
二. 线性模型
线性回归
在统计学中,回归分析(regression analysis)指的是确定两种或两种以上变量间互相依赖的定量关系的一种统计分析方法。
按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。
所有机器学习方法论里,线性回归绝对是最简单且最实用的方法。只要涉及到回归问题,第一时间需要想到的就是线性回归。
一元线性回归针对的是只包含一个自变量的数据,可表示为 Y = a + b*X;
多元线性回归可表示为 Y = a + b1*X1 + b2*X2
线性回归作为一个必不可少的方法论,在几乎所有的 回归 问题上都可以派上用场,线性回归具有简单、有效、 可解释性强等特点。
线性回归是机器学习中最为经典的模型,总结起来:
- 几乎任何的回归问题可以使用线性回归来解决,因变量Y是连续的,自变量X可以是连续的也可以是离散的,回归线的性质是线性的;
- 线性回归训练效率高,可用于数据量特别大的情况
- 线性回归的可解释性强,这也是很多其他模型不具备的有点
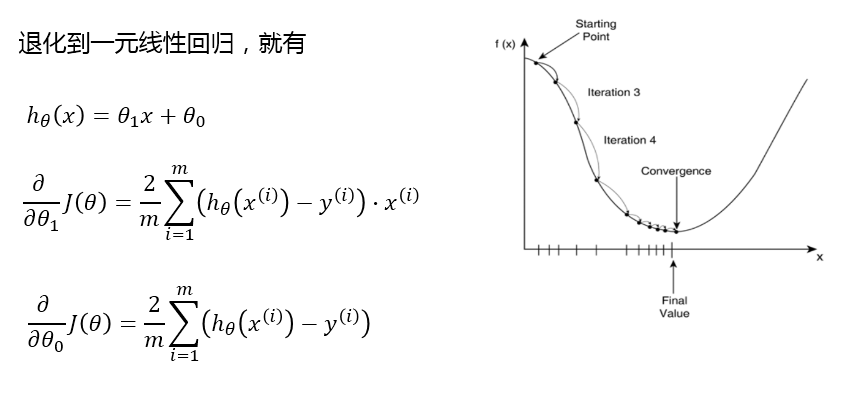
1. 一元线性回归模型
误差
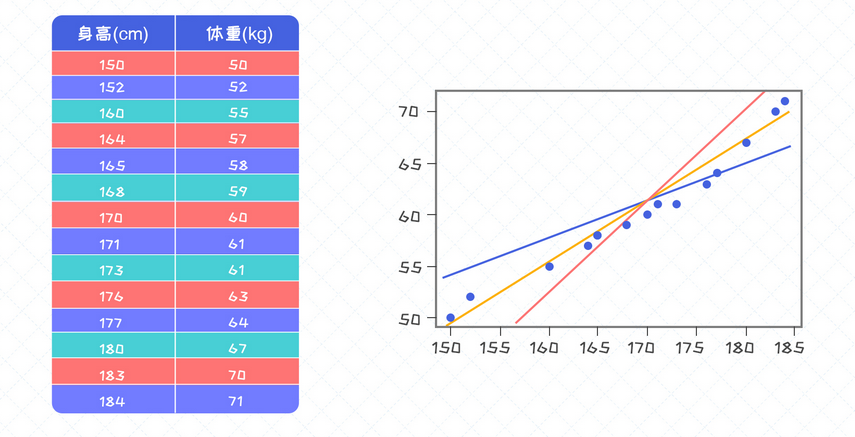
上图中黄线对数据的拟合度最高, 肉眼很容易看出哪一条线对样本的拟合度最高。这个拟合的标准如何量化? 可以通过计算的方式来求解出拟合度最高的那条线了。
量化的本质其实是设计一个评估标注, 并通过这个标准来寻求最好的那条线。
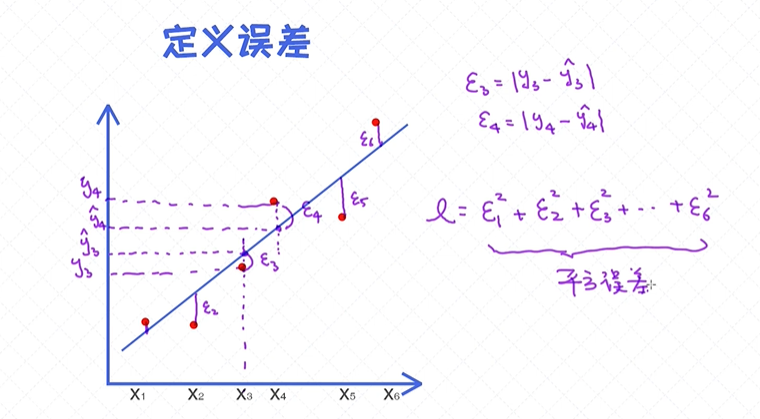
”离样本点越近的线条越适合“, 把这句话转换成一套可量化的评估标准,即误差 的概念, 就是实际值和预测值之间的差异。如果一条线产生的误差较小,就可以认为这条线拟合度较高。
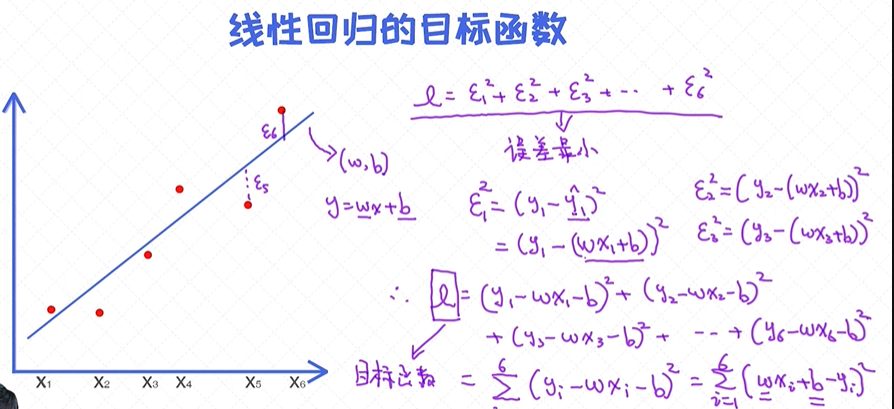
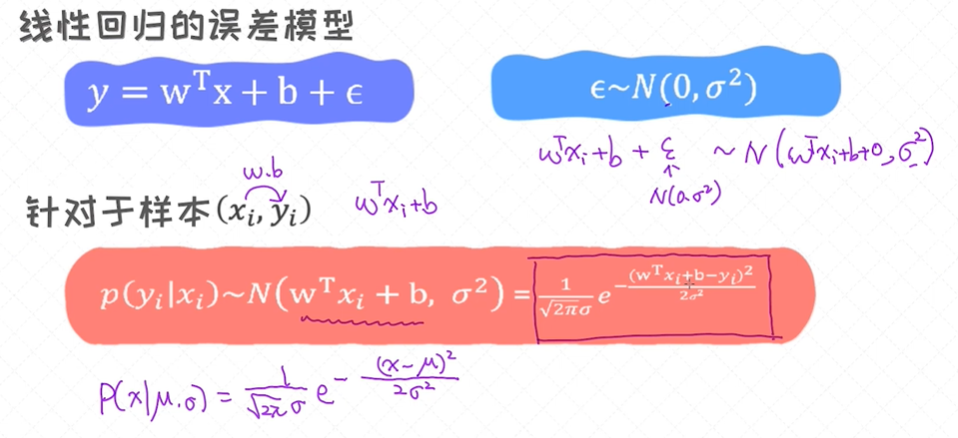
误差表示成了包含ϵ 的式子,用其来表示真实值和预测值之间的差异。一条线可以由两个参数来表示,分别是斜率w和偏移量b,所以寻求拟合度最好的那条线实际上是求解最好的w和b值。
为了求解这两个值,我们需要把ϵ表示成包含w, b的函数,这样一来整个误差就可以表示成包含 w, b的函数。
目标函数
样本数据虽不在一条直线上,但大致分布在一条直线周围,则把直线表示为:y(i) = wTx(i) + ϵ(i) ,其中ϵ是误差项,通常用一个随机变量表示,也称为随机扰动项;
如何界定这条直线 - 样本值和拟合值的误差,满足求和最小,所以回归可行,则ϵ 是一个期望值为0的随机变量:
y(i) = wTx(i) + ϵ(i) ϵ~N(0, σ2) ,ϵ误差项的要求:每一个ϵ相互独立,且服从均值为0,方差为σ2 的正态分布:
- 这里均值为0,意义在于ϵ 求和为0;
- 拟合直线不要求完全服从期望值为0的正态分布,但要求尽量趋近;
有了目标函数(objective function)之后,剩下的工作就是求解让这个目标函数最小的参数w,b了,这实际上就是模型训练的过程。
求解一元函数的最优解
给定一个包含若干个参数的函数, 如果想寻求这个函数的最小值或者最大值,这种问题称之为优化问题。
优化问题贯穿整个机器学习领域, 通常所说的”模型的训练“,其实指的就是函数的优化过程。
求解函数的最大最小值,就是函数的导数为0得到的x值代入求解即可得。
对于函数f(x)=x3−3x2−9x+10 的最小值为?
把导数设置为0之后,可以求出两个极值点,分别为3和-1。当x=3是获得最小值−17。

