
十五. 支持向量机
支持向量机的核心思想
支持向量机在机器学习领域中扮演着举足轻重的角色,应该算是前深度学习时代最重要的产物。即便现在,对于很多分类问题我们也倾向于使用支持向量机如文本分类、疾病分类等等。之所以支持向量
机受到如此的关注,主要原因归类为以下几点:
- 从模型的效果来说确实比较优秀,甚至很多时候可以媲美比它更复杂的深度学习模型
- 核技巧(kernel trick)和支持向量机的结合极大推动这个领域的发展
- 对于支持向量机的研究同时也推动了对机器学习理论领域的发展如PAC的学习,VC维度等
对于第三点,可以简单理解为SVM的研究推动了机器学习理论的发展。
对于逻辑回归模型, 它的目标函数为交叉熵损失函数(cross-entropy loss function)。问题: 对于某一个样本,利用模型预测出来的标签0和标签1的输出概率分别为(0.3, 0.7), 而样本真实标签为1, 那么交叉熵
损失为多少?
损失为 -(log 0.3 * 0 + log 0.7 * 1) = −log0.7
对于分类任务, 很多时候我们的最终目的是提升分类器的准确率(或者降低分类错误率), 但从模型的角度我们通常使用交叉熵损失函数。问题: 能不能把错误率作为分类器的目标函数, 然后最小化错误率?
实际是可以的,除了准确率, 我们甚至也可以把AUC, F1-Score当做最终的目标来对待。
如果把最大化分类器的准确率或者最小化错误率当作是函数的目标,主要会存在什么样的问题?
不利于优化,错误率和交叉熵有着”类似“正比的关系, 也就是当交叉熵变小时分类器错误率下降; 当交叉熵变大时, 分类器错误率上升, 其实可以认为是一个近似的过程。
最大化Max-Margin
除了常见的交叉熵损失,还有一种损失函数比较常见,叫作基于Max-margin的损失,这也是组成支持向量机模型的核心。这里的核心单词为:"margin", 通俗理解为我们尽可能地让不同类别样本之间的距
离变大。举个例子,疫情期间我们建议保持人和人之间的距离,如果小于这个距离可能就会存在风险。类似的,如果不同类别样本之间的距离小于某个值,就会产生penalty。
①和③相比②它是更加的不稳定的,③ 如果加了些噪声测试集 它就被分类为别的类别了;
② 距离绿色和红色的点的距离margin都非常大,SVN本质上就是第二条②模型;
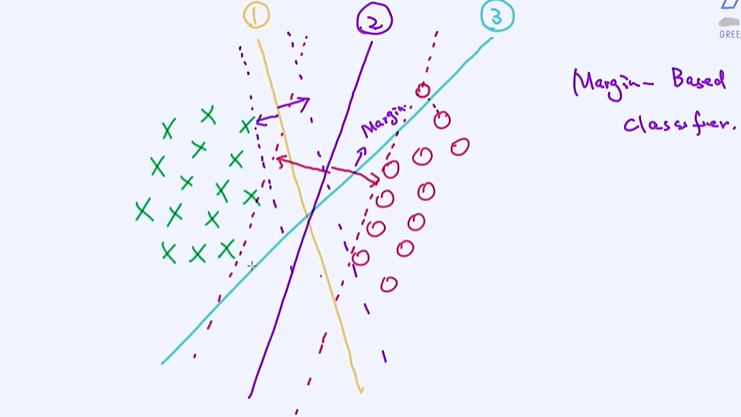
如果我们能够让这个安全区域的宽度最大化,训练出来的分类模型也是稳定的。SVM的目标函数其实就是最大化上面所述的安全区域的宽度。接下来的问题就来了,如何去量化这个安全区域的宽度? 一
旦能把这个宽度利用参数来量化,剩下的就是优化工作了,即寻找让这个宽度最大化的模型的参数。
支持向量机的目标函数
在构造支持向量目标函数之前,先来定义线性分类器,以及相关的数学表达式。我们将会沿用这些数学表达是来推导后续支持向量机的目标函数。 线性分类器的本质是决策边界为线性方程,比如在二维
空间里,决策边界就是一条线,并利用这条线来区分两种不同类型的样本。
线性分类器
n个样本数据,yi (标签为-1和1,可以合并为一种情况),逻辑回归用的是0和1,线性分类器,参数θ
两个条件合并为一个 (wTxi + b) yi >= 0 ,任何满足这个条件的都叫做可行解,都可以把这两批点区分开,它的集合表示成如下

