
Kylin| 常见问题
详细使用参考官方文档:
http://kylin.apache.org/cn/docs/
Kylin的构建过程
sql如下



SELECT `APP_POINT`.`MID` as `APP_POINT_MID` ,`APP_POINT`.`MEMBER_LEVEL` as `APP_POINT_MEMBER_LEVEL` ,`APP_POINT`.`MARKET_ID` as `APP_POINT_MARKET_ID` ,`APP_POINT`.`SUMMARY_TIME` as `APP_POINT_SUMMARY_TIME` ,`APP_USER_BASE_INFO`.`GENDER` as `APP_USER_BASE_INFO_GENDER` ,`APP_USER_BASE_INFO`.`BIRTH_TIME` as `APP_USER_BASE_INFO_BIRTH_TIME` ,`APP_USER_BASE_INFO`.`IS_HAVE_CHILD` as `APP_USER_BASE_INFO_IS_HAVE_CHILD` ,`APP_USER_BASE_INFO`.`MEMBER_TYPE` as `APP_USER_BASE_INFO_MEMBER_TYPE` ,`APP_USER_BASE_INFO`.`IS_NEW_MEMBER` as `APP_USER_BASE_INFO_IS_NEW_MEMBER` ,`APP_USER_BASE_INFO`.`IS_HAVE_CAR` as `APP_USER_BASE_INFO_IS_HAVE_CAR` ,`APP_USER_BASE_INFO`.`VIP_LEVEL` as `APP_USER_BASE_INFO_VIP_LEVEL` ,`APP_USER_BASE_INFO`.`MID` as `APP_USER_BASE_INFO_MID` ,`APP_POINT`.`POINT` as `APP_POINT_POINT` FROM `HST_APP`.`APP_POINT` as `APP_POINT` INNER JOIN `HST_APP`.`APP_USER_BASE_INFO` as `APP_USER_BASE_INFO` ON `APP_POINT`.`MID` = `APP_USER_BASE_INFO`.`MID` WHERE 1=1
kylin.log日志,构建所创建的表及索引
USE default; DROP TABLE IF EXISTS kylin_intermediate_point_cube_0051b1b9_09d4_be20_1c3b_034038b5b306; CREATE EXTERNAL TABLE IF NOT EXISTS kylin_intermediate_point_cube_0051b1b9_09d4_be20_1c3b_034038b5b306 ( \`APP_POINT_MID\` bigint ,\`APP_POINT_MEMBER_LEVEL\` bigint ,\`APP_POINT_MARKET_ID\` bigint ,\`APP_POINT_SUMMARY_TIME\` string ,\`APP_USER_BASE_INFO_GENDER\` string ,\`APP_USER_BASE_INFO_BIRTH_TIME\` string ,\`APP_USER_BASE_INFO_IS_HAVE_CHILD\` string ,\`APP_USER_BASE_INFO_MEMBER_TYPE\` string ,\`APP_USER_BASE_INFO_IS_NEW_MEMBER\` string ,\`APP_USER_BASE_INFO_IS_HAVE_CAR\` string ,\`APP_USER_BASE_INFO_VIP_LEVEL\` string ,\`APP_POINT_POINT\` bigint ) STORED AS SEQUENCEFILE LOCATION 'hdfs://nameservice1/kylin/kylin_metadata/kylin-8a15ba0f-54d5-699e-9812-bab76649c511/kylin_intermediate_point_cube_0051b1b9_09d4_be20_1c3b_034038b5b306'; ALTER TABLE kylin_intermediate_point_cube_0051b1b9_09d4_be20_1c3b_034038b5b306 SET TBLPROPERTIES('auto.purge'='true'); INSERT OVERWRITE TABLE \`kylin_intermediate_point_cube_0051b1b9_09d4_be20_1c3b_034038b5b306\` SELECT \`APP_POINT\`.