
关联规则| 支持度 置信度| Apriori
关联规则
关联规则
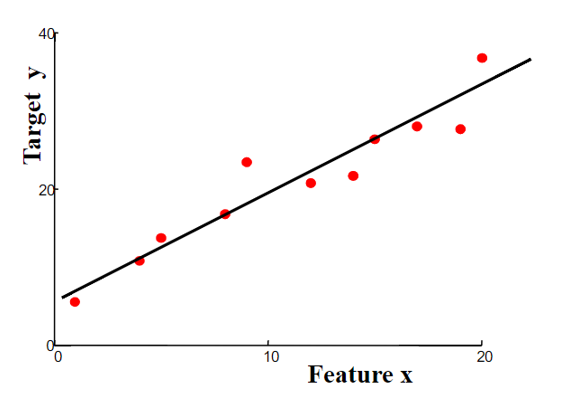
关联分析是大数据计算的重要场景之一,通过数据挖掘,商家发现尿不湿和啤酒经常会同时被购买,所以商家就把啤酒和尿不湿摆放在一起促进销售。
在传统商超确实没有见过把啤酒和纸尿裤放在一起的情况,可能是因为传统商超的物理货架分区策略限制它没有办法这么做,而啤酒和尿不湿存在关联关系则确实是大数据中存在的规律,在电子商务网
站就可以轻易进行关联推荐。
通过商品订单,可以发现频繁出现在同一个购物篮里商品间的关联关系,这种大数据关联分析也被称作是“购物篮分析”,频繁出现的商品组合也被称作是“频繁模式”。
在深入关联分析前,你需要先了解两个基本概念,一个是支持度,一个是置信度。
支持度是指一组频繁模式的出现概率,比如(啤酒,尿不湿)是一组频繁模式,它的支持度是 4%,也就是说,在所有订单中,同时出现啤酒和尿不湿这两件商品的概率是 4%。
置信度用于衡量频繁模式内部的关联关系,如果出现尿不湿的订单全部都包含啤酒,那么就可以说购买尿不湿后购买啤酒的置信度是 100%;如果出现啤酒的订单中有 20% 包含尿不湿,那么就可以说购
买啤酒后购买尿不湿的置信度是 20%。
大型超市的商品种类数量数以万计,所有商品的组合更是一个天文数字;而电子商务网站的商品种类更多,历史订单数据同样也非常庞大,虽然我们有大数据技术,但是资源依然是有限的。
美国明尼苏达州一家Target被客户投诉,一位中年男子指 控Target将婴儿产品优惠券寄给他的女儿(高中生)。但 没多久他却来电道歉,因为女儿经他逼问后坦承自己真 的怀孕了。
关联规则:Association Rules, 或者是 Basket Analysis 解释了:如果一个消费者购买 了产品A,那么他有多大几率会 购买产品B?

啤酒和尿布:
沃尔玛在分析销售记录时,发现啤酒和尿布经常一起被购买,于是他们调整了货架,把两者放在一起,结果真的提升了啤酒的销量。
原因解释:爸爸在给宝宝买尿布的时候,会顺便给自己买点啤酒?
沃尔玛是最早通过大数据分析而受益的传统零售企业,对消费者购物行为进行跟踪和分析。
支持度、置信度和提升度
支持度:是个百分比,指的是某个商品组合出现的次数与总次数之间的比例。支持度越高,代表这个组合出现的频率越大。
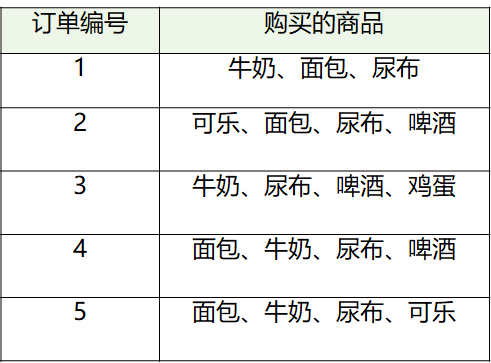
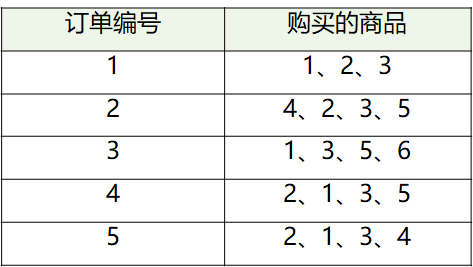
“牛奶”的支持度=4/5=0.8
“牛奶+面包”的支持度=3/5=0.6。
置信度:是个条件概念,指的是当你购买了商品A,会有多大的概率购买商品B
- 置信度(牛奶→啤酒)=2/4=0.5
- 置信度(啤酒→牛奶)=2/3=0.67
提升度:商品A的出现,对商品B的出现概率提升的程度
如果我们单纯看置信度(可乐→尿布)=1,也就是说可乐出现的时候,用户都会购买尿布,那么当用户购买可乐的时候,就需要推荐尿布么?
