
ALS矩阵分解
ALS矩阵分解
1. 推荐系统的算法都有哪些
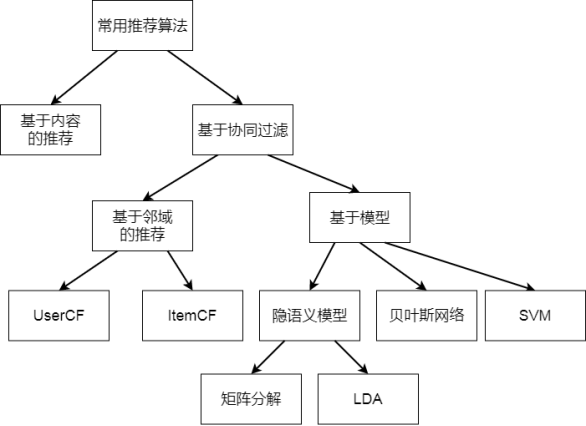
协同过滤是推荐系统的主流思想之一:
基于模型与基于邻域的推荐之间的区别:
- 基于邻域的协同过滤包括UserCF, ItemCF,将用户的所有数据读入到内存中进行运算,也称之为基于内存的协同过滤(Memory-based)。数据量少的情况下,可以在线实时推荐;
- 基于模型的推荐(Model-based),采用机器学习的方式,分成训练集和测试集。离线训练时间比较长,但训练完成后,推荐过程比较快。
- 基于邻域的协同过滤
- UserCF
- ItemCF
- 基于模型的协同过滤
- 隐语义模型(LFM, Latent Factor Model)
- 矩阵分解(MF)
- LDA, LSA, pLSA
- 基于贝叶斯网络
- 基于SVM
- 隐语义模型(LFM, Latent Factor Model)
什么是隐语义模型:
- 用户与物品之间存在着隐含的联系
- 通过隐含特征(Latent Factor)联系用户兴趣和物品,基于用户行为的自动聚类
- 我们可以指定隐特征的个数,粒度可粗(隐特征少),可细(隐特征多)
- 计算物品属于每个隐特征的权重,物品有多个隐特征的权重
- 可解释性差,隐含特征计算机能理解就好,相比之下ItemCF可解释性强
2. 什么是矩阵分解
推荐系统的两大应用场景
- 评分预测(Rating Prediction)
- 主要用于评价网站,比如用户给自己看过的电影评多少分(MovieLens),或者用户给自己看过的书籍评价多少分(Douban)。矩阵分解技术主要应用于评分预测问题。
- Top-N推荐(Item Ranking)
- 常用于购物网站,拿不到显式评分,通过用户的隐式反馈为用户提供一个可能感兴趣的Item列表。排序任务,需要排序模型进行建模。
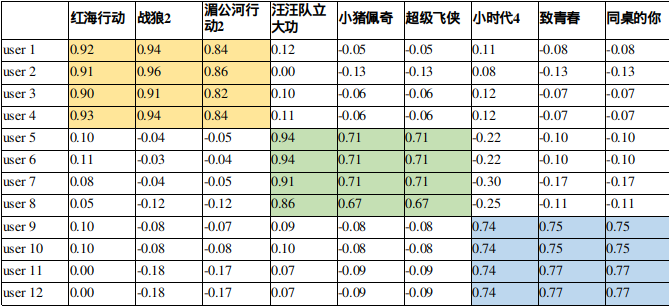
为用户找到其感兴趣的item推荐给他; 用矩阵表示收集到的用户行为数据,12个用户,9部电影;
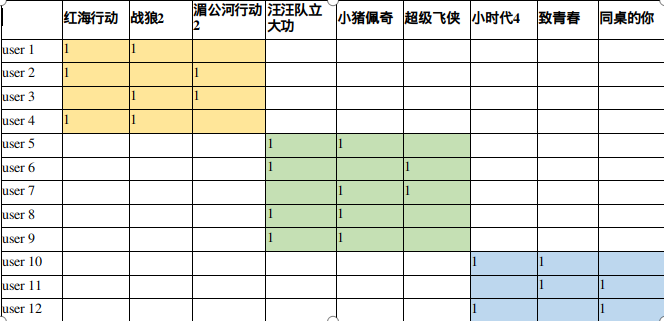
矩阵分解要做的是预测出矩阵中缺失的评分,使得预测评分能反映用户的喜欢程度。 可以把预测评分最高的前K个电影推荐给用户了。
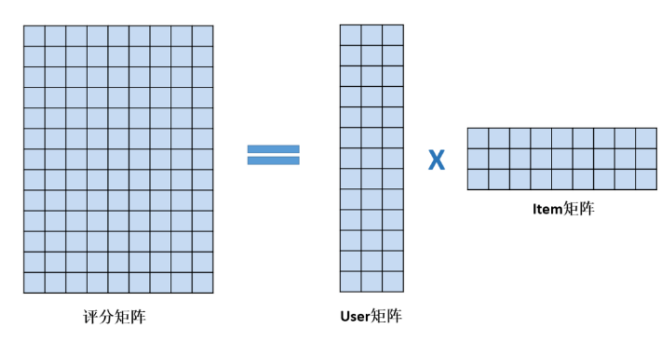
