
Apache Kudu
1. Kudu
Kudu,Storage for Fast Analytics on fast Data,C++实现的分布式存储系统。是专为Apache Hadoop平台开发的列式存储管理器。Kudu具有Hadoop生态系统应用程序的共同技术特性:它在商品硬件上运行,可水平扩展,并支持高可用性操作。
概述
低延迟的随机访问; 快速的scan能力; 有效提升CPU利用率
(1)与MapReduce,Spark和其他Hadoop生态系统组件集成
(2)与Apache Impala的紧密集成,使其成为将HDFS与Apache Parquet结合使用的好选择。
(3)强大而灵活的一致性模型,允许您根据每个请求选择一致性要求,包括用于严格可序列化的一致性的选项
(4)同时运行顺序和随机工作负载的强大性能。
(5)高可用性。例如,如果3个副本中有2个副本或5个副本中有3个副本可用,则可用。
(6)结构化数据模型,列式存储。
适用场景:
实时数据的实时分析
- predictive learning models
- online reporting of market data
Time-series application
- 数据是根据时间的发生顺序来记录的
主要适用于OLAP场景; 支持频繁更新的数据进行快速分析;
介于HBase和HDFS之间,兼具高效的随机读写和顺序扫描能力,与Spark,Impala高度集成。
架构原理实现
① 数据模型
结构化数据
Schema
- Column(列名、类型、是否为null)
- Primary key(用户指定的若干个列的有序组合,满足唯一性约束)
- Partition
Alter Table
- Alter table name
- Add/remove non-PrimaryKey columns
- Add/remove range partition
不支持二级索引
只支持单行事务
② 一致性模型
Snapshot Consistency(默认的一致性模型)
- 只保证一个客户端能够看到自己所提交的写操作,而并不保障全局的(跨多个客户端的)事务可见性。
- 具有更好的读性能,但可能会有 write skew 问题。
External Consistency
- 能够完全保证整个系统的串行化。
- 两种实现方式:
在 clients 之间显式地传递时间戳;
提供类似 Spanner 的 commit-wait 机制:写入一条数据之后,client 需要等待一段时间来确定写入成功。
③ 数据分片
Hash Partition:避免热点
Range Partition: 提高scan效率
一个 partition schema 可以包括 0 或者多个 hash-partitioning 规则和最多一个 range-partitioning 规则
Primary key: Partition key
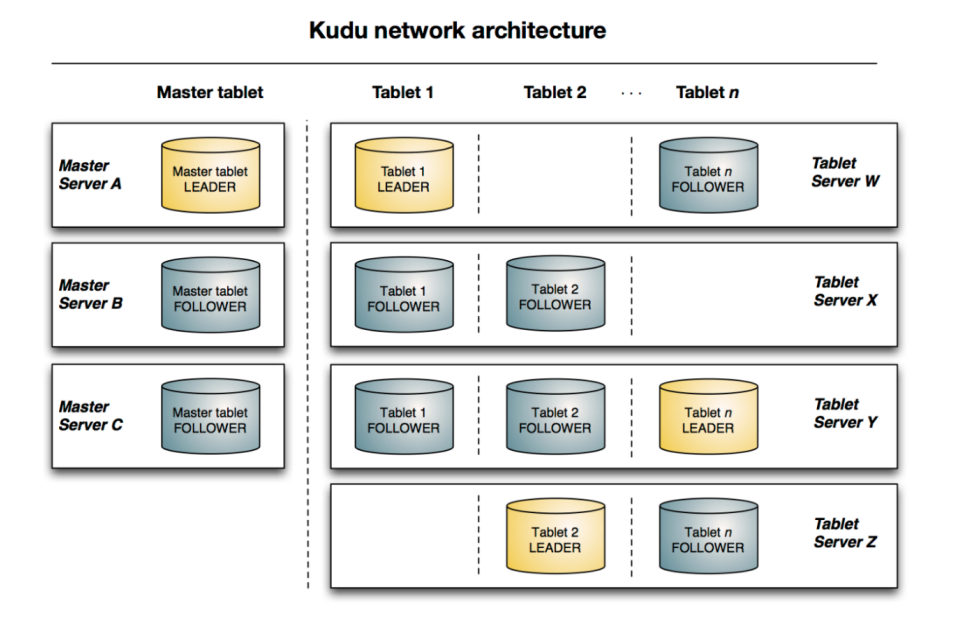
Master
- 本质也是Tablet Server,管理两个元表:Table、Tablet。
- 存放表的Schema信息(Table),负责处理建表等请求。
- 跟踪管理集群中的所有的Tablet Server,并且在Tablet Server异常之后协调数据的重部署。
- 存放Tablet到Tablet Server的部署信息(Tablet)。
Tablet Storage
- 可提供快速的列式查询。
- 可支持快速的随机更新
- 可提供更为稳定的查询性能保障。
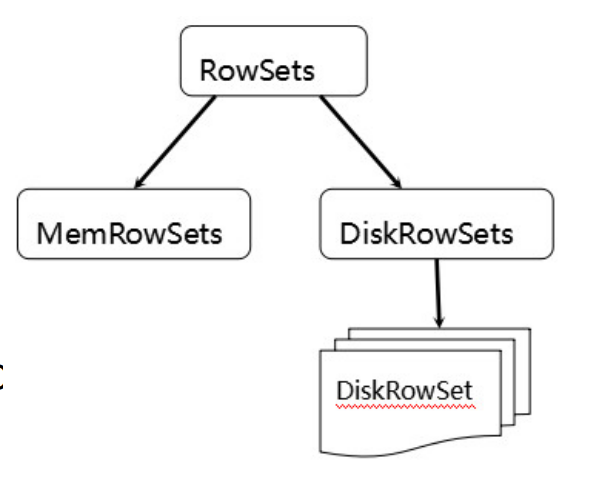
- 类似LSM
- MemRowSet
- 行存,B-Tree
- Insert写入MRS,MRS满或定时Flush到DRS
- DiskRowSet
- 列存,B-Tree
- 包含两部分数据: BaseData with index tree 和 Delta to store updates
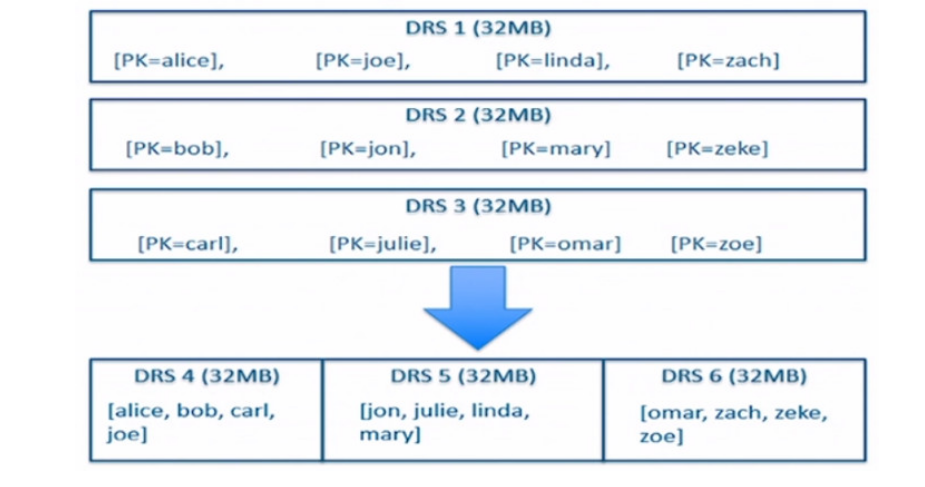
Compaction
将已经存在的多个DiskRowSets重新排序而生成一个新的DiskRowSets,提升scan效率。
一致性协议
Raft算法 如果出现failed leader election,使用了 exponential back-off 算法来处理 leader re-election 问题。
当一个新的 leader 跟 follower 进行交互的时候,Raft 会尝试先找到这两个节点的 log 分叉点,然后 leader 再从这个点去发送 log。Kudu 直接是通过 committedIndex 这个点来发送。
其他一些术语
(1)Columnar Data Store
Kudu是一个列式数据存储。列式数据存储将数据存储在强类型的列中。通过适当的设计,由于以下几个原因,它对于分析或数据仓库工作负载而言是优越的。
(2)Read Efficiency
对于分析查询,您可以阅读单个列或该列的一部分,而忽略其他列。这意味着您可以在读取磁盘上最少数量的块的同时完成查询。对于基于行的存储,即使您仅从几列中返回值,也需要读取整行。
(3)Data Compression
Kudu表中的每一列都可以根据列的类型使用一种编码来创建。
