
DorisDB | 安装配置
DorisDB
Apache Doris最早诞生于2008年,最初只为解决百度凤巢报表的专用系统。在08年那个时候数据存储和计算成熟的开源产品非常少,Hbase的导入性能只有大约2000条/秒,在这种不能满足业务的背景下,doris
诞生了,并且跟随百度凤巢系统一起正式上线。
Apache Doris是一个现代化的MPP分析性数据库产品。仅需要亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。Apache Doris可以满足多种数据分析需求,例如固定历史报表,实时数据分析。
https://baijiahao.baidu.com/s?id=1633669902039812353&wfr=spider&for=pc
http://doc.dorisdb.com/2178813
DorisDB集群的安装
|
hadoop102 |
hadoop103 |
hadoop104 |
|
FE(LEADER) |
FE(FOLLOWER) |
FE(OBSERVER) |
|
BE |
BE |
BE |
|
BROKER |
BROKER |
BROKER |
1.FE的磁盘主要用于存储元数据,包括日志,和image。通常几百MB到几个GB不等
2.BE的磁盘主要用于存储用户数据,总磁盘空间按用户总数据量*3(3份副本)计算,然后再预留额外40%的空间用作后台compaction以及一些中间数据的存放。
3.一台机器上可以部署多个BE实例,但只能部署一个FE。如果需要3副本数据,那么至少三台机器各部署一个BE实例。
4.FE角色分为Follower和Observer,(Leader为Follwer中选举出来的一种角色)
5.FE节点至少为1个。当部署1个Follower和1个Observer时,可以实现高可用HA
6.Follower的数量必须为奇数,Observer数量随意
7.根据官网描述,以往经验,当集群可用性要求很高,可以部署3个Follower和1-3个Observer。如果是离线业务,建议部署1个Follower和1-3个Observer
8.Broker部署,Broker是用于访问外部数据源hdfs进程。通常每台机器上部署一个broker实例即可。
二进制产品包
安装包的下载:https://www.starrocks.com/zh-CN/download/community
DorisDB-XX-1.0.0
├── be # BE目录
│ ├── bin
│ │ ├── start_be.sh # BE启动命令
│ │ └── stop_be.sh # BE关闭命令
│ ├── conf
│ │ └── be.conf # BE配置文件
│ ├── lib
│ │ ├── dorisdb_be # BE可执行文件
│ │ └── meta_tool
│ └── www
├── fe # FE目录
│ ├── bin
│ │ ├── start_fe.sh # FE启动命令
│ │ └── stop_fe.sh # FE关闭命令
│ ├── conf
│ │ └── fe.conf # FE配置文件
│ ├── lib
│ │ ├── dorisdb-fe.jar # FE jar包
│ │ └── *.jar # FE 依赖的jar包
│ └── webroot
└── udf
部署FE
FE的基本配置
第一步: 定制配置文件conf/fe.conf:
FE的配置文件为DorisDB-XX-1.0.0/fe/conf/fe.conf
可以根据FE内存大小调整 -Xmx4096m,为了避免GC建议16G以上,DorisDB的元数据都在内存中保存。
vim fe/conf/fe.conf
meta_dir = /opt/module/apache-doris/fe/doris-meta
第二步: 创建元数据目录:
mkdir -p fe/doris-meta
第三步: 启动FE进程:
fe/bin/start_fe.sh --daemon
第四步: 确认启动FE启动成功.
查看日志log/fe.log确认.
[FeServer.start():48] thrift server started. [NMysqlServer.start():70] Open mysql server success on 9030 [QeService.start():60] QE service start. [HttpServer$HttpServerThread.run():231] HttpServer started with port 8030
- 如果FE启动失败,可能是由于端口号被占用,修改配置文件conf/fe.conf中的端口号http_port。
- 使用jps命令查看java进程确认"DorisDbFe"存在.
- 使用浏览器访问8030端口, 打开DorisDB的WebUI, 用户名为root, 密码为空.
