
数据湖| Iceberg
1. Iceberg构建数据湖
核心思想
在时间轴上跟踪表的所有变化;
- 快照表示表数据文件的一个完整集合;
- 每次更新操作会生成一个新的快照;
特性
① 优化数据入库流程
- Iceberg提供ACID事务能力,上游数据写入即可见,不影响当前数据处理任务,这大大简化了ETL;
- Iceberg提供upsert/merge into能力,可以极大地缩小数据入库延迟;
② 支持更多的分析引擎
- 优秀的内核抽象使之不绑定特定引擎,目前在支持的有spark、flink、presto、hive;
- Iceberg提供了java native API,不用特定引擎也可以访问Iceberg表;
③ 统一数据存储和灵活的文件组织
- 提供了基于流式的增量计算模型和基于批处理的全量表计算模型,批任务和流任务可以使用相同 的存储模型(HDFS、OZONE),数据不再孤立;
- Iceberg支持隐藏分区和分区进化,方便业务进行数据分区策略更新;
- 支持Parquet、ORC、Avro行列存兼顾;
④ 增量读取处理能力
- Iceberg支持通过流式方式读取增量数据;
- Spark struct streaming支持;
- Flink table source支持;
文件发布
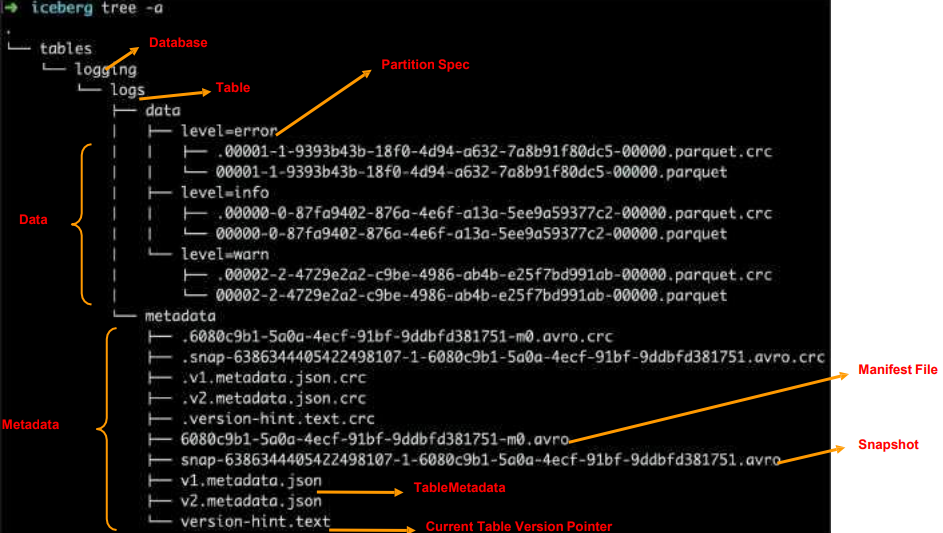
Apache Iceberg的实现细节
快照设计方式
快照隔离
• 读操作仅适用当前已生成快照
• 写操作会生成新的隔离快照,并在写完成后原子性提交 l
对于文件列表的所有修改都是原子操作
• 在分区中追加数据
• 合并或是重写分区
元数据组织形式
实现基于快照的跟踪方式;
• 记录表的结构,分区信息,参数等
• 跟踪老的快照以确保能够最终回收
表的元数据是不可修改的, 并且始终向前迭代;
当前的快照可以回退;
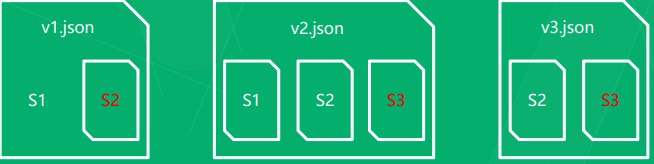
事务性提交
写操作必须
• 记录当前元数据的版本--base version
• 创建新的元数据以及manifest文件
• 原子性的将base version 替换为新的版本
原子性替换保证了线性的历史
原子性替换需要依靠以下操作来保证
冲突解决--乐观锁
• 假定当前没有其他的写操作
• 遇到冲突则基于当前最新的元数据进行重试
• 元数据管理器所提供的能力
• HDFS或是本地文件系统所提供的原子化的rename能力
2. IceBerg结合Flink的应用场景
场景① 构建近实时Data Pipeline