https://kudu.apache.org/docs/schema_design.html#encoding
(4)Table
表是您的数据存储在Kudu中的位置,一个表具有一个模式和一个完全有序的主键,表分为多段称为tablets
(5)Tablet
一个片(tablet)是表的连续段,类似于其他数据存储引擎或关系数据库的分区。一个给定的分片可以在多个服务器上进行复制,并且在任何给定的时间点,这些副本之一会被认为是leader片(tablet)。任何副本片均可服务于读取,而写入则要求提供服务的分片服务(tablet server)达成共识
(6)Tablet Server
分片服务用于存储并提供客户端。对于给定的分片,一个分片服务充当领导者,而其他分片服务则充当该分片服务的跟随者副本。仅leader服务用于写请求,其他跟随者服务用于读请求。leader选举用Raft共识算法,一个tablet server 可以提供多个tablet,并且一个tablet可以服务于多个tablet server。
https://kudu.apache.org/docs/#raft
(7)Master
master会持续跟踪所有tables,tablet servers,the catalog table,以及与集群有关的其他元数据。只能有一个leader,如果leader挂了则使用Raft共识算法重新选举。主服务器还协调客户端的元数据操作。
例如,在创建新表时,客户端在内部将请求发送到主服务器。主机将新表的元数据写入目录表,并协调tablet server创建tablet的过程。
所有master的数据存储在一个tablet,可以复制到其他候选master。
Tablet server默认每秒一次向master发送心跳
(8)Catalog Table
目录表是kudu用于存储元数据的位置,它存储有关table和tablet的信息。目录表可能无法直接读取或写入。而是只能通过客户端Api的方式进行访问。
(9)Logical Replication
kudu复制操作,不是磁盘数据,与物理复制相反这成为逻辑复制。有以下几个有点:
- 尽管插入和修改确实会通过网络传输数据,但是删除并不需要移动任何数据。删除操作被发送到每个tablet server,每个tablet server在本地执行删除。
- 物理操作(例如压缩)不需要在kudu中通过网络传输数据,这与使用HDFS的存储系统不一样,在HDFS中需要通过网络传输数据块以实现所需数量的副本。
- Tablet无需同时或按相同的时间表执行压缩,也无需在物理层上保持同步。由于压缩或沉重的写入负载,这减少所有tablet server同时经历高延迟的机会
写流程

读流程
- 读流程与Hbase类似,重点优化以下几点:
- 通过Scan的范围,与每一个DiskRowSets中的Primary Key Range进行对比,可以首先过滤掉一些不必要参与此次Scan的DiskRowSets。
- Delta Store部分,针对记录级别的更改,记录了Base Data中对应原始数据的Offset。
- Lazy Materialization:基于一些列的条件进行过滤查询时,可以优先过滤掉一些不必要的Primary Keys。
与其他系统的对接
MapReduce: 提供针对Kudu用户表的Input以及Output任务对接。
Spark: 提供与Spark SQL以及DataFrames的对接。
Impala: Kudu的SQL能力源自与Impala的集成。在这些集成中,能够很好的感知Kudu表数据的本地性信息,能够充分利用Kudu所提供的过滤器对查询进行优化,同时,Impala本身的DDL/DML语法针对Kudu也做了一些扩展
性能评估
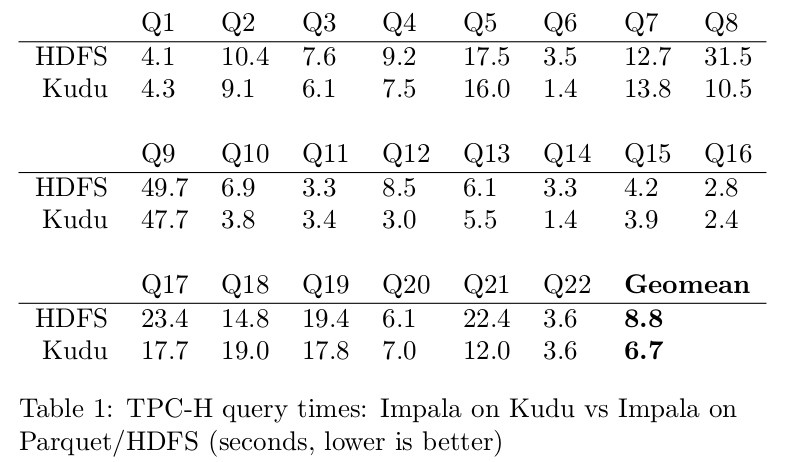
① 与Parquet对比
Impala On Kudu的平均性能比Impala On Parquet提升了31%
Lazy Meterialization
对CPU效率的提升
② Impala-Kudu与Phoenix-HBase的对比

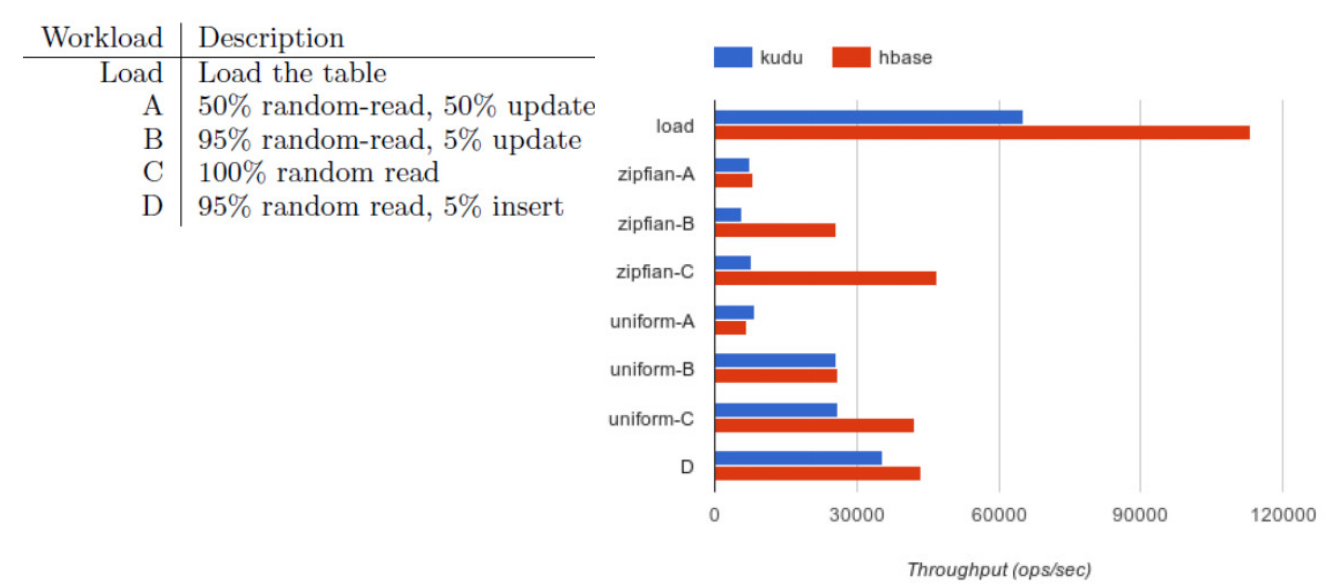
③ 随机读写性能测试
2. Spark使用Kudu
环境搭建
CDH-5.16.2 Spark2.0以上 kudu1.7

查看Web UI
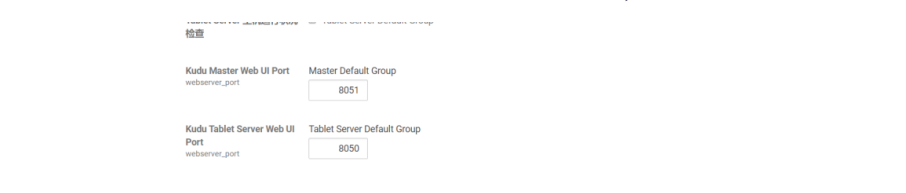
根据CDH配置可以看出KUDU WEB UI端口为8050 8051,将相应端口放开
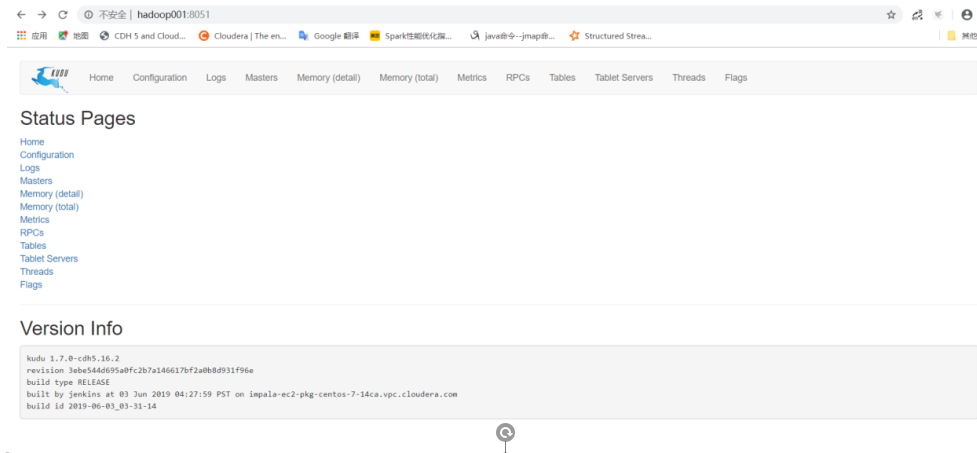
点击Tablets查看相应端口,rpc端口号为7050,知道端口号后,可以进行相应开发
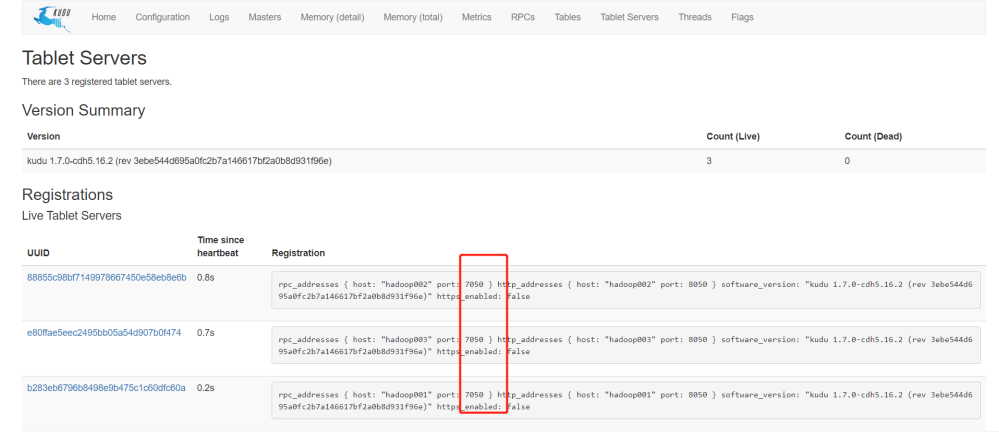
点击Masters查看 可以看出master节点地址和端口号

Spark DF操作Kudu
添加依赖

<dependency> <groupId>org.apache.kudu</groupId> <artifactId>kudu-client</artifactId> <version>1.10.0</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.kudu/kudu-spark2 --> <dependency> <groupId>org.apache.kudu</groupId> <artifactId>kudu-spark2_2.11</artifactId> <version>1.7.0</version> </dependency>