Margin的数学表示
有了以上基本的表示方法之后,接下来就需要定义Margin了,也就是通过一定的方程式来量化margin。对于margin的推导会涉及到几个简单的几何知识点。
最大化margin
决策边界 wTx+b = 0,两个向量乘积为0即两个向量垂直;
通过下面式子的推导得到Margin = 2/ ||w||

有了Margin的表示之后,下一个问题就是推导支持向量机的目标函数了,当然这个目标函数也需要考虑到二分类的约束条件。 所以,目标函数本身也具有对应的限制条件。
SVM的目标函数:Hard Constraint
需要满足绿色的点在线左边,红色的点在线右边;最大化 1/x,也就是最小化x ;下面描述的式子只是在线性可分的情况下,如果线性不可分是无解的;
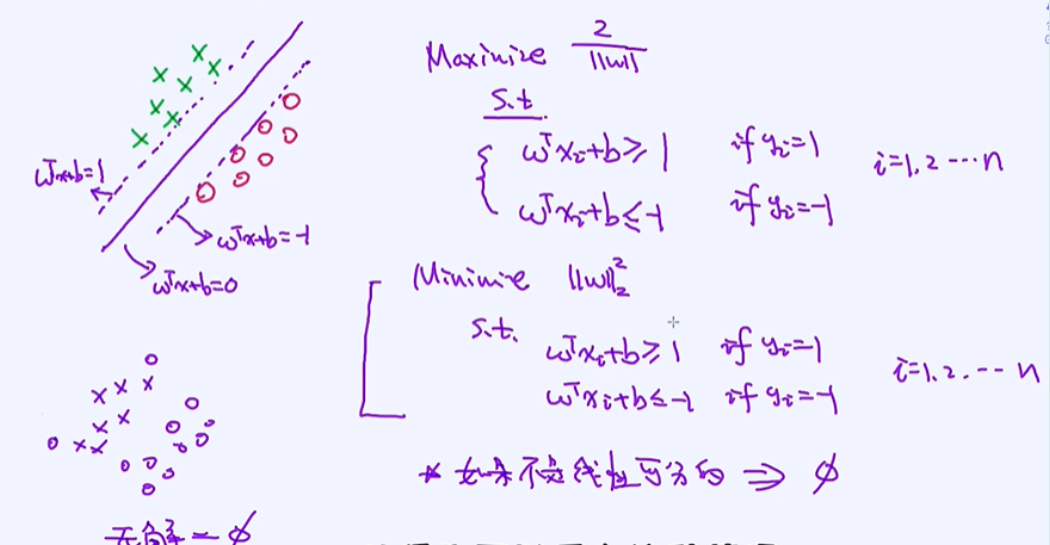
之前所讲的目标函数有一定缺陷的,它只能适用于线性可分的情况。如果有些样本无法线性可分,那上述问题就变成无解了,因为找不到满足所有条件的解。比如我们在找AI人才,我们定了很多条件,
比如一定是博士,有20篇以上顶会文章,需要30岁以下,并且要懂得5种语言还有具备海外高管担任经验。那对于这样的条件,有可能是没有合适的人选的,也就是没有一个解满足所有的条件,问题就变
成无解了。所以这个时候怎么办? 一种思路就是做一些”牺牲“,把一些条件看淡,可以违背部分条件,但我们还是尽量希望找到比较优秀的人才。对于上述SVM的目标函数也是同样的道理。我们是想最小
化目标函数,同时要满足所有的条件,但很可惜找不到。对于上述问题,一种解决思路是我们可以允许部分条件不满足,但这时候需要给一定的惩罚,而且我们也希望这种惩罚越小越好。通过这个思想
我们能把上述hard-constraint的SVM表示成具备soft-constraint的SVM。
SVM的目标函数:Soft Constraint
将条件灵活处理,运行犯错误;条件做一个松弛化,犯错误的程度Degree of mistake 它大于等于0;

