
五. 广告点击率(CTR)
广告点击率(CTR)预测项目
点击率(Click through rate)预估用来判断一条广告被用户点击的概率,对每次广告的点击做出预测,把用户最有可能点击的广告找出来,是广告技术最重要的算法之一。
https://www.kaggle.com/c/avazu-ctr-prediction

Dataset Description
File descriptions
train - Training set. 10 days of click-through data, ordered chronologically. Non-clicks and clicks are subsampled according to different strategies.
test - Test set. 1 day of ads to for testing your model predictions.
sampleSubmission.csv - Sample submission file in the correct format, corresponds to the All-0.5 Benchmark.
Data fields
id: ad identifier
click: 0/1 for non-click/click 预测的值
hour: format is YYMMDDHH, so 14091123 means 23:00 on Sept. 11, 2014 UTC.
C1 -- anonymized categorical variable
banner_pos 放在第一个或哪个位置上
site_id
site_domain
site_category
app_id
app_domain
app_category
device_id
device_ip
device_model
device_type
device_conn_type
C14-C21 -- anonymized categorical variables 类别型变量
模型评估
任何的AI系统需要有一个合理的评价指标,在没有想好评价标准之前最好暂时不要去开启项目的实施。因为一个没有办法评估的系统是没有办法去持续优化的,这是搭建任何AI系统时必须要考虑关键点。
对于广告点击率预测任务来说, 合理的评价指标是 F1-Score,由于此项目中, 正负样本的比例有较大的差距, 更适合使用 F1-Score来评估训练好的模型。
1. 特征选择技术
常用的特征选择技术
特征选择在建模过程中起到非常重要的作用。对于很多AI问题,数据本身具有很多的特征,但未必所有的特征跟所要完成的任务强相关,通常把这些不太相关的特征从数据中删除并不影响模型的效果,
反而会提升模型的泛化能力。 比如对于一个预测任务,假如一开始有100100个特征,但后来发现其中只有2020个特征是跟预测目标相关的,那这时候可以只保留其中2020个特征。