\`MID\` as \`APP_POINT_MID\` ,\`APP_POINT\`.\`MEMBER_LEVEL\` as \`APP_POINT_MEMBER_LEVEL\` ,\`APP_POINT\`.\`MARKET_ID\` as \`APP_POINT_MARKET_ID\` ,\`APP_POINT\`.\`SUMMARY_TIME\` as \`APP_POINT_SUMMARY_TIME\` ,\`APP_USER_BASE_INFO\`.\`GENDER\` as \`APP_USER_BASE_INFO_GENDER\` ,\`APP_USER_BASE_INFO\`.\`BIRTH_TIME\` as \`APP_USER_BASE_INFO_BIRTH_TIME\` ,\`APP_USER_BASE_INFO\`.\`IS_HAVE_CHILD\` as \`APP_USER_BASE_INFO_IS_HAVE_CHILD\` ,\`APP_USER_BASE_INFO\`.\`MEMBER_TYPE\` as \`APP_USER_BASE_INFO_MEMBER_TYPE\` ,\`APP_USER_BASE_INFO\`.\`IS_NEW_MEMBER\` as \`APP_USER_BASE_INFO_IS_NEW_MEMBER\` ,\`APP_USER_BASE_INFO\`.\`IS_HAVE_CAR\` as \`APP_USER_BASE_INFO_IS_HAVE_CAR\` ,\`APP_USER_BASE_INFO\`.\`VIP_LEVEL\` as \`APP_USER_BASE_INFO_VIP_LEVEL\` ,\`APP_POINT\`.\`POINT\` as \`APP_POINT_POINT\` FROM \`HST_APP\`.\`APP_POINT\` as \`APP_POINT\` INNER JOIN \`HST_APP\`.\`APP_USER_BASE_INFO\` as \`APP_USER_BASE_INFO\` ON \`APP_POINT\`.\`MID\` = \`APP_USER_BASE_INFO\`.\`MID\` WHERE 1=1 AND (\`APP_POINT\`.\`SUMMARY_TIME\` >= '2020-12-01' AND \`APP_POINT\`.\`SUMMARY_TIME\` < '2021-02-01') ; " --hiveconf hive.auto.convert.join=true --hiveconf dfs.replication=2 --hiveconf hive.auto.convert.join.noconditionaltask=true --hiveconf hive.merge.mapfiles=false --hiveconf mapreduce.reduce.java.opts=-Xms6g --hiveconf mapreduce.map.memory.mb=8192 --hiveconf hive.merge.mapredfiles=false --hiveconf mapreduce.reduce.input.buffer.percent=0.5 --hiveconf hive.exec.compress.output=true --hiveconf mapreduce.reduce.memory.mb=16384 --hiveconf mapreduce.job.split.metainfo.maxsize=-1 --hiveconf mapreduce.map.java.opts=-Xms3g --hiveconf hive.auto.convert.join.noconditionaltask.size=100000000 --hiveconf hive.stats.autogather=true
1. 常见问题
兼容性问题
apache-kylin-3.0.2、 apache-hive-3.1.2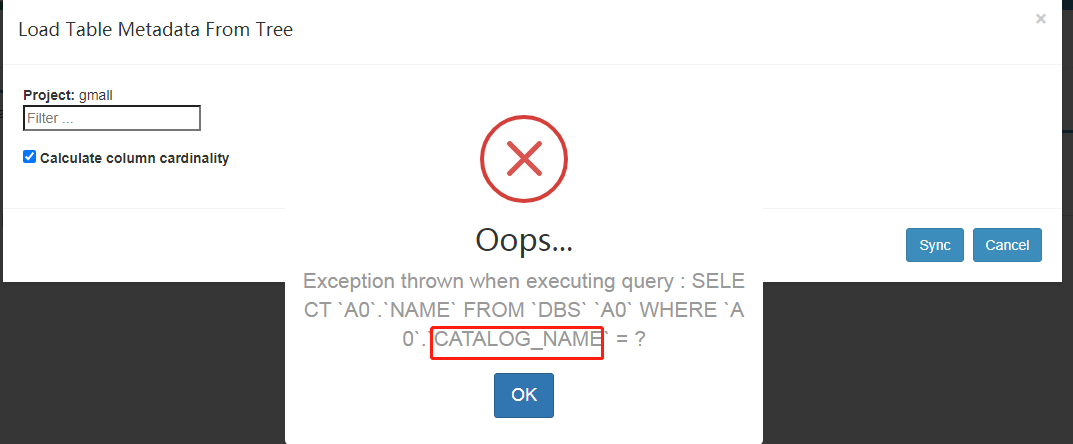
它去读取Hive的原数据,发现没有CATALOG_NAME:
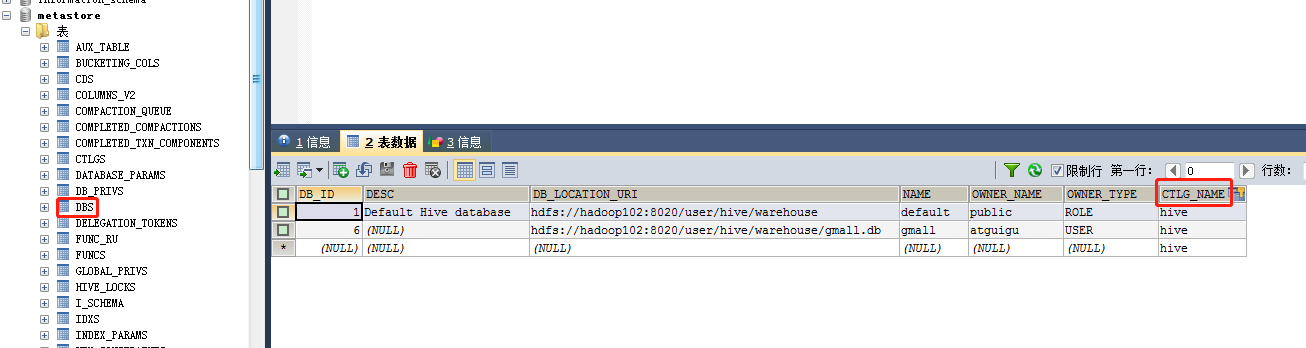
解决方法:1)修改源码 或者
Hive访问元数据必须采用metastore的方式,即保证以下两点:
① 保证hive-site.xml文件有以下参数: 否则它就会去获取myslq中的元数据。
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop101:9083</value>
</property>
②启动hive metastore服务
hive --service metastore
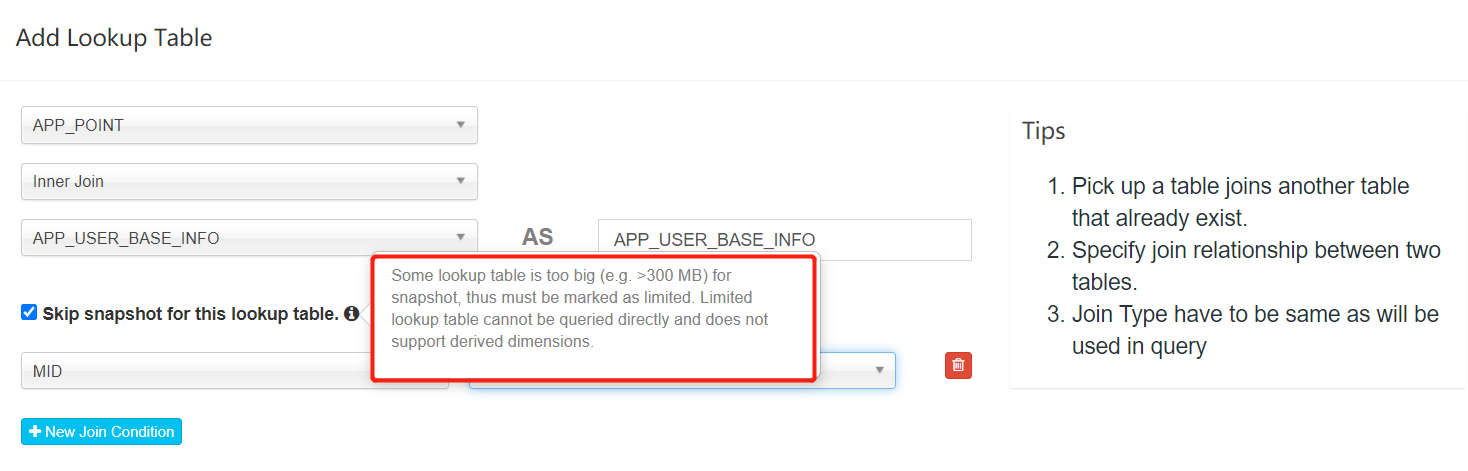
Skip snapshot for this lookup table.