使用MySQL客户端访问FE
第一步: 安装mysql客户端(如果已经安装,可忽略此步):
Ubuntu:sudo apt-get install mysql
Centos:sudo yum install mysql-client
第二步: 使用mysql客户端连接:
mysql -h hadoop102 -P9030 -uroot
注意:这里默认root用户密码为空,端口为fe/conf/fe.conf中的query_port配置项,默认为9030
第三步: 查看FE状态:
mysql> SHOW PROC '/frontends'\G
mysql> SHOW PROC '/frontends'\G
*************************** 1. row ***************************
Name: 192.168.122.1_9010_1634461485149
IP: 192.168.122.1
HostName: 192.168.122.1
EditLogPort: 9010
HttpPort: 8030
QueryPort: 9030
RpcPort: 9020
Role: FOLLOWER
IsMaster: true
ClusterId: 1315220597
Join: true
Alive: true
ReplayedJournalId: 61
LastHeartbeat: 2021-10-17 17:08:25
IsHelper: true
ErrMsg:
1 row in set (20.07 sec)
Role为FOLLOWER说明这是一个能参与选主的FE;IsMaster为true,说明该FE当前为主节点。
如果MySQL客户端连接不成功,请查看log/fe.warn.log日志文件,确认问题。由于是初次启动,如果在操作过程中遇到任何意外问题,都可以删除并重新创建FE的元数据目录,再从头开始操作。
FE的高可用集群部署
FE的高可用集群采用主从复制架构, 可避免FE单点故障. FE采用了类raft的bdbje协议完成选主, 日志复制和故障切换. 在FE集群中, 多实例分为两种角色: follower和observer; 前者为复制协议的可投票成员, 参与
选主和提交日志, 一般数量为奇数(2n+1), 使用多数派(n+1)确认, 可容忍少数派(n)故障; 而后者属于非投票成员, 用于异步订阅复制日志, observer的状态落后于follower, 类似其他复制协议中的leaner角色.
FE集群从follower中自动选出master节点, 所有更改状态操作都由master节点执行, 从FE的master节点可以读到最新的状态. 更改操作可以从非master节点发起, 继而转发给master节点执行, 非master节点记录最
近一次更改操作在复制日志中的LSN, 读操作可以直接在非master节点上执行, 但需要等待非master节点的状态已经同步到最近一次更改操作的LSN, 因此读写非Master节点满足顺序一致性. Observer节点能够增
加FE集群的读负载能力, 时效性要求放宽的非紧要用户可以读observer节点.
FE节点之间的时钟相差不能超过5s, 使用NTP协议校准时间.
一台机器上只可以部署单个FE节点。所有FE节点的http_port需要相同。
集群部署按照下列步骤逐个增加FE实例.
第一步: 分发二进制和配置文件到另外两个节点, 配置文件和单实例情形相同.
scp -r apache-doris/ hadoop103:/opt/module/
scp -r apache-doris/ hadoop104:/opt/module/
第二步: 使用MySQL客户端连接已有的FE, 添加新实例的信息,信息包括角色、ip、port:
mysql> ALTER SYSTEM ADD FOLLOWER "host:port";
或
mysql> ALTER SYSTEM ADD OBSERVER "host:port";
mysql> ALTER SYSTEM ADD FOLLOWER "hadoop103:9010";
Query OK, 0 rows affected (0.02 sec)
mysql> ALTER SYSTEM ADD OBSERVER "hadoop104:9010";
Query OK, 0 rows affected (0.00 sec)
host为机器的IP,如果机器存在多个IP,需要选取priority_networks里的IP,例如priority_networks=192.168.1.0/24 可以设置使用192.168.1.x 这个子网进行通信。port为edit_log_port,默认为9010。
DorisDB的FE和BE因为安全考虑都只会监听一个IP来进行通信,如果一台机器有多块网卡,可能DorisDB无法自动找到正确的IP,例如 ifconfig 命令能看到 eth0 ip为 192.168.1.1, docker0: 172.17.0.1 ,我们可以设置 192.168.1.0/24 这一个字网来指定使用eth0作为通信的IP,这里采用是CIDR的表示方法来指定IP所在子网范围,这样可以在所有的BE,FE上使用相同的配置。
priority_networks 是 FE 和 BE 相同的配置项,写在 fe.conf 和 be.conf 中。该配置项用于在 FE 或 BE 启动时,告诉进程应该绑定哪个IP。示例如下:priority_networks=10.1.3.0/24
启动hadoop103、hadoop104的fe
sh bin/start_fe.sh --daemon
mysql> SHOW PROC '/frontends'\G
*************************** 1. row ***************************
Name: 192.168.122.1_9010_1634461485149
IP: 192.168.122.1
HostName: 192.168.122.1
EditLogPort: 9010
HttpPort: 8030
QueryPort: 9030
RpcPort: 9020
Role: FOLLOWER
