
SVD矩阵分解
1. SVD矩阵分解
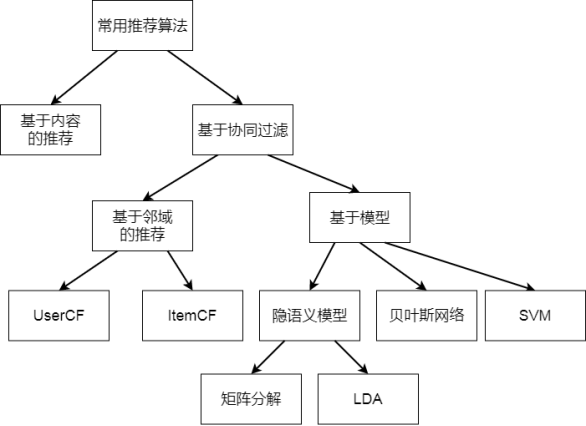
协同过滤是推荐系统的主流思想之一:
- 基于邻域的协同过滤
- UserCF
- ItemCF
- 基于模型的协同过滤
- 隐语义模型(LFM, Latent Factor Model)
- 矩阵分解(MF)
- LDA, LSA, pLSA
- 基于贝叶斯网络
- 基于SVM
- 隐语义模型(LFM, Latent Factor Model)
1.1 矩阵分解方法
矩阵分解:
- 将矩阵拆解为多个矩阵的乘积
- 在推荐系统中,协同过滤=>基于模型=>隐语义模型=>SVD
矩阵分解方法:
- EVD(特征值分解)
- SVD(奇异值分解)
求解近似矩阵分解的最优化问题
- ALS
- SGD
1.2 普通矩阵的矩阵分解
矩阵的特征分解:
- 特征分解,是将矩阵分解为特征值和特征向量表示的矩阵之积的方法,也称为谱分解;
- N 维非零向量 v 是 N×N 的矩阵 A 的特征向量,当且仅当下式成立 Av = λv ;
λ为特征值(标量),v为特征值λ 对应的特征向量。特征向量被施以线性变换 A 只会使向量伸长或缩短,而方向保持不变;
求解 |A - λI| = 0 ,也称为特征方程
令p(λ) = |A - λI| = 0 称为矩阵的特征多项式
特征多项式是关于λ 的N次多项式,特征方程有N个解
对多项式p(λ) 进行因式分解,可得




import numpy as np A = np.array([[5,3], [1,1]]) lamda, U = np.linalg.eig(A) print('矩阵A: ') print(A) print('特征值: ',lamda) print('特征向量') print(U) ----> 矩阵A: [[5 3] [1 1]] 特征值: [5.64575131 0.35424869] 特征向量 [[ 0.97760877 -0.54247681] [ 0.21043072 0.84007078]]
1.3 对称矩阵的矩阵分解
对称矩阵的矩阵分解


1.4 奇异值分解SVD
矩阵分解中的问题
- 很多矩阵都是非对称的
- 矩阵A不是方阵,即维度为m*n
我们可以将它转化为对称的方阵,因为:AAT 与 ATA 是对称的方阵;
因为AAT 与 ATA 是对称的方阵,我们可以将A和A的转置矩阵进行相乘,得到对称方阵:
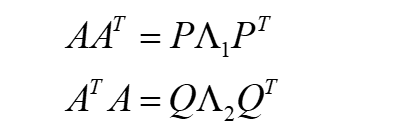
此时Λ1和Λ2 均为对角矩阵,具有相同的非零特征值。
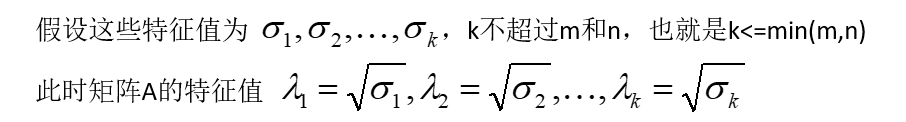
我们可以得到为奇异值分解 A = PΛQT
- P为左奇异矩阵,m*m维
- Q为右奇异矩阵,n*n维
- Λ对角线上的非零元素为特征值λ1, λ2, ... , λk
在推荐系统中
- 左奇异矩阵:User矩阵
- 右奇异矩阵:Item矩阵