一元线性回归的最小二乘法
对于一元线性回归的求解, 首先把样本误差的平方作为 目标函数 , 再通过优化算法去寻求最优参数w,b, 整个过程称之为普通最小二乘法(ordinary least-square method)。
利用 求导的方法来求解极值点 (extreme point)是解决最小二乘的一个经典的优化方法。


求解线性回归 - 求导


多元线性回归
- 如果有两个或两个以上的自变量,这样的线性回归分析就称为多元线性回归
- 实际问题中,一个现象往往是受多个因素影响的,所以多元线性回归比一元线性回归的实际应用更广

梯度下降法求解线性回归
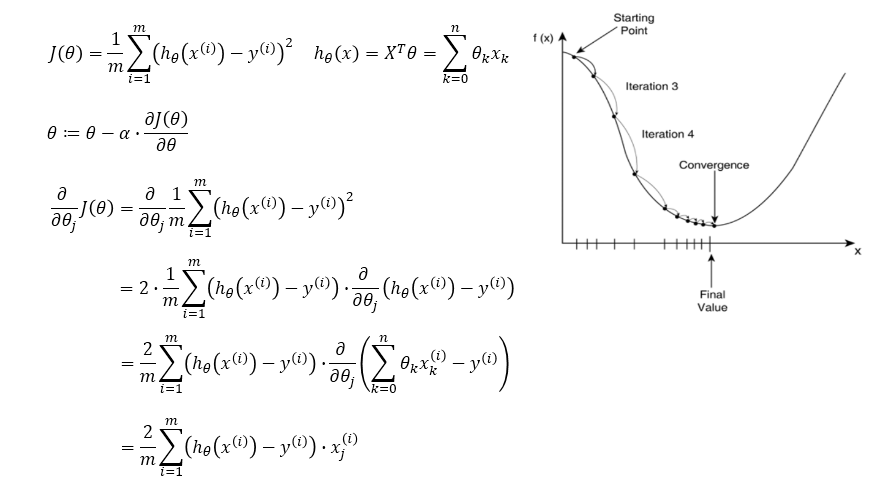
- α 在梯度下降算法中被称作为学习率或者步长; 步长 * 梯度
- 这意味着我们可以通过 α 来控制每一步走的距离,以保证不要走太快,错过了最低点;同时也要保证收敛速度不要太慢
- 所以 α 的选择在梯度下降法中往往是很重要的,不能太大也不能太小
梯度下降法流程