创建kudu表
import java.util import org.apache.kudu.client.CreateTableOptions import org.apache.kudu.spark.kudu._ import org.apache.spark.SparkConf import org.apache.spark.sql.SparkSession import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType} //创建kudu表 object KuduSparkTest1 { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setMaster("local[*]") val spark = SparkSession.builder().config(sparkConf).getOrCreate() val sparkConetxt = spark.sparkContext val kuduContext = new KuduContext("hadoop001,hadoop002,hadoop003", sparkConetxt) val tableFields = (Array(new StructField("id", IntegerType, false), new StructField("name", StringType)))//id为主键 val arrayList = new util.ArrayList[String]() arrayList.add("id") val b = new CreateTableOptions().setNumReplicas(1).addHashPartitions(arrayList, 3) kuduContext.createTable("test_table", StructType(tableFields), Seq("id"), b) } }
将代码打成jar包 使用集群运行 运行完毕后查看UI界面
查询kudu表
import org.apache.spark.SparkConf import org.apache.spark.sql.SparkSession //查询kudu object KuduSparkTest2 { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setMaster("local[*]") val spark = SparkSession.builder().config(sparkConf).getOrCreate() val df = spark.read.options(Map("kudu.master" -> "hadoop001,hadoop002,hadoop003", "kudu.table" -> "test_table")) .format("org.apache.kudu.spark.kudu").load() df.show() } }
查询出来返回值是个dataframe,之后就可以使用dataframe api进行操作
增删改kudu表
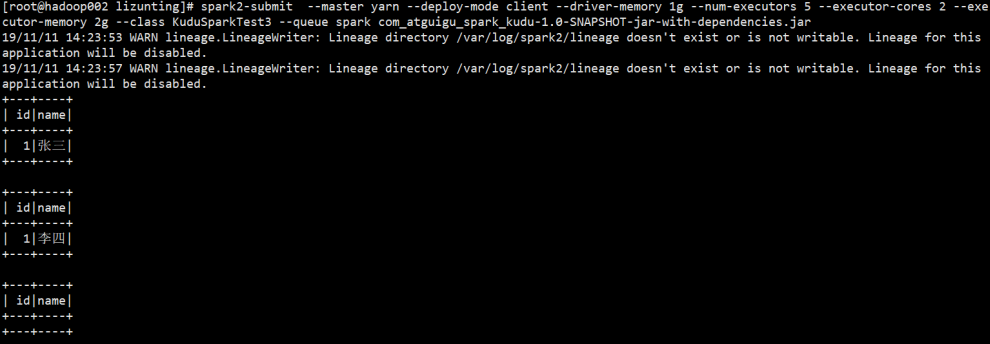
object KuduSparkTest3 { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf() val spark = SparkSession.builder().config(sparkConf).getOrCreate() val sparkContext = spark.sparkContext val kuduContext = new KuduContext("hadoop001,hadoop002,hadoop003", sparkContext) val testTableDF = spark.read.options(Map("kudu.master" -> "hadoop001,hadoop002,hadoop003", "kudu.table" -> "test_table")) .format("org.apache.kudu.spark.kudu").load() val flag = kuduContext.tableExists("test_table") //判断表是否存在 if (flag) { import spark.implicits._ val tuple = (1, "张三") val df = sparkContext.makeRDD(Seq(tuple)).toDF("id","name") kuduContext.insertRows(df, "test_table") //往test_table表中插入 id为1 name为张三的数据 testTableDF.show() val tuple2 = (1, "李四") val df2 = sparkContext.makeRDD(Seq(tuple2)).toDF("id","name") kuduContext.updateRows(df2, "test_table") //将test_table表中主键id为1 的数据name值修改为李四 testTableDF.show() kuduContext.deleteRows(df2, "test_table") //将test_table表中的主键id为1 name值为李四的数据删除 testTableDF.show() } } }