如何从评分矩阵中分解出User矩阵和Item矩阵
- 只有左侧的评分矩阵R是已知的
- User矩阵和Item矩阵是未知
- 学习出User矩阵和Item矩阵,使得User矩阵*Item矩阵与评分矩阵中已知的评分差异最小 => 即最优化问题
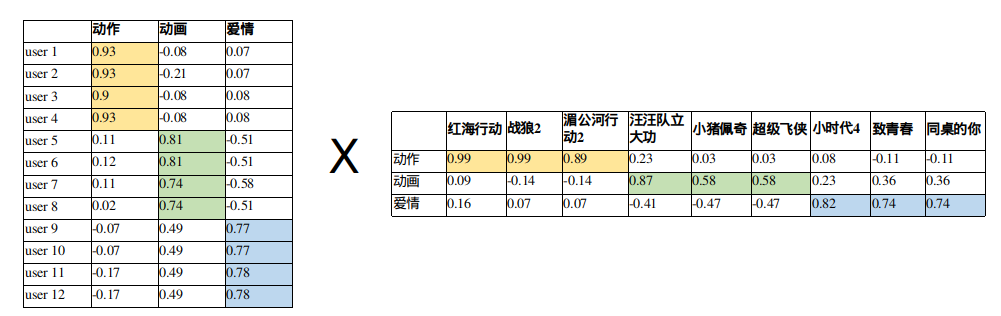
观察User矩阵:用户的听歌爱好体现在User向量上
观察Item矩阵,电影的风格也会体现在Item向量上
MF用user向量和item向量的内积去拟合评分矩阵中该user对该item的评分,内积的大小反映了user对item的喜欢程度。内积大匹配度高,内积小匹配度低。
隐含特征个数k,k越大,隐类别分得越细,计算量越大。
某个用户u对电影i 的预测评分 = User向量和Item向量的内积;
把这两个矩阵相乘,就能得到每个用户对每部电影的预测评分了,评分值越大,表示用户喜欢该电影的可能性越大,该电影就越值得推荐给用户。
3. 矩阵分解的目标函数
不知道的loss需要放到目标函数吗?答不需要,根据已知的得分去看误差,没有填不知道它真实的误差评分;
回归任务的目标函数:Σ(y - y`)2 最小;
rui 表示用户u对item i 的评分;
当rui > 0 时,表示有评分,rui = 0时表示没有评分;
xu 表示用户u的向量,k维列向量;
yi 表示item i 的向量,k维列向量;
- 用户矩阵 X, 用户数为N ,X = [x1, x2, x3,...,xN ]
- 商品矩阵Y,商品数为M,Y = [y1, y2, ..., yM ]

4. 目标函数优化问题(ALS和SGD)
目标函数最优化问题的工程解法:
- ALS,Alternating Least Squares,交替最小二乘法
- SGD,Stochastic Gradient Descent,随机梯度下降
5. ALS求解方法
ALS, Alternative Least Square, ALS,交替最小二乘法
- Step1,固定Y 优化X
- Step2,固定X 优化Y
- 重复Step1和2,直到X 和Y 收敛。每次固定一个矩阵,优化另一个矩阵,都是最小二乘问题
最小二乘法的应用
| 实验(N次) | 观测值 x |
| 1 | 9.8 |
| 2 | 9.9 |
| 3 | 9.8 |
| 4 | 10.2 |
| 5 | 10.3 |
- N次试验,每次观测值略有不同,实际观测值应该为多少?
