
数据湖| Hudi
1. Hudi核心概念
Hudi核心组件结构
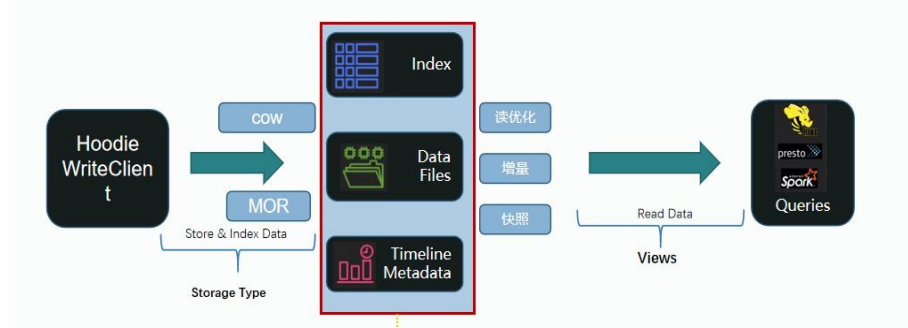
通过Hudi客户端把数据写入Hudi, 写入的时候有两种方式:
- COW(copy on write)写时复制-java中的读写分离
- MOR(merge on read)读时合并 (读数据的时候先合并,写数据时写到par文件中,有新增的写到预写日志log中)
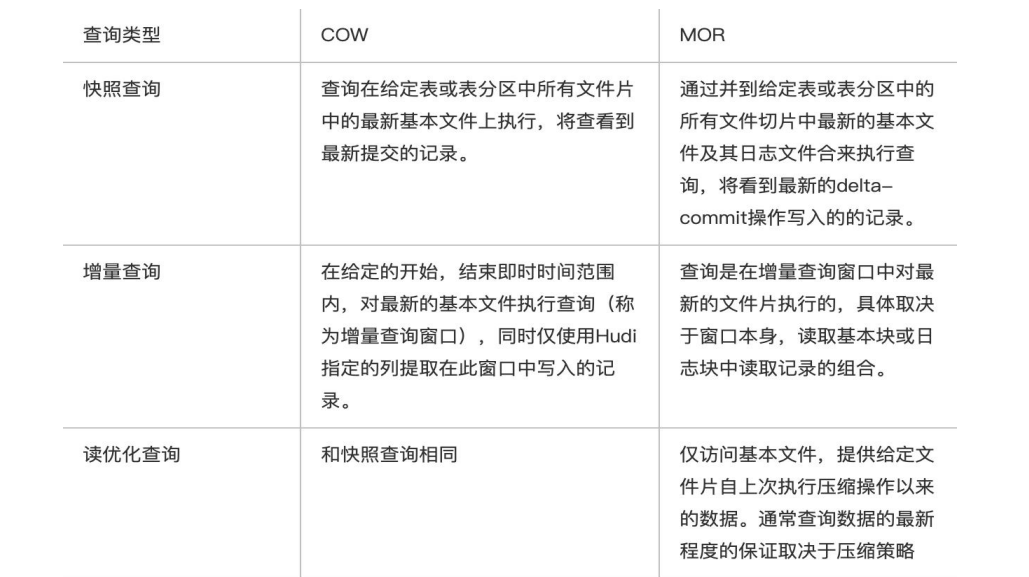
Hudi提供了3种查询数据的方式:
- 读优化(只读取par文件-base文件)
- 增量(不同数据版本之间的增量, 最新写入表里的数据, 指定commit之后的数据)
- 快照(每隔一段时间可以保留版本的数据; )
有序的时间轴Timeline元数据(增量管理数据版本, 方便回溯数据)
分层布局的数据文件(支持两种: parquet列式存储和avro行式存储)
索引Index
Hudi原语
提供两种原语(可理解为原子性,一旦开始就不能被中断),使得除了经典的批处理之外,还可以在数据湖上进行流处理。这两种原语分别是:
- Update(Upsert)/Delete记录(对单条数据):Hudi使用细粒度的文件/记录级别索引来支持 Update/Delete记录,同时还提供写操作的事务保证。查询会处理最后一个提交的快照, 并基于此输出结果。
- PB 万亿级别数据想修改其中一条,Hive把某个分区数据查出来然后更新单条数据再写进去;
delete, 插入时 标记这条数据commit的时间、标记是否删除; update, 标记删除true, 标记insert插入数据;
- PB 万亿级别数据想修改其中一条,Hive把某个分区数据查出来然后更新单条数据再写进去;