Spark Streaming实时写Kudu
注意:spark创建的kudu表在impala里不会显示,但确实存在,在impala创建外部表指定kudu表即可
pom.xml配置


<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>education-online</artifactId> <groupId>com.atguigu</groupId> <version>1.0-SNAPSHOT</version> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>com_atguigu_spark_kudu</artifactId> <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <scope>provided</scope> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <scope>provided</scope> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <scope>provided</scope> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.apache.kudu</groupId> <artifactId>kudu-client</artifactId> <version>1.10.0</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.29</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.kudu/kudu-spark2 --> <dependency> <groupId>org.apache.kudu</groupId> <artifactId>kudu-spark2_2.11</artifactId> <version>1.7.0</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.16</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-10_2.11</artifactId> <!-- <scope>provided</scope>--> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.11</artifactId> <scope>provided</scope> <version>${spark.version}</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <version>2.15.1</version> <executions> <execution> <id>compile-scala</id> <goals> <goal>add-source</goal> <goal>compile</goal> </goals> </execution> <execution> <id>test-compile-scala</id> <goals> <goal>add-source</goal> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <configuration> <archive> <manifest> </manifest> </archive> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> </plugin> </plugins> </build> </project>
使用impala创建kudu表
[hadoop003:21000] > CREATE TABLE register_table( > id INTEGER, > servicetype STRING, > count BIGINT, > PRIMARY KEY(id) > ) > PARTITION BY HASH PARTITIONS 3 > STORED AS KUDU;
工具类
