
Elasticsearch-Restful API
1. 基本概念
Elasticsearch有几个核心概念,先理解这些概念将有助于掌握Elasticsearch。
近实时(Near Realtime / NRT)
Elasticsearch是一个近实时的搜索平台,从生成文档索引到文档成为可搜索,有一个轻微的延迟(通常是一秒钟)。
集群(Cluster)
ES 默认就是集群状态,整个集群是一份完整、互备的数据。
集群是一个或多个节点(服务器)的集合。集群中的节点一起存储数据,对外提供搜索功能。集群由一个唯一的名称标识,该名称默认是“elasticsearch”。集群名称很重要,节点都是通过集群名称加入集群。
集群不要重名,取名一般要有明确意义,否则会引起混乱。例如,开发、测试和生产集群的名称可以使用logging-dev、logging-test和logging-prod。
集群节点数不受限制,可以只有一个节点。
节点(Node)
节点是一个服务器,属于某个集群。节点存储数据,参与集群的索引和搜索功能。与集群一样,节点也是通过名称来标识的。默认情况下,启动时会分配给节点一个UUID(全局惟一标识符)作为名称。如有需要,可以给节点取名,通常取名时应考虑能方便识别和管理。
默认情况下,节点加入名为elasticsearch的集群,通过设置节点的集群名,可加入指定集群。
索引(Index)
索引是具有某种特征的文档集合,相当于一本书的目录。例如,可以为客户数据建立索引,为订单数据建立另一个索引。索引由名称标识(必须全部为小写),可以使用该名称,对索引中的文档进行建立索引、搜索、更新和删除等操作。一个集群中,索引数量不受限制。
类似于rdbms的database(5.x), 对于用户来说是一个逻辑数据库,虽然物理上会被分多个shard存放,也可能存放在多个node中。 6.x 7.x index相当于table
类型(Type)
类似于rdbms的table,但是与其说像table,其实更像面向对象中的class , 同一Json的格式的数据集合。(6.x只允许建一个,7.0被废弃,造成index实际相当于table级)
文档(Document)
文档是可以建立索引的基本信息单元,相当于书的具体章节。
例如,可以为单个客户创建一个文档,为单个订单创建另一个文档。文档用JSON (JavaScript对象表示法)表示。在索引中,理论上可以存储任意数量的文档。
类似于rdbms的 row、面向对象里的object
字段|属性(Field)
相当于字段、属性
分片与副本(Shards & Replicas)
索引可能存储大量数据,数据量可能超过单个节点的硬件限制。
例如,一个索引包含10亿个文档,将占用1TB的磁盘空间,单个节点的磁盘放不下。
Elasticsearch提供了索引分片功能,创建索引时,可以定义所需的分片数量。每个分片本身都是一个功能齐全,独立的“索引”,可以托管在集群中的任何节点上。
分片之所以重要,主要有2个原因:
- 允许水平切分内容,以便内容可以存储到普通的服务器中
- 允许跨分片操作(如查询时,查询多个分片),提高性能/吞吐量
分片如何部署、如何跨片搜索完全由Elasticsearch管理,对外是透明的。
网络环境随时可能出现故障,如果某个分片/节点由于某种原因离线或消失,那么使用故障转移机制是非常有用的,强烈建议使用这种机制。为此,Elasticsearch允许为分片创建副本。
副本之所以重要,主要有2个原因:
- 在分片/节点失败时提供高可用性。因此,原分片与副本不应放在同一个节点上。
- 扩展吞吐量,因为可以在所有副本上并行执行搜索。
总而言之,索引可以分片,索引分片可以创建副本。复制后,每个索引将具有主分片与副本分片。
创建索引时,可以为每个索引定义分片和副本的数量。之后,还可以随时动态更改副本数量。您可以使用_shrink和_split api更改现有索引的分片数量,但动态修改副本数量相当麻烦,最好还是预先计划好分片数量。
默认情况下,Elasticsearch中的每个索引分配一个主分片和一个副本(7.X之前,默认是5片,副本是0。7.X默认改为1片,副本为1)。如果集群中有两个节点,就可以将索引主分片部署在一个节点,副本分片放在另一个节点,提高可用性。
概念之间关系图

这张图可以展示出ES各组件之间的关系,整张表是一个Cluster,横行是Nodes,竖列是Indices,深绿色方块是Primary Shards,浅绿色方块是Replica Shards。
至于单个Host上的Node数目问题,在硬件资源有限的情况下,一般的做法是一个Host只运行一个ES进程,也就是一个Node。例外情况是,由于ES内存配置上的特殊要求(JVM
Heap不能超过32G),如果你的Host特别NB(16 Core CPU + 128G RAM + SSD 这种),完全可以在单个Host上运行多个ES进程以避免硬件资源的浪费。
ES概念和MySQL关系对比
|
MySQL |
ES5.X |
ES6.X |
ES7.X |
|
Database |
Index |
|
|
|
Table |
Type |
Index(Type成了摆设) |
Index(Type被移除掉) |
|
Row |
Document |
Document |
|
|
Column |
Field |
Field |
|
Elasticsearch数据存储方式
数据的插入用PUT,用文档的方式进行数据的存储;
1)面向文档