提升度:商品A的出现,对商品B的出现概率提升的程度
提升度(A→B)=置信度(A→B)/支持度(B)
提升度的三种可能:
- 提升度(A→B)>1:代表有提升;
- 提升度(A→B)=1:代表有没有提升,也没有下降;
- 提升度(A→B)<1:代表有下降。
Apriori算法
那我们应该从哪里考虑着手,可以使用最少的计算资源寻找到最小支持度的频繁模式?寻找满足最小支持度的频繁模式经典算法是 Apriori 算法,Apriori 算法的步骤是:
第 1 步:设置最小支持度阈值。
第 2 步:寻找满足最小支持度的单件商品,也就是单件商品出现在所有订单中的概率不低于最小支持度。
第 3 步:从第 2 步找到的所有满足最小支持度的单件商品中,进行两两组合,寻找满足最小支持度的两件商品组合,也就是两件商品出现在同一个订单中概率不低于最小支持度。
第 4 步:从第 3 步找到的所有满足最小支持度的两件商品,以及第 2 步找到的满足最小支持度的单件商品进行组合,寻找满足最小支持度的三件商品组合。
第 5 步:以此类推,找到所有满足最小支持度的商品组合。
Apriori 算法极大地降低了需要计算的商品组合数目,这个算法的原理是,如果一个商品组合不满足最小支持度,那么所有包含这个商品组合的其他商品组合也不满足最小支持度。所以从最小商品组合,
也就是一件商品开始计算最小支持度,逐渐迭代,进而筛选出所有满足最小支持度的频繁模式。
通过关联分析,可以发现看似不相关商品的关联关系,并利用这些关系进行商品营销,比如上面提到的啤酒和尿不湿的例子,一方面可以为用户提供购买便利;另一方面也能提高企业营收。
网页的链接关系如何用数据表示呢?PageRank 算法用 MapReduce 或者 Spark 编程如何实现呢?
我们把上面案例中的商品用ID来代表,牛奶、面包、尿布、可乐、啤酒、鸡蛋的商品ID分别设置为1-6
Apriori算法就是查找频繁项集(frequent itemset)的过程
频繁项集:支持度大于等于最小支持度(Min Support)阈值的项集。
非频繁项集:支持度小于最小支持度的项集
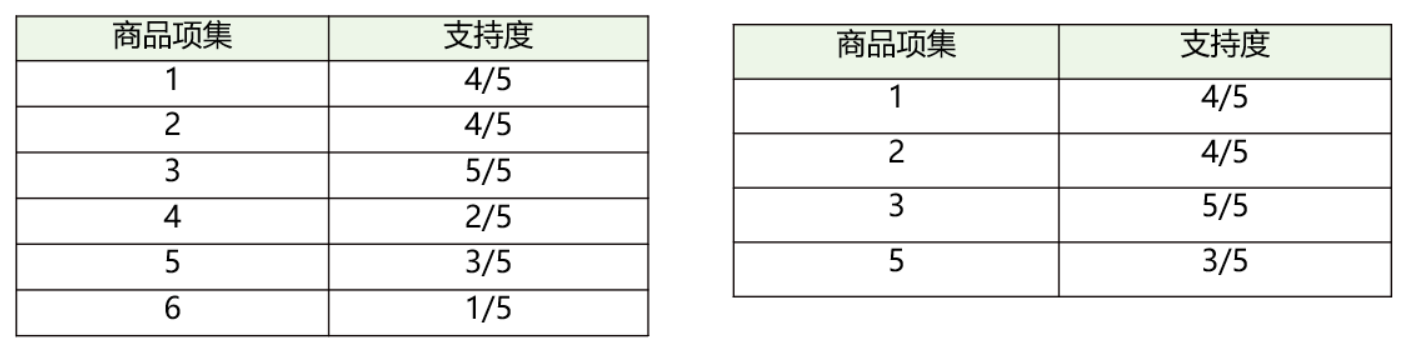
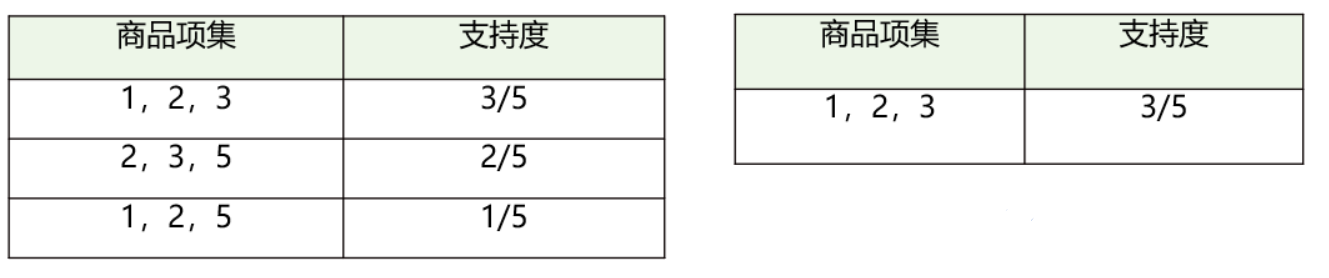
先计算K=1项的支持度;(4和6在K=1时的支持度 < 0.5,在K=2时就需要去掉)
假设最小支持度=0.5,那么Item4和 6 不符合最小支持度的,不属于频繁项集;
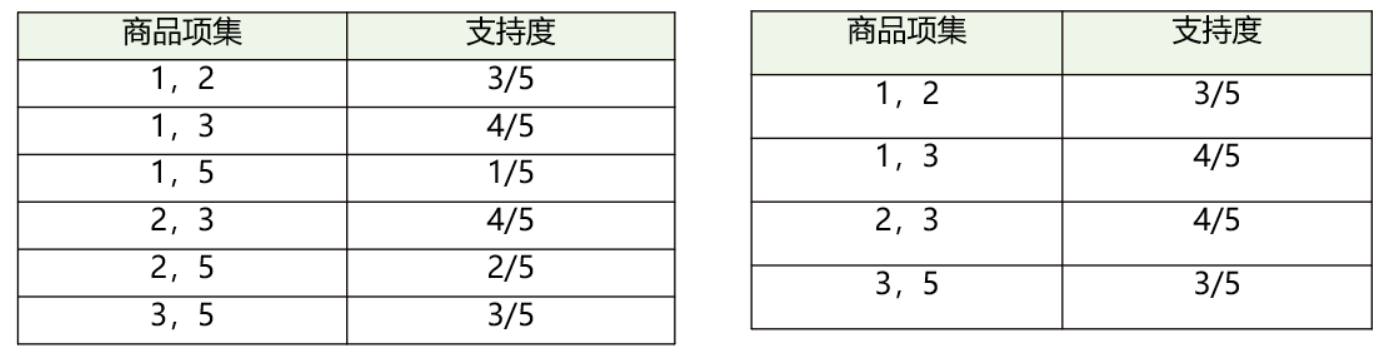
在这个基础上,我们将商品两两组合,得到K=2项的支持度;
筛选掉小于最小值支持度的商品组合;
将商品进行 K=3项的商品组合,可以得到如左下图所示;
筛选掉小于最小值支持度的商品组合,得到K=3项的频繁项集{1, 2, 3},也就是{牛奶、面包、尿布} 的组合;
Apriori算法的流程:
- Step1,K=1,计算K项集的支持度;
- Step2,筛选掉小于最小支持度的项集;
- Step3,如果项集为空,则对应K-1项集的结果为最终结果。
- 否则K=K+1,重复1-3步。
使用Apriori算法做关联分析
- 使用工具包:
- from efficient_apriori import apriori
- 或者:
- from mlxtend.frequent_patterns import apriori
- from mlxtend.frequent_patterns import association_rules

- from efficient_apriori import apriori #这个包的bug是没有min_lift , 只有min_confidence
- # 设置数据集
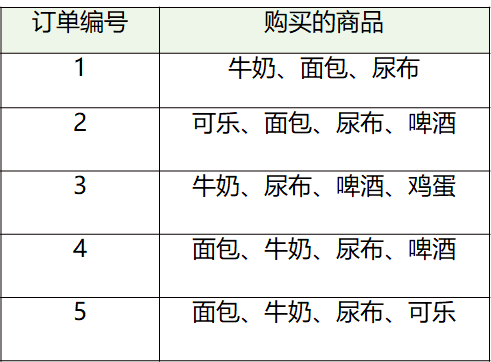