(Some lookup table is too big eg. > 300MB for snapshot,thus must be marked as limited. Limited lookup table cannot be queried directly and does not support derived dimensions. )
如果维度表超过了300M,没有勾选Skip snapshot,在cube构建时就会报错:
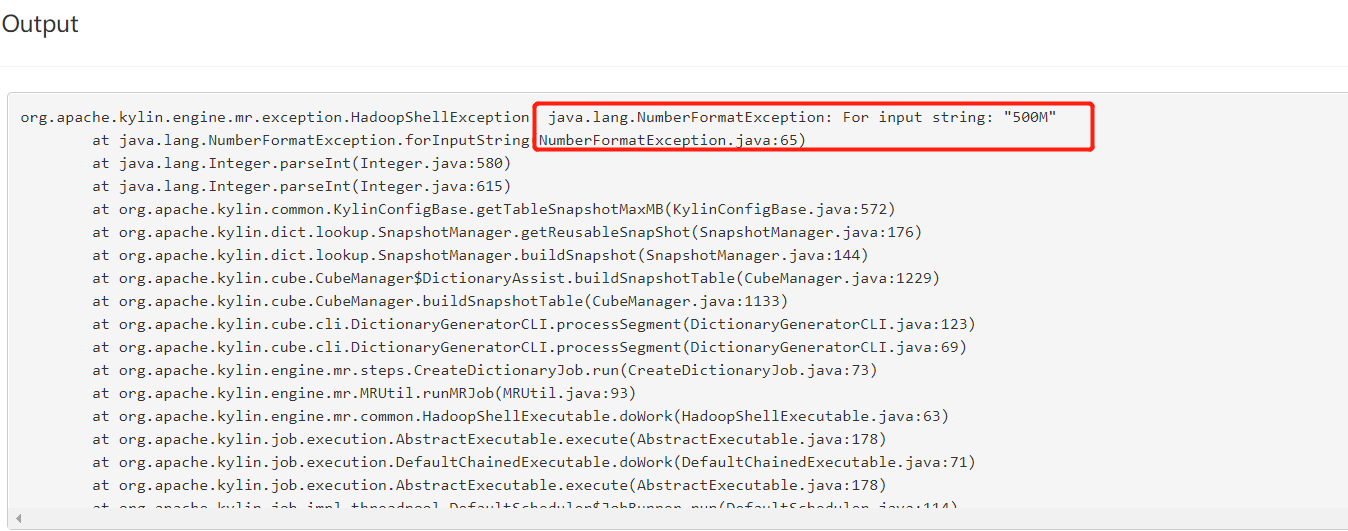
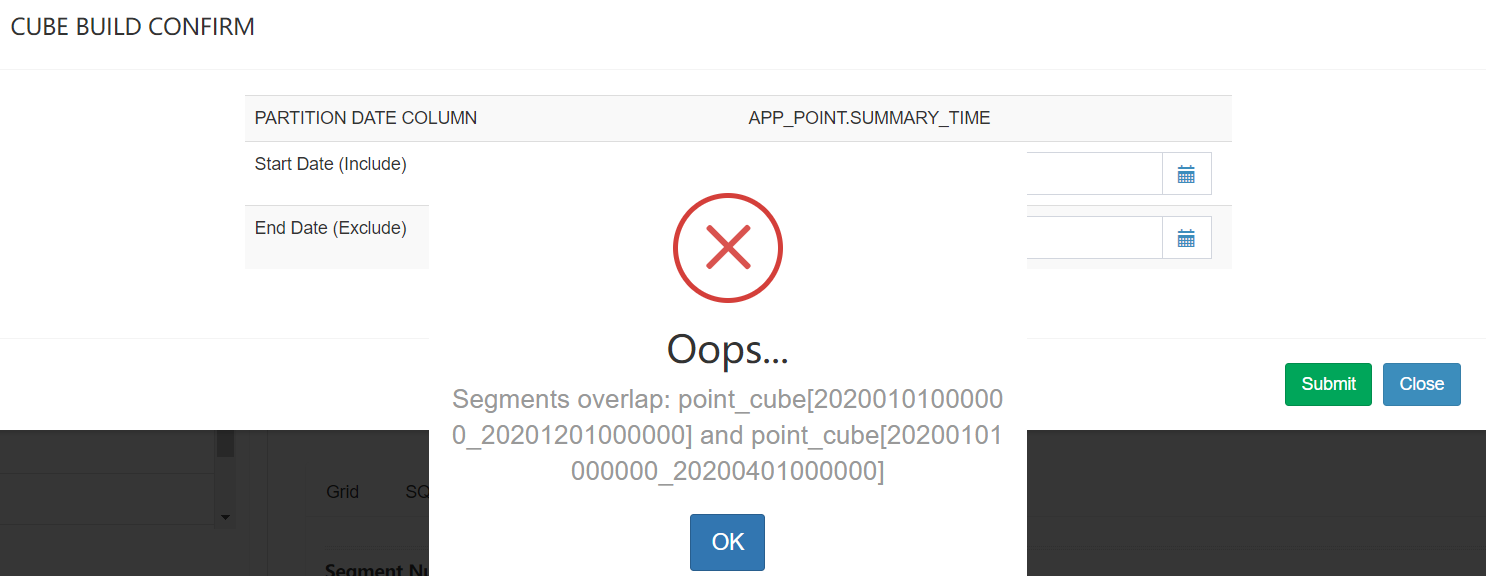