IceBerg提供了增量拉取的能力,类似Huidi增量查询的方式;IceBerg可以做到分钟级别;

场景② CDC数据实时摄入摄出
FlinkCDC增量数据写入IceBerg

场景③ 近实时场景的流批统一
原有的架构为lambda架构,分为离线链路和 实时链路;
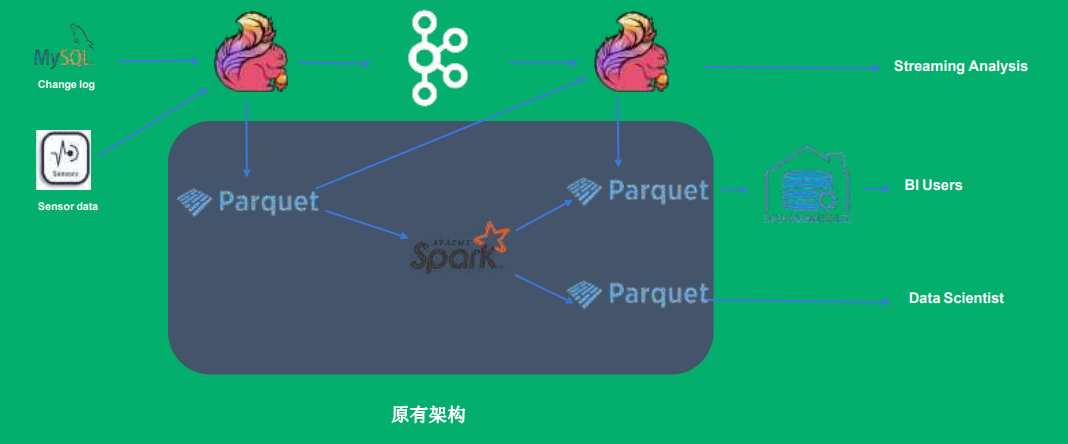
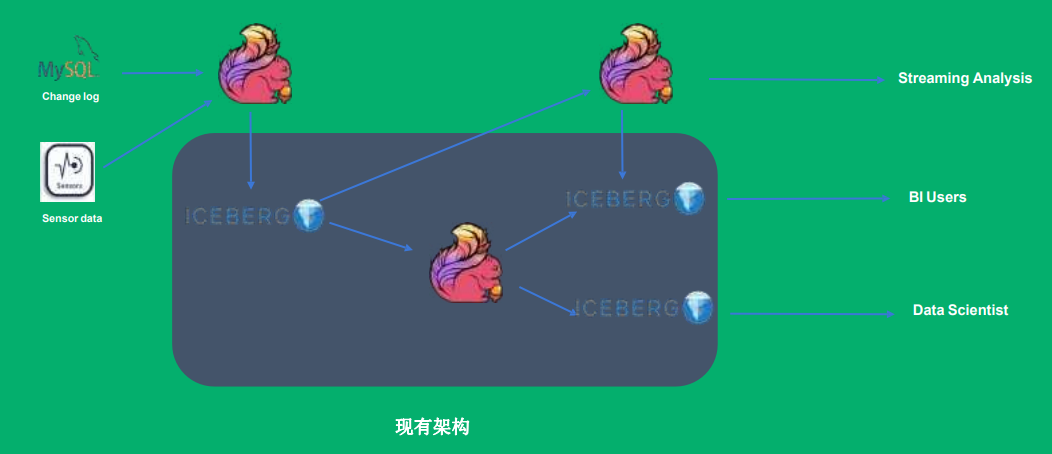
场景④ 从Iceberg历史数据启动Flink任务
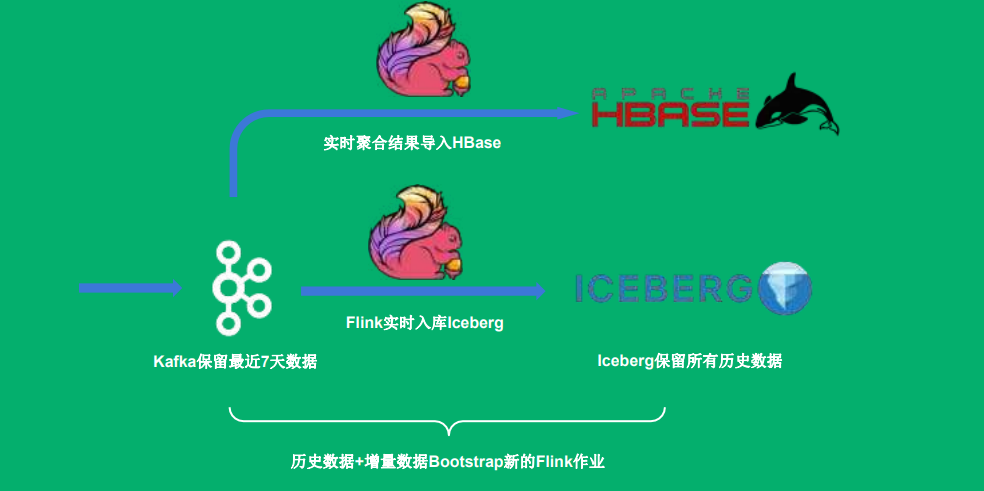
场景⑤ 通过Iceberg数据来订正实时聚合结果

3. Apache Flink如何集成Apache Iceberg
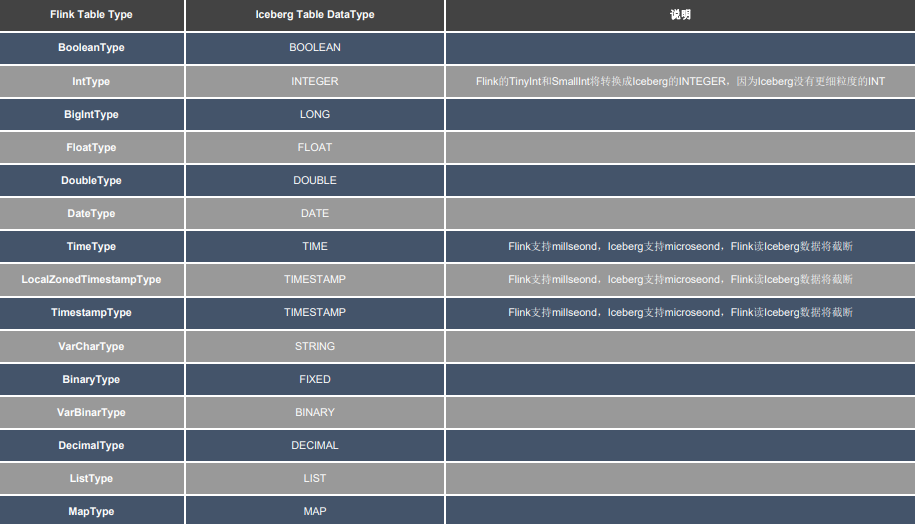
如何对齐Flink和Iceberg的Schema ;
Flink SQL、Flink Table API、Iceberg API,它们之间类型互相对比映射,Iceberg屏蔽了跟底下文件交互的细节,只需考虑上层即可。
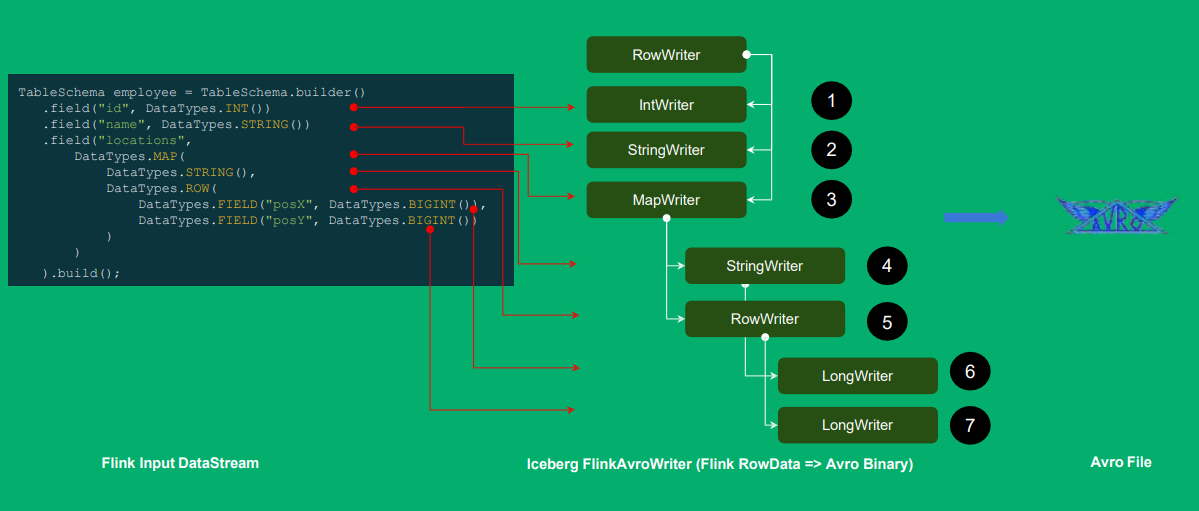
Flink 记录如何写入 Iceberg 表的 AVRO 文件 ?
