
数据结构-02| 链表
1. 链表
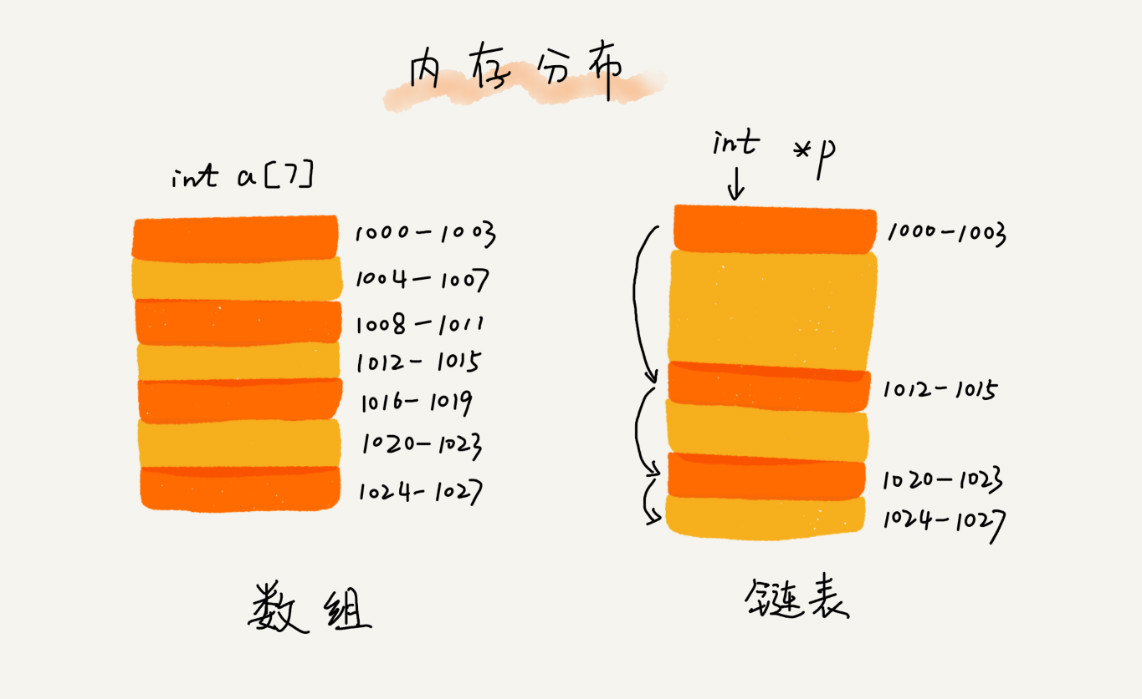
数组需要一块连续的内存空间来存储,对内存的要求比较高。如果申请一个 100MB 大小的数组,当内存中没有连续的、足够大的存储空间时,即便内存的剩余总可用空间大于 100MB,仍然会申请失败。
而链表恰恰相反,它并不需要一块连续的内存空间,它通过“指针”将一组零散的内存块串联起来使用,所以如果申请 100MB 大小的链表,根本不会有问题。
2. 链表分类
三种最常见的链表结构:
单链表 头HEAD,尾TAIL,指针NEXT,最后一个next指向None;
双向链表 指针也指向了前一个节点previous或prev;
循环链表 最后一个NEXT指向头节点;
链表通过指针将一组零散的内存块串联在一起。其中,把内存块称为链表的“结点”。为了将所有的结点串起来,每个链表的结点除了存储数据之外,还需要记录链上的下一个结点的地址。
记录下个结点地址的指针叫作后继指针 next。
2.1 单链表

其中有两个结点是比较特殊的,它们分别是第一个结点和最后一个结点。习惯性地把第一个结点叫作头结点,把最后一个结点叫作尾结点。
其中,头结点用来记录链表的基地址。有了它,就可以遍历得到整条链表。而尾结点特殊的地方是:指针不是指向下一个结点,而是指向一个空地址 NULL,表示这是链表上最后一个结点。
两个指针,使用NEXT连接起来的,同时还提供了一个头指针和尾指针,很方便的知道头和尾在哪里。
单链表的增加插入、删除和查找操作。
① 增加插入结点

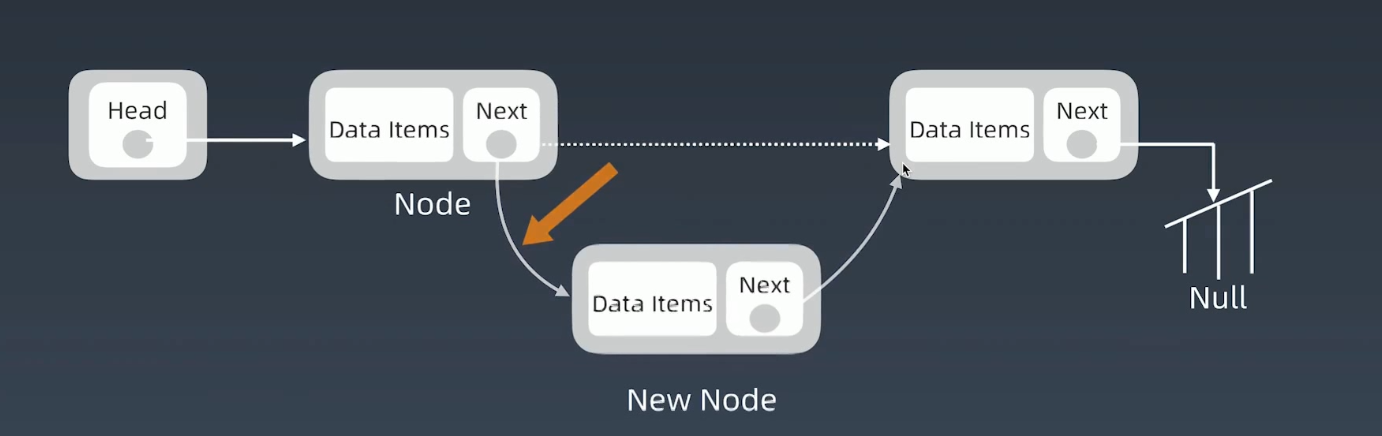

增加一个新节点,一个新的结点要插入链表中时候,找到它的位置,新结点直接把它的NEXT指针指向要插入的位置元素的前边,然后把前边元素的指针再指向新结点,这个元素就自然的插入到了链表中。
