
Elasticsearch| 分词
如何通过分词生成倒排索引
分词是指将文本转换成一系列单词(term or token)的过程,也可以叫做文本分析,在es里面称为Analysis.
Analysis 和Analyzer
Analysis - 文本分析是把全文本转换一系列单词(term / token)的过程,也叫分词;
Analysis 是通过Analyzer来实现的,可使用Elasticsearch内置的分析器/ 或者按需定制分析器;
除了在数据写入时转换词条,匹配Query语句时候也需要用相同的分析器对查询语句进行分析。
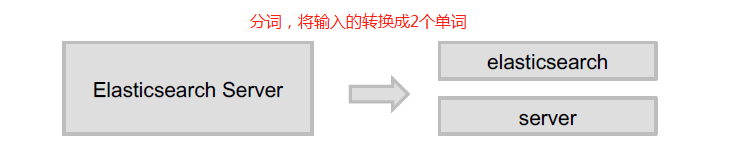
Analyzer的组成
分词器是专门处理分词的组件,Analyzer由三部分组成:
Character Filters(针对原始文本处理,例如去除html)/ Tokenizer(按照规则切分单词) / Token Filter(将切分的单词进行加工,小写,删除stopwords,增加同义词)
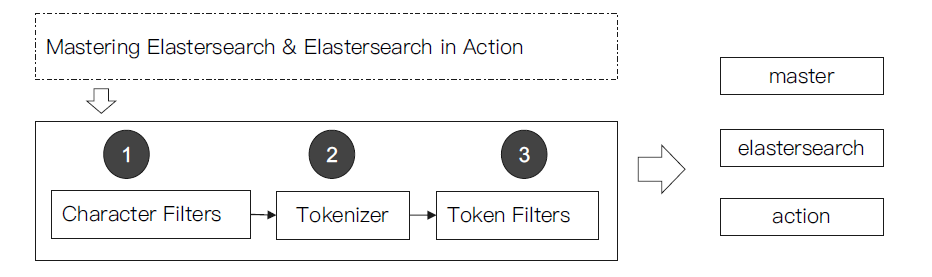
Elasticsearch的内置分词器
- Standard Analyzer - 默认分词器,按词切分,小写处理;
- Simple Analyzer - 按照非字母切分(符合被过滤),小写处理;
- Stop Analyzer - 小写处理,停用词过滤(the ,a, is)
- Whitespace Analyzer - 按照空格切分,不转小写
- Keyword Analyzer - 不分词,直接将输入当做输出
- Patter Analyzer - 正则表达式,默认\w(非字符分隔)
- Language - 提供了30多种常见语言的分词器
- Customer Analyzer 自定义分词器
使用_Analyzer API
#直接指定 Analyzer 进行测试
Get/_analyze
{
"analyzer":"standard",
"text":"Mastering Elasticsearch,elasticsecrch in Action"
}
#指定索引的字段进行测试
POST books/_anatyze
{
"field":"title",
"text":"Mastering Elasticseach"
}
#自定义分词起进行测试
POST/_anatyze
{
"tokenizer":"standard",
"filter":["lowercase"],
"text":"Mastering Elasticseach"
}
① Standard Analyzer - 默认分词器,按词切分,小写处理
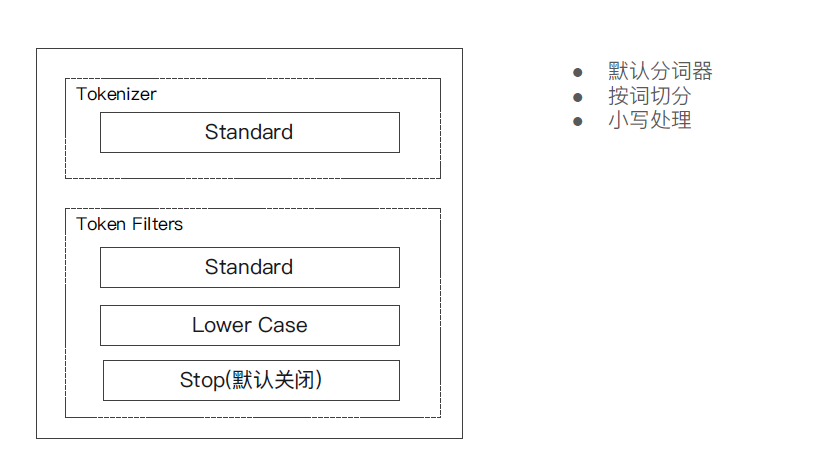