- transactions = [('牛奶','面包','尿布'),
- ('可乐','面包', '尿布', '啤酒'),
- ('牛奶','尿布', '啤酒', '鸡蛋'),
- ('面包', '牛奶', '尿布', '啤酒'),
- ('面包', '牛奶', '尿布', '可乐')]
- # 挖掘频繁项集和频繁规则 最小置信度50%, 基于关联规则最小置信度为1
- itemsets, rules = apriori(transactions, min_support=0.5, min_confidence=1)
- print("频繁项集:", itemsets)
- print("关联规则:", rules)
频繁项集: {1: {('啤酒',): 3, ('尿布',): 5, ('牛奶',): 4, ('面包',): 4}, 2: {('啤酒', '尿布'): 3, ('尿布', '牛奶'): 4, ('尿布', '面包'): 4, ('牛奶', '面包'): 3}, 3: {('尿布', '牛奶', '面包'): 3}}
关联规则: [{啤酒} -> {尿布}, {牛奶} -> {尿布}, {面包} -> {尿布}, {牛奶, 面包} -> {尿布}]
关联分析使用的场景
万物皆Transaction:
- 超市购物小票(TransactionID => Item)
- 每部电影的分类(MovieID => 分类)
- 每部电影的演员(MovieID => 演员)
超市购物小票的关联关系
每笔订单的商品(TransactionID => Item)
BreadBasket数据集(21293笔订单):
BreadBasket_DMS.csv
字段:Date(日期),Time(时间),Transaction(交易ID)Item(商品名称)
交易ID的范围是[1,9684],存在交易ID为空的情况,同一笔交易中存在商品重复的情况。以外,有些交易没有购买商品(对应的Item为NONE)
# 数据加载 data = pd.read_csv('./BreadBasket_DMS.csv') # 统一小写 data['Item'] = data['Item'].str.lower() # 去掉none项 data = data.drop(data[data.Item == 'none'].index) # 得到一维数组orders_series,并且将Transaction作为index, value为Item取值 orders_series = data.set_index('Transaction')['Item'] # 将数据集进行格式转换 transactions = [] temp_index = 0 for i, v in orders_series.items(): if i != temp_index: temp_set = set() temp_index = i temp_set.add(v) transactions.append(temp_set) else: temp_set.add(v) itemsets, rules = apriori(transactions, min_support=0.02, min_confidence=0.5) 通过调整min_support,min_confidence可以得到不同的频繁项集和关联规则 min_support=0.02,min_confidence=0.5时 一共有33个频繁项集,8种关联规则 使用efficient_apriori工具包 效率较高,但返回参数较少 from mlxtend.frequent_patterns import apriori from mlxtend.frequent_patterns import association_rules