② 删除节点



删除操作,直接把它前边结点的指针直接挪到它后边的结点中,也就是跨过中间要删除的结点,再把要删除的结点从内存中释放掉。
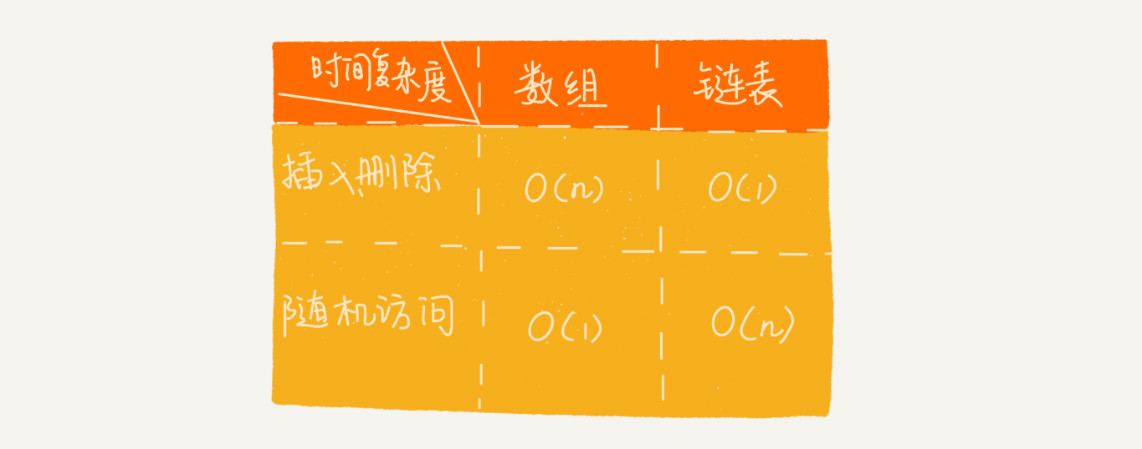
插入和删除,都是直接操作两次NEXT指针,是常数级的,时间复杂度是O(1),要优于数组,但是它的查找却是O(n)。
在进行数组的插入、删除操作时,为了保持内存数据的连续性,需要做大量的数据搬移,所以时间复杂度是 O(n)。
而在链表中插入或者删除一个数据,我们并不需要为了保持内存的连续性而搬移结点,因为链表的存储空间本身就不是连续的。所以,在链表中插入和删除一个数据是非常快速的。针对链表的插入和删除操作,
只需要考虑相邻结点的指针改变,所以对应的时间复杂度是 O(1)。
③ 查找
有利就有弊。链表要想随机访问第 k 个元素,就没有数组那么高效了。因为链表中的数据并非连续存储的,所以无法像数组那样,根据首地址和下标,通过寻址公式就能直接计算出对应的内存地址,而是需要
从头节点一步一步往后挪动 依次遍历,直到找到相应的结点。
可以把链表想象成一个队伍,队伍中的每个人都只知道自己后面的人是谁,所以当我们希望知道排在第 k 位的人是谁的时候,就需要从第一个人开始,一个一个地往下数。所以,链表随机访问的性能没有数组好,需要 O(n) 的时间复杂度。
所以,链表随机访问的性能没有数组好,需要 O(n) 的时间复杂度。
2.2 双向链表 Double Linked List

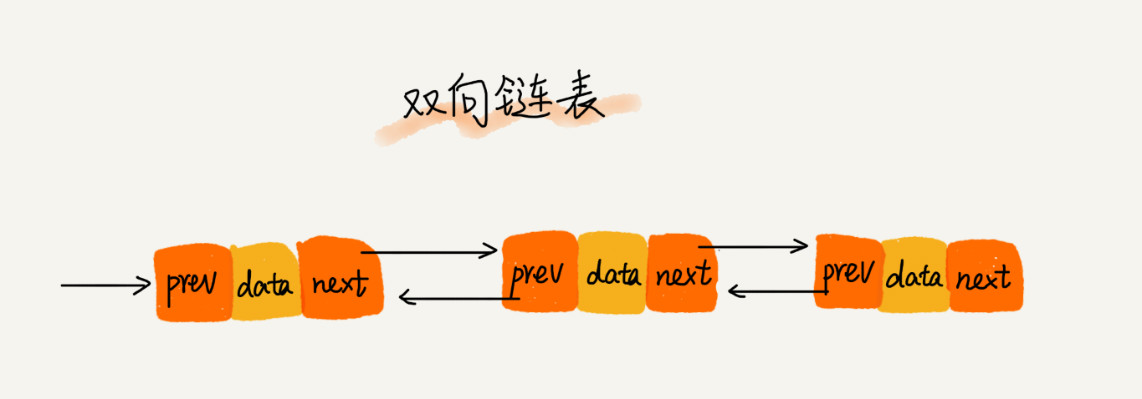
单向链表只有一个方向,结点只有一个后继指针 next 指向后面的结点。而双向链表,它支持两个方向,每个结点不止有一个后继指针 next 指向后面的结点,还有一个前驱指针 prev 指向前面的结点,查找的