代码计算得
from scipy.linalg import svd import numpy as np from scipy.linalg import svd A = np.array([[1,2], [1,1], [0,0]]) p,s,q = svd(A,full_matrices=False) print('P=', p) print('S=', s) print('Q=', q) ----->> P= [[-0.85065081 -0.52573111] [-0.52573111 0.85065081] [ 0. 0. ]] S= [2.61803399 0.38196601] Q= [[-0.52573111 -0.85065081] [ 0.85065081 -0.52573111]]
1.5 使用SVD进行降维
如何理解SVD的作用
对于特征值矩阵,我们如果只包括某部分特征值,结果会怎样?
矩阵A:大小为1440*1080的图片
- Step1,将图片转换为矩阵
- Step2,对矩阵进行奇异值分解,得到p,s,q
- Step3,包括特征值矩阵中的K个最大特征值,其余特征值设置为0
- Step4,通过p,s',q得到新的矩阵A',对比A'与A的差别
import numpy as np from scipy.linalg import svd from PIL import Image import matplotlib.pyplot as plt # 取前k个特征,对图像进行还原 def get_image_feature(s, k): # 对于S,只保留前K个特征值 s_temp = np.zeros(s.shape[0]) s_temp[0:k] = s[0:k] s = s_temp * np.identity(s.shape[0]) # 用新的s_temp,以及p,q重构A temp = np.dot(p,s) temp = np.dot(temp,q) plt.imshow(temp, cmap=plt.cm.gray, interpolation='nearest') plt.show() print(A-temp) # 加载256色图片 image = Image.open('./256.bmp') A = np.array(image) # 显示原图像 plt.imshow(A, cmap=plt.cm.gray, interpolation='nearest') plt.show() # 对图像矩阵A进行奇异值分解,得到p,s,q p,s,q = svd(A, full_matrices=False) # 取前k个特征,对图像进行还原 get_image_feature(s, 5) get_image_feature(s, 50) get_image_feature(s, 500)

1.6 传统SVD在推荐系统中的应用
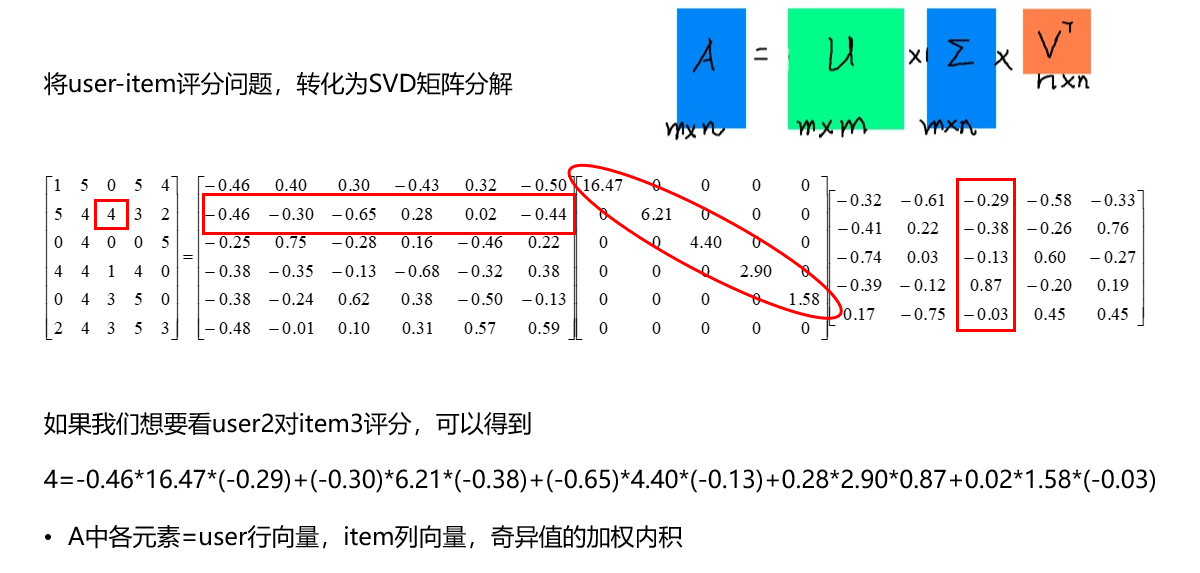
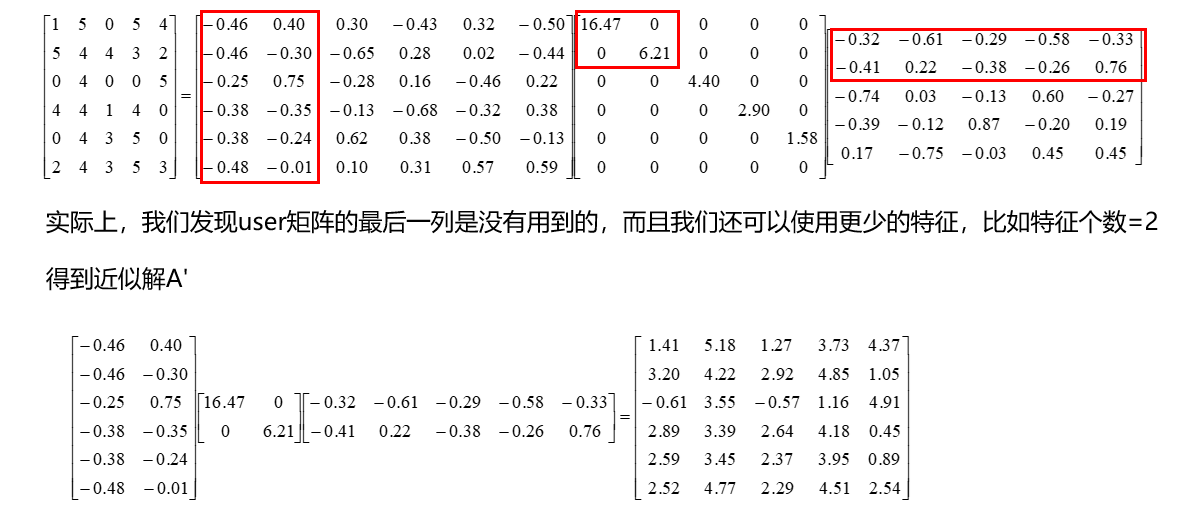
传统SVD在推荐系统中的应用
- 我们可以通过k来对矩阵降维
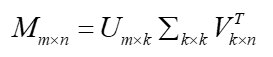
- 第i个用户对第j个物品的评分
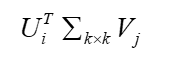
- 完整的SVD,可以将M无损的分解成为三个矩阵
- 为了简化矩阵分解,我们可以使用k,远小于min(m,n),对矩阵M近似还原
看起来完美,但忽略了一个重要的问题
传统SVD在使用上的局限:
- SVD分解要求矩阵是稠密的 => 矩阵中的元素不能有缺失
- 所以,类似于数据清洗,我们需要先对矩阵中的缺失元素进行补全
- 先有鸡,还是先有蛋。实际上传统SVD更适合做降维
存在的问题:
- 矩阵往往是稀疏的,大量缺失值 => 计算量大
- 填充方式简单粗暴 => 噪音大
1.7 SVD算法家族:FunkSVD, BiasSVD, SVD++
FunkSVD
FunkSVD算法思想:
我们需要设置k,来对矩阵近似求解
矩阵补全以后,再预测,实际上噪音大。矩阵分解之后的还原,只需要关注与原来矩阵中有值的位置进行对比即可,不需要对所有元素进行对比
解决思路:
避开稀疏问题,而且只用两个矩阵进行相乘 Mm*n = PTm*k Qk*n
损失函数=P和Q矩阵乘积得到的评分,与实际用户评分之差
让损失函数最小化 => 最优化问题

