
深度学习| 卷积神经网络CNN与典型结构
神经网络与卷积神经网络
卷积神经网络会很频繁的用在计算机视觉中,同样也会应用到自然语言处理中的情感分析等;
从神经网络到卷积神经网络
- DNN能用到计算机视觉上吗?为什么需要CNN?
- 卷积神经网络和人工神经网络的差异在哪?
① 图像三维矩阵,跟输入的维度没有关系,采集到的数据单个样本的维度很高,256*256*3 10w的维度,第二层给个2^n 4096个,中间会有4亿个以上的参数w;若干层加在一起参数会非常非常大,有可能会过拟合;
② 神经网络的计算不会放在CPU上,而是放GPU上,显卡比CPU是要贵的而且它的存储也是有限的;这么多东西存在GPU上对计算也是压力很大的;
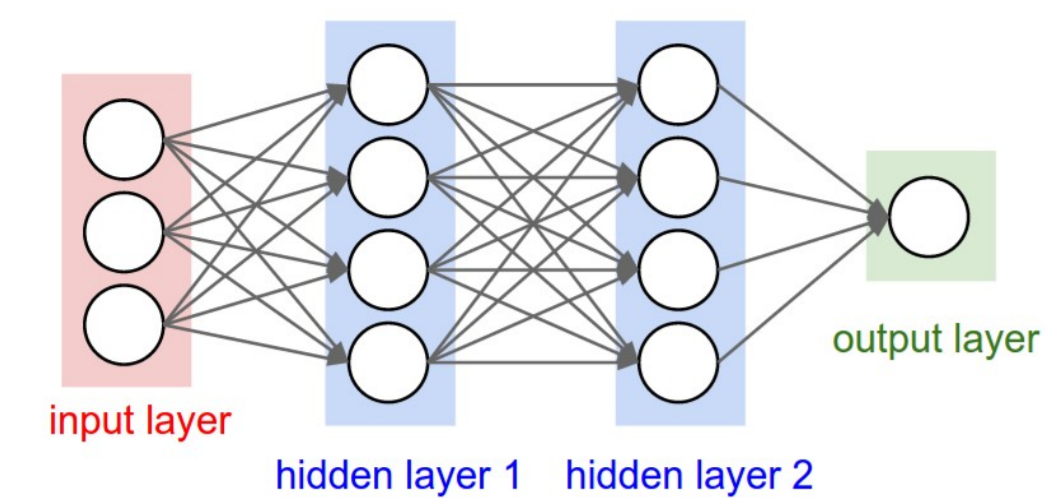
1.层级结构
保持了层级网络结构;
不同层次有不同形式(运算)与功能;
输入X,输出一个概率向量score,经过若干层的处理;

主要是以下层次:
- 数据输入层/ Input Iayer
- 卷积计算层/ CONV Iayer
- 激励层/ Activation Iayer
- 池化层/ Pooling layer
- 全连接层/ FC Iayer
- Batch Normal i zation层(可能有)
数据输入层/ Input Iayer
有3种常见的数据处理方式
resize: 输入的图片大小可能是不一样的,统一为同一个维度,一模一样的大小方便神经网络去用相同参数去做计算;
- 去均值(把输入数据各个维度都中心化到0)
- 归一化(幅度归一化到同样的范围)
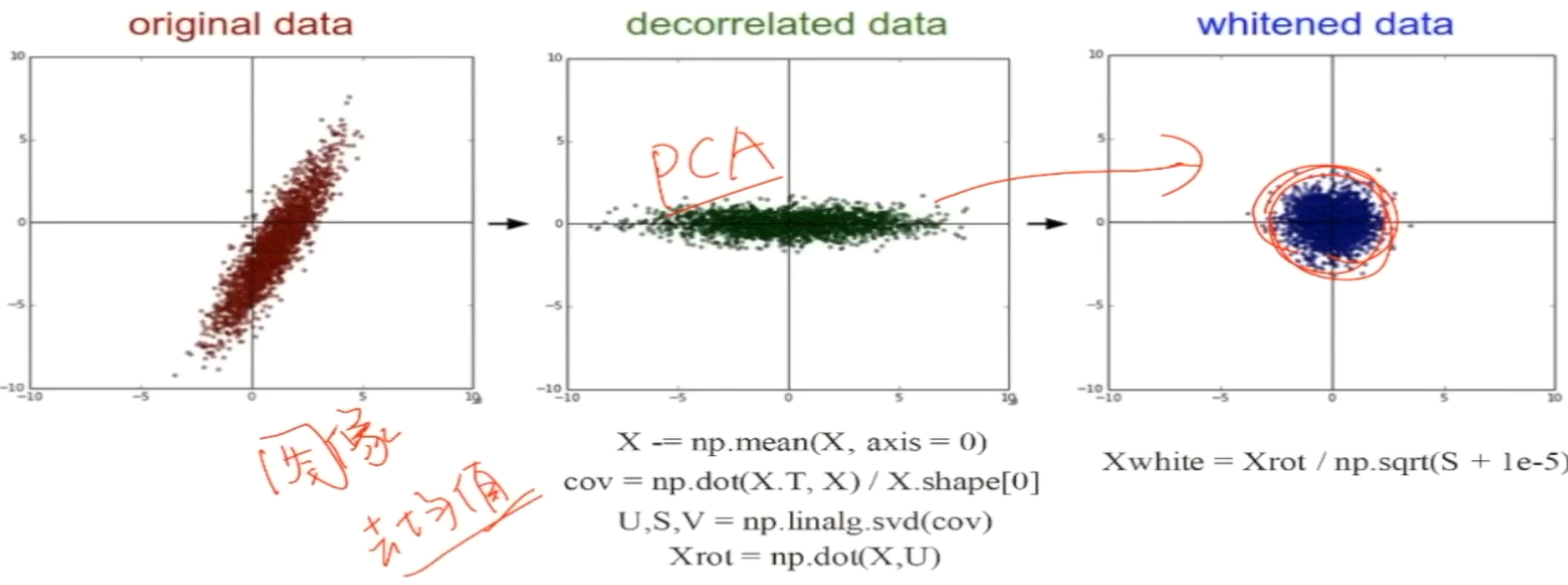
- PCA/ 白化(用PCA降维;白化是对数据每个特征轴上的幅度归一化)
去均值与归一化
中心,幅度归一化到同样的幅度;