#standard 分词器
GET _analyze
{
"analyzer": "standard",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
② Simple Analyzer - 按照非字母切分(符合被过滤),小写处理;
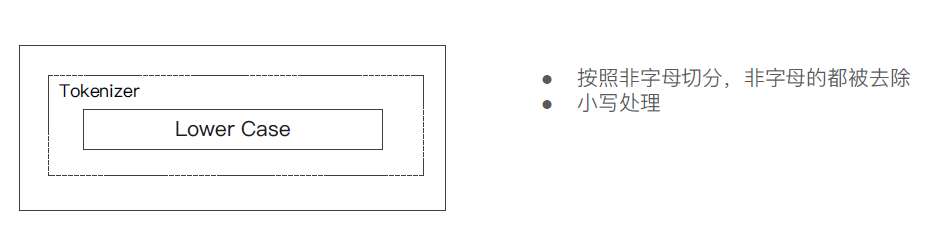
#simpe 分词器
GET _analyze
{
"analyzer": "simple",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
③ Stop Analyzer - 小写处理,停用词过滤(the ,a, is)

GET _analyze { "analyzer": "stop", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." }
④ Whitespace Analyzer - 按照空格切分,不转小写

GET _analyze { "analyzer": "whitespace", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." }
⑤ Keyword Analyzer - 不分词,直接将输入当做输出
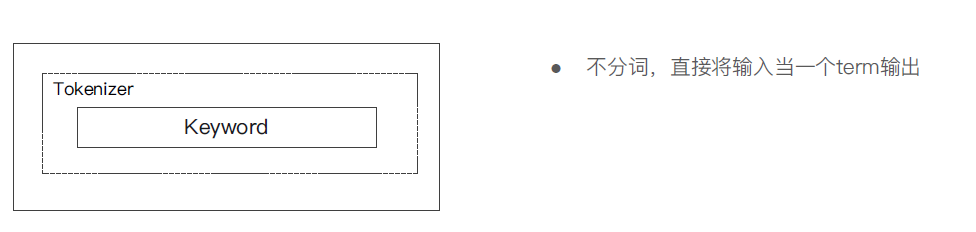
#keyword GET _analyze { "analyzer": "keyword", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." }
⑥ Patter Analyzer - 正则表达式,默认\w(非字符分隔)
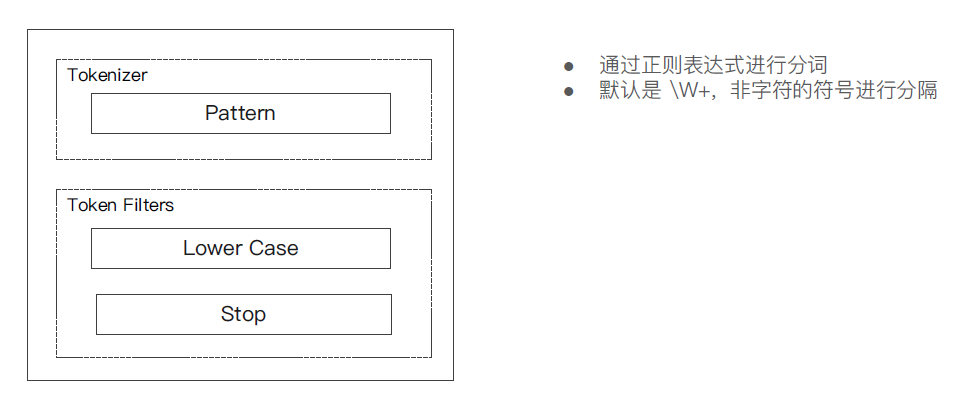
GET _analyze { "analyzer": "pattern", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." }
⑦ Language - 提供了30多种常见语言的分词器

#english GET _analyze { "analyzer": "english", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." }
⑧ Customer Analyzer 自定义分词器
中文分词
中文分词的难点
中文句子,切分成一个一个词(不是一个个字);英文中,单词有自然的空格作为分隔;
一句中文,在不同的上下文,有不同的理解;(例如这个苹果,不大好吃 / 这个苹果,不大,好吃!)