- 观测值x = (9.8+9.9+9.8+10.2+10.3) / 5 = 10
- 为什么要用平均数,而不是中位数,或者是几何平均数?
- 最小二乘法由统计学家道尔顿(F.Gallton)提出

为什么算数平均值为实际值
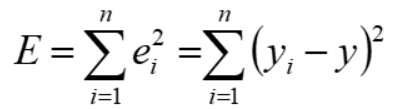
导数为0的时候为最小值,因此
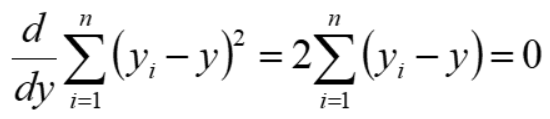
也就是 (y1 - y) + (y2 - y) + (y3 - y) + (y4 - y) + (y5 - y) = 0 ;所以:
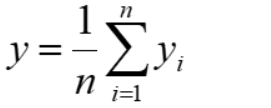
1889年道尔顿和他的朋友K.Pearson收集了上千个家庭的身高、臂长和腿长的记录,企图寻找出儿子们身高与父亲们身高之间关系的具体表现形式。
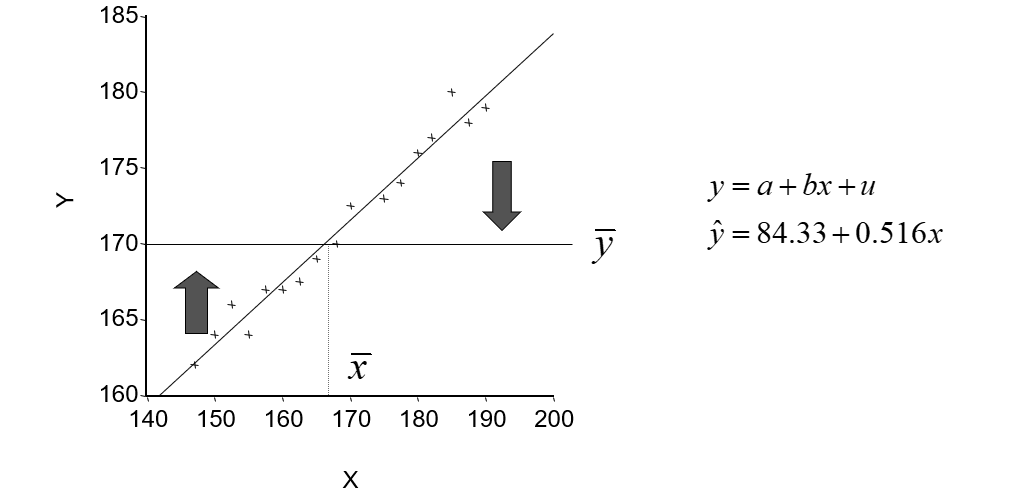
最小二乘法是一种重要的数据拟合技术; 可以应用于线性回归,非线性回归
ALS求解方法
ALS,Alternative Least Square, ALS, 交替最小二乘法;
Step1,固定Y优化X
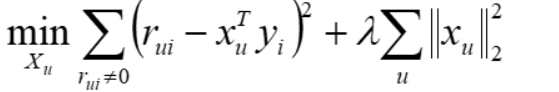
将目标函数转化为矩阵表达形式
Ru 用户u对m个物品的评分,Yu m个物品的向量
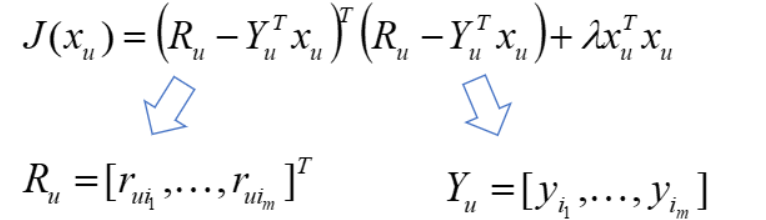
对目标函数J 关于xu 求梯度,并令梯度为0,得
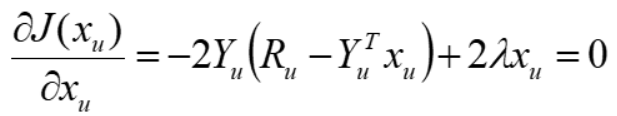
求解后可得:
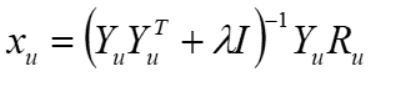
除了针对显式评分矩阵,ALS还可以对隐式矩阵进行分解:
-
- 将评分看成行为的强度,比如浏览次数、阅读时间等;
- 当rui > 0 时,用户u 对商品i 有行为;
- 当rui = 0时,用户对商品i 没有行为;
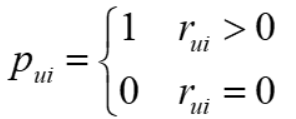
pui称为用户偏好:
当用户u 对物品i 有过行为,认为用户u 对物品i 感兴趣,pui = 1 ;
当用户u 对物品i 没有过行为,认为用户u 对物品i 不感兴趣,pui = 0;
对隐式矩阵进行分解:
引入置信度 cui = 1 + α rui
当rui > 0 时,cui 与 rui 线性递增;
当rui = 0时,cui = 1,也就是cui 最小值为1;
目标函数
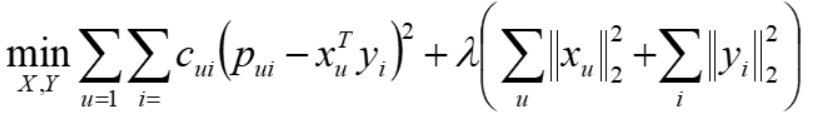
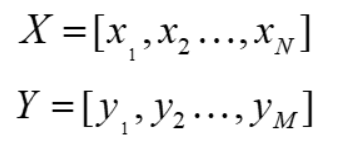
xu,yi 都为k维列向量,k为隐特征的个数;
将目标函数转化为矩阵形式,并进行求导:
Step1,固定Y 优化X
同理,求解得
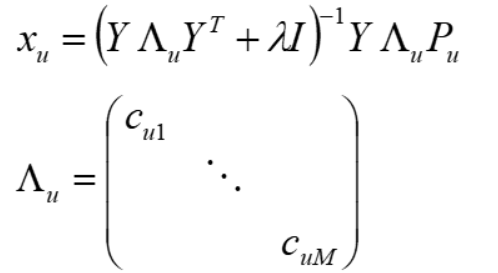
Λu 为用户u对所有物品的置信度cui 构成的对角阵;
Step2,固定X 优化Y
同理,求解得
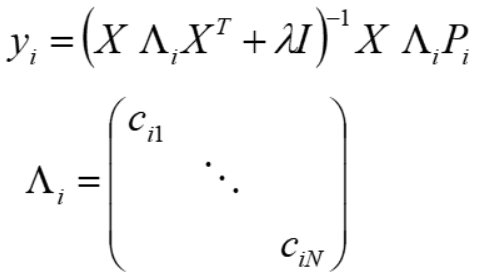
