
DorisDB | 原理剖析和应用实践篇
1. 数据驱动
数据驱动的新趋势
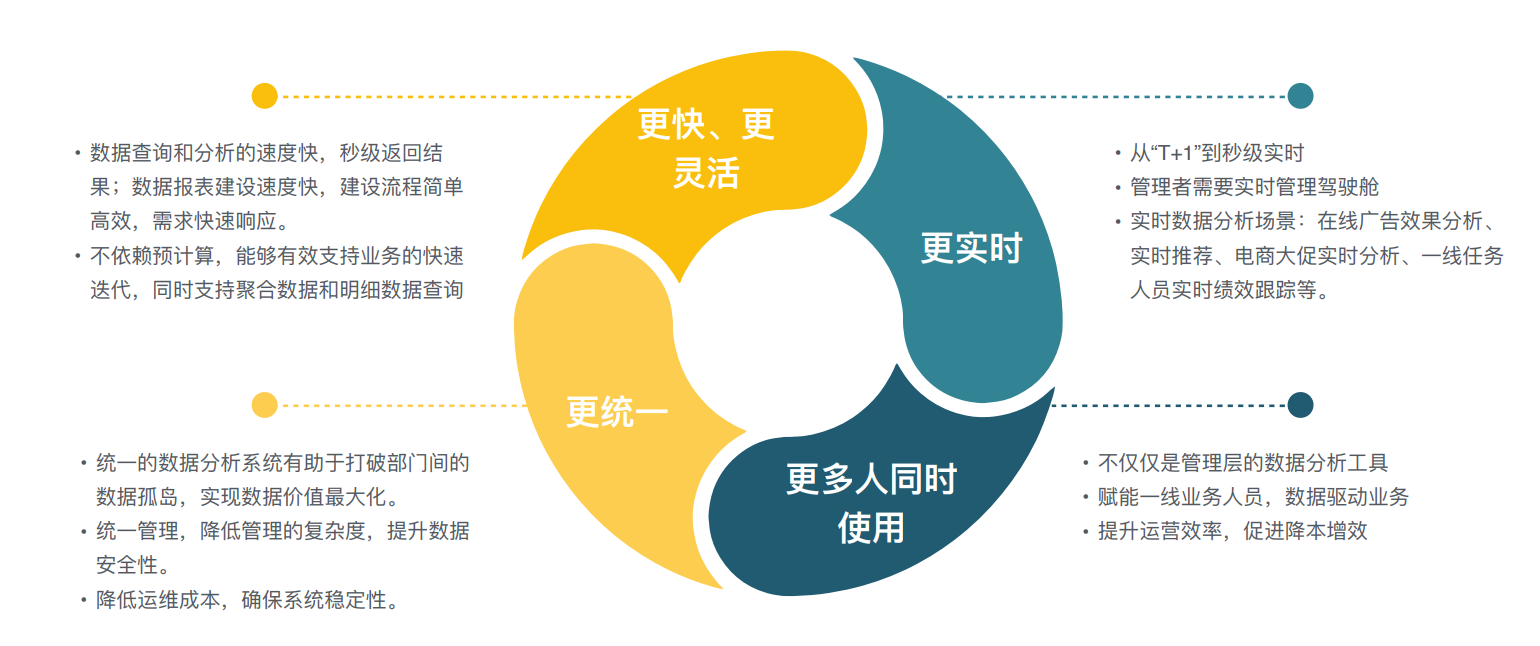
对速度和性能要求越来越高: 查询(亚秒级别返回),快速开发,
传统的方式进行预计算kylin、clickhouse, 星型模型--宽表模型--预聚合--(聚合度越高就会丧失一些灵活性,业务变更、维度变化就要重新刷新数据)
星型和雪花模型的多表关联, 高效的即席查询,预计算;
kylin+hbase做预处理
实时分析druid-聚合模型(对宽表支持度不高)
宽表选用clickhouse(对更新不友好)
Impala+kudu实现更新+多表关联
ES 全文检索、倒排索引;
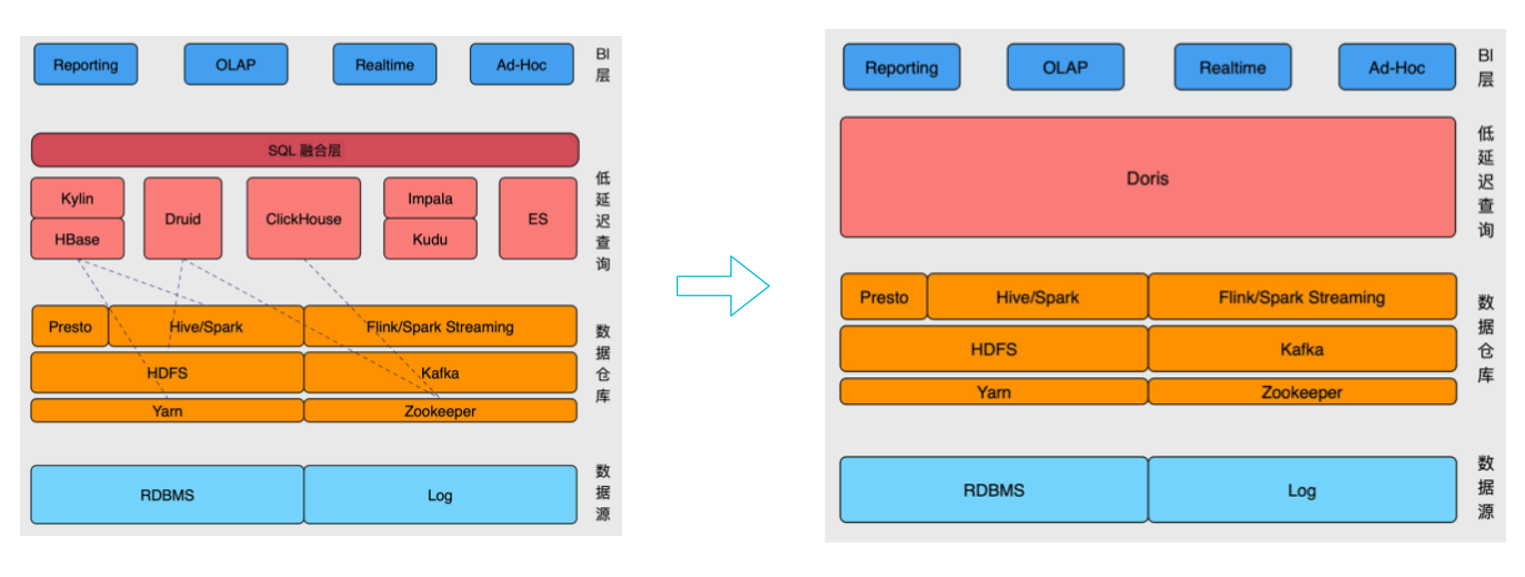
Doris解决不同系统之间的差异;
支持Mysql、ES、Hive的外表;
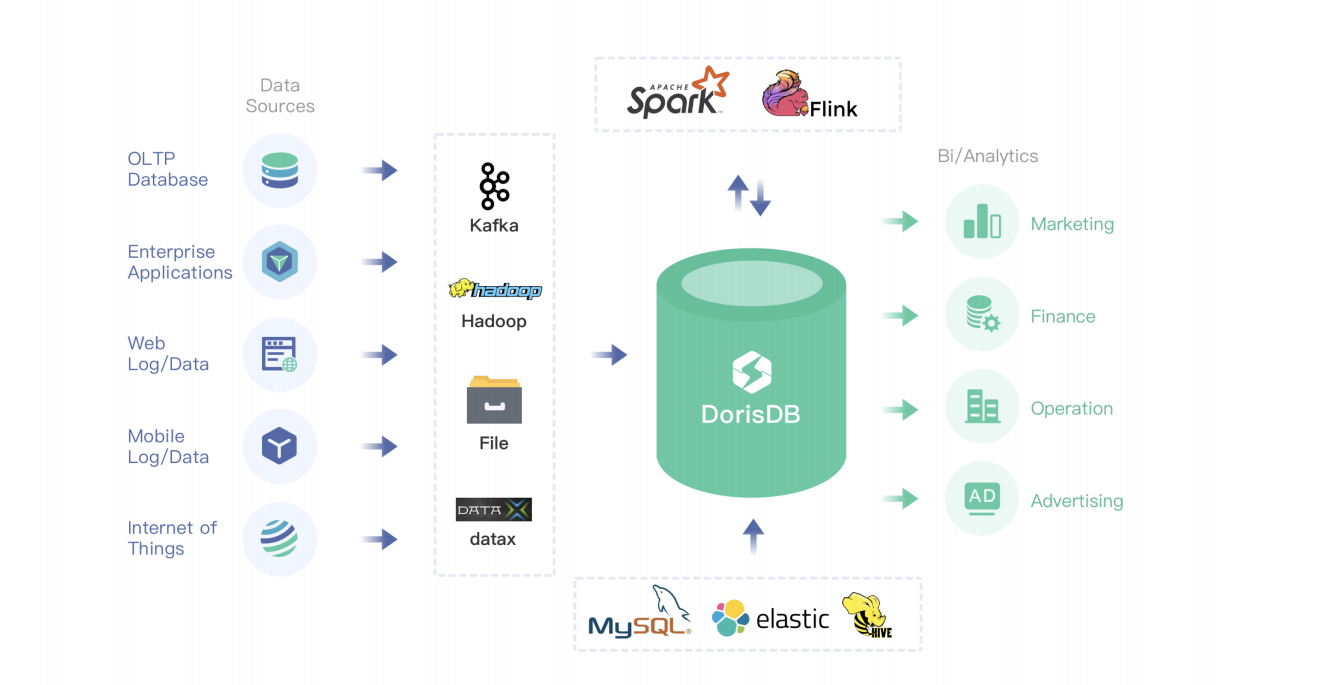
Doris数据源: kafka、hdfs、file、datax-mysql等数据库;
spark、flink对doris数据的读写;
支持外部表: 小的维度表更新可以放mysql,更新、倒排索引可以放ES(聚合|关联不太友好),创建hive的外部表等
2. 整体架构 - MPP架构
弹性MPP架构-极简架构
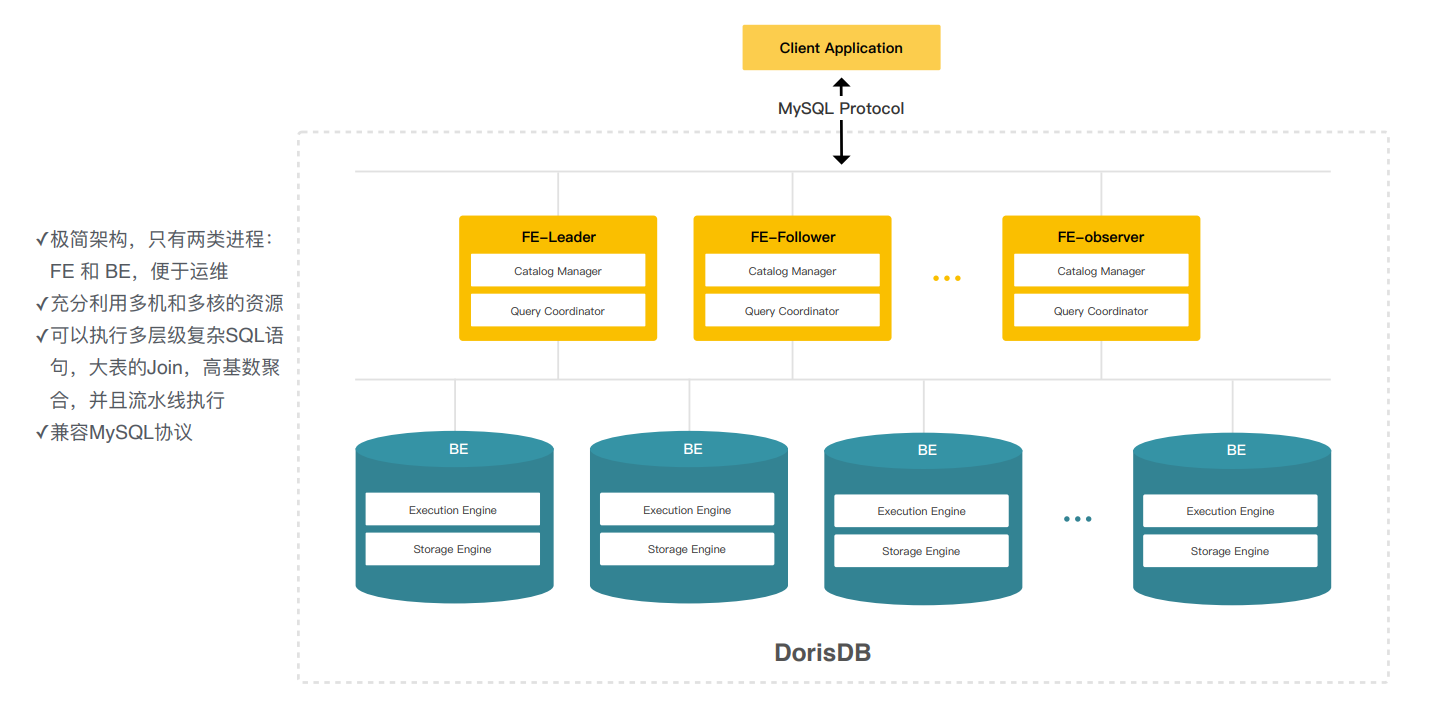
FE前端节点, 主要负责元数据的管理,查询的规划调度,解析sql对应的执行计划下发给BE
BE数据的存储和执行的引擎,这里存储和计算还是在一起的;
FE分为Leader、 Follower、 Observer
