
一. AI简介| 建模流程
1. 人工智能
所谓人工智能就是利用数学统计方法,统计数据中的规律,然后利用这些统计规律进行自动化数据处理,使计算机表现出某种智能的特性,而各种数学统计方法,就是大数据算法。
人工智能(AI),几乎的行业跟AI息息相关。谈到AI,很多人的脑海里第一个浮现出的可能是当年火遍全球的 AlphaGo 的事件。但实际上,它也仅仅是AI领域众多应用中的一个场景而已。现在,我们每天都在跟
AI打交道。比如当刷抖音时,每个视频都是通过AI算法推荐过来的; 逛淘宝时,它的推荐算法促使大家不断地买买买;现在国内很多小区开始装上了 人脸识别 门禁系统,只能刷脸就可以通过;
通俗来讲,只要一个系统具备一定的智能,同时可以帮助我们做一些决策,我们都可以把它列为AI系统。
Al is the field that studies the synthesis and analysis Of computational agents that act intelligently.
Think like humans Think rationally
Act like humans Actr ationally
- 分析犯罪嫌疑人生活轨迹及可能出现的场所,利用了计算机视觉(CV)技术和大数据分析犯罪嫌疑人生活轨迹及可能出现的场所;
- 在线客服,让人人都享受一对一专业服务,在线客服需要使用自然语言处理技术;
- 快速进行癌症早期筛查,帮助患者更早发现病灶,通过分析病理图像和其他一些身体状态特征得出。
人工智能的现状
近几年每个人都在谈论AI,甚至也流传AI可能会给人类带来威胁的言论。但实际上,从技术的角度来看,我们还远没有达到这个程度。特别是,近两年人们也已经开始意识到了这一点,对AI的认知也变得更
加的理智,不再像15年的时候那样AI的泡沫到处可见。我们认为18-19年大概是个分水岭,从那之后,能看出来人们对AI的理解变得越来越理性,同时从之前观望的态度,开始慢慢转变为真正试着去拥抱和学习AI
知识。
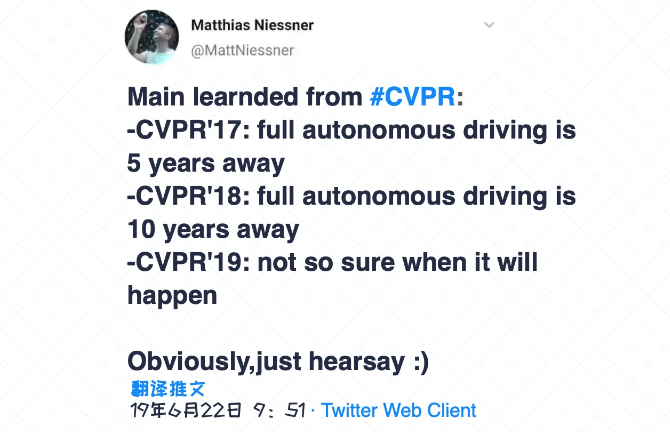
在早些年,我们甚至觉得无人驾驶的普及也就几年而已,但现在看来离真正全方位的落地还有很长的路要走。这里不仅仅需要有可靠的AI识别系统,而且也需要依赖于坚实的基础建设(比如为了无人驾驶而设
计的道路等),这些事情并不是短暂几年就可以完全做出来的,何况我们还需要考虑极高的安全问题。虽然特斯拉具备无人驾驶功能,但我想问有多少人真正放心地把驾驶权交给机器,然后自己在车里看书或者
睡觉?在知识探索的旅途中,我们经常会经历一个特殊的阶段:一个人掌握得越多,就会发现自己什么都不会。
之所以谈论这些较为负面的事情,并不是在否定AI的价值,只是希望大家能够对AI有个更理性的认知,不要过于理想化,同时也希望能够踏踏实实地学习并对待AI。其实AI远没有比大家想象中的那么复杂,万事
开头难!
