
数据结构-05 |散列表-③| 链表和散列表的组合使用
1. 链表和散列表的组合使用
散列表和链表,经常会被放在一起使用;
- 用链表来实现 LRU 缓存淘汰算法,时间复杂度是 O(n),通过散列表可以将这个时间复杂度降低到 O(1)。
- 跳表,Redis的有序集合是使用跳表来实现的,跳表可以看作一种改进版的链表。当时我们也提到,Redis 有序集合不仅使用了跳表,还用到了散列表。
- Java 编程语言,LinkedHashMap 这样一个常用的容器,也用到了散列表和链表两种数据结构。
1.1 基于链表+散列表实现的 LRU
通过链表如何实现 LRU 缓存淘汰算法
① 我们需要维护一个按照访问时间从大到小有序排列的链表结构。
② 因为缓存大小有限,当缓存空间不够,需要淘汰一个数据的时候,我们就直接将链表头部的结点删除。
③ 当要缓存某个数据的时候,先在链表中查找这个数据。如果没有找到,则直接将数据放到链表的尾部;如果找到了,我们就把它移动到链表的尾部。
因为查找数据需要遍历链表,所以单纯用链表实现的LRU缓存淘汰算法的时间复杂很高,是 O(n)。
一个缓存(cache)系统主要包含下面这几个操作:
- 往缓存中添加一个数据;
- 从缓存中删除一个数据;
- 在缓存中查找一个数据。
这三个操作都要涉及“查找”操作,如果单纯地采用链表的话,时间复杂度只能是 O(n)。如果将散列表和链表两种数据结构组合使用,可以将这三个操作的时间复杂度都降低到 O(1)。
具体存储结构如下:
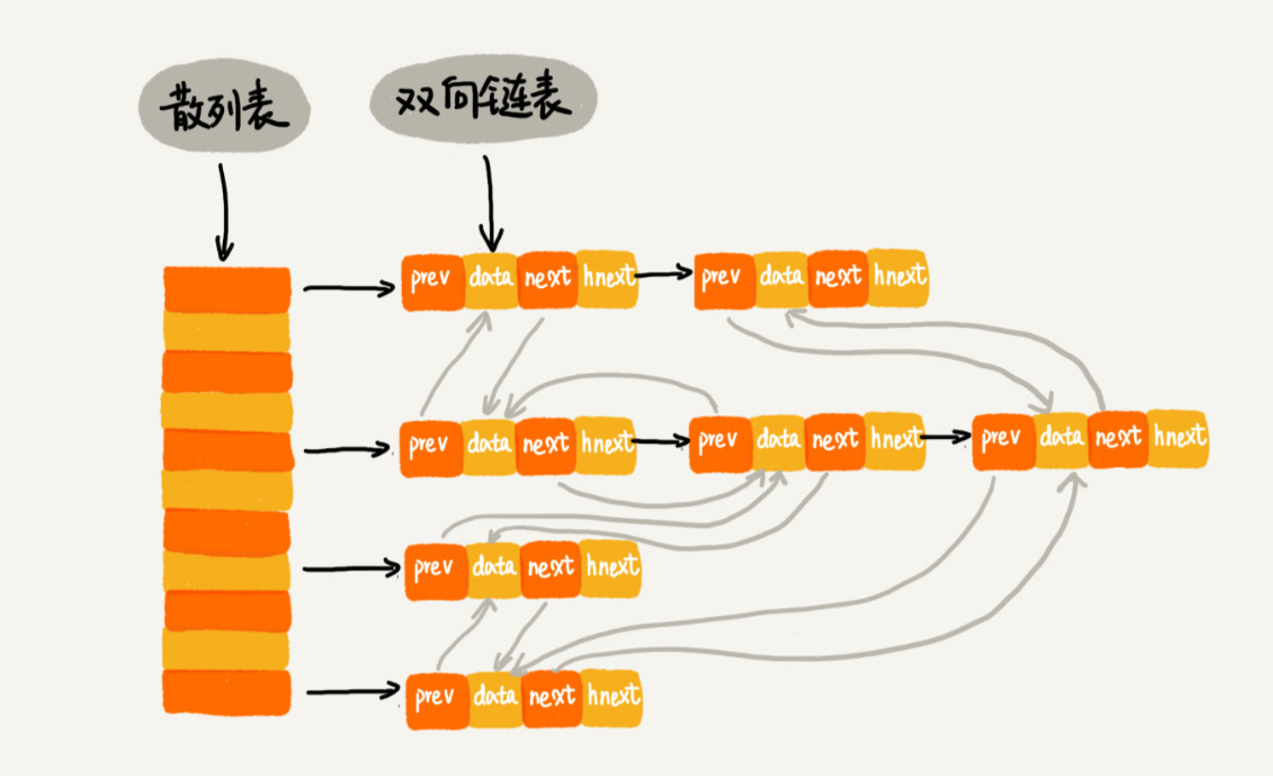
使用双向链表存储数据,链表中的每个结点处理存储数据(data)、前驱指针(prev)、 后继指针(next)之外,还新增了一个特殊的字段 hnext。这个 hnext 有什么作用呢?
