
数据结构 |Redis中数据类型对应的数据结构
Redis
Redis 是一种键值(Key-Value)数据库。相对于关系型数据库(比如 MySQL),Redis 也被叫作非关系型数据库。
像 MySQL 这样的关系型数据库,表的结构比较复杂,会包含很多字段,可以通过 SQL 语句,来实现非常复杂的查询需求。而 Redis 中只包含“键”和“值”两部分,只能通过“键”来查询“值”。正是因为这样简单的存储结构,也让 Redis 的读写效率非常高。
Redis 主要是作为内存数据库来使用,也就是说,数据是存储在内存中的。尽管它经常被用作内存数据库,但是,它也支持将数据存储在硬盘中。
Redis 中,键的数据类型是字符串,值的数据类型有很多,常用的数据类型有字符串、列表、字典、集合、有序集合。
1. 字符串(string)
“字符串(string)”这种数据类型非常简单,对应到数据结构里,就是字符串。
2. 列表(list)
列表这种数据类型支持存储一组数据。这种数据类型对应两种实现方法,一种是压缩列表(ziplist),另一种是双向循环链表。
① 当列表中存储的数据量比较小的时候,列表就可以采用压缩列表的方式实现。具体需要同时满足下面两个条件:
-
列表中保存的单个数据(有可能是字符串类型的)小于 64 字节;
-
列表中数据个数少于 512 个。
关于压缩列表,它并不是基础数据结构,而是 Redis 自己设计的一种数据存储结构。它有点儿类似数组,通过一片连续的内存空间,来存储数据。不过,它跟数组不同的一点是,它允许存储的数据大小不同。具
体的存储结构也非常简单。
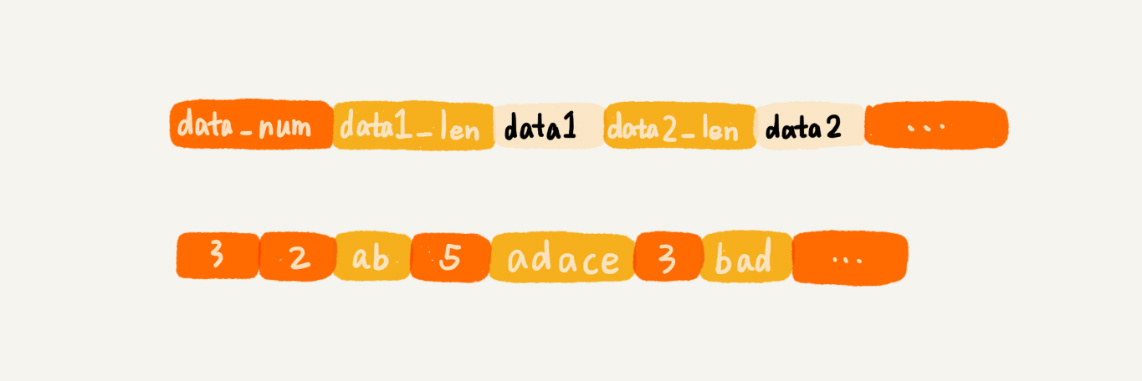
压缩列表中的“压缩”两个字该如何理解 ?