- 变更流:Hudi对获取数据变更提供了一流的支持:可以从给定的时间点获取给定表中已 updated/inserted/deleted的所有记录的增量流,并解锁新的查询姿势(类别)。把 Hudi当作kafka用。
- 增量变更数据流
Hudi表设计
时间
- Arrival time: 数据到达 Hudi 的时间
- commit time:提交时间
- Event time: record 中记录的时间
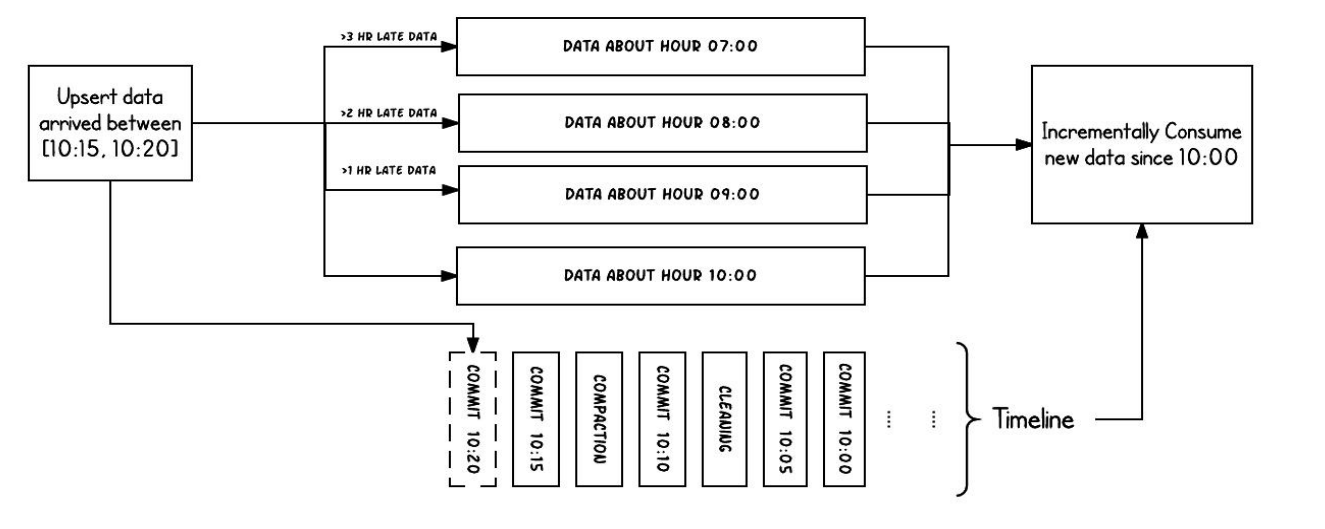
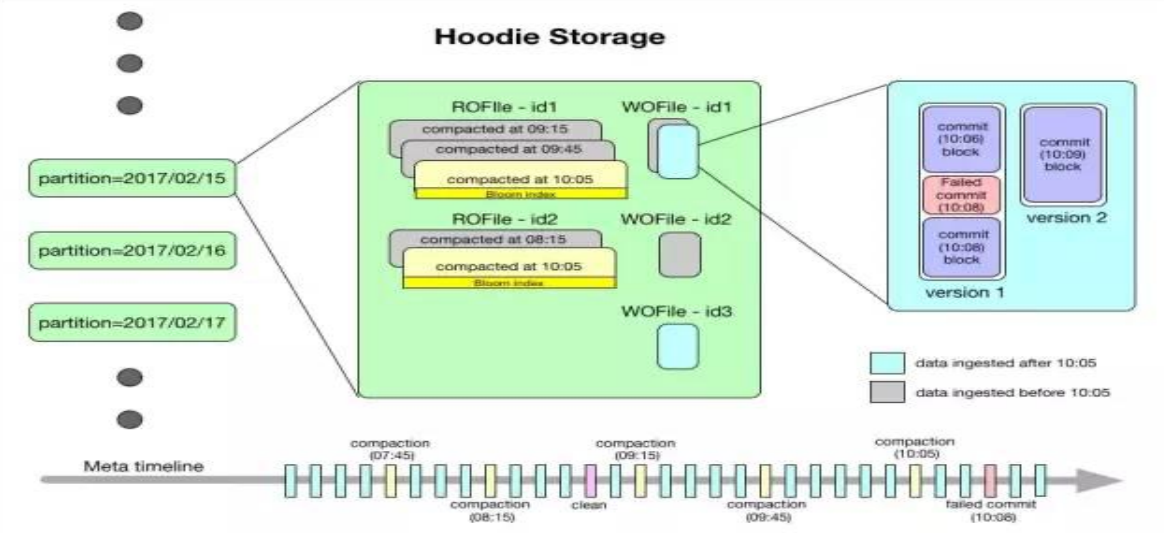
有序的时间轴元数据
TimeLine
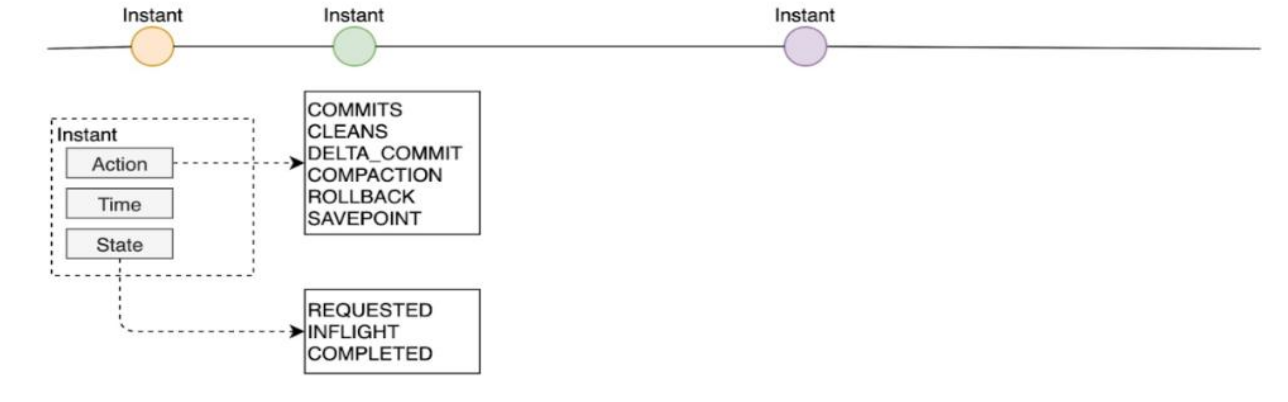
Timeline原理
只要对数据有一些操作,Hudi就会把这些操作对应的元数据用时间轴Timeline的形式
维护起来,Timeline中记录了每次操作, Instant可以理解为一个时间点
每个Instant里面包含: Action/ Time/ State
Action(表示当前的动作)
- COMMITS:写完提交数据
- CLEANS:删除以前版本数据
- DELTA_COMMIT:MOR写数据方式, 提交了
- COMPACTION:追加写的日志进行合并统一一个par文件
- ROLLBACK:回滚
- SAVEPOINT:把当前commit数据版本保留起来
Hudi中的每个操作都是原子性的, Hudi保证了在时间轴上操作的原子性和基于Instant时间轴的一致性;
Time
是Action产生的一些时间
State
- Requested 动作刚发起;
- Inflight 动作正在进行中;
- Completed 动作已完成;
数据文件
FileManage

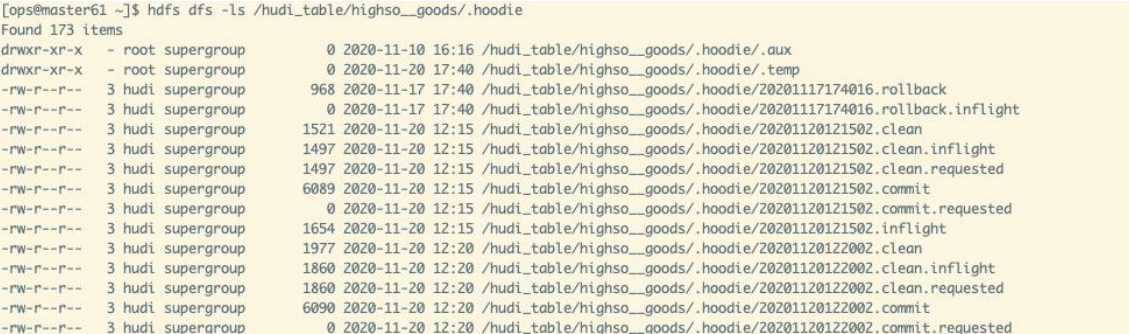
