
数据结构-07| 堆
1. 堆概念
二叉堆的性能有很大的问题,现实中很大高级的堆用的是斐波拉契堆和加的堆。
https://www.cnblogs.com/skywang12345/p/3610187.html#a1
https://en.wikipedia.org/wiki/Binary_heap
堆是一种特殊的树。只要满足这两点,它就是一个堆:
-
堆是一个完全二叉树;
-
堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值。
第一点,堆必须是一个完全二叉树。完全二叉树要求,除了最后一层,其他层的节点个数都是满的,最后一层的节点都靠左排列。
第二点,堆中的每个节点的值必须大于等于(或者小于等于)其子树中每个节点的值。实际上,还有换一种说法,堆中每个节点的值都大于等于(或者小于等于)其左右子节点的值。这两种表述是等价的。
对于每个节点的值都大于等于子树中每个节点值的堆,叫作“大顶堆”。对于每个节点的值都小于等于子树中每个节点值的堆,叫作“小顶堆”。
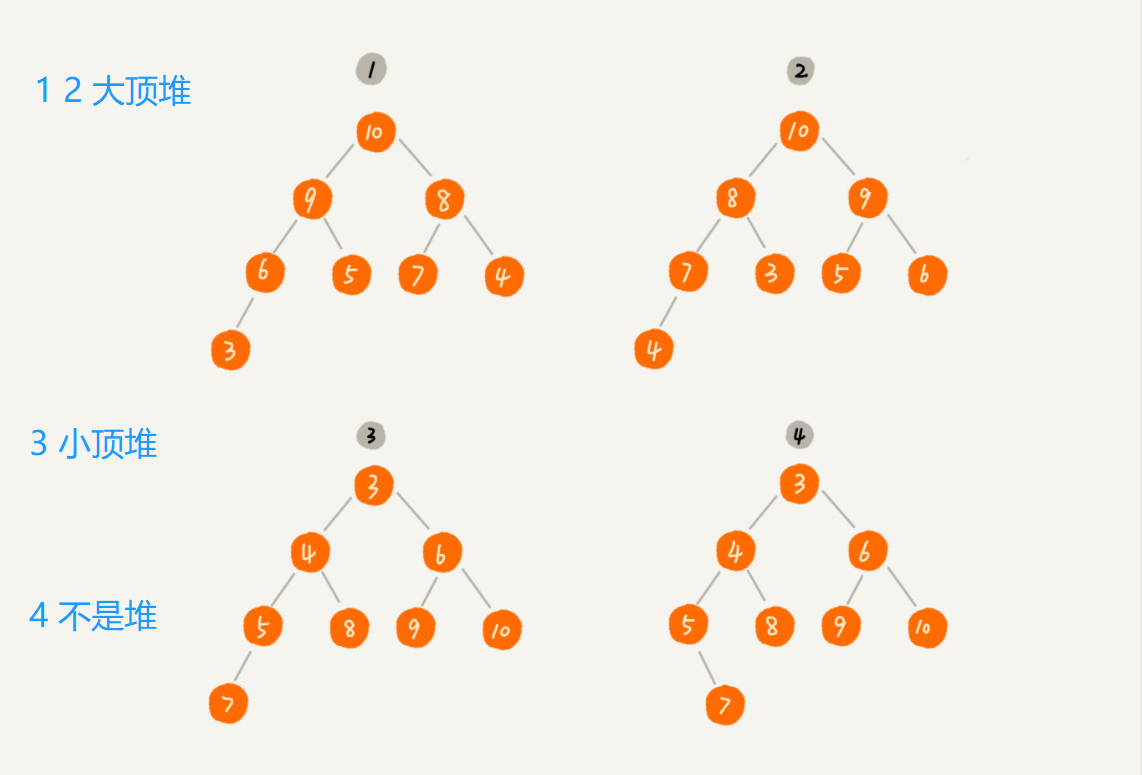
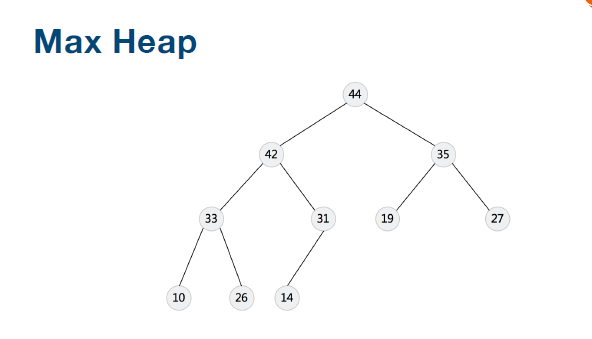