时候更方便简洁一点。
双向链表需要额外的两个空间来存储后继结点和前驱结点的地址。所以,如果存储同样多的数据,双向链表要比单链表占用更多的内存空间。虽然两个指针比较浪费存储空间,但可以支持双向遍历,这样也带来了双向链表操作的灵活性。
从结构上来看,双向链表可以支持 O(1) 时间复杂度的情况下找到前驱结点,正是这样的特点,也使双向链表在某些情况下的插入、删除等操作都要比单链表简单、高效。
单链表和双链表的删除和插入操作的比较
单链表的插入、删除操作的时间复杂度是 O(1) ,但是这种说法实际上是不准确的,或者说是有先决条件的。
① 删除操作。
在实际的软件开发中,从链表中删除一个数据无外乎这两种情况:
-
删除结点中“值等于某个给定值”的结点;
-
删除给定指针指向的结点。
对于第一种情况,不管是单链表还是双向链表,为了查找到值等于给定值的结点,都需要从头结点开始一个一个依次遍历对比,直到找到值等于给定值的结点,然后再通过指针操作将其删除。
尽管单纯的删除操作时间复杂度是 O(1),但遍历查找的时间是主要的耗时点,对应的时间复杂度为 O(n)。根据时间复杂度分析中的加法法则,删除值等于给定值的结点对应的链表操作的总时间复杂度为 O(n)。
对于第二种情况,已经找到了要删除的结点,但是删除某个结点 q 需要知道其前驱结点,而单链表并不支持直接获取前驱结点,所以,为了找到前驱结点,我们还是要从头结点开始遍历链表,
直到 p.next = q,说明 p 是 q 的前驱结点。
但是对于双向链表来说,这种情况就比较有优势了。因为双向链表中的结点已经保存了前驱结点的指针,不需要像单链表那样遍历。所以,针对第二种情况,单链表删除操作需要 O(n) 的时间复杂度,而双向链
表只需要在 O(1) 的时间复杂度内就搞定了!