ICU Analyzer分词器

POST _analyze { "analyzer": "icu_analyzer", "text": "他说的确实在理”" }
效果:
“他” “说的” “确实” “在理”
POST _analyze { "analyzer": "standard", "text": "他说的确实在理”" } 效果: “他” “说” “的” “确” “实” “在” “理”
通过上面的查询,我们可以看到ES本身自带的中文分词,就是单纯把中文一个字一个字的分开逐字拆解,根本没有词汇的概念,不符合中文的搜索习惯。但是实际应用中,用户都是
以词汇为条件,进行查询匹配的,如果能够把文章以词汇为单位切分开,那么与用户的查询条件能够更贴切的匹配上,查询速度也更加快速。
常见的一些开源分词器对比
IK
支持自定义词库,支持热更新分词字典; https://github.com/medcl/elasticsearch-analysis-ik
THULAC
THU Lexucal Analyzer for Chinese,清华大学自然语言处理和社会人文计算实验室的一套中文分词器; https://github.com/microbun/elasticsearch-thulac-plugin
|
分词器 |
优势 |
劣势 |
|
Smart Chinese Analysis |
官方插件 |
中文分词效果惨不忍睹 |
|
IKAnalyzer |
简单易用,支持自定义词典和远程词典 |
词库需要自行维护,不支持词性识别 |
|
结巴分词 |
新词识别功能 |
不支持词性识别 |
|
Ansj中文分词 |
分词精准度不错,支持词性识别 |
对标hanlp词库略少,学习成本高 |
|
Hanlp |
目前词库最完善,支持的特性非常多 |
需要更优的分词效果,学习成本高 |
IK分词器的安装及使用
- 解压zip文件 unzip elasticsearch-analysis-ik-6.6.0.zip -d /opt/module/elasticsearch/plugins/ik
注意
- 使用unzip进行解压
- -d指定解压后的目录