实现表级别的语义,Flink中每个字段都给它设计成了一个writer的样式,ID Int -> IntWriter... 形成 一颗树形结构,再遍历写入iceberg;
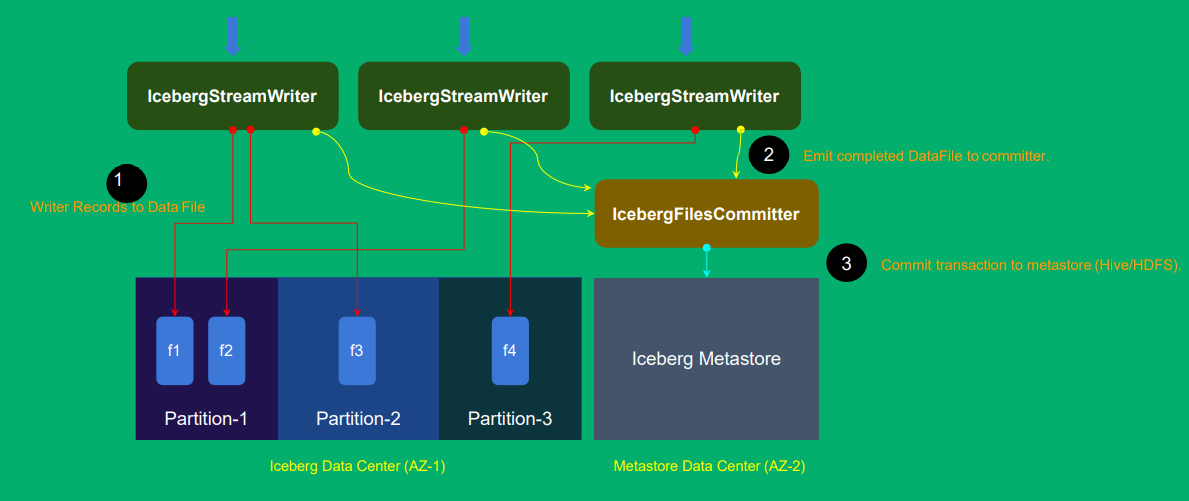
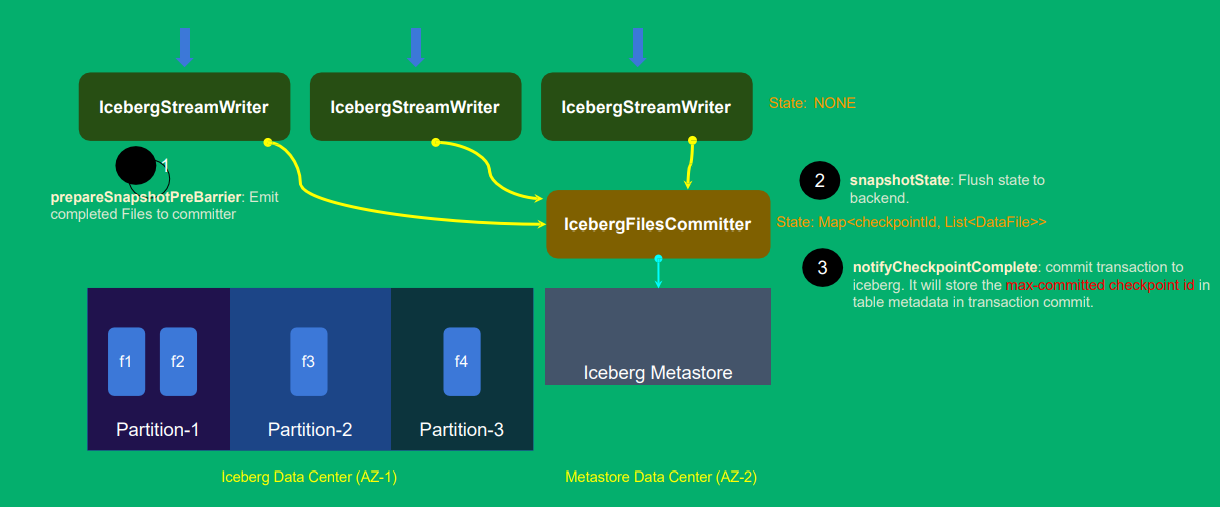
如何设计 Iceberg Sink 的 Operator ?
如何设计flink中的算子才能sink到iceberg中,并且实现exactly-once语义、容错机制(checkpoint、state)等功能;
每个并发写入为一个IcebergStreamWriter,写到了两个partition,但是还没commit提交,这时可以设计一个IcebergFilesCommitter(单并发节点来进行提交,如果有多个commit提交会有冲突),统一提交给Iceberg;
Flink算子的State,保存数据的状态(就可以实现复杂的业务逻辑),spark中没有状态,但特殊算子如updateStateBykey才会有状态;
如何设计 Operator 的 State ?
如何在failover的时候保证 exactly-once 语义?
如果中途某次checkpoint失败,其他checkpoint都正常。 如何设计来保证数据不丢且语义正确?
两个算子 IcebergStreamWriter不给state为空(因为它会把写成功 的数据文件传给FileCommitter), IceberFileCommitter有state 它做checkpoint时,保存到flink中的stateBackend中,再提交到Iceberg中的表中;
StateBackend是flink中存储state的方式,checkpoint也会存储到StateBackend中;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号