梯度下降法和最小二乘法
相同点:
本质和目标相同:两种方法都是经典的学习算法,在给定已知数据的前提下利用求导算出一个模型(函数),使得损失函数最小,然后对给定的新数据进行估算预测
不同点:
- 损失函数:梯度下降可以选取其它损失函数,而最小二乘一定是平方损失函数
- 实现方法:最小二乘法是直接求导找出全局最小;而梯度下降是一种迭代法
- 效果:最小二乘找到的一定是全局最小,但计算繁琐,且复杂情况下未必有解;梯度下降迭代计算简单,但找到的一般是局部最小,只有在目标函数是凸函数时才是全局最小;到最小点附近时收敛速度会变慢,且对初始点的选择极为敏感
代码:
在实际的工作中,我们只需要直接调用sklearn里的LinearRegression函数。
# 创建数据集,把数据写入到numpy数组
import numpy as np # 引用numpy库,主要用来做科学计算
import matplotlib.pyplot as plt # 引用matplotlib库,主要用来画图
data = np.array([[152,51],[156,53],[160,54],[164,55],
[168,57],[172,60],[176,62],[180,65],
[184,69],[188,72]])
# 打印大小
x, y = data[:,0], data[:,1]
#print (x.shape, y.shape)
# 1. 手动实现一个线性回归算法
# TODO: 实现w和b参数, w是斜率, b是偏移量
w = ((sum(x*y) / x.size) - (sum(x)/x.size * sum(y)/y.size)) / ((sum(x**2) / x.size) - (sum(x) / x.size) ** 2)
b = (sum(y)/y.size) - (w * sum(x)/x.size)
print ("通过手动实现的线性回归模型参数: %.5f %.5f"%(w,b))
# 2. 使用sklearn来实现线性回归模型, 比较跟手动实现的结果
from sklearn.linear_model import LinearRegression
model = LinearRegression().fit(x.reshape(-1,1),y)
print ("基于sklearn的线性回归模型参数:%.5f %.5f"%(model.coef_, model.intercept_))
---->>
通过手动实现的线性回归模型参数: 0.57576 -38.07879
基于sklearn的线性回归模型参数:0.57576 -38.07879
对于一元线性回归做一个简单总结
- 一元线性回归用来拟合一维的特征向量
- 一元线性回归的求解可以采用把导数设置为0的方法
- 一条线由两个参数来组成,分别是 斜率w和偏移量b,训练一元线性回归模型实际上是寻找最优参数
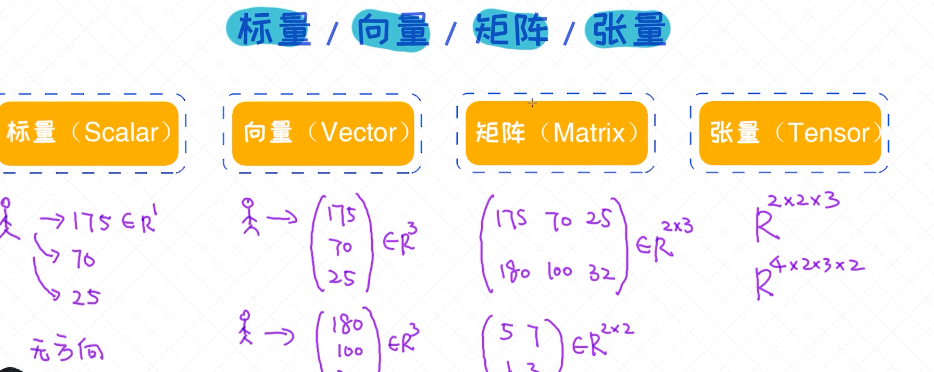
2. 向量、矩阵等的概念
向量以及它的基本运算
对于数据的表示的几个概念:
标量 (scalar), 向量 (vector), 矩阵 (matrix)和 张量 (tensor)。不管使用 sklearn , Pytorch ,还是 Tensorflow 也好,一定要掌握这几个概念。即便工具化趋势越来越明显,而
且我们可以把模型当作黑盒子来对待,但唯一绕不开的是这个“黑盒子的”输入和输出,而且输入和输出必须要以标量、向量、矩阵或者张量的方式来表示。
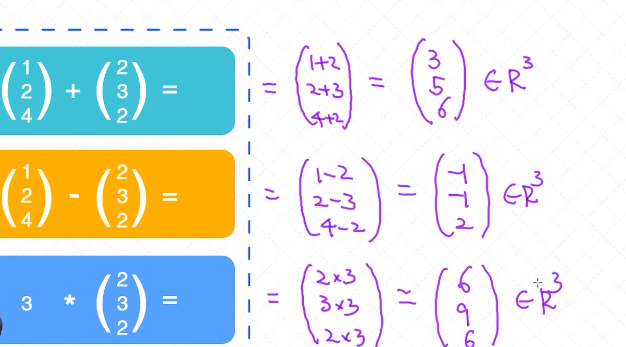
向量的运算
加、减、乘、内积
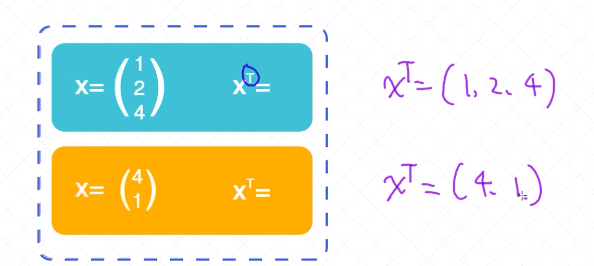
向量的转置(横着的给它逆时针旋转90° )
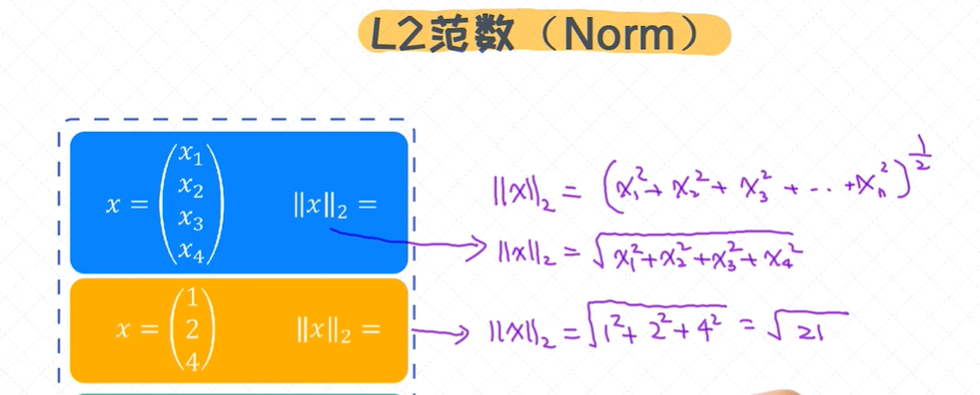
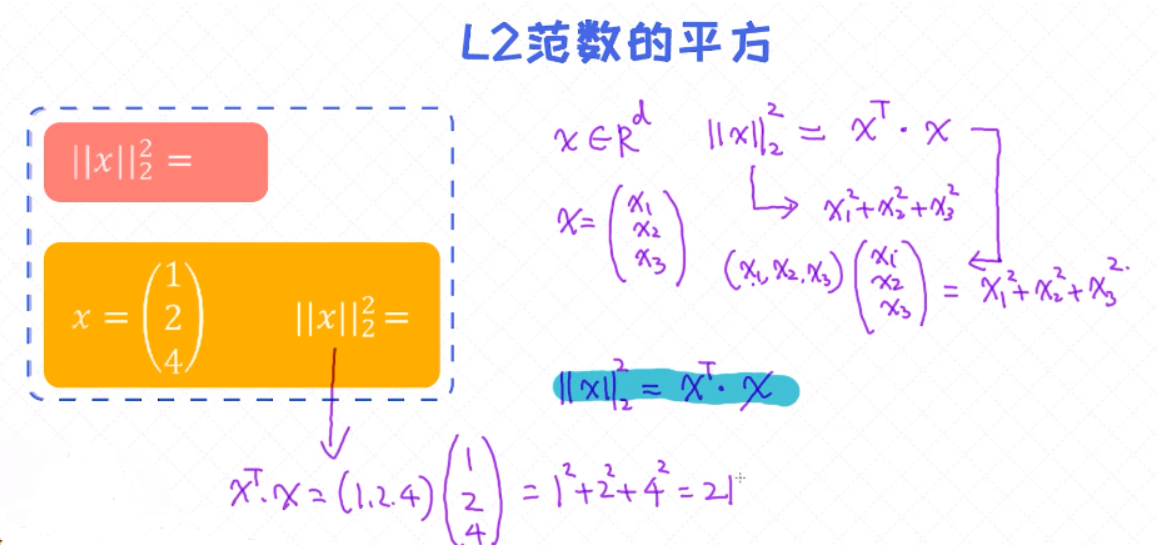
L2范数(Norm)
向量的范数,下面例子中, 四维向量和三维向量;
矩阵以及基本运算
除了向量, 还有一个很重要的概念是矩阵。矩阵也有一些常用的运算如 矩阵 加法、 矩阵 乘法、 矩阵 转置、 矩阵 求逆 。
矩阵可以看作多个向量的组合;
2行2列 R2*2

