
用户画像
用户画像
假设你是个产品经理,如何定义用户画像
你是算法工程师,如何使用标签来做推荐

我们已经进入到互联网的下半场,增长的动力来自数据驱动
而数据分析的出发点,来自于对用户行为及需求的洞察
用户画像的准则
假设一个场景,你刚入职一家火锅店,你的老板对你说给用户做用户画像,你会怎么办?
我们需要解决三个问题:
- 都是谁
- 从哪来
- 到哪去
如果你来设计用户标签,都会考虑哪些维度?
Step1、统一标识
用户唯一标识是整个用户画像的核心
Step2、给用户打标签
用户标签的4个维度
Step3、基于标签指导业务
业务赋能的3个阶段
用户标签
用户标签都有哪些维度?
八字原则:用户消费行为分析
用户标签:性别、年龄、地域、收入、学历、职业等
消费标签:消费习惯、购买意向、是否对促销敏感
行为标签:时间段、频次、时长、收藏、点击、喜欢、评分
(User Behavior可以分成Explicit Behavior和Implicit Behavior)
内容分析:对用户平时浏览的内容进行分析,比如体育、游戏、八卦
如何使用这些标签来指导业务?
用户生命周期的三个阶段
- 获客:如何进行拉新,通过更精准的营销获取客户;
- 粘客:个性化推荐,搜索排序,场景运营等;
- 留客:流失率预测,分析关键节点降低流失率。
按照数据流处理阶段划分
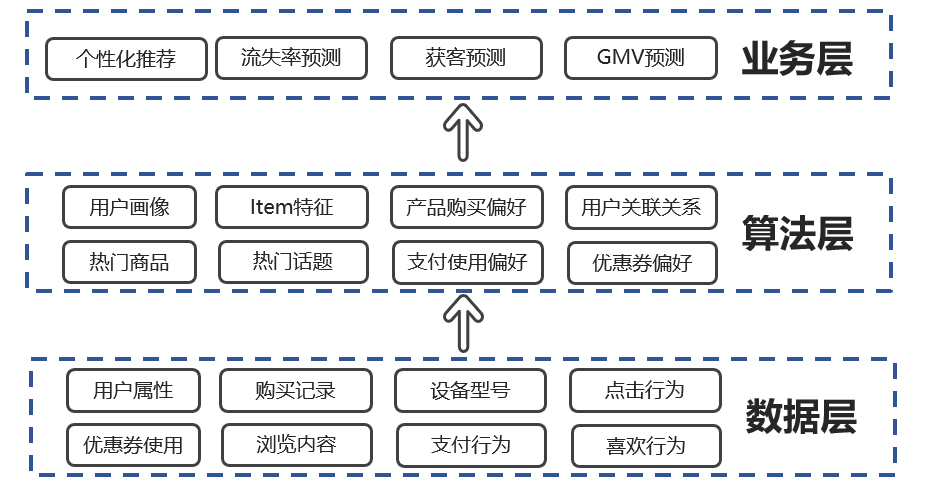
标签从何而来:
典型的方式有:
PGC:专家生产
UGC:普通生产
标签是对高维事物的抽象(降维)
聚类算法:K-Means,EM聚类,Mean-Shift,DBSCAN,层次聚类,PCA
现在你是一名算法工程师,你将面对:
如何对大量的数据需要标注(打标签)
如何利用用户标签,对商品进行推荐(推荐算法)
聚类算法
kmeans
KMeans:
Step1, 选取K个点作为初始的类中心点,这些点一般都是从数据集中随机抽取的;
Step2, 将每个点分配到最近的类中心点,这样就形成了K个类,然后重新计算每个类的中心点;
重复Step2,直到类不发生变化,或者你也可以设置最大迭代次数,这样即使类中心点发生变化,但是只要达到最大迭代次数就会结束
EM
Thinking:你炒了一份菜,想要把它平均分到两个碟子里,该怎么分?