hot_encoded_df=data.groupby(['Transaction','Item'])['Item'].count().unstack().reset_index().fillna(0).set_index('Transaction') hot_encoded_df = hot_encoded_df.applymap(encode_units) frequent_itemsets = apriori(hot_encoded_df, min_support=0.02, use_colnames=True) rules = association_rules(frequent_itemsets, metric="lift", min_threshold=0.5) 使用mlxtend.frequent_patterns工具包 效率较低,但返回参数较多
电影分类中的关联关系
每部电影的分类(MovieID => 分类)
数据集:MovieLens
下载地址:https://www.kaggle.com/jneupane12/movielens/download
主要使用的文件:movies.csv
格式:movieId title genres
记录了电影ID,标题和分类
我们可以分析下电影分类之间的频繁项集和关联规则
MovieLens 主要使用 Collaborative Filtering 和 Association Rules 相结合的技术,向用户推荐他们感兴趣的电影。
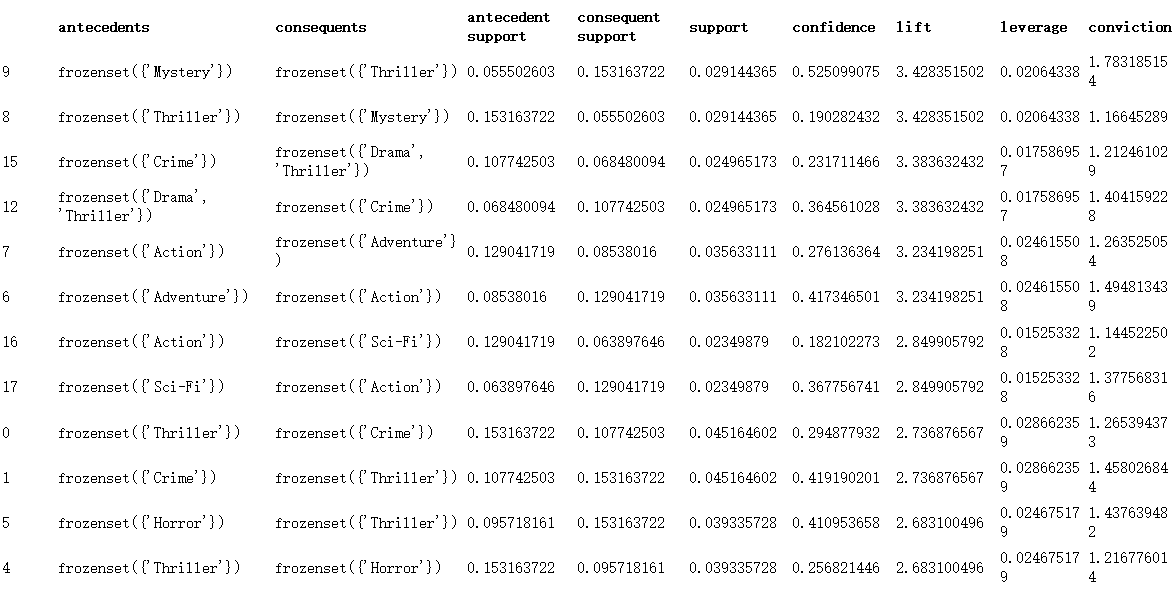
# 将genres进行one-hot编码(离散特征有多少取值,就用多少维来表示这个特征) movies_hot_encoded = movies.drop('genres',1).join(movies.genres.str.get_dummies()) # 将movieId, title设置为index movies_hot_encoded.set_index(['movieId','title'],inplace=True) # 挖掘频繁项集,最小支持度为0.02 itemsets = apriori(movies_hot_encoded,use_colnames=True, min_support=0.02) # 根据频繁项集计算关联规则,设置最小提升度为2 rules = association_rules(itemsets, metric='lift', min_threshold=2)
电影演员中的关联关系
每部电影的演员列表(MovieID => 演员)
数据集:MovieActors
来源:movie_actors.csv
爬虫抓取 movie_actors_download.py
格式:title actors
记录了电影标题和演员列表
我们可以分析下电影演员之间的频繁项集和关联规则
from selenium import webdriver # 设置想要下载的导演 数据集 director = u'徐峥' base_url = 'https://movie.douban.com/subject_search?search_text='+director+'&cat=1002&start=' # 下载指定页面的数据 def download(request_url): # 将字典类型转化为DataFrame movie_actors = pd.DataFrame(movie_actors, index=[0]) # DataFrame 行列转换 movie_actors = pd.DataFrame(movie_actors.values.T, index=movie_actors.columns, columns=movie_actors.index) movie_actors.index.name = 'title' movie_actors.set_axis(['actors'], axis='columns', inplace=True) movie_actors.to_csv('./movie_actors.csv') from mlxtend.frequent_patterns import apriori from mlxtend.frequent_patterns import association_rules # 数据加载 movies = pd.read_csv('./movie_actors.csv') # 将genres进行one-hot编码(离散特征有多少取值,就用多少维来表示这个特征) movies_hot_encoded = movies.drop('actors',1).join(movies.actors.str.get_dummies('/')) # 将movieId, title设置为index movies_hot_encoded.set_index(['title'],inplace=True) # 挖掘频繁项集,最小支持度为0.05 itemsets = apriori(movies_hot_encoded,use_colnames=True, min_support=0.05) # 按照支持度从大到小进行时候粗 itemsets = itemsets.sort_values(by="support" , ascending=False) pd.options.display.max_columns=100 # 根据频繁项集计算关联规则,设置最小提升度为2 rules = association_rules(itemsets, metric='lift', min_threshold=2) # 按照提升度从大到小进行排序 rules = rules.sort_values(by="lift" , ascending=False) #rules.to_csv('./rules.csv')
Action:MarketBasket购物篮分析
数据集:MarketBasket
下载地址:https://www.kaggle.com/dragonheir/basket-optimisation
该数据集为rawdata,没有记录TransactionID和列名
ToDo:统计交易中的频繁项集和关联规则
关联规则与协同过滤的区别
- 关联规则是基于transaction,而协同过滤基于用户偏好(评分)
- 商品组合使用的是购物篮分析,也就是Apriori算法,协同过滤计算的是相似度
- 关联规则没有利用“用户偏好”,而是基于购物订单进行的频繁项集挖掘
推荐使用场景:
- 当下的需求:
- 推荐的基础是且只是当前一次的购买/点击
- 长期偏好:
- 基于用户历史的行为进行分析,建立一定时间内的偏好排序
- 两种推荐算法的思考维度不同,很多时候,我们需要把多种推荐方法的结果综合起来做一个混合的推荐
关联规则的视角
不需要考虑用户一定时期内的偏好,而是基于Transaction
只要能将数据转换成Transaction,就可以做购物篮分析:
- Step1、把数据整理成id=>item形式,转换成transaction
- Step2、设定关联规则的参数(support、confident)挖掘关联规则
- Step3、按某个指标(lift、support等)对以关联规则排序
关联规则中的最小支持度、最小置信度该如何确定
- 最小支持度,最小置信度是实验出来的
- 最小支持度:
- 不同的数据集,最小值支持度差别较大。可能是0.01到0.5之间
- 可以从高到低输出前20个项集的支持度作为参考
- 最小置信度:可能是0.5到1之间
- 提升度:表示使用关联规则可以提升的倍数,是置信度与期望置信度的比值