A ∈ Rm * n,表示这个矩阵有m行、n列;在数据集中的表示方法:X ∈ RN * O,N个样本,O个特征维度
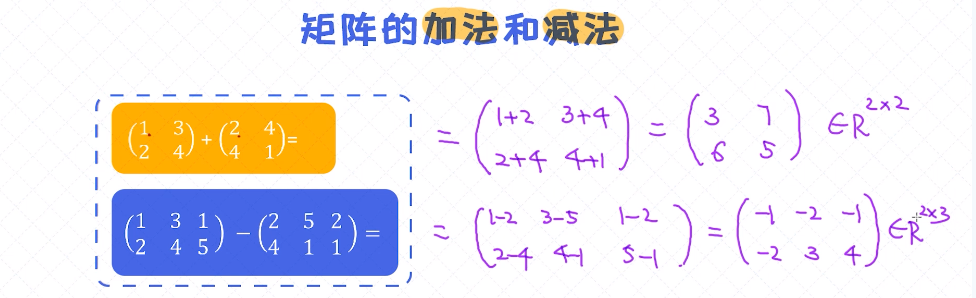
矩阵的加减法
矩阵的加减法跟向量的加减法一样
(都要保证两个矩阵的大小是一样的)
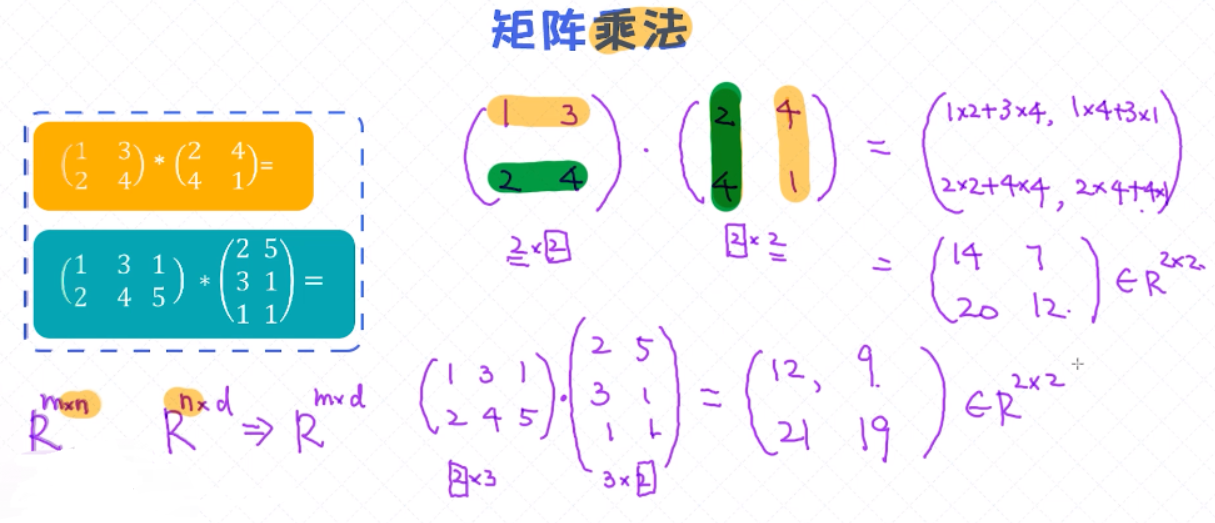
矩阵的乘法
矩阵的乘法跟它的加减法不太一样,两个矩阵如果相乘 Rm*n * Rn*d = Rm*d,第一个矩阵的第二个维度n 要等于第二个矩阵的第一个维度n;
第一个矩阵的第一行和 第二个矩阵的第一列做内积;
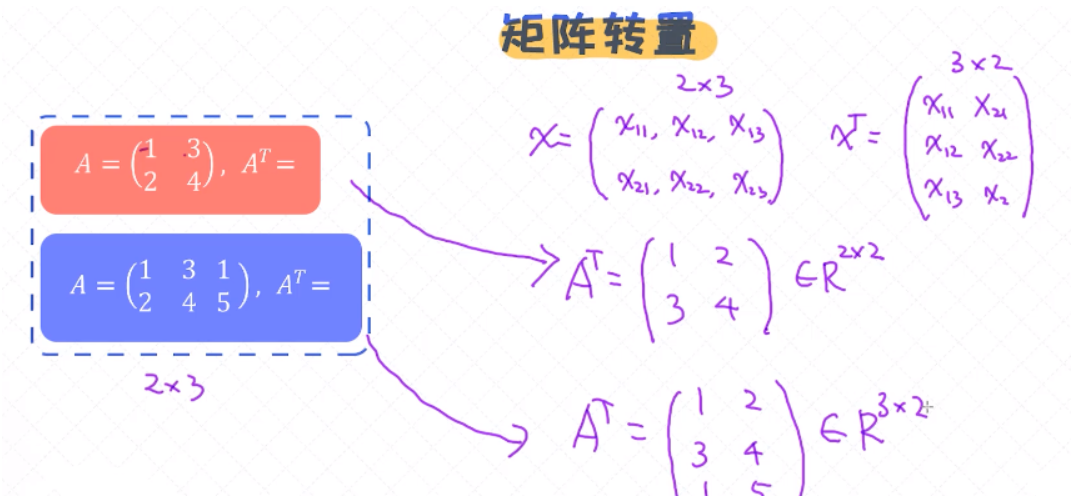
矩阵的转置
矩阵的转置跟向量的转置是类似的
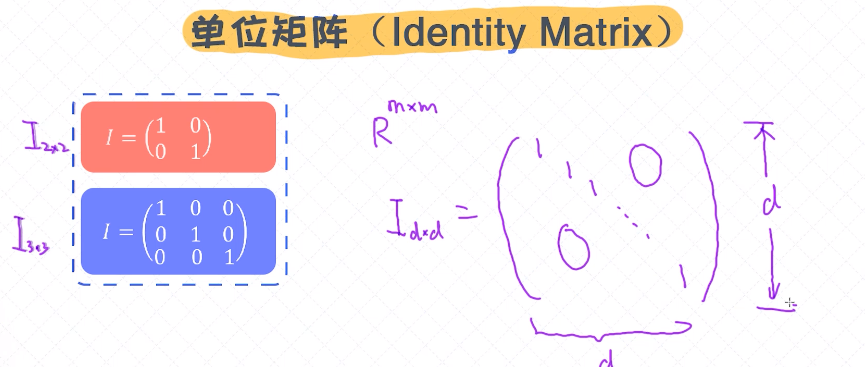
单位矩阵
对角线全是1,行数和列数是一样的,一般是m*m的形态;
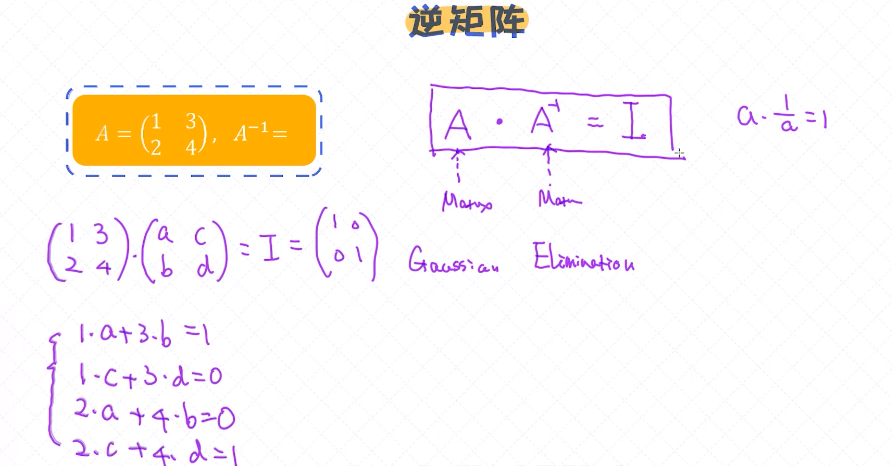
逆矩阵 A-1
逆矩阵和单位矩阵结合使用
A . A-1 = I (单位矩阵)
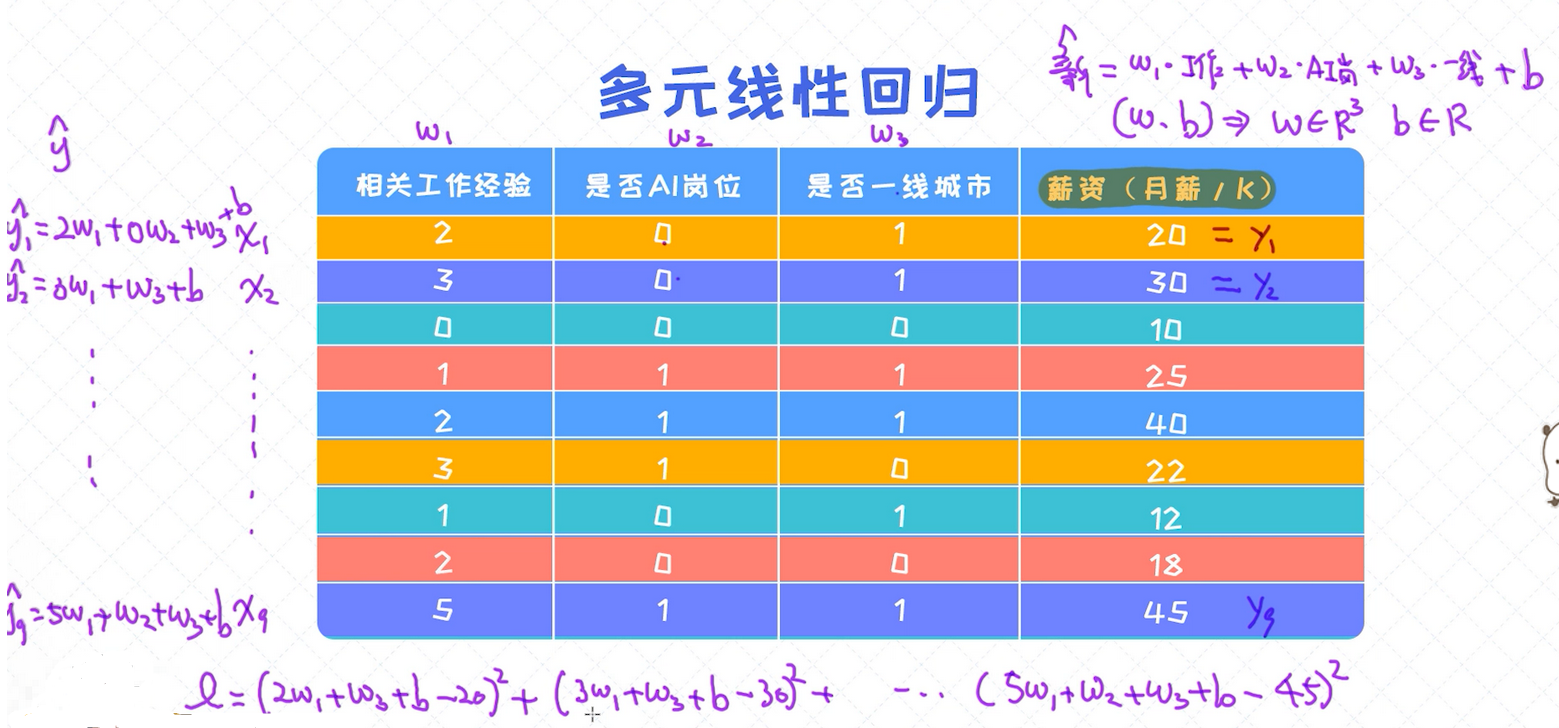
3. 多元线性回归模型
绝大多数情况下,需要处理的自变量可能有多个(特征向量维度大于1)。对于这类数据,假如要拟合线性回归模型,则使用的模型称之为多元线性回归模型。
在大多数情况下,给定的数据通常会包含多个 特征 ,所以更实用的还是多元线性回归模型。 除了特征个数的增加,从本质上跟 一元线性回归 是没有区别的。
y为薪资是需要去预测的,一共有三个特征(w1、w2、w3,三维向量),9个样本(x1、x2...x9)
跟一元线性回归没有本质的区别,唯一的区别是原来的参数w是标量,现在变成了向量的形式 多维向量;
多元线性回归的目标函数
(x1, y1),(x2, y2)...(xn, yn),称为样本;xi 由d 维向量构成,d个特征;yi是具体的值(一维) ;
薪资 = 影响因子1 * 工作经验 + 影响因子2*是否AI岗位 + 影响因子3 * 是否一线城市 + 回归系数;
Y(x) = θ0 + w1x1 + w2x2 + w3x3 = ∑wi * xi = wT x
所有样本的平方误差,需要循环 每个样本的平方误差。

