
MySQL| 事务
事务
事务就是要保证一组数据库操作,要么全部成功,要么全部失败。在MySQL中,事务支持是在引擎层实现的。MySQL是一个支持多引擎的系统,但并不是所有的引擎都支持事务。比如
原生的MyISAM引擎就不支持事务。
隔离性与隔离级别
提到事务,你肯定会想到ACID(Atomicity、Consistency、Isolation、Durability,即原子性、一 致性、隔离性、持久性)
隔离性
当数据库上有多个事务同时执行的时候,就可能出现脏读(dirty read)、不可重复读(non- repeatable read)、幻读(phantomread)的问题,为了解决这些问题,就有了“隔离级别”
的概念。 在谈隔离级别之前,你首先要知道,你隔离得越严实,效率就会越低。因此很多时候,要在二者之间寻找一个平衡点。
SQL标准的事务隔离级别包括:
- 读未提交(read uncommitted)、
- 读提交(read committed)、
- 可重复读(repeatable read)、
- 串行化(serializable )。
① 读未提交是指,一个事务还没提交时,它做的变更就能被别的事务看到。
② 读提交是指,一个事务提交之后,它做的变更才会被其他事务看到。
③ 可重复读是指,一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。当然在可重复读隔离级别下,未提交变更对其他事务也是不可见的。
④ 串行化,是对于同一行记录,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突时,后访问的事务必须等前一个事务执行完成,才能继续执行。
其中“读提交”和“可重复读”比较难理解。
假设数据表T中只有一列,其中一行的值为1,下面是按照时间顺序执行两个事务的行为。

在不同的隔离级别下,事务A会有哪些不同的返回结果,也就是图里面V1、V2、V3 的返回值分别是什么。
① 若隔离级别是“读未提交”, 则V1的值就是2。这时候事务B虽然还没有提交,但是结果已经被 A看到了。因此,V2、V3也都是2。
② 若隔离级别是“读提交”,则V1是1,V2的值是2。事务B的更新在提交后才能被A看到。所以, V3的值也是2。
③ 若隔离级别是“可重复读”,则V1、V2是1,V3是2。之所以V2还是1,遵循的就是这个要求: 事务在执行期间看到的数据前后必须是一致的。
④ 若隔离级别是“串行化”,则在事务B执行“将1改成2”的时候,会被锁住。直到事务A提交后, 事务B才可以继续执行。所以从A的角度看, V1、V2值是1,V3的值是2。 在实现上,数据
库里面会创建一个视图,访问的时候以视图的逻辑结果为准。在“可重复读”隔离级别下,这个视图是在事务启动时创建的,整个事务存在期间都用这个视图。在“读提交”隔离级别下,
这个视图是在每个SQL语句开始执行的时候创建的。这里需要注意的是,“读未提交”隔离 级别下直接返回记录上的最新值,没有视图概念;而“串行化”隔离级别下直接用加锁的方式来
避免并行访问。 我们可以看到在不同的隔离级别下,数据库行为是有所不同的。
Oracle数据库的默认隔离级别其实就是“读提交”,因此对于一些从Oracle迁移到MySQL的应用,为保证数据库隔离级别的一致, 你一定要记得将MySQL的隔离级别设置为“读提交”。
配置的方式是,将启动参数transaction-isolation的值设置成READ-COMMITTED。你可以用showvariables来查看当前的值。
show variables like 'transaction_isolation';
总结来说,存在即合理,哪个隔离级别都有它自己的使用场景,你要根据自己的业务情况来定。
什么时候需要“可重复读”的场景呢?看一个数据校对逻辑的案例。 假设你在管理一个个人银行账户表。一个表存了每个月月底的余额,一个表存了账单明细。这时你要做数据校对,也
就是判断上个月的余额和当前余额的差额,是否与本月的账单明细一致。 你一定希望在校对过程中,即使有用户发生了一笔新的交易,也不影响你的校对结果。 这时使用“可重复读”
隔离级别就很方便。事务启动时的视图可以认为是静态的,不受其他事务 更新的影响。
事务隔离的实现
理解了事务的隔离级别,再来看看事务隔离具体是怎么实现的。这里展开说明“可重复读”。 在MySQL中,实际上每条记录在更新的时候都会同时记录一条回滚操作。记录上的最新
值,通过回滚操作,都可以得到前一个状态的值。
假设一个值从1被按顺序改成了2、3、4,在回滚日志里面就会有类似下面的记录。
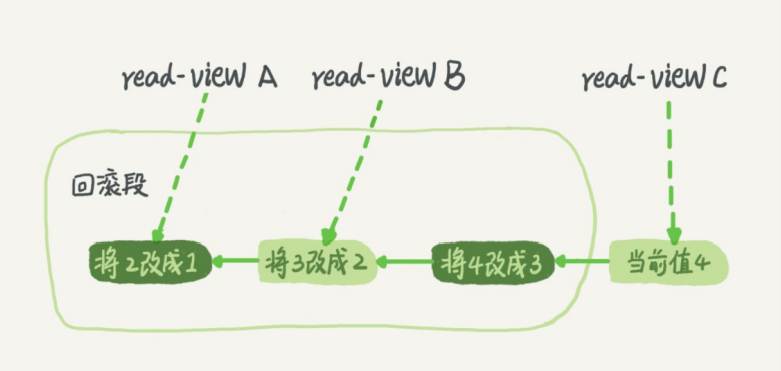
当前值是4,但是在查询这条记录的时候,不同时刻启动的事务会有不同的read-view。如图中看 到的,在视图A、B、C里面,这一个记录的值分别是1、2、4,同一条记录在系统中