- 提升度至少要大于1
基于关联规则的推荐算法:
- Apriori算法
- FPGrowth算法
- PrefixSpan算法
FPGrowth算法
Apriori在计算的过程中存在的不足:
- 可能产生大量的候选集。因为采用排列组合的方式,把可能的项集都组合出来了
- 每次计算都需要重新扫描数据集,计算每个项集的支持度
- 浪费了计算空间和时间
在Apriori算法基础上提出了FP-Growth算法:
- 创建了一棵FP树来存储频繁项集。在创建前对不满足最小支持度的项进行删除,减少了存储空间。
- 整个生成过程只遍历数据集2次,大大减少了计算量
- 理解:Apriori存在的不足,有更快的存储和搜索方式进行频繁项集的挖掘
创建项头表(item header table)
作用是为FP构建及频繁项集挖掘提供索引。
Step1、流程是先扫描一遍数据集,对于满足最小支持度的单个项(K=1项集)按照支持度从高到低进行排序,这个过程中删除了不满足最小支持度的项。
项头表包括了项目、支持度,以及该项在FP树中的链表。初始的时候链表为空。
Step2、对于每一条购买记录,按照项头表的顺序进行排序,并进行过滤。
构造FP树,根节点记为NULL节点
Step3、整个流程是需要再次扫描数据集,把Step2得到的记录逐条插入到FP树中。节点如果存在就将计数count+1,如果不存在就进行创建。同时在创建的过程中,需要更新项头表的链表。
Step4、通过FP树挖掘频繁项集
现在已经得到了一个存储频繁项集的FP树,以及一个项头表。可以通过项头表来挖掘出每个频繁项集
挖掘从项头表最后一项“啤酒”开始。
从FP树种找到所有“啤酒”节点,向上遍历祖先节点,得到3条路径。对于每条路径上的节点,其count都设置为“啤酒”的count
具体的操作会用到一个概念,叫“条件模式基”
因为每项最后一个都是“啤酒”,因此我们把“啤酒”去掉,得到条件模式基,此时后缀模式是(啤酒)
继续找项头表倒数第2项面包,求得“面包”的条件模式基
根据条件模式基,可以求得面包的频繁项集:{面包},{尿布,面包},{牛奶,面包},{尿布,牛奶,面包}
继续找项头表倒数第3项面包,求得“牛奶”的条件模式基
根据条件模式基,可以求得面包的频繁项集:{牛奶},{尿布,牛奶}
继续找项头表倒数第4项面包,求得“尿布”的条件模式基
根据条件模式基,可以求得尿布的频繁项集:{尿布}
所以全部的频繁项集为:
{啤酒},{尿布,啤酒}
{面包},{尿布,面包},{牛奶,面包},{尿布,牛奶,面包}
{牛奶},{尿布,牛奶}
{尿布}
工具包
通过Python官方的第三方软件库
https://pypi.org/
import fptools as fp
Spark.mllib 提供并行FP-growth算法
summary
支持度、置信度、提升度
最小支持度,最小置信度是实验出来的
基于关联规则的推荐算法:
Apriori算法
FPGrowth算法
PrefixSpan算法
万物皆Transaction:
超市购物小票(TransactionID => Item)
每部电影的分类(MovieID => 分类)
每部电影的演员(MovieID => 演员)
关联规则与协同过滤:
关联规则是基于transaction,而协同过滤基于用户偏好(评分)
商品组合使用的是购物篮分析,也就是Apriori算法,协同过滤计算的是相似度
关联规则没有利用“用户偏好”,而是基于购物订单进行的频繁项集挖掘
• BreadBasket:面包店购物清单的关联分析
• MovieLens:电影分类中的关联分析
• MovieActors:电影演员中的关联分析
• 关联规则与协同过滤的区别
• 关联规则中的最小支持度、最小置信度该如何确定 相关性分析
数据相关性分析
Thinking:如果各自变量x跟因变量y之间没有相关性,还需要做回归分析么?