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。这种理解数据的方式与以往完全不同,这也是Elasticsearch能够执行复杂的全文搜索的原因之一。
面向对象(表)是基于二维表(行列excel)的存储模型-如mysql,操作数据时把它当做一个对象,创建封装对象;写sql语句,查询等

面向对象:表
id name age
1 kris 22
2 alex 18
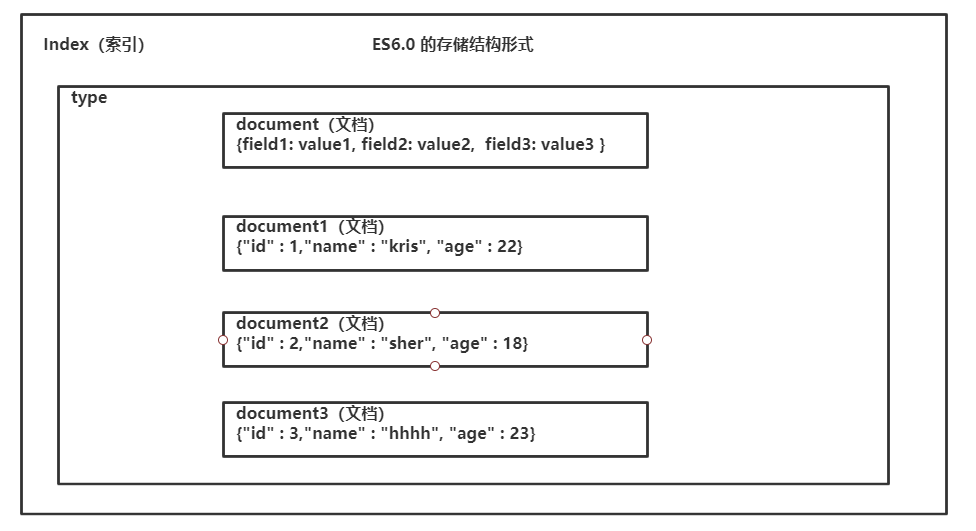
面向文档:单条
----------------------------------------------
{"id" : 1,"name" : "kris", "age" : 22}
-----------------------------------------------
{"id" : 2,"name" : "sher", "age" : 18}
-----------------------------------------------
{"id" : 3,"name" : "hhhh", "age" : 23}
面向文档(单条)是一条一条的,多个文档在一块,以单条数据位单位;json字符串,可直接进行操作如.split(“ ”);遍历等
2)JSON
ELasticsearch使用Javascript对象符号(JavaScript Object Notation),也就是JSON,作为文档序列化格式。JSON现在已经被大多语言所支持,而且已经成为NoSQL领域的标准格式。它简洁、简单且容易阅读。
更方便的堆数据进行操作;更方便的分词,全文检索、搜索等
以下使用JSON文档来表示一个用户对象:
{
"email": "john@smith.com",
"first_name": "John",
"last_name": "Smith",
"info": {
"bio": "Eco-warrior and defender of the weak",
"age": 25,
"interests": [ "dolphins", "whales" ]
},
"join_date": "2014/05/01"
}
存储结构
5.x
index--->①库database
type -->②表 table
field-->③字段column
document-->row一行数据;存储数据的基本单元;
6.0之后
一个index中只能有一个type,
一个type中有多个文档document,
一个document中有多个field字段,k v形式的json格式
index可以看作一个表:index( index:_doc默认的 )
7.x,type就被取消了
ES6.0之后就不能运行有type2了!!
在Es6.0之后,一个index中只运行有1个type,弱化了表的概念;(有可能把type取消掉,完全的面向文档)
名词解释 索引 index 一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。 类型 type 在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。 字段Field 相当于是数据表的字段,对文档数据根据不同属性进行的分类标识 document 一个document相当于mysql中的一条 一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。在一个index/type里面,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type。
Type可以理解为关系型数据库的Table,每个Type中的字段的数据类型,由mapping定义,如果我们在创建Index的时候,没有设定mapping,系统会自动根据一条数据的格式来推断出该数据对应的字段类型
假设有如下实体
public class Movie {
String id;
String name;
Double doubanScore;
List<Actor> actorList;
}
public class Actor{
String id;
String name;
}
这两个对象如果放在关系型数据库保存,会被拆成2张表,但是ElasticSearch是用一个json来表示一个document。类似豆瓣某个电影详情页 https://movie.douban.com/
保存到ES中应该是
{
"id":"1",
"name":"operation red sea",
"doubanScore":"8.5",
"actorList":[
{"id":"1","name":"zhangyi"},
{"id":"2","name":"haiqing"},
{"id":"3","name":"zhanghanyu"}
]
}
2. ElasticSearch RestFulAPI(DSL)
DSL全称 Domain Specific language,即特定领域专用语言
全局操作
① 查询集群健康情况 API:GET /_cat/health?v
?v表示显示头信息

集群的健康状态有红、黄、绿三个状态
- 绿 – 一切正常(集群功能齐全)
- 黄 – 所有数据可用,但有些副本尚未分配(集群功能完全)
- 红 – 有些数据不可用(集群部分功能)