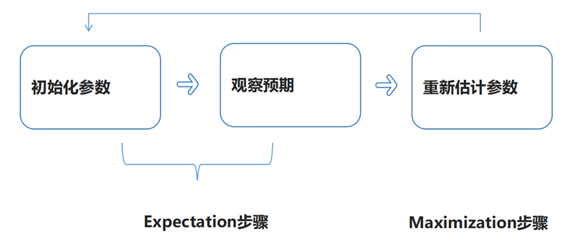
- 主要步骤:初始化参数、观察预期、重新估计
- 首先是先给每个碟子初始化一些菜量,然后再观察预期,这两个步骤实际上就是期望步骤(Expectation)
- 如果结果存在偏差就需要重新估计参数,这个就是最大化步骤(Maximization)
E通过观察评估,M是调整;
最大似然:
Maximum Likelihood,最大似然也就是最大可能性
Thinking:有一男一女两个同学,现在要对他俩进行身高的比较,谁会更高呢?
(男同学高的可能性会很大 => 使用最大似然的概念)
最大似然估计,指的就是一件事情已经发生了,然后反推更有可能是什么因素造成的,假设有一个人比另一个人高,反推他可能是男性
最大似然估计是一种通过已知结果,估计参数的方法
EM算法:
一种求解最大似然估计的方法,通过观测样本,来找出样本的模型参数
通过EM算法中的E步来进行观察,然后通过M步来进行调整A和B的参数,最后让碟子A和碟子B的参数不再发生变化为止
EM算法:
假设我们有A和B两枚硬币,我们做了5组实验,每组实验投掷10次,然后统计出现正面的次数(投掷硬币时,我们不知道投掷的硬币是A还是B)
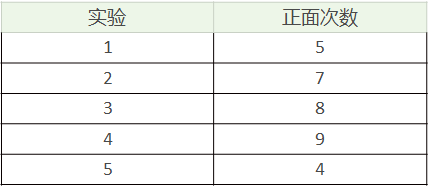
假设我们知道这个隐含的数据:
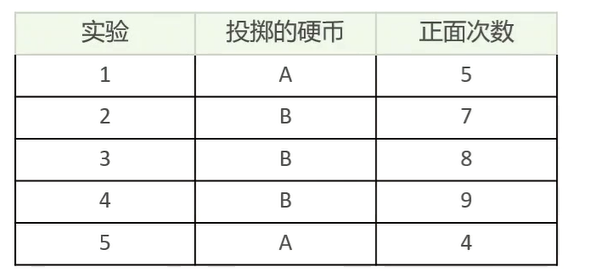
想要求得硬币A和B出现正面次数的概率,直接求得

Thinking:不知道每次投掷的硬币是A还是B,如何求得硬币A和硬币B出现正面的概率呢?
Step1,初始化参数,假设硬币A和B的正面概率(随机指定)分别为θA=0.5和θB=0.9。
Step2,计算期望值,如果实验1投掷的是硬币A,那么正面次数为5的概率为
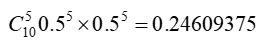
如果投掷的硬币B ,概率为
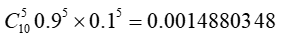
所以实验1更有可能投掷的是硬币A,对实验2~5重复这个计算过程,推理出来硬币顺序应该是{A,A,B,B,A}
通过假设的参数来估计未知参数,即“每次投掷是哪枚硬币”
Step3,通过猜测的结果{A, A, B, B, A}来完善初始的参数θA和θB
一直重复Step2 和Step3,直到参数不再发生变化
GMM
GaussianMixture:
- 高斯混合模型,简称GMM,就是用高斯概率密度函数(二维时也称为:正态分布曲线)
- 模型思想:任何一个曲线,无论多么复杂,都可以用若干个高斯曲线来无限逼近它
- 混合高斯就是通过求解多个单高斯模型,并通过一定的权重将多个单高斯模型融合成一个模型,即最终的混合高斯模型
