
基于内容的推荐| 基于协同过滤
推荐算法
在用户对自己需求相对明确的时候,可以用搜索引擎通过关键字搜索很方便地找到自己需要的信息。但有些时候,搜索引擎并不能完全满足用户对信息发现的需求。一方面,用户有时候其实对自己的需
求并不明确,期望系统能主动推荐一些自己感兴趣的内容或商品;另一方面,企业也希望能够通过更多渠道向用户推荐信息和商品,在改善用户体验的同时,提高成交转化率,获得更多营收。而这中间
发现用户兴趣和喜好的就是推荐引擎。
在豆瓣中打开电影《肖申克的救赎》的页面,你会发现这个页面还会推荐一些其他电影。如果你喜欢《肖申克的救赎》,那么有很大概率你也会喜欢下面这些电影,这就是推荐引擎发挥的作用。
推荐引擎的思想其实很早就存在了,后来随着大数据技术的发展,推荐引擎的普及程度和重要性也越来越高,淘宝曾经就主推“千人千面”,要让每个用户打开的淘宝都不一样,背后的核心技术就是推荐引
擎。现在稍有规模的互联网应用几乎都有推荐功能,而一些新兴崛起的互联网产品,推荐功能甚至是其核心产品特点与竞争优势,比如今日头条,就是靠智能推荐颠覆了互联网新闻资讯领域。
那么推荐引擎如何预测用户的喜好,进行正确的推荐呢?
主要就是依靠各种推荐算法,常用的推荐算法有:基于人口统计的推荐、基于商品属性的推荐、基于用户的协同过滤推荐、基于商品的协同过滤推荐。
除了这些推荐算法,还有基于模型的推荐,根据用户和商品数据,训练数学模型,然后进行推荐。前面我们讨论过的关联分析,也可以进行推荐。在实践中,通常会混合应用多种算法进行推荐,特别是
大型电商网站,推荐效果每进步一点,都可能会带来巨大的营收转化,
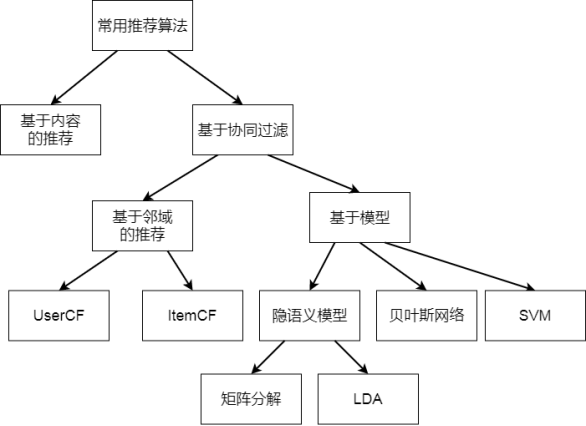
协同过滤是推荐系统的主流思想之一:
- 基于邻域的协同过滤
- UserCF
- ItemCF
- 基于模型的协同过滤
- 隐语义模型(LFM, Latent Factor Model)
- 矩阵分解(MF)
- LDA, LSA, pLSA
- 基于贝叶斯网络
- 基于SVM
- 隐语义模型(LFM, Latent Factor Model)
基于人口统计的推荐
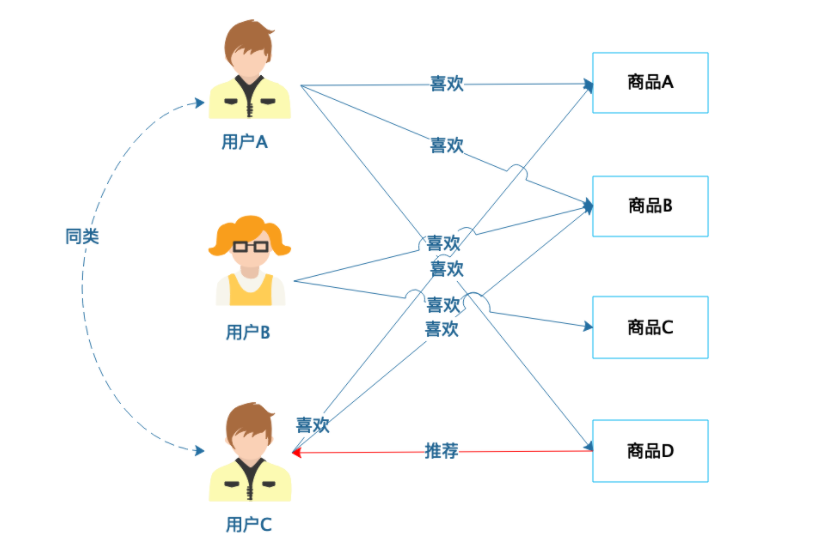
基于人口统计的推荐是相对比较简单的一种推荐算法,根据用户的基本信息进行分类,然后将商品推荐给同类用户。

从图中可以看到,用户 A 和用户 C 有相近的人口统计信息,划分为同类,那么用户 A 喜欢(购买过)的商品 D 就可以推荐给用户 C。基于人口统计的推荐比较简单,只要有用户的基本信息就可以进行
分类,新注册的用户总可以分类到某一类别,那么立即就可以对他进行推荐,没有所谓的“冷启动”问题,也就是不会因为不知道用户的历史行为数据而不知道该如何向用户推荐。
而且这种推荐算法也不依赖商品的数据,和要推荐的领域无关,不管是服装还是美食,不管是电影还是旅游目的地,都可以进行推荐,甚至可以混杂在一起进行推荐。
当然也正因为这种推荐算法比较简单,对于稍微精细一点的场景,推荐效果就比较差了。因此,在人口统计信息的基础上,根据用户浏览、购买信息和其他相关信息,进一步细化用户的分类信息,给用
户贴上更多的标签,比如家庭成员、婚姻状况、居住地、学历、专业、工作等,即所谓的用户画像,根据用户画像进行更精细的推荐,并进一步把用户喜好当做标签完善用户画像,再利用更完善的用户
画像进行推荐,如此不断迭代优化用户画像和推荐质量。
基于商品属性的推荐
前面一个算法是基于用户的属性进行分类,然后根据同类用户的行为进行推荐。而基于商品属性的推荐则是将商品的属性进行分类,然后根据用户的历史行为进行推荐。