上面得到的SVM我们也称之为Linear SVM,因为模型本身就是线性的,这是一开始制定决策边界的时候决定的。到此为主,目标函数以及它的限制条件有了。接下来就是如何去优化它了。
SVM是带条件的优化,逻辑回归是不带条件的;
Hinge Loss以及梯度下降法
把目标转换成Hinge Loss形态
把LinearSVM的目标和条件写了出来,那具体如何去优化呢?这个问题实际上是一个优化问题。这里的难点在于处理限制条件。如果没有限制条件,其实我们可以通过梯度下降法就可以把解求出来,但这
里有个条件,具体如何处理呢?对于上述问题,我们其实有一种方式可以把条件去掉,然后把这部分的信息融合在目标里面。这样一来问题就变成了无条件的目标函数,接下来就可以通过梯度下降法来优
化参数。
转换成Hinge Loss
把限制条件融合到目标函数中 即Hinge Loss

对Hinge Loss求解
上述损失函数也叫作Hinge Loss。Hinge Loss不亚于交叉熵损失函数,经常用于实际的问题当中。其实不仅仅是SVM, 其他模型也可以使用Hinge Loss,
所以它具备通用性,就像交叉熵损失。没有了限制条件之后,优化就变得格外简单了。下面来看如何做梯度下降法。
计算梯度,更新参数,(样本产生损失的时候);
如果样本不产生loss满足所有的条件这个时候就不需要去更新参数;这是跟逻辑回归不一样的地方

到此为止,我们已经知道了如何对线性SVM求解了,其实一点都不难!对于线性SVM其实网上有很多不错的工具可以用来求解的,其中最流行的是Liblinear,
它是专门为线性SVM而设计的,所以很高效。在sklearn里已经提供了liblinear工具,
具体使用法请参考: https://scikit-learn.org/stable/modules/generated/sklearn.svm.LinearSVC.html
线性SVM的缺点以及解决思路
线性SVM的缺点
我们已经学习了线性SVM的细节。首先来看看优点吧! 优点很明显,就是效果不错,虽然是线性模型。由于我们在最大化Margin, 模型本身也比较稳定,所以一直以来受到工业界的青睐。而且线性SVM
的训练效率也比较高,对于非常大量的数据,也很快训练出想要的参数出来。
那具体缺点又是什么呢? 稍微想一下,其实也不难理解。毕竟它是线性分类器,假如数据呈现出很强的非线性性,则很难分类正确。比如图像识别或者语音识别,这些数据本身很复杂,所以一般很难通过
线性模型就可以得到较好的效果。
假如数据呈现出非线性特点, 我们应该如何解决呢?
第一个解决方案就是使用非线性模型,比如神经网络。这个应该很容易理解。第二种解决方案是在特征上做一些操作,比如把原来10维特征映射到100维空间里,然后在100维空间上做分类。这个时候数据本
身在高维空间里不再具有那么高的非线性化, 而且我们可以使用简单的线性模型即可以很好地把数据分开。具体为什么会是这样,先不用纠结,之后会做详细的介绍。
当我们把数据映射到高维的空间,然后再用线性SVM做分类的时候效果可能就会变得更好。但同时也会增加时间复杂度,因为毕竟数据的维度变多了。但庆幸的是,SVM可以使用Kernel Trick,也就是即
便数据维度变大了,但并没有让计算本身增加! 这就是Kernel Trick的好处! Kernel Trick是SVM在AI界流行起来的主要原因。
线性SVM极其简单,而且可用于大规模的数据。但毕竟是线性模型,所以它的决策边界也是线性的。但实际上数据的形状有可能是极度非线性的。这个如何去理解呢?
从低纬到高维的映射
原始的表示方式 primal

