
Kylin |2.ModuleProject
employee实事表才会参与真正运算,dept维表不参与
model模型分以下2种:
① 当所有维表都直接连接到“ 事实表”上时,整个图解就像星星一样,故将该模型称为星形模型
星状模型是直接关联;
② 当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。
雪花模型是主从间接关联;
创建分区表:
create table emp_partition(empno int, ename string, job string, mgr int, sal double, comm double, deptno int) partitioned by(hire_date string) row format delimited fields terminated by '\t'; 动态分区应该手动开启: set hive.exec.dynamic.partition.mode=nonstrict;
动态插入数据 insert into table emp_partition partition(hire_date) select empno, ename, job, mgr, sal, comm, deptno, hiredate from emp;
1. 创建module项目名称
project_partition
主表--FactTable: default.emp_partition
从表--Add Lookup Table:emp_partition inner join dept
维度--Select dimension columns:EMP_PARTITION-->job,mgr,hire_date ; DEPT-->dname
度量--Select measure columns: EMP_PARTITION--->sal
2. 构建Data Model
Data Model 主要是构建整体的数据模型,无论你的数据是星型模型或者是雪花模型,需要在这个地方建立数据表之间的关系。
2.1. 选择事实表与维度表
建立数据模型的第一步是选择事实表,选择完成后点击 “Add Lookup Table” 按钮设置事实表与维度表之间的关系。
2.2. 建立数据关系
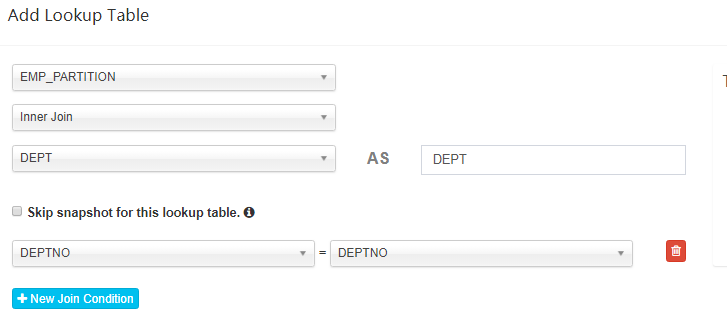
对 “Add Lookup Table” 页面的几点说明:
- 数据关系不仅仅是事实表与维度表之间(星型模型),维度表和维度表之间(雪花模型)也可以建立联系;
- 表与表之间的连接添加有三种:“Left Join”、“Inner Join”、“Right Join”;
Skip snapshot for this lookup table选项指的是是否跳过生成 snapshotTable,由于某些 Lookup 表特别大(大于 300M),如果某一个维度的基数比较大 ,可能会导致内存出现 OOM,所以在创建 snapshotTable 的时候会限制原始表的大小不能超过配置的一个上限值(kylin.snapshot.max-mb,默认值300);- 跳过构建 snapshot 的 lookup 表将不能搜索,同时不支持设置为衍生维度(Derived);