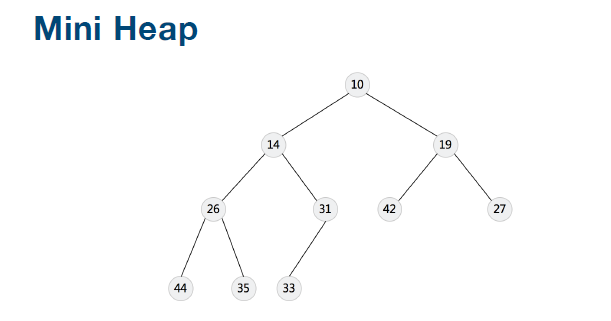
小顶堆--越小的越排到前边;每一个根节点都大于它的左右节点;最顶的节点最大;
从图中还可以看出来,对于同一组数据,我们可以构建多种不同形态的堆。
Heap Wiki
https://en.wikipedia.org/wiki/Heap_(data_structure)
Google 搜索 heap 或者 堆

2. 堆的存储
完全二叉树比较适合用数组来存储。用数组来存储完全二叉树是非常节省存储空间的。因为不需存储左右子节点的指针,单纯地通过数组的下标,就可以找到一个节点的左右子节点和父节点。
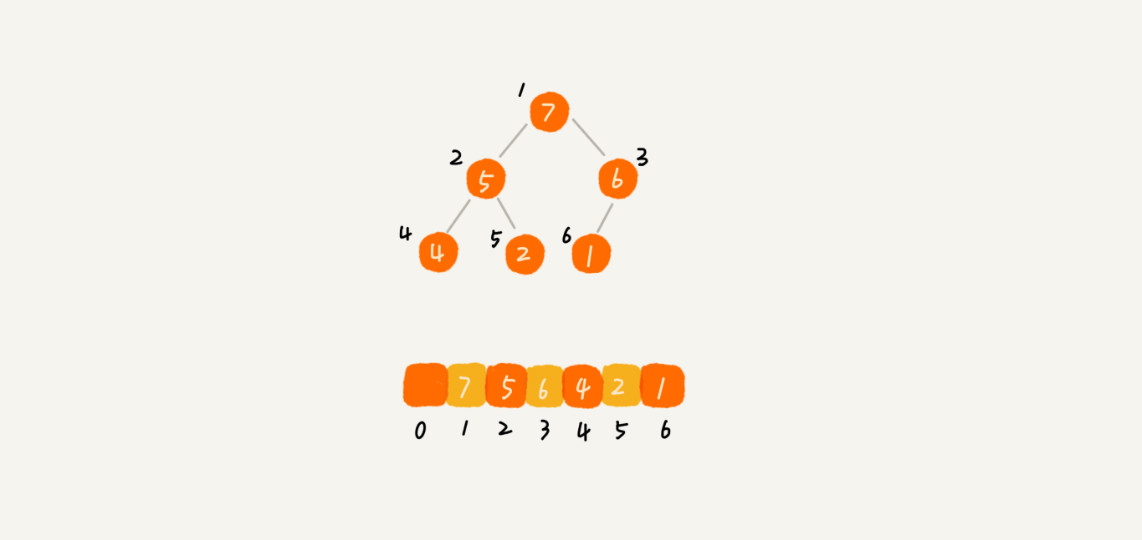
上图中 i = 1 存储根节点,下标为 i 的节点的左子节点就是下标为 i ∗ 2 的节点,右子节点就是下标为 i ∗ 2 + 1 的节点,父节点就是下标为 i / 2 的节点;
如果 i = 0 存储根节点,下标为 i 的节点的左子节点就是下标为 i ∗ 2 + 1 的节点,右子节点就是下标为 i ∗ 2 + 2 的节点,但父节点的下标为 ( i - 1 ) / 2 。
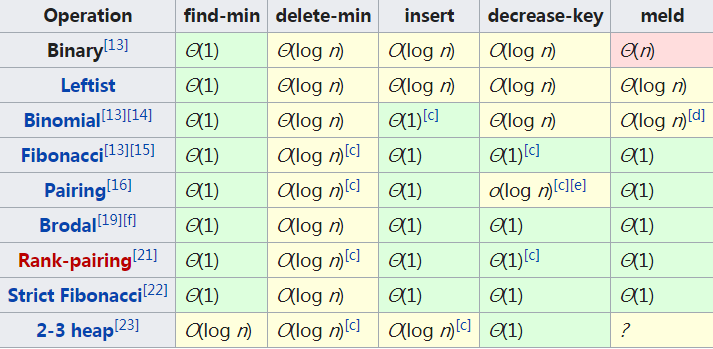