- 假设混合高斯模型由K个高斯模型组成(即K个类),则GMM的概率密度函数
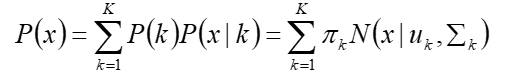
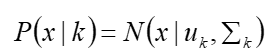
表示第k个高斯模型的概率密度函数,可以看成选定第k个模型后,该模型产生x的概率
p(k)=πk 是第k个高斯模型的权重,称作选择第k个模型的先验概率,且满足
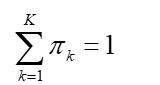
- GMM的目的就是找到一个合适的高斯分布(也就是确定高斯分布的参数μ,Σ),使得这个高斯分布能产生这组样本的可能性尽可能大
- 高斯混合模型是聚类,是机器学习中对“无标签数据”进行训练得到的分类结果(分类结果由概率表示,概率大者,则认为属于这一类)
GaussianMixture:
常用聚类算法,使用了EM算法进行迭代计算
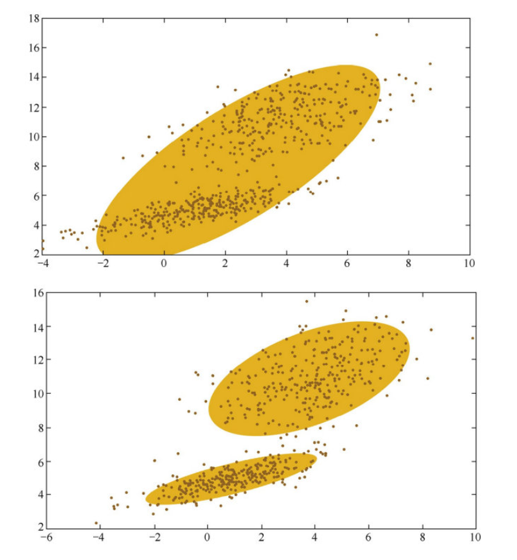
GMM模型假设每个簇的数据都是符合高斯分布的,当前数据呈现的分布就是各个簇的高斯分布的叠加
均值 uk 和方差 ∑k 是待估计的参数,此外每个分模型还有一个参数 πk,理解为权重或生成数据的概率
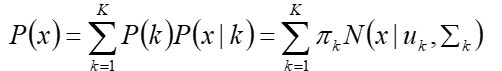
我们不知道最佳的K个高斯分布的各自3个参数,每次循环:
- Step1,固定当前的高斯分布不变 => 获得每个数据点由各个高斯分布生成的概率
- Step2,固定这个生成概率不变,根据数据点和生成概率,获得一个组更佳的高斯分布
循环往复,直到参数的不再变化 => 得到合理的高斯分布
工具
K-Means工具:
- from sklearn.cluster import KMeans
- KMeans(n_clusters=8, max_iter=300)
- n_clusters:聚类个数,缺省值为8
- max_iter:执行一次k-means算法所进行的最大迭代数,缺省值为300
GMM工具:
- from sklearn.mixture import GaussianMixture
- GaussianMixture(n_components=1, covariance_type="full")
- n_components:聚类个数,缺省值为1
- covariance_type:协方差类型,一共4种,默认为full
- covariance_type="full",完全协方差矩阵(元素都不为零)
- covariance_type="tied",相同的完全协方差矩阵(HMM会用到)
- covariance_type="diag",对角协方差矩阵(非对角为零,对角不为零)