② 插入操作
同理,如果在链表的某个指定结点前面插入一个结点,双向链表比单链表有很大的优势。双向链表可以在 O(1) 时间复杂度搞定,而单向链表需要 O(n) 的时间复杂度。可参照刚刚的删除操作。
除了插入、删除操作有优势之外,对于一个有序链表,双向链表的按值查询的效率也要比单链表高一些。因为,可以记录上次查找的位置 p,每次查询时,根据要查找的值与 p 的大小关系,决定是往前还是
往后查找,所以平均只需要查找一半的数据。
在实际的软件开发中,双向链表尽管比较费内存,但还是比单链表的应用更加广泛的原因。Java 语言中LinkedHashMap 这个容器,它的实现原理就用到了双向链表这种数据结构。
用空间换时间
当内存空间充足的时候,如果我们更加追求代码的执行速度,就可以选择空间复杂度相对较高、但时间复杂度相对很低的算法或者数据结构。相反,如果内存比较紧缺,比如代码跑在手机或者单片机上,这
个时候,就要反过来用时间换空间的设计思路。
缓存实际上就是利用了空间换时间的设计思想。如果我们把数据存储在硬盘上,会比较节省内存,但每次查找数据都要询问一次硬盘,会比较慢。但如果我们通过缓存技术,事先将数据加载在内存中,虽然
会比较耗费内存空间,但是每次数据查询的速度就大大提高了。
对于执行较慢的程序,可以通过消耗更多的内存(空间换时间)来进行优化; 而消耗过多内存的程序,可以通过消耗更多的时间(时间换空间)来降低内存的消耗。
2.3 循环链表
循环链表是一种特殊的单链表
实际上,循环链表也很简单。它跟单链表唯一的区别就在尾结点。 单链表的尾结点指针指向空地址,表示这就是最后的结点了。而循环链表的尾结点指针是指向链表的头结点。
和单链表相比,循环链表的优点是从链尾到链头比较方便。当要处理的数据具有环型结构特点时,就特别适合采用循环链表。比如著名的约瑟夫问题。尽管用单链表也可以实现,但是用循环链表实现的话,代码就会简洁很多。
2.4 双向循环链表
了解了循环链表和双向链表,把这两种链表整合在一起就是一个新的版本:双向循环链表。
Java中LinkedList即 实现了一个双向循环链表。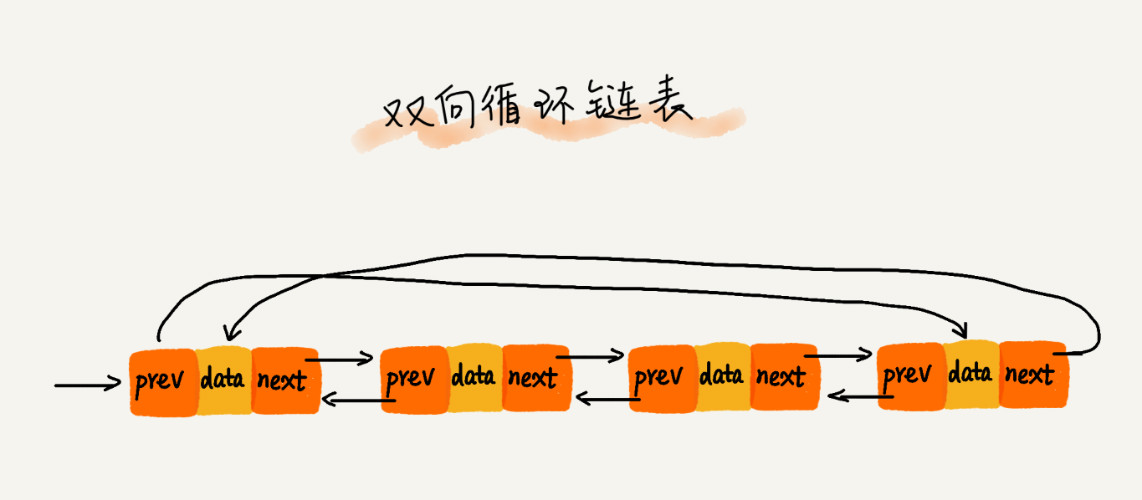
3. 链表 VS 数组
正是因为内存存储的区别,它们插入、删除、随机访问操作的时间复杂度正好相反。
① 数组简单易用,在实现上使用的是连续的内存空间,可以借助 CPU 的缓存机制,预读数组中的数据,所以访问效率更高。
而链表在内存中并不是连续存储,所以对 CPU 缓存不友好,没办法有效预读。
PS:CPU缓存机制(
CPU在从内存读取数据的时候,会先把读取到的数据加载到CPU的缓存中。而CPU每次从内 存读取数据并不是只读取那个特定要访问的地址,而是读取一个数据块 并保存到CPU缓存中,然后下次访问内存 数据的时候就会先从CPU缓存开始查找,如果找到就不需要再从内存中取。这样就实现了比内存访问速度更快的机制,也就是CPU缓存存在的意义: 为了弥补内存访问速度过慢与CPU执行速度快之间的差异而引入。
对于数组来说,存储空间是连续的,所以在加载某个下标的时候可以把以后的几个下标元素 也加载到CPU缓存这样执行速度会快于存储空间不连续的链表存储。
)
② 数组的缺点是大小固定,一经声明就要占用整块连续内存空间。如果声明的数组过大,系统可能没有足够的连续内存空间分配给它,导致“内存不足(out of memory)”。如果声明的数组过小,则可能出现不
够用的情况。这时只能再申请一个更大的内存空间,把原数组拷贝进去,非常费时。
链表本身没有大小的限制,天然地支持动态扩容,我觉得这也是它与数组最大的区别。 Java 中的 ArrayList 容器,虽然支持动态扩容,但当我们往支持动态扩容的数组中插入一个数据时,如果数组中没有空闲
空间了,就会申请一个更大的空间,将数据拷贝过去,而数据拷贝的操作是非常耗时的。 比如用 ArrayList 存储了了 1GB 大小的数据,这个时候已经没有空闲空间了,当再插入数据的时候,ArrayList 会申请一
个 1.5GB 大小的存储空间,并且把原来那 1GB 的数据拷贝到新申请的空间上。听起来是不是就很耗时?