3. 堆的基本操作
3.1 往堆中插入一个元素
往堆中插入一个元素后,我们需要继续满足堆的两个特性。如果把新插入的元素放到堆的最后,就不符合堆的特性了。调整让它重新满足堆的特性,这个过程就叫作堆化(heapify)。
堆化非常简单,就是顺着节点所在的路径,向上或者向下,对比,然后交换。堆化方法有两种: 从下往上和从上往下。
从下往上

新插入的节点与父节点对比大小。如果不满足子节点小于等于父节点的大小关系,就互换两个节点。一直重复这个过程,直到父子节点之间满足刚说的那种大小关系。
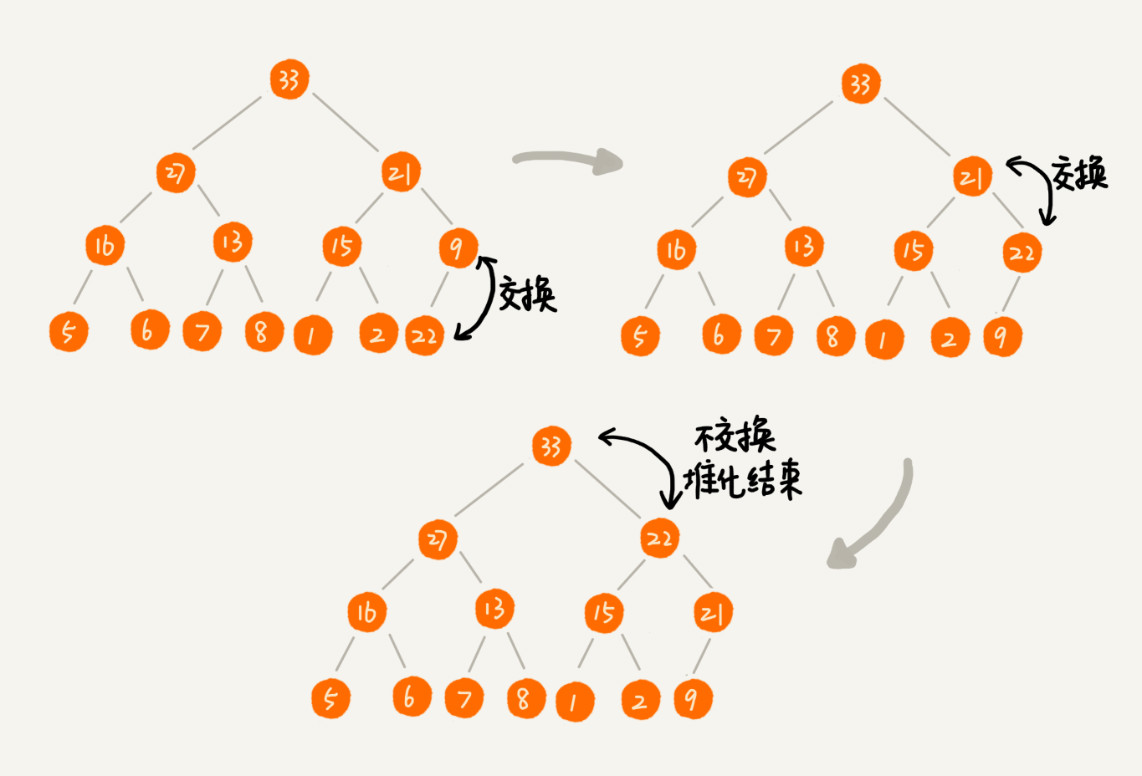
3.2 删除堆顶元素
从堆的定义的第二条中,任何节点的值都大于等于(或小于等于)子树节点的值,堆顶元素存储的就是堆中数据的最大值或者最小值。
对于大顶堆:
堆顶元素就是最大的元素。当删除堆顶元素之后,就需要把第二大的元素放到堆顶,那第二大元素肯定会出现在左右子节点中。然后再迭代地删除第二大节点,以此类推,直到叶子节点被删除。(这种操作最后堆化出来的堆并不满足完全二叉树的特性,会出现数组空洞。)