Λi 为所有用户对所有物品i 的偏好的置信度构成的对角阵;
ALS工具
- spark mllib库(spark3.0版本后废弃)
- 支持常见的算法,包括 分类、回归、聚类和协同过滤
- from pyspark.mllib.recommendation import ALS, Rating, MatrixFactorizationModel
- spark ml库(官方推荐)
- 功能更全面更灵活,ml在DataFrame上的抽象级别更高,数据和操作耦合度更低,使用起来像sklearn
- Spark安装很多坑,需要慢慢来
- Python代码
- https://github.com/tushushu/imylu/blob/master/imylu/recommend/als.py
5. Project A 对movelens进行电影推荐
数据集:MovieLens
下载地址:https://www.kaggle.com/jneupane12/movielens/download
主要使用的文件:ratings.csv
格式:userId, movieId, rating, timestamp
记录了用户在某个时间对某个movieId的打分情况
我们需要补全评分矩阵,然后对指定用户,比如userID为1-5进行预测
直接使用Python class Matrix(object): class ALS(object): X = load_movie_ratings() model = ALS() model.fit(X, k=3, max_iter=3) print("对用户进行推荐") user_ids = range(1, 5) predictions = model.predict(user_ids, n_items=2) for user_id, prediction in zip(user_ids, predictions): _prediction = [format_prediction(item_id, score) for item_id, score in prediction] print("User id:%d recommedation: %s" % (user_id, _prediction))
目标函数的优化方法
目标函数最优化问题的工程解法:
- ALS,Alternating Least Squares,交替最小二乘法
- SGD,Stochastic Gradient Descent,随机梯度下降
基本思路是以随机方式遍历训练集中的数据,并给出每个已知评分的预测评分。用户和物品特征向量的调整就沿着评分误差越来越小的方向迭代进行,直到误差达到要求。所以,SGD不需要遍历所有的
样本即可完成特征向量的求解。
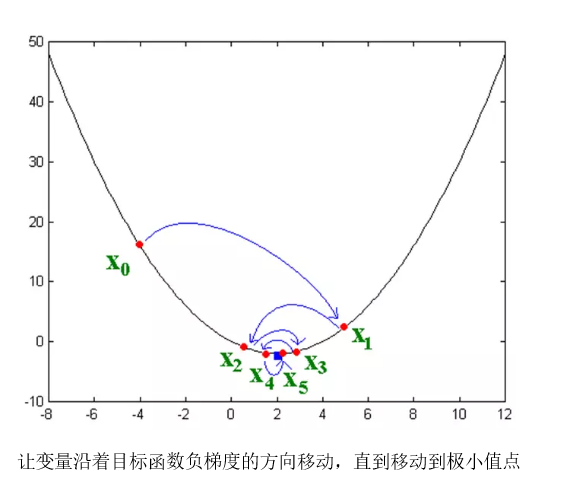
梯度下降法
hθ(x) = θ0 + θ1x1 + θ2x2 +...+ θnxn
其中θ为参数,代表权重,n为特征数,用它来建模y,需要将损失函数最小化;损失函数:
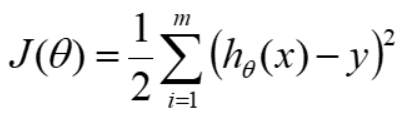