听到“压缩”两个字,直观的反应就是节省内存。之所以说这种存储结构节省内存,是相较于数组的存储思路而言的。数组要求每个元素的大小相同,如果要存储不同长度的字符串,那就需要
用最大长度的字符串大小作为元素的大小(假设是 20 个字节)。当存储小于 20 个字节长度的字符串的时候,便会浪费部分存储空间。
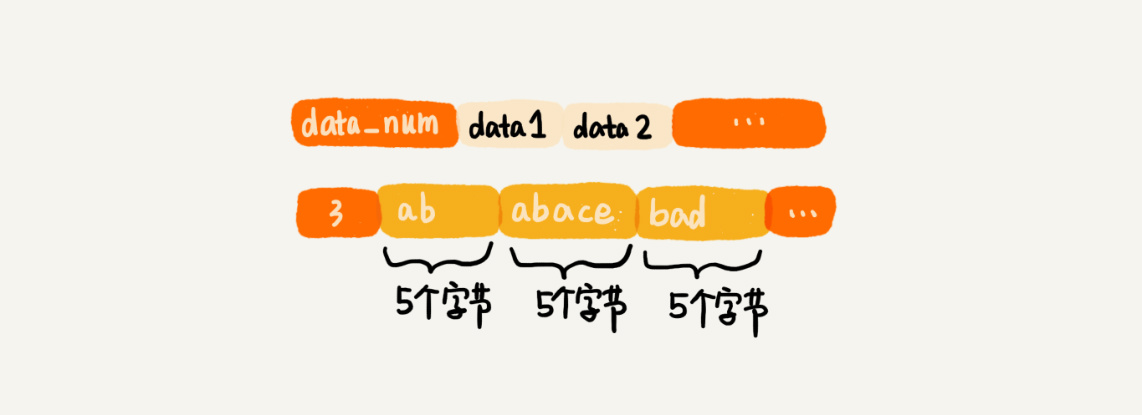
压缩列表这种存储结构,一方面比较节省内存,另一方面可以支持不同类型数据的存储。而且,因为数据存储在一片连续的内存空间,通过键来获取值为列表类型的数据,读取的效率也非常高。
② 当列表中存储的数据量比较大的时候,也就是不能同时满足刚刚讲的两个条件的时候,列表就要通过双向循环链表来实现了。
双向循环链表这种数据结构了见之前。这里着重看一下 Redis 中双向链表的编码实现方式。
Redis 的这种双向链表的实现方式,非常值得借鉴。它额外定义一个 list 结构体,来组织链表的首、尾指针,还有长度等信息。这样,在使用的时候就会非常方便。

// 以下是 C 语言代码,因为 Redis 是用 C 语言实现的。
typedef struct listnode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
typedef struct list {
listNode *head;
listNode *tail;
unsigned long len;
// .... 省略其他定义
} list;
3. 字典(hash)
字典类型用来存储一组数据对。每个数据对又包含键值两部分。字典类型也有两种实现方式。一种是压缩列表,另一种是散列表。
① 当存储的数据量较小时,Redis 才使用压缩列表来实现字典类型。具体需要满足两个条件:
-
字典中保存的键和值的大小都要小于 64 字节;
-
字典中键值对的个数要小于 512 个。
② 当不能同时满足上面两个条件的时候,Redis 就使用散列表来实现字典类型。Redis 使用MurmurHash2这种运行速度快、随机性好的哈希算法作为哈希函数。对于哈希冲突问题,Redis 使用链表法来解决。除此之外,Redis 还支持散列表的动态扩容、缩容。
当数据动态增加之后,散列表的装载因子会不停地变大。为了避免散列表性能的下降,当装载因子大于 1 的时候,Redis 会触发扩容,将散列表扩大为原来大小的 2 倍左右(具体值需要计算才能得到,如果感兴趣,可以去阅读源码)。
当数据动态减少之后,为了节省内存,当装载因子小于 0.1 的时候,Redis 就会触发缩容,缩小为字典中数据个数的大约 2 倍大小(这个值也是计算得到的,可以去阅读源码)。
扩容缩容要做大量的数据搬移和哈希值的重新计算,所以比较耗时。针对这个问题,Redis 使用我们在散列表(中)的渐进式扩容缩容策略,将数据的搬移分批进行,避免了大量数据一次性搬移导致的服务停顿。
4. 集合(set)
集合这种数据类型用来存储一组不重复的数据。这种数据类型也有两种实现方法,一种是基于有序数组,另一种是基于散列表。
① 当要存储的数据,同时满足下面这样两个条件的时候,Redis 就采用有序数组,来实现集合这种数据类型。
-
存储的数据都是整数;
-
存储的数据元素个数不超过 512 个。
② 当不能同时满足这两个条件的时候,Redis 就使用散列表来存储集合中的数据。
5. 有序集合(sortedset)zset