- 必须放到ES的plugins目录下,并在plugins目录下创建单独的目录
IK提供了两个分词算法ik_smart 和 ik_max_word,其中 ik_smart 为最少切分,粗粒度分词器; ik_max_word为最细粒度划分,细粒度分词器;
查看: /opt/module/elasticsearch/plugins/ik/conf下的文件,分词就是将所有词汇分好放到文件中
分发: xsync /opt/module/elasticsearch/plugins/ik
重启ES: es.sh stop es.sh start
测试使用
- 默认分词器
GET movie_index/_analyze
{
"text": "我是中国人"
}

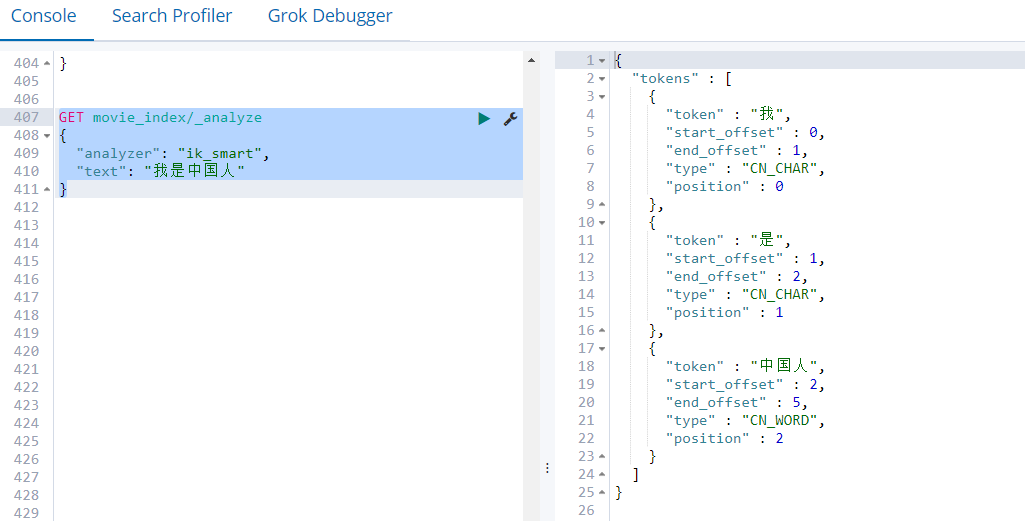
- IK分词器 —① ik_smart分词方式,粗粒度分词
GET movie_index/_analyze
{
"analyzer": "ik_smart",
"text": "我是中国人"
}
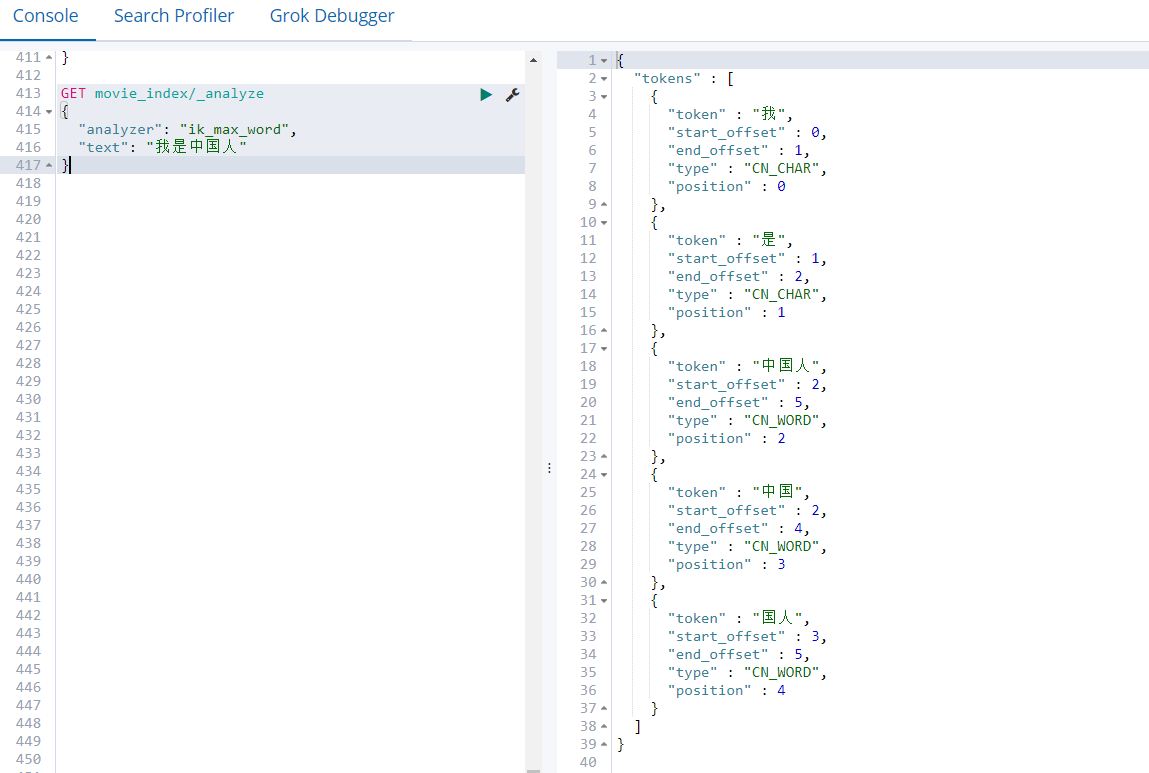
- IK分词器 —② ik_max_word分词方式,细粒度分词
GET movie_index/_analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
自定义词库-本地指定
由于第三方分词器预存的词库有限,远远赶不上层出不穷的新词。有的时候,词库提供的词并不包含项目中使用到的一些专业术语或者新兴网络用语,需要我们对词库进行补充。具体步骤
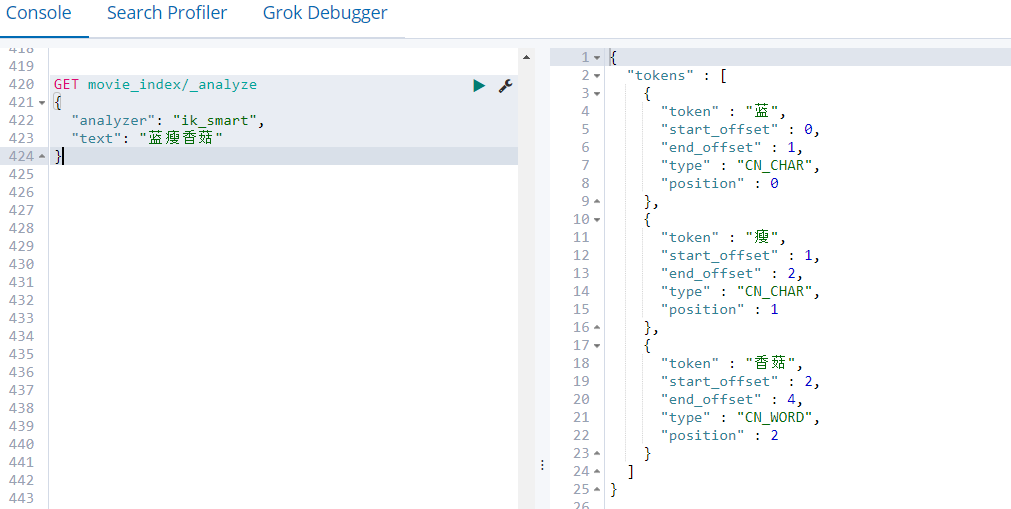
- 没有使用自定义词库前
GET movie_index/_analyze
{
"analyzer": "ik_smart",
"text": "蓝瘦香菇"
}
- 通过配置本地目录直接指定自定义词库
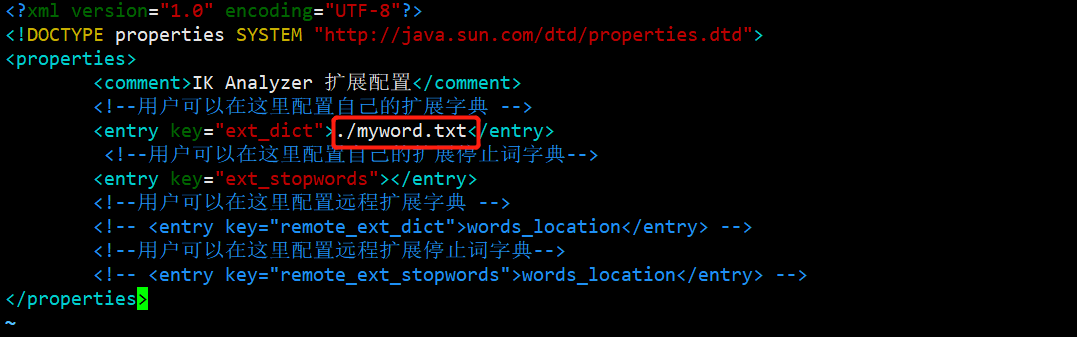
修改/opt/module/elasticsearch/plugins/ik/config/中的IKAnalyzer.cfg.xml