从图中可以看到,电影 A 和电影 D 有相似的属性,被划分为同类商品,如果用户 A 喜欢电影 A,那么就可以向用户 A 推荐电影 D,比如给喜欢《星球大战》的用户推荐《星际迷航》。一般来说,相对于
基于人口统计的推荐,基于商品属性的推荐会更符合用户的口味,推荐效果相对更好一点。
但是基于商品属性的推荐需要对商品属性进行全面的分析和建模,难度相对也更大一点,在实践中,一种简单的做法是提取商品描述的关键词和商品的标签作为商品的属性。此外,基于商品属性的推荐
依赖用户的历史行为数据,如果是新用户进来,没有历史数据,就没有办法进行推荐了,即存在“冷启动”问题。
1. 基于内容的推荐
基于内容的推荐:
依赖性低,不需要动态的用户行为,只要有内容就可以进行推荐
系统不同阶段都可以应用
系统冷启动,内容是任何系统天生的属性,可以从中挖掘到特征,实现推荐系统的冷启动。一个复杂的推荐系统是从基于内容的推荐成长起来的
商品冷启动,不论什么阶段,总会有新的物品加入,这时只要有内容信息,就可以帮它进行推荐

物品表示 Item Representation:
为每个item抽取出features
特征学习Profile Learning:
利用一个用户过去喜欢(不喜欢)的item的特征数据,来学习该用户的喜好特征(profile);
生成推荐列表Recommendation Generation:
通过用户profile与候选item的特征,推荐相关性最大的item。
案例-为酒店建立内容推荐系统
西雅图酒店数据集:
下载地址:https://github.com/susanli2016/Machine-Learning-with-Python/blob/master/Seattle_Hotels.csv
字段:name, address, desc
基于用户选择的酒店,推荐相似度高的Top10个其他酒店
方法:计算当前酒店特征向量与整个酒店特征矩阵的余弦相似度,取相似度最大的Top-k个
余弦相似度
通过测量两个向量的夹角的余弦值来度量它们之间的相似性。
判断两个向量⼤致方向是否相同,方向相同时,余弦相似度为1;两个向量夹角为90°时,余弦相似度的值为0,方向完全相反时,余弦相似度的值为-1。
两个向量之间夹角的余弦值为[-1, 1]
给定属性向量A和B,A和B之间的夹角θ余弦值可以通过点积和向量长度计算得出
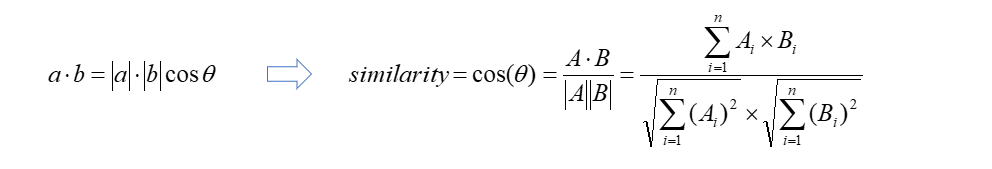
计算A和B的余弦相似度:
句子A:这个程序代码太乱,那个代码规范
句子B:这个程序代码不规范,那个更规范
- Step1,分词
- 句子A:这个/程序/代码/太乱,那个/代码/规范
- 句子B:这个/程序/代码/不/规范,那个/更/规范
- Step2,列出所有的词
- 这个,程序,代码,太乱,那个,规范,不,更
- Step3,计算词频
- 句子A:这个1,程序1,代码2,太乱1,那个1,规范1,不0,更0
- 句子B:这个1,程序1,代码1,太乱0,那个1,规范2,不1,更1
- Step4,计算词频向量的余弦相似度
- 句子A: (1, 1, 2, 1, 1, 1, 0, 0)
- 句子B: (1, 1, 1, 0, 1, 2, 1, 1)
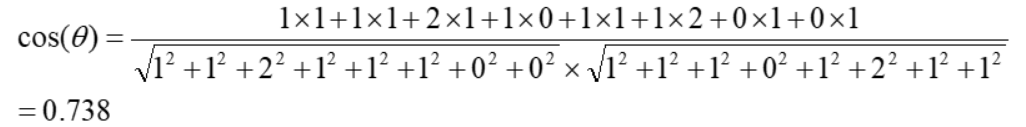
结果接近1,说明句子A和句子B是相似的;
什么是N-Gram(N元语法)
基于一个假设:第n个词出现与前n-1个词相关,而与其他任何词不相关.