IsMaster: true
ClusterId: 1315220597
Join: true
Alive: true
ReplayedJournalId: 687
LastHeartbeat: 2021-10-17 17:43:03
IsHelper: true
ErrMsg:
*************************** 2. row ***************************
Name: 192.168.1.104_9010_1634463682433
IP: 192.168.1.104
HostName: hadoop104
EditLogPort: 9010
HttpPort: 8030
QueryPort: 9030
RpcPort: 9020
Role: OBSERVER
IsMaster: false
ClusterId: 1315220597
Join: false
Alive: true
ReplayedJournalId: 549
LastHeartbeat: 2021-10-17 17:43:03
IsHelper: false
ErrMsg:
*************************** 3. row ***************************
Name: 192.168.1.103_9010_1634463628227
IP: 192.168.1.103
HostName: hadoop103
EditLogPort: 9010
HttpPort: 8030
QueryPort: 9030
RpcPort: 9020
Role: FOLLOWER
IsMaster: false
ClusterId: 1315220597
Join: false
Alive: true
ReplayedJournalId: 539
LastHeartbeat: 2021-10-17 17:43:03
IsHelper: true
ErrMsg:
3 rows in set (20.08 sec)
mysql>
节点的Alive显示为true则说明添加节点成功。192.168.122.1_9010_1634461485149 为主节点。
xcall.sh jps
--------- hadoop102 ----------
3008 StarRocksFe
3760 Jps
--------- hadoop103 ----------
3441 Jps
3244 StarRocksFe
--------- hadoop104 ----------
3234 StarRocksFe
3404 Jps
部署BE
如果开启了hadoop,yarn的8040端口号与be的web端口号会产生冲突;
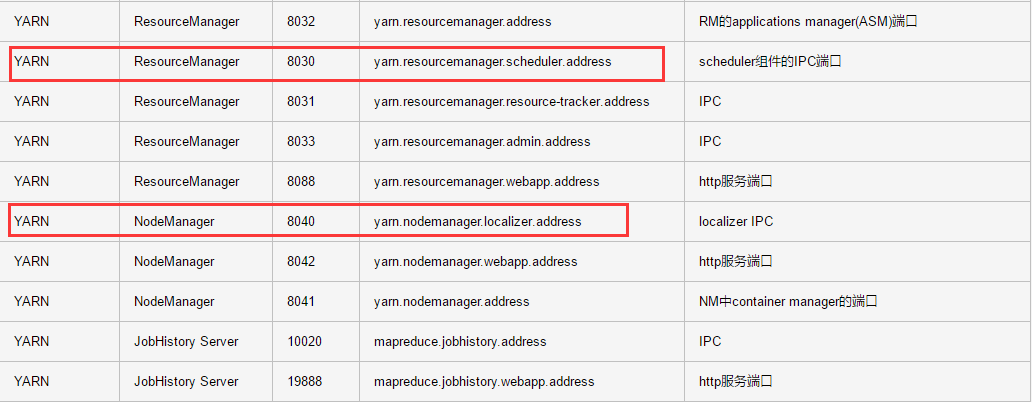
修改doris fe.conf配置,将http port修改为其他端口
BE的基本配置
BE的配置文件为DorisDB-XX-1.0.0/be/conf/be.conf,
BE部署
用户可使用下面命令添加BE到DorisDB集群, 一般至少部署3个BE实例, 每个实例的添加步骤相同.
cd DorisDB-XX-1.0.0/be
第一步: 创建数据目录:
mkdir -p be/storage
添加到be/conf/be.conf中 vim be/conf/be.conf
storage_root_path = /opt/module/apache-doris/be/storage,10;
storage_root_path配置存储目录,可以用来指定多个目录,每个目录后可以跟逗号,指定大小默认GB;
第二步: 通过mysql客户端添加BE节点:
mysql> ALTER SYSTEM ADD BACKEND "host:port";
这里IP地址为和priority_networks设置匹配的IP,portheartbeat_service_port,默认为9050
在mysql客户端添加BE 节点
mysql> ALTER SYSTEM ADD BACKEND "hadoop102:9050";
Query OK, 0 rows affected (0.00 sec)
mysql> ALTER SYSTEM ADD BACKEND "hadoop103:9050";
Query OK, 0 rows affected (0.00 sec)
mysql> ALTER SYSTEM ADD BACKEND "hadoop104:9050";
Query OK, 0 rows affected (0.00 sec)
在hadoop102、hadoop103、hadoop104节点启动BE:
sh bin/start_be.sh --daemon
sh bin/start_be.sh --daemon
sh bin/start_be.sh --daemon
查看BE状态,确认BE就绪:
mysql> SHOW PROC '/backends'\G
*************************** 1. row ***************************
BackendId: 10003
Cluster: default_cluster
IP: 192.168.1.102
HostName: hadoop102
HeartbeatPort: 9050
BePort: 9060
HttpPort: 8040
BrpcPort: 8060
LastStartTime: 2021-10-17 18:07:27
LastHeartbeat: 2021-10-17 18:07:47
Alive: true
SystemDecommissioned: false
ClusterDecommissioned: false
TabletNum: 0
DataUsedCapacity: .000
AvailCapacity: 20.053 GB
TotalCapacity: 45.095 GB
UsedPct: 55.53 %
MaxDiskUsedPct: 55.53 %
ErrMsg:
Version: 1.18.2-7b65727