|
名词概念:停止词,是由英文单词:stopword翻译过来的,原来在英语里面会遇到很多a,the,or等使用频率很多的字或词,常为冠词、介词、副词或连词等。 如果搜索引擎要将这些词都索引的话,那么几乎每个网站都会被索引,也就是说工作量巨大。可以毫不夸张的说句,只要是个英文网站都会用到a或者是the。那么这些英文的词跟我们中文有什么关系呢? 在中文网站里面其实也存在大量的stopword,我们称它为停止词。比如,我们前面这句话,“在”、“里面”、“也”、“的”、“它”、“为”这些词都是停止词。这些词因为使用频率过高,几乎每个网页上都存在,所以搜索引擎开发人员都将这一类词语全部忽略掉。如果我们的网站上存在大量这样的词语,那么相当于浪费了很多资源。原本可以添加一个关键词,排名就可以上升一名的,为什么不留着添加为关键词呢?停止词对SEO的意义不是越多越好,而是尽量的减少为宜。 |
在/opt/module/elasticsearch/plugins/ik/config/当前目录下创建myword.txt
[kris@hadoop101 config]$ vim myword.txt
蓝瘦
蓝瘦香菇
分发配置文件以及myword.txt
- xsync /opt/module/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml
- xsync /opt/module/elasticsearch/plugins/ik/config/myword.txt
重启ES服务 es.sh stop es.sh start
测试分词效果


自定义词库-远程指定
远程配置一般是如下流程,我们这里简易通过nginx模拟

修改/opt/module/elasticsearch/plugins/ik/config/中的IKAnalyzer.cfg.xml
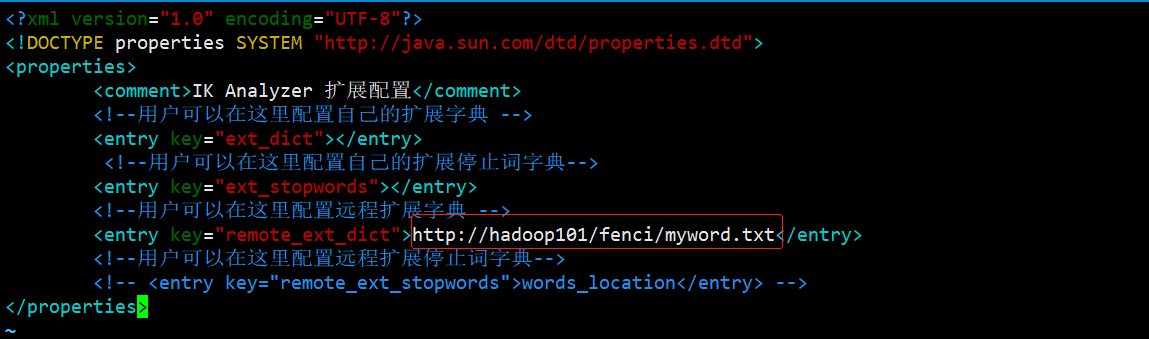
注意:将本地配置注释掉