N=1时为unigram,N=2为bigram,N=3为trigram
N-Gram指的是给定一段文本,其中的N个item的序列
比如文本:A B C D E,对应的Bi-Gram为A B, B C, C D, D E
当一阶特征不够用时,可以用N-Gram做为新的特征。比如在处理文本特征时,一个关键词是一个特征,但有些情况不够用,需要提取更多的特征,采用N-Gram => 可以理解是相邻两个关键词的特征组合
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 df = pd.read_csv('Seattle_Hotels.csv', encoding="latin-1") # 得到酒店描述中n-gram特征中的TopK个 def get_top_n_words(corpus, n=1, k=None): # 统计ngram词频矩阵 vec = CountVectorizer(ngram_range=(n, n), stop_words='english').fit(corpus) bag_of_words = vec.transform(corpus) sum_words = bag_of_words.sum(axis=0) words_freq = [(word, sum_words[0, idx]) for word, idx in vec.vocabulary_.items()] # 按照词频从大到小排序 words_freq =sorted(words_freq, key = lambda x: x[1], reverse=True) return words_freq[:k] common_words = get_top_n_words(df['desc'], 1, 20) df1 = pd.DataFrame(common_words, columns = ['desc' , 'count']) df1.groupby('desc').sum()['count'].sort_values().plot(kind='barh', title='去掉停用词后,酒店描述中的Top20单词') plt.show() # Bi-Gram common_words = get_top_n_words(df['desc'], 2, 20) # Tri-Gram common_words = get_top_n_words(df['desc'], 3, 20) def clean_text(text): # 全部小写 text = text.lower() …… return text df['desc_clean'] = df['desc'].apply(clean_text) # 使用TF-IDF提取文本特征 tf = TfidfVectorizer(analyzer='word', ngram_range=(1, 3), min_df=0, stop_words='english') tfidf_matrix = tf.fit_transform(df['desc_clean']) print(tfidf_matrix) print(tfidf_matrix.shape) # 计算酒店之间的余弦相似度(线性核函数) cosine_similarities = linear_kernel(tfidf_matrix, tfidf_matrix) print(cosine_similarities) # 基于相似度矩阵和指定的酒店name,推荐TOP10酒店 def recommendations(name, cosine_similarities = cosine_similarities): recommended_hotels = [] # 找到想要查询酒店名称的idx idx = indices[indices == name].index[0] print('idx=', idx) # 对于idx酒店的余弦相似度向量按照从大到小进行排序 score_series = pd.Series(cosine_similarities[idx]).sort_values(ascending = False) # 取相似度最大的前10个(除了自己以外) top_10_indexes = list(score_series.iloc[1:11].index) # 放到推荐列表中 for i in top_10_indexes: recommended_hotels.append(list(df.index)[i]) return recommended_hotels print(recommendations('Hilton Seattle Airport & Conference Center')) print(recommendations('The Bacon Mansion Bed and Breakfast'))