tail -f kylin.log #监控kylin.log日志
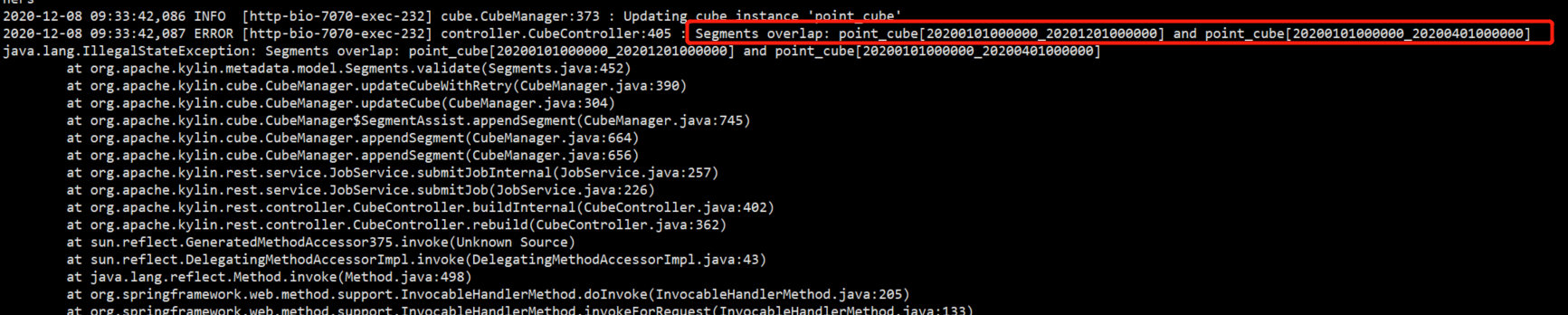
以上错误是两个Segments overlap 构建的时间维度有重合了。
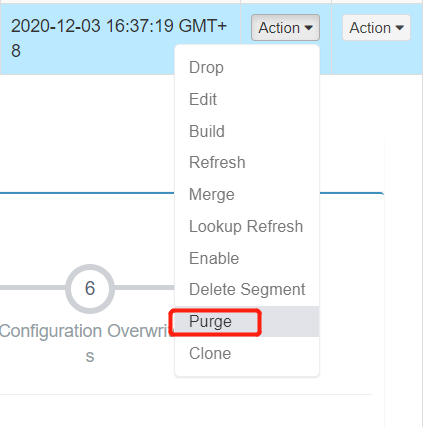
解决方法:
进行refresh
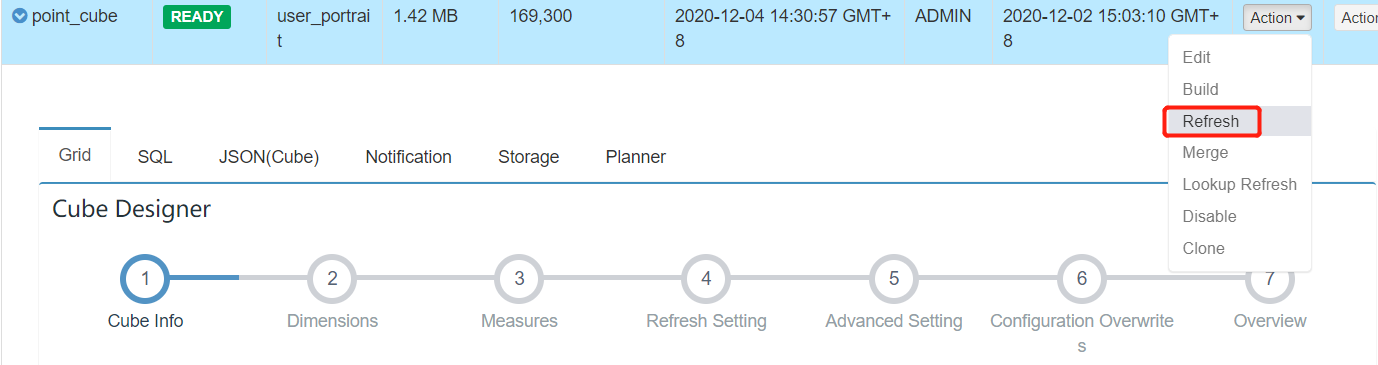
或者 将状态 从READY 变成 DISABLE 后进行清除Purge 重新构建
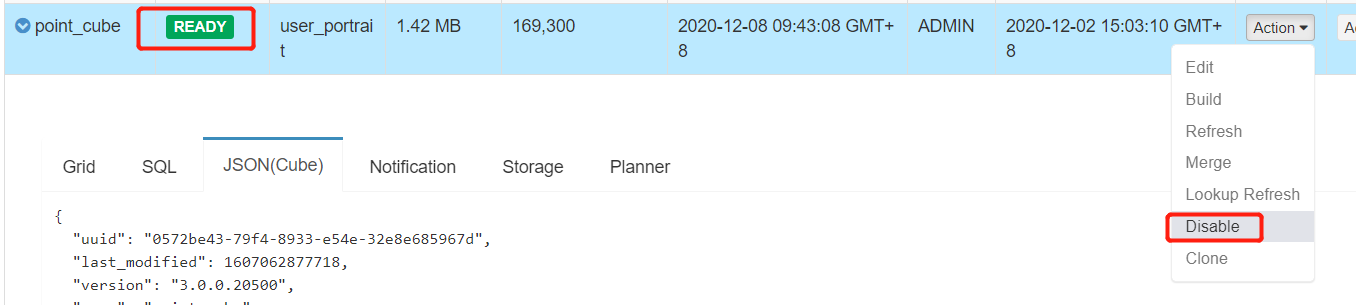
