
实时--1.5 ADS聚合| Mysql事务精准一次
ADS聚合
需求分析
以热门品牌统计为例,将数据写入到ads层,然后根据各种报表及可视化来生成统计数据。通常这些报表及可视化都是基于某些维度的汇总统计。
热门商品统计(作业)
热门品类统计(作业)
交易用户性别对比(作业)
交易用户年龄段对比(作业)
交易额省市分布(作业)
业务流程图
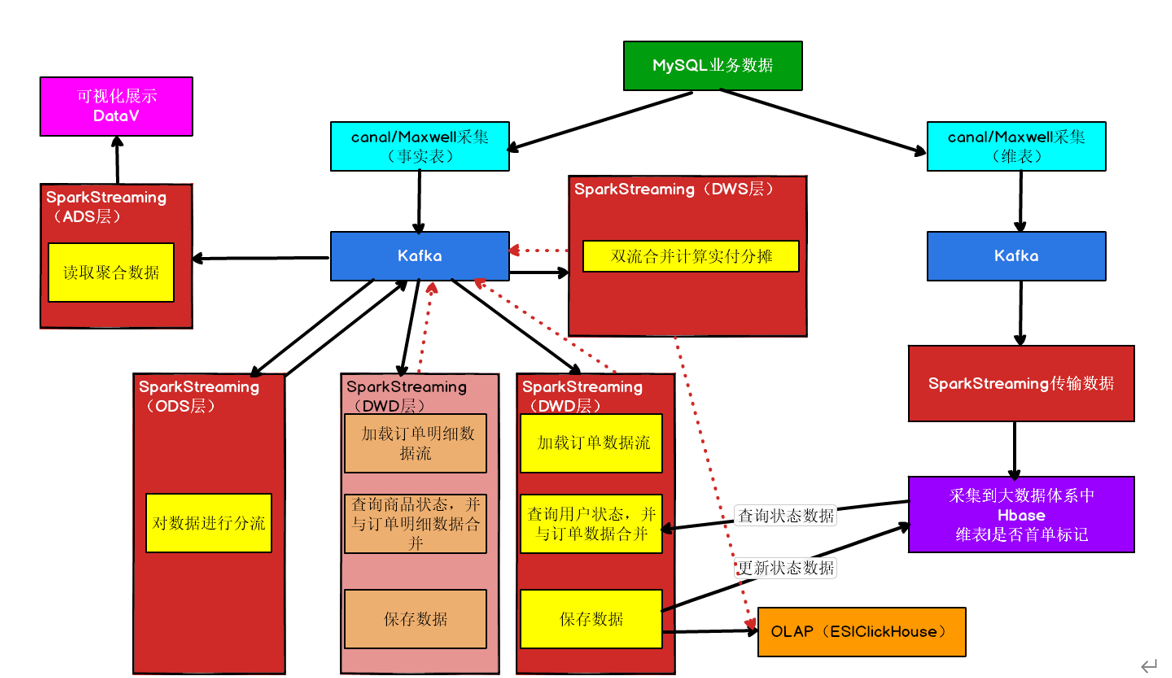
ADS层写入
发布查询接口
可视化查询
ADS层写入
分析
ads层,主要是根据各种报表及可视化来生成统计数据。通常这些报表及可视化都是基于某些维度的汇总统计。
统计表分为三个部分:时间点、维度、度量
时间点:即统计结果产生的时间,或者本批次数据中业务日期最早的时间。
维度:统计维度,比如地区、商品名称、性别
度量:汇总的数据,比如金额、数量
每个批次进行一次聚合,根据数据的及时性要求,可以调整批次的时间长度,将聚合后的结果一波一波的存放到数据库中。
数据库的选型与难点
聚合数据本身并不麻烦,利用reducebykey或者groupbykey都可以聚合,但是麻烦的是实现精确性一次消费。因为聚合数据不是明细,没有确定的主键,所以没有办法实现幂等。那么如果想实现精确一次消费,
就要考虑利用关系型数据库的事务处理。
用本地事务管理最大的问题是数据保存操作要放在driver端变成单线程操作,性能降低。 但是由于本业务保存的是聚合后的数据所以数据量并不大,即使单线程保存也是可以接受的,因此数据库和偏移量选用
mysql进行保存。
代码实现,在gmall-realtime中编写代码
创建保存偏移量的表 offset
CREATE TABLE `offset` (
`group_id` varchar(200) NOT NULL,
`topic` varchar(200) NOT NULL,
`partition_id` int(11) NOT NULL,
`topic_offset` bigint(20) DEFAULT NULL,
PRIMARY KEY (`group_id`,`topic`,`partition_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
创建保存品牌聚合结果的表
CREATE TABLE `trademark_amount_stat`
(
`stat_time` datetime,
`trademark_id` varchar(20),
`trademark_name` varchar(200),
`amount` decimal(16,2) ,
PRIMARY KEY (`stat_time`,`trademark_id`,`trademark_name`)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
读取MySQL中偏移量的工具类
在OrderWideApp中将数据写回Kafka
关于本地事务保存MySql
我们在处理事务的时候引用了一个 scala的MySQL工具:scalikeJdbc
(1) 读取配置文件
默认从classpath下读取application.conf,获取数据库连接信息,resources下创建application.conf文件
db.default.driver="com.mysql.jdbc.Driver"