如果有一定的相关性了,然后再通过回归分析进一步验证他们之间的准确关系
通过相关分析求得相关系数没有回归分析的准确
相关分析是一种描述性的分析,而回归分析得到的结果更为重要和准确
使用DataFrame显示各元素间的相关性:
DataFrame.corr(method='pearson', min_periods=1)
method参数
pearson,衡量两个数据集合是否在一条线上面,针对线性数据的相关系数计算,对于非线性数据有误差
kendall,反映分类变量相关性的指标,通常用于评分数据一致性水平研究,比如评委打分,数据排名等
spearman:非线性的,非正太分布的数据的相关系数
pearson系数,使用最广泛的相关性统计量,用于测量两组连续变量之间的线性关联程度
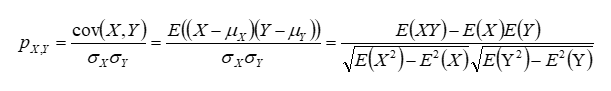
# 构造一元二次方程,y=2x*x+1 非线性关系 def compute(x): return 2*x*x+1 x=[i for i in range(100)] y=[compute(i) for i in x] data = pd.DataFrame({'x':x,'y':y}) # 查看pearson系数 print(data.corr()) print(data.corr(method='spearman')) print(data.corr(method='kendall'))
回归分析
回归分析(Regression) :
确定两种或两种以上变量之间相互依赖的定量关系的统计方法,使用非常广泛
按照涉及的变量的多少,分为一元分析和多元回归分析
按照因变量的多少,分为简单回归分析和多重回归分析
按照自变量和因变量之间的关系类型,分为线性回归分析和非线性回归分析
线性回归模型
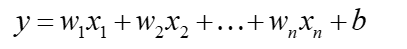
损失函数
损失函数可以衡量模型的好坏
MSE,均方误差,是在回归问题中比较常用的损失函数
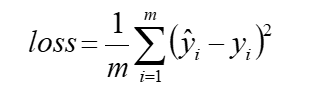
回归分析工具:
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
在进行多项式回归之前,需要对数据进行变换,因为模型里包含 x²等变量,所以在创建数据之后要将x转换为 x²
clf = linear_model.LinearRegression()
fit(X,y),训练,拟合参数
predict(X) ,预测
coef_ ,存放回归系数
intercept_,存放截距
score(X,y), 得到评分结果,R方(确定系数)
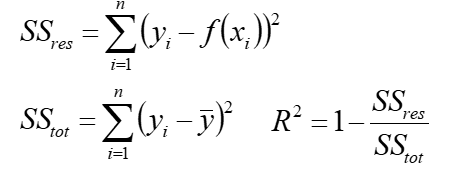
R方(r-squared):
R方也叫确定系数(coefficient of determination),表示模型对现实数据拟合的程度,评估预测效果
R方计算,等于1减去y对回归方程的方差(未解释离差)与y的总方差的比值
一元线性回归中R方等于皮尔逊积矩相关系
比如,R平方=0.8,表示回归关系可以解释因变量80%的变异。换句话说,如果我们能控制自变量x不变,那么因变量y的变异程度会减少80%
在sklearn计算中,相关系数有正负
Sklearn中的回归分析
TO DO:随机生成(x, y),并进行回归分析
模拟生成 y = 2*x + 10
使用LinearRegression进行拟合
TO DO:一元线性回归
x = np.array([5, 15, 25, 35, 45, 55]).reshape((-1, 1))
y = np.array([5, 20, 14, 32, 22, 38])
多元线性回归
x = [[0, 1], [5, 1], [15, 2], [25, 5], [35, 11], [45, 15], [55, 34], [60, 35]]
y = [4, 5, 20, 14, 32, 22, 38, 43]
多项式回归
x = np.array([5, 15, 25, 35, 45, 55]).reshape((-1, 1))
y = np.array([15, 11, 2, 8, 25, 32])
糖尿病回归分析
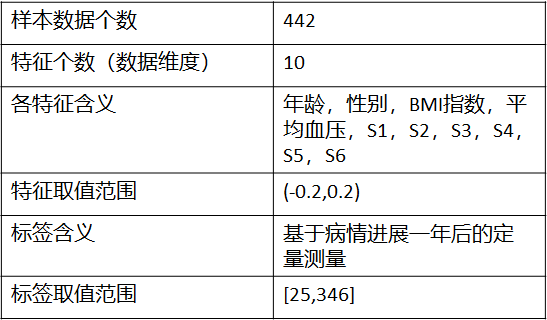
数据集Diabetes,包含442个患者的10个生理特征(年龄,性别、体重、血压)和一年以后疾病级数指标
10项特征:
年龄,性别,体质指数,血压
s1,s2,s3,s4,s4,s6 (六种血清的化验数据)
糖尿病回归分析步骤:
Step1,数据加载
Step2,训练集、测试集切分
Step3,使用回归分析模型进行学习
输出回归分析模型的系数coef
Step4,使用测试集进行评价
数据集切分 train_test_split
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y =train_test_split(train_data,train_target,test_size=0.3, random_state=33)