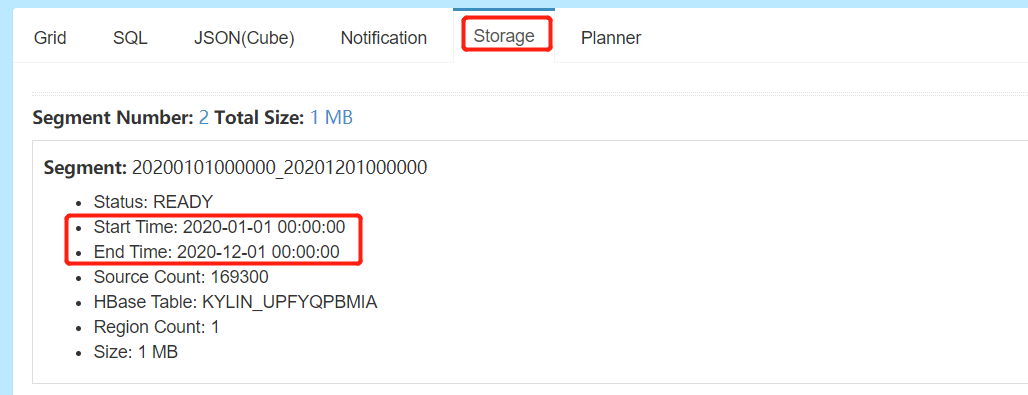
页面中的Storage记录了 每次Segment的记录
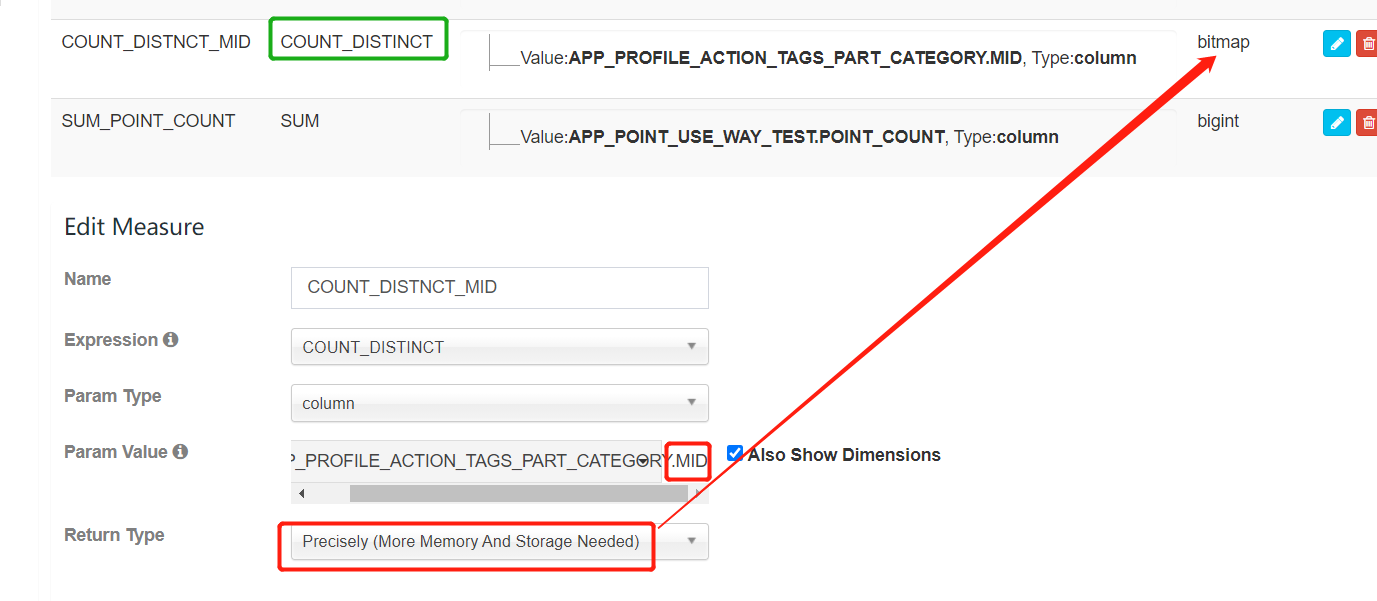
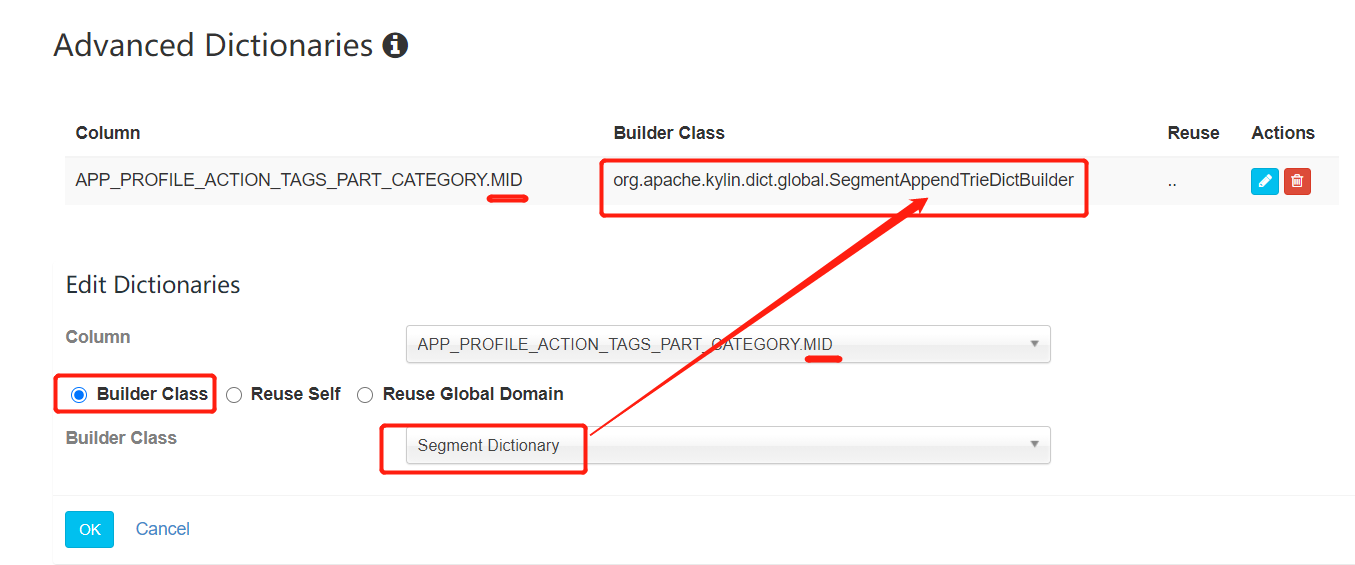
2. BitMap的使用
http://kylin.apache.org/cn/docs/howto/howto_use_hive_mr_dict.html
Count distinct(bitmap) 度量对于许多场景来说都非常重要, 比如统计点击量, kylin从1.5.3版本开始支持精确去重.