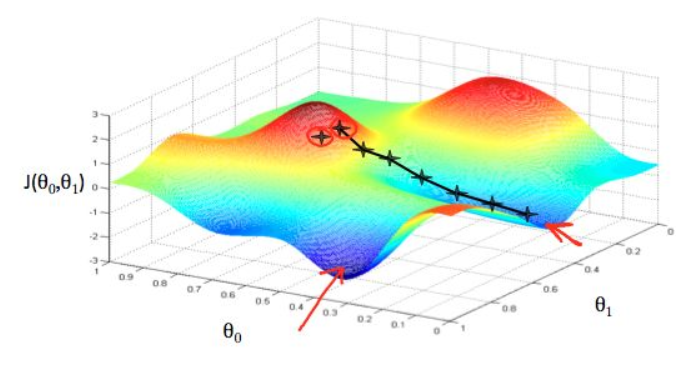
我们处于山中的某个位置,不知道极值点在哪里;
每一步,我们都以下降最多的路线来下山;
θj = θj - α∇ J(θ) ,α表示学习率(步长),(参数更新 = 原参数 - 步长*梯度向量)
曲线上方向导数的最大值的方向代表了梯度的方向;沿着梯度方法,会让h 值升高,因此我们需要沿着梯度的反方向,也就是采用梯度下降的方式进行权重更新;
梯度下降法的更新过程:
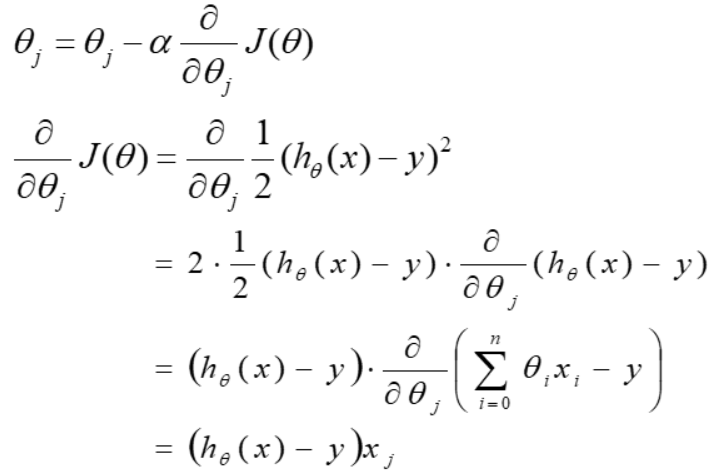
批量梯度下降
- 在每次更新时用所有样本;
- 稳定,收敛慢;
随机梯度下降
- 每次更新时用1个样本,用1个样本来近似所有的样本;
- 更快收敛,最终解在全局最优解附近;
mini-batch梯度下降
- 每次更新时用b个样本,折中方法;
- 速度较快;

6. Baseline算法
ALS和SGD作为优化方法,应用于很多优化问题
Factor in the Neighbors: Scalable and Accurate Collaborative Filtering,ACM Transactions on Knowledge Discovery from Data, 2010
Baseline算法:基于统计的基准预测线打分
- bui 预测值
- bu 用户对整体的偏差
- bi 商品对整体的偏差

BaseLine算法
使用ALS进行优化:
- Step1, 固定bu,优化bi
- Step2,固定bi, 优化bu

7. 推荐系统工具:Surprise与LightFM
Surprise
- Surprise是scikit系列中的一个推荐系统库
- 文档:https://surprise.readthedocs.io/en/stable/
LightFM
- Python推荐算法库,具有隐式和显式反馈的多种推荐算法实现。
- 易用、快速(通过多线程模型估计),能够产生高质量的结果。
Surprise中的常用算法
- Baseline算法
- 基于邻域的协同过滤
- 矩阵分解:SVD,SVD++,PMF,NMF
- SlopeOne 协同过滤算法
| 算法 | 描述 |
| NormalPredictor() | 基于统计的推荐系统打分,假定用户打分的分布是基于正态分布的 |
| BaselineOnly | 基于统计的基准预测线打分 |
| knns.KNNBase | 基本的协同过滤算法 |
| knns.KNNWithMeans | 协同过滤算法的变种,考虑每个用户的平均评分 |
| knns.KNNWithZScore | 协同过滤算法的变种,考虑每个用户评分的归一化操作 |
| knns.KNNBaseline | 协同过滤算法的变种,考虑每个用户评分的基线 |
| matrix_factorzation.SVD | SVD矩阵分解算法 |
| matrix_factorzation.SVDpp | SVD++矩阵分解算法 |
| matrix_factorzation.NMF | 一种非负矩阵分解的协同过滤算法 |