AI的落地需要注意的事项
由于技术成熟度的限制,当我们试着去落地AI应用的时候,一定要认清技术的边界以及定义好问题的范围(scope),千万不要把问题设计得过大,而且要善于结合专家经验(人的经验)来实现AI系统。举一个“糟糕”
的例子,现阶段如果想去实现什么都能做的私人AI助理是不可能的。但相反,如果把问题的范围定位成设计一个帮你做记账管理的私人助手是有可能做出来的。
如果之前从事过IT行业,应该能了解到一个软件开发项目的失败率是很大的。对于AI应用来讲,可以自信地说市面上90%以上的工作可能最后给业务带来不了什么价值。其中有很多原因,比如问题定位的太大
导致超出了目前技术所能达到的极限,再比如一开始就定义了一个错误的问题等等。所以,以后如果决定做AI项目,实施之前一定要想好这些风险,要做充分的可行性分析。如何正确地实施一个AI项目从而减
少失败率
AI和 BI 最大的区别在于, AI可以帮助我们做决策, 但BI更多的是辅助人做决策。一个BI系统最终呈现给用户的是各类的可视化分析图,并通过这些数据统计,帮我们做更精准的决策。举个例子,基于用户信息
自动判断一个人的信用状况是AI应用,因为通过数据机器可以下定决策结果; 但相反,一个APP的留存分析是停留在了BI上,因为这些统计数据只是辅助我们做接下来产品上的决策。
人工智能的应用场景
人工智能的应用场景非常之多,不仅涉足到了新型的互联网行业、也在慢慢改变传统行业如房地产行业、保险行业等等。 那有没有行业不会受到人工智能影响呢? 其实还真想不到... 有人可能会提出理发行
业会不会不受AI影响? 但仔细想一想,其实不一定。比如我们在理发之前,可以在虚拟场景下尝试各类的发型,然后再决定具体的发型。再者,或许也能够做出机器人理发师呢?
- AI + 教育 ->因材施教、 人工智能助教、 人工智能老师、 自动判卷
- AI + 金融 ->大数据风控、 量化投资、 智能保险
- AI + 农业 ->种子、种植、管理等
- AI + 医疗 ->病情演变、图形分析等
- AI + 汽车 ->自动驾驶
- AI + 广告 ->精准投放
全民AI
数据思维(从数据中发掘价值)、 迭代思维、 最优化思维等;
数据公司(从数据中挖掘价值);
AI开发门槛越来越低;
2. 机器学习与深度学习
什么是机器学习
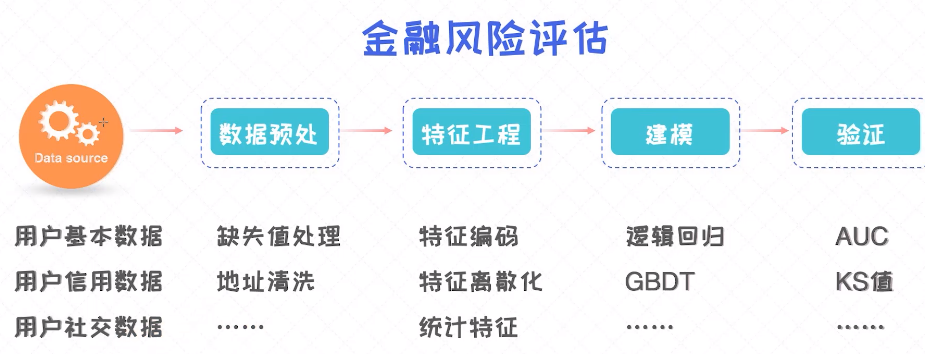
机器学习自动帮我们从数据中挖掘并总结规律,广泛应用在电商推荐、无人驾驶、人脸识别、金融风险评估等应用。
FieId of study that gives computers the ability to learn without being explicitly programmed.