CountVectorizer:
将文本中的词语转换为词频矩阵
fit_transform:计算各个词语出现的次数
get_feature_names:可获得所有文本的关键词
toarray():查看词频矩阵的结果。
TF-IDF
TF:Term Frequency,词频 TF = 单词次数 / 文档中总单词数
一个单词的重要性和它在文档中出现的次数呈正比。
IDF:Inverse Document Frequency,逆向文档频率
一个单词在文档中的区分度。这个单词出现的文档数越少,区分度越大,IDF越大
IDF = log (文档总数/ (单词出现的文档数+1) )
TfidfVectorizer:
将文档集合转化为tf-idf特征值的矩阵
构造函数
analyzer:word或者char,即定义特征为词(word)或n-gram字符
ngram_range: 参数为二元组(min_n, max_n),即要提取的n-gram的下限和上限范围
max_df:最大词频,数值为小数[0.0, 1.0],或者是整数,默认为1.0
min_df:最小词频,数值为小数[0.0, 1.0],或者是整数,默认为1.0
stop_words:停用词,数据类型为列表
功能函数:
fit_transform:进行tf-idf训练,学习到一个字典,并返回Document-term的矩阵,也就是词典中的词在该文档中出现的频次
基于内容的推荐:
Step1,对酒店描述(Desc)进行特征提取
N-Gram,提取N个连续字的集合,作为特征
TF-IDF,按照(min_df, max_df)提取关键词,并生成TFIDF矩阵
Step2,计算酒店之间的相似度矩阵
余弦相似度
Step3,对于指定的酒店,选择相似度最大的Top-K个酒店进行输出
Word Embedding
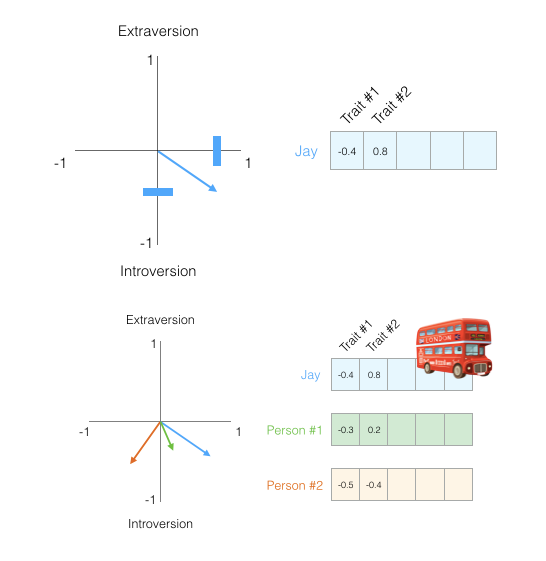
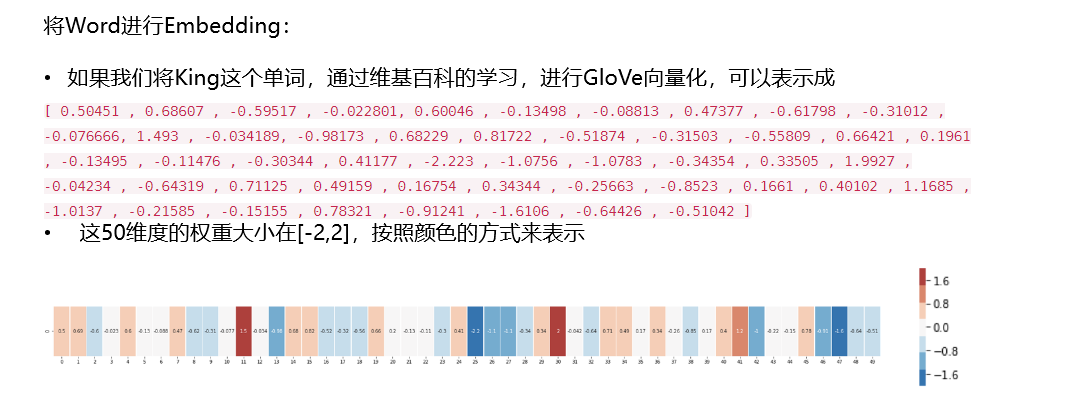
什么是Embedding:
一种降维方式,将不同特征转换为维度相同的向量
离线变量转换成one-hot => 维度非常高,可以将它转换为固定size的embedding向量
任何物体,都可以将它转换成为向量的形式,从Trait #1到 #N
向量之间,可以使用相似度进行计算
当我们进行推荐的时候,可以选择相似度最大的
Word2Vec
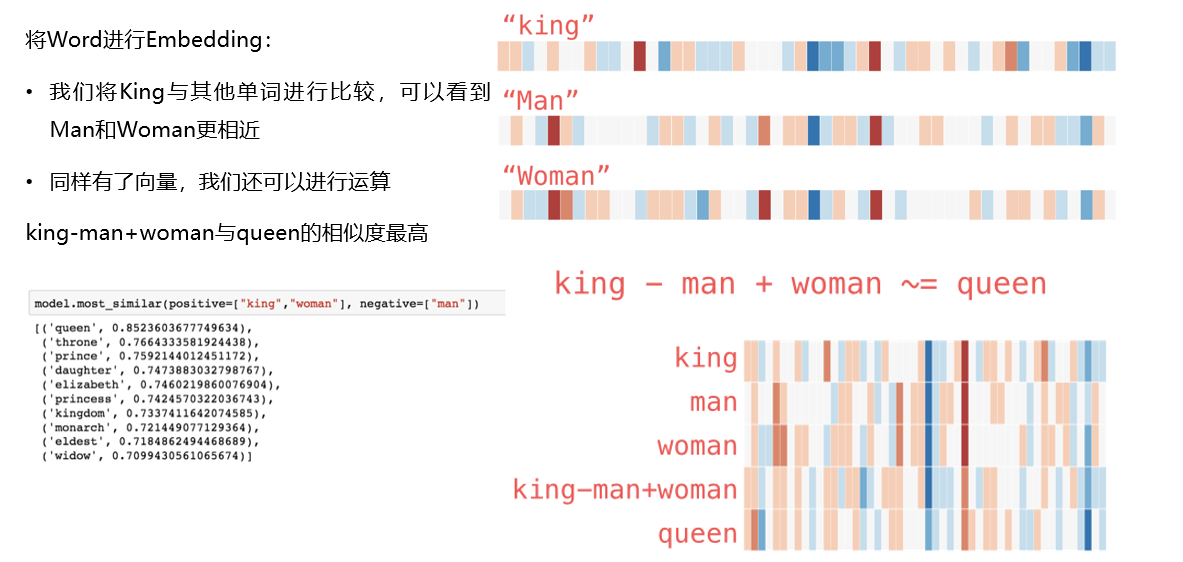
通过Embedding,把原先词所在空间映射到一个新的空间中去,使得语义上相似的单词在该空间内距离相近。
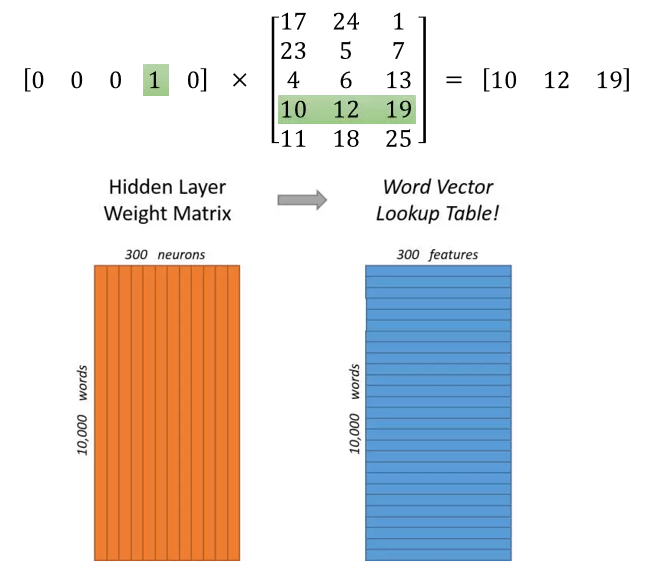
Word Embedding => 学习隐藏层的权重矩阵
输入测是one-hot编码
隐藏层的神经元数量为hidden_size(Embedding Size)
对于输入层和隐藏层之间的权值矩阵W,大小为[vocab_size, hidden_size]
输出层为[vocab_size]大小的向量,每一个值代表着输出一个词的概率

对于输入的one-hot编码:
在矩阵相乘的时候,选取出矩阵中的某一行,而这一行就是输入词语的word2vec表示
隐含层的节点个数 = 词向量的维数
隐层的输出是每个输入单词的Word Embedding
word2vec,实际上就是一个查找表
word2vec工具
Gensim工具
- pip install gensim
- 开源的Python工具包
- 可以从非结构化文本中,无监督地学习到隐层的主题向量表达
- 每一个向量变换的操作都对应着一个主题模型
- 支持TF-IDF,LDA, LSA, word2vec等多种主题模型算法
