的风险排序能力(ranking ability)越强
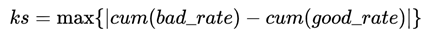
KS曲线:计算每个Score分箱区间累计坏账户占比与累计好账户占比差的绝对值
KS值:在这些绝对值中取最大值,是衡量好坏客户分数距离的上限值
KS含义:如果排除掉一定比例的坏用户,会有多少比例的好用户会被误杀掉
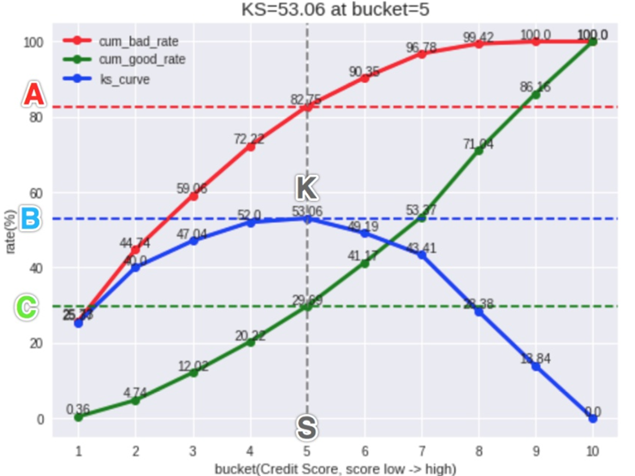
评估指标KS( Kolmogorov-Smirnov ):
- KS统计量是好坏距离或区分度的上限
- KS越大,表明正负样本区分程度越好
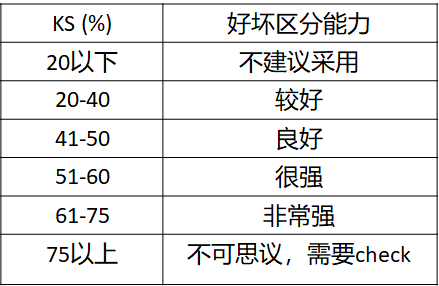
模型报告
- 将测试样本按照评分进行升序排序
- 将样本等频切分(10-20个分箱)
- 计算每个分箱对应的指标
- 计算KS值
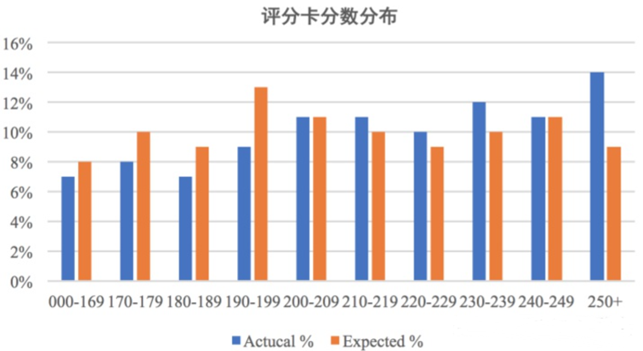
评估指标PSI:
群体稳定性指标, Population Stability Index
反映了验证样本在各分数段的分布与建模样本分布的稳定性。在建模中,我们常用来筛选特征变量、评估模型稳定性
稳定性是有参照的,需要有两个分布,即实际分布(actual)与预期分布(expected)
其中,建模时以训练样本(In the Sample, INS)作为预期分布,而验证样本作为实际分布
PSI = SUM( (实际占比 - 预期占比)* ln(实际占比 / 预期占比) )
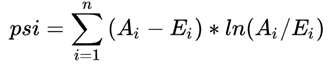
评估指标PSI:
PSI = SUM( (实际占比 - 预期占比)* ln(实际占比 / 预期占比) )
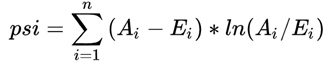
PSI数值越小,两个分布之间的差异就越小 => 越稳定
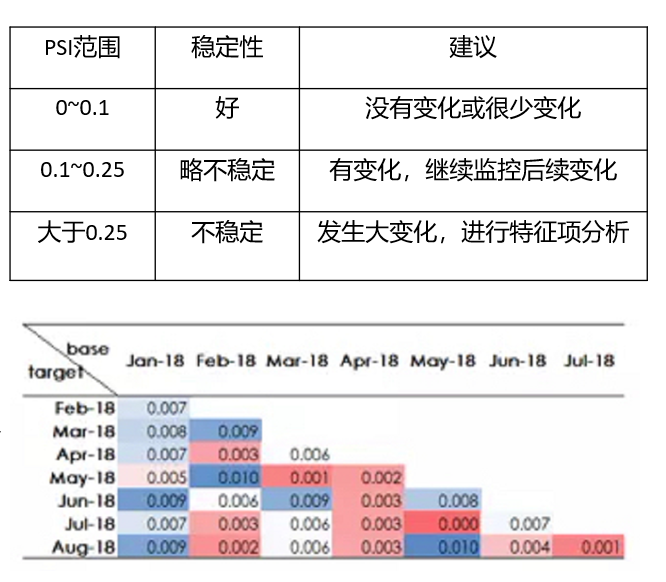
PSI矩阵:
- 衡量base月份与target月份之间的模型稳定性
- 一般认为 PSI<0.1 模型是优秀的,PSI >0.1 不一定有问题,需要具体分析
Covariate Shift场景下的模型监控
Thinking:Offline KS=52,Online KS=34的原因?
模型上线后,最坏的客户会被模型拒绝掉,不会进入到模型评估的样本中 => 导致 Covariate Shift(客群本身发生迁移)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号