Follower, 参与选主,一个Follower宕机会自动选主, 保证服务的高可用; 可水平扩展, 线性增加只读的observe节点 以应对高并发的查询
对外提供mysql兼容协议,像navicat等工具都可以直接连接,客户的迁移成本比较小;
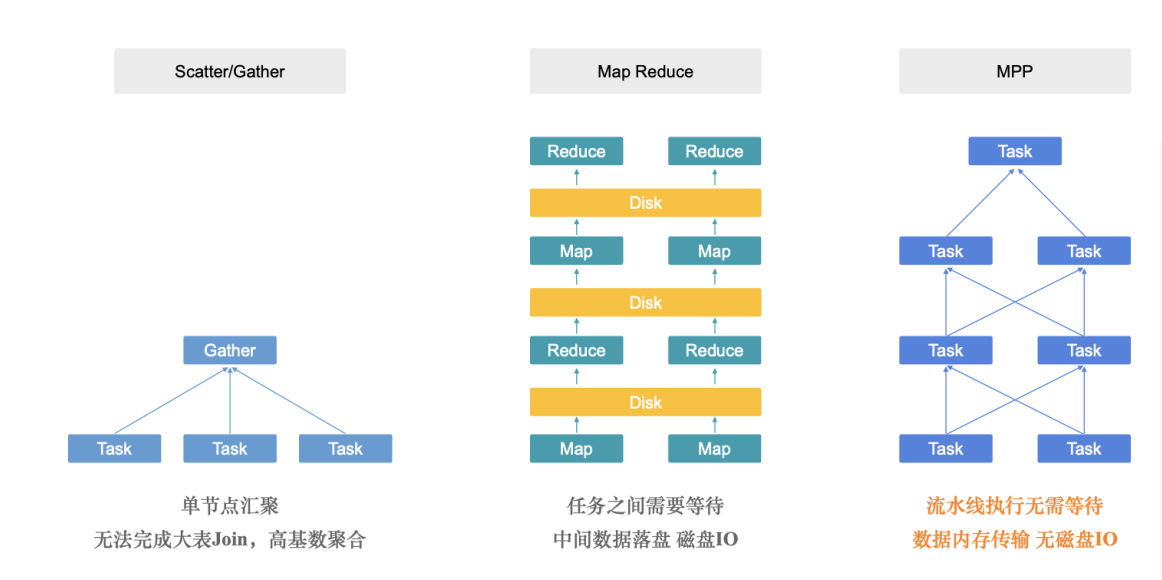
跟传统架构的区别:
通过分布式拆分成不同的task在每个节点运行,再在中心节点汇聚;
druid、clickhouse都是类型架构;
离线计算MR是任务的拆分、落盘,会有一定的等待磁盘IO,合适跑特别大的任务;
doris是MPP架构,任务之间分成task、全都在内存中执行和传输,所有任务都是流水线,没有磁盘IO,适用于低延迟亚秒级查询;
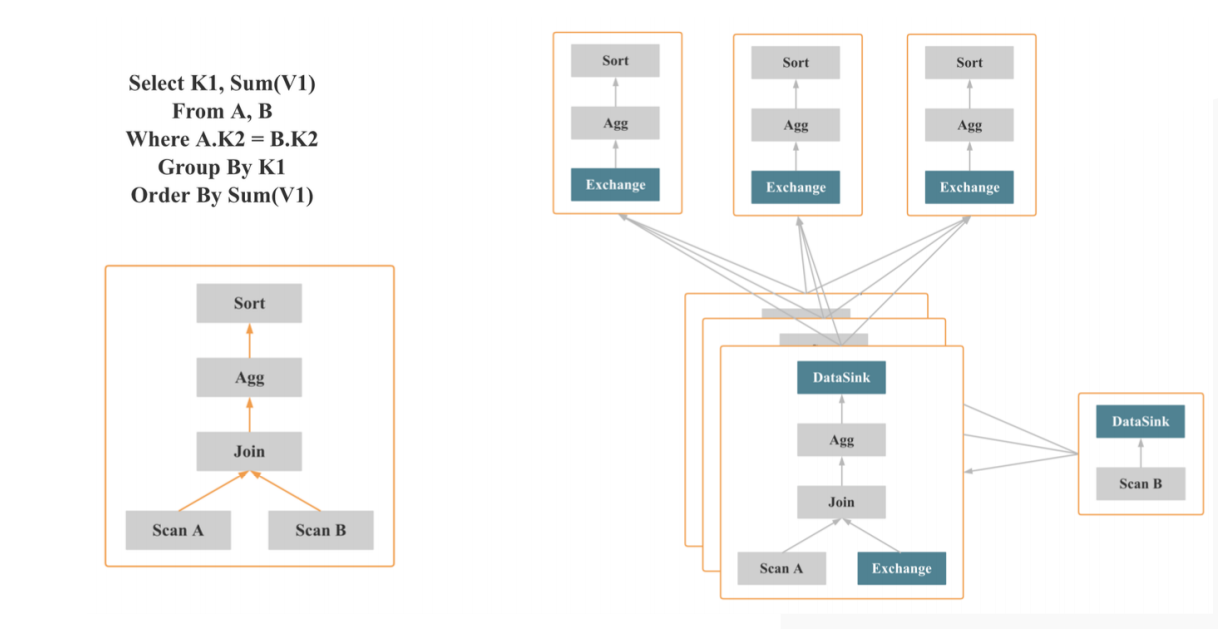
sql查询进入doris的过程:
MPP架构的使用逻辑
将上边的sql解析成逻辑执行计划-
A|B两个表的scan -> Join ->聚合(group by K1 sum(V1) )聚合操作 -> 最后再sort by sum(V1)排序 ;
MPP架构就是可以把逻辑执行计划转换成物理层面的,
假设有3个节点,会把执行计划分成类似fregment (有节点的组合); scanB扫描B表的数据,通过一个brokercast、dataSink和exchange这样的节点会把fregment串联起来,每个fregment中会有不同的计算节点;
比如数据经过广播跟A表join,之后进行聚合操作;
在doris中一个MPP就是支持两层的数据聚合,像在Scatter/Gather中每个节点做完聚合操作后最后汇总到一个节点再做一次;