Status: {"lastSuccessReportTabletsTime":"2021-10-17 18:07:28"}
*************************** 2. row ***************************
BackendId: 10007
Cluster: default_cluster
IP: 192.168.1.103
HostName: hadoop103
HeartbeatPort: 9050
BePort: 9060
HttpPort: 8040
BrpcPort: 8060
LastStartTime: 2021-10-17 18:07:37
LastHeartbeat: 2021-10-17 18:07:47
Alive: true
SystemDecommissioned: false
ClusterDecommissioned: false
TabletNum: 0
DataUsedCapacity: .000
AvailCapacity: 1.000 B
TotalCapacity: .000
UsedPct: 0.00 %
MaxDiskUsedPct: 0.00 %
ErrMsg:
Version: 1.18.2-7b65727
Status: {"lastSuccessReportTabletsTime":"N/A"}
*************************** 3. row ***************************
BackendId: 10008
Cluster: default_cluster
IP: 192.168.1.104
HostName: hadoop104
HeartbeatPort: 9050
BePort: 9060
HttpPort: 8040
BrpcPort: 8060
LastStartTime: 2021-10-17 18:07:32
LastHeartbeat: 2021-10-17 18:07:47
Alive: true
SystemDecommissioned: false
ClusterDecommissioned: false
TabletNum: 0
DataUsedCapacity: .000
AvailCapacity: 1.000 B
TotalCapacity: .000
UsedPct: 0.00 %
MaxDiskUsedPct: 0.00 %
ErrMsg:
Version: 1.18.2-7b65727
Status: {"lastSuccessReportTabletsTime":"N/A"}
3 rows in set (0.03 sec)
如果isAlive为true,则说明BE正常接入集群。如果BE没有正常接入集群,请查看log目录下的be.WARNING日志文件确定原因。
部署Broker
部署FS_BROKER,BROKER以插件的形式,独立与Doris的部署,建议每个PE和BE节点都部署一个Broker,Broker是用于访问外部数据源的进程,默认是HDSF。
配置文件为apache_hdfs_broker/conf/apache_hdfs_broker.conf
注意:如果机器有多个IP,需要配置priority_networks,方式同FE。
如果有特殊的hdfs配置,复制线上的hdfs-site.xml到conf目录下
启动:
./apache_hdfs_broker/bin/start_broker.sh --daemon
添加broker节点到集群中:
MySQL> ALTER SYSTEM ADD BROKER broker1 "172.16.139.24:8000";
查看broker状态
添加broker节点到集群:
mysql> ALTER SYSTEM ADD BROKER broker2 "hadoop102:8000";
Query OK, 0 rows affected (0.02 sec)
mysql> ALTER SYSTEM ADD BROKER broker2 "hadoop103:8000";
Query OK, 0 rows affected (0.00 sec)
mysql> ALTER SYSTEM ADD BROKER broker2 "hadoop104:8000";
Query OK, 0 rows affected (0.00 sec)
查看broker状态:
mysql> SHOW PROC "/brokers"\G
*************************** 1. row ***************************
Name: broker2
IP: 192.168.1.103
Port: 8000
Alive: true
LastStartTime: 2021-10-17 18:24:10
LastUpdateTime: 2021-10-17 18:24:20
ErrMsg:
*************************** 2. row ***************************
Name: broker2
IP: 192.168.1.104
Port: 8000
Alive: true
LastStartTime: 2021-10-17 18:24:00
LastUpdateTime: 2021-10-17 18:24:20
ErrMsg:
*************************** 3. row ***************************
Name: broker2
IP: 192.168.1.102
Port: 8000
Alive: true
LastStartTime: 2021-10-17 18:23:35
LastUpdateTime: 2021-10-17 18:24:20
ErrMsg:
3 rows in set (0.00 sec)
Alive为true代表状态正常。
xcall.sh jps
--------- hadoop102 ----------
3008 StarRocksFe
5364 Jps
5189 BrokerBootstrap
--------- hadoop103 ----------