② 查询各个节点状态 API:GET /_cat/nodes?v

对索引的操作
① 查询各个索引状态 API:GET /_cat/indices?v

ES中会默认存在一些索引
|
health |
green(集群完整) yellow(单点正常、集群不完整) red(单点不正常) |
|
status |
是否能使用 |
|
index |
索引名 |
|
uuid |
索引统一编号 |
|
pri |
主节点几个分片 |
|
rep |
从节点几个(副本数) |
|
docs.count |
文档数 |
|
docs.deleted |
文档被删了多少 |
|
store.size |
整体占空间大小 |
|
pri.store.size |
主节点占空间大小 |
② 创建索引API: PUT 索引名?pretty
PUT movie_index?pretty

使用PUT创建名为“movie_index”的索引。末尾追加pretty,可以漂亮地打印JSON响应(如果有的话)。红色警告说在7.x分片数会由默认的5改为1,我们忽略即可
索引名命名要求:
- 仅可能为小写字母,不能下划线开头
- 不能包括 , /, *, ?, ", <, >, |, 空格, 逗号, #
- 7.0版本之前可以使用冒号:,但不建议使用并在7.0版本之后不再支持
- 不能以这些字符 -, _, + 开头
- 不能包括 . 或 …
- 长度不能超过 255 个字符
查询某个索引的分片情况API:GET /_cat/shards/索引名
GET /_cat/shards/movie_index
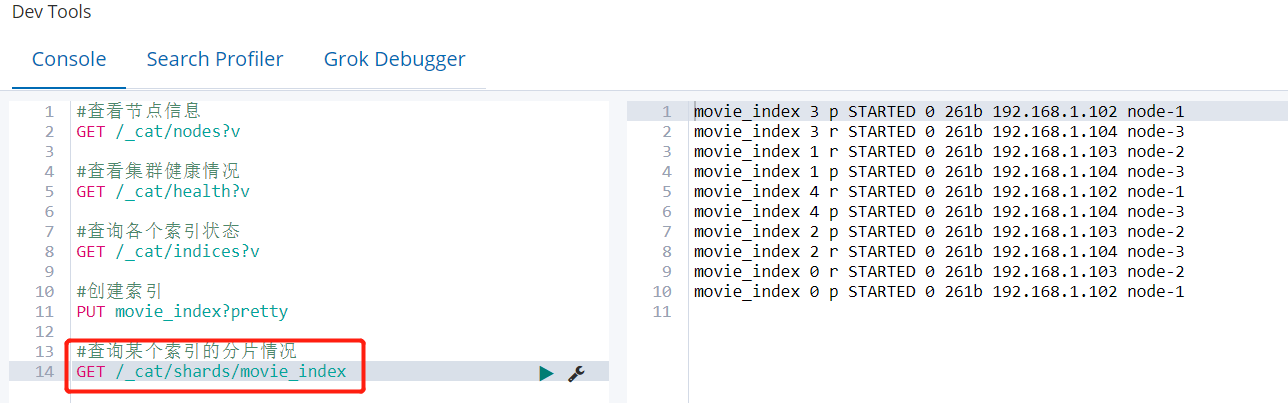
默认5个分片,1个副本。所以看到一共有10个分片,5个主,每一个主分片对应一个副本,注意:同一个分片的主和副本肯定不在同一个节点上
删除索引 API: DELETE /索引名
DELETE /movie_index
对文档进行操作
① 创建文档
文档通过其_index、_type、_id唯一确定。id不指定就会自动生成一个20位的_id;
现在向索引movie_index中放入文档,文档ID分别为1,2,3。 API: PUT /索引名/类型名/文档id
注意:文档id和文档中的属性”id”不是一回事;
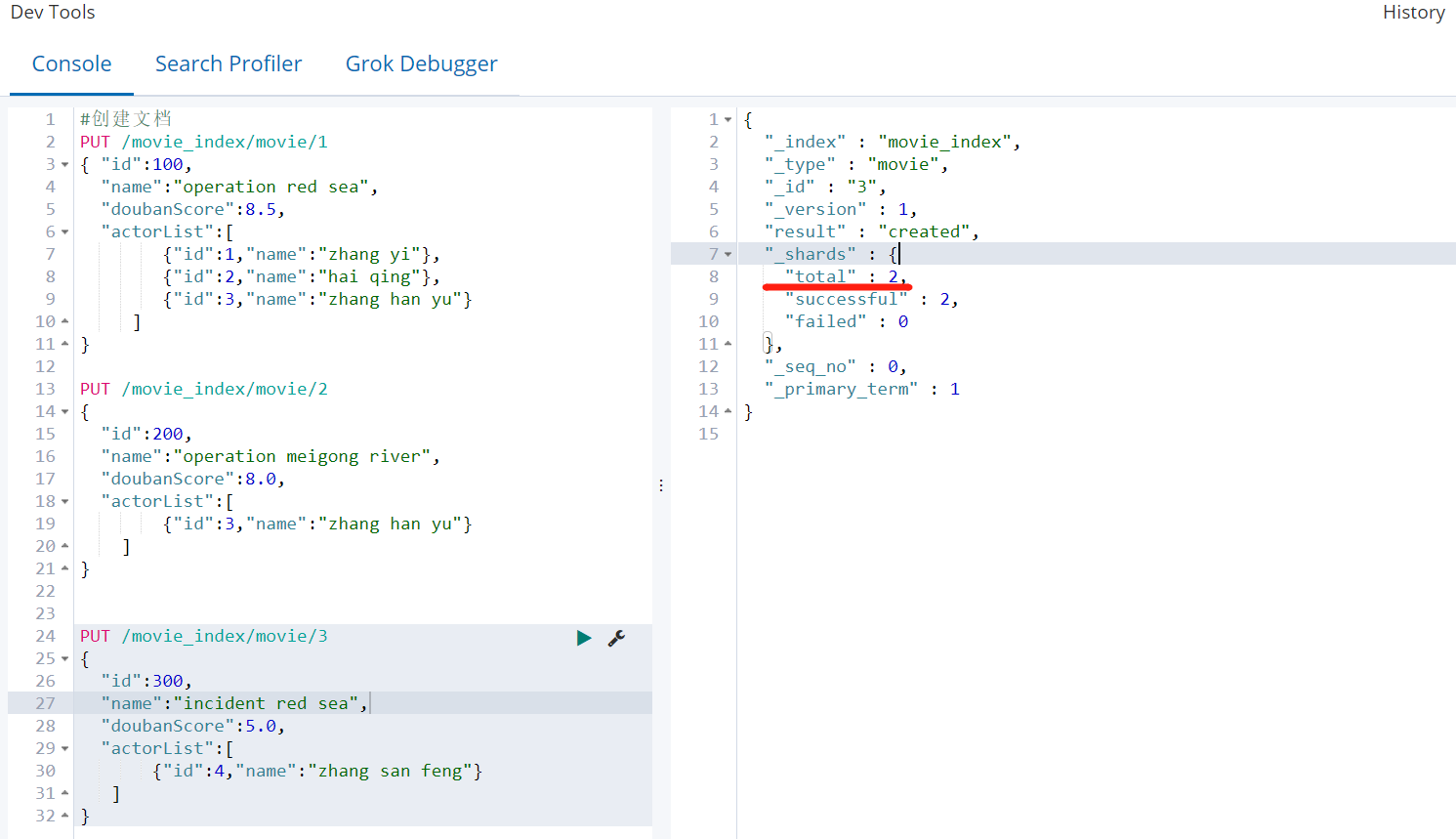
PUT /movie_index/movie/1
{ "id":100,
"name":"operation red sea",
"doubanScore":8.5,
"actorList":[
{"id":1,"name":"zhang yi"},
{"id":2,"name":"hai qing"},
{"id":3,"name":"zhang han yu"}
]
}
PUT /movie_index/movie/2
{
"id":200,
"name":"operation meigong river",
"doubanScore":8.0,
"actorList":[
{"id":3,"name":"zhang han yu"}
]
}
PUT /movie_index/movie/3
{
"id":300,
"name":"incident red sea",
"doubanScore":5.0,
"actorList":[
{"id":4,"name":"zhang san feng"}
]
}
注意,Elasticsearch并不要求,先要有索引,才能将文档编入索引。创建文档时,如果指定索引不存在,将自动创建。默认创建的索引分片是5,副本是1,我们创建的文档会在其中的某一个分片上存一份,副本
上存一份,所以看到的响应 _shards-total:2 。
如果Put时,这个文档ID已经存在了,会保错,通过版本号_version判断是否冲突。
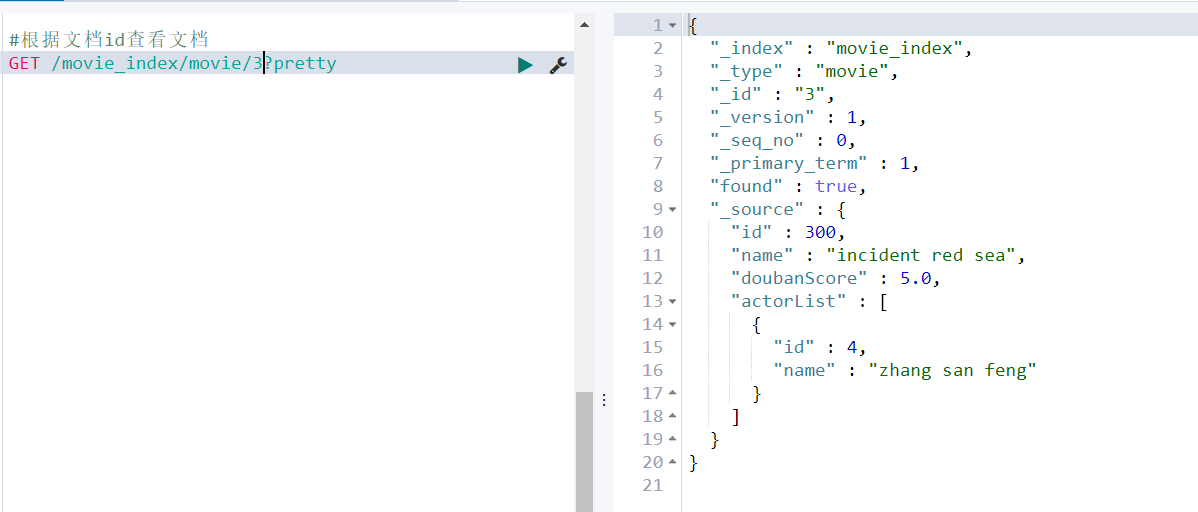
② 根据文档id查看文档
API:GET /索引名/类型名/文档id GET /movie_index/movie/1?pretty
这里有一个字段found为真,表示找到了一个ID为3 的文档,另一个字段_source,该字段返回完整JSON文档。
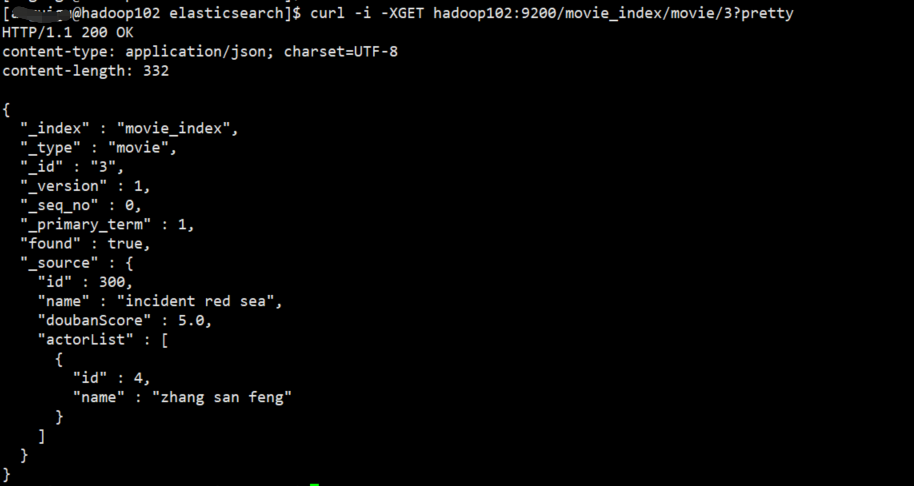
# 通过HTTP请求的方式:
[kris@hadoop102 elasticsearch]$ curl -i -XGET hadoop102:9200/movie_index/movie/3?pretty
pretty 格式化
在任意的查询字符串中增加 pretty参数,类似于上面的例子。会让Elasticsearch美化输出(pretty-print)JSON响应以便更加容易阅读。_source字段不会被美化,它的样子与我们输入的一致。
GET请求返回的响应内容包括 {"found": true}。这意味着文档已经找到。如果我们请求一个不存在的文档,依旧会得到一个JSON,不过found值变成了false。
此外,HTTP响应状态码也会变成'404 Not Found'代替'200 OK'。我们可以在curl 后加 -i 参数得到响应头
检索文档的一部分
GET /movie_index/movie/3?_source=id,doubanScore
_source字段现在只包含我们请求的字段,而且过滤了date字段;