做特征选择的原因:
- ①特征越多就会导致模型越容易过拟合;
- ②很多的特征可能是噪声,噪声对模型建模没有任何帮助,反而会影响模型的效果;
常用的特征如下:
- ①尝试所有的组合;
- ②贪心算法;
- ③L1正则;
- ④使用树算法;
- ⑤相关性技术;
①尝试所有的组合
假设有五个特征,使用这五个特征去建模,所有特征组合的可能性叫powerset = 25-1 复杂度比较高 ,减1表示减的空集 ;适用于特征比较小的,好处是可以得到一个全局的最优解;
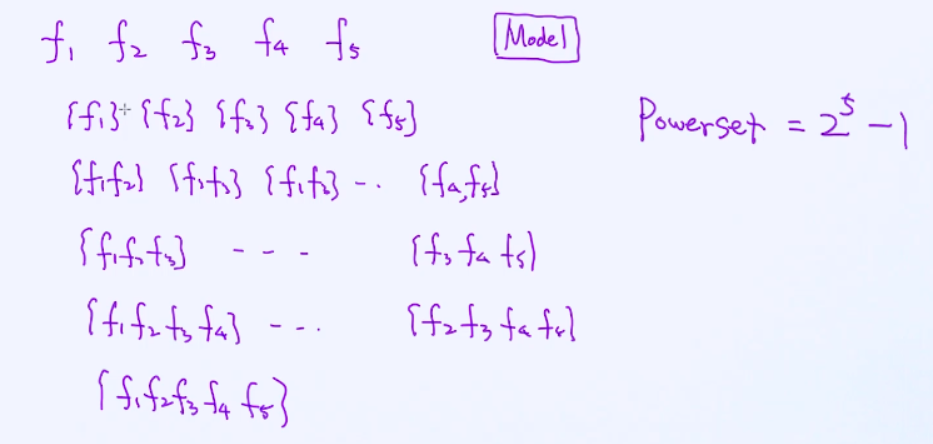
一个数据中有10 个特征, 假如我们考虑包含3个以上(包括3个)特征的组合, 总共有多少种组合? (2^10 - 56)种组合;
由于只考虑3个特征以上的组合, 也就意味着要排除包含1个特征的组合和包含2个特征的组合, 分别是10个和45个 (10*9/2), 另外我们也需要排除空集合, 所以答案是 2^10-56。
我们完全可以把所有的可能性都罗列出来,并尝试每一种组合,但这样的问题点在于时间复杂度特别高,这种复杂度我们也称之为指数级复杂度(exponential complexity)。
贪心算法 step-wise forward selection
假设有五个特征,使用某个model模型, 使用贪心算法去选择其中最好的子集,它是没办法保值给出解是全局最优解,只是当前时刻最好的方法论或者它的一个解;
首先解设S是空集,把每个特征做一个循环,计算每个特征的准确率,可看到最好的一个特征是f4,把它放到集合S中;
第二次循环,S里已经包含f4了,再去对f1、f2、f3、f5进行循环计算它的准确率;依次类推,把最好的特征加进来,这种算法比较高效,但不能得到全局最优;

对于贪心算法的特征选择, 它找出来的是sub-optimal特征组合; 这种方法需要借助于某个具体的模型一起使用;贪心算法的效率高;
贪心算法在特征选择的问题上, 并不能保证找出来的特征组合是全局最优解。
L1正则 => Sparse
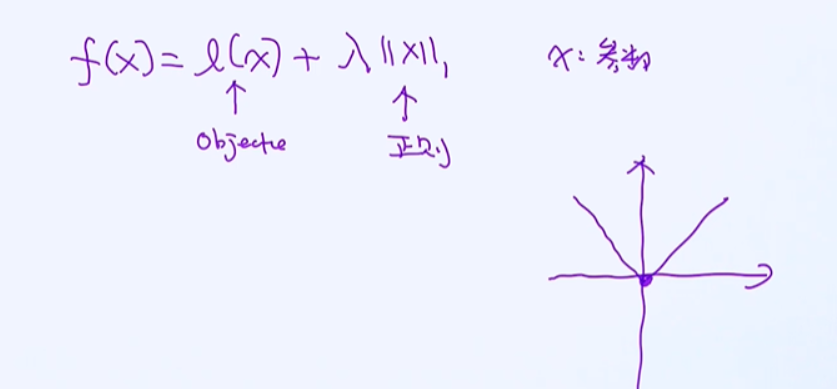
L1正则特别适用于样本量少,但特征维度高的情况。一个经典的场景就是神经科学,如果把每个人大脑里的神经元看作是特征,那这个特征维度非常之高。另外,在建模环节里,有时候我们希望模型训练过程
中产生一些稀疏性的特点,这时候L1的正则必然是我们的首选。
使用树算法(决策树)
相关性计算
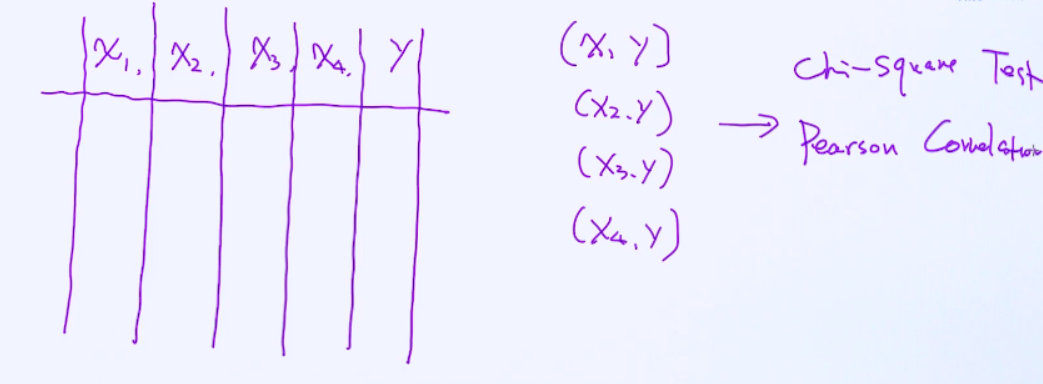
特征选择总结
那最后的问题是,特征选择到底用什么方法比较好呢? 其实也没有正确的答案,要看问题本身。比如我们要构建一个评分卡系统,而且这是跟钱直接打交道的,所以每一个使用的变量都要精心地设计。这时候,
我们通常花一些精力在变量相关性分析上,并决定哪些变量要放在模型里。通过相关性分析来选择变量有一个很大的好处:就是很强的可解释性,这也是金融领域的需求。