train_data:样本特征集
train_target:样本标签
test_size:如果是浮点数[0,1]表示样本占比,如果是整数表示样本的数量
random_state:随机数的种子
from sklearn import datasets from sklearn import linear_model from sklearn.model_selection import train_test_split # 加载数据 diabetes = datasets.load_diabetes() data = diabetes.data # 训练集 70%,测试集30% train_x, test_x, train_y, test_y = train_test_split(diabetes.data, diabetes.target, test_size=0.3, random_state=14) print(len(train_x)) #回归训练及预测 clf = linear_model.LinearRegression() clf.fit(train_x, train_y) print(clf.coef_) pred_y = clf.predict(test_x) print(mean_squared_error(test_y, pred_y))
股票回归分析
DataReader
Pandas提供了专门从财经网站获取金融数据的API接口
from pandas_datareader.data import DataReader data_tlz = DataReader("300005.SZ", "yahoo",start,end) print(data_tlz.head()) DataReader 下载速度慢,为了方便后续使用可将数据保存到本地 # 读取上证综指 及 探路者数据 def load_data(): if os.path.exists('000001.csv'): data_ss = pd.read_csv('000001.csv') data_tlz = pd.read_csv('300005.csv') else: # 上证综指 data_ss = DataReader("000001.SS", "yahoo",start,end) # 300005 探路者股票 深证 data_tlz = DataReader("300005.SZ", "yahoo",start,end) data_ss.to_csv('000001.csv') data_tlz.to_csv('300005.csv') return data_ss, data_tlz DataFrame.diff()函数 用来将数据进行某种移动之后与原数据进行比较得出的差异数据 DataFrame.shift()函数 可以把数据移动指定的位数 periods=-1 往上移动或往左移动 periods=1 往下移动或往右移动 # 回归分析 import statsmodels.api as sm # 加入截距项 daily_return["intercept"]=1.0 model = sm.OLS(daily_return["探路者"],daily_return[["上证综指","intercept"]]) results = model.fit() print(results.summary()) OLS:Ordinary Least Squares 最小二乘法进行回归分析 R-squared,可决策系数,0.265 可解释性一般 上证综指 coef=1.1155,说明“探路者”的日收益率波动比上证综指大,即上证综指日收益率波动1%,个股日收益率波动1.1155%
使用Apriori完成Basket Analysis
万物皆Transaction的三种使用场景:
BreadBasket数据集
MovieLens数据集
MovieActors数据集(需要抓取数据)
相关性分析场景:
相关性分析 pearson
掌握sklearn中回归分析的使用
通过糖尿病回归分析,来理解数据分析的流程
ToDo Action:关联规则&相关性分析
Thinking1:关联规则中的支持度、置信度和提升度代表的什么,如何计算
Thinking2:关联规则与协同过滤的区别
Thinking3:为什么我们需要多种推荐算法
Thinking4:关联规则中的最小支持度、最小置信度该如何确定
Thinking5:都有哪些常见的回归分析方法,评价指标是什么
Action1:购物篮分析
数据集:MarketBasket
下载地址:https://www.kaggle.com/dragonheir/basket-optimisation
该数据集为rawdata,没有记录TransactionID和列名
ToDo:统计交易中的频繁项集和关联规则



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人