比如想用程序来辨别张三和李四两个人。一种实现方法是根据它俩的 显著特征 来设计规则如:假如一个人比较高、偏胖、脸上有皱纹,同时拥有啤酒肚就识别为张三,否则为李四。这种实现方案是基于
人的 先验知识 的,也就把一个人已经了解到的知识提前写成规则的形式。
机器学习的运作方式恰好跟这个相反:假如我们手里有若干张张三和李四的照片,然后给机器看,同时告诉机器哪个是张三,哪个是李四。之后我们期待机器可以从这些数据中自动寻找可以分辨张三和李四的规律出来,这叫作机器学习。
- 机器学习技术可以帮助我们从数据中自动找出规律,并把这个规律应用在未来的任务中。
- 机器学习通常需要依赖于大量的数据。数据量越大,通常总结出来的规律就会越准确,对于预测效果也越好。
- 机器学习,从字面意思上可以理解为 ”机器“从数据中自动“学习”规律,而不是我们提前告诉机器具体怎么做,后者也称之为经验主义。
什么是深度学习
AI的崛起过程中有两件非常具有代表性的事件,一个是2012年的ImageNet竞赛, 另外一个是2015年的AlphaGo事件,利用的都是深度学习。深度学习带动了AI的发展和带动了大众对AI的热潮;
Deep Learning is a subfield Of machine learning concerned with algorithms inspired by the structure and function 0f the brain called artificial neural networks.
深度学习并不特指某一个模型,而是泛指某一类模型。一个模型如果是属于深度学习范畴,它必将具有比较”深“的结构。这种”深“度通常是通过把一系列简单的模型通过不断叠加的方式来实现的。
- 深度神经网络
- 深度随机森林
- 深度高斯混合模型
- 深度BI-LSTM
比如深度神经网络就是把经典的神经网络不断叠加在一起;深度随机森林就是把随机森林不断叠加在一起。
主流的深度学习模型
- 深度神经网络(Deep Neural Networks)
- 卷积网络(Convolutional Neural Networks) -- 图像
- 循环神经网络(Recurrent Neural Networks) -- 时序数据
- 递归神经网络(Recursive Neural Networks) -- 递归方式构造
- 生成式对抗网络(Generative Adversarial Networks) -- 生产图片
机器学习和深度学习
深度学习的提出实际上要远早于2000年,在1986年的时候hinton等人已经提出了反向传播算法(back-propagation)。在那个年代,以hinton为代表的学术界的人已经开始进行了深度学习相关的研究。但不幸的
是,那个年代我们缺乏数据,同时也缺乏好的硬件资源,导致深度学习未能把它的潜力足够发挥出来。所以,从另外一个角度,我们也可以说实际上当代AI的发展很大程度上依托于数据量的爆发式增长以及基于
摩尔定律的硬件的发展。

常用工具:
- Numpy、 Pandas、 matplotlib
- scikit_learn(机器学习算法)
- spark MLib(分布式-大数据环境)
- PyTorch、 keras、 TensorFlow (深度学习框架)
从应用的角度,AI技术可以分为三大类: 视觉、自然语言和语音。
文本(自然语言处理)、 图像| 视频(图像识别)、 语音识别(音频、语音)
AI领域顶级会议
- AI全领域:AAAI、IJCAI
- 机器学习领域:Neurips、ICML、UAI、AISTATS
- 深度学习领域:ICLR
- 计算机视觉领域:CVPR、ICCV、ECCV
- 自然语言处理领域:ACL、EMNLP、COLING、NAACL
- 数据挖掘领域:KDD、WSDM、SDM
- 语音识别领域:ICASSP、INTERSPEECH
机器学习基本概念
监督学习、无监督学习、回归、分类。
监督学习和无监督学习的区别
监督学习处理的数据是带有标签(label)的,无监督学习处理的数据则没有标签的。由于后者的数据没有被标记, 我们就无法做预测。
除了 监督学习 和 无监督学习 ,其实还有一类叫作强化学习(reinforcement learning)。AlphaGo就是强化学习最经典的代表作。虽然在棋牌等任务上强化学习取得了不俗的表现, 但对于工业界实际问题来讲,
强化学习目前为止并没有特别突出的表现,这也意味着强化学习技术本身也需要更多的探索。 其实,对于现实中的问题,它所面临的环境要比棋牌复杂得多,同时也充斥了很多的不确定性 。
监督学习例子:
- 人脸识别(人脸 -> 人名)
- 语音识别(语音 -> 文本)
- 主题/文本分类(文档->这个文本属于哪个主题?)