去相关与白化
X - mean(X) ,image 256*256*3的矩阵,100w的矩阵对应的位置求均值;
VGG,R/G/B三个颜色通道,分别求均值做个差值;
图像数据只做去均值,每幅图每个像素点的RGB的取值只可能是0~255之间的;
卷积计算层/ CONV Iayer
- 局部关联,每个神经元看做一个filter;(一幅图会很大,但是局部区域里的信息是比较具体的,局部区域中像素点的RGB颜色变化是有种连续型变化在里面的)
- 窗口(receptive field 比如3*3窗口大小)滑到,filter对局部数据计算; (通过滑窗的方式去看到每个窗口内的数据)
- 涉及概念:
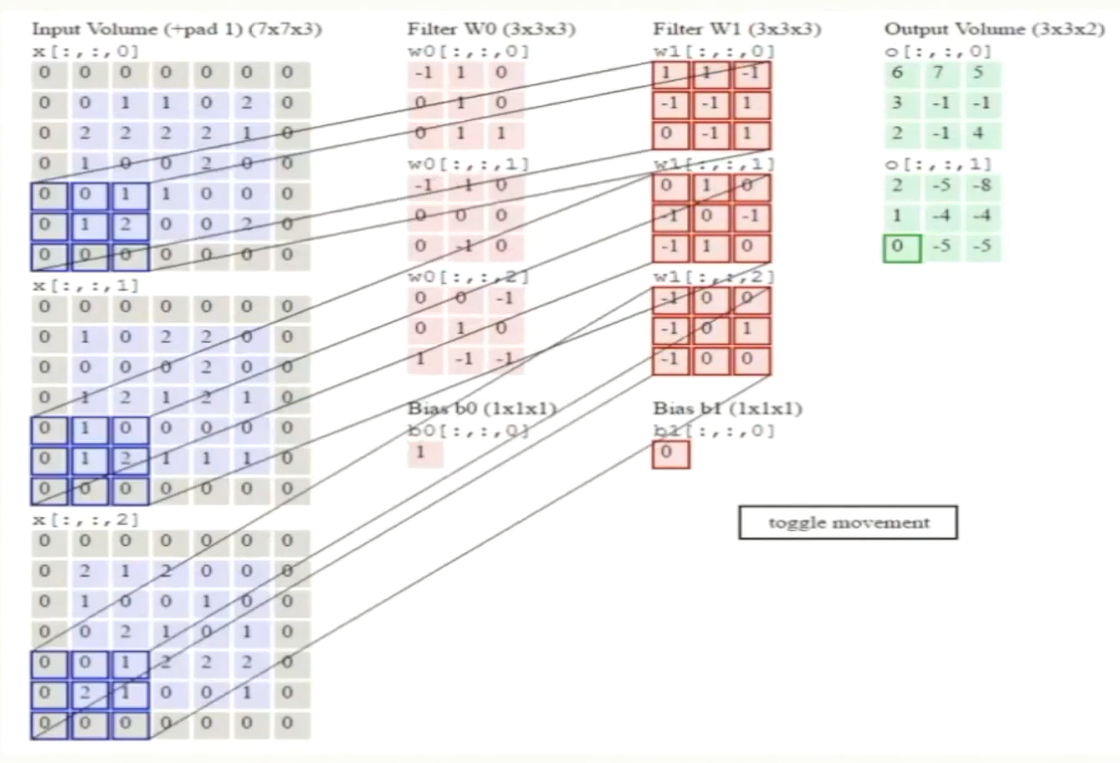
- 深度/ depth (每个神经元会对原始图片做处理,会得到一个特征图矩阵,每个神经元都会得到一个特征图矩阵,有多少个神经元就有多少层,神经元的个数即深度)
- 步长/ stride (每次滑窗滑多少格)
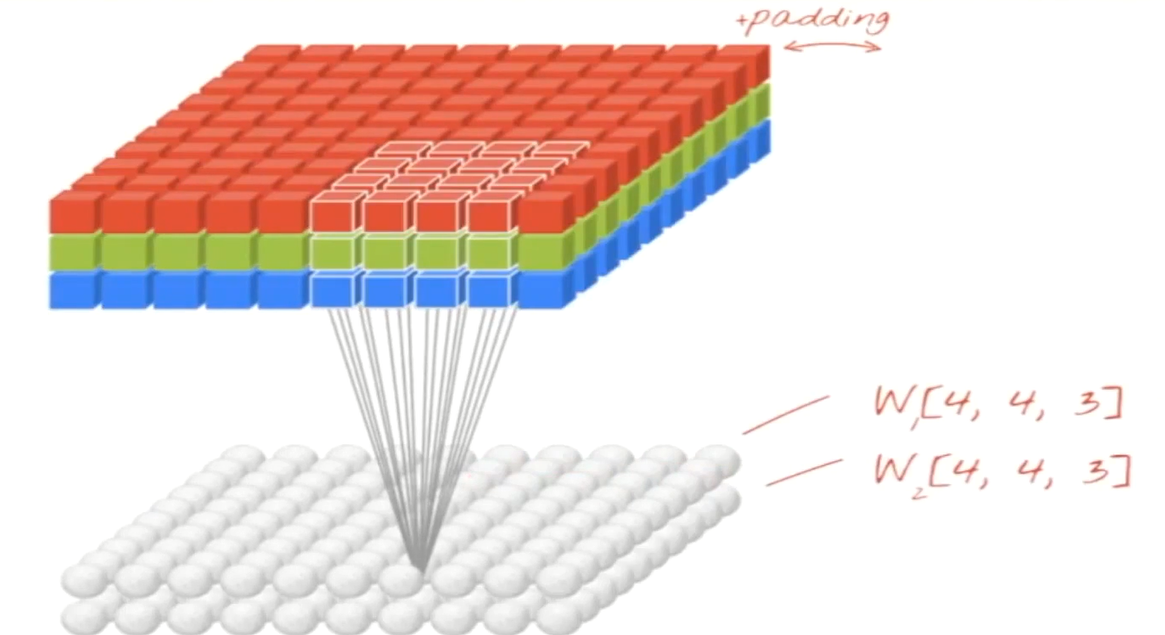
- 填充值/ zero-padding (每经过一个卷积层它的特征图就会变小一点,到后面就收缩没了,为了防止这个事情在它的周边补了0,把它的框框变大点,最后就可以得到32*32*3)
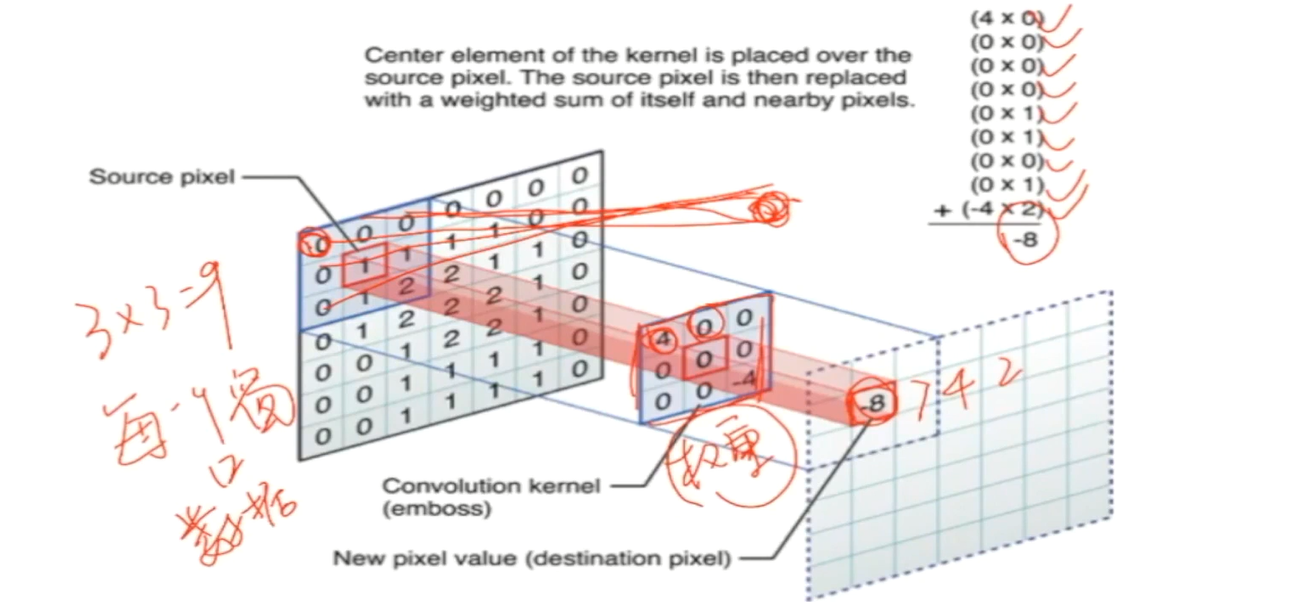
32*32*3,特征图矩阵 ;