在doris中支持在中间做一次数据的shuffle,shuffle完成之后在上层再做一次聚合,这样子就不会有大单点的计算瓶颈。再推给上层去做排序。
根据不同的机器每个fregment会拆成instent它执行的子单元,就可以充分发挥MPP的多基多合的能力,根据机器数量和设置的并行度,充分利用资源。
智能CBO查询优化器
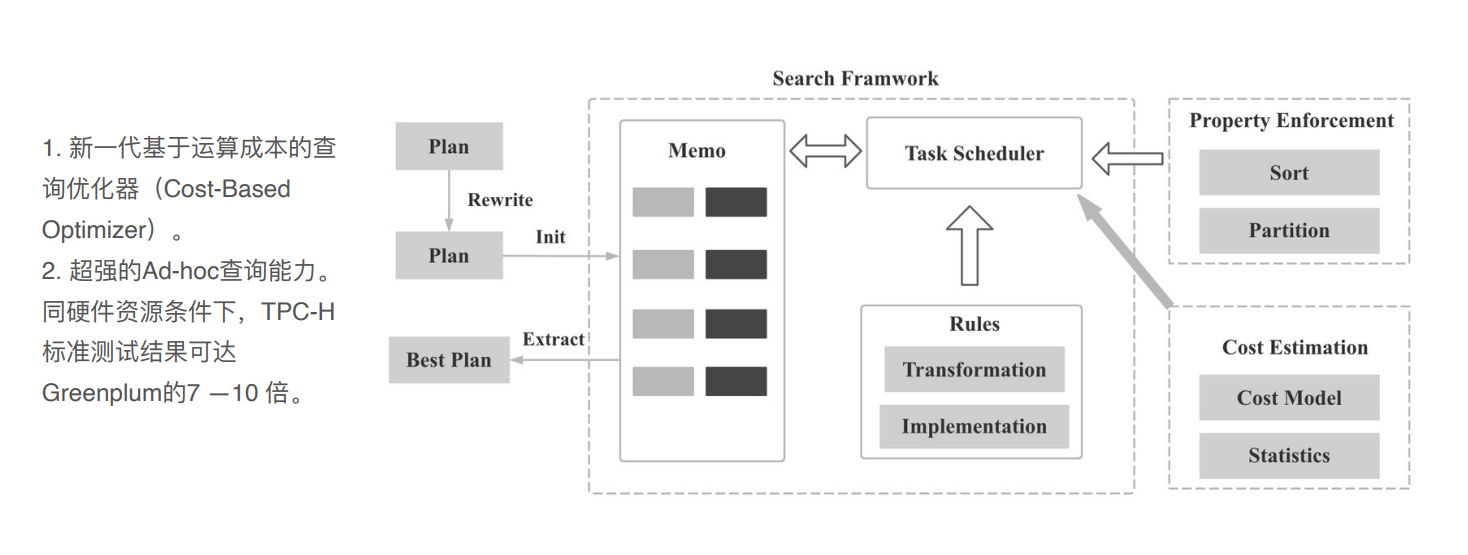
dorisDB跟开源的apache doris有几个改造点:
在FE这边的改造:
plan会根据cpu的成本预估,加入更多的统计信息(列的基数、直方图等等),能够更准确的预估表的执行计划。
两个表join时,使用brokercast join还是shuffle join还是其他join的一些方式,左右表过滤出来应该有多少行数等,哪个表作为左右表等位置关系;聚合函数用1层还是2层等等 会有更好的执行调度
在全新的plan下,对复杂的查询可以提高7-10倍的性能优势;
极速向量化引擎
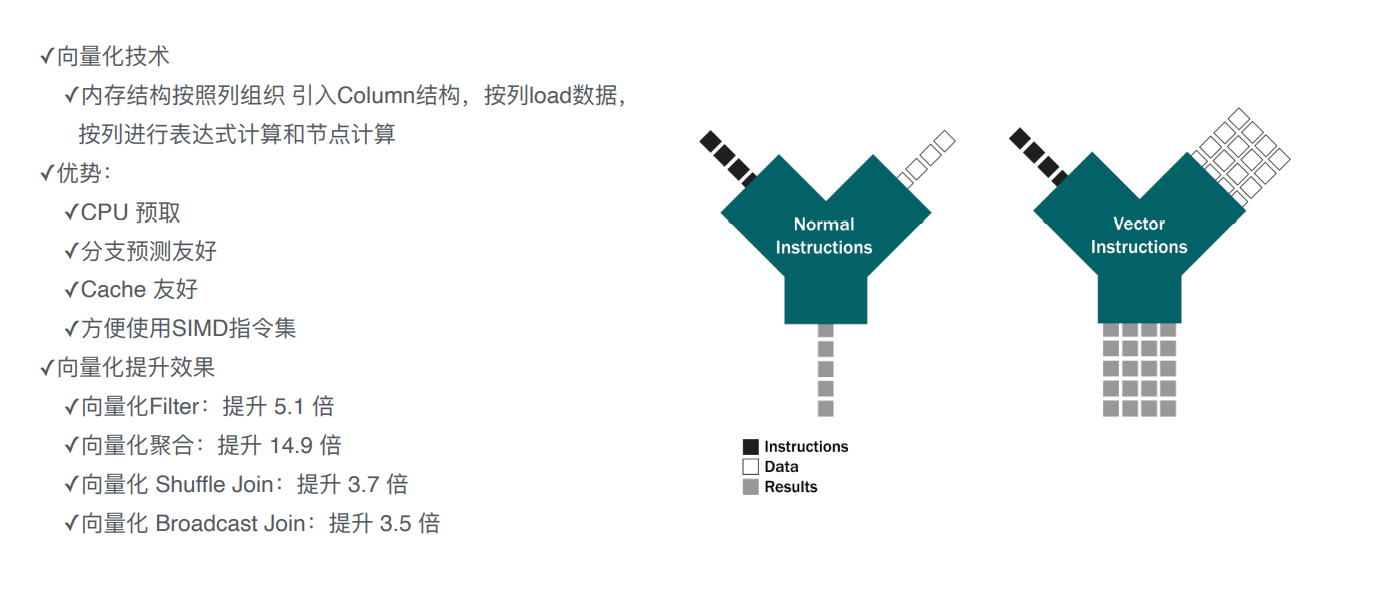
对BE的改造点:
计算+存储层,
计算层: 在简单化查询上的性能提升,主要是向量化引擎,即把内存结构按照列的方式进行组织;
跟之前按行来处理不一样的地方是 可以充分利用全新的cpu指令(单指令、多数据流),一条指令可以处理很多的数据。
高效的列式存储

列式存储:
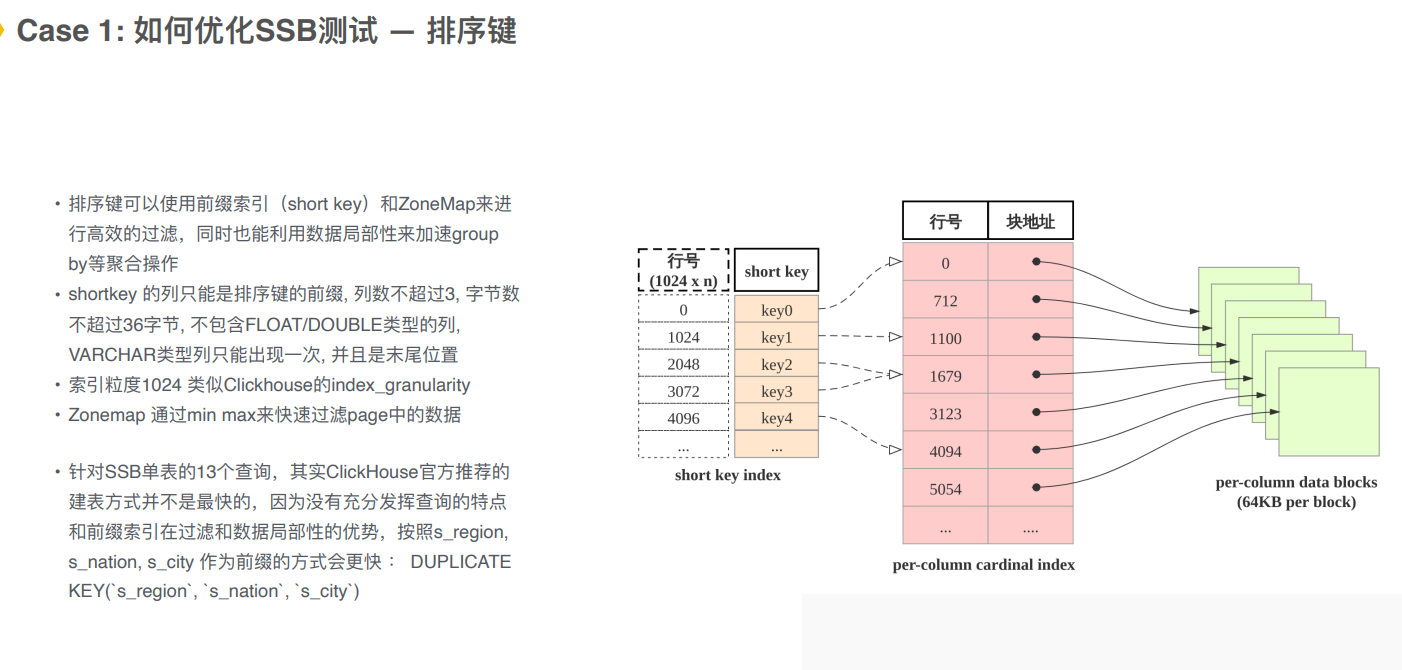
- 支持排序,选择排序键,对数据进行排序二分查找,前缀索引快速找到对应数据。
- 支持二级索引:bitmap、 bloom filter等来构建二级索引;