③ 查询所有文档
API:GET /索引名/_search, Kinana中默认显示10条,可以通过size控制

took: 执行查询花费的时间毫秒数
_shards=>total:搜索了多少个分片(当前表示搜索了全部5个分片)
④ 根据文档id删除文档
API: DELETE /索引名/类型名/文档id DELETE /movie_index/movie/3
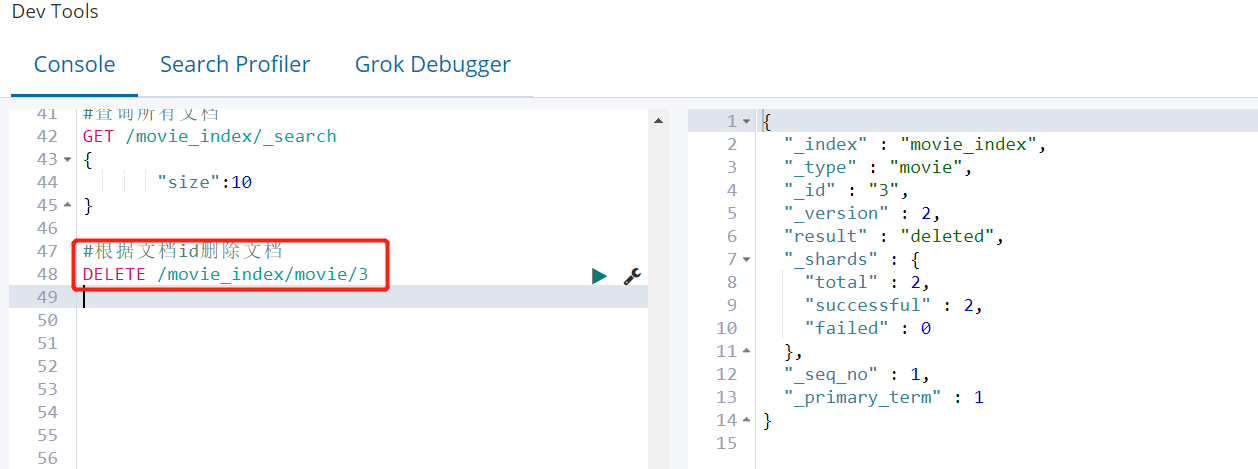
注意:删除索引和删除文档的区别
- 删除索引是会立即释放空间的,不存在所谓的“标记”逻辑。
- 删除文档的时候,是将新文档写入,同时将旧文档标记为已删除。 磁盘空间是否释放取决于新旧文档是否在同一个segment file里面,因此ES后台的segment merge在合并segment file的过程中有可能触发旧文档的物理删除。
- 也可以手动执行POST /_forcemerge进行合并触发
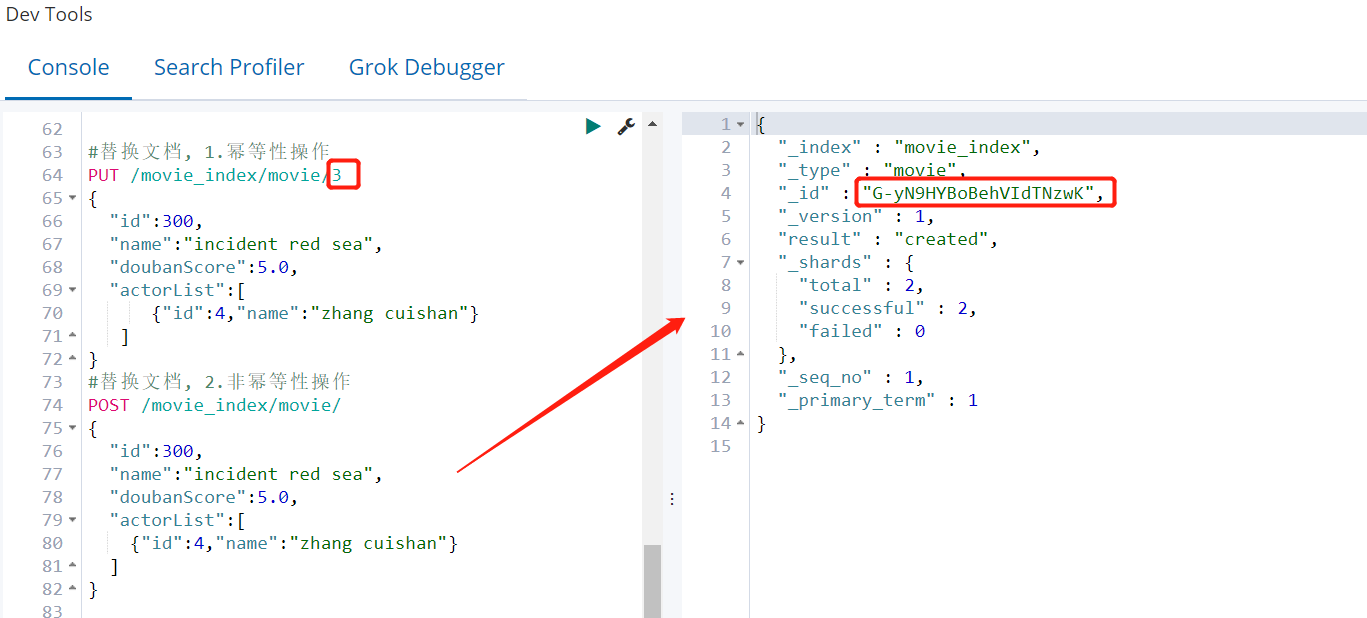
⑤ 替换文档
- PUT(幂等性操作)
当我们通过执行PUT /索引名/类型名/文档id命令的添加时候,如果文档id已经存在,那么再次执行上面的命令,ElasticSearch将替换现有文档。
PUT /movie_index/movie/3
{
"id":300,
"name":"incident red sea",
"doubanScore":5.0,
"actorList":[
{"id":4,"name":"zhang cuishan"}
]
}
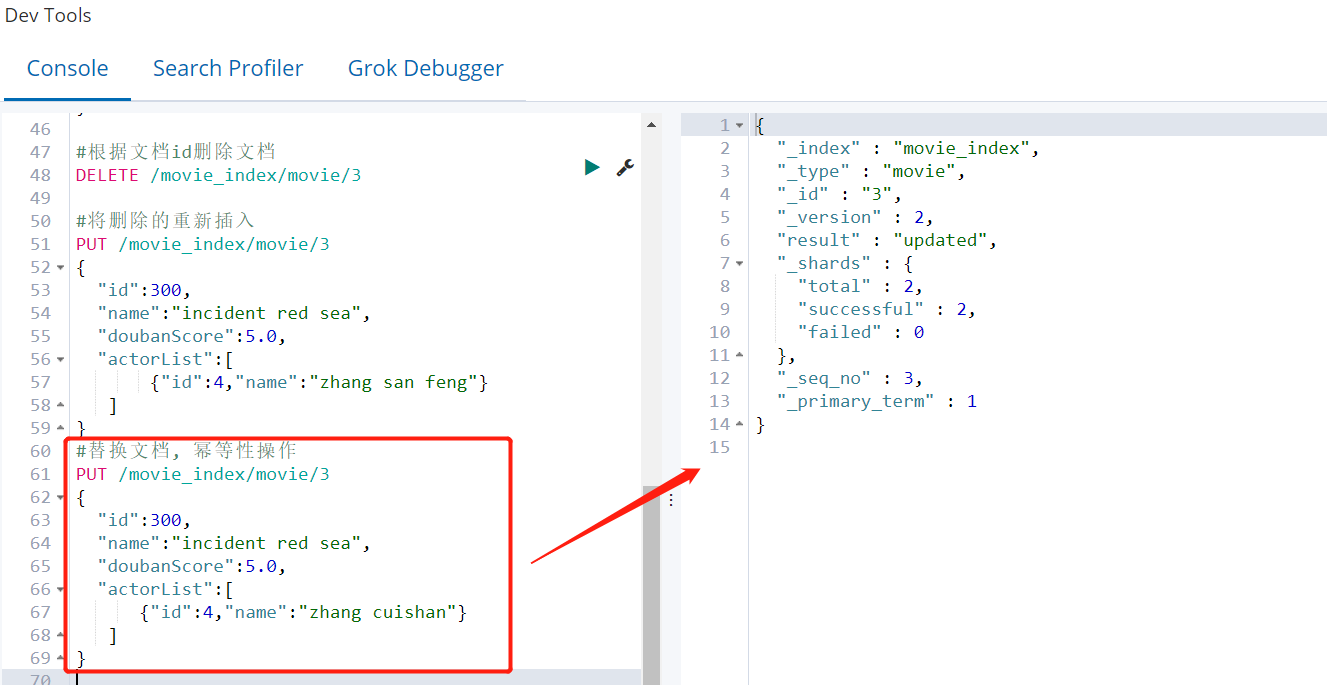
文档 id3 已经存在,会替换原来的文档内容
- POST(非幂等性操作)
创建文档时,ID部分是可选的。如果没有指定,Elasticsearch将生成一个随机ID,然后使用它来引用文档。
POST /movie_index/movie/
{
"id":300,
"name":"incident red sea",
"doubanScore":5.0,
"actorList":[
{"id":4,"name":"zhang cuishan"}
]
}
⑥ 根据文档id更新文档
除了创建和替换文档外,ES还可以更新文档中的某一个字段内容。注意,Elasticsearch实际上并没有在底层执行就地更新,而是先删除旧文档,再添加新文档。
更新即直接修改值去PUT,version会发生变化;在响应中,我们可以看到Elasticsearch把_version增加
API:
POST /索引名/类型名/文档id/_update?pretty
{
"doc": { "字段名": "新的字段值" } doc固定写法
}
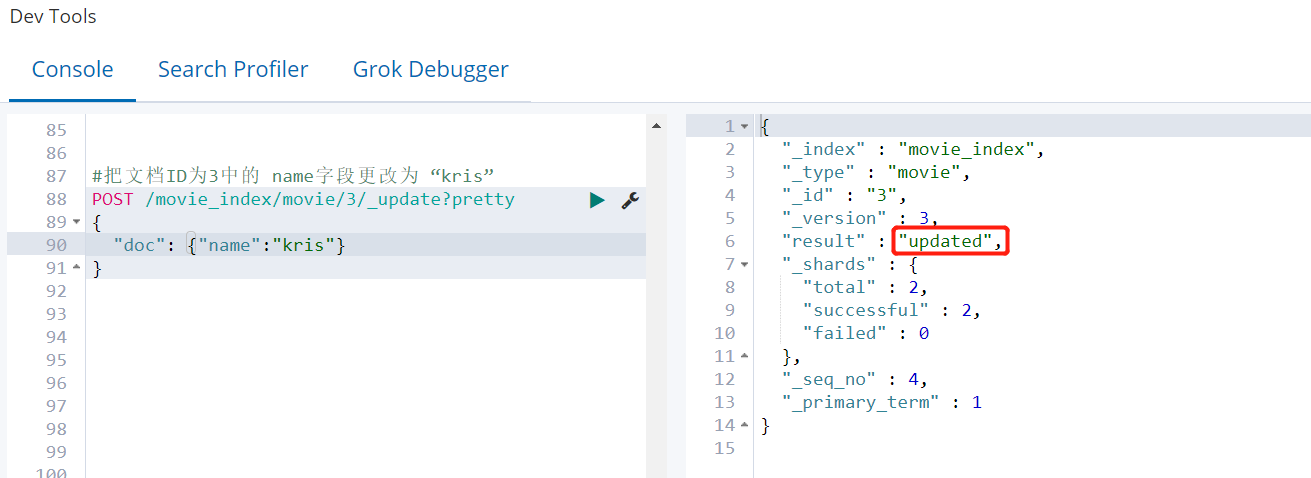
需求:把文档ID为3中的 name字段更改为 “kris”
POST /movie_index/movie/3/_update?pretty
{
"doc": {"name":"kris"}
}
##可以看到 _version 版本号增加
更新操作小案例


PUT /website/blog/1 { "title": "blog", "text": "I am starting to get the hang of this...", "date": "2021/01/02" } GET /website/blog/1 ## 局部更新 POST /website/blog/1/_update { "doc" : { "title" : "--My blog--", "date": "2018/08/25" } }
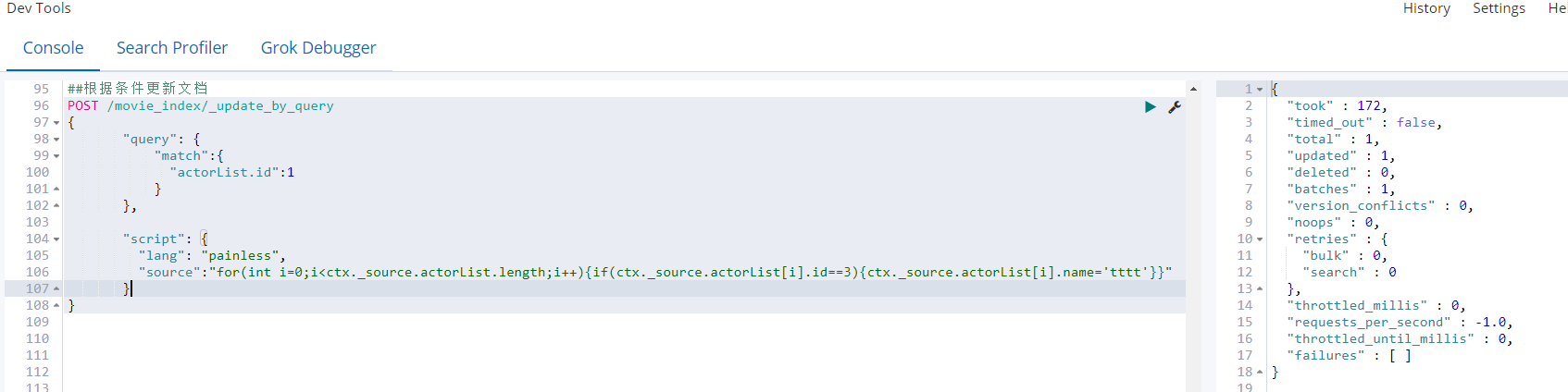
⑦ 根据条件更新文档(了解)
##根据条件更新文档
POST /movie_index/_update_by_query
{
"query": {
"match":{
"actorList.id":1
}
},
"script": {
"lang": "painless",
"source":"for(int i=0;i<ctx._source.actorList.length;i++){if(ctx._source.actorList[i].id==3){ctx._source.actorList[i].name='tttt'}}"
}
}
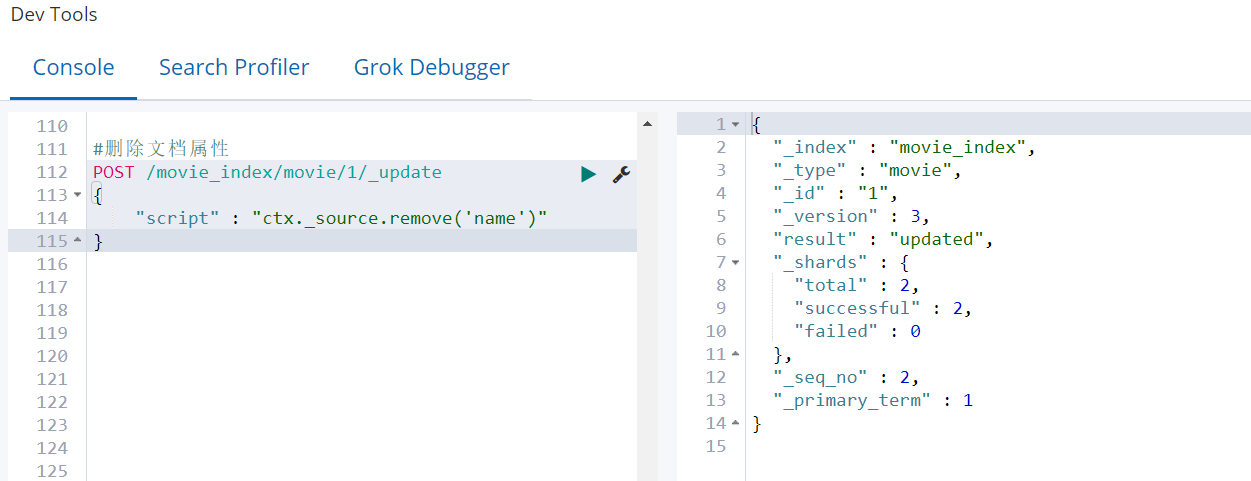
⑧ 删除文档属性(了解)
POST /movie_index/movie/1/_update
{
"script" : "ctx._source.remove('name')"
}
⑨ 根据条件删除文档(了解)
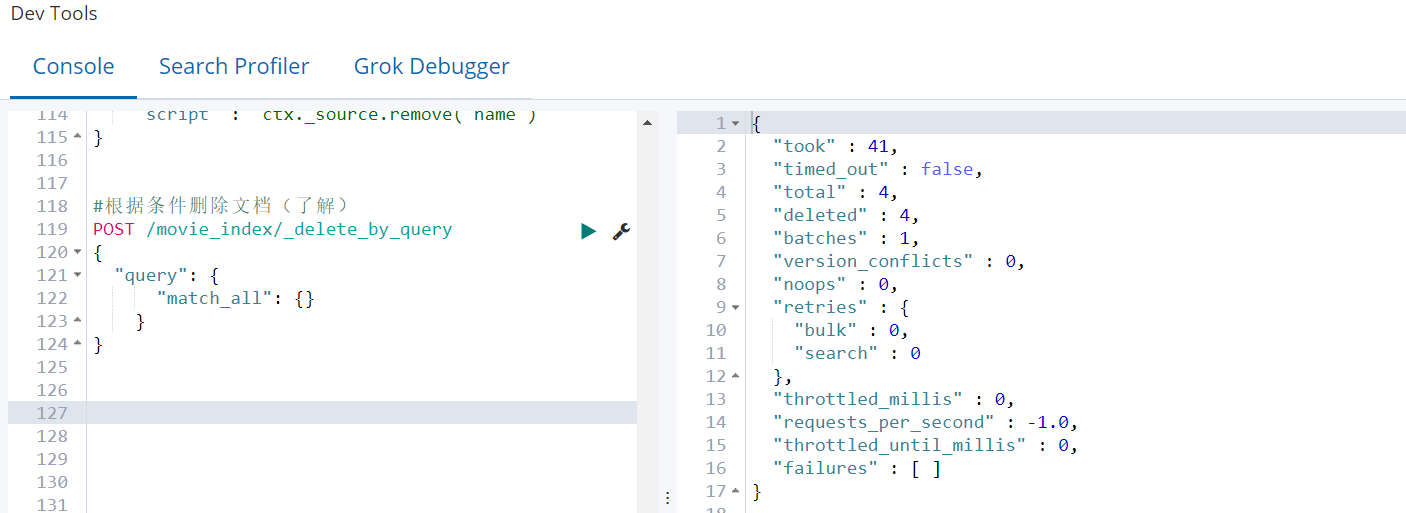
POST /movie_index/_delete_by_query
{
"query": {
"match_all": {}
}
}
批处理
批量插入(从mysql中) | (每个json中不能有换行),先建立索引+doc,使用_bulk
除了对单个文档执行创建、更新和删除之外,ElasticSearch还提供了使用 _bulk API 批量执行上述操作的能力。
API: POST /索引名/类型名/_bulk?pretty
_bulk表示批量操作