| SlopeOne | SlopeOne协同过滤算法 |
基准算法包含两个主要的算法NormalPredictor和BaselineOnly
- Normal Perdictor 认为用户对物品的评分是服从正态分布的,从而可以根据已有的评分的均值和方差 预测当前用户对其他物品评分的分数。
- Baseline算法的思想就是设立基线,并引入用户的偏差以及item的偏差
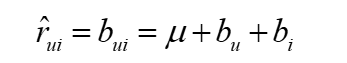
μ为所有用户对电影评分的均值
bui:待求的基线模型中用户u给物品i 打分的预估值; ---->> ALS 求得Bi和Bu,也就是评分矩阵;
bu:user偏差(如果用户比较苛刻,打分都相对偏低, 则bu<0;反之,bu>0);
bi为item偏差,反映商品受欢迎程度
使用Surprise对Movelens进行电影推荐
from surprise import Dataset from surprise import Reader from surprise import BaselineOnly, KNNBasic from surprise import accuracy from surprise.model_selection import KFold # 数据读取 reader = Reader(line_format='user item rating timestamp', sep=',', skip_lines=1) data = Dataset.load_from_file('./ratings.csv', reader=reader) train_set = data.build_full_trainset()
# Baseline算法,使用ALS进行优化 bsl_options = {'method': 'als','n_epochs': 5,'reg_u': 12,'reg_i': 5} algo = BaselineOnly(bsl_options=bsl_options) # 定义K折交叉验证迭代器,K=3 kf = KFold(n_splits=3) for trainset, testset in kf.split(data): algo.fit(trainset) predictions = algo.test(testset) accuracy.rmse(predictions, verbose=True) uid = str(196) iid = str(302) pred = algo.predict(uid, iid, r_ui=4, verbose=True)
# Baseline算法,使用SGD进行优化 bsl_options = {'method': 'sgd','n_epochs': 5} algo = BaselineOnly(bsl_options=bsl_options) # 定义K折交叉验证迭代器,K=3 kf = KFold(n_splits=3) for trainset, testset in kf.split(data): algo.fit(trainset) predictions = algo.test(testset) accuracy.rmse(predictions, verbose=True) uid = str(196) iid = str(302) pred = algo.predict(uid, iid, r_ui=4, verbose=True)
使用NormalPredictor对Movelens进行电影推荐