- 延时物化通过读取时对数据裁剪,过滤条件应用在引擎中降低数据的读取量;
- 编码加速,对数据的估计做一些自适应编码,转化成字典编码,对列读取的性能提升;
- 算子智能下推会把复杂查询推到存储层, 向量化指令做过滤等。
现代化物化视图加速
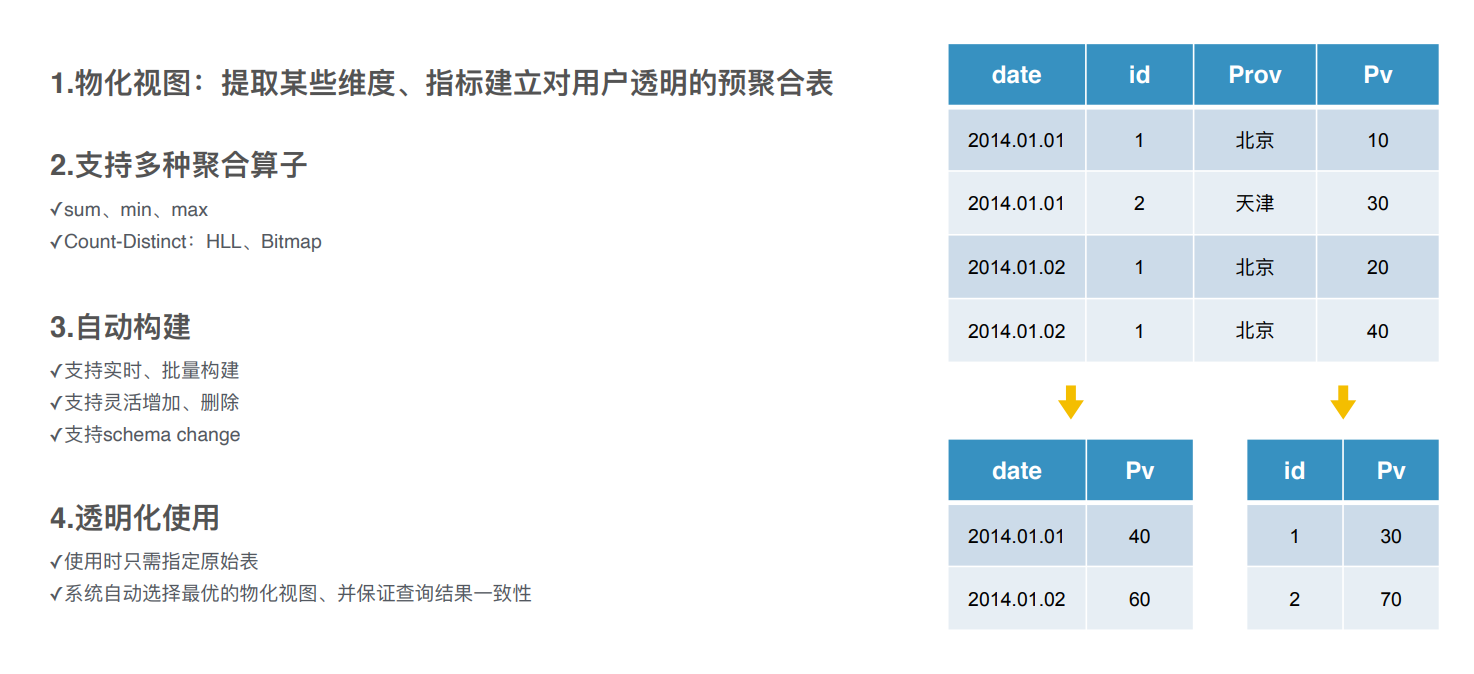
不同场景下预处理 :
kylin的cube,doris中的物化视图;
图中要计算每个日期和id的pv个数,可以创建物化视图, 预习计算好每个date的pv个数,每个id的pv个数,再进行查询时进可以直接从物化视图中查询;
doris的物化视图跟clickhouse的区别 :
clickhouse中是直接去查询它的物化视图那张表,
doris中是透明的物化视图, 会有一个智能路由,查询的时候还是查询原表它会路由到效果最好的一张物化视图中。
自动化构建 - 离线异步构建物化视图;新增的实时更新到物化视图中;
实时构建DWS数据
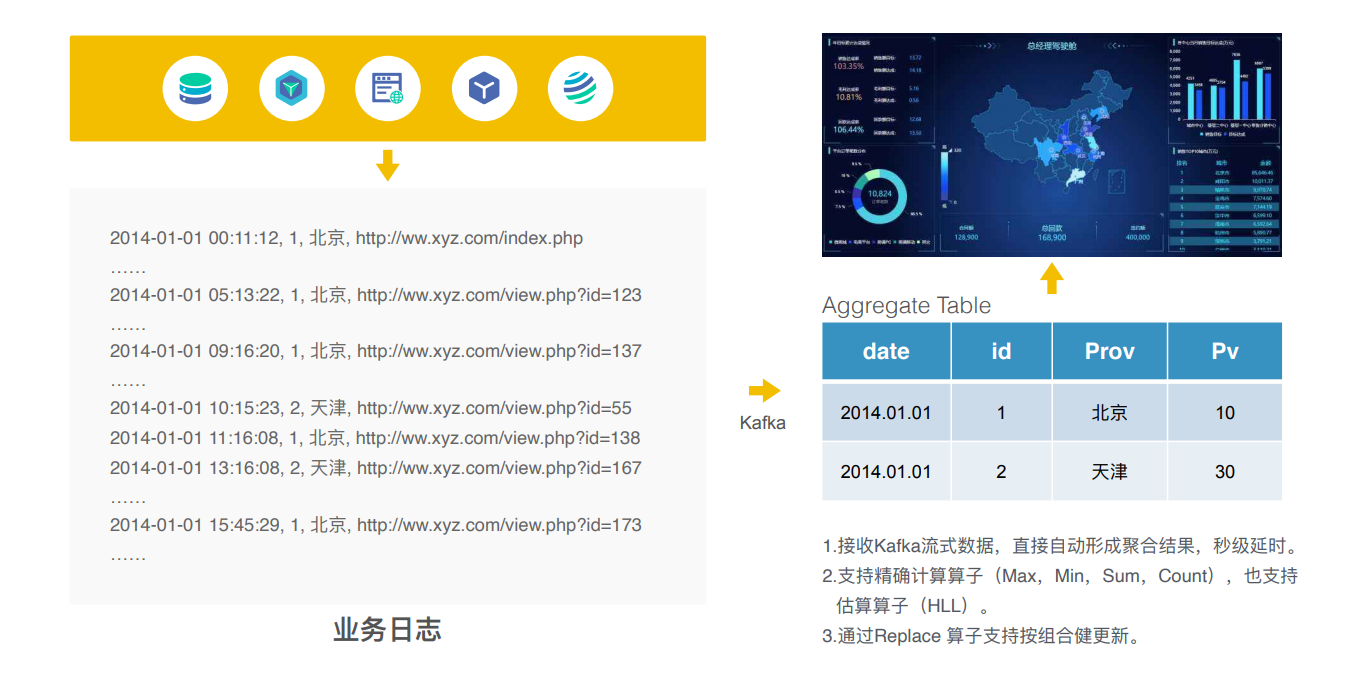
实时数据分析报表的场景:
flume-kafka-doris(进行实时数据的聚合)-BI工具的展示
Join优化 — colocated Join
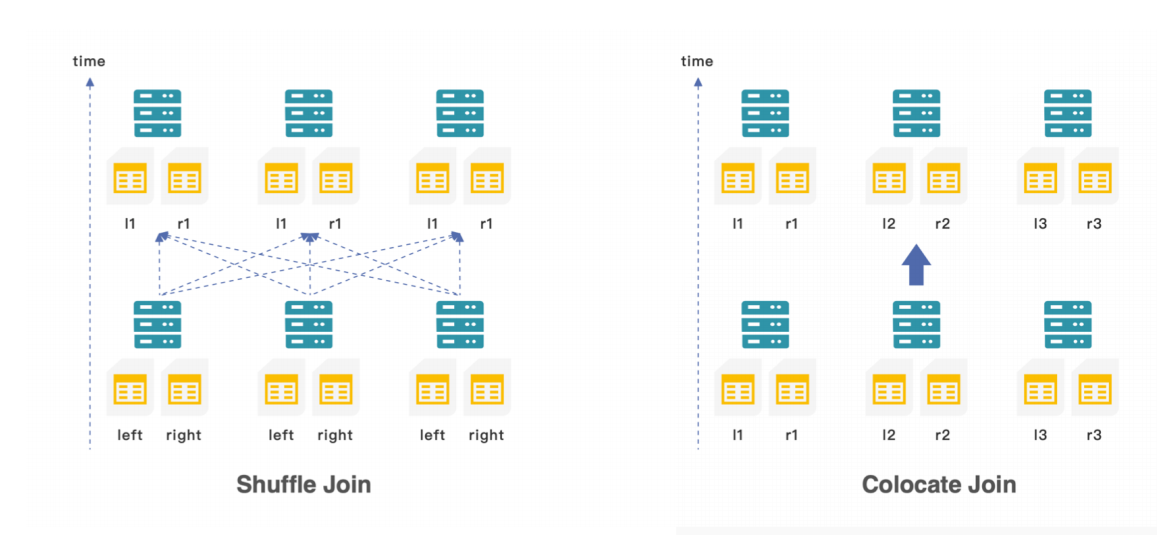
doris多表关联有一个明显的优势 :
原来的建模倾向于宽表,一旦维度的变更就会导致数据的重新刷新,灵活性降低。
doris现场关联,秒级查询返回;
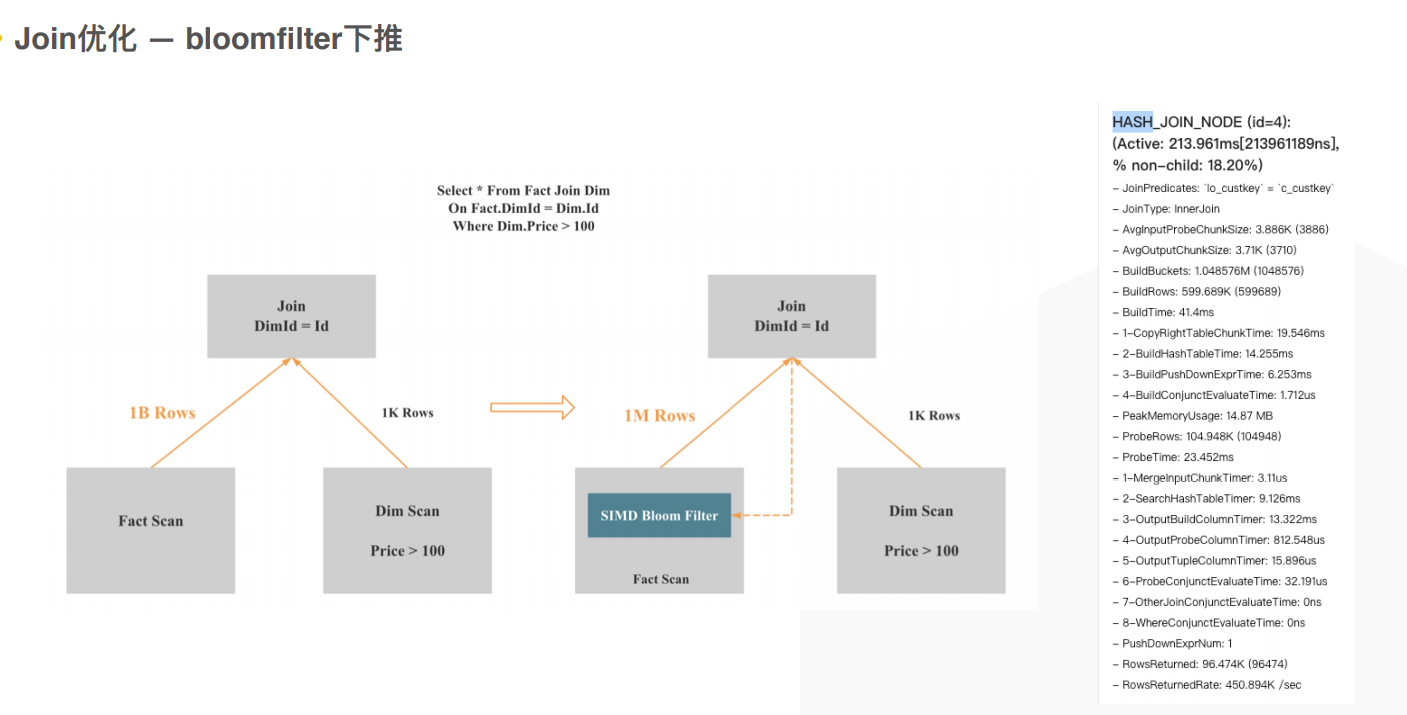
除了高效的shuffle join外还会有一个colocate join 降低特别大的两个表关联时的数据传输量。