- 机器翻译
- 目标检测(图片里标记过的物体)
- 金融风控
- 情感分析(文本-情感)
- 自动驾驶
监督学习 进一步分为回归(Regression)和分类(Classfication)问题
- 其中回归问题是用来预测具体的数值如温度、身高、气温、股价;(输出连续性变量、数值)
- 分类问题则用来预测特定的类别, 如文档的主题, 信用的好坏、阴晴、好坏等。(输出特定的结果、数值)
数值和类别的主要区别在于后者是没有大小关系的, 比如”好“和”坏“,”电商“和"体育", ”国内“和”国外“。
无监督学习(聚类算法)
- 人群划分(精准推送)
特征与标签
数据集 (Dataset)包含了100个 样本 (sample), 每一个样本拥有50个特征和1个类别 标签 , 标签取自于(0,1)”,这就是经典的用于监督学习的数据。我们可以使用一个标准化的数学用语来表示上面的这句话。
一共有2个样本;
工作经验、职位、城市都属于特征,用X表示;
薪资属于标签(label),用Y表示,是我们需要去预测的,属于一个回归问题(预测的是个具体的值)。
| 工作经验 | 职位 | 城市 | 薪资(月薪/k) |
| 2 | 运营 | 北京 | ? |
| 3 | 后端开发工程师 | 杭州 | ? |
X就是一个矩阵,Y就是一个向量;
数据集的描述:

D表数据集,里边有n个样本,x1,x2...xn 叫一组特征向量; y1,y2...yn叫标签 ,这个标签数据其中一个类别。
训练数据和测试数据
对于给定的训练数据,我们通常把它进一步分为 训练数据 和 测试数据 。这么做的目的是需要留出一部分数据来验证训练出来的模型的好坏。我们使用训练数据来训练模型,并在测试数据上做最后的验证。
如果在测试数据上表现也良好,就说明达到了上线的标准。
3. 机器学习建模流程
机器学习建模通常都需要经过以下几步:
从 数据探索 、 数据处理 、 建模 到最终的 模型验证 和 部署上线 。
案例:通过身高去预测一个人的体重
属于经典的回归问题;AI建模流程:
1. 数据的探索
通过数据探索我们会对业务和数据本身有更深入的理解,从而能够选择更合适的方法来解决问题。 数据探索过程中,最常用的是 数据可视化技术 ,也就是把数据直观地展示在二维或者三维的空间。 通过这
种可视化的方法,我们可以试着理解数据的 分布特征 (如是否满足线性?)、发现是否包含 异常值 、 特征值 是否满足某一类分布(如高斯分布)等等。

# 创建数据集,把数据写入到numpy数组
import numpy as np # 引用numpy库,主要用来做科学计算
import matplotlib.pyplot as plt # 引用matplotlib库,主要用来画图
# 定义数据,总共10个样本,每个样本包含两个值,分别为身高和体重。
data = np.array([[152,51],[156,53],[160,54],[164,55],
[168,57],[172,60],[176,62],[180,65],
[184,69],[188,72]])
# 打印出数组的大小
print(data.shape) #(10, 2)
# 从data中提取身高和体重的值,分别存放在x, y变量中。
# data[:,0]指的是取出所有第一列,也就是身高特征。
x, y = data[:,0].reshape(-1,1), data[:,1]
# 在二维空间里画出身高和体重的分布图
plt.scatter(x, y, color='black')
plt.xlabel('height (cm)')
plt.ylabel('weight (kg)')
plt.show()
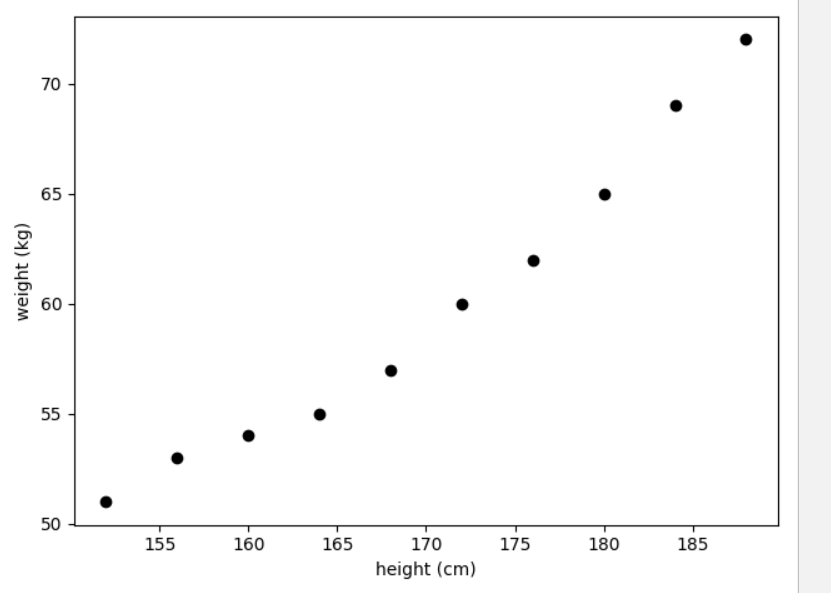
从身高和体重的可视化结果中,通过肉眼可以直观地看到它们之间的关系,偏向于线性关系。
数据本身具有线性关系,同时属于回归类问题,所以我们可以选择线性回归模型来解决这个任务。线性回归是最为经典的、最简单的回归模型,广泛地应用在各类预测任务中,如下一季度收入预测、销量预测等等。对于线性回归,在之后的章节里做详细的介绍。
