
Embedding的应用
Embedding的应用
Embedding在推荐系统中的应用
广泛应用在深度推荐系统中
深度学习就是一种表示学习,学习过程就是对原有数据的特征抽取,经过层层学习后提取出来,最终交给后面的分类层进行预测
深度学习网络包括MLP(数据挖掘),RNN(文本| 时序),CNN(图像相关),对原有数据进行特征提取
Embedding在推荐系统中做特征处理,从稀疏 到 稠密;
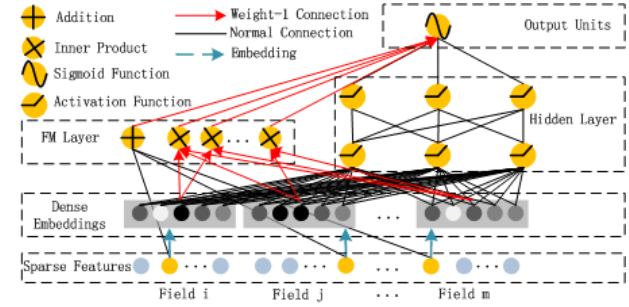
DeepFM = FM + DNN:
- 提取低阶(low order)特征 => 因子分解机FM。既可以做1阶特征建模,也可以做2阶特征建模
- 提取高阶(high order)特征 => 神经网络DNN
- end-to-end,共享特征输入
对于特征i,wi是1阶特征的权重,
Vi表示该特征与其他特征的交互影响,输入到FM模型中可以获得特征的2阶特征表示,输入到DNN模型得到高阶特征。
- 在推荐系统中,可以通过Embedding向量进行快速召回
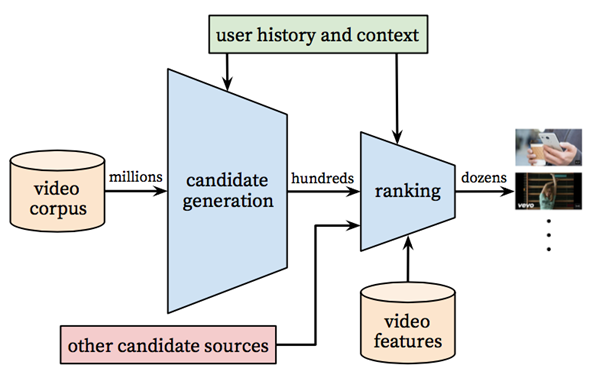
- 向量化召回(把这些特征压缩到向量中),通过模型来学习用户和物品的兴趣向量,并通过内积来计算用户和物品之间的相似性,从而得到最终的候选集(经典的Youtube召回模型)
- 收集数据:神经网络需要大量的训练样本;
- 数据处理:根据具体问题将数据按照embedding的场景标准进行处理
- 训练weights:建立embedding模型训练weights;
- 使用weights:使用Embedding weight进行recommendation和visualizations
推荐:通过内积计算用户与物品之间的相似度
可视化,可以通过PCA进行可视化
使用近似最近邻查找加速:
- 对于在线服务,有严格的性能要求(几十毫秒)。通过保存用户兴趣embedding和视频兴趣embedding,通过最近邻搜索的方法得到top N的结果
- 代表算法是LSH,局部敏感Hash
Thinking:如何使用LSH进行加速?
在召回阶段,将所有的物品兴趣向量映射到不同的桶内,然后将用户兴趣向量映射到桶内,这样只需要将用户向量和这个桶内的物品向量求内积即可 => 大大减小计算量
预测的类别很大,
如果将视频库中的每一个视频当作一个类别,那么在时刻t,对于用户U和上下文C,用户会观看视频i的概率为
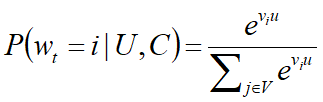
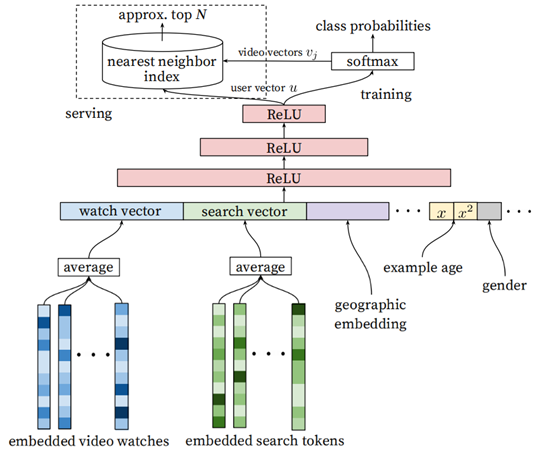
- u是用户的embedding(网络最后一个Relu激活函数的输出)
- vi是视频i的embedding
输入层的embedding分别是用户空间和Video空间的向量,最终的输出层,通过user embedding和全部video embedding矩阵进行点积(全联接层的线性变化),将两者转换到了同一空间,所以对于用户
和视频来说,输出层的embedding是同一空间(可以理解是兴趣空间,二者的内积代表相似性)
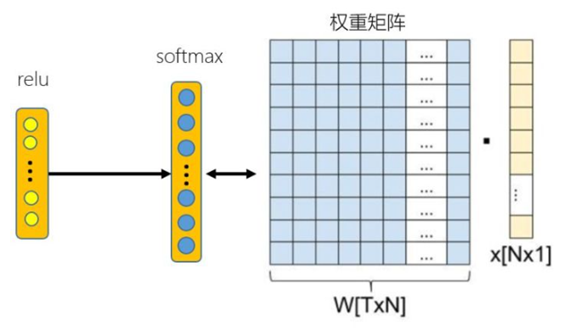
relu输出user embedding
softmax之前进行全连接,全连接层参数W[TXN] 保存了vedio embedding
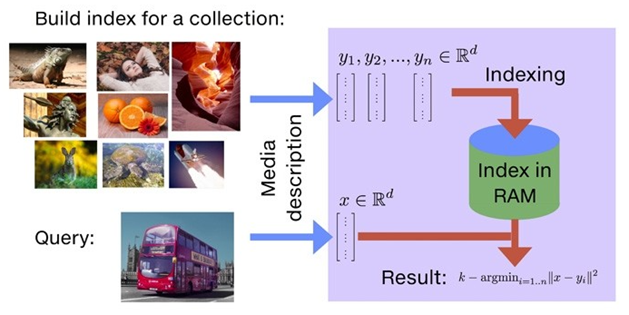
Faiss工具
- FAIR(Facebook AI Research)团队开发的AI相似性搜索工具,处理大规模d维向量近邻检索的问题
- 使用Faiss,Facebook 在十亿级数据集上创建的最邻近搜索(nearest neighbor search),速度提升了 8.5 倍
- Faiss 只支持在 RAM 上搜索
- Faiss 用 C++ 实现,支持 Python
pip install faiss-cpu
pip install faiss-gpu
Faiss使用
- 常用的功能包括:索引Index,PCA降维、PQ乘积量化
- 有两个基础索引类Index、IndexBinary
索引选择:
- 精度高,使用IndexFlatL2,能返回精确结果
- 速度快,使用IndexIVFFlat,首先将数据库向量通过聚类方法分割成若干子类,每个子类用类中心表示,当查询向量来临时,选择距离最近的类中心,然后在子类中应用精确查询方法,通过增加相邻的子类个数提高索引的精确度
- 内存小,使用IndexIVFPQ,可以在聚类的基础上使用PQ乘积量化进行处理
IndexFlatL2
- 不支持自定义id,只能将添加的顺序作为id
- 为向量集构建IndexFlatL2索引,它是最简单的索引类型,只执行强力L2距离搜索
IndexIVFFlat
更快的搜索
IndexIVFPQ
更低的内存占用