- 大部分情况下都是使用 “Left Join”,其他两种 Join 方式不是很常用。
每一个 Snapshot 是和一个 Hive 维度表对应的,生成的过程是:
- 从原始的hive维度表中顺序得读取每一行每一列的值;
- 使用 TrieDictionary 方式对这些所有的值进行编码(一个值对应一个 Id);
- 再次读取原始表中每一行的值,将每一列的值使用编码之后的 Id 进行替换,得到了一个只有 Id 的新表;
- 同时保存这个新表和 Dictionary 对象(Id 和值的映射关系)就能够保存整个维度表;
- Kylin 将这个数据存储到元数据库中。
2.3. 完成表关系构建
通过上述的操作即可将事实表以及维度表联系起来,构成一个数据模型。
点击了Skip snapshot就会进行limit限制; 否则就是 Table kind --> Normal

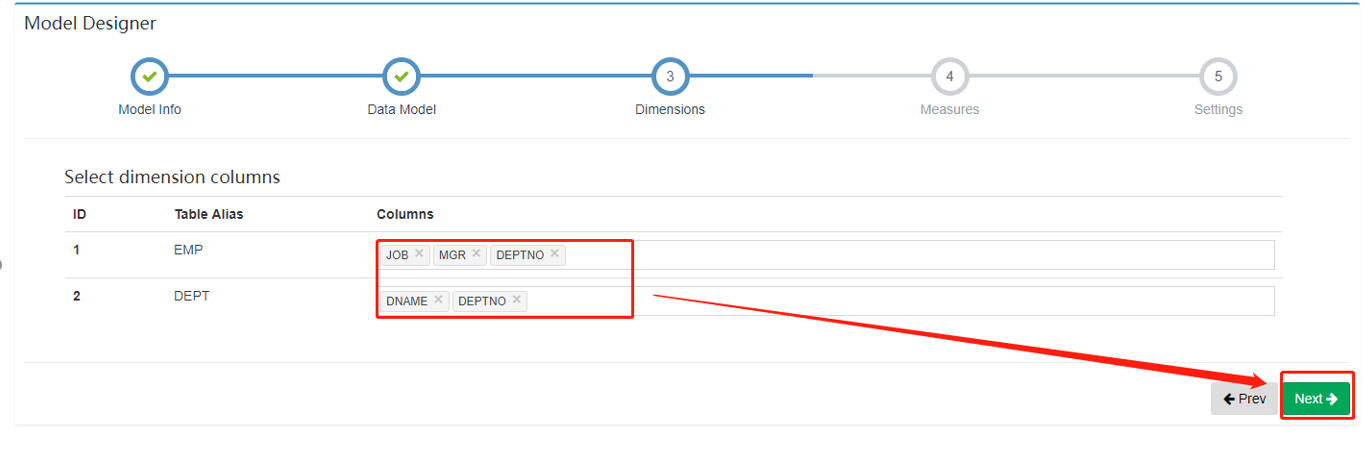
2.4. Dimensions
在 Dimensions 页面选择可能参与计算的维度,这里被选择的只是在 Cube 构建的时候拥有被选择资格的维度,并不是最后参与 Cube 构建的维度,推荐将维度表中的字段都选择上。
一般而言,日期、商品种类、区域等会作为维度。
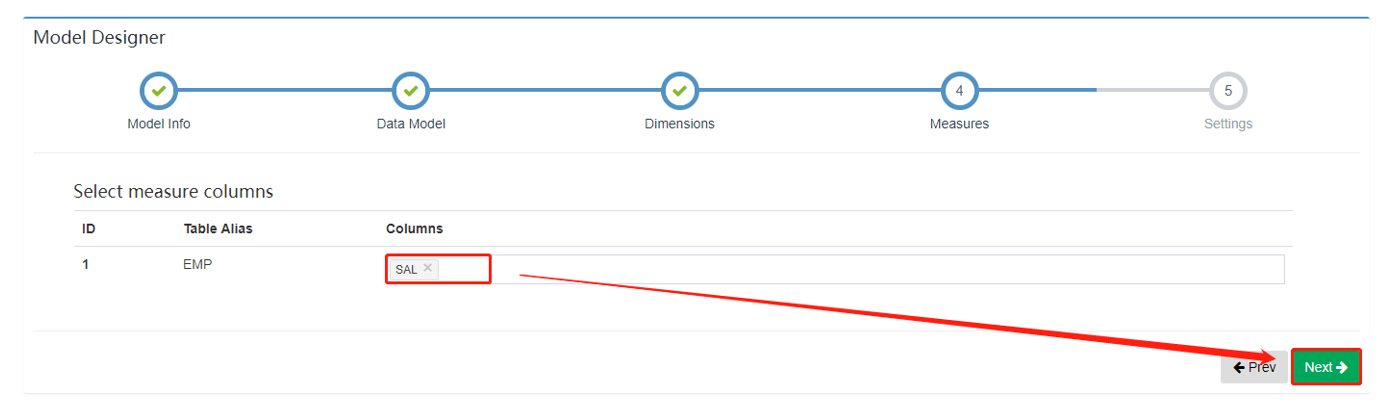
2.5. Measures
在 Measures 页面选择可能用于计算的度量。
一般而言,销售额、流量、温湿度等会作为度量。
2.6. Settings
在 Settings 页面可以设置分区以及过滤条件,其中分区是为了系统可以进行增量构建而设计的,目前 Kylin 支持基于日期的分区,在 “Partition Date Column” 后面选择事实表或者维度表中的日期字段,然后选择
日期格式即可;过滤条件设置后,Kylin 在构建的时候会选择符合过滤条件的数据进行构建。
需要注意的几点:
- 时间分区列可以支持日期或更细粒度的时间分区;
- 时间分区列支持的数据类型有
time/date/datetime/integer等; - 过滤条件不需要写
WHERE; - 过滤条件不能包含日期维度。
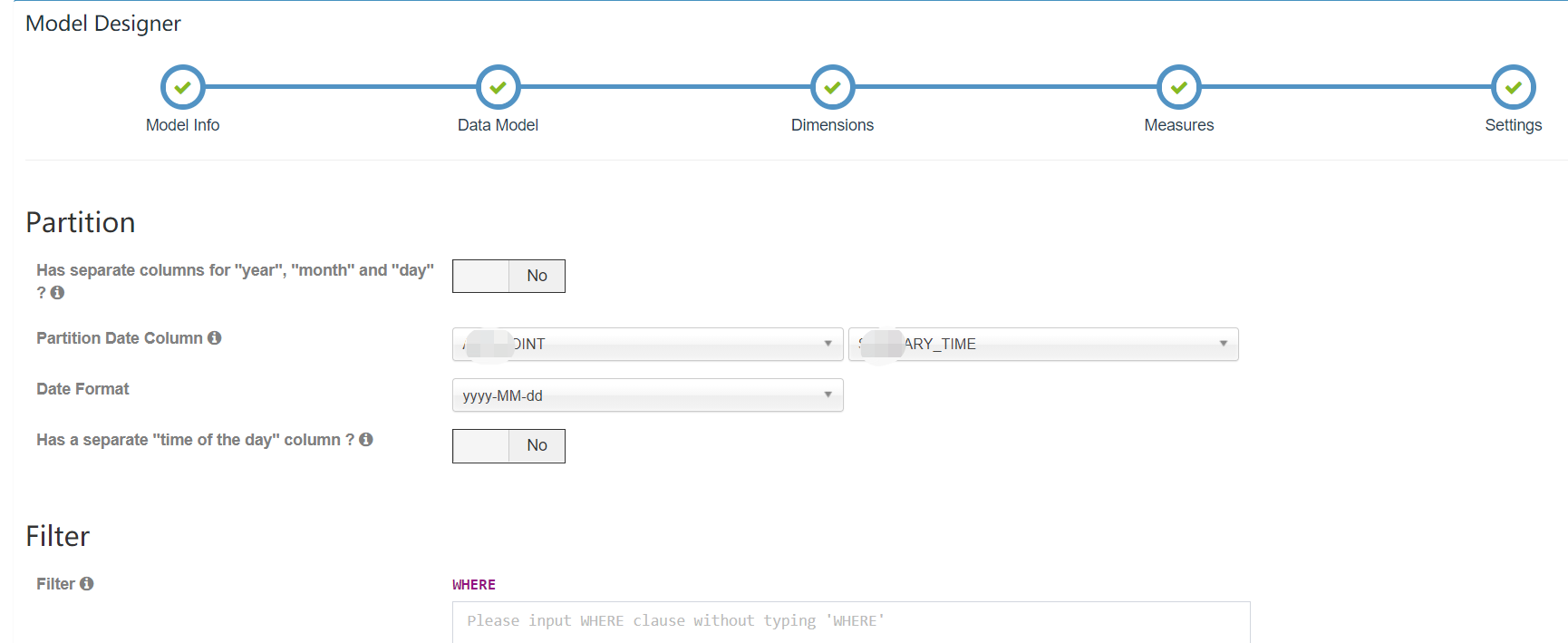
与动量cute做呼应,分区必须是日期;选分区表:summary_time
2.7. Save
最后保存即可完成 Model 的创建,可以打开 Model 中的 Visualization 标签页查询模型的表连接情况。
3. 构建cube
3.1. Dimensions
Dimensions是维度选择界面,从数据模型的维度中选择一些列作为 Cube 的维度,这里的设置会影响到生成的 Cuboid 数量,进而影响 Cube 的数据量大小。
在选择维度时,每一个维度列可以作为普通维度(Normal),也可以作为衍生维度(Derived)。相对于普通维度来说,衍生维度并不参与维度的 Cuboid,衍生维度对应的外键(FK)参与维度 Cuboid,从而
降低 Cuboid 数。在查询时,对衍生维度的查询会首先转换为对外键所在维度的查询,因此会牺牲少量性能(大部分情况可以接受)。

维度的选择
- 作为 Cube 的维度需要满足下面的条件:可能存在于 where 条件中或者 groupBy 中的维度;