在数据探索阶段,可视化技术起到了很重要的作用。但对于特征维度很高的数据来讲,直接去可视化是不太现实的,因为我们人类只能识别出二维或者三维的可视化。
如果给定的数据维度很大,如何做可视化分析呢?
- 没有特别好的方法一下子把所有特征一起做可视化
- 可以采用降维的方法,把特征映射到二维或者三维的空间
- 针对于每一个特征单独做可视化,并观察俩俩特征之间的关系
最为常用的方法是做数据的降维, 比如把100维的数据降维到2维或者3维的空间。用来做数据降维的方法有很多种, 其中最经典的方法叫作主成分分析(PCA)。
2. 数据预处理和特征工程
在建模过程中,数据预处理扮演着举足轻重的角色,这个过程通常会涉及到一些 数据清洗 的工作。在很多的AI任务中,数据本身具有大量的噪声,所以处理好这些是一项必要的工作。噪声可以是,数据字段的缺失、数据字段的异常、数据字段的不匹配等等。虽然这些工作看似很枯燥,但对于结果有着非常重要的影响,所以一定要引起足够的重视。
特征工程 (feature engineering)也起着非常重要的作用。所谓的特征工程指的是把一个物体表示为向量的过程。那为什么需要这种向量呢?这是因为任何模型的输入要求的就是一个个向量。
特征工程本身具有很多的学问和技巧, 而且对于不同的数据类型如文本或者图像, 需要使用不一样的特征工程技术。 在一般的建模过程中,花费50%以上的时间在特征工程上其实也很正常。
对于体重预测问题来讲,实际上不太需要特征预处理或者特征工程步骤的。首先,我们的特征都很干净,而且也没有任何异常值。另外,毕竟只有一个特征,也不太需要特征工程的步骤。
3. 构建回归模型
当选定了模型之后(如线性回归),下一步的事情就是针对于训练数据去 拟合 一个最好的线性回归模型。这部分的工作可以通过 sklearn 里封装好的函数来实现。
对于给定的特征X和标签y,我们可以直接调用sklearn里的LinearRegression()类初始化一个线性回归模型,之后再通过fit()函数在给定的数据上做拟合。样例代码如下:
# 实例化一个线性回归的模型
regr = linear_model.LinearRegression()
# 拟合给定的数据(X, y)
regr.fit(X_train,y_train) 拟合完之后对象regr里存储着已经训练好的线性回归模型的参数,并可以使用regr来对未来的数据做预测了。这里需要注意的是,对于给定的数据我们可以提前分好训练集和测试集。
数据集划分
- 如果样本数据充足,一种简单方法是随机将数据集切成三部分:训练集(training set)、验证集(validation set)和测试集(test set)
- 训练集用于训练模型,验证集用于模型选择,测试集用于学习方法评估
数据不充足时,可以重复地利用数据——交叉验证(cross validation)
简单交叉验证
- 数据随机分为两部分,如70%作为训练集,剩下30%作为测试集
- 训练集在不同的条件下(比如参数个数)训练模型,得到不同的模型
- 在测试集上评价各个模型的测试误差,选出最优模型
S折交叉验证
- 将数据随机切分为S个互不相交、相同大小的子集;S-1个做训练集,剩下一个做测试集
- 重复进行训练集、测试集的选取,有S种可能的选择
留一交叉验证
4. 验证模型效果
对于验证模型的效果,可以从两个方面考虑。一方面,我们可以观察在训练数据上的 拟合度 ,另外一方面观察在测试数据上的 预测能力 。在训练数据上的拟合度是根本,如果在训练数据上都没有很好地拟合,就更不要谈测试数据上的验证了。
对于线性回归模型,它的拟合度可以通过真实值和预测值之间的误差来表示。
# 计算训练好的模型在训练数据上的拟合度
print (regr.score(X_train, y_train))
# 可视化在训练数据上拟合后的线条,这部分通过matplotlib库来实现,线条可以通过
# plot()函数来实现
# 首先,画出给定的训练数据
plt.scatter(x_train, y_train, color='red')
# 画出训练好的线条
plt.plot(x_train, regr.predict(x_train), color='blue')