- covariance_type="spherical",球面协方差矩阵(非对角为零,对角完全相同,球面特性)
数据规范化
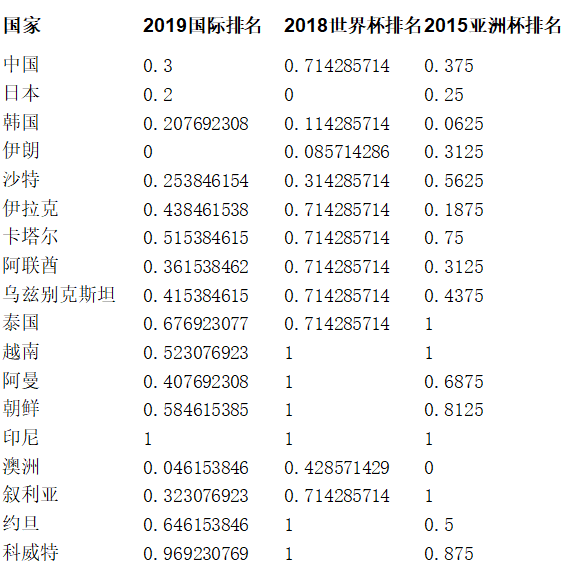
Project:给18支亚洲球队进行聚类
数据规范化的方式:
Min-max规范化
- 将原始数据投射到指定的空间[min,max]
- 新数值 = (原数值-极小值)/ (极大值 - 极小值)
- 当min=0, max=1时,为[0,1]规范化
- sklearn中的MinMaxScaler
Z-Score规范化
- 将原始数据转换为正态分布的形式
- 新数值 = (原数值 - 均值)/ 标准差
- sklearn中的preprocessing.scale()
- 小数定标规范化
- 通过移动小数点的位置来进行规范化
- 使用numpy
数据规范化的方式:
Min-max规范化
进行[0, 1]规范化之后,可以让不同维度的特征数据,在同一标准下可以进行比较
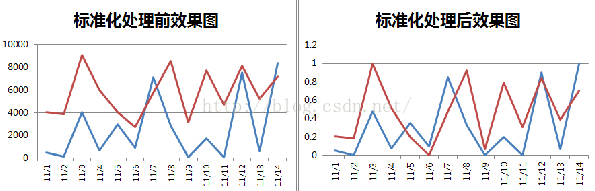
数据规范化示例
Thinking:假设A与B的考试成绩都为85分
- A的考卷满分是100分(及格60分)
- B的考卷满分是150分(及格90分)
两个人的成绩 谁更好?
假设A所在的班级平均分为90,标准差为10。B所在的班级平均分为80,标准差为20。
那么A的新数值=(85-90)/10=-0.5,B的新数值=(85-80)/20=0.25
数据规范化的方式:
Z-Score规范化
新数值 = (原数值 - 均值)/ 标准差
当前用得最多的数据标准化方式。
回答了这样一个问题:"给定数据距离其均值多少个标准差"
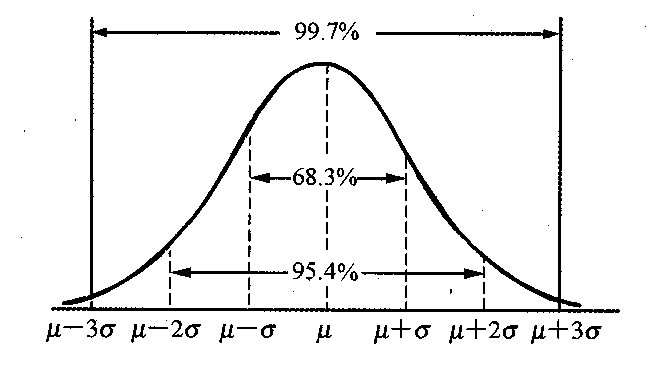
数据规范化的方式:
小数定标规范化
通过移动小数点的位置来进行规范化
比如A的取值范围 [-9999,666]
A的新数值=原数值/10000
通过移动小数点,将数值映射到 [-1, 1]
使用k-means进行聚类

# 数据加载 data = pd.read_csv('team_cluster_data.csv', encoding='gbk') train_x = data[["2019国际排名","2018世界杯排名","2015亚洲杯排名"]] kmeans = KMeans(n_clusters=3) # 规范化到[0,1]空间 min_max_scaler=preprocessing.MinMaxScaler() train_x=min_max_scaler.fit_transform(train_x) # 使用kmeans进行聚类 kmeans.fit(train_x) predict_y = kmeans.predict(train_x) # 使用GMM进行聚类 from sklearn.mixture import GaussianMixture model = GaussianMixture(n_components=3, covariance_type="full") model.fit(train_x) predict_y = model.predict(train_x)
聚类是无监督的学习,具体含义需要我们指定
什么时候使用聚类:
缺乏足够的先验知识
人工打标签太贵
利用用户标签做推荐
Delicious数据集:
- 1867名用户,105000个书签,53388个标签
- https://grouplens.org/datasets/hetrec-2011/
- 格式:userID bookmarkID tagID timestamp
SimpleTagBased算法
比如一个商品item 经常打 火锅(tag)标签的 说明它的属性强,一个人user经常打 火锅(tag)标签 说明它的属性强,计算它的分值;
- 统计每个用户的常用标签
- 对每个标签,统计被打过这个标签次数最多的商品
- 对于一个用户,找到他常用的标签,然后找到具有这些标签的最热门物品推荐给他
- 用户u 对商品i 的兴趣
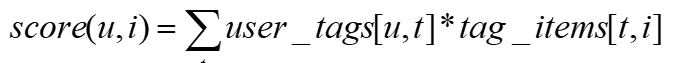
用户u 使用过标签t 的次数;
商品i 被打过标签t 的次数;
数据结构定义:
- 用户打标签记录:records[i] = {user, item, tag}
- 用户打过的标签:user_tags[u][t]
- 用户打过标签的商品:user_items[u][i]
- 打上某标签的商品:tag_items[t][i]
- 某标签使用过的用户:tags_users[t][u]
评测指标
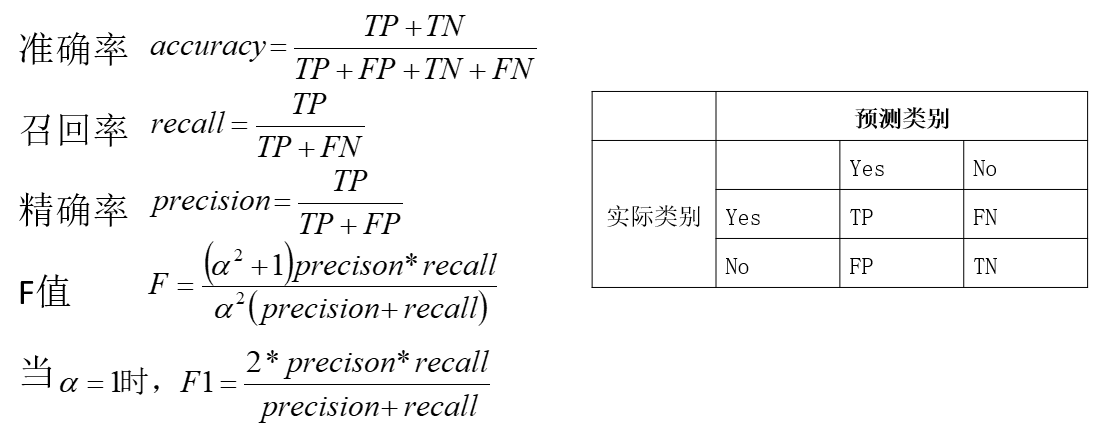
如何给用户推荐标签
当用户u给物品i打标签时,可以给用户推荐和物品i相关的标签,方法如下:
- 方法1:给用户u推荐整个系统最热门的标签
- 方法2:给用户u推荐物品i上最热门的标签
- 方法3:给用户u推荐他自己经常使用的标签
- 将方法2和3进行加权融合,生成最终的标签推荐结果
基于内容的推荐系统架构
- 物品表示 Item Representation:
- 为每个item抽取出features
- 特征学习Profile Learning:
- 利用一个用户过去喜欢(不喜欢)的item的特征数据,来学习该用户的喜好特征(profile);
- 生成推荐列表Recommendation Generation:
- 通过用户profile与候选item的特征,推荐相关性最大的item。
Action:对SimpleTagBased算法进行改进
- NormTagBased算法:
- 对score进行归一化
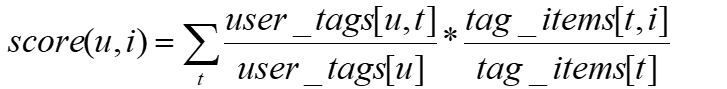
- TagBased-TFIDF算法:
- 如果一个tag很热门,会导致user_tags[t]很大,所以即使tag_items[u,t]很小,也会导致score(u,i)很大。给热门标签过大的权重,不能反应用户个性化的兴趣
- 这里借鉴TF-IDF的思想,使用tag_users[t]表示标签t被多少个不同的用户使用
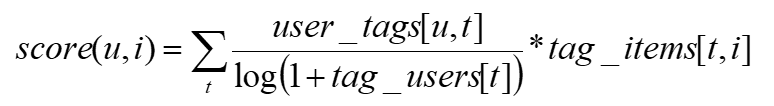
什么是TF-IDF:
TF:Term Frequency,词频 TF = (单词次数) / (文档中总单词次数)
一个单词的重要性和它在文档中出现的次数呈正比。
IDF:Inverse Document Frequency,逆向文档频率
一个单词在文档中的区分度。这个单词出现的文档数越少,区分度越大,IDF越大, IDF = Log ((文档总数) / (单词出现的文档数+1))
summary
- 聚类是一种降维的方式,距离的定义
- 定义用户画像的维度(用户、消费、行为、内容),从而指导业务
- 围绕用户生命周期开展业务(获客、粘客、留客)
- 数据处理的层次:数据源 => 算法层 => 业务层
- 标签是一种抽象能力,通过对用户画像进行Profile Learning,同时对item提取标签,从而可以完成基于标签的召回
- 标签召回计算简单,属于召回的一种策略
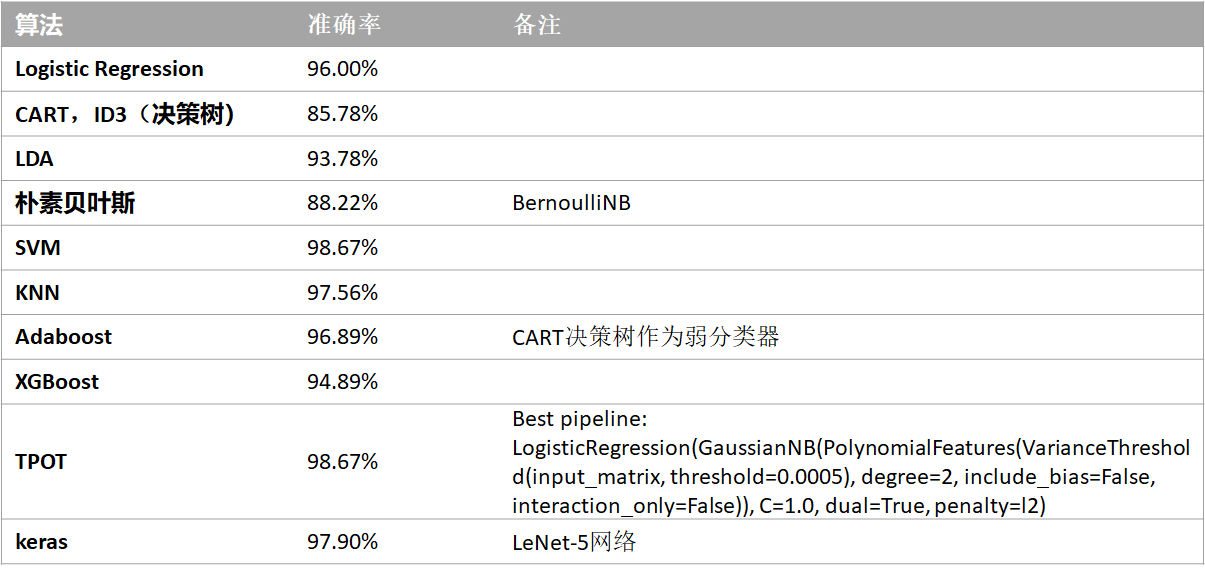
Mnist的10种解法

TPOT https://github.com/EpistasisLab/tpot (6.2K)
TPOT可以解决:特征选择,模型选择,但不包括数据清洗
处理小规模数据非常快,大规模数据非常慢。可以先抽样小部分,使用TPOT
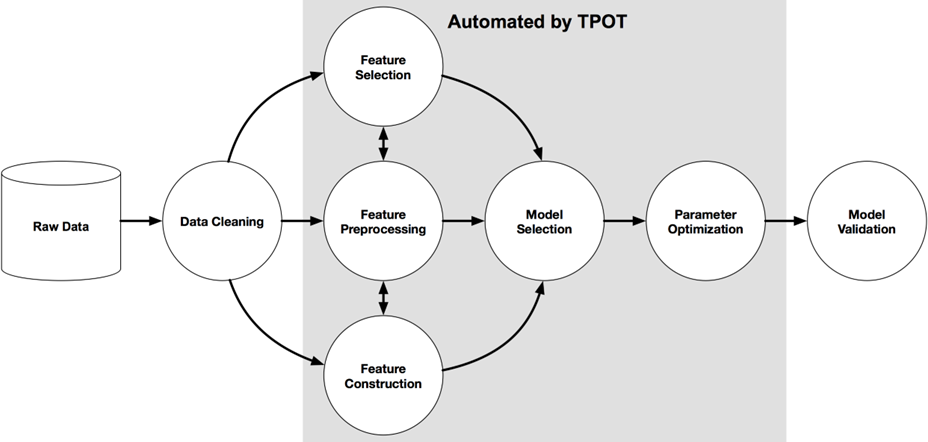
TPOT:基于Python的AutoML工具
目前只能做有监督学习
支持的分类器主要有贝叶斯、决策树、集成树、SVM、KNN、线性模型、xgboost
支持的回归器主要有决策树、集成树、线性模型、xgboost
数据预处理:二值化、聚类、降维、标准化、正则化等
特征选择:基于树模型、基于方差、基于F-值的百分比
可以通过export()方法把训练过程导出为形式为sklearn pipeline的.py文件
TPOT:一个简单的实例(iris数据集)