- 事实表(Fact Table)只选择参与查询的字段,不参与查询的一定不要勾选(即便是外键);
- 维度表(Lookup Table)中的主键与事实表的外键一一对应,推荐勾选事实表的外键,维度表的主键勾选后选择为衍生(Derived)维度;
- 对于星型模型而言,维度表的字段往往可以全部为衍生字段;
- 对于雪花模型而言,如果维度表存在子表,则维度表对于子表的外键推荐作为普通(Normal)维度。
特别注意项
- 表连接的字段并非一定要参与 Cuboid 计算;
- 表连接的字段如果没有被勾选,且其外键表中没有任何字段作为衍生维度,则该表连接字段是不会参与 Cuboid 的;
- 一旦被设置为 Normal 类型,则一定会参与 Cuboid 计算;
- 如果维度表存在层级(例如省市县、日月年等),则推荐分层级的相关字段选择为普通(Normal)维度。
3.2. Measures
维度选择完成后,需要选择度量聚合的方式,比较常规的聚合方式有:COUNT、SUM、MIN、MAX、PERCENTILE,下面将详细介绍其他几种聚合方式。
①TOP_N
Top-N 度量,旨在在 Cube 构建的时候预计算好需要的 Top-N;在查询阶段,就可以迅速的获取并返回 Top-N 记录,这样查询性能就远远高于没有 Top-N 预计算结果的 Cube。
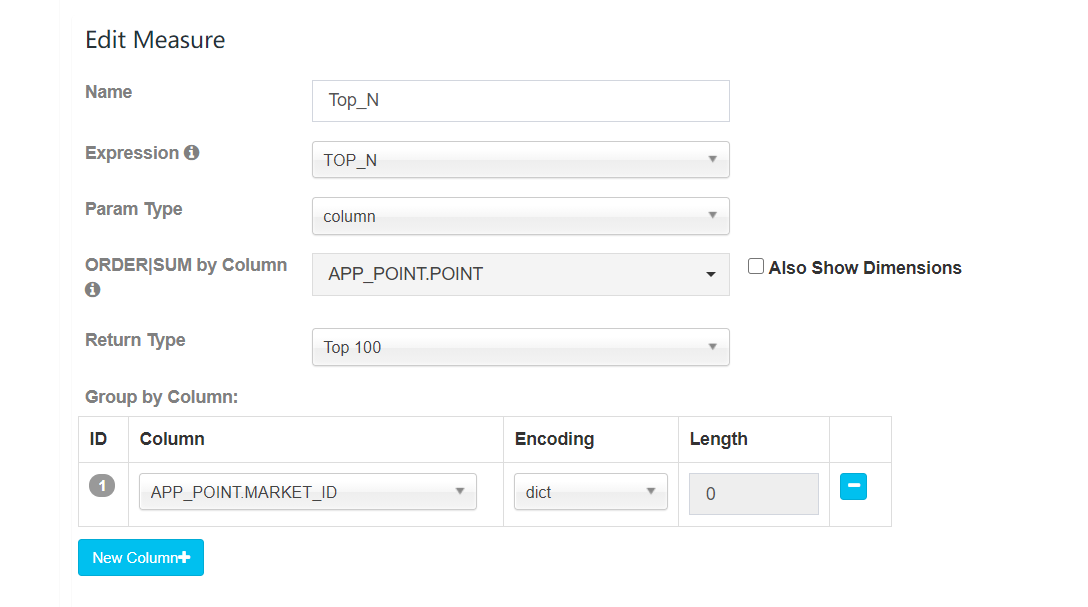
Top-N 中 Group By 的该如何选择?
例如:全国二氧化碳污染物总和的省份排名,结果是省份排名,需要测量的是污染物的总和,因此 Group By 需要设置为 污染物类型。
Return Type 中的 Top N 是什么意思?
TOP N 表示最终获取的前 N 名的排序是比较准确的,例如 TOP 10 表示最终的前 10 名是比较准确的(维度的基数非常大时存在误差),但是不代表只能取前 10 个(Limit 10),可以使用其他数字,例如 Limit 500,只是返回更多内容时,精准度没有保证。
TOP-N 的存储
使用 TOP-N 时,排序度量字段和 Group By 字段会组合在一起,形成一个字段进行存储,用户需要 Top 100 的结果,Kylin 对于每种组合条件值,保留 Top 5000 (50倍)的纪录, 并供以后再次合并。
② Count_Distinct
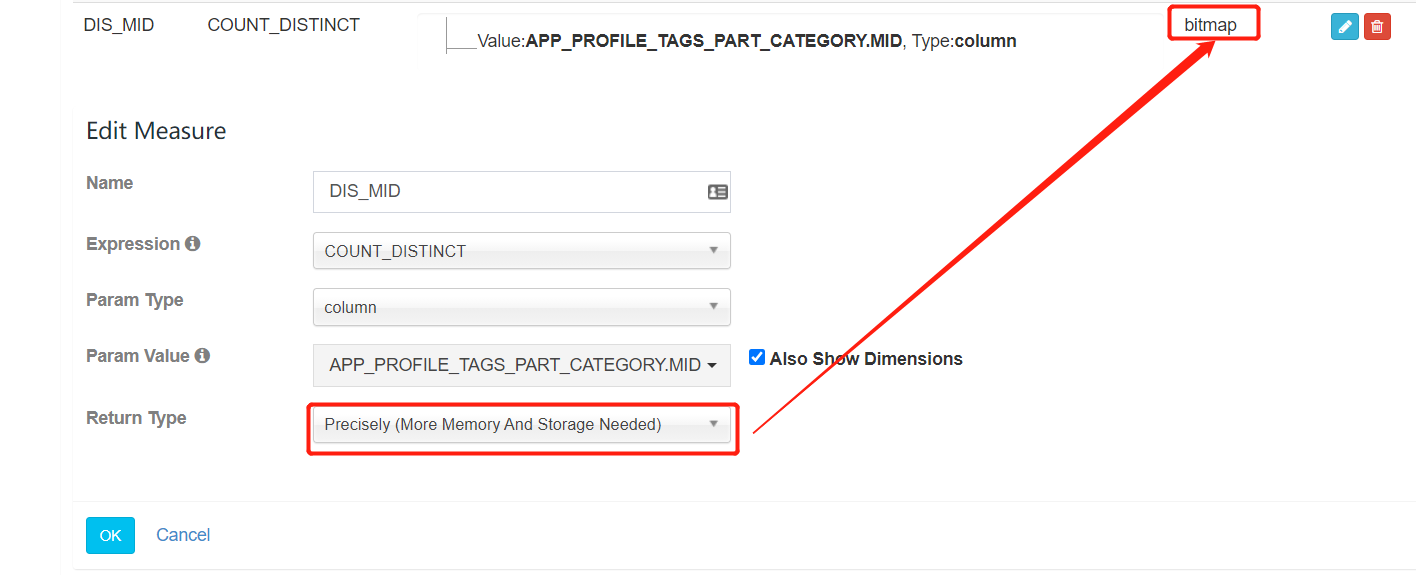
Count_Distinct 度量有两个实现:
- 近似实现:基于 HyperLogLog 算法,可选择接受的错误率(从9.75% 到 1.22%),低错误率需要更多存储;
- 精确实现:基于 Bitmap(位图)算法,对于数据型为 tinyint、smallint 和 int 的数据,将把数据对应的值直接打入位图;对于数据型为 long,string 和其他的数 据,将它们编码成字符串放入字典,然后再将对应的值打入位图。返回的度量结果是已经序列化的位图数据,而不仅是计算的值。这确保了不同的 segment 中,甚至跨越不同的 segment 来上卷,结果也是正确的。
越精确消耗的存储空间越大,大多数场景下 HyperLogLog 的近似实现即可满足需求。

④ EXTEND_COLUMN