改变下思路: 把最后一个节点放到堆顶,然后利用同样的父子节点对比方法。对于不满足父子节点大小关系的,互换两个节点,并且重复进行这个过程,直到父子节点之间满足大小关系为止。这就是从上往下的堆化方法。因为移除的是数组中的最后一个元素,而在堆化的过程中,都是交换操作,不会出现数组中的“空洞”,所以这种方法堆化之后的结果,肯定满足完全二叉树的特性。
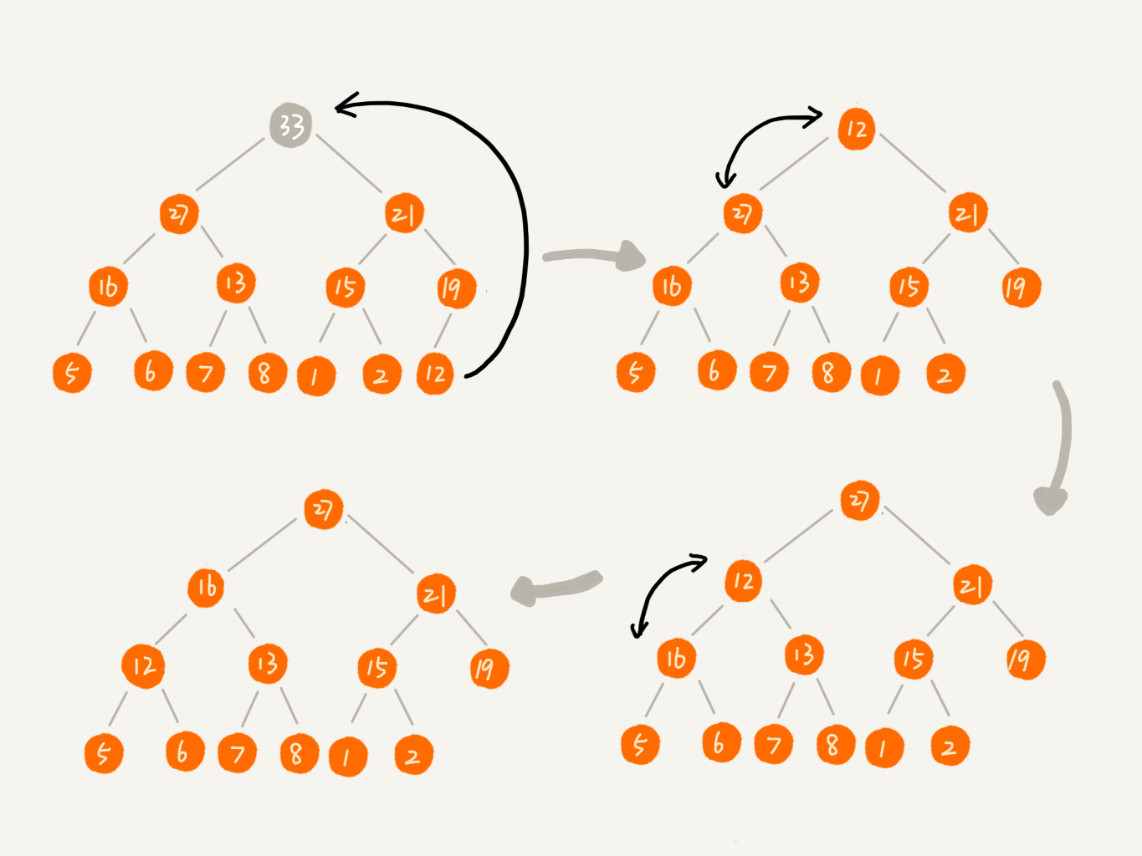
一个包含 n 个节点的完全二叉树,树的高度小于 log2n,堆化的过程是顺着节点所在路径比较交换,所以堆化的时间复杂度跟树的高度成正比,为O(log n)。
插入数据和删除堆顶元素的主要逻辑就是堆化,所以,往堆中插入一个元素和删除堆顶元素的时间复杂度都是 O(log n)。
4. 堆排序
借助堆这种数据结构实现的排序算法,就叫堆排序。这种排序方法的时间复杂度非常稳定,是 O(nlogn),并且它还是原地排序算法。
堆排序大致分成两个大的步骤: 建堆和排序。
4.1 建堆
首先将数组原地建成一个堆。所谓“原地”就是,不借助另一个数组,就在原数组上操作。
建堆的过程,有两种思路:
第一种是上边在堆中插入一个元素的思路。尽管数组中包含 n 个数据,但可以假设,起初堆中只包含一个数据,就是下标为 1 的数据。然后,调用插入操作,将下标从 2 到 n 的数据依次插入到堆中。这样我们就将包含 n 个数据的数组,组织成了堆。