有序集合这种数据类型,见跳表。它用来存储一组数据,并且每个数据会附带一个得分。通过得分的大小,将数据组织成跳表这样的数据结构,以支持快速地按照得分值、得分区间获取数据。
② 实际上,跟 Redis 的其他数据类型一样,有序集合也并不仅仅只有跳表这一种实现方式。
① 当数据量比较小的时候,Redis 会用压缩列表来实现有序集合。具体点说就是,使用压缩列表来实现有序集合的前提,有这样两个:
-
所有数据的大小都要小于 64 字节;
-
元素个数要小于 128 个。
数据结构持久化
尽管 Redis 经常会被用作内存数据库,但是,它也支持数据落盘,也就是将内存中的数据存储到硬盘中。这样,当机器断电的时候,存储在 Redis 中的数据也不会丢失。在机器重新启动之后,Redis 只需要再将
存储在硬盘中的数据,重新读取到内存,就可以继续工作了。
Redis 的数据格式由“键”和“值”两部分组成。而“值”又支持很多数据类型,比如字符串、列表、字典、集合、有序集合。像字典、集合等类型。 底层用到了散列表,散列表中有指针的概念,而指针指向的是内存
中的存储地址。 那 Redis 是如何将这样一个跟具体内存地址有关的数据结构存储到磁盘中的呢?
实际上,Redis 遇到的这个问题并不特殊,很多场景中都会遇到。把它叫作数据结构的持久化问题,或者对象的持久化问题。这里的“持久化”,可以笼统地可以理解为“存储到磁盘”。
如何将数据结构持久化到硬盘?主要有两种解决思路:
第一种是清除原有的存储结构,只将数据存储到磁盘中。当需要从磁盘还原数据到内存的时候,再重新将数据组织成原来的数据结构。实际上,Redis 采用的就是这种持久化思路。
不过,这种方式也有一定的弊端。那就是数据从硬盘还原到内存的过程,会耗用比较多的时间。比如,我们现在要将散列表中的数据存储到磁盘。当我们从磁盘中,取出数据重新构建散列表的时候,需要重新计
算每个数据的哈希值。如果磁盘中存储的是几 GB 的数据,那重构数据结构的耗时就不可忽视了。
第二种方式是保留原来的存储格式,将数据按照原有的格式存储在磁盘中。比如散列表这样的数据结构可以将散列表的大小、每个数据被散列到的槽的编号等信息,都保存在磁盘中。有了这些信息,从磁盘中将
数据还原到内存中的时候,就可以避免重新计算哈希值。
总结
Redis 中常用数据类型底层依赖的数据结构,五种:压缩列表(可以看作一种特殊的数组)、有序数组、链表、散列表、跳表。实际上,Redis 就是这些常用数据结构的封装。
你有没有发现,在数据量比较小的情况下,Redis 中的很多数据类型,比如字典、有序集合等,都是通过多种数据结构来实现的,为什么会这样设计呢?用一种固定的数据结构来实现,不是更加简单吗?
redis的数据结构由多种数据结构来实现,主要是出于时间和空间的考虑,当数据量小的时候通过数组下标访问最快、占用内存最小,而压缩列表只是数组的升级版;
因为数组需要占用连续的内存空间,所以当数据量大的时候,就需要使用链表了,同时为了保证速度又需要和数组结合,也就有了散列表。
对于数据的大小和多少采用哪种数据结构,相信redis团队一定是根据大多数的开发场景而定的。
数据结构持久化有两种方法。对于二叉查找树这种数据结构,我们如何将它持久化到磁盘中呢?
二叉查找树的存储,倾向于存储方式一,通过填充叶子节点形成完全二叉树,然后以数组的形式存储到硬盘,数据还原过程也是非常高效的。如果用存储方式二就比较复杂了。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2018-11-25 Practice| 面向对象
2018-11-25 JavaSE| 面向对象的三大特征