多元线性回归的目标函数(矩阵形态)

有了目标函数之后,我们就可以通过优化算法去寻找让目标函数最小的参数w了。跟一元线性回归类似,首先需要把导数设置为0,之后在求解它的极值点。 唯一不同的点在于,对于多元线性回归我们处理
的参数变成了向量, 需要用到向量的求导法则。
对于向量的求导
多元线性回归的求解涉及到对向量的求导, 以及跟向量有关的基本运算。首先, 我们有必要把基础知识巩固一下,之后再去试着求解多元线性回归的解。 通常来讲,对向量和矩阵的求导会比较复杂。即便从事AI研究
很多年的学者也未必能把这些求导法则记得很清楚,所以很多时候还是要依赖于类似词典的参考资料。
对向量、矩阵的求导
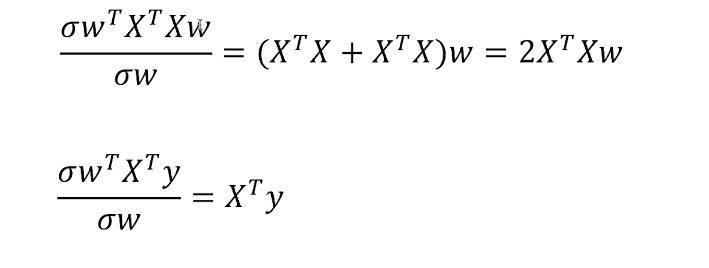
上图中分子有2个w,属于二阶求导;参数w的转置 * 某个值 * w ,查找刚工具书中的二阶求导法则:

第二个求导是属于一阶导,查找公式得到
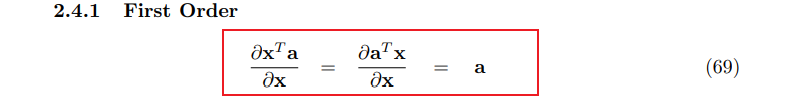
L2范数的平方
转置的运算

求多元线性回归的解
有了对向量和矩阵的基本概念, 以及理解了对它们的求导法则之后,便可以开始来解决多元线性回归的问题了, 先回到之前多元线性回归的目标函数。
多元线性回归的解析解
对于多元线性回归的目标函数,我们是通过求导的方式直接求出了对应的最优参数。这种方法,也称之为解析解(Analytical Solution)。
但需要注意的一点是,并不是所有的目标函数我们都可以通过把导数设置为0的方式来求出极值点的。(比如逻辑回归)

越简单的模型可解释性越强,越复杂的模型可解释性越弱;