因为散列表是通过链表法解决散列冲突的,所以每个结点会在两条链中。一个链是双向链表,另一个链是散列表中的拉链。
前驱和后继指针是为了将结点串在双向链表中,hnext 指针是为了将结点串在散列表的拉链中。
缓存的三个操作,它是如何做到时间复杂度是 O(1) 的?
- 首先,来看如何查找一个数据。散列表中查找数据的时间复杂度接近O(1),所以通过散列表,可以很快地在缓存中找到一个数据。当找到数据之后,还需要将它移动到双向链表的尾部。
- 其次,如何删除一个数据。我们需要找到数据所在的结点,然后将结点删除。借助散列表,可以在 O(1) 时间复杂度里找到要删除的结点。因为我们的链表是双向链表,双向链表可以通过前驱指针 O(1) 时间复杂度获取前驱结点,所以在双向链表中,删除结点只需要 O(1)的时间复杂度。
- 最后,来看如何添加一个数据。添加数据到缓存稍微有点麻烦,我们需要先看这个数据是否已经在缓存中。如果已经在其中,需要将其移动到双向链表的尾部;如果不在其中,还要看缓存有没有满。如果满了,则将双向链表头部的结点删除,然后再将数据放到链表的尾部;如果没有满,就直接将数据放到链表的尾部。
整个过程涉及的查找操作都可以通过散列表来完成。其他的操作,比如删除头结点、链表尾部插入数据等,都可以在 O(1) 的时间复杂度内完成。所以,这三个操作的时间复杂度都是 O(1)。至此,我们就通过散列表和双向链表的组合使用,实现了一个高效的、支持 LRU 缓存淘汰算法的缓存系统原型。
代码如下:
1.2 Redis 有序集合
有序集合中,每个成员对象有两个重要的属性,key(键值)和score(分值)。我们不仅会通过 score 来查找数据,还会通过 key 来查找数据。
比如用户积分排行榜有这样一个功能:我们可以通过用户的 ID 来查找积分信息,也可以通过积分区间来查找用户 ID 或者姓名信息。这里包含 ID、姓名和积分的用户信息,就是成员对象,用户 ID 就是 key,积分就是 score。
细化Redis 有序集合的操作,那就是下面这样:
- 添加一个成员对象;
- 按照键值来删除一个成员对象;
- 按照键值来查找一个成员对象;
- 按照分值区间查找数据,比如查找积分在 [100, 356] 之间的成员对象;
- 按照分值从小到大排序成员变量;
如果仅仅按照分值将成员对象组织成跳表的结构,那按照键值来删除、查询成员对象就会很慢,解决方法与 LRU 缓存淘汰算法的解决方法类似。我们可以再按照键值构建一个散列表,这样按照 key 来删除、查找一个成员对象的时间复杂度就变成了 O(1)。同时,借助跳表结构,其他操作也非常高效。
实际上,Redis 有序集合的操作还有另外一类,也就是查找成员对象的排名(Rank)或者根据排名区间查找成员对象。这个功能单纯用刚刚讲的这种组合结构就无法高效实现了。
1.3 Java LinkedHashMap
HashMap 底层是通过散列表这种数据结构实现的。而 LinkedHashMap 前面比 HashMap 多了一个“Linked”,这里的“Linked”是不是说,LinkedHashMap 是一个通过链表法解决散列冲突的散列表呢?实际上,LinkedHashMap 并没有这么简单,其中的“Linked”也并不仅仅代表它是通过链表法解决散列冲突的。关于这一点,初学者会有很多误解。
看下面这段代码会以什么样的顺序打印 3,1,5,2 这几个 key 呢?原因又是什么呢?