使用方法:
- 建立词向量模型:word2vec.Word2Vec(sentences)
- window,句子中当前单词和被预测单词的最大距离
- min_count,需要训练词语的最小出现次数,默认为5
- size,向量维度,默认为100
- worker,训练使用的线程数,默认为1即不使用多线程
- 模型保存 model.save(fname)
- 模型加载 model.load(fname)
数据集:西游记
journey_to_the_west.txt
计算小说中的人物相似度,比如孙悟空与猪八戒,孙悟空与孙行者
方案步骤:
- Step1,使用分词工具进行分词,比如NLTK,JIEBA
- Step2,将训练语料转化成一个sentence的迭代器
- Step3,使用word2vec进行训练
- Step4,计算两个单词的相似度
# 字词分割,对整个文件内容进行字词分割 def segment_lines(file_list,segment_out_dir,stopwords=[]): for i,file in enumerate(file_list): segment_out_name=os.path.join(segment_out_dir,'segment_{}.txt'.format(i)) with open(file, 'rb') as f: document = f.read() document_cut = jieba.cut(document) sentence_segment=[] for word in document_cut: if word not in stopwords: sentence_segment.append(word) result = ' '.join(sentence_segment) result = result.encode('utf-8') with open(segment_out_name, 'wb') as f2: f2.write(result) # 对source中的txt文件进行分词,输出到segment目录中 file_list=files_processing.get_files_list('./source', postfix='*.txt') segment_lines(file_list, './segment') # 将Word转换成Vec,然后计算相似度 from gensim.models import word2vec import multiprocessing # 如果目录中有多个文件,可以使用PathLineSentences sentences = word2vec.PathLineSentences('./segment') # 设置模型参数,进行训练 model = word2vec.Word2Vec(sentences, size=100, window=3, min_count=1) print(model.wv.similarity('孙悟空', '猪八戒')) print(model.wv.similarity('孙悟空', '孙行者')) # 设置模型参数,进行训练 model2 = word2vec.Word2Vec(sentences, size=128, window=5, min_count=5, workers=multiprocessing.cpu_count()) # 保存模型 model2.save('./models/word2Vec.model') print(model2.wv.similarity('孙悟空', '猪八戒')) print(model2.wv.similarity('孙悟空', '孙行者')) print(model2.wv.most_similar(positive=['孙悟空', '唐僧'], negative=['孙行者']))
Summary
基于内容的推荐:
- 将你看的item,相似的item推荐给你
- 通过物品表示Item Representation => 抽取特征
- TF-IDF => 返回给某个文本的“关键词-TFIDF值”的词数对
- TF-IDF可以帮我们抽取文本的重要特征,做成item embedding
- 计算item之间的相似度矩阵
- 对于指定的item,选择相似度最大的Top-K个进行输出