BiasSVD算法

SVD++算法

1.8 Surprise工具中的SVD
biasSVD算法
使用Surprise工具中的SVD
参数:
n_factors: k值,默认为100
n_epochs:迭代次数,默认为20
biased:是否使用biasSVD,默认为True
verbose:输出当前epoch,默认为False
reg_all:所有正则化项的统一参数,默认为0.02
reg_bu:bu的正则化参数,reg_bi:bi的正则化参数
reg_pu:pu的正则化参数,reg_qi:qi的正则化参数
funkSVD算法
使用Surprise工具中的SVD
参数:
n_factors: k值,默认为100
n_epochs:迭代次数,默认为20
biased:是否使用biasSVD,设置为False
verbose:输出当前epoch,默认为False
reg_all:所有正则化项的统一参数,默认为0.02
reg_bu:bu的正则化参数,reg_bi:bi的正则化参数
reg_pu:pu的正则化参数,reg_qi:qi的正则化参数
SVD++算法
使用Surprise工具中的SVDpp
参数:
n_factors: k值,默认为20
n_epochs:迭代次数,默认为20
verbose:输出当前epoch,默认为False
reg_all:所有正则化项的统一参数,默认为0.02
reg_bu:bu的正则化参数,reg_bi:bi的正则化参数
reg_pu:pu的正则化参数,reg_qi:qi的正则化参数
reg_yj:yj的正则化参数
1.9 Google Colab编辑器
1.10 对MovieLens进行推荐
数据集:MovieLens
下载地址:https://www.kaggle.com/jneupane12/movielens/download
主要使用的文件:ratings.csv
格式:userId, movieId, rating, timestamp
记录了用户在某个时间对某个movieId的打分情况
我们需要补全评分矩阵,然后对指定用户,比如userID为1-5进行预测
# 使用funkSVD algo = SVD(biased=False) # 定义K折交叉验证迭代器,K=3 kf = KFold(n_splits=3) for trainset, testset in kf.split(data): algo.fit(trainset) predictions = algo.test(testset) accuracy.rmse(predictions, verbose=True) uid = str(196) iid = str(302) # 输出uid对iid的预测结果 pred = algo.predict(uid, iid, r_ui=4, verbose=True)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号