③ 除此之外,如果你的代码对内存的使用非常苛刻,那数组就更适合你。因为链表中的每个结点都需要消耗额外的存储空间去存储一份指向下一个结点的指针,所以内存消耗会翻倍。而且,对链表进行频繁的
插入、删除操作,还会导致频繁的内存申请和释放,容易造成内存碎片,如果是 Java 语言,就有可能会导致频繁的 GC(Garbage Collection,垃圾回收)。
4. 链表的时间复杂度
space: O(n)
prepend: O(1)
append: O(1)
lookup: O(n)
insert: O(1)
delete: O(1)
链表的两种常用操作:插入和删除 时间复杂度都是O(1)
Java中的LinkedList :它的实现不是一个单链表,而是一个双向链表。
它的Node Class名字叫Entry;



/** 85: * The first element in the list. 86: */ 87: transient Entry<T> first; //HEAD指针 88: 89: /** 90: * The last element in the list. 91: */ 92: transient Entry<T> last; //TAIL指针 /** 100: * Class to represent an entry in the list. Holds a single element. 101: */ 102: private static final class Entry<T> 103: { 104: /** The element in the list. */ 105: T data; 106: 107: /** The next list entry, null if this is last. */ 108: Entry<T> next; 109: 110: /** The previous list entry, null if this is first. */ 111: Entry<T> previous; 112: 113: /** 114: * Construct an entry. 115: * @param data the list element 116: */ 117: Entry(T data) 118: { 119: this.data = data; 120: } 121: } // class Entry
对链表做优化操作即得到:跳表
链表的应用场景:插入和删除操作很多;
不知道有多少个元素在,每来一个一般放在最后边。
使用NEXT指针指向下一个节点,连接成一个表就是链表。
一个经典的链表应用场景,那就是 LRU 缓存淘汰算法, 用链表来实现 LRU 缓存淘汰策略。
5. 链表的应用-LRUCache
6. 附录:常用的数据结构的时间、空间复杂度
https://www.bigocheatsheet.com/

Big O Cheat Sheet

7. 写链表代码的技巧
一、理解指针或引用的含义
1.含义:将某个变量赋值给指针,实际上就是就是将这个变量的地址赋值给指针。或者反过来说,指针中存储了这个变量的内存地址,指向了这个变量,通过指针就能找到这个变量。 如:
p.next = q; 表示p节点的next后继指针存储了q节点的内存地址。
p.next = p.next.next; 表示p节点的next后继指针存储了p节点的下下一个节点的内存地址。
指针就是一个存储的地址变量, 放在右边就是取值, 放在左边就是被赋值;
Node p = head; 把p赋值给head
p = p.next; 把p指针后移一位
二、警惕指针丢失和内存泄漏(单链表)

往链表中插入节点时:
在节点a和节点b之间插入节点x,假设当前指针p 指向节点a。 造成指针丢失和内存泄漏的代码如下:
p.next = x; // 将 p 的 next 指针指向 x 结点
x.next = p.next; // 将 x 的结点的 next 指针指向 b 结点;
p.next 指针在完成第一步操作之后,已经不再指向结点 b 了,而是指向结点 x。 第 2 行代码相当于将 x 赋值给 x.next,自己指向自己。因此,整个链表也就断成了两半,从结点 b 往后的所有结点都无法访问到
了。对于C 语言,内存管理是由程序员负责的,如果没有手动释放结点对应的内存空间,就会产生内存泄露。 所以,我们插入结点时,一定要注意操作的顺序,要先将结点 x 的 next 指针指向结点 b,再把结点
a 的 next 指针指向结点 x,这样才不会丢失指针,导致内存泄漏。 所以,对于刚刚的插入代码,我们只需要把第 1 行和第 2 行代码的顺序颠倒一下就可以了:
x.next = p.next;
p.next = x;
同理,删除链表结点时,也一定要记得手动释放内存空间,否则,也会出现内存泄漏的问题。当然,对于像Java 这种虚拟机自动管理内存的编程语言来说,就不需要考虑这么多了。
三、利用“哨兵”简化实现难度
未引入“哨兵”时
插入:
在p节点后插入一个节点,只需2行代码即可搞定:
new_node.next = p.next;
p.next = new_node;
但,若向空链表中插入一个节点,head表链表的头结点,代码如下:
if(head == null) {
head = new_node;
}
删除:
如果要删除节点p的后继节点,只需1行代码即可搞定:
p.next = p.next.next;
但,若要删除链表的最有一个节点(链表只剩下最后一个节点),则代码如下:
if(head.next == null) {
head = null;
}