1个神经元去和3*3的窗口去连接得到3*3=9个W,source pixel 去和convolution kernel做点乘(每一个窗口数据会和权重做计算拿到一个结果值),4*0 + 0*0 + ...+ (-4*2) = -8 ; 最后得到一个值;
窗口会滑动,但是权重会保持不变;用一组一模一样的权重去和滑窗当中遇到的不同的数据去做计算,每算出一个值就把它填到上面-8、7、4、2等;
- 参数共享机制;
- 假设每个神经元连续数据窗的权重是固定的;(固定住一组权重去和滑动窗口内的数据去做内积,这是一个很明显的卷积)
- 固定每个神经元连接权重,可以看做模板;
- 每个神经元只关注一个特性;
- 需要估算的权重个数减少:一层1亿 => 3.5w
- 一组固定的权重和不同窗口内数据做内积:卷积

激励层(ReLU)
把卷积层输出结果做非线性映射
- Sigmoid
- Tanh(双曲正切)
- ReLU
- Leeky ReLU
- ELU
- Maxout
- ...
sigmoid和tanh双曲正切用的都不太多了,因为他们两个两边的梯度约等于0,方向传播是每层导数相乘, 如果有一个猪队友的导数约等于0了那么相乘就都等于0了;
Relu分段函数,左边求导为0,右边y=x求导就是1;

激励层
- CNN慎用sigmoid!慎用sigmoid!慎用sigmoid!
- 首先试RELU,因为快,但要小心点;
- 如果2失效,请用Leaky ReLU或者Maxout;
- 某些情况下tanh倒是有不错的结果,但是很少;
池化层/下采样层 Pooling Iayer
- 夹在连续的卷积层中间;
- 压缩数据和参数的量,减小过拟合;