注意:Kibana要求批量操作的json内容写在同一行
需求1:在索引中批量创建两个文档
POST /movie_index/movie/_bulk
{"index":{"_id":66}}
{"id":300,"name":"incident red sea","doubanScore":5.0,"actorList":[{"id":4,"name":"kris"}]}
{"index":{"_id":88}}
{"id":300,"name":"incident red sea","doubanScore":5.0,"actorList":[{"id":4,"name":"kris"}]}

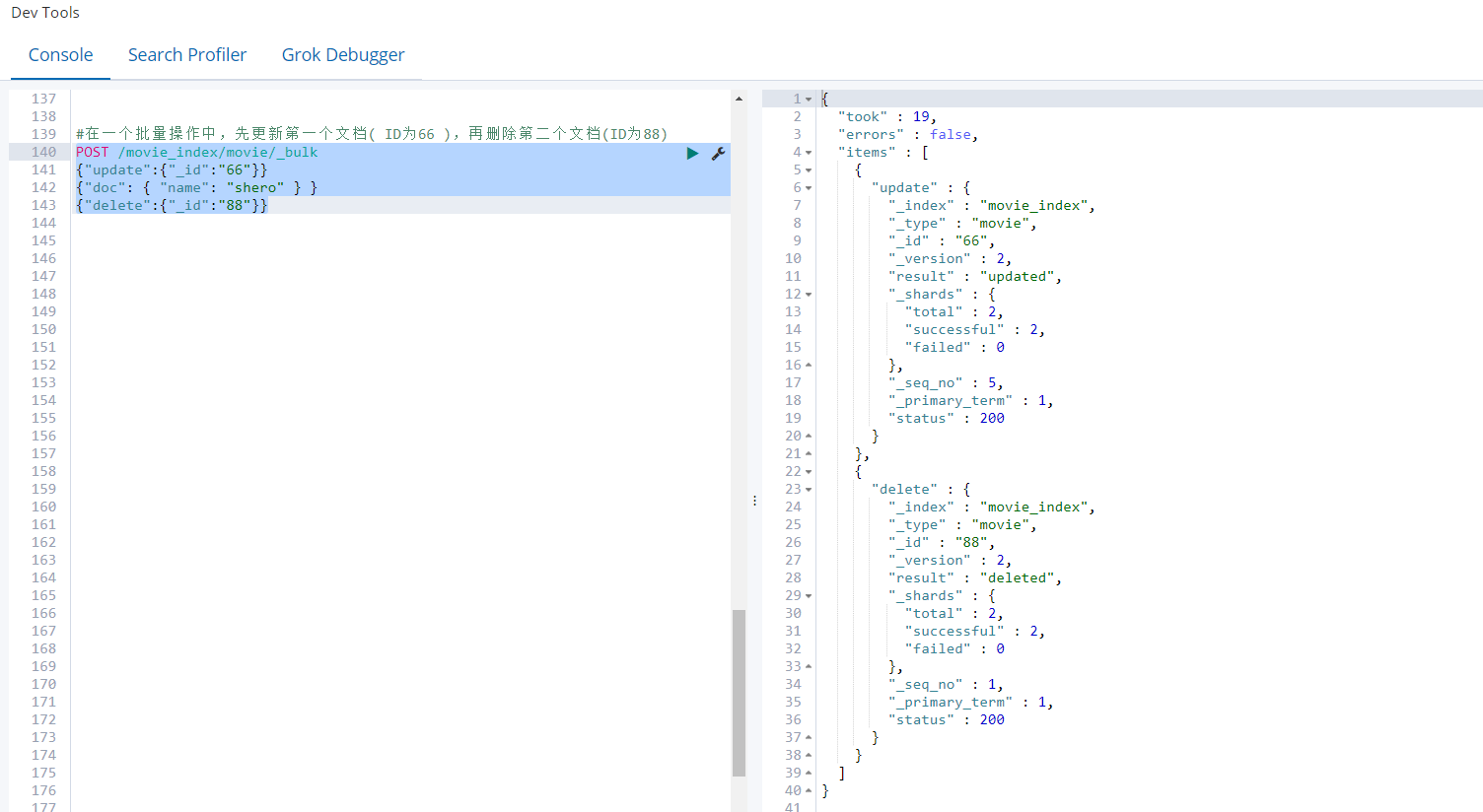
需求2:在一个批量操作中,先更新第一个文档( ID为66 ),再删除第二个文档(ID为88)
POST /movie_index/movie/_bulk
{"update":{"_id":"66"}}
{"doc": { "name": "shero" } }
{"delete":{"_id":"88"}}
查询操作
搜索参数传递有2种方法
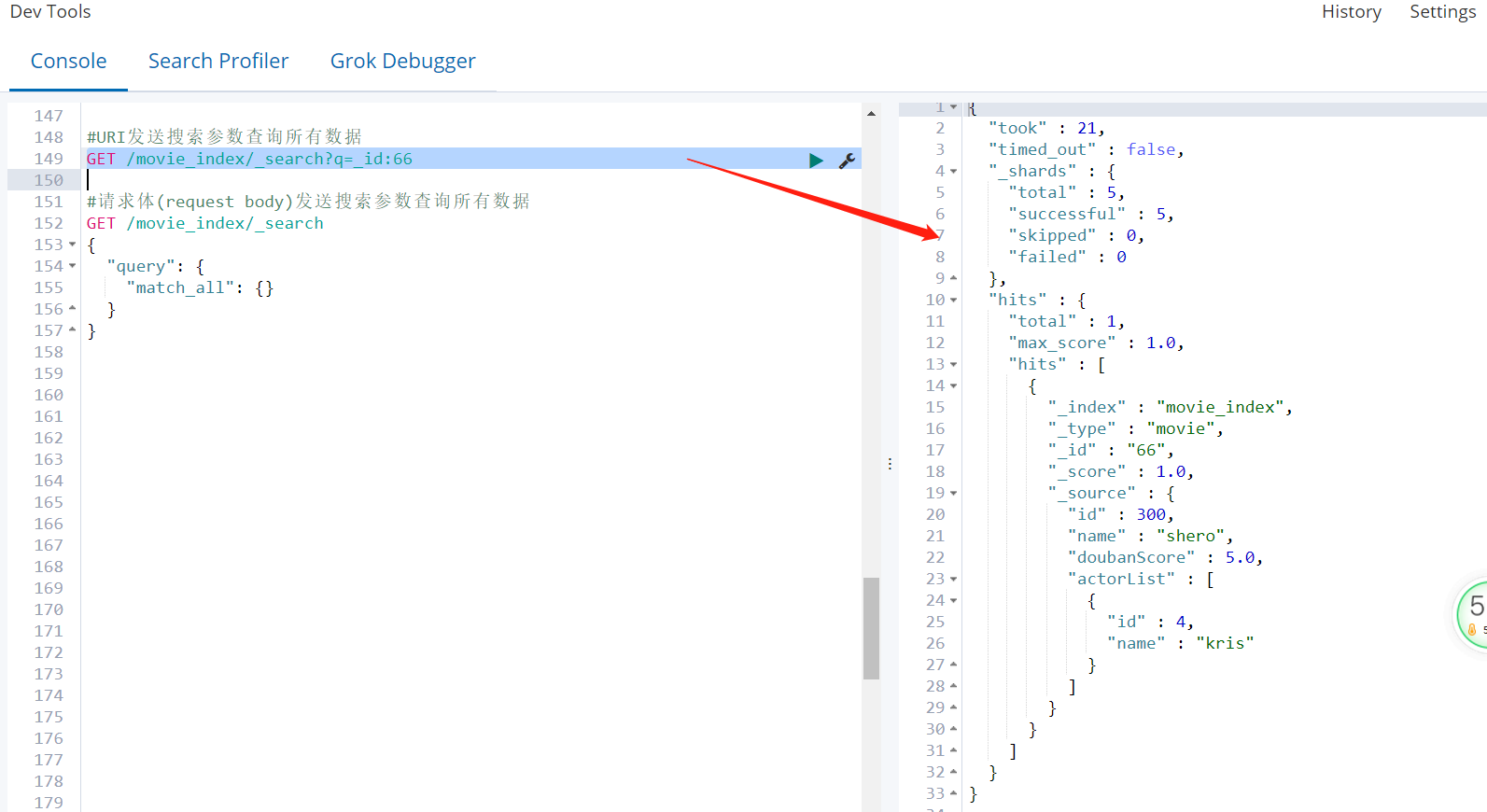
- URI发送搜索参数查询所有数据
GET /索引名/_search?q=* &pretty 例如:GET /movie_index/_search?q=_id:66
这种方式不太适合复杂查询场景,了解 https://www.elastic.co/guide/en/elasticsearch/reference/current/search-search.html
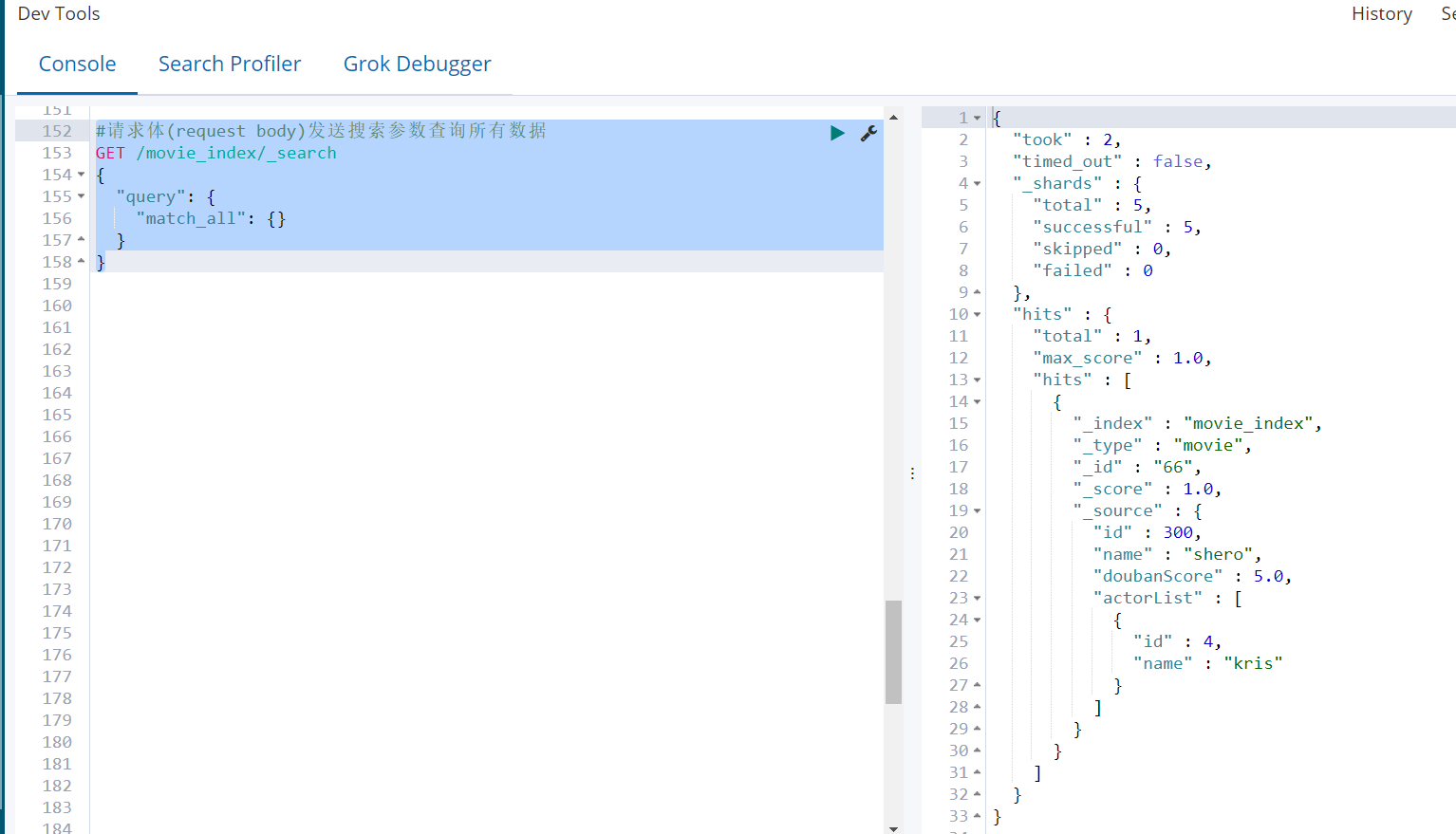
- 请求体(request body)发送搜索参数查询所有数据
GET /movie_index/_search
{
"query": {
"match_all": {}
}
}
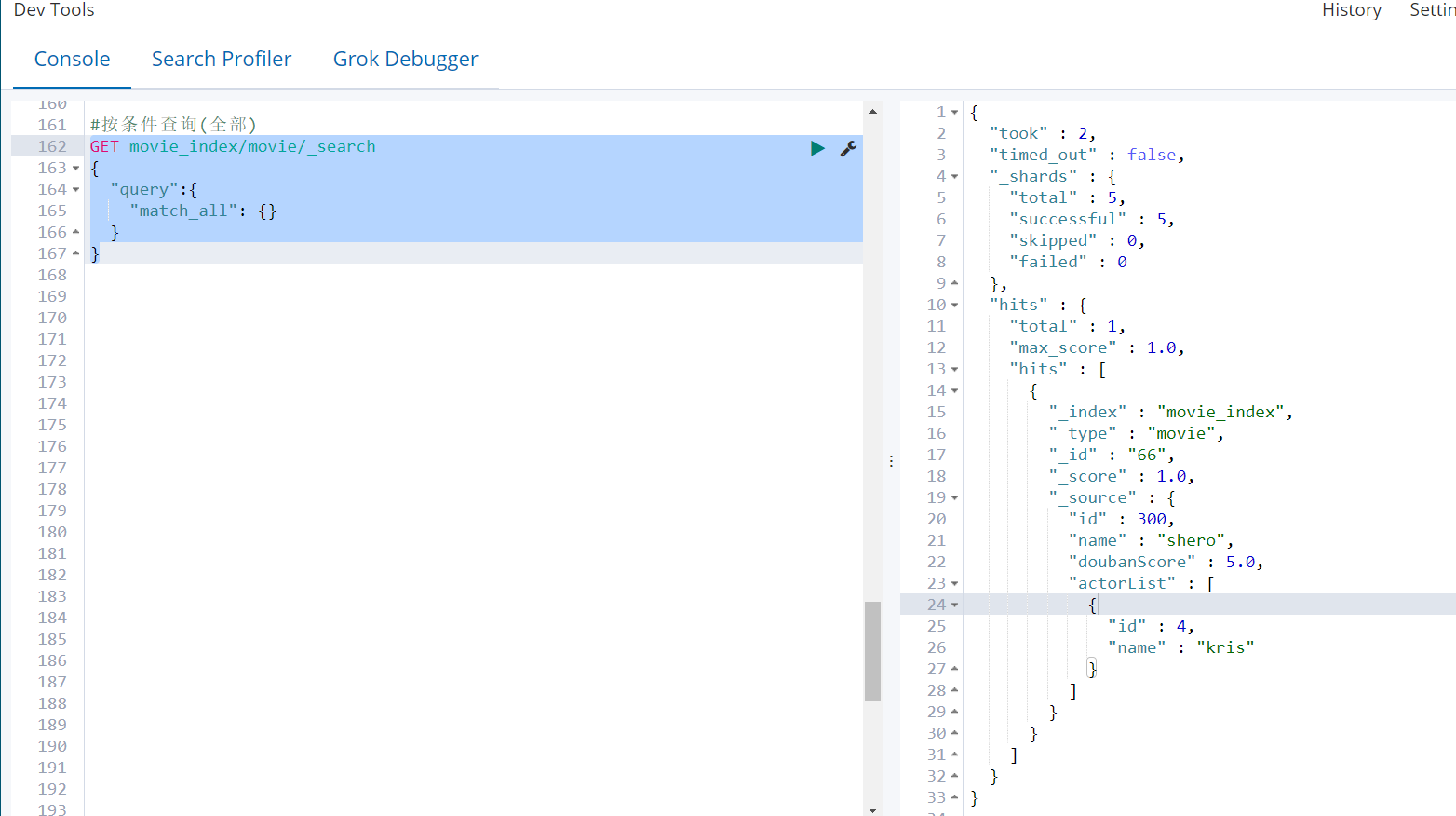
按条件查询(全部)
GET movie_index/movie/_search
{
"query":{
"match_all": {}
}
}
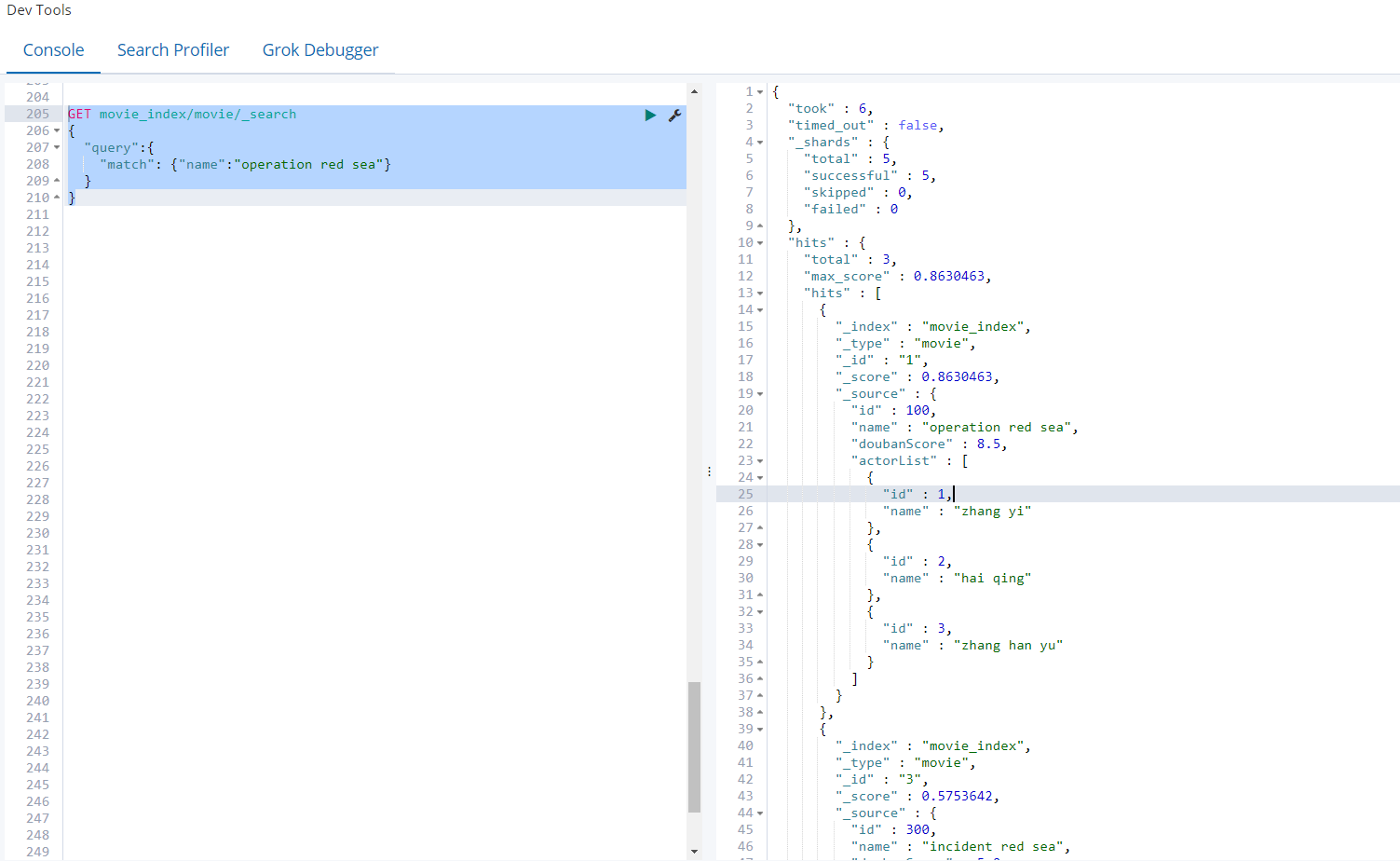
按分词查询(必须使用分词text类型)
测试前:将movie_index索引中的数据恢复到初始的3条
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 0.8630463,
"hits" : [
{
"_index" : "movie_index",
"_type" : "movie",
"_id" : "1",
"_score" : 0.8630463,
"_source" : {
"id" : 100,
"name" : "operation red sea",
"doubanScore" : 8.5,
"actorList" : [
{
"id" : 1,
"name" : "zhang yi"
},
{
"id" : 2,
"name" : "hai qing"
},
{
"id" : 3,
"name" : "zhang han yu"
}
]
}
},
{
"_index" : "movie_index",
"_type" : "movie",
"_id" : "3",
"_score" : 0.5753642,
"_source" : {
"id" : 300,
"name" : "incident red sea",
"doubanScore" : 5.0,
"actorList" : [
{
"id" : 4,
"name" : "zhang san feng"
}
]
}
},
{
"_index" : "movie_index",
"_type" : "movie",
"_id" : "2",
"_score" : 0.2876821,
"_source" : {
"id" : 200,
"name" : "operation meigong river",
"doubanScore" : 8.0,
"actorList" : [
{
"id" : 3,
"name" : "zhang han yu"
}
]
}
}
]
}
}
ES中,name属性会进行分词,底层以倒排索引的形式进行存储,对查询的内容也会进行分词,然后和文档的name属性内容进行匹配,所以命中3次,不过命中的分值不同。
注意:ES底层在保存字符串数据的时候,会有两种类型text和keyword
text:分词
keyword:不分词
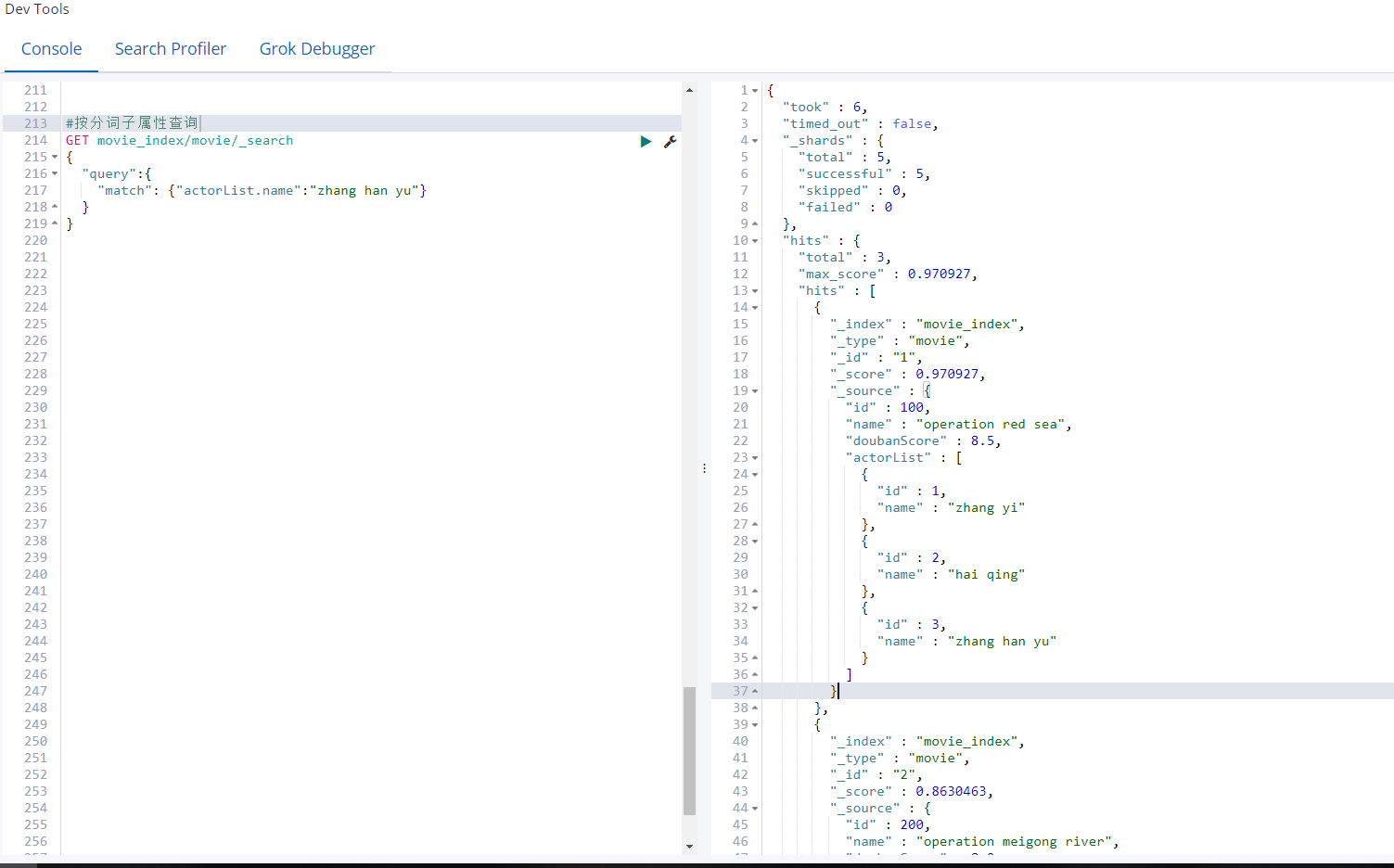
按分词子属性查询
GET movie_index/movie/_search
{
"query":{
"match": {"actorList.name":"zhang han yu"}
}
}
返回3 条结果。
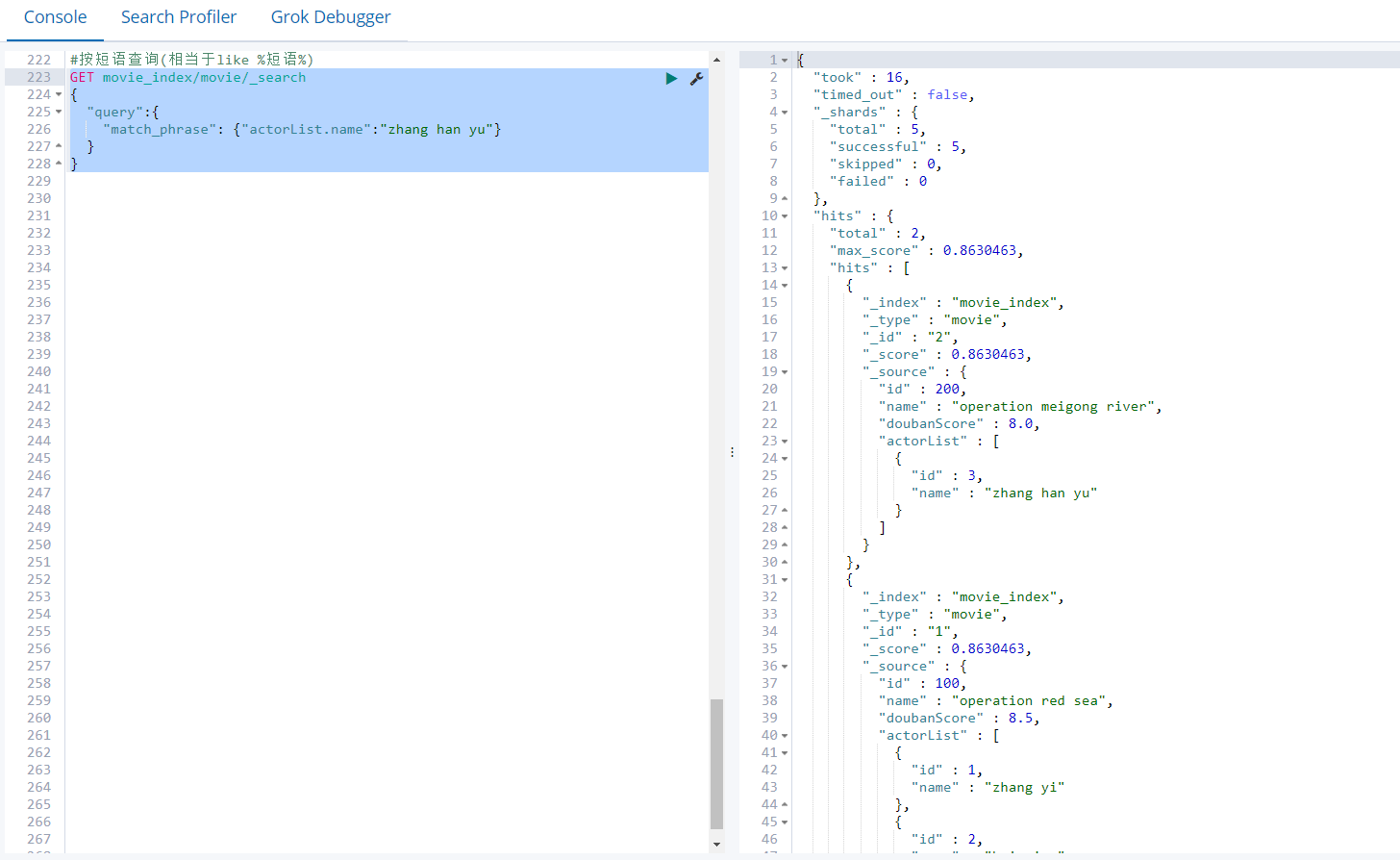
按短语查询(相当于like %短语%)
按短语查询,不再利用分词技术,直接用短语在原始数据中匹配
GET movie_index/movie/_search { "query":{ "match_phrase": {"actorList.name":"zhang han yu"} } }