import numpy as np import matplotlib.pyplot as plt # 512维,data包含2000个向量,每个向量符合正态分布 d = 512 n_data = 2000 np.random.seed(0) data = [] mu = 3 sigma = 0.1 for i in range(n_data): data.append(np.random.normal(mu, sigma, d)) data = np.array(data).astype('float32') # 查看第6个向量是不是符合正态分布 import matplotlib.pyplot as plt plt.hist(data[5]) plt.show() # 创建查询向量 query = [] n_query = 10 …… for i in range(n_query): query.append(np.random.normal(mu, sigma, d)) query = np.array(query).astype('float32')
import faiss index = faiss.IndexFlatL2(d) # 构建 IndexFlatL2 print(index.is_trained) # False时需要train index.add(data) #添加数据 print(index.ntotal) #index中向量的个数 #精确索引无需训练便可直接查询 k = 10 # 返回结果个数 query_self = data[:5] # 查询自身 dis, ind = index.search(query_self, k) print(dis.shape) # 打印张量 (5, 10) print(ind.shape) # 打印张量 (5, 10) print(dis) # 升序返回每个查询向量的距离 print(ind) # 升序返回每个查询向量 True 2000 (5, 10) (5, 10) [[0. 8.007045 8.313328 8.53525 8.560175 8.561642 8.624167 8.628234 8.709978 8.77004 ] …… [0. 8.346273 8.407202 8.462828 8.49723 8.520801 8.597084 8.600386 8.605133 8.630594]] [[ 0 798 879 223 981 1401 1458 1174 919 26] [ 1 981 1524 1639 1949 1472 1162 923 840 300] [ 2 1886 375 1351 518 1735 1551 1958 390 1695] [ 3 1459 331 389 655 1943 1483 1723 1672 1859] [ 4 13 715 1470 608 459 888 850 1080 1654]]
IndexIVFFlat:
- IndexFlatL2为暴力搜索,速度慢
- IndexIVFFlat的目的是提供更快的搜索,首先将数据库向量通过聚类方法分割成若干子类,每个子类用类中心表示
- IndexIVFFlat需要一个训练的阶段,与另外一个索引quantizer有关,通过quantizer来判断属于哪个cell
- 当进行查询向量计算时,选择距离最近的类中心,然后在子类中应用精确查询方法,通过增加相邻的子类个数提高索引的精确度
- nlist,将数据库向量分割为多少了维诺空间
- quantizer = faiss.IndexFlatL2(d) # 量化器
- index.nprobe,选择n个维诺空间进行索引
- 通过改变nprobe的值,调节速度与精度
nprobe较小时,查询可能会出错,但时间开销很小
nprobe较大时,精度逐渐增大,但时间开销也增加
nprobe=nlist时,等效于IndexFlatL2索引类型。
# IndexIVFFlat快速索引 nlist = 50 # 将数据库向量分割为多少了维诺空间 k = 10 quantizer = faiss.IndexFlatL2(d) # 量化器 # METRIC_L2计算L2距离, 或faiss.METRIC_INNER_PRODUCT计算内积 index = faiss.IndexIVFFlat(quantizer, d, nlist, faiss.METRIC_L2) # 倒排表索引类型需要训练,训练数据集与数据库数据同分布 print(index.is_trained) index.train(data) print(index.is_trained) index.add(data) index.nprobe = 50 # 选择n个维诺空间进行索引 dis, ind = index.search(query, k) print(dis) print(ind) False True [[0. 