下采样的方法包括:
- Max pooling (比如有个2*2的滑窗,步长stride为2;最大的值保持了里面最显著的特性)
- average pooling

全连接层/ FC Iayer
- 两层之间所有神经元都有权重连接;
- 通常全连接层在卷积神经网络尾部;
典型的CNN结构为
- INPUT
- [[ CONV -> RELU ] * N -> POOL ?] * M
- [ FC -> RELU ] * K
- FC
2.卷积可视化理解


前向运算,第一次卷积层之后拿到一个filters(滑窗的W),把一部分的filters拿出来之后可视化得到是如下左侧图,原始图片和filters做一个卷积运算拿到一个特征图矩阵,可视化得到如下右图;
有些filters关注轮廓,有些filters关注颜色的深浅,有些filters关注边缘的东西等;每个filters每组不同的权重在滑窗滑动的过程中这组权重都是在捕捉某种特定的模式,这种模式可能是图像的轮廓、颜色、深浅、纹理等;

第二个卷积层,我们已经很难分辨出它是在捕捉什么信息了;

再往后完全无法理解了;

3.训练算法
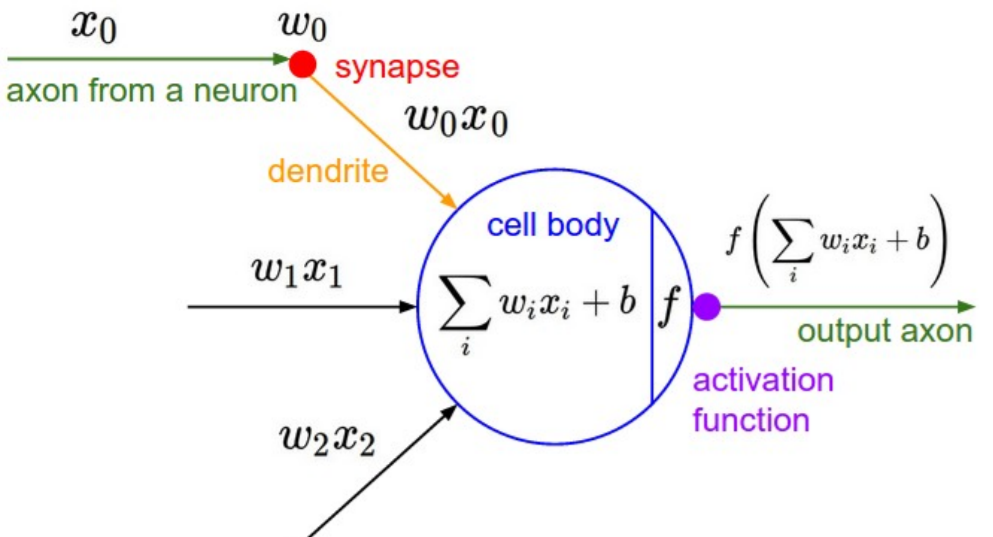
卷积神经网络和深度神经网络、人工神经网络其实没有太大的区别,唯一的区别在于,之前的神经网络就是一堆 Wx+b过一个激活函数 f (Wx + b);
现在不是每一层都是这个运算了,卷积层可能是某种运算、池化层可能是另外一种运算、激活层可能是另外一种运算;
Relu左边导数为0它不会产生梯度消失吗,有可能会;但是我们一般不是一张一张图片去做训练,而是一个batch一个batch送进去去做训练;加入落在Relu左边的概率为1/2,128中图都落在左边的概率有多大呢,这种情况是比较小的;
- 同一般机器学习算法,先定义Loss function,衡量和实际结果之间的差距;
- 找到最小化损坏函数的W和b,CNN中用的算法是SGD ;
- SGD需要计算W和b的偏导;
- BP算法就是计算偏导用的;
- BP算法的核心是求导链式法则;
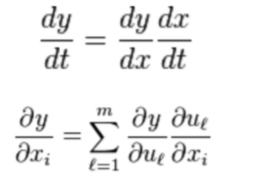
BP算法利用链式求导法则,逐级相乘直到求解出dw和db ;
利用SGD/ 随机梯度下降法,迭代和更新w和b
4.优缺点
优点
- 共享卷积核,优化计算量;
- 无需手动选取特征,训练好权重,即得特征;
- 深层次的网络抽取图像信息丰富,表达效果好;
缺点
- 需要调参,需要大样本量,GPU等硬件依赖;
- 物理含义不明确;
正则化与Dropout
1.正则化与Dropout处理
神经网络学习能力强可能会过拟合;
Dropout(随机失活)正则化:别一次开启所有学习单元
Regularization: Dropout
“randomly set some neurons to zero in the forward pass”
给每个神经元按上一个开关,这个开关会有一定几率打开;下图左边是全连接的神经网络,右边是打开了开关的神经网络,打开开关之后信息是不会 通过的;这个是在前向运算的时候随机的去把一个神经元开关打开;
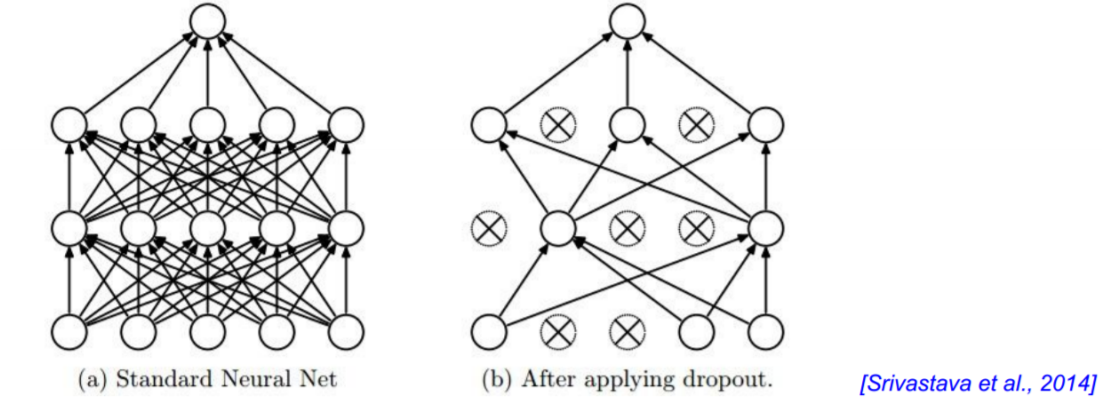
Dropout
E(x) = P*x + (1-P) * 0=Px;
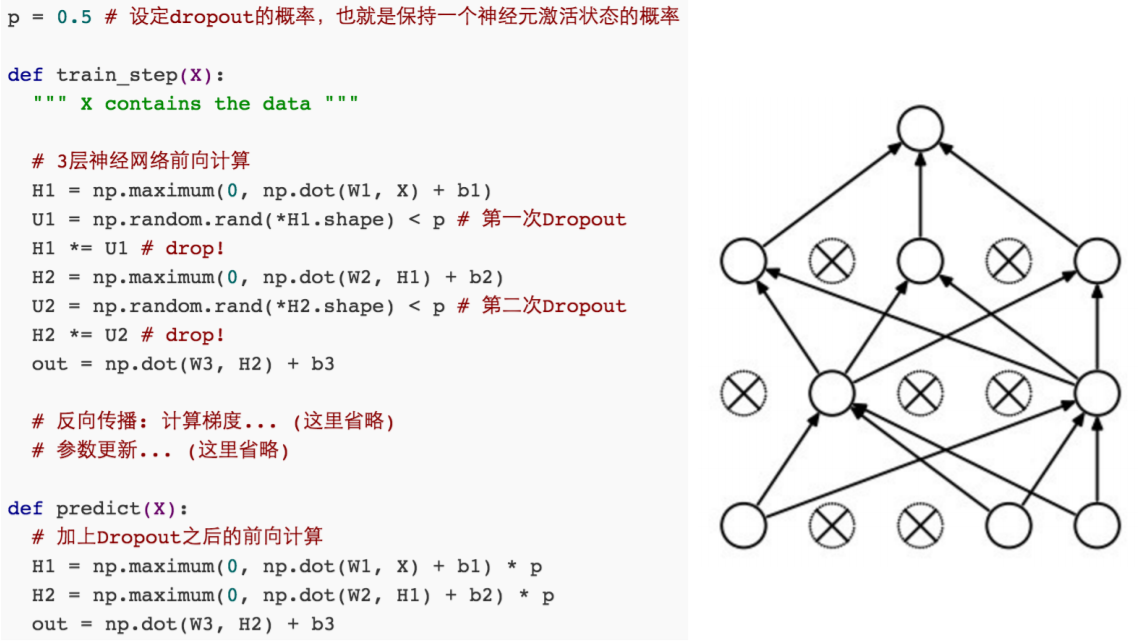
实际实现:把预测阶段的时间转移到训练上