在分析场景中,经常存在对某个 id 进行过滤,但查询结果要展示为 name 的情况,比如user_id和user_name。这类问题通常有三种解决方式:
- 将 id 和 name 都设置为维度,查询语句类似
select name, count(*) from table where id = 1 group by id,name,这种方式的问题是会导致维度增多,导致预计算结果膨胀; - 将 id 和 name 都设置为维度,并且将两者设置为联合维度(Joint Dimensions),这种方式的好处是保持维度组合数不会增加,但限制了维度的其它优化,比如 id 不能再被设置为强制维度或者层次维度;
- 将 id 设置为维度,name 设置为特殊的 Measure,类型为 Extended Column,这种方式既能保证过滤 id 且查询 name 的需求,同时也不影响 id 维度的进一步优化。
3.3 Refresh Setting
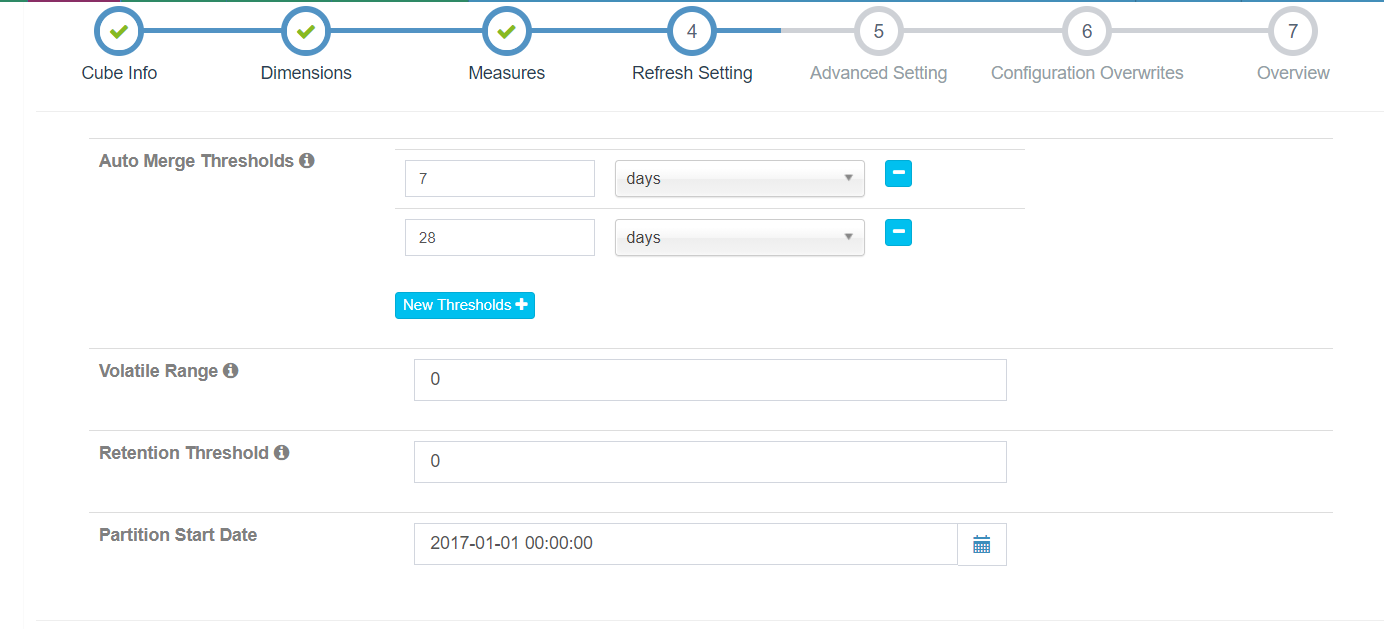
- 触发自动合并的时间阈值(Auto Merge Thresholds):自动合并小的 segments 到中等甚至更大的 segment,如果不想自动合并,删除默认 2 个选项;
- Volatile Range: 默认为 0,‘Auto Merge’ 会自动合并所有可能的 cube segments;设置具体的数值后,‘Auto Merge’ 将不会合并最近
Volatile Range天的 cube segments;假设 Volatile Range 设置为 7,则最近 7 天内生成的 cube segments 不会被自动合并; - 保留时间阈值(Retention Threshold):对于时间久远的不需要再被查询的 Segment,Kylin 通过设置保留时间阈值可以自动清除这些 Segment,以节省磁盘空间;每当构建新的 Segment 时,Kylin 会自动检查老的 Segment,当这些 Segment 的结束日期与当前最新 Segment 的结束日期的差值大于保留时间阈值,则会被清除;如果无需自动清理,可以默认设置保留时间阈值为 0。
- 分区起始时间(Partition Start Date):Cube 构建的起始时间,
1970-01-01 08:00:00默认为分区起始时间。
3.4 Advanced Setting
高级设置主要用于 Cuboid 的剪枝优化,通过聚合组(Aggregation Group)、必要维度(Mandatory Dimension)、层级维度(Hierarchy Dimension)、联合维度(Joint Dimension)等方式,可以使得 Cuboid
的组合在预期范围内。
① 聚合组(Aggregation Group)
根据查询的维度组合,可以划分出维度组合大类,这些大类在 Kylin 里面被称为聚合组。例如查询需求为:污染物排放量在特定的时间范围内,各个区域(省、市、区县三个级别)的排名以及各个流域(一、二、三级流域)的排名。
上述的查询需求就可以氛围两个聚合组:
- 根据区域维度、时间维度查询污染物排放量;
- 根据流域维度、时间维度查询污染物排放量。