从零实现多元线性回归模型的参数求解。
import numpy as np
from sklearn.linear_model import LinearRegression
# 生成样本数据, 特征维度为2
X = np.array([[1, 1], [1, 2], [2, 2], [2, 3]])
# y = 1 * x_0 + 2 * x_1 + 3
y = np.dot(X, np.array([1, 2])) + 3
# 先使用sklearn自带的库来解决
model = LinearRegression().fit(X, y)
# 打印参数以及偏移量(bias)
print ("基于sklearn的线性回归模型参数为 coef: ", model.coef_, " intercept: %.5f" %model.intercept_)
# TODO: 手动实现多元线性回归的参数估计, 把最后的结果放在res变量里。 res[0]存储的是偏移量,res[1:]存储的是模型参数
a = np.ones(X.shape[0]).reshape(-1, 1)
X = np.concatenate((a, X),axis=1)
res = np.matmul(np.linalg.inv(np.matmul(X.T, X)), np.matmul(X.T, y))
# 打印参数以偏移量(bias)
print ("通过手动实现的线性回归模型参数为 coef: ", res[1:], " intercept: %.5f"%res[0])
--->>>
基于sklearn的线性回归模型参数为 coef: [1. 2.] intercept: 3.00000
通过手动实现的线性回归模型参数为 coef: [1. 2.] intercept: 3.00000
数据线性相关的情况
import numpy as np
from sklearn.linear_model import LinearRegression
# 生成样本数据, 特征维度为2
X = np.array([[1, 1, 2], [2, 2, 3], [3, 3, 2], [5, 5, 2]])
# y = 1 * x_0 + 2 * x_1 + 3 * x_2 + 3
y = np.dot(X, np.array([1, 2, 3])) + 3
# 手动实现参数的求解。先把偏移量加到X里
a = np.ones(X.shape[0]).reshape(-1,1)
X = np.concatenate((a, X), axis=1)
# 通过矩阵、向量乘法来求解参数, res已经包含了偏移量
res = np.matmul(np.linalg.inv(np.matmul(X.T, X)), np.matmul(X.T, y))
# 打印参数以偏移量(bias)
print ("通过手动实现的线性回归模型参数为 coef: ", res[1:], " intercept: %.5f"%res[0])
----->>
numpy.linalg.LinAlgError: Singular matrix
当我们运行上述代码时出现了“Singular Matrix”的错误,导致没有办法进行下去。
问题主要出现在求解逆矩阵的过程中,因为并不是所有的矩阵都具有逆矩阵。
并不是所有的矩阵都具有逆矩阵, 对于某些矩阵我们是无法计算出逆矩阵的。那对于什么样的矩阵它没有逆矩阵呢?
答案是这个矩阵的行列式(Determinant)的值为0的时候,那什么时候行列式为0呢?
答案是矩阵为非满秩(not full rank)的时候。那为什么对于上述的数据,矩阵X是非满秩呢?
它的答案是: 因为特征之间线性相关!
很多概念包括行列式、秩、满秩等等。现阶段不要纠结这些概念, 它并不会影响后续对内容的理解,暂时把上述的观点当作是已知的就可以。
但如果感兴趣, 可以查看相应的资料去学习。
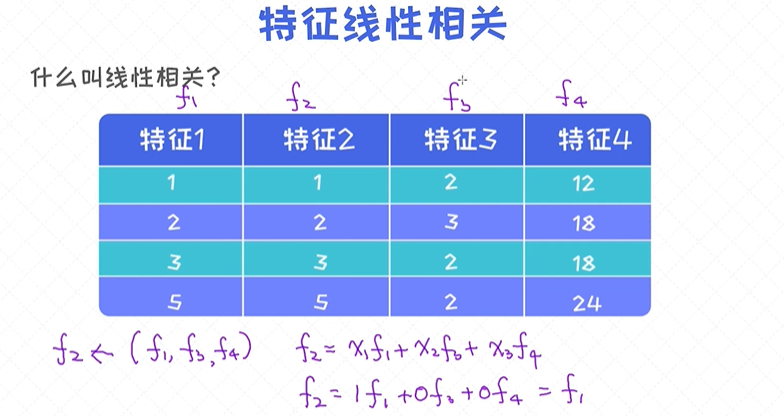
逆矩阵无法求解时
逆矩阵无法求解时:结合单位矩阵来求解无法求逆的问题
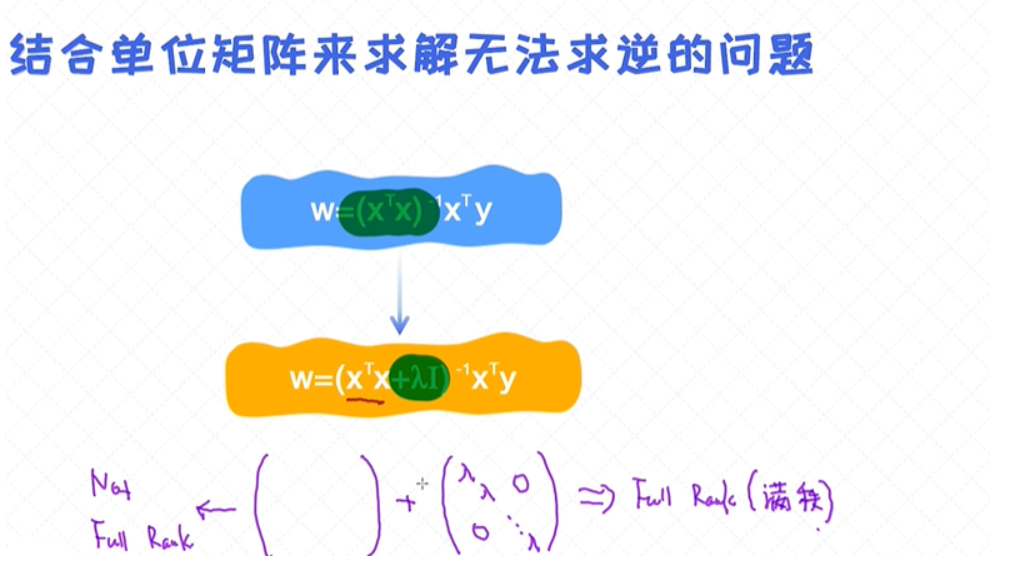
加了单位矩阵,其实跟加入正则(regularization)项起到的作用是一样的。
在现实问题中,在预处理阶段,我们通常会做特征之间的相关性检测,然后把那些相关性比较大的特征从中去掉, 这种操作也可以有效地避免无法求逆的问题。
两种常用的优化方法
- 解析解:通过把导数设置为0来求解;
- 梯度下降法:通过循环迭代的方式来求解;逻辑回归是无法使用解析解的方式,只能使用梯度下降法;
总结:
- 向量、矩阵、张量是建模中最常用的概念,一定要好好理解
- 多元线性回归解决多变量的问题
- 对于多元线性回归,可通过求导的方法来求出解析解
- 当特征线性相关的时候,无法求出解析解。一种处理方法是加入单位矩阵
4. 案例:股价预测
股价预测问题
首先,股价预测本身可以看作是回归问题,因为被预测的股价可以看作是具体的数值。但如果我们想预测的是未来股价的涨或者跌,那就变成分类问题了。股价其实是有一定预
测性的,但由于受到的外部因素很多,预测具有极高的挑战性。
理解了股票数据之后,该定义具体的预测任务了。 在这里,制定的任务是:根据历史的股价数据,预测出5天之后的股价。有了这个预测值之后就可以设计这样的买卖策略:
如果5天之后的预测值大于现在的价格,就买进。当然,实操中用的买卖策略远比这个复杂得多。
数据清洗
对于上面的数据,我们首先希望以时间的维度做一个排序,因为我们的任务是预测未来5天之后的股价。所以,下面按照date字段,把所有的样本以时间的升序做个排序。 具体排序的代码可以参考如下部分:
df['date'] = pd.to_datetime(df['date']) # 把字符串转换成时间的格式
df = df.set_index('date') # 把date字段作为index
# 按照时间升序排列
df.sort_values(by=['date'], inplace=True, ascending=True)
df.head() 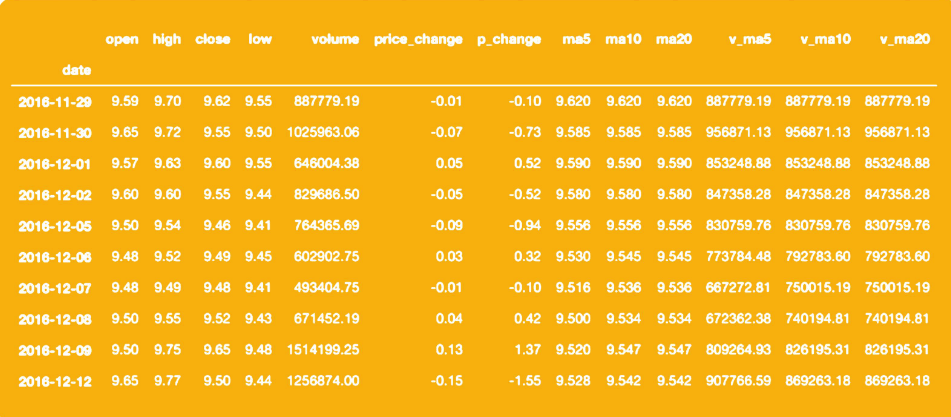
构造训练数据
由于问题本身是回归问题,所以需要预测值。对于这次的任务,我们的目标是通过当日的数据特征去预测5天之后的股价。在数据中,暂时还没有包含这5天之后的股价。但构造的方式很简单,比如对于2016-11-29当天的数据,根据5天的规定,预测值设定为9.49(5天之后的收盘价),对于2016-11-30当天的数据,预测值设定为9.48,以此类推。所以在预测值的构造上,我们只需要把原来数据中的close字段的值往前挪5位就可以了,可通过以下的代码来实现:
df['label'] = df['close'].shift(-num) # 构造预测值,这里的num=5 处理NA字段
df.dropna(inplace=True)
数据中每个字段的值
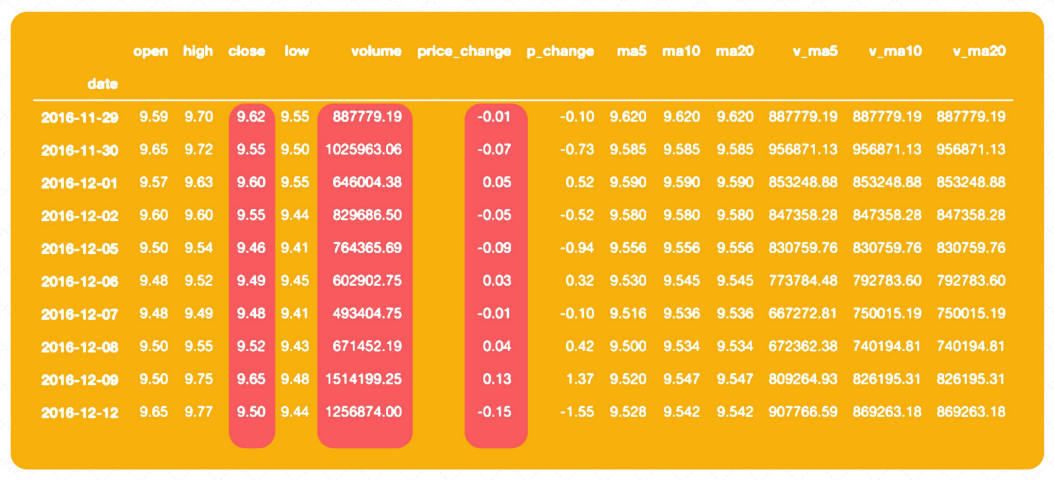
- 有些字段的值很大(如volume),有些字段的值很小 (open)
- 字段值的大小不一样,会影响模型的训练
- 数据值大,不代表这个特征就越重要
数据中明显可以看到不同数据字段的值的区间是不一样的, 这会影响后续模型的训练(但也要看具体是什么类型的模型,以及用什么样的优化方法)。
数据归一化
为了解决字段值之间大小的差异,我们通常在训练模型前做归一化的操作。归一化的目的就是把每个字段转换到同等大小的区间来消除字段大小所带来的影响。
归一化通常有两种方法:
- 第一种是 min-max归一化 ,
- 第二种是 z-score归一化 。