# 画x,y轴的标题
plt.xlabel('height (cm)')
plt.ylabel('weight (kg)') 代码如下:
# 引用 sklearn库,主要为了使用其中的线性回归模块
from sklearn import datasets, linear_model
# train_test_split用来把数据集拆分为训练集和测试机
from sklearn.model_selection import train_test_split
# 引用numpy库,主要用来做科学计算
import numpy as np
# 引用matplotlib库,主要用来画
import matplotlib.pyplot as plt
# 创建数据集,把数据写入到numpy数组
data = np.array([[152, 51], [156, 53], [160, 54], [164, 55],
[168, 57], [172, 60], [176, 62], [180, 65],
[184, 69], [188, 72]])
# 打印出数据大小
print("The size of dataset is (%d,%d)" % data.shape)
# X,y分别存放特征向量和标签. 注:这里使用了reshape(-1,1), 其主要的原因是
# data[:,0]是一维的数组(因为只有一个特征),但后面调用模型的时候对特征向量的要求
# 是矩阵的形式,所以这里做了reshape的操作。
X, y = data[:, 0].reshape(-1, 1), data[:, 1]
# 使用train_test_split函数把数据随机分为训练数据和测试数据。 训练数据的占比由
# 参数train_size来决定。如果这个值等于0.8,就意味着随机提取80%的数据作为训练集
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8)
# TODO 1. 请实例化一个线性回归的模型
# TODO 2. 在X_train,y_train上训练一个线性回归模型。 如果训练顺利,则regr会存储训练完成之后的结果模型
# 实例化一个线性回归的模型
regr = linear_model.LinearRegression()
# 拟合给定的数据(X, y)
regr.fit(X_train,y_train)
# 在训练集上做验证,并观察是否训练得当,首先输出训练集上的决定系数R平方值
print("Score for training data %.2f" % regr.score(X_train, y_train)) #0.97
# 画训练数据
plt.scatter(X_train, y_train, color='red')
# 画出训练好的线条
plt.plot(X_train, regr.predict(X_train), color='blue')
# TODO 3. 画在训练数据上已经拟合完毕的直线
# 画测试数据
plt.scatter(X_test, y_test, color='black')
# 画x,y轴的标题
plt.xlabel('height (cm)')
plt.ylabel('weight(kg)')
plt.show()
# 输出在测试集上的决定系数R平方值
print("Score for testing data %.2f" %regr.score(X_test, y_test))
print("Prediction for a person with height 171 is: %.2f" % regr.predict([[171]]))
---->>
The size of dataset is (10,2)
Score for training data 0.97
Score for testing data 0.89
Prediction for a person with height 171 is: 60.38



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人