从上面的情况可以看出,针对链表的插入、删除操作,需要对插入第一个节点和删除最后一个节点的情况进行特殊处理。这样代码就会显得很繁琐,所以引入“哨兵”节点来解决这个问题。
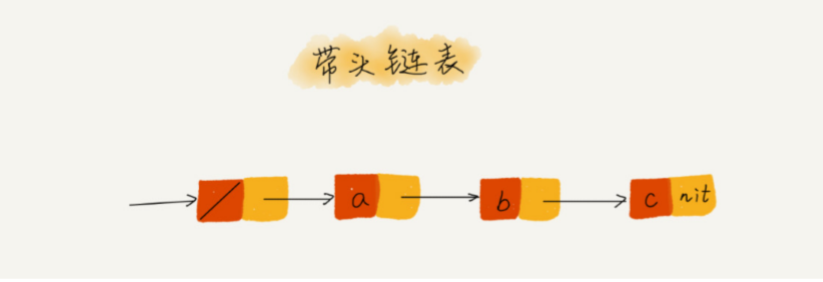
链表中的“哨兵”节点是解决边界问题的,不参与业务逻辑。如果我们引入“哨兵”节点,则不管链表是否为空,head指针都会指向这个“哨兵”节点。
我们把这种有“哨兵”节点的链表称为带头链表,相反,没有“哨兵”节点的链表就称为不带头链表。
空链表: head=null 表示链表中没有结点了。其中 head 表示头结点指 针,指向链表中的第一个结点。
如果引入“哨兵”结点,在任何时候不管链表是否为空,head指针都会指向哨兵结点。 哨兵结点不存放数据,作为链表的头结点始终存在。这样,插入第一个节点和插入其他节点,删除最后一个节点和删除其他
节点都可以 统一为相同的代码实现逻辑了。
这种利用哨兵简化编程难度的技巧(简化边界条件的处理),在很多代码实现中都有用到,比如插入排序、归并 排序、动态规划等。
四、重点留意边界条件处理 经常用来检查链表是否正确的边界4个边界条件:
- 1.如果链表为空时,代码是否能正常工作?
- 2.如果链表只包含一个节点时,代码是否能正常工作?
- 3.如果链表只包含两个节点时,代码是否能正常工作?
- 4.代码逻辑在处理头尾节点时是否能正常工作?
五、举例画图,辅助思考核心思想:
释放脑容量,留更多的给逻辑思考,这样就会感觉到思路清晰很多。

六、多写多练,没有捷径
Java中使用链表数据结构的集合
LinkedList的分析
LinkedList底层是一个双向链表,并且实现了Deque接口,还是一个双端队列
- 底层是通过双向链表来实现的,但是并非循环链表。
- 不需要扩容,因为底层是线性存储
- 增删快,但是查找比较慢
- 非线程安全
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
Deque是一个双端队列,说明在LinkedList中同时也支持对队列的操作;
LinkedList的属性只有三个:
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
Node是它的一个内部类,用来保存数据
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
add( E e )方法源码如下
/** * Appends the specified element to the end of this list. * * <p>This method is equivalent to {@link #addLast}. * * @param e element to be appended to this list * @return {@code true} (as specified by {@link Collection#add}) */ public boolean add(E e) { linkLast(e); return true; } /** * Links e as last element. */ void linkLast(E e) { //保存 last 尾结点 final Node<E> l = last; //将要保存的元素放到 新建一个结点中, final Node<E> newNode = new Node<>(l, e, null); // 这样这个新的节点就变成 了尾结点 last = newNode; // 判断下如果这个尾结点为空,就说明这个链表是空的 //那么这个新的结点就是 首结点。 if (l == null) first = newNode; //如果不是空的,那么之前旧的尾结点的 next 保存的就是这个新结点 else l.next = newNode; size++; modCount++; }
addAll(int index, Collection<? extends E> c) 源码方法
addAll 方法有两个重载函数,前一个是调用的后一个 public boolean addAll(Collection<? extends E> c) { return addAll(size, c); } public boolean addAll(int index, Collection<? extends E> c) { //首先进行下标合理性检查,下面有这个方法 checkPositionIndex(index); //将集合转换为 Object 数组 Object[] a = c.toArray(); int numNew = a.length; if (numNew == 0) return false; //定义下标位置的前置结点和后继结点 Node<E> pred, succ; if (index == size) { //从尾部添加,前置结点是 之前的尾结点,后继结点为null succ = null; pred = last; } else { //从指定位置添加,后继结点是下标是index的结点; //前置结点是下标位置的前一个结点 succ = node(index); pred = succ.prev; } for (Object o : a) { @SuppressWarnings("unchecked") E e = (E) o; Node<E> newNode = new Node<>(pred, e, null); if (pred == null) //如果插入位置在头部 first = newNode; else //非空链表插入 pred.next = newNode; pred = newNode; //更新前置结点为最新的结点 } if (succ == null) { //如果是从尾部插入的,插入完成后重置尾结点 last = pred; } else { //如果不是尾部,那么把之前的数据和尾部连接起来 pred.next = succ; succ.prev = pred; } //集合的原来数量+新集合的数量 size += numNew; modCount++; return true; }