package util; import java.io.InputStream; import java.util.Properties; /** * * 读取配置文件工具类 */ public class ConfigurationManager { private static Properties prop = new Properties(); static { try { InputStream inputStream = ConfigurationManager.class.getClassLoader() .getResourceAsStream("comerce.properties"); prop.load(inputStream); } catch (Exception e) { e.printStackTrace(); } } //获取配置项 public static String getProperty(String key) { return prop.getProperty(key); } //获取布尔类型的配置项 public static boolean getBoolean(String key) { String value = prop.getProperty(key); try { return Boolean.valueOf(value); } catch (Exception e) { e.printStackTrace(); } return false; } } package util; import com.alibaba.druid.pool.DruidDataSourceFactory; import javax.sql.DataSource; import java.io.Serializable; import java.sql.Connection; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.sql.SQLException; import java.util.Properties; /** * 德鲁伊连接池 */ public class DataSourceUtil implements Serializable { public static DataSource dataSource = null; static { try { Properties props = new Properties(); props.setProperty("url", ConfigurationManager.getProperty("jdbc.url")); props.setProperty("username", ConfigurationManager.getProperty("jdbc.user")); props.setProperty("password", ConfigurationManager.getProperty("jdbc.password")); props.setProperty("initialSize", "5"); //初始化大小 props.setProperty("maxActive", "10"); //最大连接 props.setProperty("minIdle", "5"); //最小连接 props.setProperty("maxWait", "60000"); //等待时长 props.setProperty("timeBetweenEvictionRunsMillis", "2000");//配置多久进行一次检测,检测需要关闭的连接 单位毫秒 props.setProperty("minEvictableIdleTimeMillis", "600000");//配置连接在连接池中最小生存时间 单位毫秒 props.setProperty("maxEvictableIdleTimeMillis", "900000"); //配置连接在连接池中最大生存时间 单位毫秒 props.setProperty("validationQuery", "select 1"); props.setProperty("testWhileIdle", "true"); props.setProperty("testOnBorrow", "false"); props.setProperty("testOnReturn", "false"); props.setProperty("keepAlive", "true"); props.setProperty("phyMaxUseCount", "100000"); // props.setProperty("driverClassName", "com.mysql.jdbc.Driver"); dataSource = DruidDataSourceFactory.createDataSource(props); } catch (Exception e) { e.printStackTrace(); } } //提供获取连接的方法 public static Connection getConnection() throws SQLException { return dataSource.getConnection(); } // 提供关闭资源的方法【connection是归还到连接池】 // 提供关闭资源的方法 【方法重载】3 dql public static void closeResource(ResultSet resultSet, PreparedStatement preparedStatement, Connection connection) { // 关闭结果集 // ctrl+alt+m 将java语句抽取成方法 closeResultSet(resultSet); // 