2.Dropout理解
防止过拟合的第1种理解方式
- 别让你的神经网络记住那么多东西(虽然CNN记忆力好);
- 学习的过程中,保持泛化能力;
比如有些神经元,它有两只耳朵,这些信息就可以不要的,猫和狗都有两个耳朵,所以可以给它随机去掉;

防止过拟合的第2种理解方式(模型融合):
- 每次都关掉一部分感知器,得到一个新模型,最后做融合,不至于听一家所言;

对Dropout想要有更细致的了解,参见
《Dropout: A Simple Way to Prevent Neural Networks from Overfitting》 2014, Hinton, etc
《Dropout Training as Adaptive Regularization》 2013, Stefan Wager, etc
典型结构与训练
1.典型CNN
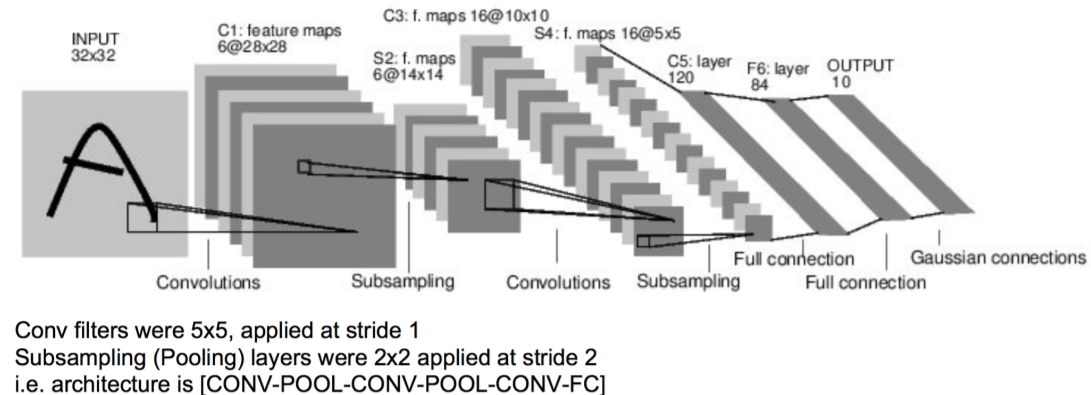
- LeNet, 这是最早用于手写数字识别的CNN;