返回2条结果,把演员名包含zhang han yu的查询出来
通过term精准搜索匹配(必须使用keyword类型)
GET movie_index/movie/_search { "query":{ "term":{ "actorList.name.keyword":"zhang han yu" } } }
返回2条结果,把演员中完全匹配zhang han yu的查询出来
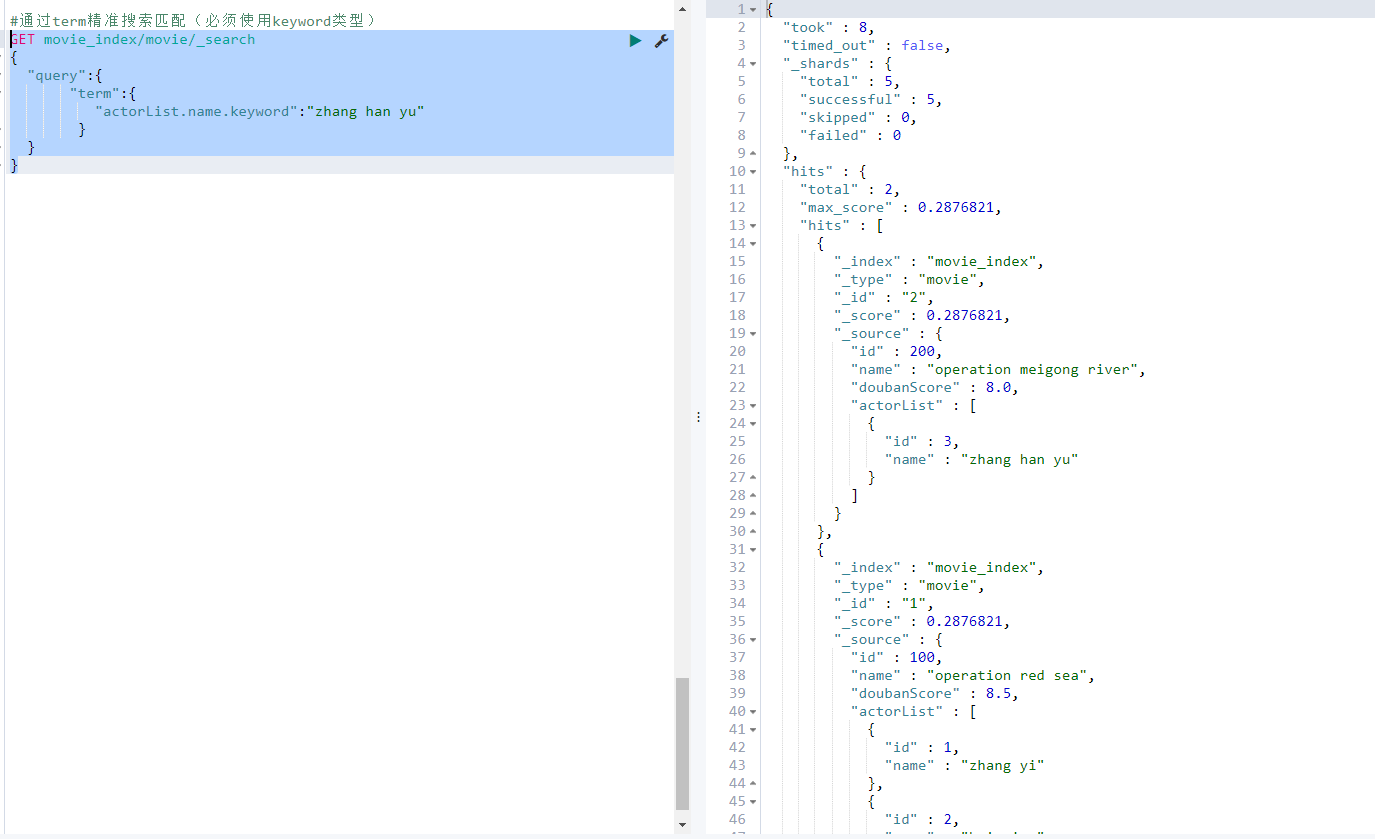
fuzzy查询(容错匹配)
校正匹配分词,当一个单词都无法准确匹配,ES通过一种算法对非常接近的单词也给与一定的评分,能够查询出来,但是消耗更多的性能,对中文来讲,实现不是特别好。
GET movie_index/movie/_search { "query":{ "fuzzy": {"name":"rad"} } }
返回2个结果,会把 incident red sea 和 operation red sea 匹配上
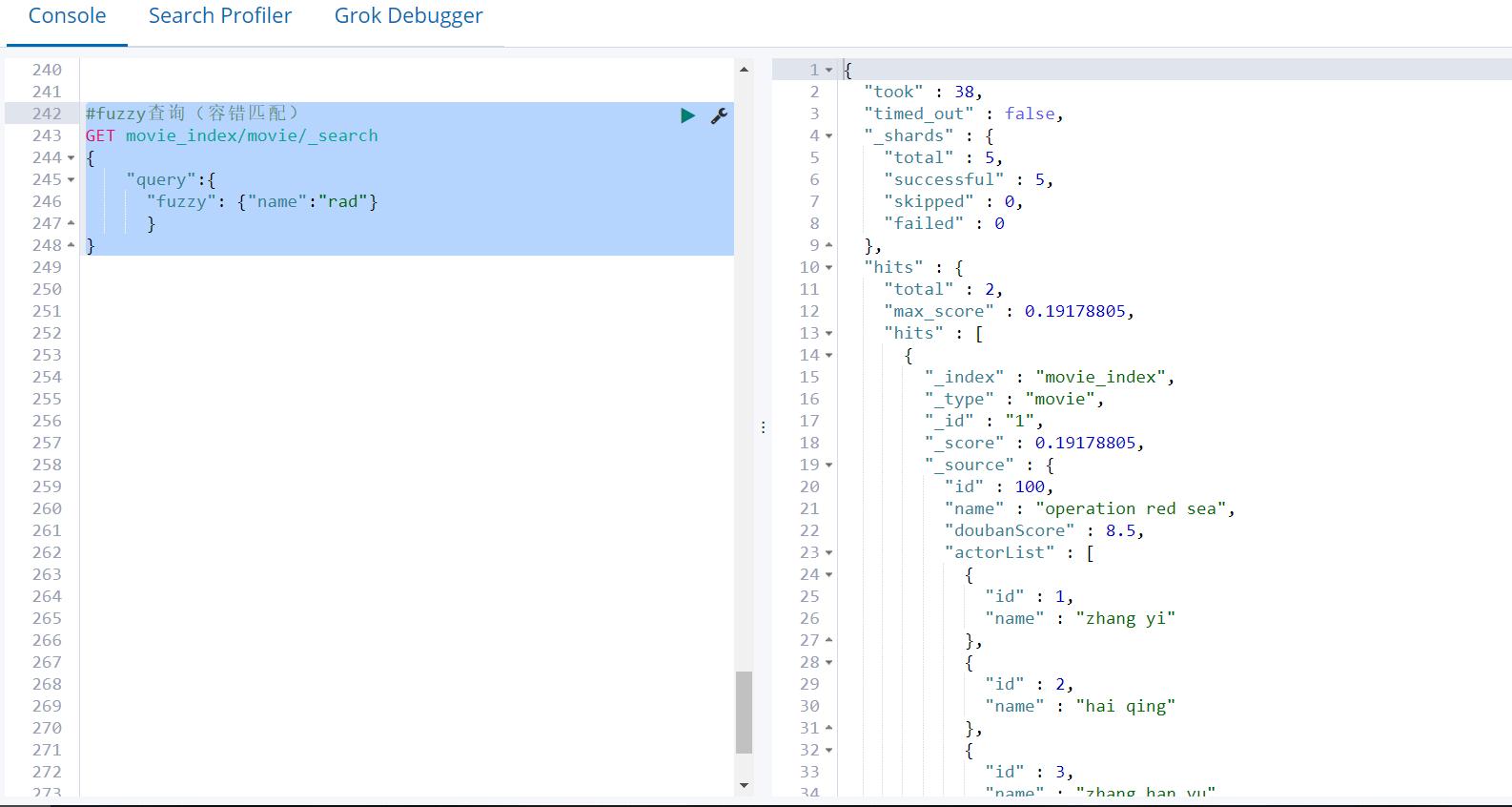
过滤—先匹配,再过滤
GET movie_index/movie/_search { "query":{ "match": {"name":"red"} }, "post_filter":{ "term": { "actorList.id": 3 } } }
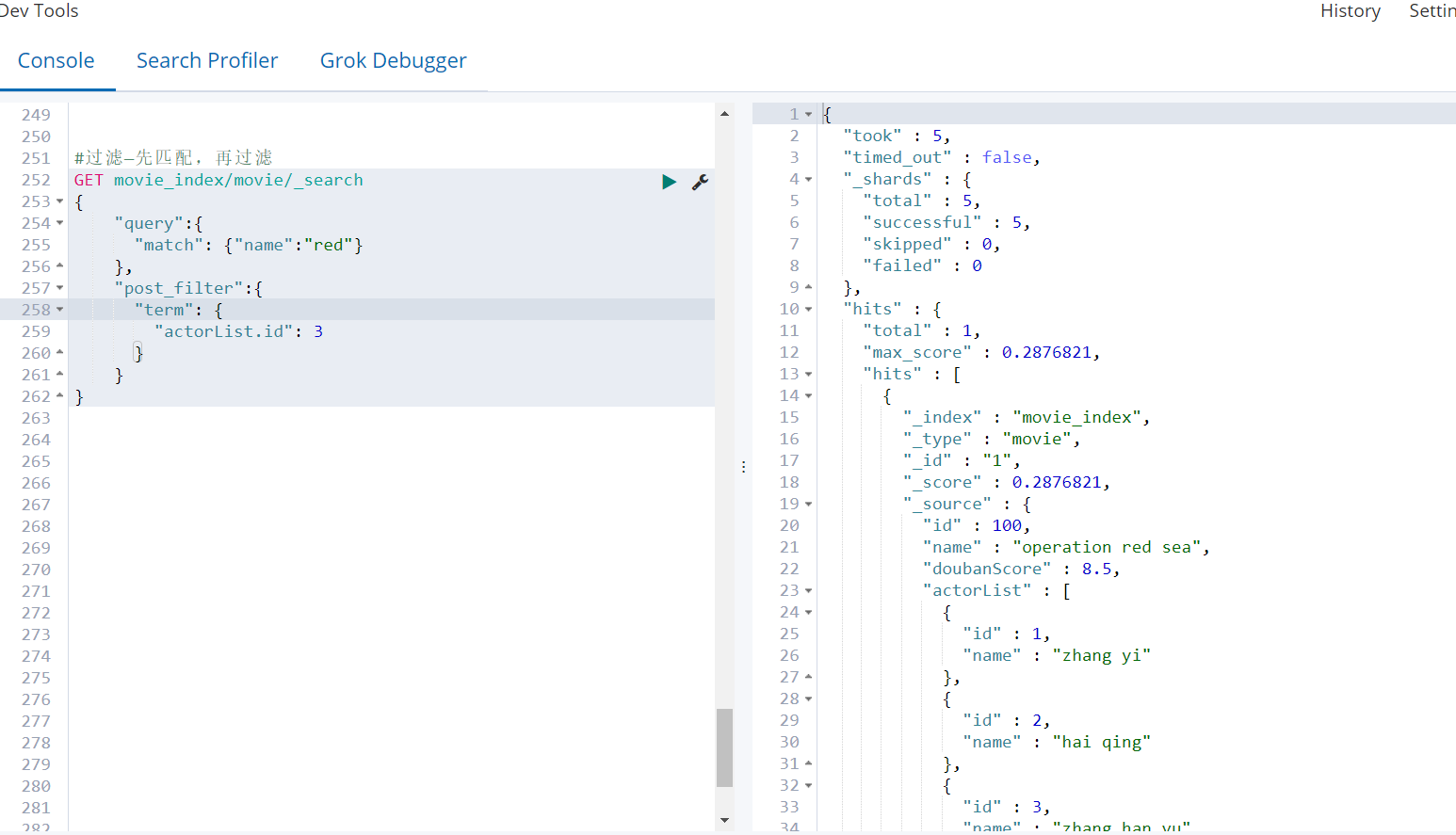
过滤—匹配和过滤同时(推荐使用)
GET movie_index/movie/_search
{
"query": {
"bool": {
"must": [
{"match": {
"name": "red"
}}
],
"filter": [
{"term": { "actorList.id": "1"}},
{"term": {"actorList.id": "3"}}
]
}
}
}
过滤--按范围过滤
GET movie_index/movie/_search
{
"query": {
"range": {
"doubanScore": {
"gte": 6,
"lte": 8.5
}
}
}
}
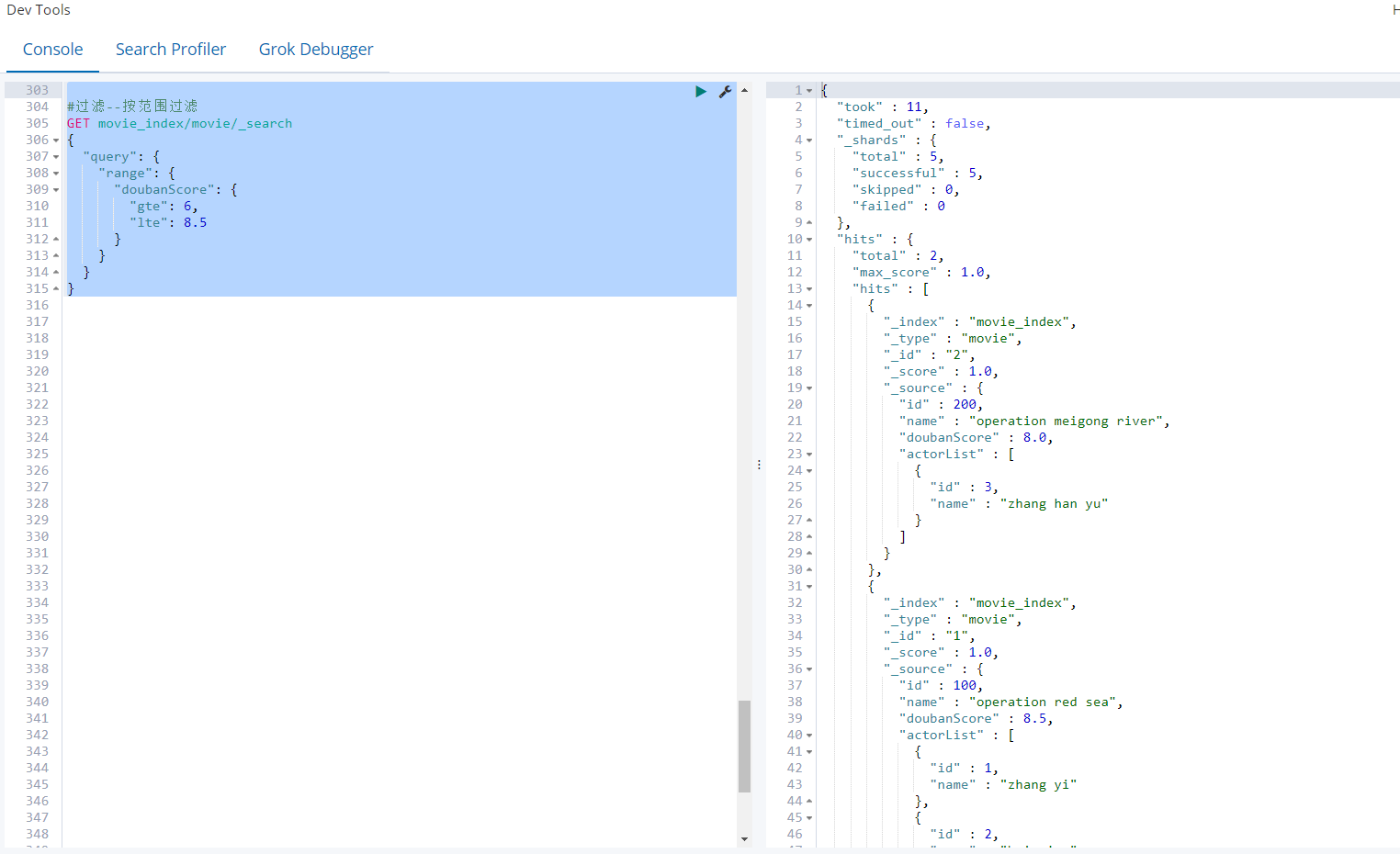
关于范围操作符
|
gt |
大于 |
|
lt |
小于 |
|
gte |
大于等于 great than or equals |
|
lte |
小于等于 less than or equals |
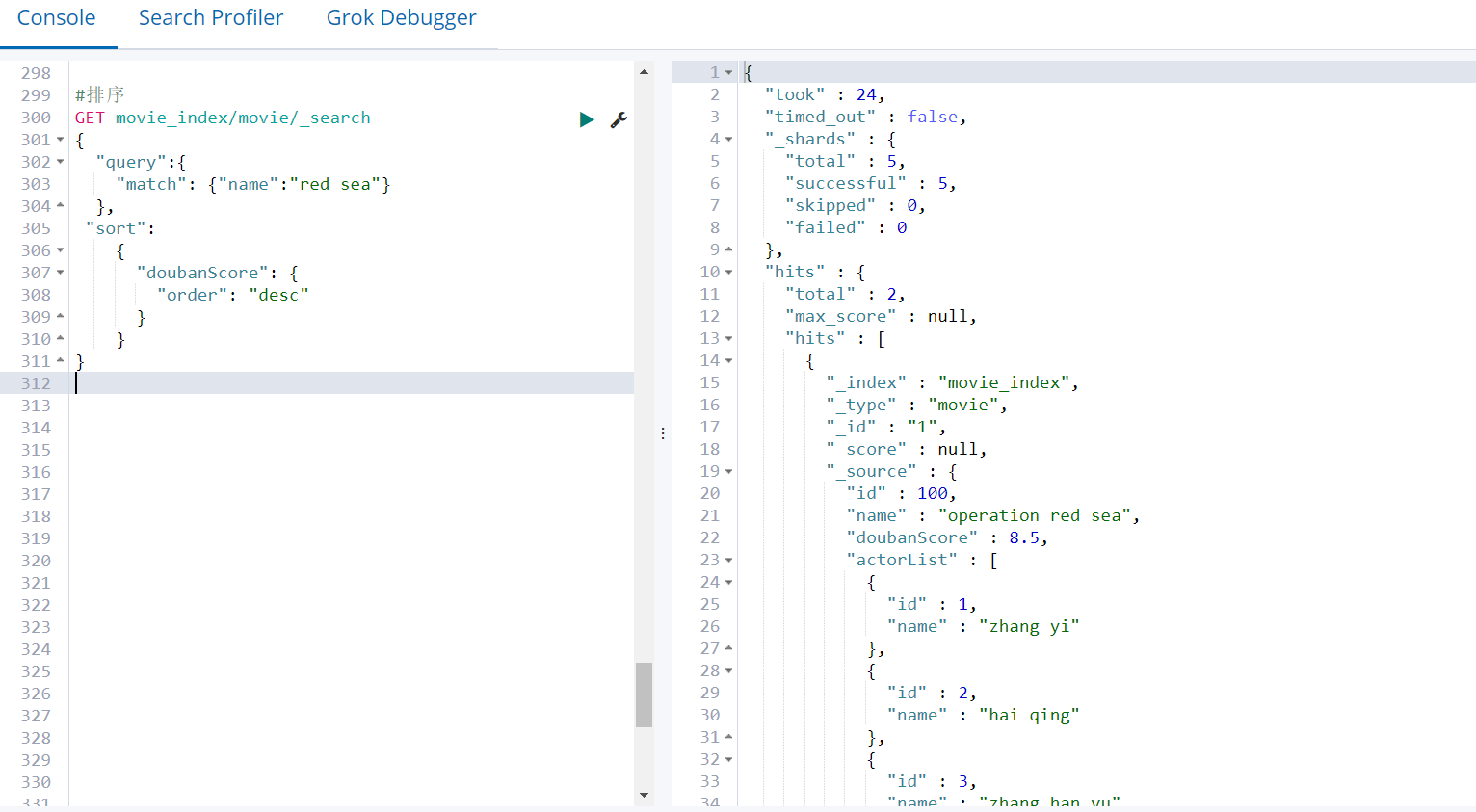
排序
GET movie_index/movie/_search
{
"query":{
"match": {"name":"red sea"}
},
"sort":
{
"doubanScore": {
"order": "desc"
}
}
}
分页查询
from参数(基于0)指定从哪个文档序号开始,size参数指定返回多少个文档,这两个参数对于搜索结果分页非常有用。注意,如果没有指定from,则默认值为0。
GET movie_index/movie/_search
{
"query": { "match_all": {} },
"from": 1,
"size": 1
}
指定查询的字段
GET movie_index/movie/_search
{
"query": { "match_all": {} },
"_source": ["name", "doubanScore"]
}
只显示name 和doubanScore 字段
高亮
对命中的词进行高亮显示
GET movie_index/movie/_search
{
"query":{
"match": {"name":"red sea"}
},
"highlight": {
"fields": {"name":{} }
}
}
聚合
聚合提供了对数据进行分组、统计的能力,类似于SQL中Group By和SQL聚合函数。在ElasticSearch中,可以同时返回搜索结果及其聚合计算结果,这是非常强大和高效的。
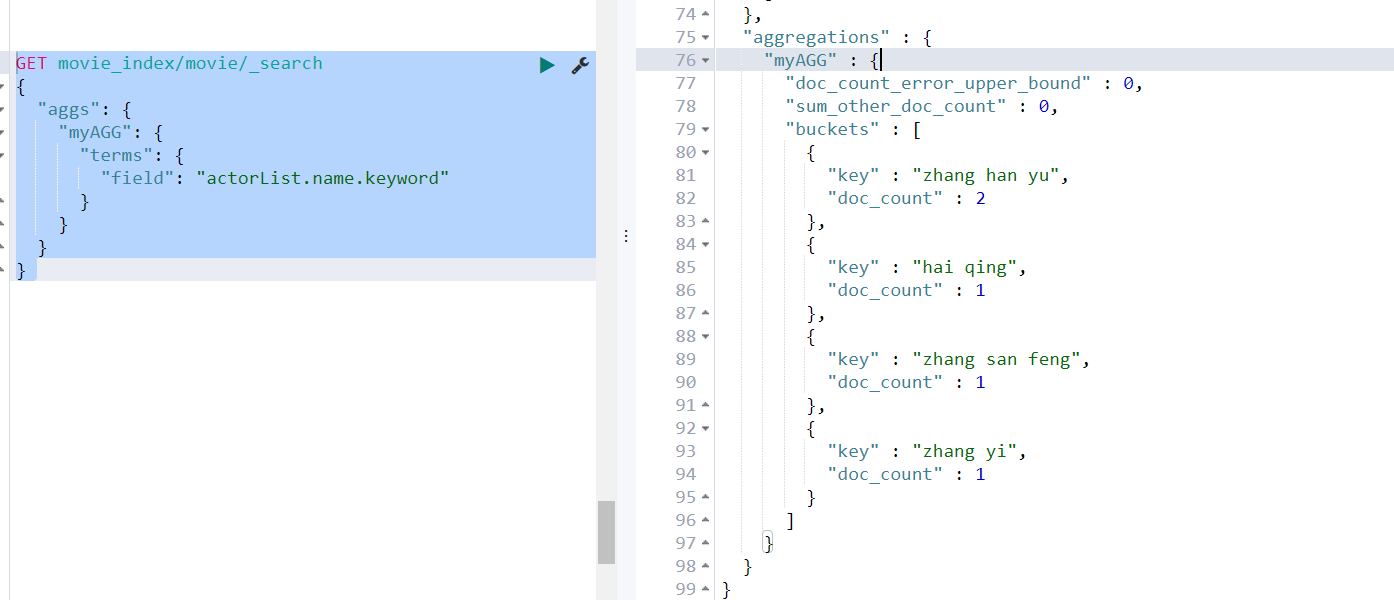
需求1:取出每个演员共参演了多少部电影
GET movie_index/movie/_search { "aggs": { "myAGG": { "terms": { "field": "actorList.name.keyword" } } } }
- aggs:表示聚合
- myAGG:给聚合取的名字,
- trems:表示分组,相当于groupBy
- field:指定分组字段
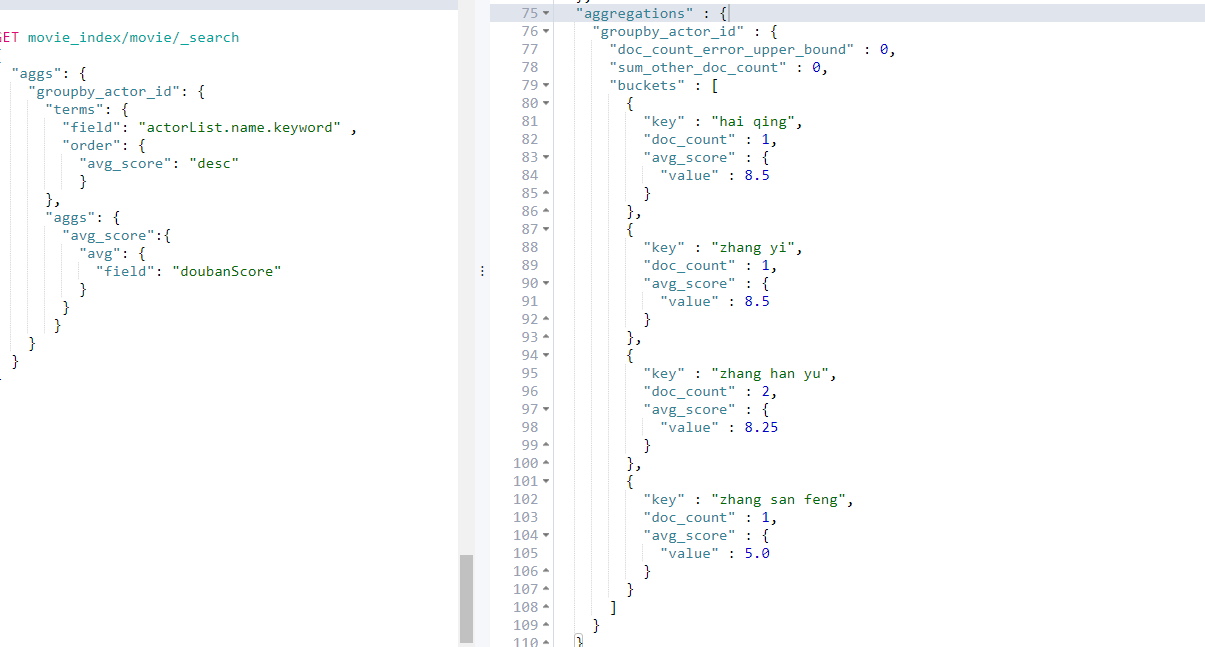
需求2:每个演员参演电影的平均分是多少,并按评分排序
GET movie_index/movie/_search
{
"aggs": {
"groupby_actor_id": {
"terms": {
"field": "actorList.name.keyword" ,
"order": {
"avg_score": "desc"
}
},
"aggs": {
"avg_score":{
"avg": {
"field": "doubanScore"
}
}
}
}
}
}
思考:聚合时为何要加 .keyword后缀?