关闭语句执行者 closePrepareStatement(preparedStatement); // 关闭连接 closeConnection(connection); } private static void closeConnection(Connection connection) { if (connection != null) { try { connection.close(); } catch (SQLException e) { e.printStackTrace(); } } } private static void closePrepareStatement(PreparedStatement preparedStatement) { if (preparedStatement != null) { try { preparedStatement.close(); } catch (SQLException e) { e.printStackTrace(); } } } private static void closeResultSet(ResultSet resultSet) { if (resultSet != null) { try { resultSet.close(); } catch (SQLException e) { e.printStackTrace(); } } } } package util import java.sql.{Connection, PreparedStatement, ResultSet} trait QueryCallback { def process(rs: ResultSet) } class SqlProxy { private var rs: ResultSet = _ private var psmt: PreparedStatement = _ /** * 执行修改语句 * * @param conn * @param sql * @param params * @return */ def executeUpdate(conn: Connection, sql: String, params: Array[Any]): Int = { var rtn = 0 try { psmt = conn.prepareStatement(sql) if (params != null && params.length > 0) { for (i <- 0 until params.length) { psmt.setObject(i + 1, params(i)) } } rtn = psmt.executeUpdate() } catch { case e: Exception => e.printStackTrace() } rtn } /** * 执行查询语句 * 执行查询语句 * [hadoop003:21000] > CREATE TABLE register_table( > id INTEGER, > servicetype STRING, > count BIGINT, > PRIMARY KEY(id) > ) > PARTITION BY HASH PARTITIONS 3 > STORED AS KUDU; * @param conn * @param sql * @param params * @return */ def executeQuery(conn: Connection, sql: String, params: Array[Any], queryCallback: QueryCallback) = { rs = null try { psmt = conn.prepareStatement(sql) if (params != null && params.length > 0) { for (i <- 0 until params.length) { psmt.setObject(i + 1, params(i)) } } rs = psmt.executeQuery() queryCallback.process(rs) } catch { case e: Exception => e.printStackTrace() } } def shutdown(conn: Connection): Unit = DataSourceUtil.closeResource(rs, psmt, conn) }
Spark Streaming写Kudu