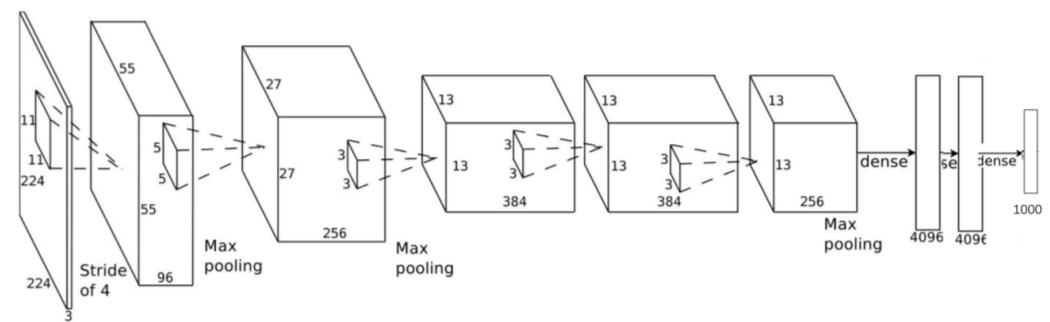
- AlexNet, 2012ILSVRC比赛远超第2名的CNN,比LeNet更深,用多层小卷积层叠加替换单大卷积层;
- ZF Net,2013ILSVRC比赛冠军;
- GoogLeNet, 2014ILSVRC比赛冠军;
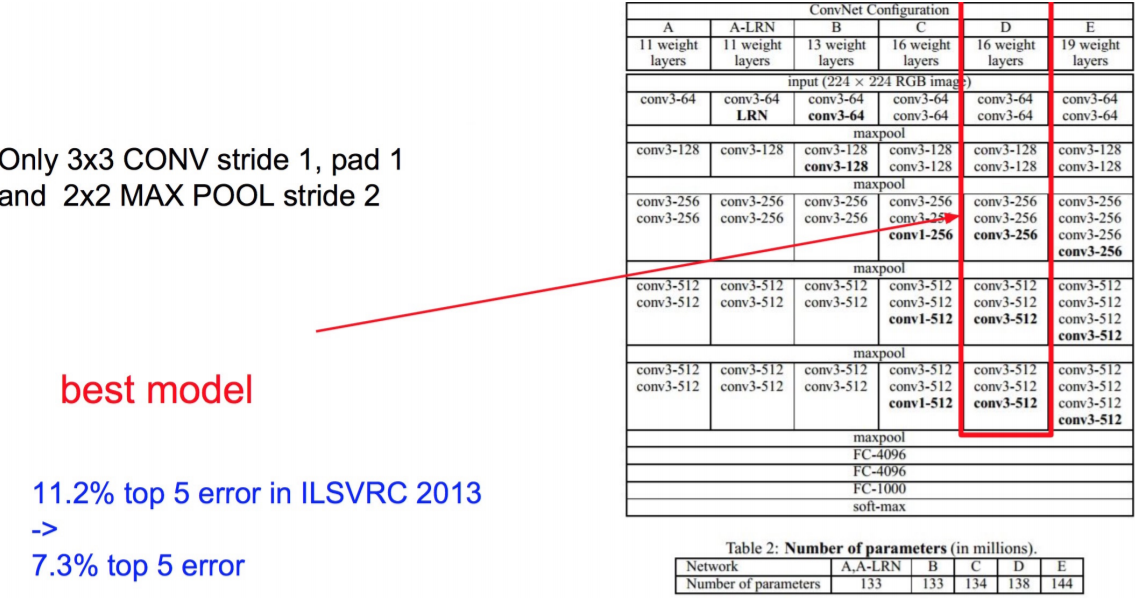
- VGGNet,2014ILSVRC比赛中的模型,图像识别略差于GoogLeNet,但是在很多图像转化学习问题(比如object detection)上效果很好;
- ResNet,2015ILSVRC比赛冠军,结构修正(残差学习)以适应深层次CNN训练;
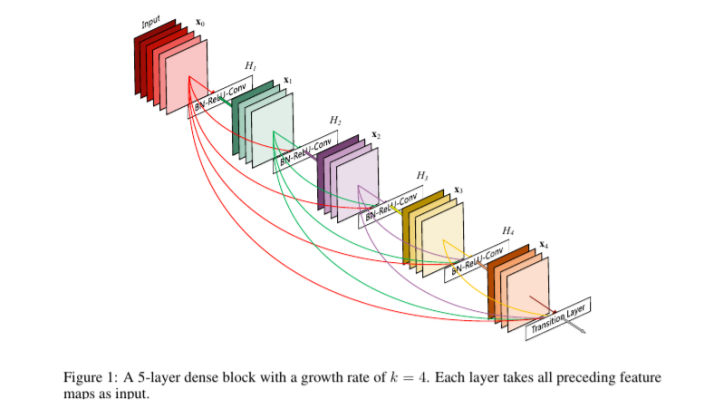
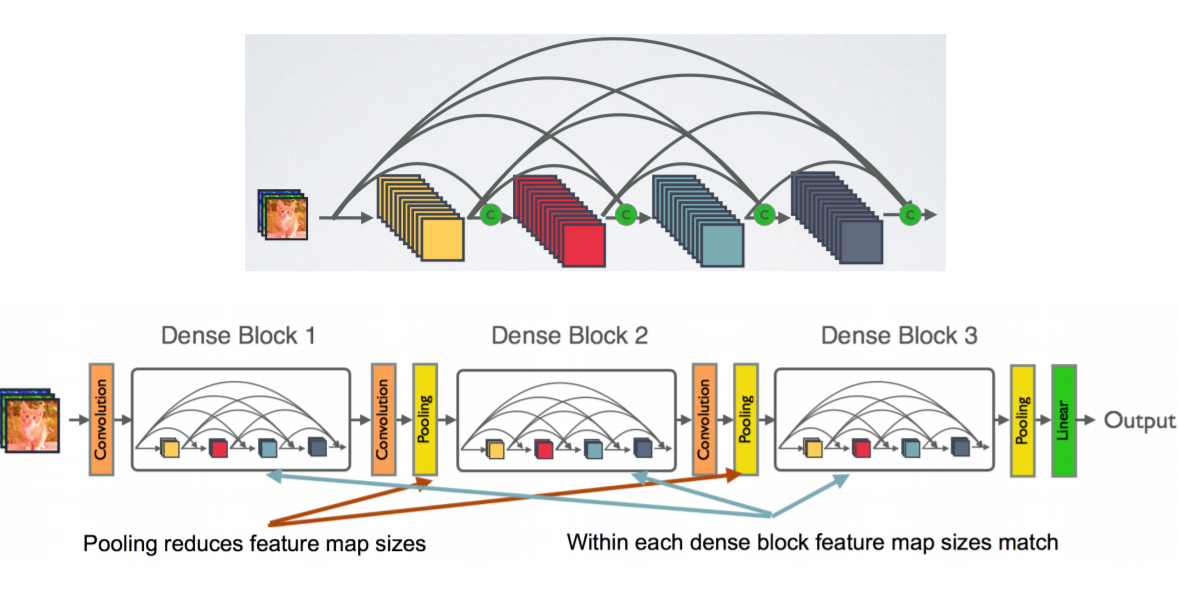
- DenseNet,CVPR2017best paper, 把ResNet的add变成concat
LeNet