4937 Jps
4810 BrokerBootstrap
3244 StarRocksFe
--------- hadoop104 ----------
4784 BrokerBootstrap
3234 StarRocksFe
4916 Jps
fe节点的查看:
ps -ef | grep fe
root 94 2 0 16:10 ? 00:00:00 [deferwq]
kris 3008 1 1 17:04 pts/0 00:01:17 /opt/module/jdk1.8.0_212/bin/java -Xmx8192m -XX:+UseMembar -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=7 -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSClassUnloadingEnabled -XX:-CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -Xloggc:/opt/module/apache-doris/fe/log/fe.gc.log.20211017-170443 com.starrocks.StarRocksFe
kris 5356 3381 0 18:34 pts/1 00:00:00 grep --color=auto fe
参数设置
- Swappiness
关闭交换区,消除交换内存到虚拟内存时对性能的扰动。
echo 0 | sudo tee /proc/sys/vm/swappiness
- Compaction相关
当使用聚合表或更新模型,导入数据比较快的时候,可改下列参数以加速compaction。
cumulative_compaction_num_threads_per_disk = 4
base_compaction_num_threads_per_disk = 2
cumulative_compaction_check_interval_seconds = 2
- 并行度
在客户端执行命令,修改DorisDB的并行度(类似clickhouse set max_threads= 8)。并行度可以设置为当前机器CPU核数的一半。
set global parallel_fragment_exec_instance_num = 8;使用MySQL客户端访问DorisDB
1 Root用户登录
使用MySQL客户端连接某一个FE实例的query_port(9030), DorisDB内置root用户,密码默认为空:
mysql -h fe_host -P9030 -u root
2 创建新用户
通过下面的命令创建一个普通用户:
mysql > create user 'test' identified by '123456';
3 创建数据库
DorisDB中root账户才有权建立数据库,使用root用户登录,建立example_db数据库:
mysql > create database example_db;
数据库创建完成之后,可以通过show databases查看数据库信息:
mysql > show databases;
+--------------------+
| Database |
+--------------------+
| example_db |
| information_schema |
+--------------------+
2 rows in set (0.00 sec)
information_schema是为了兼容mysql协议而存在,实际中信息可能不是很准确,所以关于具体数据库的信息建议通过直接查询相应数据库而获得。
4 账户授权
example_db创建完成之后,可以通过root账户example_db读写权限授权给test账户,授权之后采用test账户登录就可以操作example_db数据库了:
mysql > grant all on example_db to test;
退出root账户,使用test登录DorisDB集群:
mysql > exit
mysql -h hadoop102 -P9030 -utest -p123456
5 建表
DorisDB支持支持单分区和复合分区两种建表方式
在复合分区中:
- 第一级称为Partition,即分区。用户可以指定某一维度列作为分区列(当前只支持整型和时间类型的列),并指定每个分区的取值范围。
- 第二级称为Distribution,即分桶。用户可以指定某几个维度列(或不指定,即所有KEY列)以及桶数对数据进行HASH分布。
以下场景推荐使用复合分区:
- 有时间维度或类似带有有序值的维度:可以以这类维度列作为分区列。分区粒度可以根据导入频次、分区数据量等进行评估。
- 历史数据删除需求:如有删除历史数据的需求(比如仅保留最近N 天的数据)。使用复合分区,可以通过删除历史分区来达到目的。也可以通过在指定分区内发送DELETE语句进行数据删除。
- 解决数据倾斜问题:每个分区可以单独指定分桶数量。如按天分区,当每天的数据量差异很大时,可以通过指定分区的分桶数,合理划分不同分区的数据,分桶列建议选择区分度大的列。
用户也可以不使用复合分区,即使用单分区。则数据只做HASH分布。
下面分别演示两种分区的建表语句:
- 首先切换数据库:mysql > use example_db;
- 建立单分区表建立一个名字为table1的逻辑表。使用全hash分桶,分桶列为siteid,桶数为10。这个表的schema如下:
- siteid:类型是INT(4字节), 默认值为10
- cidy_code:类型是SMALLINT(2字节)
- username:类型是VARCHAR, 最大长度为32, 默认值为空字符串
- pv:类型是BIGINT(8字节), 默认值是0; 这是一个指标列, DorisDB内部会对指标列做聚合操作, 这个列的聚合方法是求和(SUM)。这里采用了聚合模型,除此之外DorisDB还支持明细模型和更新模型,具体参考数据模型介绍。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号