.keyword 是某个字符串字段,专门储存不分词格式的副本,在某些场景中只允许只用不分词的格式,比如过滤filter比如聚合aggs, 所以字段要加上.keyword的后缀。
关于mapping
PUT /movie_chn_1/movie/1
{ "id":1,
"name":"红海行动",
"doubanScore":8.5,
"actorList":[
{"id":1,"name":"张译"},
{"id":2,"name":"海清"},
{"id":3,"name":"张涵予"}
]
}
PUT /movie_chn_1/movie/2
{
"id":2,
"name":"湄公河行动",
"doubanScore":8.0,
"actorList":[
{"id":3,"name":"张涵予"}
]
}
PUT /movie_chn_1/movie/3
{
"id":3,
"name":"红海事件",
"doubanScore":5.0,
"actorList":[
{"id":4,"name":"张三丰"}
]
}
- 查看自动定义的mapping
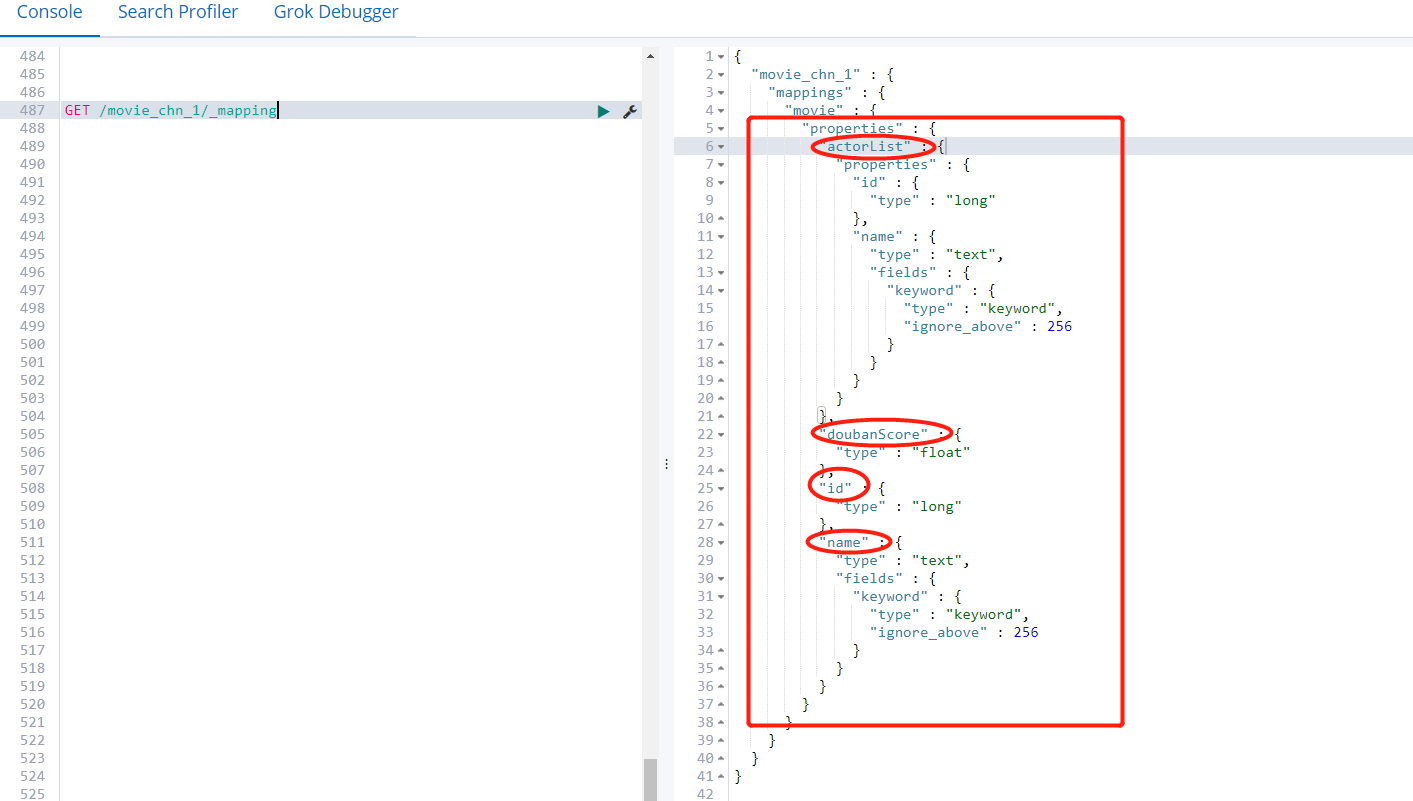
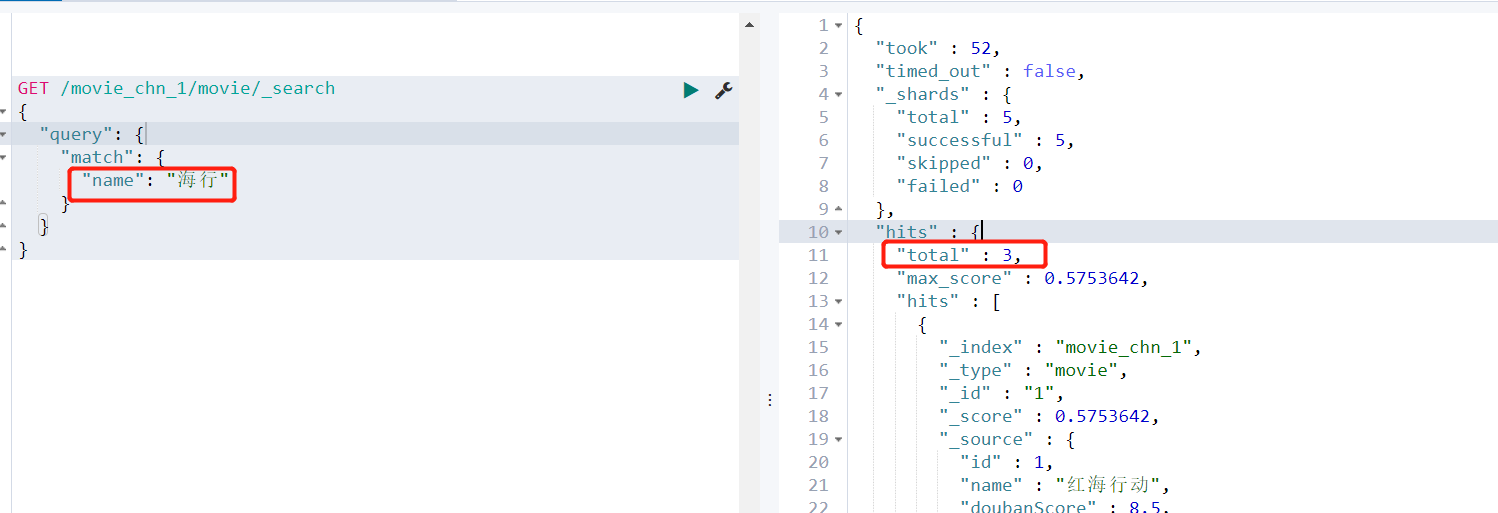
- 查询测试
GET /movie_chn_1/movie/_search
{
"query": {
"match": {
"name": "海行"
}
}
}
- 分析结论
上面查询“海行”命中了三条记录,是因为我们在定义的Index的时候,没有指定分词器,使用的是默认的分词器,对中文是按照每个汉字进行分词的。
基于中文分词搭建索引-手动定义mapping
- 定义Index,指定mapping
PUT movie_chn_2
{
"mappings": {
"movie":{
"properties": {
"id":{
"type": "long"
},
"name":{
"type": "text",
"analyzer": "ik_smart"
},
"doubanScore":{
"type": "double"
},
"actorList":{
"properties": {
"id":{
"type":"long"
},
"name":{
"type":"keyword"
}
}
}
}
}
}
}
- 向Index中放入Document
PUT /movie_chn_2/movie/1 { "id":1, "name":"红海行动", "doubanScore":8.5, "actorList":[ {"id":1,"name":"张译"}, {"id":2,"name":"海清"}, {"id":3,"name":"张涵予"} ] } PUT /movie_chn_2/movie/2 { "id":2, "name":"湄公河行动", "doubanScore":8.0, "actorList":[ {"id":3,"name":"张涵予"} ] } PUT /movie_chn_2/movie/3 { "id":3, "name":"红海事件", "doubanScore":5.0, "actorList":[ {"id":4,"name":"张三丰"} ] }
- 查看手动定义的mapping
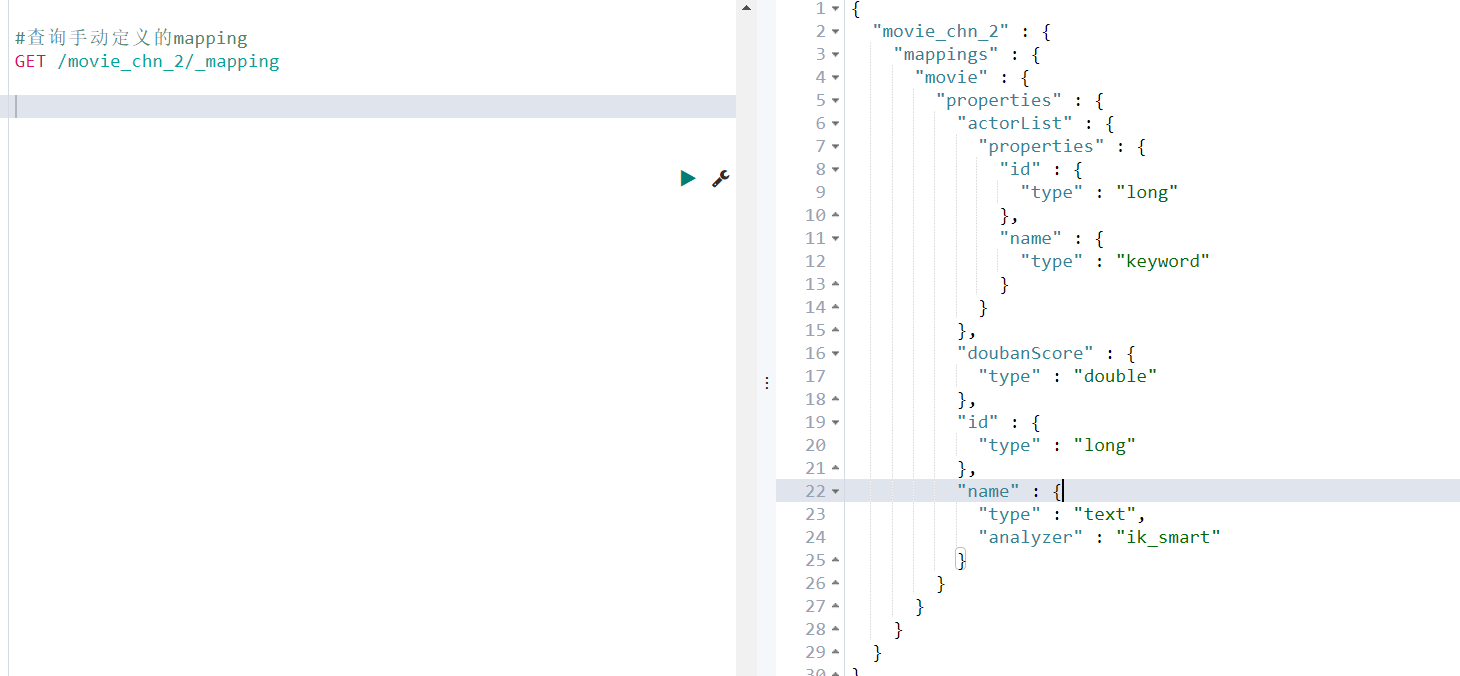
- 查询测试
GET /movie_chn_2/movie/_search { "query": { "match": { "name": "海行" } } }
- 分析结论
上面查询没有命中任何记录,是因为我们在创建Index的时候,指定使用ik分词器进行分词

索引数据拷贝
ElasticSearch虽然强大,但是却不能动态修改mapping到时候我们有时候需要修改结构的时候不得不重新创建索引;
ElasticSearch为我们提供了一个reindex的命令,就是会将一个索引的快照数据copy到另一个索引,默认情况下存在相同的_id会进行覆盖(一般不会发生,除非是将两个索引的数据copy到一个索引中),可以使
用POST _reindex命令将索引快照进行copy
POST _reindex
{
"source": {
"index": "my_index_name"
},
"dest": {
"index": "my_index_name_new"
}
}
索引别名 _aliases
索引别名就像一个快捷方式或软连接,可以指向一个或多个索引,也可以给任何一个需要索引名的API来使用。
创建索引别名
- 创建Index的时候声明
PUT 索引名
{
"aliases": {
"索引别名": {}
}
}
#创建索引的时候,手动mapping,并指定别名
创建movie_chn_3索引
PUT movie_chn_3
{
"aliases": {
"movie_chn_3_aliase": {}
},
"mappings": {
"movie":{
"properties": {
"id":{
"type": "long"
},
"name":{
"type": "text",
"analyzer": "ik_smart"
},
"doubanScore":{
"type": "double"
},
"actorList":{
"properties": {
"id":{
"type":"long"
},
"name":{
"type":"keyword"
}
}
}
}
}
}
}
为已存在的索引增加别名
POST _aliases { "actions": [ { "add":{ "index": "索引名", "alias": "索引别名" }} ] }
#给movie_chn_3添加别名
POST _aliases
{
"actions": [
{ "add":{ "index": "movie_chn_3", "alias": "movie_chn_3_a2" }}
]
}

查询别名列表
GET _cat/aliases?v

使用索引别名查询
与使用普通索引没有区别, GET 索引别名/_search
删除某个索引的别名
POST _aliases
{
"actions": [
{ "remove": { "index": "索引名", "alias": "索引别名" }}
]
}
POST _aliases
{
"actions": [
{ "remove": { "index": "movie_chn_3", "alias": "movie_chn_3_a2" }}
]
}

使用场景
- 给多个索引分组 (例如, last_three_months)
POST _aliases
{
"actions": [
{ "add": { "index": "movie_chn_1", "alias": "movie_chn_query" }},
{ "add": { "index": "movie_chn_2", "alias": "movie_chn_query" }}
]
}
GET movie_chn_query/_search