HashMap<Integer, Integer> m = new LinkedHashMap<>();
m.put(3, 11);
m.put(1, 12);
m.put(5, 23);
m.put(2, 22);
for (Map.Entry e : m.entrySet()) {
System.out.println(e.getKey());
}
上面的代码会按照数据插入的顺序依次来打印,也就是说,打印的顺序就是3,1,5,2。你有没有觉得奇怪?散列表中数据是经过散列函数打乱之后无规律存储的,这里
是如何实现按照数据的插入顺序来遍历打印的呢?LinkedHashMap 也是通过散列表和链表组合在一起实现的。实际上,它不仅支持按照插入顺序遍历数据,还支持按照访问顺序来遍历数据。看下面这段代码:

1 // 10 是初始大小,0.75 是装载因子,true 是表示按照访问时间排序
2 HashMap<Integer, Integer> m = new LinkedHashMap<>(10, 0.75f, true);
3 m.put(3, 11);
4 m.put(1, 12);
5 m.put(5, 23);
6 m.put(2, 22);
7 m.put(3, 26);
8 m.get(5);
9 for (Map.Entry e : m.entrySet()) {
10 System.out.println(e.getKey());
11 }
这段代码打印的结果是 1,2,3,5。分析一下,为什么这段代码会按照这样顺序来打印。
每次调用 put() 函数,往 LinkedHashMap 中添加数据的时候,都会将数据添加到链表的尾部,所以,在前四个操作完成之后,链表中的数据是下面这样:
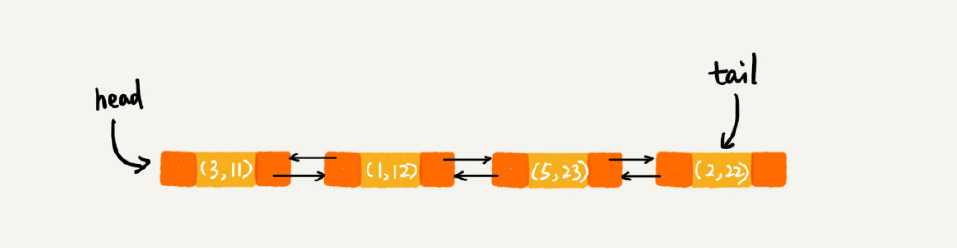
在第 7 行代码中,再次将键值为 3 的数据放入到 LinkedHashMap 的时候,会先查找这个键值是否已经有了,然后,再将已经存在的 (3,11) 删除,并且将新的 (3,26) 放到链表的尾部。所以,这个时候链表中的
数据就是下面这样:

当第 8 行代码访问到 key 为 5 的数据的时候,我们将被访问到的数据移动到链表的尾部。所以,第 8 行代码之后,链表中的数据是下面这样:

所以,最后打印出来的数据是 1,2,3,5。从上面的分析,你有没有发现,按照访问时间排序的 LinkedHashMap 本身就是一个支持 LRU 缓存淘汰策略的缓存系统?
实际上,它们两个的实现原理也是一模一样的。
实际上,LinkedHashMap 是通过双向链表和散列表这两种数据结构组合实现的。LinkedHashMap 中的“Linked”实际上是指的是双向链表,并非指用链表法解决散列冲突。
小结:
散列表这种数据结构虽然支持非常高效的数据插入、删除、查找操作,但是散列表中的数据都是通过散列函数打乱之后无规律存储的。也就说,它无法支持按照某种顺序快速地遍历数据。如果希望按照顺序遍历散列表中的数据,那我们需要将散列表中的数据拷贝到数组中,然后排序,再遍历。
因为散列表是动态数据结构,不停地有数据的插入、删除,所以每当我们希望按顺序遍历散列表中的数据的时候,都需要先排序,那效率势必会很低。为了解决这个问题,我们将散列表和链表(或者跳表)结合在一起使用。
数组占据随机访问的优势,却有需要连续内存的缺点。
链表具有可不连续存储的优势,但访问查找是线性的。
散列表和链表、跳表的混合使用,是为了结合数组和链表的优势,规避它们的不足。
我们可以得出数据结构和算法的重要性排行榜:连续空间 > 时间 > 碎片空间。
-
以上是几个散列表和链表结合使用的例子里,我们用的都是双向链表。如果把双向链表改成单链表,还能否正常工作呢?为什么呢?
在删除一个元素时,虽然能 O(1) 的找到目标结点,但是要删除该结点需要拿到前一个结点的 指针,遍历到前一个结点复杂度会变为 O(N),所以用双链表实现比较合适。
-
假设猎聘网有 10 万名猎头,每个猎头都可以通过做任务(比如发布职位)来积累积分,然后通过积分来下载简历。假设你是猎聘网的一名工程师,如何在内存中存储这 10 万个猎头 ID 和积分信息,让它能够支持这样几个操作:
-
根据猎头的 ID 快速查找、删除、更新这个猎头的积分信息;
-
查找积分在某个区间的猎头 ID 列表;
-
查找按照积分从小到大排名在第 x 位到第 y 位之间的猎头 ID 列表。
-
以积分排序构建一个跳表,再以猎头 ID 构建一个散列表。
1)ID 在散列表中所以可以 O(1) 查找到这个猎头;
2)积分以跳表存储,跳表支持区间查询;
3)还无法实现



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人