如果只使用一个聚合组,区域维度和流域维度就很产生很多组合的 Cuboid,然而这些组合对查询毫无用处,此时就可以使用两个聚合组把区域和流域分开,这样便可以大大减少无用的组合。
② 必要维度(Mandatory Dimension)
Mandatory 维度指的是那些总是会出现 在Where 条件或 Group By 语句里的维度。
当然必须存在不一定是显式出现在查询语句中,例如查询日期是必要字段,月份、季度、年属于它的衍生字段,那么查询的时候出现月份、季度、年这些衍生字段等效于出现查询日期这个必要字段。
③ 层级维度 (Hierachy Dimension)
Hierarchy 是一组有层级关系的维度,例如:国家->省->市,这里的“国家”是高级别的维度,“省”“市”依次是低级别的维度;用户会按高级别维度进行查询,也会按低级别维度进行查询,但在查询低级别维度时,
往往都会带上高级别维度的条件,而不会孤立地审视低级别维度的数据。也就是说,用户对于这三个维度的查询可以归类为以下三类:
- group by country
- group by country, province(等同于group by province)
- group by country, province, city(等同于group by country, city 或者group by city)
④ 联合维度(Joint Dimension)
有些维度往往一起出现,或者它们的基数非常接近(有1:1映射关系),例如 “user_id” 和 “email”。把多个维度定义为组合关系后,所有不符合此关系的 cuboids 会被跳过计算。
就 Joint Dimension (A, B) 来说,在 group by 时 A, B 最好同时出现,这样不损失性能。但如果只出现 A 或者 B,那么就需要在查询时从 group by A,B 的结果做进一步聚合运算,会降低查询的速度。

3.5 Rowkeys
编码
Kylin 以 Key-Value 的方式将 Cube 存储到 HBase 中,HBase 的 key,也就是 Rowkey,是由各维度的值拼接而成的;为了更高效地存储这些值,Kylin 会对它们进行编码和压缩;每个维度均可以选择合适的编
码(Encoding)方式,默认采用的是字典(Dictionary)编码技术;字段支持的基本编码类型如下:
dict:适用于大部分字段,默认推荐使用,但在超高基情况下,可能引起内存不足的问题;boolean:适用于字段值为true, false, TRUE, FALSE, True, False, t, f, T, F, yes, no, YES, NO, Yes, No, y, n, Y, N, 1, 0;integer:适用于字段值为整数字符,支持的整数区间为[ -2^(8N-1), 2^(8N-1)];date:适用于字段值为日期字符,支持的格式包括yyyyMMdd、yyyy-MM-dd、yyyy-MM-dd HH:mm:ss、yyyy-MM-dd HH:mm:ss.SSS,其中如果包含时间戳部分会被截断;time:适用于字段值为时间戳字符,支持范围为[ 1970-01-01 00:00:00, 2038/01/19 03:14:07],毫秒部分会被忽略,time编码适用于 time, datetime, timestamp 等类型;fix_length:适用于超高基场景,将选取字段的前 N 个字节作为编码值,当 N 小于字段长度,会造成字段截断,当 N 较大时,造成 RowKey 过长,查询性能下降,只适用于 varchar 或 nvarchar 类型;fixed_length_hex:适用于字段值为十六进制字符,比如 1A2BFF 或者 FF00FF,每两个字符需要一个字节,只适用于 varchar 或 nvarchar 类型。