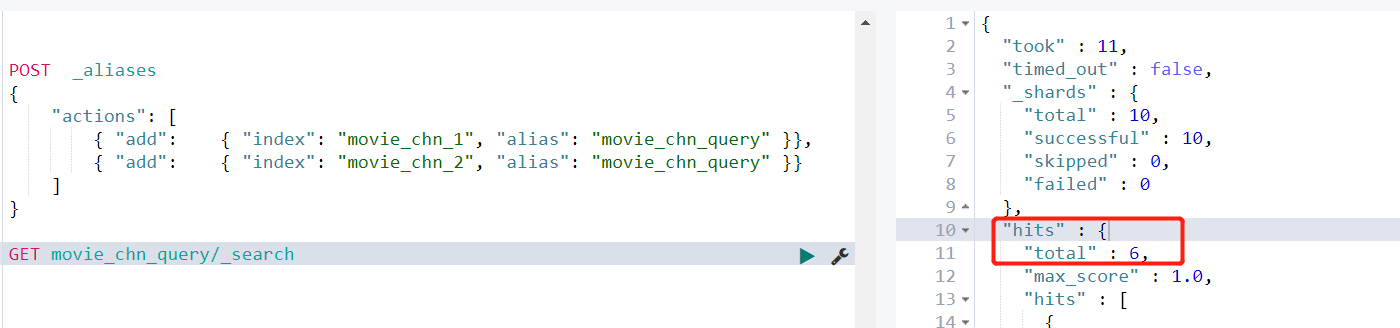
- 给索引的一个子集创建视图
相当于给Index加了一些过滤条件,缩小查询范围
POST _aliases
{
"actions": [
{
"add":
{
"index": "movie_chn_1",
"alias": "movie_chn_1_sub_query",
"filter": {
"term": { "actorList.id": "4"}
}
}
}
]
}
GET movie_chn_1_sub_query/_search
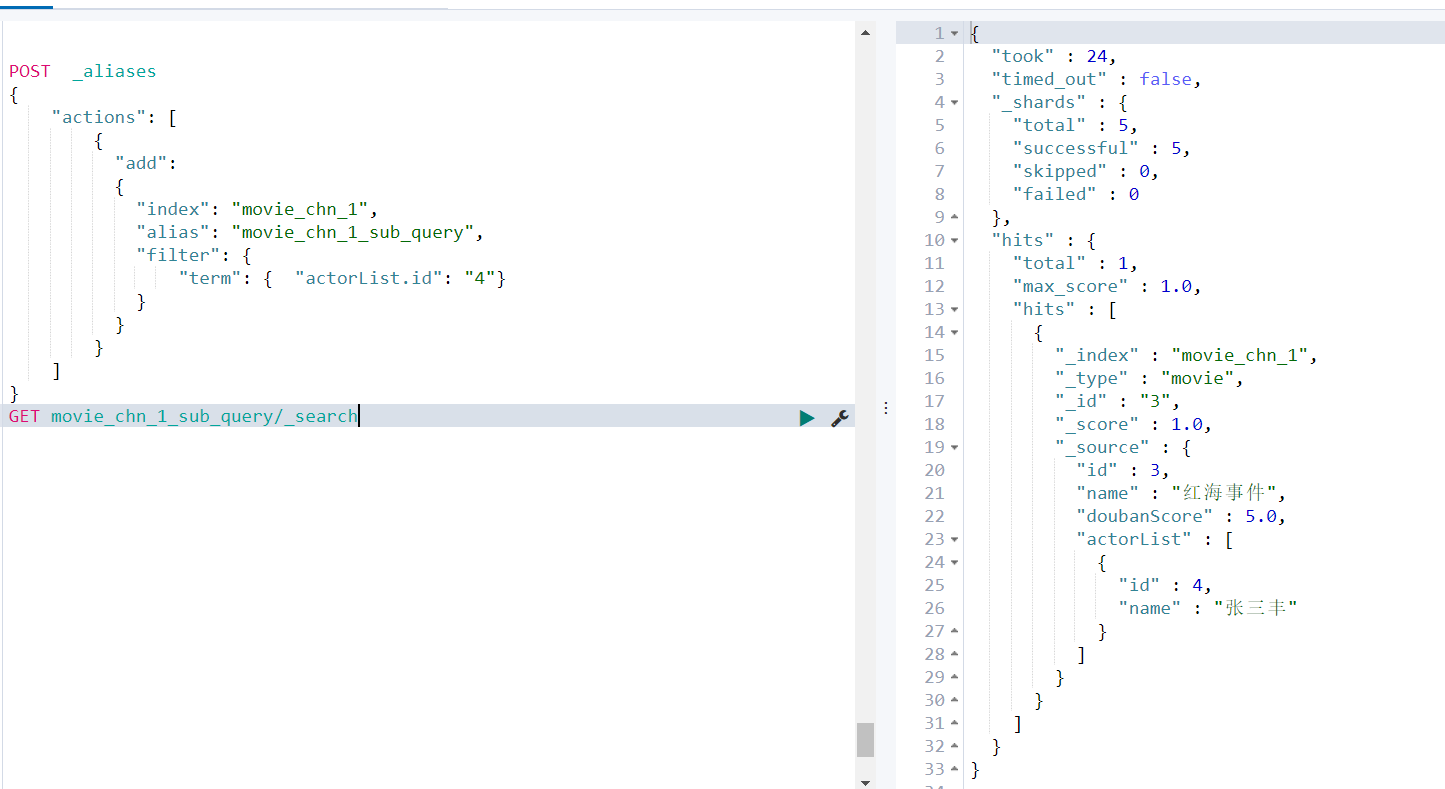
- 在运行的集群中可以无缝的从一个索引切换到另一个索引
POST /_aliases { "actions": [ { "remove": { "index": "movie_chn_1", "alias": "movie_chn_query" }}, { "remove": { "index": "movie_chn_2", "alias": "movie_chn_query" }}, { "add": { "index": "movie_chn_3", "alias": "movie_chn_query" }} ] } #整个操作都是原子的,不用担心数据丢失或者重复的问题
索引模板
索引模板(Index Template),顾名思义就是创建索引的模具,其中可以定义一系列规则来帮助我们构建符合特定业务需求的索引的mappings和settings,通过使用索引模板可以让我们的索引具备可预知的一致
性。
创建索引模板
PUT _template/template_movie2020 { "index_patterns": ["movie_test*"], "settings": { "number_of_shards": 1 }, "aliases" : { "{index}-query": {}, "movie_test-query":{} }, "mappings": { "_doc": { "properties": { "id": { "type": "keyword" }, "movie_name": { "type": "text", "analyzer": "ik_smart" } } } } }
其中 "index_patterns": ["movie_test*"]的含义就是凡是往movie_test开头的索引写入数据时,如果索引不存在,那么ES会根据此模板自动建立索引。
在 "aliases" 中用{index}表示,获得真正的创建的索引名。aliases中会创建两个别名,一个是根据当前索引创建的,另一个是全局固定的别名。
测试
- 向索引中添加数据
POST movie_test_202011/_doc { "id":"333", "name":"zhang3" }
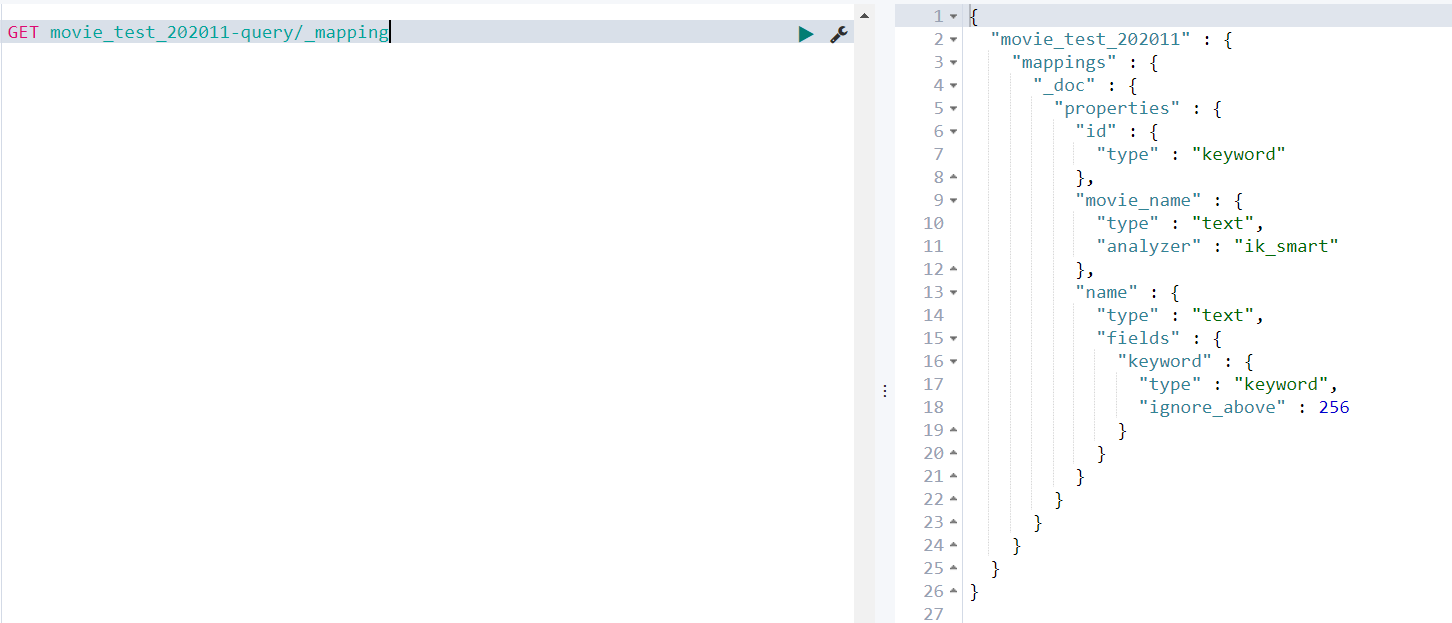
- 查询Index的mapping,就是使用我们的索引模板创建的
GET movie_test_202011-query/_mapping
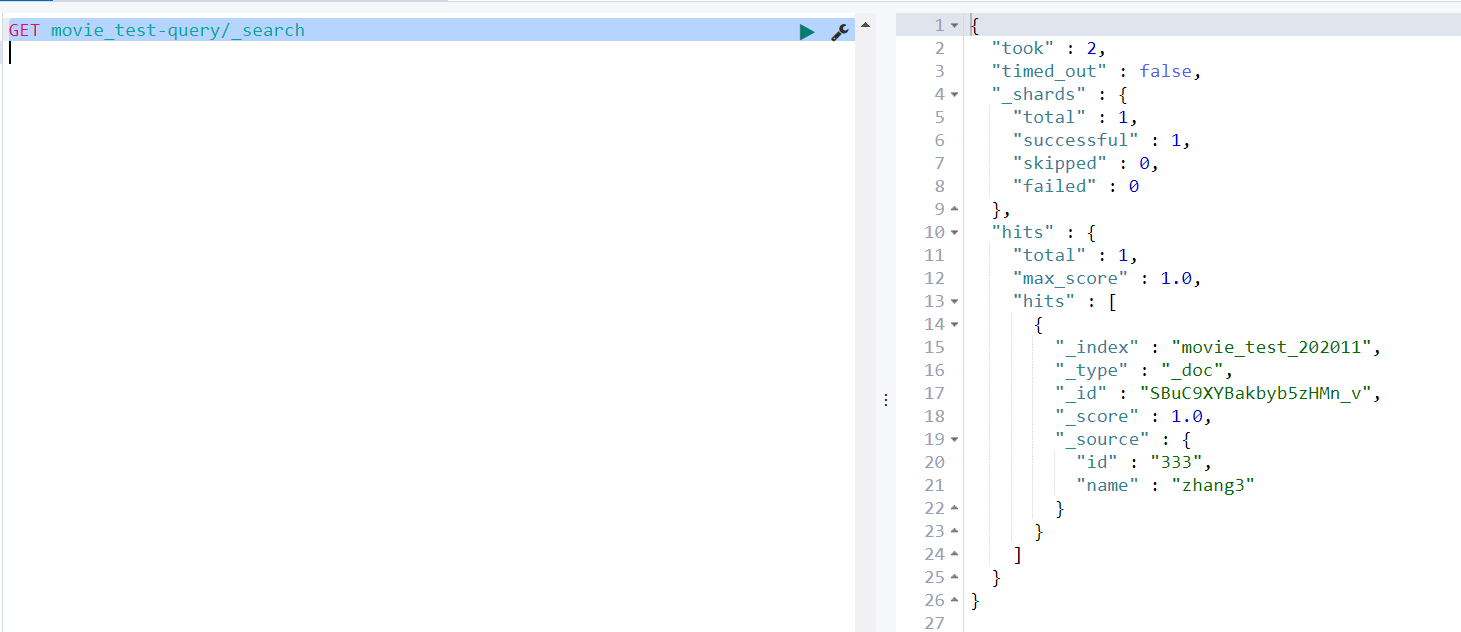
- 根据模板中取的别名查询数据
GET movie_test-query/_search
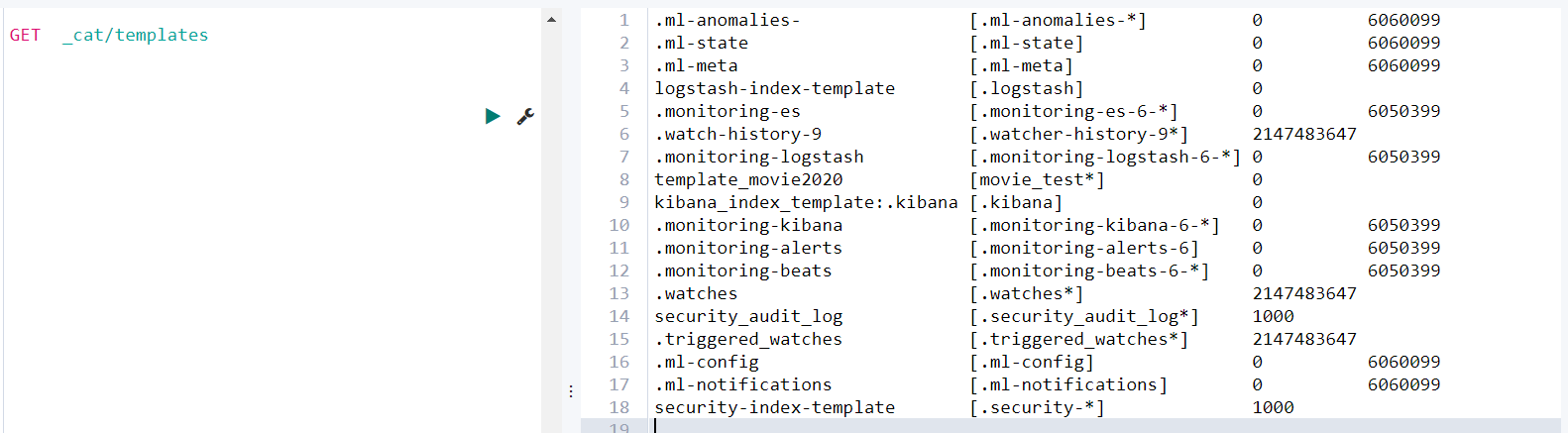
查看系统中已有的模板清单
GET _cat/templates
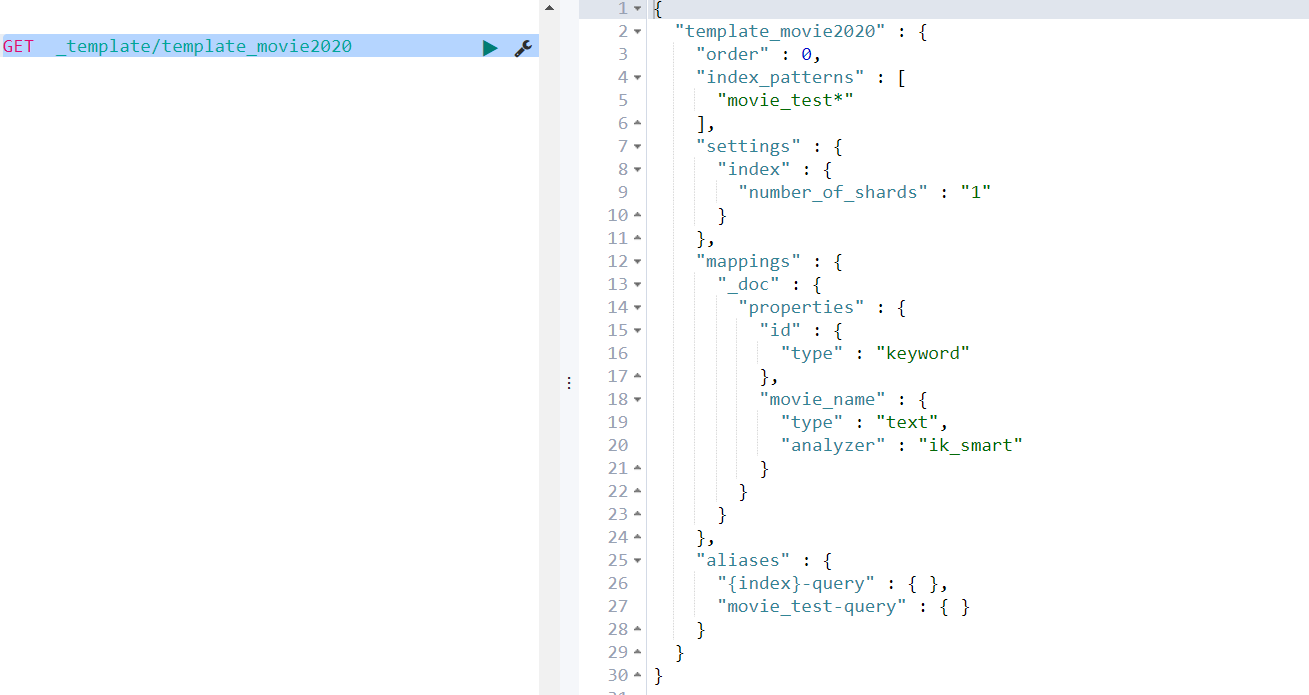
查看某个模板详情
GET _template/template_movie2020
或者
GET _template/template_movie*
使用场景
分割索引
分割索引就是根据时间间隔把一个业务索引切分成多个索引。
比如 把order_info 变成 order_info_20200101,order_info_20200102 …..
这样做的好处有两个:
- 结构变化的灵活性
因为ES不允许对数据结构进行修改。但是实际使用中索引的结构和配置难免变化,那么只要对下一个间隔的索引进行修改,原来的索引维持原状。这样就有了一定的灵活性。
要想实现这个效果,我们只需要在需要变化的索引那天将模板重新建立即可。
- 查询范围优化
因为一般情况并不会查询全部时间周期的数据,那么通过切分索引,物理上减少了扫描数据的范围,也是对性能的优化。
注意
使用索引模板,一般在向索引中插入第一条数据创建索引,如果ES中的Shard特别多,有可能创建索引会变慢,如果延迟不能接受,可以不使用模板,使用定时脚本在头一天提前建立第二天的索引。
Idea中操作ElasticSearch
(1) 选择操作ES的java客户端
目前市面上有两类客户端
- 一类是TransportClient 为代表的ES原生客户端,不能执行原生DSL语句必须使用它的Java api方法。
- 一类是以Rest ApI为主的client,最典型的就是jest。 这种客户端可以直接使用DSL语句拼成的字符串,直接传给服务端,然后返回json字符串再解析。
两种方式各有优劣,但是最近ElasticSearch官网,宣布计划在7.0以后的版本中废除TransportClient,以RestClient为主。
所以在官方的RestClient 基础上,进行了简单包装的Jest客户端,就成了首选,而且该客户端也与SpringBoot完美集成。
Jest相关依赖
<dependencies>
<!--Java操作ES的客户端工具Jest-->
<dependency>
<groupId>io.searchbox</groupId>
<artifactId>jest</artifactId>
<version>5.3.3</version>
</dependency>
<!--Jest需要的依赖-->
<dependency>
<groupId>net.java.dev.jna</groupId>
<artifactId>jna</artifactId>
<version>4.5.2</version>
</dependency>
<!--Jest需要的依赖-->
<dependency>
<groupId>org.codehaus.janino</groupId>
<artifactId>commons-compiler</artifactId>
<version>3.0.16</version>
</dependency>
<!-- ElasticSearch依赖 -->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>6.6.0</version>
</dependency>
</dependencies>



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2019-01-13 MySQL| 安装配置| 主从复制
2019-01-13 Spring | SpringMVC
2019-01-13 MySQL| 性能分析优化