Huid的数据存储在hdfs上, 分区partition
FileGroup(逻辑上的概念)-对数据分桶
一个FileSlice对应一个parquet文件
以HDFS存储来看,一个Hudi表的存储文件分为两类:
Hudi真实的数据文件使用Parquet文件格式存储

.hoodie文件夹中存放对应操作的状态记录
Hoodie key
Hudi为了实现数据的CRUD,需要能够唯一标识一条记录。hudi将把数据集中的唯一字段(record key ) + 数据所在分区 (partitionPath) 联合起来当做数据的唯一键
索引
Hoodie key (record key + partition path) 和 file id (FileGroup) 之间的映射关系,数据第一次写入文件后保持不变,所以,一个 FileGroup 包含了一批 record 的所有版本记录。
Index 用于区分消息是 INSERT 还是 UPDATE。
Index的创建过程
BloomFilter Index
- 新增 records 找到映射关系:record key => target partition
- 当前最新的数据 找到映射关系:partition => (fileID, minRecordKey, maxRecordKey) LIST (如果是 base files 可加速)
- 新增 records 找到需要搜索的映射关系:fileID => HoodieKey(record key + partition path) LIST,key 是候选的 fileID
- 通过 HoodieKeyLookupHandle 查找目标文件(通过 BloomFilter 加速)
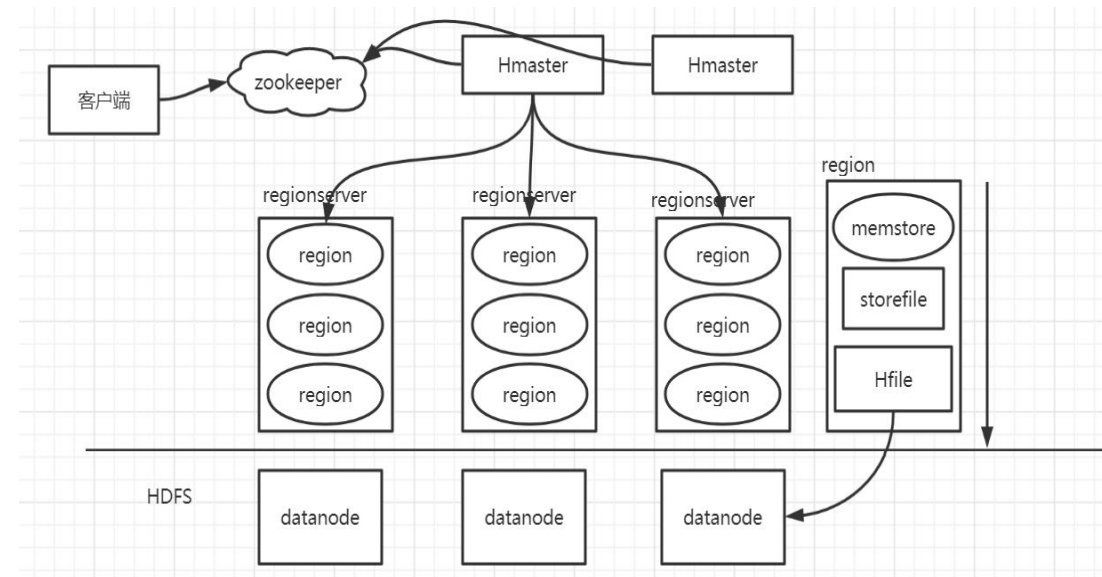