shuffle join左右表会根据shuffle key回写重新排布后再进行关联,会消耗很多网络带宽和时间;
colocate join 在建表时就指定数据的分布方式,相同的数据可以哈希到一个桶中,所有的数据都可以在本地进行关联操作,最后再在上层做一次数据的聚合,就可以完成高效的数据管理。
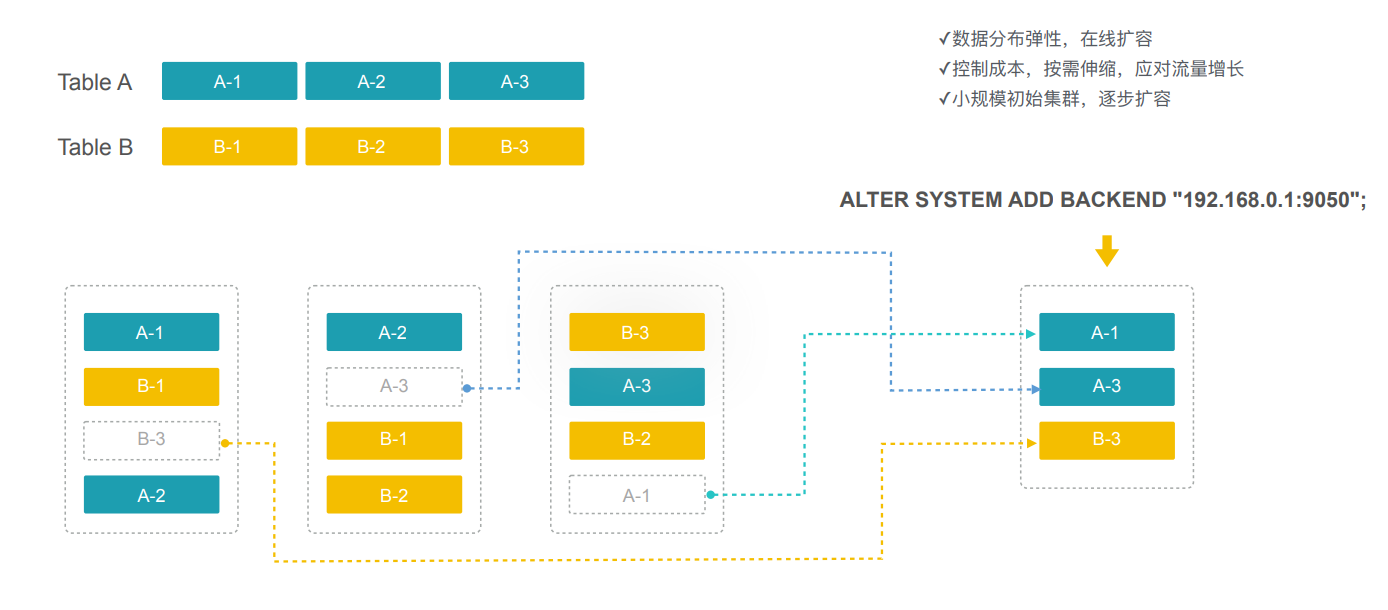
极简运维,弹性伸缩
3. 性能测试

------------------------doris建表-------------------
CREATE TABLE `lineorder_flat` (
`lo_orderdate` date NOT NULL COMMENT "",
`lo_orderkey` int(11) NOT NULL COMMENT "",
`lo_linenumber` tinyint(4) NOT NULL COMMENT "",
`lo_custkey` int(11) NOT NULL COMMENT "",
…
`p_color` varchar(100) NOT NULL COMMENT "",
`p_type` varchar(100) NOT NULL COMMENT "",
`p_size` tinyint(4) NOT NULL COMMENT "",
`p_container` varchar(100) NOT NULL COMMENT ""
) ENGINE=OLAP
DUPLICATE KEY(`lo_orderdate`, `lo_orderkey`)
COMMENT "OLAP"
PARTITION BY RANGE(`lo_orderdate`)