Apache Kylin 实现了基于bitmap的精确去重, 并且使用全局字典将字符串类型编码为整数类型。当前的全局字典是单线程构建的,对于高基列可能会占用大量的时间和内存。
Kylin v3.0.0 引入了第一版的 Hive global dictionary(KYLIN-3841). 这个功能使用Hive的分布式SQL引擎来构建全局字典。
为了进一步提升性能, kylin v3.1.0 引入了第二版的Hive global dictionary v2(KYLIN-4342), 这个版本在某些步骤使用MapReduce代替HQL进行全局字典的构建。
收益
1.使用分布式的方式来构建全局字典,节省时间。
2.Kylin集群中的Job Server可以做更少的工作, 因此会更加稳定。
3.OneID, Hive Global Dictionary在kylin之外仍然具有可读性,因此每个人都可以在公司其他场景中重用这个字典。
cubes的sql如下:
SELECT `APP_PROFILE_ACTION_TAGS_PART_CATEGORY`.`MARKET_ID` as `APP_PROFILE_ACTION_TAGS_PART_CATEGORY_MARKET_ID` ,`APP_PROFILE_ACTION_TAGS_PART_CATEGORY`.`TAG_KEY` as `APP_PROFILE_ACTION_TAGS_PART_CATEGORY_TAG_KEY` ,`APP_PROFILE_ACTION_TAGS_PART_CATEGORY`.`TAG_TYPE` as `APP_PROFILE_ACTION_TAGS_PART_CATEGORY_TAG_TYPE` ,`APP_PROFILE_ACTION_TAGS_PART_CATEGORY`.`TAG_VALUE` as `APP_PROFILE_ACTION_TAGS_PART_CATEGORY_TAG_VALUE` ,`APP_PROFILE_ACTION_TAGS_PART_CATEGORY`.`TAG_WEIGHT` as `APP_PROFILE_ACTION_TAGS_PART_CATEGORY_TAG_WEIGHT` ,`APP_POINT_USE_WAY_TEST`.`POINT_COUNT` as `APP_POINT_USE_WAY_TEST_POINT_COUNT` ,`APP_POINT_USE_WAY_TEST`.`CHANNEL` as `APP_POINT_USE_WAY_TEST_CHANNEL` ,`APP_PROFILE_ACTION_TAGS_PART_CATEGORY`.`MID` as `APP_PROFILE_ACTION_TAGS_PART_CATEGORY_MID` FROM `HST_APP`.`APP_PROFILE_ACTION_TAGS_PART_CATEGORY` as `APP_PROFILE_ACTION_TAGS_PART_CATEGORY` LEFT JOIN `HST_APP`.`APP_POINT_USE_WAY_TEST` as `APP_POINT_USE_WAY_TEST` ON `APP_PROFILE_ACTION_TAGS_PART_CATEGORY`.`MID` = `APP_POINT_USE_WAY_TEST`.`MID` WHERE 1=1
Monitor的jobs工作过程如下:
USE default; DROP TABLE IF EXISTS kylin_intermediate_midbitmap_3a2a2ec7_c7d7_b5ea_34cc_19b581afe9c0; CREATE EXTERNAL TABLE IF NOT EXISTS kylin_intermediate_midbitmap_3a2a2ec7_c7d7_b5ea_34cc_19b581afe9c0 ( \`APP_PROFILE_ACTION_TAGS_PART_CATEGORY_MARKET_ID\` bigint ,\`APP_PROFILE_ACTION_TAGS_PART_CATEGORY_TAG_KEY\` string ,\`APP_PROFILE_ACTION_TAGS_PART_CATEGORY_TAG_TYPE\` string ,\`APP_PROFILE_ACTION_TAGS_PART_CATEGORY_TAG_VALUE\` string ,\`APP_PROFILE_ACTION_TAGS_PART_CATEGORY_TAG_WEIGHT\` decimal(32,10) ,\`APP_POINT_USE_WAY_TEST_POINT_COUNT\` bigint ,\`APP_POINT_USE_WAY_TEST_CHANNEL\` bigint ,\`APP_PROFILE_ACTION_TAGS_PART_CATEGORY_MID\` string ) STORED AS SEQUENCEFILE LOCATION 'hdfs://nameservice1/kylin/kylin_metadata/kylin-0c6c73f4-9871-1f04-ccc2-2d276126b7cd/kylin_intermediate_midbitmap_3a2a2ec7_c7d7_b5ea_34cc_19b581afe9c0'; ALTER TABLE kylin_intermediate_midbitmap_3a2a2ec7_c7d7_b5ea_34cc_19b581afe9c0 SET TBLPROPERTIES('auto.purge'='true'); INSERT OVERWRITE TABLE \`kylin_intermediate_midbitmap_3a2a2ec7_c7d7_b5ea_34cc_19b581afe9c0\` SELECT \`APP_PROFILE_ACTION_TAGS_PART_CATEGORY\`.\`MARKET_ID\` as \`APP_PROFILE_ACTION_TAGS_PART_CATEGORY_MARKET_ID\` ,\`APP_PROFILE_ACTION_TAGS_PART_CATEGORY\`.\`TAG_KEY\` as \`APP_PROFILE_ACTION_TAGS_PART_CATEGORY_TAG_KEY\` ,\`APP_PROFILE_ACTION_TAGS_PART_CATEGORY\`.\`TAG_TYPE\` as \`APP_PROFILE_ACTION_TAGS_PART_CATEGORY_TAG_TYPE\` ,\`APP_PROFILE_ACTION_TAGS_PART_CATEGORY\`.\`TAG_VALUE\` as \`APP_PROFILE_ACTION_TAGS_PART_CATEGORY_TAG_VALUE\` ,\`APP_PROFILE_ACTION_TAGS_PART_CATEGORY\`.\`TAG_WEIGHT\` as \`APP_PROFILE_ACTION_TAGS_PART_CATEGORY_TAG_WEIGHT\` ,\`APP_POINT_USE_WAY_TEST\`.\`POINT_COUNT\` as \`APP_POINT_USE_WAY_TEST_POINT_COUNT\` ,\`APP_POINT_USE_WAY_TEST\`.\`CHANNEL\` as \`APP_POINT_USE_WAY_TEST_CHANNEL\` ,\`APP_PROFILE_ACTION_TAGS_PART_CATEGORY\`.\`MID\` as \`APP_PROFILE_ACTION_TAGS_PART_CATEGORY_MID\` FROM \`HST_APP\`.\`APP_PROFILE_ACTION_TAGS_PART_CATEGORY\` as \`APP_PROFILE_ACTION_TAGS_PART_CATEGORY\` LEFT JOIN \`HST_APP\`.\`APP_POINT_USE_WAY_TEST\` as \`APP_POINT_USE_WAY_TEST\` ON \`APP_PROFILE_ACTION_TAGS_PART_CATEGORY\`.\`MID\` = \`APP_POINT_USE_WAY_TEST\`.