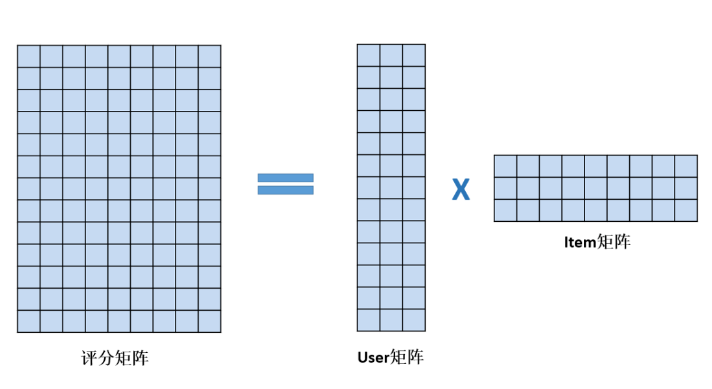
Embedding的理解:
Embedding指某个对象 X 被嵌入到另外一个对象Y中,映射 f : X → Y
一种降维方式,转换为维度相同的向量
矩阵分解中的User矩阵,第i行可以看成是第i个user的Embedding。Item矩阵中的第j列可以看成是对第j个Item的Embedding
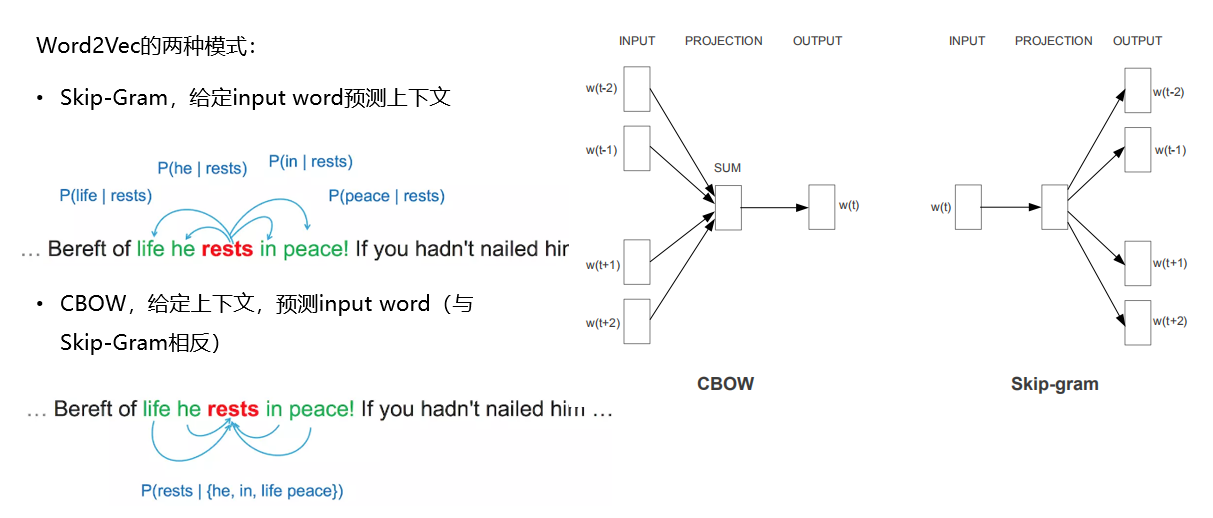
Word2Vec工具的使用:
- Word Embedding就是将Word嵌入到一个数学空间里,Word2vec,就是词嵌入的一种
- 可以将sentence中的word转换为固定大小的向量表达(Vector Respresentations),
- 其中意义相近的词将被映射到向量空间中相近的位置。
- 将待解决的问题转换成为单词word和文章doc的对应关系
- 大V推荐中,大V => 单词,将每一个用户关注大V的顺序 => 文章
- 商品推荐中,商品 => 单词,用户对商品的行为顺序 => 文章
2. 基于邻域的协同过滤
协同过滤是推荐系统的经典算法之一
基于邻域的协同过滤(neighborhood-based)
UserCF:给用户推荐和他兴趣相似的其他用户喜欢的物品
ItemCF:给用户推荐和他之前喜欢的物品相似的物品
相似的邻居
- 固定数量的邻居K-neighborhoods
- 不论距离原理,只取固定的K个最近的邻居
- k-Nearest Neighbor,KNN
- 基于相似度门槛的邻居,落在以当前点为中心,距离为 K 的区域中的所有点都作为邻居

基于用户相似度,与基于物品相似度的区别:
- 于用户相似度是基于评分矩阵中的行向量相似度求解
- 基于项目相似度计算式基于评分矩阵中列向量相似度求解
基于用户的协同过滤(UserCF)
基于用户的协同过滤推荐是根据用户的喜好进行用户分类,常用的即 KNN 算法,寻找和当前用户喜好最相近的 K 个用户,然后根据这些用户的喜好为当前用户进行推荐。
从图中可以看到,用户 A 喜欢商品 A、商品 B 和商品 D,用户 C 喜欢商品 A 和商品 B,那么用户 A 和用户 C 就有相似的喜好,可以归为一类,然后将用户 A 喜欢的商品 D 推荐给用户 C。
基于用户的协同过滤推荐和基于人口统计的推荐都是将用户分类后,根据同类用户的喜好为当前用户进行推荐。不同的是,基于人口统计的推荐仅仅根据用户的个人信息进行分类,分类的粒度比较大,
准确性也较差;而基于用户的协同过滤推荐则根据用户历史喜好进行分类,能够更准确地反映用户的喜好类别,推荐效果也更好一点。今天文章开头举的推荐电影的例子,就是基于用户的协同过滤进行
推荐。
-
利用行为的相似度计算用户的相似度
-
Step1,找到和目标用户兴趣相似的用户集合 (通过相似度找邻居)
-
Jaccard相似度计算,N(u),N(v)分别代表用户u和用户v有过正反馈的物品集合
-
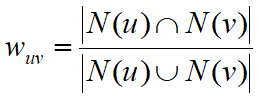
-
- 余弦相似度
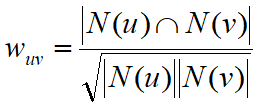
-
- 改进的相似度,基于流行度改进的相似度计算,通过 1/ log(1+|N(i)|) 惩罚了热门物品对相似度的影响力
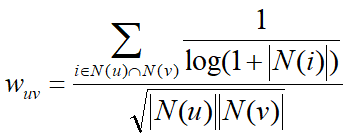
- Step2,用户u对物品i的相似度,等价于K个邻居对物品i的兴趣度

- Step3,为用户u生成推荐列表
- 把和用户兴趣相同的k个邻居,喜欢的物品进行汇总,去掉用户u已经喜欢过的物品,剩下按照从大到小进行推荐
基于物品的协同过滤(ItemCF)
基于商品的协同过滤推荐是根据用户的喜好对商品进行分类,如果两个商品,喜欢它们的用户具有较高的重叠性,就认为它们的距离相近,划分为同类商品,然后进行推荐。
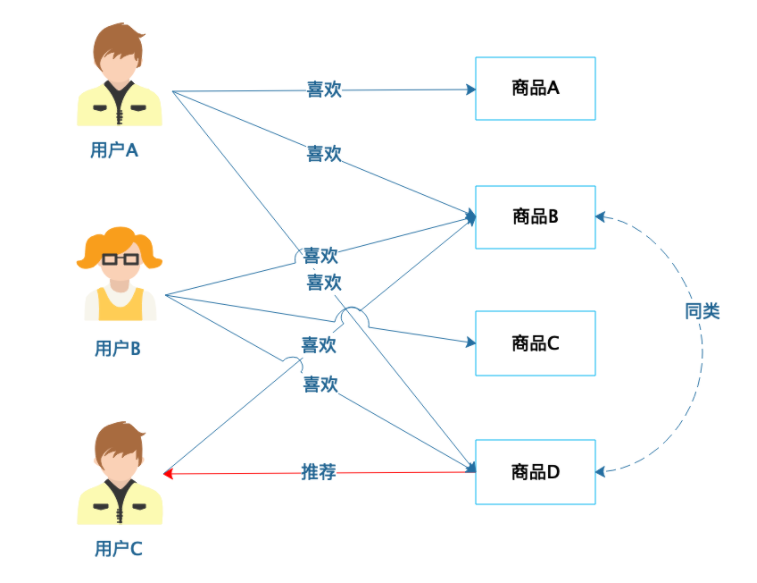
从图中可以看到,用户 A 喜欢商品 A、商品 B 和商品 D,用户 B 喜欢商品 B、商品 C 和商品 D,那么商品 B 和商品 D 的距离最近,划分为同类商品;而用户 C 喜欢商品 B,那么就可以为其推荐商品