(PARTITION p1 VALUES [('0000-01-01'), ('1993-01-01')),
PARTITION p2 VALUES [('1993-01-01'), ('1994-01-01')),
PARTITION p3 VALUES [('1994-01-01'), ('1995-01-01')),
PARTITION p4 VALUES [('1995-01-01'), ('1996-01-01')),
PARTITION p5 VALUES [('1996-01-01'), ('1997-01-01')),
PARTITION p6 VALUES [('1997-01-01'), ('1998-01-01')),
PARTITION p7 VALUES [('1998-01-01'), ('1999-01-01')))
DISTRIBUTED BY HASH(`lo_orderkey`) BUCKETS 48
PROPERTIES (
"replication_num" = "1",
"in_memory" = "false",
"storage_format" = "DEFAULT"
);
------------------------clickhouse建表------------
CREATE TABLE ssb_100g.lineorder_flat(
`lo_orderkey` UInt32,
`lo_linenumber` UInt8,
`lo_custkey` UInt32,
`lo_partkey` UInt32,
`lo_suppkey` UInt32,
`lo_orderdate` Date,
…
`p_color` LowCardinality(String),
`p_type` LowCardinality(String),
`p_size` UInt8,
`p_container` LowCardinality(String)
)
ENGINE = Distributed('ssb_test', 'ssb_100g', 'lineorder_flat_local', lo_orderkey)
CREATE TABLE ssb_100g.lineorder_flat_local
(
`lo_orderkey` UInt32,
`lo_linenumber` UInt8,
`lo_custkey` UInt32,
…
)
ENGINE = MergeTree
PARTITION BY toYear(lo_orderdate)
ORDER BY (lo_orderdate, lo_orderkey)
SETTINGS index_granularity = 8192 │
doris语法更接近mysql;
可以设置dor.. key
doris中的三种存储模型:
- 明细模型 - 跟clickhouse中的mergetree类似
- 聚合模型 - 适用于实时聚合
- 更新模型 - 对主键的覆盖等
选择拍序列
分区分桶的设置
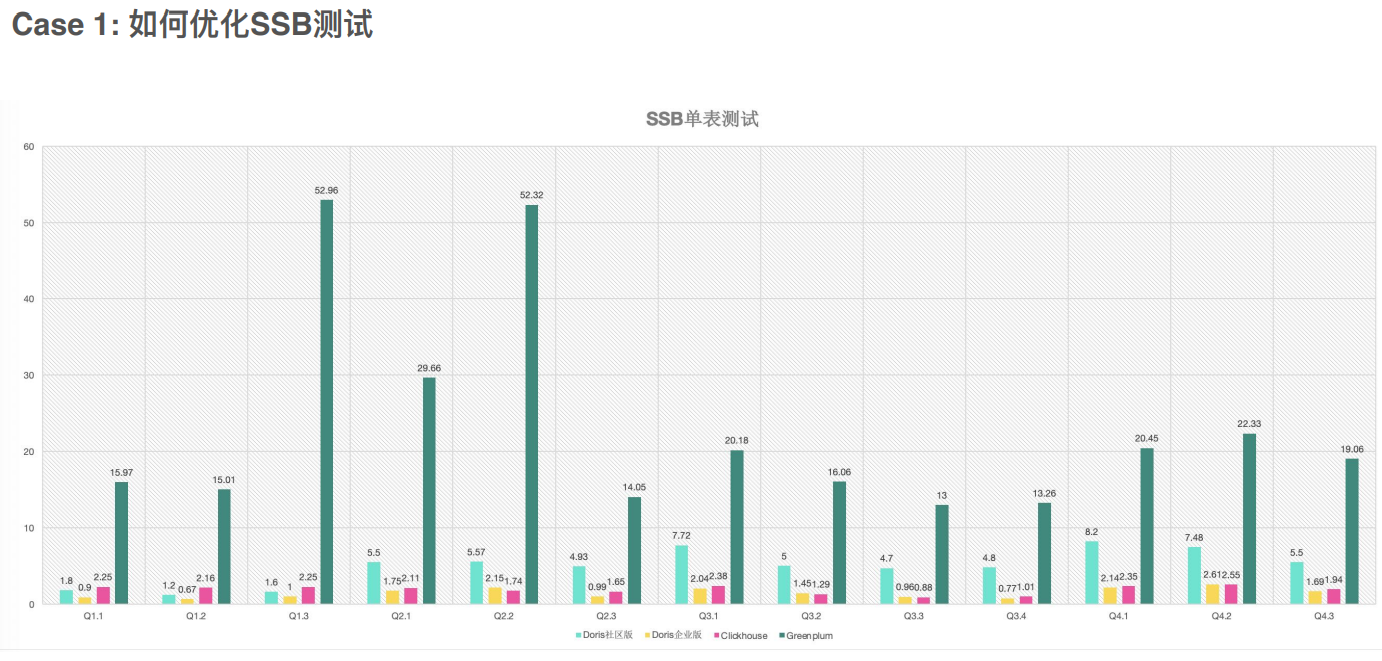
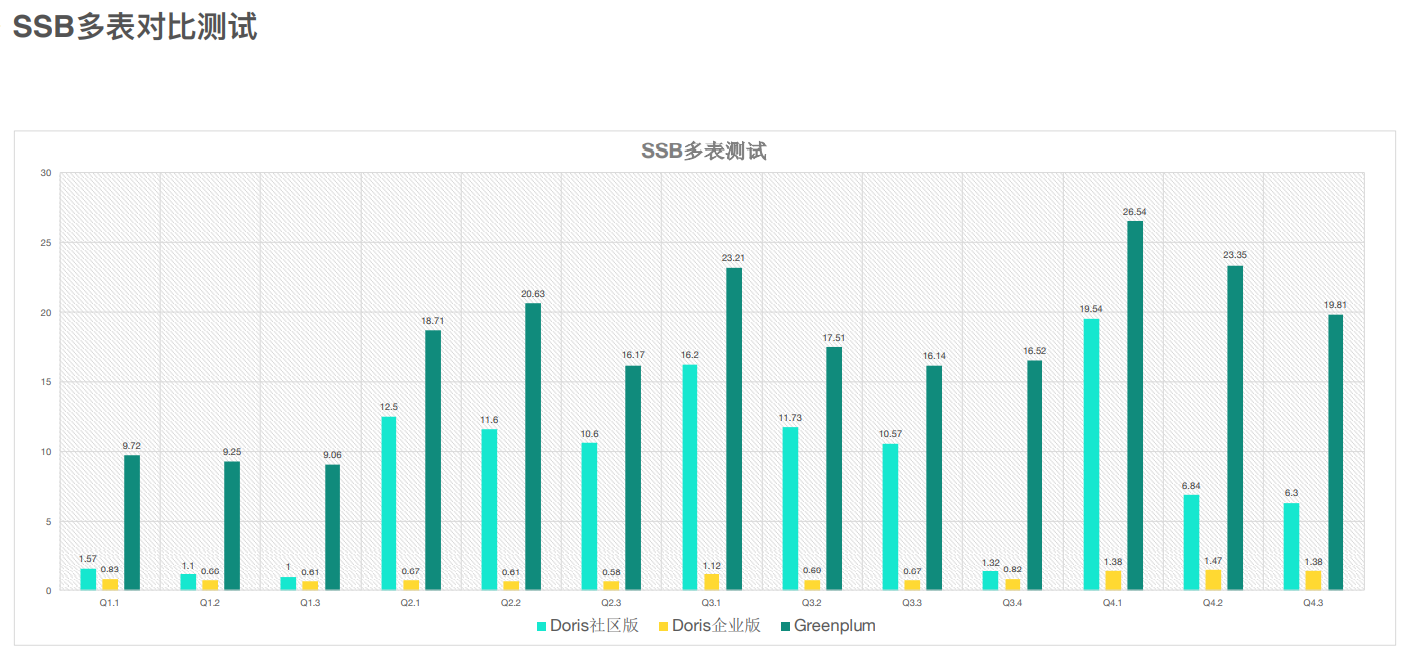
如何优化SSB测试 — 建表最佳实践
ClickHouse建表
- LowCardinality 针对低基数字符串的优化⼿段
