
实时--1.1 日志采集集群
数据的准备
有直接将日志生成到文件,而是将日志发送给某一个指定的端口
1. 通过SpringBoot进行日志的采集
开发SpringBoot程序gmall-logger,采集日志数据
借助Logbak将采集的日志落盘
(1) 在LoggerController上加@Slf4j注解,并通过log.info记录日志,进行落盘。

(2) 在gmall-logger的resources中添加logback.xml配置文件

<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property name="LOG_HOME" value="/opt/module/realtime_dw/rt_gmall/gmall2020" /> <!-- 日志落盘地址,linux中与本地测试地址注意修改 -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<appender name="rollingFile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_HOME}/app.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_HOME}/app.%d{yyyy-MM-dd}.log</fileNamePattern>
</rollingPolicy>
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<!-- 将某一个包下日志单独打印日志 -->
<logger name="com.stream.gmall.logger.controller.LoggerController"
level="INFO" additivity="false">
<appender-ref ref="rollingFile" />
<appender-ref ref="console" />
</logger>
<root level="error" additivity="false">
<appender-ref ref="console" />
</root>
</configuration>
(3) logback配置文件说明
- appender
追加器,描述如何写入到文件中(写在哪,格式,文件的切分)
ConsoleAppender--追加到控制台
RollingFileAppender--滚动追加到文件
- logger
控制器,描述如何选择追加器
注意:要是单独为某个类指定的时候,别忘了修改类的全限定名
- 日志级别
TRACE [DEBUG INFO WARN ERROR] FATAL
(3) 思考:log哪里定义的?
其实在lombok注解@Slf4j底层执行了类似
Logger log = org.slf4j.LoggerFactory.getLogger(LoggerController.class);
启动SpringBoot程序,运行模拟生成日志的jar,查看在控制台和磁盘上都可以看到日志。
将采集到的日志数据发送到kafka
整体思路:在gmall-logger的controller中接收到数据之后,对日志数据进行分流,根据日志类型(事件|启动),将日志发送到不同的kafka主题中去
(1) application.properties中配置kafka相关信息和 server端口号的修改
ZooKeeper从3.5开始,AdminServer的端口也是8080,修改application.properties 中server的端口号
#修改server的端口号
server.port=8989
#============== kafka ===================
# 指定kafka 代理地址,可以多个
spring.kafka.bootstrap-servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
# 指定消息key和消息体的编解码方式
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
将KafkaTemplate注入到Controller中
//注入Spring提供的Kafka编程模板
@Autowired
KafkaTemplate kafkaTemplate;
对接收到的数据进行分流
整体代码如下
import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONObject; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.kafka.core.KafkaTemplate; import org.springframework.web.bind.annotation.RequestBody; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; /** * * Desc: 接收模拟器生成的数据,并对数据进行处理 */ //@Controller //将对象的创建交给Spring容器 方法返回String,默认会当做跳转页面处理 //@RestController = @Controller + @ResponseBoby 方法返回Object,底层会转换为json格式字符串进行相应 @RestController @Slf4j public class LoggerController { //Spring提供的对Kafka的支持 @Autowired // 将KafkaTemplate注入到Controller中 KafkaTemplate kafkaTemplate; //http://localhost:8080/applog //提供一个方法,处理模拟器生成的数据 //@RequestMapping("/applog") 把applog请求,交给方法进行处理 //@RequestBody 表示从请求体中获取数据 @RequestMapping("/applog") public String applog(@RequestBody String mockLog){ //System.out.println(mockLog); //落盘 log.info(mockLog); //return mockLog; //根据日志的类型,发送到kafka的不同主题中去 //将接收到的字符串数据转换为json对象 JSONObject jsonObject = JSON.parseObject(mockLog); JSONObject startJson = jsonObject.getJSONObject("start"); if(startJson != null){ //启动日志 kafkaTemplate.send("gmall_start",mockLog); }else{ //事件日志 kafkaTemplate.send("gmall_event",mockLog); } return "success"; } }
打包 gmall-logger-0.0.1-SNAPSHOT.jar,上传到Linux的 /opt/module/realtime_dw/rt_gmall 目录;
启动zk和Kafka,在Kafka中创建对应的主题
注意:默认情况下,Kafka创建主题默认分区是1个,修改为3个
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --topic gmall_start --partitions 3 --replication-factor 3
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --topic gmall_event --partitions 3 --replication-factor 3
测试是否能够走通
① [kris@hadoop102 rt_applog]$ vim application.properties
#http模式下,发送的地址: mock.url=http://hadoop102:8989/applog
② 运行kafka消费者,准备消费数据
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic gmall_start
③ 运行采集数据的jar包 java -jar gmall-logger-0.0.1-SNAPSHOT.jar