8.007045 8.313328 8.53525 8.560175 8.561642 8.624167 8.628234 8.709978 8.77004 ] …… [0. 8.346273 8.407202 8.462828 8.49723 8.520801 8.597084 8.600386 8.605133 8.630594]] [[ 0 798 879 223 981 1401 1458 1174 919 26] [ 1 981 1524 1639 1949 1472 1162 923 840 300] [ 2 1886 375 1351 518 1735 1551 1958 390 1695] [ 3 1459 331 389 655 1943 1483 1723 1672 1859] [ 4 13 715 1470 608 459 888 850 1080 1654]]
IndexIVFPQ:
IndexFlatL2和IndexIVFFlat在index中都保存了完整的数据库向量,在数据量非常大的时候会占用太多内存(IndexFlatL2 和 IndexIVFFlat都要存储所有的向量数据)
对于超大规模数据集来说,可能会内存溢出,可以使用IndexIVFPQ索引来压缩向量
采用乘积量化方法(PQ,Product Quantizer,压缩算法)保存原始向量的有损压缩形式,所以查询结果是近似的
nlist,将数据库向量分割为多少了维诺空间
quantizer = faiss.IndexFlatL2(d) # 量化器
index.nprobe,选择n个维诺空间进行索引
通过改变nprobe的值,调节速度与精度
nprobe较小时,查询可能会出错,但时间开销很小
nprobe较大时,精度逐渐增大,但时间开销也增加
nprobe=nlist时,等效于IndexFlatL2索引类型。
# 乘积量化索引 nlist = 50 m = 8 # 列方向划分个数,必须能被d整除 k = 10 quantizer = faiss.IndexFlatL2(d) # 8 表示每个子向量被编码为 8 bits index = faiss.IndexIVFPQ(quantizer, d, nlist, m, 8) index.train(data) index.add(data) index.nprobe = 50 dis, ind = index.search(query_self, k) # 查询自身 print(dis) print(ind) [[4.6366587 5.1525526 5.157734 5.1658154 5.1706343 5.1914454 5.198593 5.225469 5.2277184 5.2284985 ] [0.18771398 4.718711 4.916692 4.927049 4.9375644 4.9418535 4.944034 4.9649167 4.967818 4.9723606 ]] [[ 0 363 9 1552 1667 492 919 119 276 1571] [ 1 704 1955 41 1613 1923 979 1846 1282 321] [ 2 676 1594 482 1637 316 1917 1814 1683 1903] [ 3 1337 1761 1144 1672 608 865 1282 1023 1181] [ 4 1263 578 1144 1545 1400 141 717 493 1381]]
Summary
Embedding
模型学习:Word2Vec与GloVe模型,RNN/CNN/MLP
模型使用:Embedding相似度计算,向量化召回
Faiss工具使用:
IndexFlatL2,精确的搜索
IndexIVFFlat,更快的搜索
IndexIVFPQ,更低的内存占用
Project: 文本抄袭自动检测分析
Thinking 如何进行文本抄袭自动检测:- 预测文章风格是否和自己一致 => 分类算法
- 根据模型预测的结果来对全量文本进行比对,如果数量很大,=> 可以先聚类降维,比如将全部文档自动聚成k=25类
- 文本特征提取 => 计算TF-IDF
- TopN相似 => TF-IDF相似度矩阵中TopN文档
- 编辑距离editdistance => 计算句子或文章之间的编辑距离
原有方法:分类+聚类
使用Embedding相似查找工具Faiss:
- 文本特征提取 => 计算TF-IDF
- 使用Faiss精确查找IndexFlatL2
- 向index添加数据index.add(data)
- 指定cpindex=3352,查找相似的TopN篇文章
现在方法:Faiss向量相似度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号