Hbase中使用布隆过滤器进行加速查找
Hudi的索引跟hbase比较像,它找数据时如果能够内存中的布隆过滤器,
如果没有就在磁盘中查找数据;
Hbase架构
2. Hudi的特性和功能
Hudi特性
• 效率的提升:支持CURD语义,支持增量处理,不再进行快照全量计算, 只处理有变更的记录并且只重写表中已更新/删除的部分,而不是重写整个表分区甚至整个表,为这些操作带来一个数量级的性能提升
• 更快的ETL/派生Pipelines:自动进行准实时增量计算,不再使用Azkaban 等调度系统依赖触发任务运行进行ETL处理
• 节省大量的计算资源成本
• 统一存储引擎
Hudi功能
• 支持快速,可插拔索引的upsert();
• 高效、只扫描新数据的增量查询
• 原子性的数据发布和回滚,支持恢复的Savepoint
• 具有mvcc(多版本并发控制)风格设计的读和写快照隔离;
• 已有记录update/delta的自管理压缩;
• 审核数据修改的时间轴元数据;
• 全状态数据保留功能。
3. Hudi的存储格式和查询类型
Hudi存储格式
Data - Hudi以两种不同的存储格式存储所有摄取的数据。这块的设计也是插件式的,用户可选择满足下列条件 的任意数据格式:
- 读优化的列存格式(ROFormat)。缺省值为Apache Parquet
- 写优化的行存格式(WOFormat)。缺省值为Apache Avro
存储格式的选型,判断业务场景读写哪个多
Hudi表类型
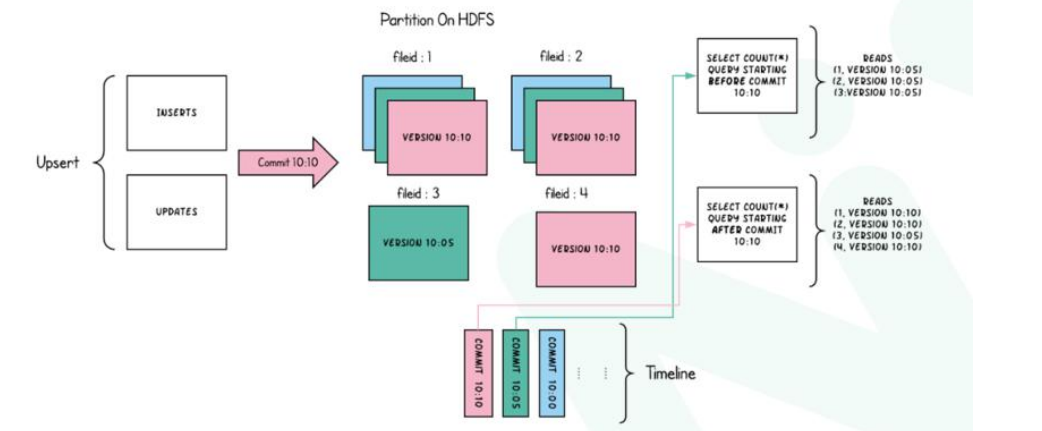
COW:Copy On Write(写时复制)
Copy On Write 类型表每次写入都会生成一个新的持有 base file(对应写入的 instant time ) 的 FileSlice。 用户在 snapshot 读取的时候会扫描所有最新的 FileSlice 下的 base file。
