
基于流行度的推荐
基于流行度的推荐
认知流行度
流行度(Popularity)
- 内容的流行程度,也称之为热度,最常见的是将榜单中热度的内容推荐给用户(微博热搜,TopN商品)
- 基于流行度的推荐是围绕流行度计算产生的推荐模型(不仅是TopN)
- 解决冷启动问题 => 根据流行度来推荐商品的算法,也就是什么内容吸引用户,就给用户推荐什么内容
- 流行度是对商品热度的一种衡量方式,是否对推荐结果有效,还需要具体分析
流行度的衡量:
- 流行度有多种度量的方式,可粗可细
- 一段时间内的:总数Count,相对值Ratio,可能性Possibility
- 某个item被用户反馈的次数,用户热度/用户总数,比如点击率、观看率,完播率
影响流行度的因素:
- 时间因素
- 电影上映的阶段(上映前,前3天,上映中期,尾声)
- 用户使用的时间(早上,中午,晚上)
- 空间因素
- 用户所在的位置,比如某个电影在南方和北方票房的差别,地域属性
- 某个餐厅在不同位置的流行度
- 一个网站不同Banner位置带来的影响
- 社会心理因素
- 一个商品,歌曲是否流行,未必代表它本身质量好坏,与从众心理也有关
- 社会心理学家阿西曾经做过验证从众心理的实验,结果表明测试者中大约有2/3到3/4的人都具有从众行为 => 从众心理是普遍现象
- 个性 VS 群体
- 环境压力,个体容易受到群体的影响,在群体中个性会被淹没,群体思想将会占主导地位
- 经济利益最大化,群体行为采用该群体利益最大化的方式
- 节省分析成本,直接follow群体行为
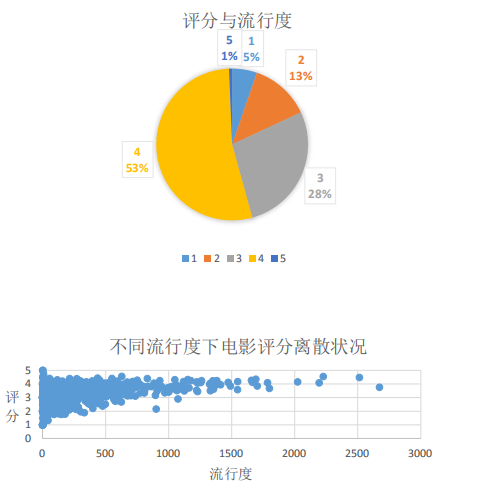
从数据集中了解流行度的趋势:
MovieLens数据集
- 5分和1分所占比例很小,但对于系统来说价值最大
- (Youtube中5分和1分的价值最大)
- 高流行度的item所占比例很小
- 低流行度的item评分差异大(越不流行=>自己的喜好来判断)
- 高流行度的item评分差异小(越流行=>群体的喜好影响力大)
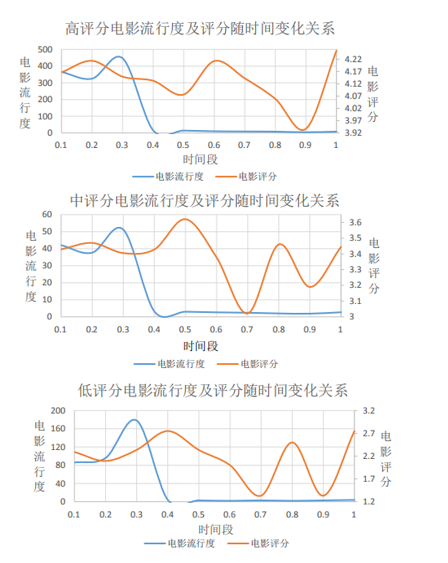
从数据集中了解流行度的趋势:
MovieLens数据集
- 高中低评分的电影,评分随时间变化的趋势相似
- 评分随时间的变化趋势,都是先升高再降低
- => 评分趋势随时间的变化规律很重要
- 高流行度的item,评分波动越小,反之低流行度的item,评分波动大
- => 用户的从众心理
基于流行度的推荐
冷启动问题
- 当用户行为信息不足时,采用非个性化推荐
- 算法本质,什么内容吸引用户,就给用户推荐什么内容
- 也需要有代表性和区分性,即不能太大众化或老少皆宜 => 无法区分用户的兴趣
- 多样性,用户兴趣的可能性很多,为了匹配兴趣的多样性 => 提供具有较高覆盖率的启动item集合(这些物品能覆盖主流的用户兴趣)
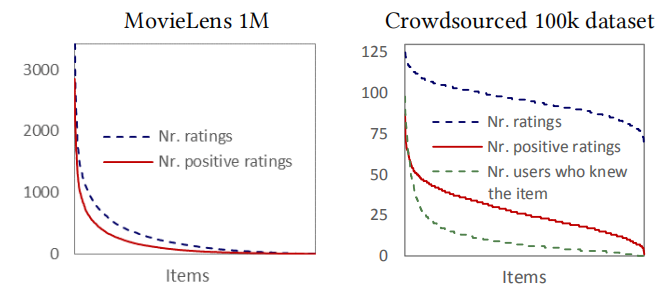