# 使用TPOP对iris进行分类 from tpot import TPOTClassifier from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split import numpy as np iris = load_iris() X_train, X_test, y_train, y_test = train_test_split(iris.data.astype(np.float64), iris.target.astype(np.float64), train_size=0.75, test_size=0.25) tpot = TPOTClassifier(generations=5, population_size=20, verbosity=2) tpot.fit(X_train, y_train) print(tpot.score(X_test, y_test)) tpot.export('tpot_iris_pipeline.py') generations:运行管道优化过程的迭代次数 population_size:在遗传进化中每一代要保留的个体数量 verbosity: TPOT运行时能传递多少信息
# 使用TPOT自动机器学习工具对MNIST进行分类 from tpot import TPOTClassifier from sklearn.datasets import load_digits from sklearn.model_selection import train_test_split import numpy as np digits = load_digits() X_train, X_test, y_train, y_test = train_test_split(digits.data.astype(np.float64), digits.target.astype(np.float64), train_size=0.75, test_size=0.25) tpot = TPOTClassifier(generations=5, population_size=20, verbosity=2) tpot.fit(X_train, y_train) print(tpot.score(X_test, y_test)) tpot.export('tpot_iris_pipeline.py') generations:运行管道优化过程的迭代次数 population_size:在遗传进化中每一代要保留的个体数量 verbosity: TPOT运行时能传递多少信息
MNIST的10种解法



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人