import java.sql.ResultSet import java.{lang, util} import _root_.util.{DataSourceUtil, QueryCallback, SqlProxy} import org.apache.kafka.clients.consumer.ConsumerRecord import org.apache.kafka.common.TopicPartition import org.apache.kafka.common.serialization.StringDeserializer import org.apache.kudu.client.KuduPredicate.ComparisonOp import org.apache.kudu.client.{KuduClient, KuduPredicate} import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.InputDStream import org.apache.spark.streaming.kafka010._ import org.apache.spark.streaming.{Seconds, StreamingContext} import scala.collection.mutable object KuduSparkTest4 { private val groupid = "register_group_test" private val KUDU_MASTERS = "hadoop001,hadoop002,hadoop003" def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName(this.getClass.getSimpleName) .set("spark.streaming.kafka.maxRatePerPartition", "100") .set("spark.streaming.stopGracefullyOnShutdown", "true") .set("spark.streaming.backpressure.enabled", "true") val ssc = new StreamingContext(conf, Seconds(3)) val sparkContext = ssc.sparkContext val topics = Array("register_topic") val kafkaMap: Map[String, Object] = Map[String, Object]( "bootstrap.servers" -> "hadoop001:9092,hadoop002:9092,hadoop003:9092", "key.deserializer" -> classOf[StringDeserializer], "value.deserializer" -> classOf[StringDeserializer], "group.id" -> groupid, "auto.offset.reset" -> "earliest", "enable.auto.commit" -> (false: lang.Boolean) ) sparkContext.hadoopConfiguration.set("fs.defaultFS", "hdfs://nameservice1") //设置高可用地址 sparkContext.hadoopConfiguration.set("dfs.nameservices", "nameservice1") //设置高可用地址 val sqlProxy = new SqlProxy val offsetMap = new mutable.HashMap[TopicPartition, Long]() val client = DataSourceUtil.getConnection try { sqlProxy.executeQuery(client, "select * from `offset_manager` where groupid=?", Array(groupid), new QueryCallback { override def process(rs: ResultSet): Unit = { while (rs.next()) { val model = new TopicPartition(rs.getString(2), rs.getInt(3)) val offset = rs.getLong(4) offsetMap.put(model, offset) } rs.close() //关闭游标 } }) } catch { case e: Exception => e.printStackTrace() } finally { sqlProxy.shutdown(client) } //设置kafka消费数据的参数 判断本地是否有偏移量 有则根据偏移量继续消费 无则重新消费 val stream: InputDStream[ConsumerRecord[String, String]] = if (offsetMap.isEmpty) { KafkaUtils.createDirectStream( ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](topics, kafkaMap)) } else { KafkaUtils.createDirectStream( ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](topics, kafkaMap, offsetMap)) } val resultDStream = stream.mapPartitions(partitions => { partitions.map(item => { val line = item.value() val arr = line.split("\t") val