另外, sklearn里其实也提供了几个常用的特征选择的方法,可以去看下官方的文档:https://scikit-learn.org/stable/modules/feature_selection.html
2. 网格搜索和贝叶斯优化
两种用于超参数搜索的方法,分别为网格搜索和贝叶斯优化。
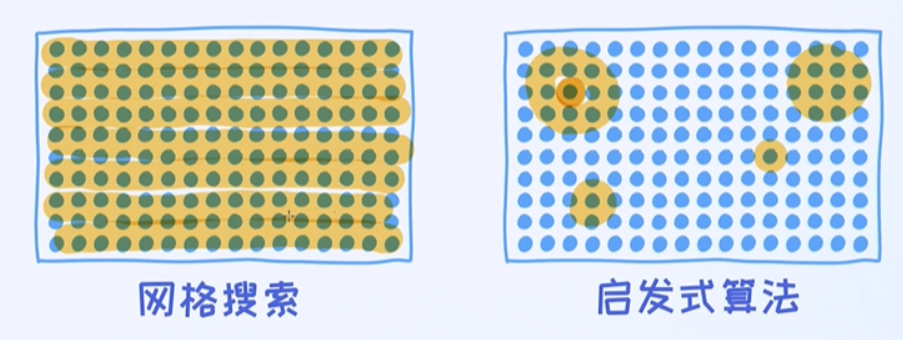
网格搜索技术
对于超参数的搜索,最常用的方法叫作网格搜索 (Grid Search),就是在可选的空间里,把每一种可能性逐一去尝试,也是工业界里最常用的方法。网格搜索核心思想无非就是把预先定义好的所有可能的组合全部
搜索一遍,最终定下来哪一组超参数组合的效果最好。
网络搜索(Grid Seard)

一个模型有3个超参数a, b, c, 对于这三个超参数我们去搜索最好的一种组合。
- 对于参数a, 使用np.linspace(1, 10, 10)来搜索,
- 对于参数b, 使用np.linspace(1,10,5)来搜索,
- 对于参数c, 使用np.logspace(0.01, 100, 5)
来搜索。请问: 对于此网格搜索,总共要考虑多少个组合? 10×5×5=250种
需要先了解 np.linspace和 np.logspace的用法。
np.linspace(1,10,10)的意思是在1和10的区间里取出10个点使得每个点之间的距离是一样的。
网格搜索是最简单的用于搜索超参数的方法。但由于需要把所有可能的组合全部考虑进来,时间复杂度非常高。但好处是,在网格搜索的前提下,这些操作都可以并行进行下去。
启发式搜索
遗传算法和贝叶斯优化都属于经典的启发式算法范畴。对于遗传算法,我们也可以用它来做量化投资。另外,对于贝叶斯优化,这是一个崭新的领域,它的内核是基于了贝叶斯思想,并内部使用了高斯过程等技
术。可以参考Ryan Adams的工作: http://www.cs.princeton.edu/~rpa
此项目的主要的目的是通过给定的广告信息和用户信息来预测一个广告被点击与否。 如果广告有很大概率被点击就展示广告,如果概率低,就不展示。 因为如果广告没有被点击,对双方(广告主、平
台)来讲都没有好处。所以预测这个概率非常重要,也是此项目的目标。
需要完成以下的任务:
1.数据的读取和理解: 把给定的.csv文件读入到内存,并通过pandas做数据方面的统计以及可视化来更深入地理解数据。
2.特征构造: 从原始特征中衍生出一些新的特征,这部分在机器学习领域也是很重要的工作。
3.特征的转化: 特征一般分为连续型(continuous)和类别型(categorical), 需要分别做不同的处理。
4.特征选择: 从已有的特征中选择合适的特征,这部分也是很多项目中必不可少的部分。
5.模型训练与评估: 通过交叉验证方式来训练模型,这里需要涉及到网格搜索等技术。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人