- PARTITION BY toYear(lo_orderdate)
- ORDER BY (lo_orderdate, lo_orderkey)
- ENGINE = Distributed('ssb_test', 'ssb_100g', 'lineorder_flat_local', lo_orderkey)
DorisDB建表
- ⾃适应低基数优化不需要显示指定
- PARTITION BY RANGE(`lo_orderdate`)
- DUPLICATE KEY(`lo_orderdate`, `lo_orderkey`)
- DISTRIBUTED BY HASH(`lo_orderkey`) BUCKETS 48
DorisDB的分区分桶
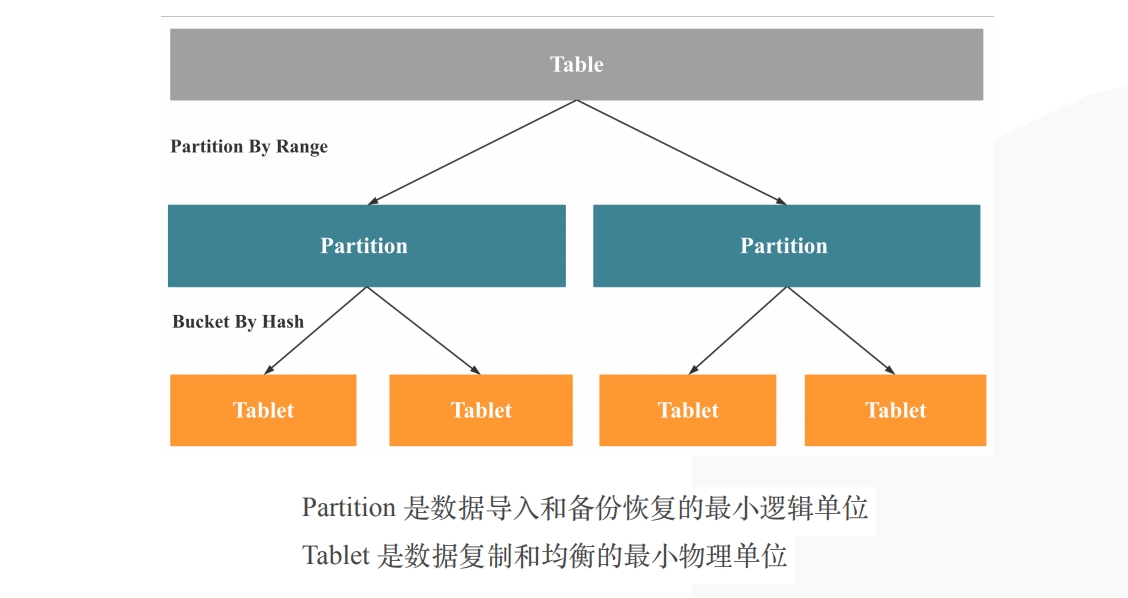
按range分区partition
每个partition中按key进行hash,分散到不同的tablet
partition是数据导入和备份恢复的最小逻辑单位;tablet是数据复制和均衡的最小物理单位;
分区分桶与裁剪
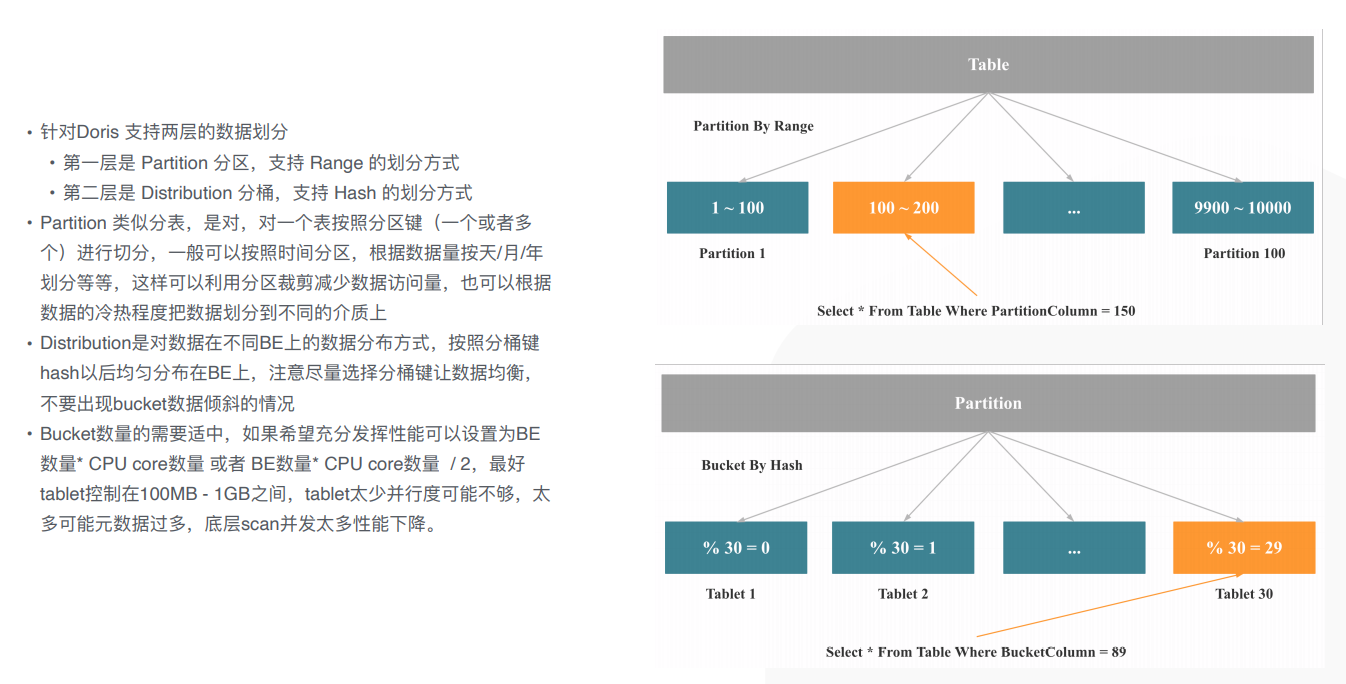
优化SSB查询:
range分区,每个partition分区(做数据的管理)到每个tablet
分桶 - 数据打散,并行度


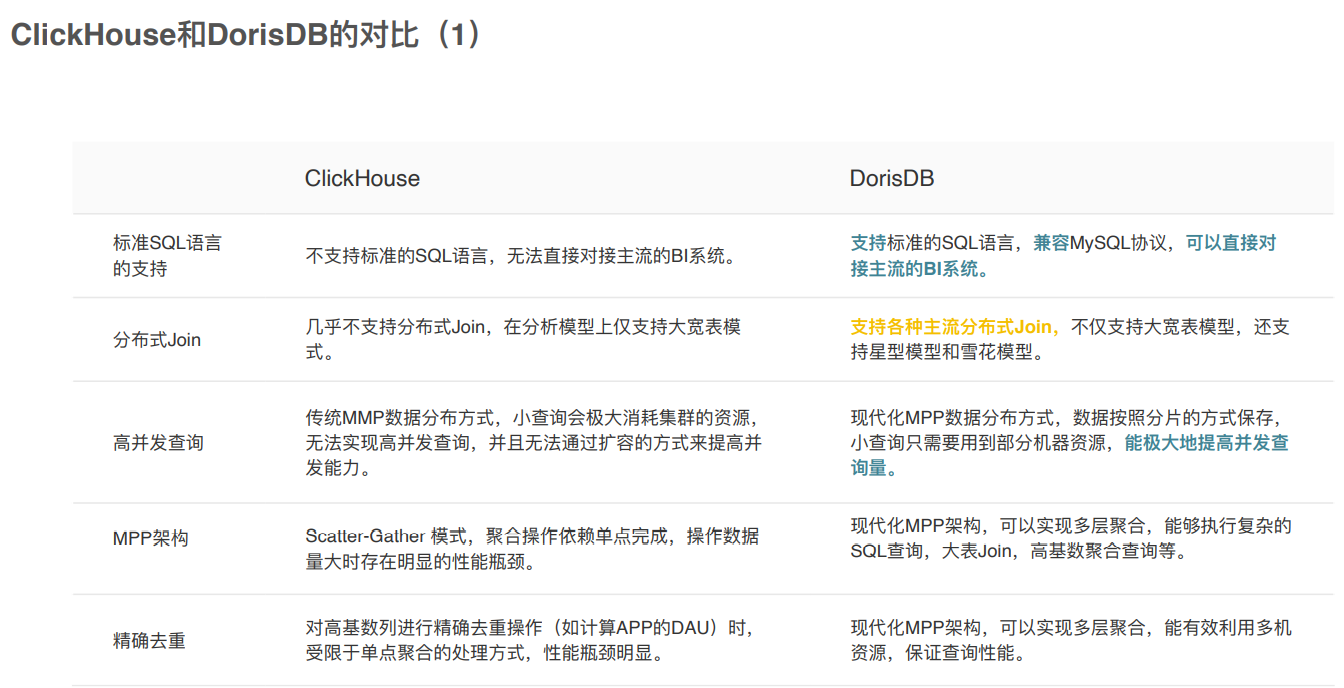
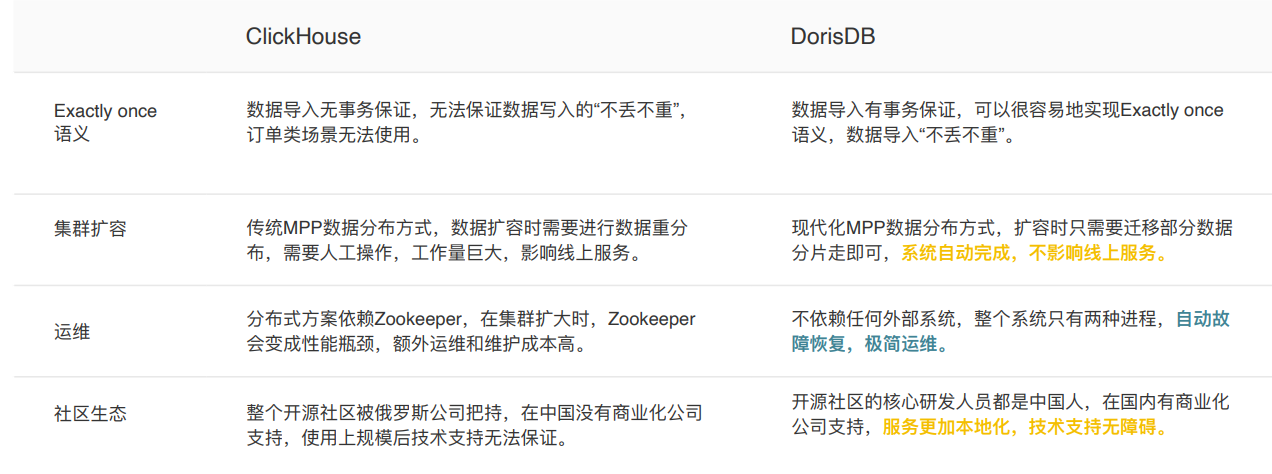
Impala+Kudu和DorisDB的对⽐




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人