D。商品的分类相对用户的分类更为稳定,通常情况下,商品的数目也少于用户的数目,因此使用基于商品的协同过滤推荐,计算量和复杂度小于基于用户的协同过滤推荐。
利用行为的相似度计算物品的相似度
- Step1,计算物品之间相似度
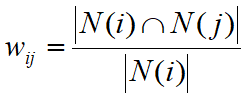
N(i),喜欢物品i的用户数
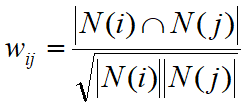
如果N(j)过大,说明j是热门物品很多人都喜欢
需要对N(j)进行惩罚,避免推荐热门物品
- Step2,用户u对物品i的兴趣度,等价于物品i的K个邻居物品,受到用户u的兴趣度

- Step3,为用户u生成推荐列表
- 和用户历史上感兴趣的物品越相似的物品,越有可能在用户的推荐列表中获得比较高的排名
- 预测用户u对物品的兴趣度,去掉用户u已经喜欢过的物品,剩下按照从大到小进行推荐
Surprise工具
https://surprise.readthedocs.io/en/stable/prediction_algorithms_package.html
基于邻域的协同过滤算法
- knns.KNNBasic
- knns.KNNWithMeans
- knns.KNNWithZScore
- knns.KNNBaseline

knns.KNNBasic
- k,邻域的个数 默认为40
- sim_options设置邻域参数,包括:
- user_based,是否为基于用户的协同过滤,默认为True,也可以设置为False
- name,相似度计算方式,默认为MSD,也可设置为cosine,pearson,pearson_baseline
- min_support,最小支持度,对用户或者商品进行筛选
- shrinkage:收缩参数(仅与Pearson correlation相似度相关)。 默认值为100


knns.KNNBasicWithMeans
- k,邻域的个数 默认为40
- sim_options设置邻域参数,包括:
- user_based,是否为基于用户的协同过滤,默认为True,也可以设置为False
- name,相似度计算方式,默认为MSD,也可设置为cosine,pearson,pearson_baseline
- min_support,最小支持度,对用户或者商品进行筛选
- shrinkage:收缩参数(仅与Pearson correlation相似度相关)。 默认值为100

knns.KNNBasicWithZScore
- k,邻域的个数 默认为40
- sim_options设置邻域参数,包括:
- user_based,是否为基于用户的协同过滤,默认为True,也可以设置为False
- name,相似度计算方式,默认为MSD,也可设置为cosine,pearson,pearson_baseline
- min_support,最小支持度,对用户或者商品进行筛选
- shrinkage:收缩参数(仅与Pearson correlation相似度相关)。 默认值为100

knns.KNNBaseline
- k,邻域的个数 默认为40
- sim_options设置邻域参数,包括:
- user_based,是否为基于用户的协同过滤,默认为True,也可以设置为False
- name,相似度计算,推荐使用pearson_baseline
- bsl_options,baseline优化方式,可以设置SGD,ALS等优化算法
- min_support,最小支持度,对用户或者商品进行筛选
- shrinkage:收缩参数(仅与Pearson correlation相似度相关)。 默认值为100

Baseline算法
ALS和SGD作为优化方法,应用于很多优化问题
Factor in the Neighbors: Scalable and Accurate Collaborative Filtering,ACM Transactions on Knowledge Discovery from Data, 2010
Baseline算法:基于统计的基准预测线打分
- bui 预测值
- bu 用户对整体的偏差
- bi 商品对整体的偏差
Baseline算法
使用ALS进行优化
- Step1,固定bu,优化bi
- Step2,固定bi,优化bu