AlexNet
2012Imagent比赛第一,Top5准确度超过第二10%;
The number of neurons in each layer is given by 253440,186624,64896,64896,43264,4096,4096,1000

ZFNet

VGG
VGG它的参数量太大了;


GoogLeNet
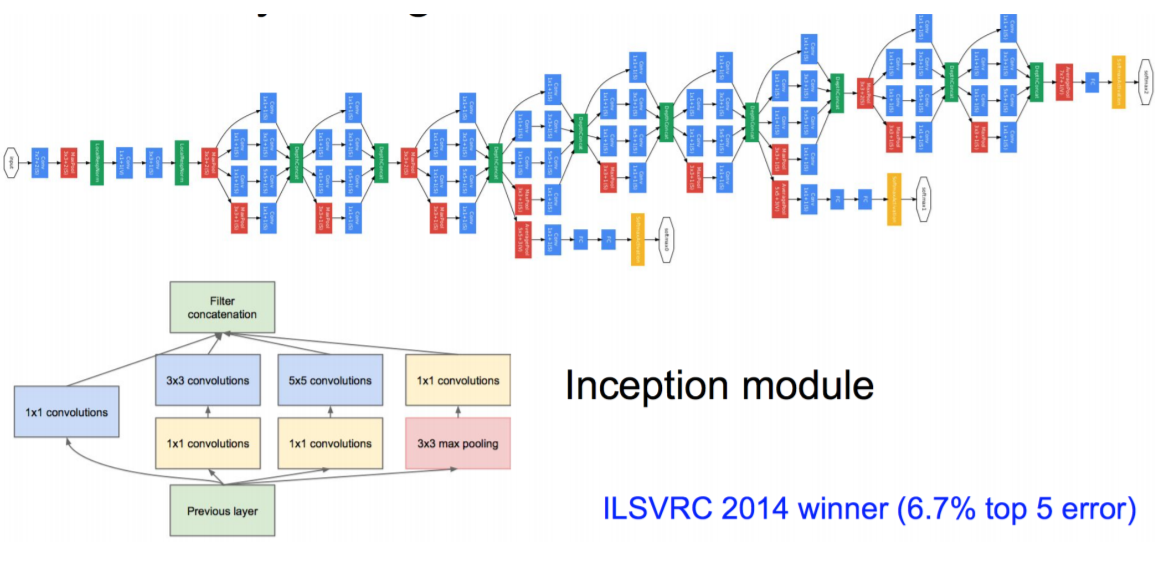
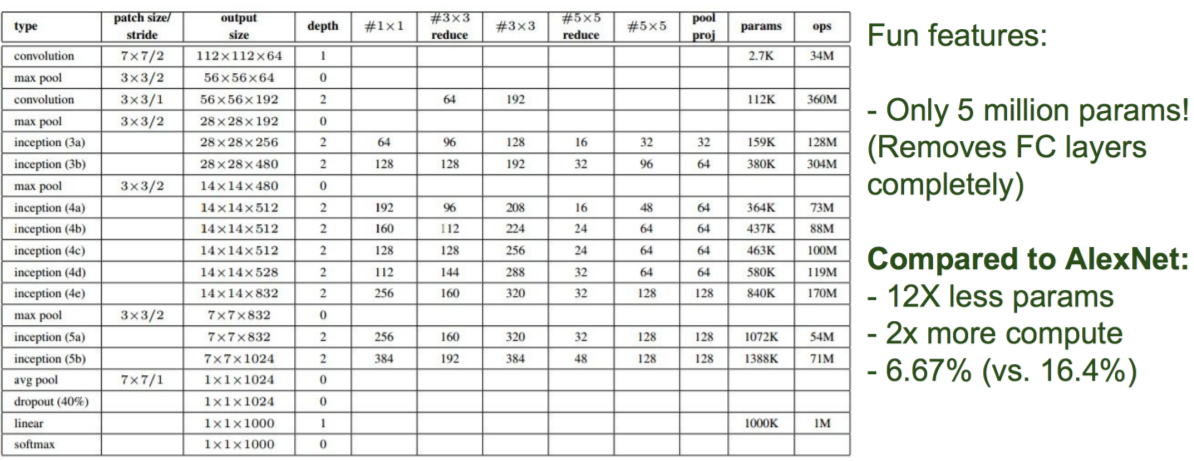
ResNet,即Deep Residual Learning network
微软亚洲研究院提出,ILSVRC 2015冠军比VGG还要深8倍;