# NormalPredictor进行求解 algo = NormalPredictor() # 定义K折交叉验证迭代器,K=3 kf = KFold(n_splits=3) for trainset, testset in kf.split(data): algo.fit(trainset) predictions = algo.test(testset) accuracy.rmse(predictions, verbose=True) uid = str(196) iid = str(302) pred = algo.predict(uid, iid, r_ui=4, verbose=True)
Surprise推荐系统工具
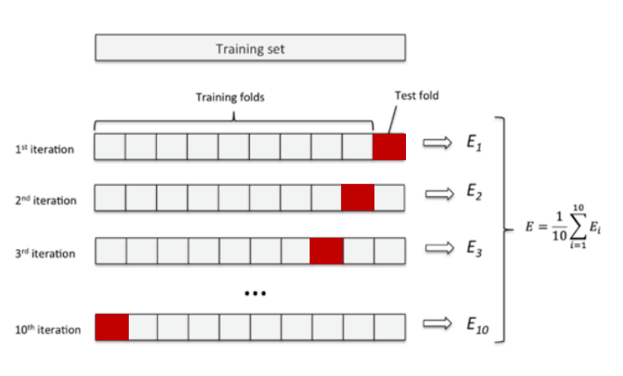
K折交叉验证
- 将训练集数据划分为K份,使用其中的K-1份作为训练集,剩余一份作为测试集
- K次误差的平均值作为泛化误差
- 所有数据都做过训练和测试,更好的利用数据
- K越大,平均误差作为泛化误差的结果就越可靠,但花费的时间也时间也越长

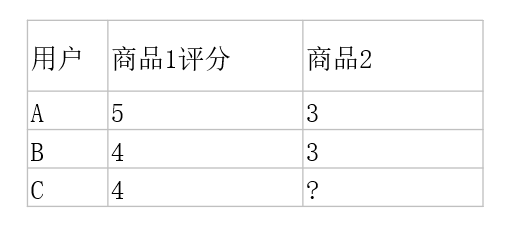
SlopeOne算法
由 Daniel Lemire在 2005 年提出的一个Item-Based 的协同过滤推荐算法
最大优点在于算法很简单, 易于实现, 效率高且推荐准确度较高。
C对商品2的评分=4-((5-3)+(4-3))/2=2.5
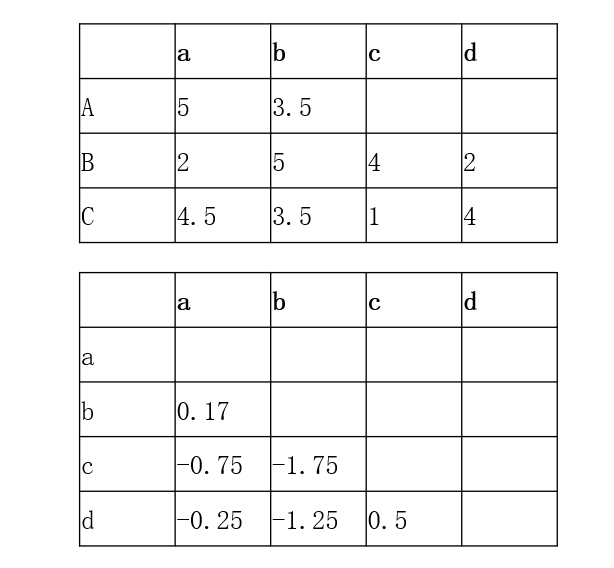
SlopeOne算法

SlopeOne算法:
Step1,计算Item之间的评分差的均值
- b与a:((3.5-5)+(5-2)+(3.5-4.5))/3=0.5/3
- c与a:((4-2)+(1-4.5))/2=-1.5/2
- d与a:((2-2)+(4-4.5))/2=-0.5/2
- c与b:((4-5)+(1-3.5))/2=-3.5/2
- d与b:((2-5)+(4-3.5))/2=-2.5/2
- d与c:((2-4)+(4-1))/2=1/2
Step2,预测用户A对商品c和d的评分
- A对c评分=((-0.75+5)+(-1.75+3.5))/2=3
- A对d评分=((-0.25+5)+(-1.25+3.5))/2=3.5
Step3,将预测评分排序,推荐给用户
- 推荐顺序为{d, c}
Daniel Lemire and Anna Maclachlan. Slope one predictors for online rating-based
collaborative filtering. 2007. http://arxiv.org/abs/cs/0702144.