SIGIR 2018最佳论文:Should I Follow the Crowd? A Probabilistic Analysis of the Effectiveness of Popularity in Recommender Systems
http://ir.ii.uam.es/pubs/sigir2018.pdf
- MovieLens,公开数据集
- Crowdsourced 100k,众包数据集,没有公开网站中的常见偏见
- 马太效应=>在Crowdsourced中没有MovieLens中明显
- 长尾理论=>普遍存在。用户的小众需求加起来非常重要
流行度 VS 个性化推荐
- 长尾理论,市场上冷门产品所占据的共同市场份额不低于热门产品所占据的市场份额。因为热门商品需求很高,但数量少。相反,单个冷门商品需求少,但数据量巨大
- 流行度较高的item,较少体现用户个性
- 流行度较低的item,更能代表用户个性(兴趣),计算用户相似度更准确
=> 我们在计算相似度推荐的时候,可以推荐相似度高,但不流行的item
流行度对于用户相似度的计算影响
- 用户之间是否相似,应该考虑共同item的流行度
-
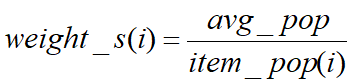
- avg_pop:平均流行度
- item_pop(i):item i的流行度
- 考虑流行度的影响,修正之后的相似度计算
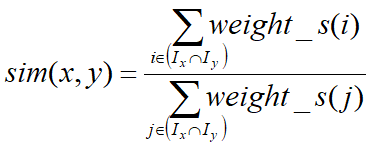
流行度对于推荐结果的影响
- 假设邻居个数取为10,对于某个item A有5个邻居感兴趣,另外item B也有5个邻居感兴趣。此时item A的流行度 >> item B,该优先推荐哪个?
- 推荐度不只与被反馈的次数有关
- 同样引入权重因子,考虑item流行度的影响
- item_pop(i):item i的流行度
- 进行TopN推荐的时候,既考虑反馈次数,也要考虑流行度的降权影响
即 num(i) * weigth_r(i),然后进行TopN推荐
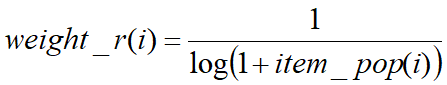
我们需要考虑到推荐系统本身的特性
- 冷启动,数据稀疏性
- Netflix研究表明,新用户在冷启动阶段更倾向于热门排行榜的,老用户会更加需要长尾推荐。
- => 对于新用户,采用非个性化推荐(基于流行度的推荐)
- => 对于老用户,可以考虑高流行度对商品推荐的降权影响,挖掘长尾
- 需要考虑到不同网站的特性
- 电商网站,比如唯品会特卖,目标是打造爆款
- 婚恋网站,比如世纪佳缘,目标是让更多人活跃起来
- 我们需要考虑到推荐系统本身的特性
- 脆弱性
- 只要有利益,就会有作弊的可能性
- 协同过滤的原理是挖掘相似的用户,通过他们的行为进行推荐。
- 是否会存在:虚假恶意的行为,故意增加或者压制某些item被推荐的可能性
- SEO优化 or 降权
- 推荐系统的效果评估
- 评价的指标包括了精准率,多样性,新颖度,覆盖率。需要结合具体的目标来进行使用
- 基于流行度的推荐 => 信息茧房

 浙公网安备 33010602011771号
浙公网安备 33010602011771号