顺序
各维度在 Rowkeys 中的顺序,对于查询的性能会产生较明显的影响;在这里用户可以根据查询的模式和习惯,通过拖曳的方式调整各个维度在Rowkeys上的顺序。推荐的顺序为:Mandatory 维度、where 过滤
条件中出现频率较多的维度、高基数维度、低基数维度。这样做的好处是,充分利用过滤条件来缩小在 HBase 中扫描的范围,从而提高查询的效率。
分片
指定 ShardBy 的列,明细数据将按照该列的值分片;没有指定 ShardBy 的列,则默认将根据所有列中的数据进行分片;选择适当的 ShardBy 列,可以使明细数据较为均匀的分散在多个数据片上,提高并行性,
进而获得更理想的查询效率;建议选择基数较大的列作为 ShardBy 列,以避免数据分散不均匀。
3.6、其他设置
Mandatory Cuboids: 维度组合白名单,指定需要构建的 cuboid 的维度的组合;Cube Engine: Cube 构建引擎,有两种:MapReduce 和 Spark;如果你的 Cube 只有简单度量(SUM, MIN, MAX),建议使用 Spark;如果 Cube 中有复杂类型度量(COUNT DISTINCT, TOP_N),建议使用 MapReduce;Global Dictionary:用于精确计算 COUNT DISTINCT 的字典, 它会将一个非 integer 的值转成 integer,以便于 bitmap 进行去重;如果你要计算 COUNT DISTINCT 的列本身已经是 integer 类型,那么不需要定义 Global Dictionary; Global Dictionary 会被所有 segment 共享,因此支持在跨 segments 之间做上卷去重操作。Segment Dictionary:另一个用于精确计算 COUNT DISTINCT 的字典,与 Global Dictionary 不同的是,它是基于一个 segment 的值构建的,因此不支持跨 segments 的汇总计算。如果你的 cube 不是分区的或者能保证你的所有 SQL 按照 partition_column 进行 group by, 那么你应该使用 “Segment Dictionary” 而不是 “Global Dictionary”,这样可以避免单个字典过大的问题。Advanced Snapshot Table: 为全局 lookup 表而设计,提供不同的存储类型;Advanced ColumnFamily: 如果有超过一个的 COUNT DISTINCT 或 TopN 度量, 你可以将它们放在更多列簇中,以优化与HBase 的I/O。
3.7 Configuration Overwrites