构建模型
处理完数据之后,就可以进入 建模 的阶段了。 针对于建模,相对比较简单,我们首先需要把数据分为训练数据和测试数据,之后在训练数据上训练模型,最后在测试数据上 评估模型 即可。
实现时,可以直接使用LinearRegression来构建线性回归模型,并用模型的fit()函数在训练数据上做训练,最后可以通过它的score()函数来评估模型的 准确率 。
5. 平方误差和高斯噪音
模型预误差
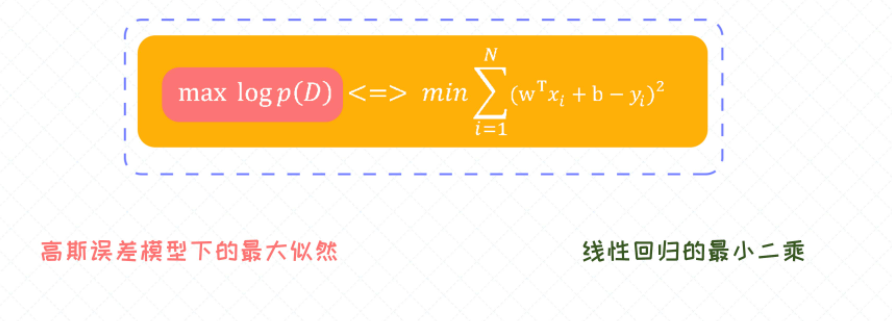
从噪声的角度来理解一下线性回归模型。线性回归的目标函数实际就是平方误差。对于平方误差,有没有可能从噪声模型来做解释呢?
线性回归的最小二乘法是基于高斯误差的假设得来的。
中心极限定理:这些误差的变量服从一个正态分布;
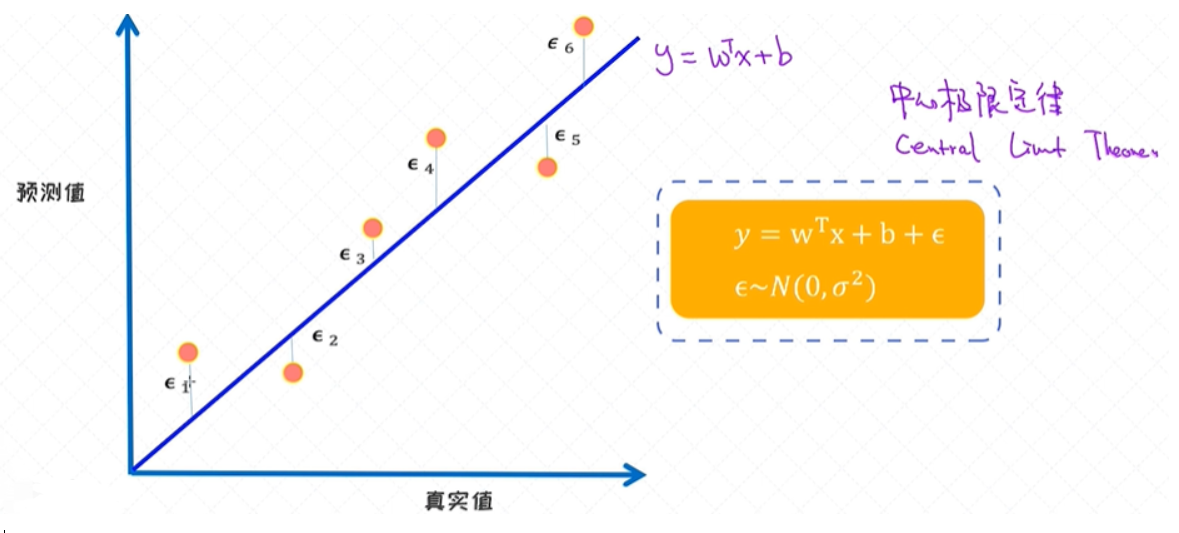

高斯分布
均值u、方差(曲线上的点--样本跟均值的距离有多大,方差越大图像越扁平,越小图像越高瘦;方差越小表示预测能力越强(很多样本集中在均值附近))
概率密度函数;

多元高斯分布
向量: X ∈ Rd ;高斯分布 N( u, ∑ ) u为均值, ∑ 协方差矩阵(衡量两两维度之间的相关性);

样本的似然概率
每个样本的似然概率
所有样本的似然概率
用条件概率来表示每一个样本, 这也称之为似然概率(likelihood)。那如何表示整体样本的似然概率呢?其实很简单,只需要把每个样本的似然概率相乘即可。得到所有样本的似然概率之后,我们接着可以通过
优化算法去求解最合适的参数,这个过程也称之为最大似然估计(Maximum Likelihood Estimation)。


当我们把误差分布假定为高斯分布的时候,最终得出来的所有样本的 似然函数 其实就是一开始讨论的平方误差。这种分析方法也叫作概率解释(Probabilistic Interpretation)的方法。
如果我们把误差的分布假定为另外一种分形态(如拉普拉斯分布),则最后得出来的结果跟平方误差结果是不一样的;
基于不同的分布假设,最后得出来的结果是不一样的。如果我们使用了拉普拉斯分布,对应的目标函数是真实值(x1)和预测值(x2)之间的绝对距离(∣x1−x2∣),而不是平方距离。
6. 线性回归模型评估
- SSE(和方差、误差平方和):The sum of squares due to error
- MSE(均方差、方差):Mean squared error
- RMSE(均方根、标准差):Root mean squared error
- R-square(确定系数): Coefficient of determination
SSE(和方差):该统计参数计算的是拟合数据和原始数据对应点的误差的平方和,SSE越接近于0 说明模型选择和拟合更好 数据预测也越成功,计算公式如下:
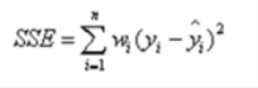
MSE(均方差):该统计参数是预测数据和原始数据对应点误差的平方和的均值,也就是SSE / n,和SSE没有太大区别,计算公式如下:
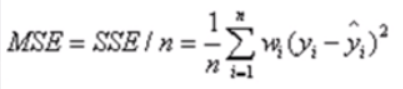
RMSE(均方根):该统计参数,也叫回归系统的拟合标准差,是MSE的平方根,计算公式如下:
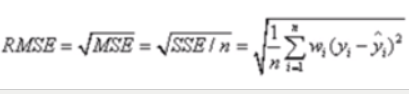
R-square(确定系数):
- SSR:Sum of squares of the regression,即预测数据与原始数据均值之差的平方和,公式如下:
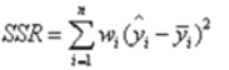
- SST:Total sum of squares,即原始数据和均值之差的平方和,公式如下:
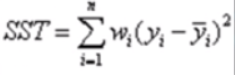
注: SST = SSE + SSR
R-square “确定系数” 是定义为SSR 和SST的比值;
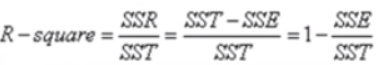
其中“确定系数” 是通过数据的变化来表征一个拟合的好坏,由上面的表达式可以知道“确定系数”的正常取值范围为[0, 1],越接近1,表明方程的变量对y 的解释能力越强,这个模型对数据拟合的也越好;
能比较的有两个 R_square '确定系数' 、 MSE,
做两个回归模型可以分别判断哪个MSE更小就好,R哪个接近于1哪个就更好。如果只有一个回归模型,判断是否接近1,只要是大于0.6、0.8就非常不错了。同时在后边做组成成分,假如现在有10个参
数,做一个回归模型,做一个R模型评估,比如说为0.85,把这10个参数降维,降维为3个主成分,再做一个3元的线性回归,这个叫回归模型2,为0.92,这个时候我们就选择那个3元的线性回归模型0.92
更好,相互比较做出最优比较。
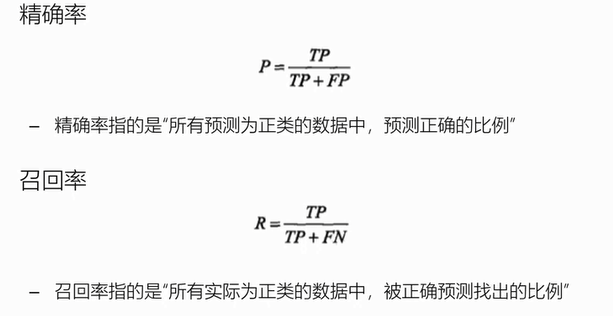
精确率和召回率