加权算法 Weighted Slope One
如果有100个用户对Item1和Item2都打过分, 有1000个用户对Item3和Item2也打过分,显然这两个rating差的权重是不一样的,因此计算方法为:
(100*(Rating 1 to 2) + 1000(Rating 3 to 2)) / (100 + 1000)

SlopeOne算法的特点:
- 适用于item更新不频繁,数量相对较稳定
- item数<<user数
- 算法简单,易于实现,执行效率高
- 依赖用户行为,存在冷启动问题和稀疏性问题
# 使用SlopeOne算法 algo = SlopeOne() algo.fit(train_set) # 对指定用户和商品进行评分预测 uid = str(196) iid = str(302) pred = algo.predict(uid, iid, r_ui=4, verbose=True)
Surprise推荐系统工具
# 相似度计算,使用皮尔逊相似度计算法,使用ItemCF的相似度计算 sim_options = {'name': 'pearson_baseline', 'user_based': False} # 使用KNNBaseline算法,一种CF算法 algo = KNNBaseline(sim_options=sim_options) algo.fit(train_set) #获得电影名称信息数据 rid_to_name, name_to_rid = read_item_names() #获得Toy Story电影的电影ID toy_story_raw_id = name_to_rid['Toy Story (1995)'] print(toy_story_raw_id) #通过Toy Story电影的电影ID获取该电影的推荐内部id toy_story_inner_id = algo.trainset.to_inner_iid(toy_story_raw_id) print(toy_story_inner_id)
summary
MF是一种隐语义模型,它通过隐类别匹配用户和item来做推荐。
MF对原有的评分矩阵R进行了降维,分成了两个小矩阵:User矩阵和Item矩阵,User矩阵每一行代表一个用户的向量,Item矩阵的每一列代表一个item的向量。将User矩阵和Item矩阵的维度降低到隐类
别个数的维度。
根据用户行为,矩阵分解分为显式矩阵分解和隐式矩阵
在显式MF中,用户向量和物品向量的内积拟合的是用户对物品的实际评分
在隐式MF中,用户向量和物品向量的内积拟合的是用户对物品的偏好(0或1),拟合的强度由置信度控制,置信度又由行为的强度决定
ALS和SGD都是数学上的优化方法,可以解决最优化问题(损失函数最小化)
ALS-WR算法,可以解决过拟合问题,当隐特征个数很多的时候也不会造成过拟合
ALS,SGD都可以进行并行化处理
SGD方法可以不需要遍历所有的样本即可完成特征向量的求解
Facebook把SGD和ALS两个算法进行了揉合,提出了旋转混合式求解方法,可以处理1000亿数据,效率比普通的Spark MLlib快了10倍
python开源推荐系统,包含了多种经典的推荐算法
官方文档:https://surprise.readthedocs.io/en/stable/
数据集:可以使用内置数据集(Movielens等),也可以自定义数据集
优化算法:支持多种优化算法,ALS,SGD
预测算法:包括基线算法,邻域方法,矩阵分解,SlopeOne等
相似性度量:内置cosine,MSD,pearson等
scikit家族,可以使用GridSearchCV自动调参,方便比较各种算法结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号