线性SVM极其简单, 而且可用于大规模的数据。但毕竟是线性模型, 所以它的决策边界也是线性的。但实际上数据的形状有可能是极度非线性的。这个如何去理解呢?
- 用线性模型很难分开
- 决策边界非线性化
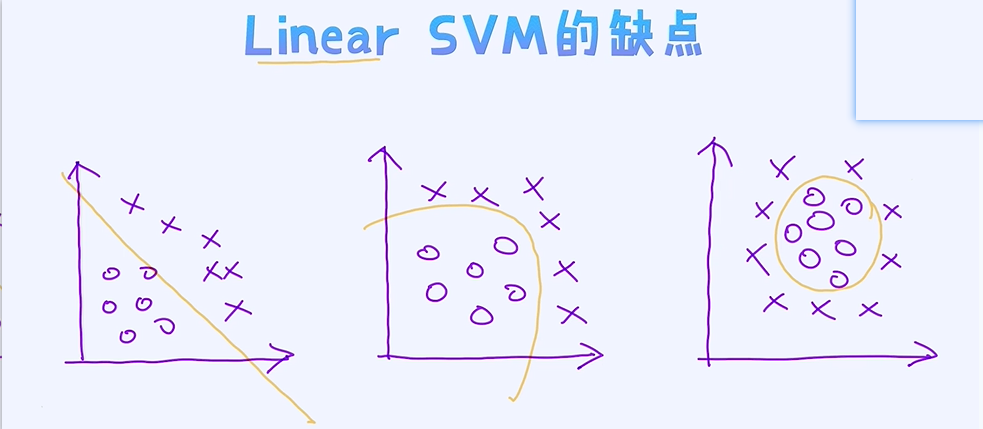
对复杂数据做分类:
① 使用非线性模型;
② 数据升维 (如做特征组合)

在这些方法里,我们本章重点需要讨论的是数据特征的转换。通过转换过程,我们把数据映射到高维的空间,然后在高维空间里用线性SVM来做分类。所以,使用的模型是一样的,仍然是线性模型。但
区别在于我们首先把数据映射到了高维的空间。这里所谓的数据映射无非就是在特征上做了一些扩充。比如原来有两个特征a和b, 我们可以增加特征比如a+b, a*b, a/b等等。通过这种方式,即可以得
到更多丰富的特征。其实这种方法我们在实际工程中也用得非常多。