db.default.url="jdbc:mysql://hadoop102/gmall?characterEncoding=utf-8&useSSL=false"
db.default.user="root"
db.default.password="123456"
(2) 程序中加载配置
DBs.setup()
(3) 本地事务提交数据
凡是在 DB.localTx(implicit session => { } )中的SQL全部被本地事务进行关联,一条失败全部回滚
DB.localTx(
implicit session => {
SQL1
SQL2
}
)
创建TrademarkStatApp(ads)
测试
确保相关服务启动
Hdfs、ZK、Kafka、Redis、Hbase、Maxwell
运行BaseDBMaxwellApp、OrderInfoApp、OrderDetailApp、OrderWideApp、TrademarkStatApp,运行模拟生成业务数据jar包
抛出异常查看数据结果,注释掉异常查看数据库表结果
发布查询接口
分析
功能1将数据写入到MySQL后,我们可以非常方便的进行一些统计,比如还是以品牌为例,我们现在要是计算某个时间段的热门品牌TopN,可以通过如下SQL完成,我们同样可以基于这些操作,发布查询接口,
方便对接可视化工具。
select
trademark_id,trademark_name, sum(amount) amount
from
trademark_amount_stat
where stat_time >= #{start_Date} and stat_time <=#{end_Date}
group by trademark_id,trademark_name
order by sum(amount) desc
limit 5;
发布接口的目的是为可视化工具提供数据服务,所以发布接口的地址和参数都要根据可视化工具的要求进行设置。后面的可视化工具选用了阿里云服务的DataV,由于DataV对地址没有要求(可以自行配置),只对
返回数据格式有一定要求,最好可以提前了解一下数据格式的要求。或者可以不考虑接口格式,先完成service的查询,然后在controller针对不同的格式要求在进行调整。
可视化查询
DataV
阿里云网址: https://datav.aliyun.com/
官方帮助手册: https://help.aliyun.com/document_detail/30360.html
阿里云有两大数据可视化服务,一个是QuickBI,一个就是DataV。
QuickBI定位BI工具定位由数据分析师使用,通过灵活配置各种多维分析、深度钻取,生成各种报表和可交互的图形化展示;而DataV ,倾向于定制数据大屏,针对运营团队使用的信息丰富炫酷的监控型可视化工
具。
数据源
DataV的数据源主要是两方面,阿里云数据服务体系内的数据源和外部数据源。
阿里云数据服务体系内的数据源,类型非常多,包括RDS服务,ADS服务,TableStore服务等等。本文只介绍基于外部数据源的配置方式。 外部数据源就是要发布出可以外网访问的地址,每一个可视化组件都要
对应一个访问地址。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号