\`MID\` WHERE 1=1; " --hiveconf hive.auto.convert.join=true --hiveconf dfs.replication=2 --hiveconf hive.auto.convert.join.noconditionaltask=true --hiveconf hive.merge.mapfiles=false --hiveconf mapreduce.reduce.java.opts=-Xms6g --hiveconf mapreduce.map.memory.mb=8192 --hiveconf hive.merge.mapredfiles=false --hiveconf mapreduce.reduce.input.buffer.percent=0.5 --hiveconf hive.exec.compress.output=true --hiveconf mapreduce.reduce.memory.mb=16384 -- hiveconf mapreduce.job.split.metainfo.maxsize=-1 --hiveconf mapreduce.map.java.opts=-Xms3g --hiveconf hive.auto.convert.join.noconditionaltask.size=100000000 --hiveconf hive.stats.autogather=true USE default; set hive.exec.compress.output=false; set hive.mapred.mode=unstrict; CREATE TABLE IF NOT EXISTS default.MidBitMap_global_dict ( dict_key STRING COMMENT '', dict_val INT COMMENT '' ) COMMENT 'Hive Global Dictionary' PARTITIONED BY (dict_column string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE; DROP TABLE IF EXISTS kylin_intermediate_midbitmap_3a2a2ec7_c7d7_b5ea_34cc_19b581afe9c0__distinct_value; CREATE TABLE IF NOT EXISTS kylin_intermediate_midbitmap_3a2a2ec7_c7d7_b5ea_34cc_19b581afe9c0__distinct_value ( dict_key STRING COMMENT '' ) COMMENT '' PARTITIONED BY (dict_column string) STORED AS TEXTFILE ; DROP TABLE IF EXISTS kylin_intermediate_midbitmap_3a2a2ec7_c7d7_b5ea_34cc_19b581afe9c0_global_dict; CREATE TABLE IF NOT EXISTS kylin_intermediate_midbitmap_3a2a2ec7_c7d7_b5ea_34cc_19b581afe9c0_global_dict ( dict_key STRING COMMENT '' , dict_val STRING COMMENT '' ) COMMENT '' PARTITIONED BY (dict_column string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE ; INSERT OVERWRITE TABLE kylin_intermediate_midbitmap_3a2a2ec7_c7d7_b5ea_34cc_19b581afe9c0__distinct_value PARTITION (dict_column = 'APP_PROFILE_ACTION_TAGS_PART_CATEGORY_MID') SELECT a.DICT_KEY FROM (SELECT APP_PROFILE_ACTION_TAGS_PART_CATEGORY_MID as DICT_KEY FROM kylin_intermediate_midbitmap_3a2a2ec7_c7d7_b5ea_34cc_19b581afe9c0 GROUP BY APP_PROFILE_ACTION_TAGS_PART_CATEGORY_MID) a LEFT JOIN (SELECT DICT_KEY FROM default.MidBitMap_global_dict WHERE DICT_COLUMN = 'APP_PROFILE_ACTION_TAGS_PART_CATEGORY_MID' ) b ON a.DICT_KEY = b.DICT_KEY WHERE b.DICT_KEY IS NULL ; INSERT OVERWRITE TABLE kylin_intermediate_midbitmap_3a2a2ec7_c7d7_b5ea_34cc_19b581afe9c0__distinct_value PARTITION (DICT_COLUMN = 'KYLIN_MAX_DISTINCT_COUNT') SELECT CONCAT_WS(',', tc.dict_column, cast(tc.total_distinct_val AS String), if(tm.max_dict_val is null, '0', cast(max_dict_val as string))) FROM ( SELECT dict_column, count(1) total_distinct_val FROM default.kylin_intermediate_midbitmap_3a2a2ec7_c7d7_b5ea_34cc_19b581afe9c0__distinct_value WHERE DICT_COLUMN != 'KYLIN_MAX_DISTINCT_COUNT' GROUP BY dict_column) tc LEFT JOIN ( SELECT dict_column, if(max(dict_val) is null, 0, max(dict_val)) as max_dict_val FROM default.MidBitMap_global_dict GROUP BY dict_column) tm ON tc.dict_column = tm.dict_column; " --hiveconf hive.auto.convert.join=true --hiveconf dfs.replication=2 --hiveconf hive.auto.convert.join.noconditionaltask=true --hiveconf hive.merge.mapfiles=false --hiveconf mapreduce.reduce.java.opts=-Xms6g --hiveconf mapreduce.map.memory.mb=8192 --hiveconf hive.merge.mapredfiles=false --hiveconf mapreduce.reduce.input.buffer.percent=0.5 --hiveconf hive.exec.compress.output=true --hiveconf mapreduce.reduce.memory.mb=16384 --hiveconf mapreduce.job.split.metainfo.maxsize=-1 --hiveconf mapreduce.map.java.opts=-Xms3g --hiveconf hive.auto.convert.join.noconditionaltask.size=100000000 --hiveconf hive.stats.autogather=true USE default; set mapreduce.job.reduces=25; set hive.merge.mapredfiles=false; INSERT OVERWRITE TABLE \`kylin_intermediate_midbitmap_3a2a2ec7_c7d7_b5ea_34cc_19b581afe9c0\` SELECT * FROM \`kylin_intermediate_midbitmap_3a2a2ec7_c7d7_b5ea_34cc_19b581afe9c0\` DISTRIBUTE BY APP_PROFILE_ACTION_TAGS_ PART_CATEGORY_MARKET_ID,APP_PROFILE_ACTION_TAGS_PART_CATEGORY_TAG_KEY,APP_PROFILE_ACTION_TAGS_PART_CATEGORY_TAG_TYPE; " --hiveconf hive.auto.convert.join=true --hiveconf dfs.replication=2 --hiveconf hive.auto.convert.join.noconditionaltask=true --hiveconf hive.merge.mapfiles=false --hiveconf mapreduce.reduce.java.opts=-Xms6g --hiveconf mapreduce.map.memory.mb=8192 --hiveconf hive.merge.mapredfiles=false --hiveconf mapreduce.reduce.input.buffer.percent=0.5 --hiveconf hive.exec.compress.output=true --hiveconf mapreduce.reduce.memory.mb=16384 --hiveconf mapreduce.job.split.metainfo.maxsize=-1 --hiveconf mapreduce.map.java.opts=-Xms3g --hiveconf hive.auto.convert.join.noconditionaltask.size=100000000 --hiveconf hive.stats.autogather=true USE default; set hive.mapred.mode=unstrict; ALTER TABLE kylin_intermediate_midbitmap_3a2a2ec7_c7d7_b5ea_34cc_19b581afe9c0_global_dict ADD IF NOT EXISTS PARTITION (dict_column='APP_PROFILE_ACTION_TAGS_PART_CATEGORY_MID'); INSERT OVERWRITE TABLE default.MidBitMap_global_dict PARTITION (dict_column = 'APP_PROFILE_ACTION_TAGS_PART_CATEGORY_MID') SELECT dict_key, dict_val FROM default.MidBitMap_global_dict WHERE dict_column = 'APP_PROFILE_ACTION_TAGS_PART_CATEGORY_MID' UNION ALL SELECT dict_key, dict_val FROM kylin_intermediate_midbitmap_3a2a2ec7_c7d7_b5ea_34cc_19b581afe9c0_global_dict WHERE dict_column = 'APP_PROFILE_ACTION_TAGS_PART_CATEGORY_MID' ; " --hiveconf hive.auto.convert.join=true --hiveconf dfs.replication=2 --hiveconf hive.auto.convert.join.noconditionaltask=true --hiveconf hive.merge.mapfiles=false --hiveconf mapreduce.reduce.java.opts=-Xms6g --hiveconf mapreduce.map.memory.mb=8192 --hiveconf hive.merge.mapredfiles=false --hiveconf mapreduce.reduce.input.buffer.percent=0.5 --hiveconf hive.exec.compress.output=true --hiveconf mapreduce.reduce.memory.mb=16384 --hiveconf mapreduce.job.split.metainfo.maxsize=-1 --hiveconf mapreduce.map.java.opts=-Xms3g --hiveconf hive.auto.convert.join.noconditionaltask.size=100000000 --hiveconf hive.stats.autogather=true USE default; set hive.exec.compress.output=false; set hive.mapred.mode=unstrict; INSERT OVERWRITE TABLE default.kylin_intermediate_midbitmap_3a2a2ec7_c7d7_b5ea_34cc_19b581afe9c0 SELECT a.APP_PROFILE_ACTION_TAGS_PART_CATEGORY_MARKET_ID ,a.APP_PROFILE_ACTION_TAGS_PART_CATEGORY_TAG_KEY ,a.APP_PROFILE_ACTION_TAGS_PART_CATEGORY_TAG_TYPE ,a.APP_PROFILE_ACTION_TAGS_PART_CATEGORY_TAG_VALUE ,a.APP_PROFILE_ACTION_TAGS_PART_CATEGORY_TAG_WEIGHT ,a.APP_POINT_USE_WAY_TEST_POINT_COUNT ,a.APP_POINT_USE_WAY_TEST_CHANNEL ,b.dict_val FROM default.kylin_intermediate_midbitmap_3a2a2ec7_c7d7_b5ea_34cc_19b581afe9c0 a LEFT OUTER JOIN (SELECT dict_key, dict_val FROM default.MidBitMap_global_dict WHERE dict_column = 'APP_PROFILE_ACTION_TAGS_PART_CATEGORY_MID') b ON a.APP_PROFILE_ACTION_TAGS_PART_CATEGORY_MID = b.dict_key; " --hiveconf hive.auto.convert.join=true --hiveconf dfs.replication=2 --hiveconf hive.auto.convert.join.noconditionaltask=true --hiveconf hive.merge.mapfiles=false --hiveconf mapreduce.reduce.java.opts=-Xms6g --hiveconf mapreduce.map.memory.mb=8192 --hiveconf hive.merge.mapredfiles=false --hiveconf mapreduce.reduce.input.buffer.percent=0.5 --hiveconf hive.exec.compress.output=true --hiveconf mapreduce.reduce.memory.mb=16384 --hiveconf mapreduce.job.split.metainfo.maxsize=-1 --hiveconf mapreduce.map.java.opts=-Xms3g --hiveconf hive.auto.convert.join.noconditionaltask.size=100000000 --hiveconf hive.stats.autogather=true
Kylin常用函数:
intersect_value 和 intersect_count
select market_id, intersect_value(mid,tag_value,array['女']) as arr_mid_bitmap from APP_PROFILE_ACTION_TAGS_PART_CATEGORY where tag_type = 'gender' and tag_value = '女' group by market_id --- 132 [119787,119798,119823] 164 [136555,140549,141655,145728,145729,145796,14580,1639794] 213 [632938,635520,644039] 150 [588915,1328378] select market_id, intersect_count(mid,tag_value,array['女']) as arr_mid_bitmap from APP_PROFILE_ACTION_TAGS_PART_CATEGORY where tag_type = 'gender' and tag_value = '女' group by market_id -- 132 3 164 8
213 3
150 2



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人