from surprise import KNNWithMeans from surprise import Dataset, Reader # 数据读取 reader = Reader(line_format='user item rating timestamp', sep=',', skip_lines=1) data = Dataset.load_from_file('./ratings.csv', reader=reader) trainset = data.build_full_trainset() # UserCF 计算得分 algo = KNNWithMeans(k=50, sim_options={'user_based': True}) algo.fit(trainset) uid = str(196) iid = str(302) pred = algo.predict(uid, iid) print(pred) from surprise import KNNWithMeans from surprise import Dataset, Reader # 数据读取 reader = Reader(line_format='user item rating timestamp', sep=',', skip_lines=1) data = Dataset.load_from_file('./ratings.csv', reader=reader) trainset = data.build_full_trainset() # ItemCF 计算得分 # 取最相似的用户计算时,只取最相似的k个 algo = KNNWithMeans(k=50, sim_options={'user_based': False, 'name': 'cosine'}) algo.fit(trainset) uid = str(196) iid = str(302) pred = algo.predict(uid, iid) print(pred)
Summary
基于邻域的协同过滤:
- 方法直接,容易实现,可解释性好
- 邻域方法可以在离线预先计算近邻,通过预先计算好的相似矩阵找出k近邻后就可以对item评分进行预测,推荐过程的实时性强
- 邻居数K是重要参数,k可以通过交叉验证来选择,通常k的取值在20到50之间
- 当用户数和item数巨大时,保存所有的相似度需要大量的存储空间。可以提前进行过滤,去掉不重要的相似度信息(Top-N过滤,阈值过滤,负值过滤)
- 冷启动问题,新的user和item找k近邻需要借助其他方法
- 稀疏问题,当评分矩阵很稀疏时,两个用户共同评分的项会很少,使得预测结果偏差较大。
UserCF与ItemCF
- UserCF: 推荐和当前用户相似度高的N个用户产生过行为的物品给当前用户
- ItemCF: 推荐和当前用户历史上行为过的物品相似的物品给当前用户(可解释性强)
- 用户数远大于物品数时,使用采用ItemCF;用户数少于物品数时,使用UserCF更准确
- 如果物品列表经常变换,那么采用UserCF更准确;如果物品列表相对于用户更稳定,那么采用ItemCF
- 在冷启动阶段,UserCF对于新加入的物品能很快进入推荐列表,ItemCF对新加入的用户可以很快进行推荐
Thinking1:在推荐系统中,FM和MF哪个应用的更多,为什么
Thinking2:FFM与FM有哪些区别?
Thinking3:DeepFM相比于FM解决了哪些问题,原理是怎样的
Thinking4:Surprise工具中的baseline算法原理是怎样的?BaselineOnly和KNNBaseline有什么区别?
Thinking5:基于邻域的协同过滤都有哪些算法,请简述原理
Action1:使用libfm工具对movielens进行评分预测,采用SGD优化算法
Action2:使用DeepFM对movielens进行评分预测
Action3:使用基于邻域的协同过滤(KNNBasic, KNNWithMeans, KNNWithZScore, KNNBaseline中的任意一种)对MovieLens数据集进行协同过滤,采用k折交叉验证(k=3),输出每次计算的RMSE,
MAE

 浙公网安备 33010602011771号
浙公网安备 33010602011771号