get(int index)方法源码如下
/** * Returns the element at the specified position in this list. * * @param index index of the element to return * @return the element at the specified position in this list * @throws IndexOutOfBoundsException {@inheritDoc} */ public E get(int index) { //元素的下标检查 checkElementIndex(index); return node(index).item; } /** * Returns the (non-null) Node at the specified element index. */ Node<E> node(int index) { // assert isElementIndex(index); //如果下标位置靠近链表前半部分,从头开始遍历 if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; //如果下标位置靠近链表后半部分,从尾部开始遍历 } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } }
链表获取指定元素效率比较低,需要将元素遍历才能找到目标元素。需要的时间复杂度是O(n)
数组简单易用,在实现上使用连续内存空间,可以通过CPU的缓存机制,来实现预读,访问速度会比较快。
而链表,由于内存不是连续的,所以不能通过这种方法来实现预读。链表大小没有限制,天然支持动态扩容,这也是和数组最大的区别。
如果对内存要求高就选择数组,因为链表中的每一个结点都需要消耗额外的内存去存储指向下一个结点的指针,所以内存消耗会翻倍,
且对于链表的频繁删除和插入,会导致频繁的内存申请和释放,造成内存碎片,就会引起频繁的GC(Garbage Collection 垃圾回收)。
LinkedHashMap
底层数据结构为 HashMap + LinkedList
- 1、LinkedHashMap可以认为是 HashMap+LinkedList ,即它既使用HashMap操作数据结构,又使用LinkedList维护插入元素的先后顺序。
- 2、LinkedHashMap的基本实现思想就是---- 多态
/**
* //调用父类HashMap的构造方法。
* Constructs an empty insertion-ordered <tt>LinkedHashMap</tt> instance
* with the default initial capacity (16) and load factor (0.75).
*/
public LinkedHashMap() {
super();
accessOrder = false;
}
// 这里的 accessOrder 默认是为false,如果要按读取顺序排序需要将其设为 true
// initialCapacity 代表 map 的 容量,loadFactor 代表加载因子 (默认即可)
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
LinkedHashMap<String, String> map = new LinkedHashMap<>(0, 0.75f, true);
上面创建 LinkedHashMap 对象,注意第三个参数为 true ,也就是内部的 accessOrder = true,默认情况该属性是为 false 的,表示按照插入顺序排序,
若是为 true 表示按照访问顺序排序。因为当前的 LinkedHashMap 是需要按照访问顺序排序的因此 accessOrder 应该需要赋值为 true
HashMap 底层是 数组 + 红黑树 + 链表 ,同时其是无序的,而 LinkedHashMap 刚好就比 HashMap 多这一个功能,就是其提供有序。
并且,LinkedHashMap的有序可以按两种顺序排列,一种是按照插入的顺序,一种是按照读取的顺序,其内部是靠建立一个双向链表 来维护这个顺序的,在每次插入、删除后,都会调用一个函数来进行 双向链
表的维护,准确的来说,是有三个函数来做这件事,这三个函数都统称为回调函数 ,这三个函数分别是:
- void afterNodeAccess(Node<K,V> p) { }
其作用就是在访问元素之后,将该元素放到双向链表的尾巴处(所以这个函数只有在按照读取的顺序的时候才会执行),可以看到优美的实现在双向链表中将指定元素放入链尾!
- void afterNodeRemoval(Node<K,V> p) { }
其作用就是在删除元素之后,将元素从双向链表中删除,很优美的方式在双向链表中删除节点!
- void afterNodeInsertion(boolean evict) { }
在插入新元素之后,需要回调函数判断是否需要移除一直不用的某些元素!