进行归一化
严格来说
归一化可以不做
但是
每个场景数值都有自己的特点,每个场景我都要专门调参
归一化好处:所有场景的数值都拉到一个维度
我的方法可以通用
特征敏感性研究
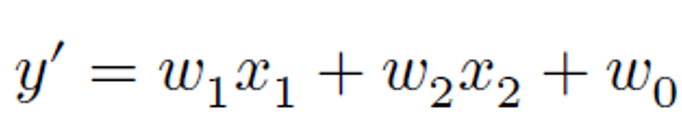
X2随机采样,对分类没有帮助,
训练结束时,w2->0
数据量大,才能抵消
数据量小,学出噪声
在模型学习时,数据量要足够大,才能消除影响
1.当数据量大的时候,对于没啥用的特征,对应w会趋向于0
2.数据量过小时,会学到一些无关的偶然事情
y=3x1+2x2+2x3+2
y:房价
x1:房屋面积
x2: 猪肉当天的涨幅
特征冗余问题


当特征出现冗余的时候,特征重要度会被稀释
x1=x2=x
y=6*x+10w
X1~x2都是面积,一模一样
Y=3*x1+3*x2+10
Y=5*x1+1*x2+10
Y=-3x1+5x2+10
w 数值越大,说明这个因素影响越大;
特征的数值越大,影响越大吗
y = w1x1 + w2x2 + w3x3 +w0
y = 10x1 + 6x2 + 3 , x1复制一个 x = x11 = x12
y = x11 + x12 + 6x2 + 3 (x11, x12系数相加为10即可)
y = 9x11 + 1x12 + 3
你的优势被拆开了,重要的值复制2遍,相当于是被稀释了
身高 体重 也有冗余(身高高的体重肯定大), 又比如工龄和年龄, 特征之间完全没有冗余很难,一般都有冗余;
大一般来说是重要,小不一定不重要;

- 指明了更新的方向
- 但是并没有指明力度
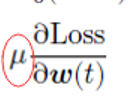 控制力度
控制力度
学习速度u的选择

模型效果评测:
1.训练集:用来学习的数据,参与更新W的数据
2.测试集:不参与训练,只是用来评测效果
3.有效集:也是一种测试集,但是训练中使用
过拟合:把噪声学会了
在训练过程中:用有效集测试Loss,如果有效集Loss开始上升,终止学习
训练最终目的:在没有看见过的数据(测试集)上Loss较低
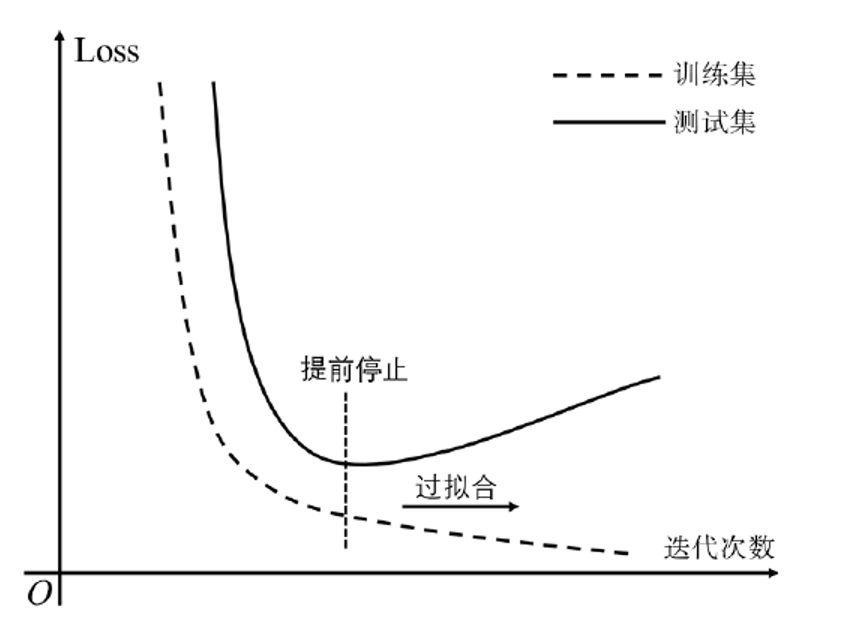
训练集Loss大,测试集Loss大:欠拟合 模型错误
训练集Loss小,测试集Loss小:最佳状态
训练集Loss小,测试集Loss大:过拟合 矫枉过正
训练集Loss大,测试集Loss小? 原则上有可能,但一般发生了异常:
测试集数量太小; 作弊,数据穿透了;
股票数据为什么不能预测?
损失函数的选择
MAE:mean absolute error
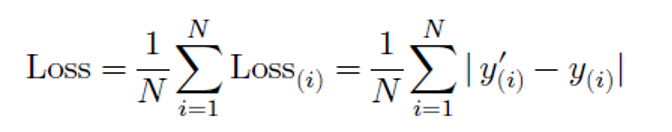
问题1:在0点导数不存在
问题2:学习困难
MAE不适用
MAE的更新力度,不能动态调整
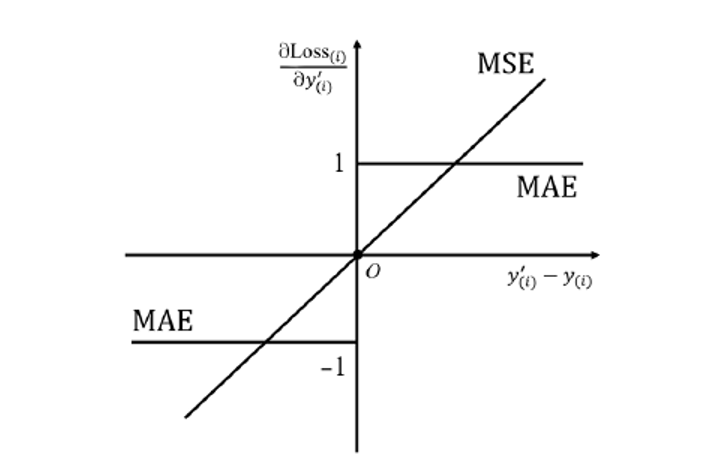
MSE 最根本的原因:
1.求解的便利性,保证有工程解
2.数学上的严格证明,理论的保证,MSE来源于噪声符合正态分布
为什么噪声要符合正态分布?
1.中心极限定理
2.正态分布是随机性最强的一种分布
正态分布也叫高斯分布
线性回归的总结:
1.X和y符合线性关系,如果不符合,采用多项式回归
2.求解w用梯度下降法,好于解方程
3.过拟合和欠拟合
4.特征的随机和冗余
5.为什么要选MSE

 浙公网安备 33010602011771号
浙公网安备 33010602011771号