id = arr(1) val app_name = id match { case "1" => "PC_1" case "2" => "APP_2" case _ => "Other_3" } (app_name, 1) }) }).reduceByKey(_ + _) resultDStream.foreachRDD(rdd => { rdd.foreachPartition(parititon => { val kuduClient = new KuduClient.KuduClientBuilder(KUDU_MASTERS).build //获取kudu连接 val kuduTable = kuduClient.openTable("impala::default.register_table") //获取kudu table val schema = kuduTable.getSchema //根据当前表register_table 将相应需要查询的列放到arraylist中 表中有id servicetype count字段 val projectColumns = new util.ArrayList[String]() projectColumns.add("id") projectColumns.add("servicetype") projectColumns.add("count") parititon.foreach(item => { var resultCount: Long = item._2 //声明结果值 默认为当前批次数据 val appname = item._1.split("_")(0) val id = item._1.split("_")(1).toInt val eqPred = KuduPredicate.newComparisonPredicate(schema.getColumn("servicetype"), ComparisonOp.EQUAL, appname); //先根据设备名称过滤 过滤条件为等于app_name的数据 val kuduScanner = kuduClient.newScannerBuilder(kuduTable).addPredicate(eqPred).build() while (kuduScanner.hasMoreRows) { val results = kuduScanner.nextRows() while (results.hasNext) { val result = results.next() //符合条件的数据有值则 和当前批次数据进行累加 val count = result.getLong("count") //获取表中count值 resultCount += count } } //最后将结果数据重新刷新到kudu val kuduSession = kuduClient.newSession() val upset = kuduTable.newUpsert() //调用upset 当主键存在数据进行修改操作 不存在则新增 val row = upset.getRow row.addInt("id", id) row.addString("servicetype", appname) row.addLong("count", resultCount) kuduSession.apply(upset) kuduSession.close() }) kuduClient.close() }) }) stream.foreachRDD(rdd => { val sqlProxy = new SqlProxy() val client = DataSourceUtil.getConnection try { val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges for (or <- offsetRanges) { sqlProxy.executeUpdate(client, "replace into `offset_manager` (groupid,topic,`partition`,untilOffset) values(?,?,?,?)", Array(groupid, or.topic, or.partition.toString, or.untilOffset)) } } catch { case e: Exception => e.printStackTrace() } finally { sqlProxy.shutdown(client) } }) ssc.start() ssc.awaitTermination() } }
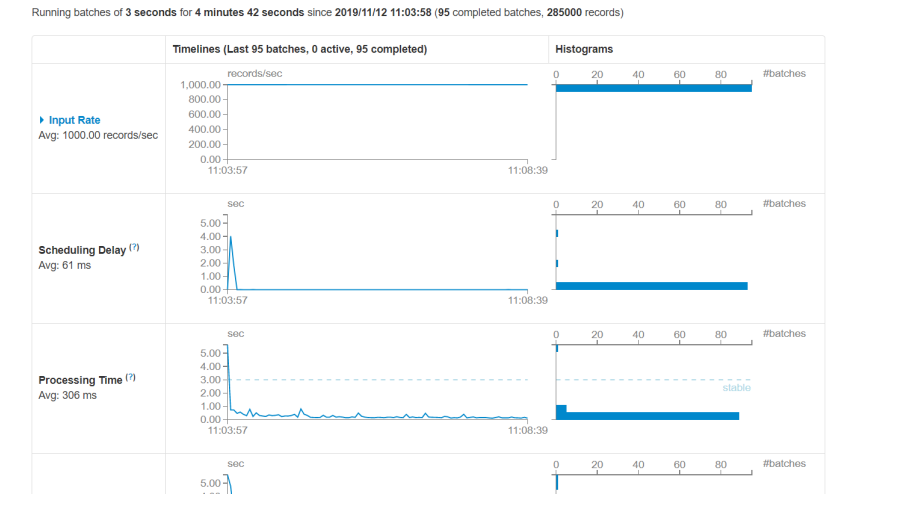
效果展示
业务为根据设备实时统计count数需要基于历史数据,控制速度每秒1000条
Kudu参考网址
https://kudu.apache.org/docs/developing.html#view_api



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2019-04-14 Spark |05 SparkStreaming
2018-04-14 第六章|网络编程-socket开发