LinkedHashMap 的构造函数
其主要是两个构造方法,一个是继承 HashMap ,一个是可以选择 accessOrder 的值(默认 false,代表按照插入顺序排序)来确定是按插入顺序还是读取顺序排序。
利用LinkedListMap实现LRU缓存淘汰策略
继承 LinkedHashMap,然后复写 removeEldestEntry()函数,就能拥有我们自己的缓存策略!
// 在插入一个新元素之后,如果是按插入顺序排序,即调用newNode()中的linkNodeLast()完成
// 如果是按照读取顺序排序,即调用afterNodeAccess()完成
// 那么这个方法是干嘛的呢,这个就是著名的 LRU 算法啦
// 在插入完成之后,需要回调函数判断是否需要移除某些元素!
// LinkedHashMap 函数部分源码
/**
* 插入新节点才会触发该方法,因为只有插入新节点才需要内存
* 根据 HashMap 的 putVal 方法, evict 一直是 true
* removeEldestEntry 方法表示移除规则, 在 LinkedHashMap 里一直返回 false
* 所以在 LinkedHashMap 里这个方法相当于什么都不做
*/
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
// 根据条件判断是否移除最近最少被访问的节点
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
// 移除最近最少被访问条件之一,通过覆盖此方法可实现不同策略的缓存
// LinkedHashMap是默认返回false的,我们可以继承LinkedHashMap然后复写该方法即可
// 例如 LeetCode 第 146 题就是采用该种方法,直接 return size() > capacity;
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
通过上述代码,我们就已经知道了只要复写 removeEldestEntry() 即可,而条件就是 map 的大小不超过 给定的容量,超过了就得使用 LRU 了!然后根据题目给定的语句构造和调用:
另外 afterNodeAccess、afterNodeRemoval这两个方法的源码如下:
//标准的如何在双向链表中将指定元素放入队尾
// LinkedHashMap 中覆写
//访问元素之后的回调方法
/**
* 1. 使用 get 方法会访问到节点, 从而触发调用这个方法
* 2. 使用 put 方法插入节点, 如果 key 存在, 也算要访问节点, 从而触发该方法
* 3. 只有 accessOrder 是 true 才会调用该方法
* 4. 这个方法会把访问到的最后节点重新插入到双向链表结尾
*/
void afterNodeAccess(Node<K,V> e) { // move node to last
// 用 last 表示插入 e 前的尾节点
// 插入 e 后 e 是尾节点, 所以也是表示 e 的前一个节点
LinkedHashMap.Entry<K,V> last;
//如果是访问序,且当前节点并不是尾节点
//将该节点置为双向链表的尾部
if (accessOrder && (last = tail) != e) {
// p: 当前节点
// b: 前一个节点
// a: 后一个节点
// 结构为: b <=> p <=> a
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
// 结构变成: b <=> p <- a
p.after = null;
// 如果当前节点 p 本身是头节点, 那么头结点要改成 a
if (b == null)
head = a;
// 如果 p 不是头尾节点, 把前后节点连接, 变成: b -> a
else
b.after = a;
// a 非空, 和 b 连接, 变成: b <- a
if (a != null)
a.before = b;
// 如果 a 为空, 说明 p 是尾节点, b 就是它的前一个节点, 符合 last 的定义
// 这个 else 没有意义,因为最开头if已经确保了p不是尾结点了,自然after不会是null
else
last = b;
// 如果这是空链表, p 改成头结点
if (last == null)
head = p;
// 否则把 p 插入到链表尾部
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
void afterNodeRemoval(Node<K,V> e) { // 优美的一笔,学习一波如何在双向链表中删除节点
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
// 将 p 节点的前驱后后继引用置空
p.before = p.after = null;
// b 为 null,表明 p 是头节点
if (b == null)
head = a;
else
b.after = a;
// a 为 null,表明 p 是尾节点
if (a == null)
tail = b;
else
a.before = b;
}
链表的插入查找删除
public static void main(String[] args) { ListNode node1 = new ListNode(2); ListNode node2 = new ListNode(4); ListNode node3 = new ListNode(6); ListNode node4 = new ListNode(8); node1.setNext(node2); node2.setNext(node3); node3.setNext(node4); TestLinkedList tList = new TestLinkedList(); //head指向 链表的链首节点 tList.head = node1; //tail指向 链表的链尾节点 tList.tail = node4; tList.insertTail(10); } //head /tail 指向虚拟头节点;把特殊处理的逻辑引入正常逻辑处理中; private ListNode head = new ListNode(); private ListNode tail = head; //链表插入 优化二: 引入虚拟头结点(处理特殊情况) //借助虚拟节点,以及tail指针,简化"往链表尾部插入节点" //链表代码中常用的编程技巧:引入虚拟节点/哑节点/哨兵节点,简化编程统一处理逻辑; public void insertTail(int value) { ListNode newNode = new ListNode(value, null); tail.next = newNode; tail = newNode; }



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人