把数据映射到的高维的空间其实也意味着特征的增加,进而意味着模型参数的增加,所以模型就变得更复杂了,所以分类能力也更强大了! 但是,另外一个问题也随之而出现,就是计算复杂度的问题,
毕竟模型参数变得更多,需要学习的参数也更多。
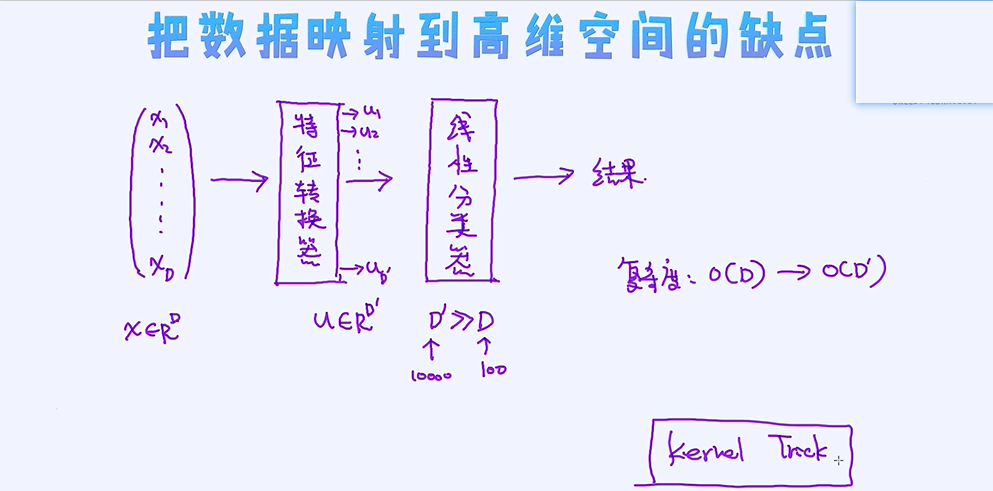
那我们的问题是: 在数据特征变多的情况下,有没有可能不让计算复杂度随之而增加呢? 答案是肯定的! 这就是Kernel Trick。有时候,即便我们把数据映射到千万维空间,或者甚至无限维空间,但我们可
以保证训练时间不随之增加。这么绝妙的东西是不是很酷呢?Kernel Trick就是这么美妙的东西。实际上不仅是SVM,还有很多其他模型上我们都可以使用Kernel Trick,但SVM上这项技术发挥的淋漓尽
致,这也是SVM为什么过去这么长时间久盛不衰的主要原因!
拉格朗日
很多人其实都使用过拉格朗日,比如高中数学里想求出最优解但具有限制条件的时候。通过拉格朗日技术我们可以把一个或一些限制条件挪到目标函数里。看似怪怪地操作,实际上可以用来帮我们把所
谓的Primal问题转换成Dual问题。先不要太纠结什么叫Primal或者Dual。打个比方,比如你面前放着一个箱子,你可以从正面去看,也可以从反面去看。当然,正面和反面看到的是不一样的,但实际上都
是同一个箱子。Primal和Dual也类似。大家所熟悉的比如线性SVM模型可以看作是Primal问题,然后当我们把它转换成另外一种形式(反面),这时候可以看作是dual问题。
为什么要考虑Dual问题呢?
- 当考虑dual问题的时候,可以看到的问题特性是不一样的;
- 在SVM,如果转换成dual问题,就可以使用Kernel Trick;
实际上, 当我们把一个问题转换成Dual问题之后, 所看到的特性是不一样的, 它有自己的特点以及好处。 比如计算起来更简单, 可以使用kernel trick等等。我们把这个领域叫作duality, 也是凸优化领域最为核
心的部分。
我们的目标听起来比较明确了:
为了使用kernel trick, 我们现在希望把原来的问题(也就是linear SVM)转换成dual的形式。那如何去把问题转换成dual呢? 核心就是拉格朗日!, 拉格朗日就是primal到dual
的桥梁!那下面我们就一步步来把SVM转换成dual的形式吧! 首先是要学会如何构建拉格朗日。也就是把各类限制条件添加到目标函数里! 限制条件可以分为: 等式条件和不等式条件。我们需要不同的方法
来处理。
限制条件的处理有两类,一个是处理等式类条件,另外一个是处理不等式的条件。
求函数最优解,通过拉格朗日将限制条件融合到目标函数中再求导;