分发配置文件 xsync /opt/module/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml
在nginx.conf文件中配置静态资源路径
[kris@hadoop101 conf]$ vim nginx.conf
location /fenci{
root es;
}
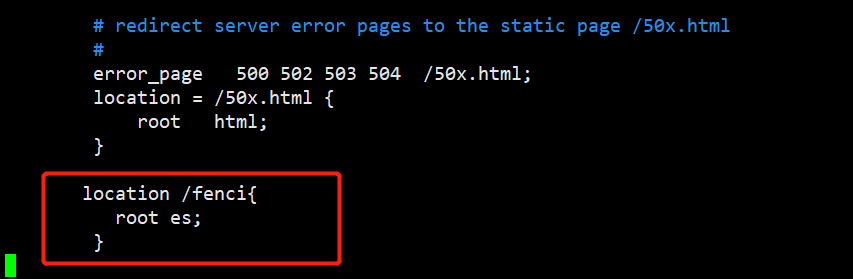
在/opt/module/nginx/目录下创建es/fenci目录,并在es/fenci目录下创建myword.txt
[kris@hadoop101 es]$ vim /opt/module/nginx/es/fenci/myword.txt
蓝瘦
蓝瘦香菇
启动nginx /opt/module/nginx/sbin/nginx
重启ES服务 es.sh stop es.sh start
测试nginx是否能够访问 浏览器中打开: http://hadoop101/fenci/myword.txt
测试分词效果
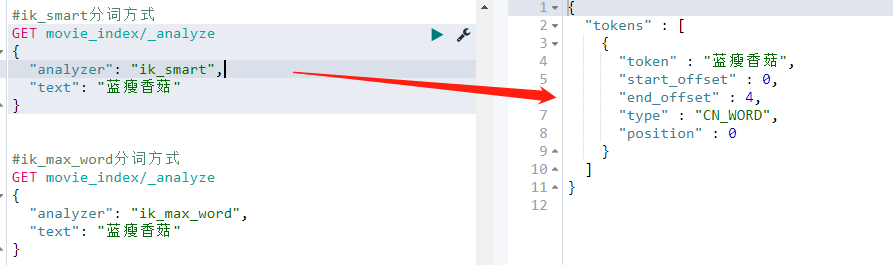

更新完成后,ES只会对新增的数据用新词分词。历史数据是不会重新分词的。如果想要历史数据重新分词。需要执行:
POST movies_index_chn/_update_by_query?conflicts=proceed
精确值Exact Value和全文本Full Text的比较
Exact Value: 包括数字 / 日期 / 具体一个字符串(例如“Apple Store”);如 Elasticsearch中的keyword,不用做分词处理(精确值);
全文本,非结构化的文本数据;如Elaticsearch中的text,会做分词的处理;
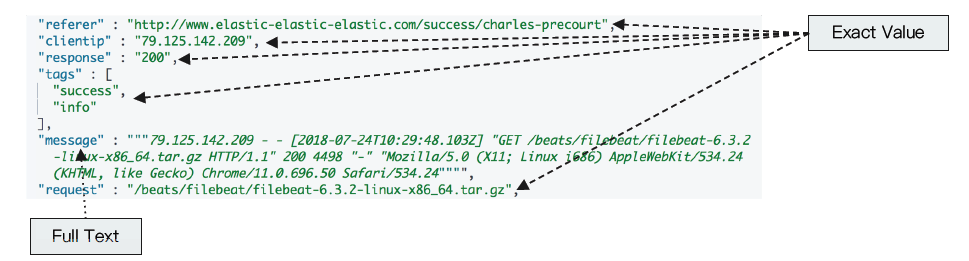
Exact Values与text最大的区别是,它不需要分词;
Elaticsearch为每一个字段创建一个倒排索引,Exact Value在索引时,不需要做特殊的分词处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号