DenseNet,CVPR2017 best paper
2.训练与调优
The number of neurons in each layer is given by 253440,186624,64896,64896,43264,4096,4096,128, 95
fine - turning


'''Trains a simple convnet on the MNIST dataset. Gets to 99.25% test accuracy after 12 epochs (there is still a lot of margin for parameter tuning). 16 seconds per epoch on a GRID K520 GPU. ''' from __future__ import print_function import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten from keras.layers import Conv2D, MaxPooling2D from keras import backend as K batch_size = 128 num_classes = 10 epochs = 12 # input image dimensions img_rows, img_cols = 28, 28 # the data, shuffled and split between train and test sets (x_train, y_train), (x_test, y_test) = mnist.load_data() if K.image_data_format() == 'channels_first': x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols) x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols) input_shape = (1, img_rows, img_cols) else: x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1) x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1) input_shape = (img_rows, img_cols, 1) x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 print('x_train shape:', x_train.shape) print(x_train.shape[0], 'train samples') print(x_test.shape[0], 'test samples') # convert class vectors to binary class matrices y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes) model = Sequential() model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape)) model.add(Conv2D(64, (3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(num_classes, activation='softmax')) model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adadelta(), metrics=['accuracy']) model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test)) score = model.evaluate(x_test, y_test, verbose=0) print('Test loss:', score[0]) print('Test accuracy:', score[1])
输出
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 11490434/11490434 [==============================] - 3s 0us/step x_train shape: (60000, 28, 28, 1) 60000 train samples 10000 test samples 2023-04-10 16:36:18.312444: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcuda.so.1'; dlerror: libcuda.so.1: cannot open shared object file: No such file or directory 2023-04-10 16:36:18.319280: W tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:265] failed call to cuInit: UNKNOWN ERROR (303) 2023-04-10 16:36:18.319367: I tensorflow/compiler/xla/stream_executor/cuda/cuda_diagnostics.cc:156] kernel driver does not appear to be running on this host (mi): /proc/driver/nvidia/version does not exist 2023-04-10 16:36:18.325515: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags. 2023-04-10 16:36:18.938274: W tensorflow/tsl/framework/cpu_allocator_impl.cc:82] Allocation of 188160000 exceeds 10% of free system memory. Epoch 1/12 2023-04-10 16:36:20.955723: W tensorflow/tsl/framework/cpu_allocator_impl.cc:82] Allocation of 18874368 exceeds 10% of free system memory. 2023-04-10 16:36:21.204782: W tensorflow/tsl/framework/cpu_allocator_impl.cc:82] Allocation of 18874368 exceeds 10% of free system memory. 2023-04-10 16:36:21.234390: W tensorflow/tsl/framework/cpu_allocator_impl.cc:82] Allocation of 23887872 exceeds 10% of free system memory. 2023-04-10 16:36:21.234427: W tensorflow/tsl/framework/cpu_allocator_impl.cc:82] Allocation of 23887872 exceeds 10% of free system memory. 469/469 [==============================] - 45s 94ms/step - loss: 2.2854 - accuracy: 0.1482 - val_loss: 2.2606 - val_accuracy: 0.2815 Epoch 2/12 469/469 [==============================] - 44s 94ms/step - loss: 2.2449 - accuracy: 0.2425 - val_loss: 2.2113 - val_accuracy: 0.3996 Epoch 3/12 469/469 [==============================] - 43s 92ms/step - loss: 2.1933 - accuracy: 0.3307 - val_loss: 2.1450 - val_accuracy: 0.5183 Epoch 4/12 469/469 [==============================] - 45s 96ms/step - loss: 2.1225 - accuracy: 0.4145 - val_loss: 2.0536 - val_accuracy: 0.6163 Epoch 5/12 469/469 [==============================] - 43s 92ms/step - loss: 2.0274 - accuracy: 0.4821 - val_loss: 1.9311 - val_accuracy: 0.6766 Epoch 6/12 469/469 [==============================] - 45s 95ms/step - loss: 1.8990 - accuracy: 0.5367 - val_loss: 1.7713 - val_accuracy: 0.7245 Epoch 7/12 469/469 [==============================] - 41s 88ms/step - loss: 1.7439 - accuracy: 0.5770 - val_loss: 1.5789 - val_accuracy: 0.7577 Epoch 8/12 469/469 [==============================] - 42s 90ms/step - loss: 1.5707 - accuracy: 0.6137 - val_loss: 1.3702 - val_accuracy: 0.7876 Epoch 9/12 469/469 [==============================] - 44s 94ms/step - loss: 1.4002 - accuracy: 0.6384 - val_loss: 1.1769 - val_accuracy: 0.8000 Epoch 10/12 469/469 [==============================] - 40s 86ms/step - loss: 1.2552 - accuracy: 0.6644 - val_loss: 1.0181 - val_accuracy: 0.8111 Epoch 11/12 469/469 [==============================] - 38s 81ms/step - loss: 1.1376 - accuracy: 0.6812 - val_loss: 0.8957 - val_accuracy: 0.8206 Epoch 12/12 469/469 [==============================] - 43s 92ms/step - loss: 1.0473 - accuracy: 0.6987 - val_loss: 0.8027 - val_accuracy: 0.8285 Test loss: 0.8026718497276306 Test accuracy: 0.828499972820282



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律