Kylin 使用了很多配置参数以提高灵活性,用户可以根据具体的环境、场景等配置不同的参数进行调优;Kylin 全局的参数值可在 conf/kylin.properties 文件中进行配置;如果 Cube 需要覆盖全局设置的话,则
需要在此页面中指定,这些配置项将覆盖项目级别和配置文件中的默认值。
3.8 Overview
你可以概览你的 cube 并返回之前的步骤进行修改,点击 Save 按钮完成 cube 创建。
3.9 Planner
如果你开启了 Cube Planner,当 Cube 保存后可以到 Planner 标签页查看 Cuboid 的个数以及各个维度的组合情况,这能够很直观的帮助你了解你的维度组合情况,如果与预想的有出入可以随时对 Cube 进行调整。
4. Build Cube
Cube已经创建好了,就可以Build了。

Action下拉框选项显示Cube操作有:
(1)Drop
删除此Cube。
(2)Edit
如果发现Cube设计有问题,可以选择Edit进行修改。
(3)Build
执行构建Cube操作,如果是增量Cube,则需要指定开始和结束时间,这两个时间区间标识本次构建的segment的数据源只选择这个时间范围内的数据。对于Build操作而言,startTime是不需要的,因为它总是会选择最后一个segment的结束时间作为当前segment的起始时间。
由于Kylin基于预计算的方式提供数据查询,构建操作是指将原始数据(存储在Hadoop中,通过Hive获取)转换成目标数据(存储在HBase中)的过程。
(4)Refresh
对某个已经构建过的Cube Segment,重新从数据源抽取数据并构建,从而获得更新。
(5)Merge
对于增量Cube,即设置分区字段,这样的Cube就可以进行多次Build,每一次的Build会生成一个segment,每一个segment对应着一个时间区间的Cube,这些segment的时间区间是连续并且不重合的,对于拥有多个segment的cube可以执行merge,相当于将一段时间区间内部的segment合并成一个,可以减少Segment的数量,同时减少Cube的存储空间。
(6)Enable
使Cube生效。如果Cube处于disabled状态时改变Cube Schema,那么Cube的所有segments将因为Data和Schema不匹配而被丢弃。
(7)Disabled
使Cube失效,此时无法再通过SQL查询Cube数据。如果再执行Enable的话,就可以继续查询了。
(8)Purge
将Cube的所有Cube Segment删除。
(9)Clone
如果我们想保留原先已经创建好的Cube,但是又想创建一个类似的Cube,那么此时就可以使用Clone功能重新克隆一个一模一样的Cube,然后对这个Cube进行修改等操作。
对于Cube不同的状态,能够执行的Action也是不同的,比如Cube处于Ready状态时可以执行的Action

如果Cube的状态变成“Ready”意味着已经准备好对外SQL查询服务。
下面我们切换到Monitor界面,查看刚才提交的Job。

等作业执行完成后,Monitor中的Job状态显示为FINISHED,并且Progress显示为100%。
Job的几种状态:
- NEW:新任务,刚刚创建。
- PENDING:等待被调度执行的任务。
- RUNNING:正在运行的任务。