多个等式的情况

不等式条件的处理
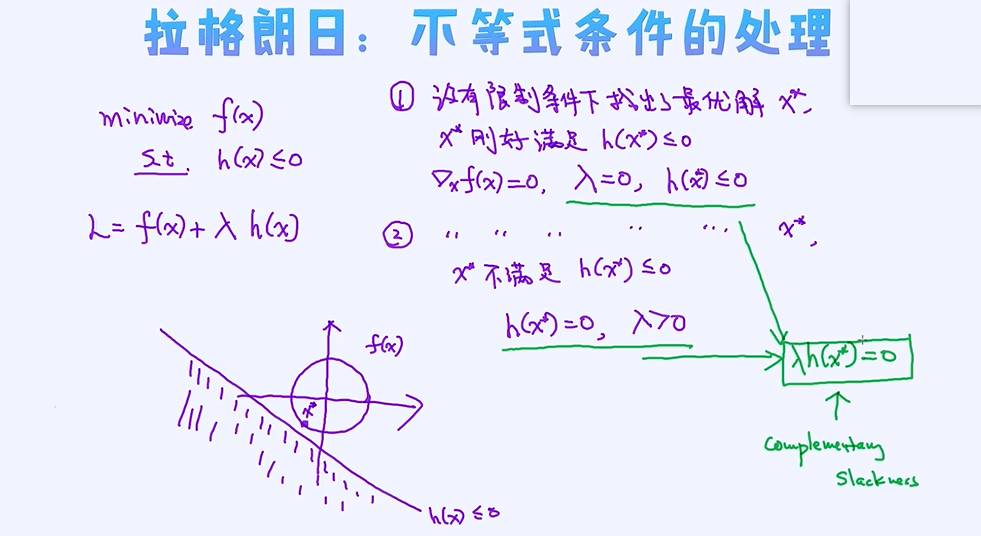
KKT条件和SVM的对偶转换
学会了如何把等式条件和不等式条件转到目标函数里。通过转换的过程实际上我们引入了新的变量比如dual的概念。这里有个
很重要的定义是: 对于primal来讲,参数是x,也就是说要寻找最好的参数x。 相反,对于dual问题来讲,它的参数其实是λ,ν等新引进的变量,所以要寻找的是最好的λ 和ν。那如何去寻找这些参数呢?
因为寻找了这些参数其实也等同于解决了primal和dual的问题。这里有个非常重要的条件叫作KKT,它可用来搭建x,λ,ν之间的关系,也可以理解成为参数之间的桥梁作用!

SVM的KKT条件
以线性SVM为基础来推导,x映射到高纬空间表示为φ(x) ;
转换为拉格朗日写法,基于拉格朗日写出几个KKT条件:
①stationarty
② complementary slackness , 小于等于的不等式
③ primal feasibility
④ dual feasibility

svm的对偶转换
通过这个KKT条件,其实我们建立了 SVM的primal 以及dual 之间的关系。线性SVM的参数为W,b, SVM dual的参数为λ和ν。
简单来讲,如果能把w,b表示成λ,ν的形式,我们即可以得到dual的目标函数。这几个参数的关系,其实已经体现在了KKT条件里面了!
那下面我们利用这个条件来构造svm的dual形式吧!

整个的转换过程其实很直接,无非就是套用了KKT条件,然后把参数W,b去掉了,剩下的就是一些新的参数的限制条件。通过dual的形式可以看到,
新的问题中限制条件变得极其简单! 所以很多时候,解决dual问题要比解决primal问题更容易。那有些人可能有这个疑问: 解决primal和解决dual,结果会是一样吗?
这个问题的答案其实是不一定的。如果两个问题的结果一样,我们称之为strong duality, 如果不一样就是weak duality。
那如何提前能判断是否两个问题的结果是一样的呢? 这个其实很难,目前仍然是open question。暂时我们就不要纠结在这里。
但幸运的是,对于线性SVM来讲,转换前和转换之后的结果是一样的 !
Kernel Trick

Kernel Trick的思想
所以,你可以看到即便我们把数据维度改变了,但它们的内积的计算其实仍然依赖于原来空间上,这就是绝妙之处!所以只要一个模型里,两个数据的依赖关系体现在内积的计算上,我们其实可以使用这
种转换。但任意的转换都具有这种性质吗?显然不是的,只有特定的转换才具备这种形式。所以很多研究者们一直在研究有没有更好的转换方式,同时带来更好的效果。我们通常把这种转换逻辑也叫作
kernels,常用的kernel有rbf kernel, gaussian kernel等等。很多已经在sklearn里面实现了。
SVN中的Kernel Trick

所以你可以看到,不管是SVM也好还是KNN算法也好,因为样本之间关系体现在了内积上,都可以使用kernel trick。其他模型比如k-means, 线性回归其实也可以改造成这种形式的。怎么样?
是不是很妙呢? 实际上Kernel trick在前深度学习时代是最为火热的话题。使用kernel trick,我们甚至可以把数据映射到无限维的空间,但计算量仍然跟原来的空间是一样的。SVM和kernel相关的内容也一
直是面试官喜欢问的题目。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2018-05-08 HTML