④ 发送数据的jar包 java -jar gmall-mock-log.jar
接收日志的JSON格式如下:
start 启动日志:
{
"common": {
"ar": "110000",
"ba": "iPhone",
"ch": "Appstore",
"md": "iPhone Xs Max",
"mid": "mid_18",
"os": "iOS 13.2.9",
"uid": "88",
"vc": "v2.1.134"
},
"start": {
"entry": "icon",
"loading_time": 13855,
"open_ad_id": 4,
"open_ad_ms": 1463,
"open_ad_skip_ms": 0
},
"ts": 1603289235000
}
event事件日志
{
"common": {
"ar": "310000",
"ba": "Huawei",
"ch": "oppo",
"md": "Huawei Mate 30",
"mid": "mid_34",
"os": "Android 11.0",
"uid": "404",
"vc": "v2.1.134"
},
"displays": [{
"display_type": "activity",
"item": "1",
"item_type": "activity_id",
"order": 1
}, {
"display_type": "activity",
"item": "1",
"item_type": "activity_id",
"order": 2
}, {
"display_type": "query",
"item": "3",
"item_type": "sku_id",
"order": 3
}, {
"display_type": "recommend",
"item": "6",
"item_type": "sku_id",
"order": 4
}, {
"display_type": "query",
"item": "8",
"item_type": "sku_id",
"order": 5
}, {
"display_type": "query",
"item": "2",
"item_type": "sku_id",
"order": 6
}, {
"display_type": "query",
"item": "5",
"item_type": "sku_id",
"order": 7
}, {
"display_type": "query",
"item": "8",
"item_type": "sku_id",
"order": 8
}, {
"display_type": "promotion",
"item": "6",
"item_type": "sku_id",
"order": 9
}, {
"display_type": "promotion",
"item": "1",
"item_type": "sku_id",
"order": 10
}, {
"display_type": "query",
"item": "2",
"item_type": "sku_id",
"order": 11
}, {
"display_type": "promotion",
"item": "5",
"item_type": "sku_id",
"order": 12
}],
"page": {
"during_time": 5016,
"page_id": "home"
},
"ts": 1603289254709
}
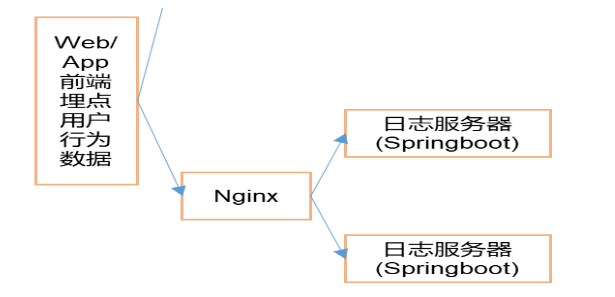
2. 日志采集集群并通过Nginx进行反向代理
(1) Nginx环境搭建好
https://www.cnblogs.com/shengyang17/p/10836168.html ,只需一台部署nginx即可;
(2) 修改nginx.conf配置文件 注意:每行配置完毕后有分号
在server内部配置
location /applog{
proxy_pass http://www.logserver.com;
}
在server外部配置反向代理
upstream www.logserver.com{
server hadoop102:8989 weight=1;
server hadoop103:8989 weight=2;
server hadoop104:8989 weight=3;
}
(3) 将日志采集的模块jar包 gmall-logger-0.0.1-SNAPSHOT.jar 同步到hadoop103和hadoop104
xsync rt_gmall/
(4) 修改模拟日志生成的配置,发送到的服务器路径修改为nginx的
[kris@hadoop102 rt_applog]$ vim application.properties
# 外部配置打开
#logging.config=./logback.xml
#业务日期
mock.date=2020-07-13
#模拟数据发送模式
mock.type=http
#http模式下,发送的地址,修改为发送给nginx,nginx反向代理发送给SpringBoot采集日志程序;
mock.url=http://hadoop102/applog
测试
启动nginx路由,路由三台虚拟机给接收日志服务的jar包 ,并发给fakfa;
- 运行kafka消费者,准备消费数据(测试启动日志)
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic gmall_start
- 启动nginx服务
/opt/module/realtime_dw/nginx
- 运行采集数据的jar
[kris@hadoop102 rt_gmall]$ java -jar gmall-logger-0.0.1-SNAPSHOT.jar
[kris@hadoop103 rt_gmall]$ java -jar gmall-logger-0.0.1-SNAPSHOT.jar
[kris@hadoop104 rt_gmall]$ java -jar gmall-logger-0.0.1-SNAPSHOT.jar
- 运行模拟生成数据的jar
[kris@hadoop102 rt_applog]$ java -jar gmall-mock-log.jar
采集集群群起脚本 将采集日志服务(nginx和采集日志数据的jar启动服务)放到脚本
在/home/kris/bin目录下创建logger.sh,并授予执行权限
#!/bin/bash
JAVA_BIN=/opt/module/jdk1.8.0_212/bin/java
APPNAME=gmall-logger-0.0.1-SNAPSHOT.jar
case $1 in
"start")
{
for i in hadoop102 hadoop103 hadoop104
do
echo "========: $i==============="
ssh $i "$JAVA_BIN -Xms32m -Xmx64m -jar /opt/module/realtime_dw/rt_gmall/$APPNAME >/dev/null 2>&1 &"
done
echo "========NGINX==============="
/opt/module/realtime_dw/nginx/sbin/nginx
};;
"stop")
{
echo "======== NGINX==============="
/opt/module/realtime_dw/nginx/sbin/nginx -s stop
for i in hadoop102 hadoop103 hadoop104
do
echo "========: $i==============="
ssh $i "ps -ef|grep $APPNAME |grep -v grep|awk '{print \$2}'|xargs kill" >/dev/null 2>&1
done
};;
esac
ssh之间的互相连接:三种联通方式:
①source /etc/profile;
②ssh 会读.bashrc cat /etc/profile>>.brashrc
③$JAVA_BIN
netstart -anp | more 查看端口



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人