- FINISHED:正常完成的任务(终态)。
- ERROR:执行出错的任务。
- DISCARDED:丢弃的任务(终态)。

Build Cube完成后,我们可以从Cube的详细信息中看到HBase的信息了(Build Cube之前没有任何信息)。

此Cube数据存储在HBase的表KYLIN_C37CNMSYXA中,2个Region,小于1MB,并且包含开始和结束时间。我们登录到HBase环境中查看:
hbase(main):001:0> list
TABLE
KYLIN_AMLAK436TI
KYLIN_C37CNMSYXA
kylin_metadata
3 row(s) in 0.3120 seconds
=> ["KYLIN_AMLAK436TI", "KYLIN_C37CNMSYXA", "kylin_metadata"]
hbase(main):002:0>
可以看到表KYLIN_C37CNMSYXA是存在的。
5. 构建增量cube
hive中的数据会逐渐增加,cube的构建也需要不断执行,但每次构建cube时,都要把已分析过的旧数据和新数据都重新分析。比如,数据累加了一年,每天做一次数据更新,随之做cube构建,则每次cube面对的数据量都在加大,第366天的分析,要面对第366天 + 之前365天的数据总和。
希望每次构建cube时,不用全量构建,即不用把所有原始hive表重新构建,而是把新增的hive数据构建一个segment即可。
见上创建项目:创建hive分区表--->module中指定分区列(--->cube增量构建

hive cube -->Segment -->Segment
-->Segment ... 全量构建(full-build) 增量构建() hive cube -->Segment1(2019-2-12) -->Segment2(2019-3-12)
由于hive中数据变更,kylin会去进行同步,同步一次叫一个segment,每次的segment就是一段一段;
cube关联着hive表,一个cube可能关联多次segment,关联一次就有一个segment
物化视图的概念
合并
手动合并
在cube中选择"build"的菜单位置,选择"merge"即可触发手动合并; 之后可以选择要合并的时间区间,提交任务即可
自动合并
通过在cube中设置阈值,让cube自动触发segment合并

自动合并(从大到小,如先看28天再看7天;7天合并1次,28天合并一次)做定期的合并
如果有时间跨度达到28天就合并1次;
例如每4天做1次构建,合并一次,做完第7次的构建之后,它和前6次的段就占满了28天,第7次时就占满了28天的间隔,则Segment合并一次;
当没有满足跨度达到28天,再判断有没有连续占满7天的,(它是会先检查大的,大的28天没有,如果7天满足了,就合并);每出现1次新的Segment就会去判断一次;
Retention Threshold中默认值为0,意思是,不丢弃任何segment;如改为20,保留最近20天的Segment,不在这个区间的就舍弃;
6. Kylin查询
在New Query中输入查询语句并Submit

数据图表展示及可以导出



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人