可以存在多个版本,就是数据库的多版本并发控制(MVCC)。对于read-viewA,要得到1,就必须将当前 值依次执行图中所有的回滚操作得到。 同时你会发现,即使现在有另外一个
事务正在将4改成5,这个事务跟read-viewA、B、C对应的 事务是不会冲突的。 你一定会问,回滚日志总不能一直保留吧,什么时候删除呢?答案是,在不需要的时候才删除。 也就
是说,系统会判断,当没有事务再需要用到这些回滚日志时,回滚日志会被删除。 什么时候才不需要了呢?就是当系统里没有比这个回滚日志更早的read-view的时候。
基于上面的说明,来讨论下尽量不要使用长事务。 长事务意味着系统里面会存在很老的事务视图。由于这些事务随时可能访问数据库里面的任何数据,所以这个事务提交之
前,数据库里面它可能用到的回滚记录都必须保留,这就会导致大量占 用存储空间。 在MySQL 5.5及以前的版本,回滚日志是跟数据字典一起放在ibdata文件里的,即使长事务最终
提交,回滚段被清理,文件也不会变小。我见过数据只有20GB,而回滚段有200GB的库。最终 只好为了清理回滚段,重建整个库。 除了对回滚段的影响,长事务还占用锁资源,也
可能拖垮整个库,这个我们会在后面讲锁的时候 展开。 事务的启动方式 如前面所述,长事务有这些潜在风险,我当然是建议你尽量避免。其实很多时候业务开发同学并 不是有意使
用长事务,通常是由于误用所致。
MySQL的事务启动方式有以下几种:
1. 显式启动事务语句, begin 或 start transaction。配套的提交语句是commit,回滚语句是 rollback。
2. set autocommit=0,这个命令会将这个线程的自动提交关掉。意味着如果你只执行一个 select语句,这个事务就启动了,而且并不会自动提交。这个事务持续存在直到你主动执行
commit或 rollback 语句,或者断开连接。 有些客户端连接框架会默认连接成功后先执行一个set autocommit=0的命令。这就导致接下来的查询都在事务中,如果是长连接,就导致了
意外的长事务。 因此,我会建议你总是使用set autocommit=1, 通过显式语句的方式来启动事务。 但是有的开发同学会纠结“多一次交互”的问题。对于一个需要频繁使用事务的业务,
第二种方式 每个事务在开始时都不需要主动执行一次 “begin”,减少了语句的交互次数。如果你也有这个顾 虑,我建议你使用commit work and chain语法。 在autocommit为1的情况
下,用begin显式启动的事务,如果执行commit则提交事务。如果执行 commit work and chain,则是提交事务并自动启动下一个事务,这样也省去了再次执行begin语 句的开销。同时
带来的好处是从程序开发的角度明确地知道每个语句是否处于事务中。 你可以在information_schema库的innodb_trx这个表中查询长事务,比如下面这个语句,用于查 找持续时间超
过60s的事务。
select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60
如何避免长事务对业务的影响?
这个问题,我们可以从应用开发端和数据库端来看。
首先,从应用开发端来看:
- 1. 确认是否使用了set autocommit=0。这个确认工作可以在测试环境中开展,把MySQL的 general_log开起来,然后随便跑一个业务逻辑,通过general_log的日志来确认。一般框架 如果会设置这个值,也就会提供参数来控制行为,你的目标就是把它改成1。
- 2. 确认是否有不必要的只读事务。有些框架会习惯不管什么语句先用begin/commit框起来。我 见过有些是业务并没有这个需要,但是也把好几个select语句放到了事务中。这种只读事务 可以去掉。
- 3. 业务连接数据库的时候,根据业务本身的预估,通过SETMAX_EXECUTION_TIME命令, 来控制每个语句执行的最长时间,避免单个语句意外执行太长时间。(为什么会意外?在后 续的文章中会提到这类案例)
其次,从数据库端来看:
- 1. 监控 information_schema.Innodb_trx表,设置长事务阈值,超过就报警/或者kill;
- 2. Percona的pt-kill这个工具不错,推荐使用;
- 3. 在业务功能测试阶段要求输出所有的general_log,分析日志行为提前发现问题;
- 4. 如果使用的是MySQL 5.6或者更新版本,把innodb_undo_tablespaces设置成2(或更大的 值)。如果真的出现大事务导致回滚段过大,这样设置后清理起来更方便。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人