写数据时,先复制一个版本往这个版本写,读数据时从复制之前的读取;
MOR:Merge On Read(读时合并)
读时合并就是,base基准文件 插入新增,用写日志的方式写入;查询时base + log文件合并查询;
Merge On Read 表的写入行为,依据 index 的不同会有细微的差别:
•对于 BloomFilter 这种无法对 log file 生成 index 的索引方案,对于 INSERT 消息仍然会写 base file (parquet format),只有 UPDATE 消息会 append log 文件(因为 base file 已经记录了该 UPDATE 消息的
FileGroup ID)。
•对于可以对 log file 生成 index 的索引方案,例如 Flink writer 中基于 state 的索引,每次写入都是 log format,并且会不断追加和 roll over。 Merge On Read 表的读在 READ OPTIMIZED 模式下,只会读最近的
经过 compaction 的 comm
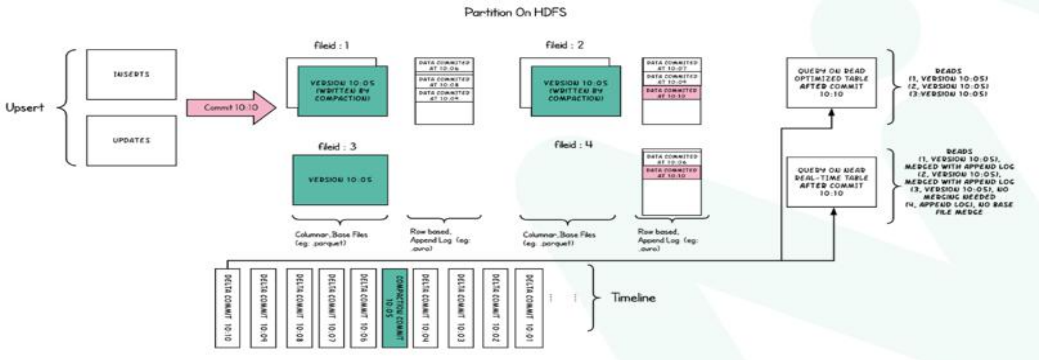
不同表如何加速
2种写入的方式 * 3种读查询方式 = 6种方式
Hudi选型结论
- 1.兼容历史数据仓库及模型
- 2.偏SQL分析,符合我司业务情况
- 3.数据分析时效性更快,兼容presto+hive+spark
- 4.数据存储更完整,历史快照版本管理,用户可随 意调用历史任意时间段状态数据
4. Hudi的企业级应用



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2020-09-26 算法 09| 多模式匹配算法| AC自动机