这种思路的处理过程是从前往后处理数组数据,并且每个数据插入堆中时,都是从下往上堆化。
第二种跟第一种截然相反,是从后往前处理数组,并且每个数据都是从上往下堆化。
因为叶子节点往下堆化只能自己跟自己比较,所以直接从第一个非叶子节点开始,依次堆化就行了。
如下图所示 对下标从 n / 2 开始到 1 的数据进行堆化,下标是 n / 2 + 1 到 n 的节点是叶子节点,不需要堆化。实际上,对于完全二叉树来说,下标从 n2+1n2+1 到 nn 的节点都是叶子节点。
9 / 2 + 1 --> 9 即(5 --> 9)为叶子节点的下标, 9 / 2 到 1 即 4, 3, 2, 1需要堆化。
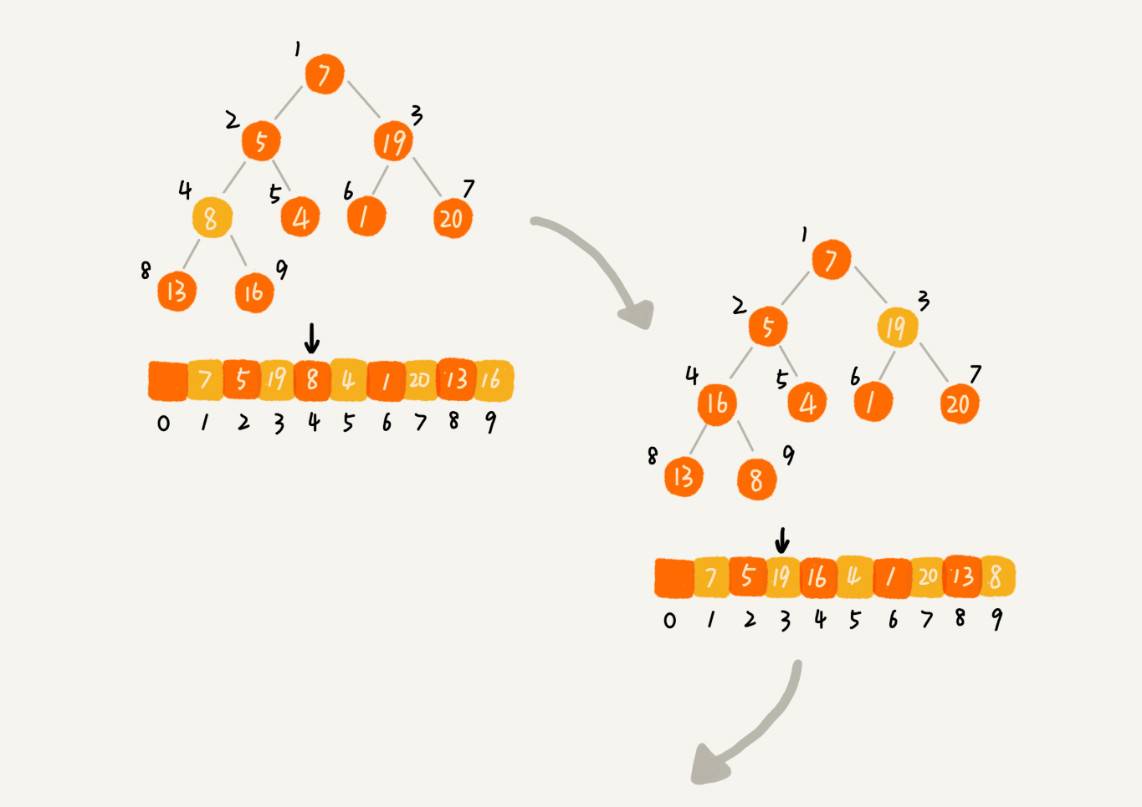

建堆操作的时间复杂度
每个节点堆化的时间复杂度是 O(logn),那 n / 2 + 1 个节点堆化的总时间复杂度是不是就是 O(nlogn) 呢?这个答案虽然也没错,但是这个值还是不够精确。实际上,堆排序的建堆过程的时间复杂度是 O(n), 推导如下:
因为叶子节点不需要堆化,所以需要堆化的节点从倒数第二层开始。每个节点堆化的过程中,需要比较和交换的节点个数,跟这个节点的高度 k 成正比。
下图为每一层的节点个数和对应的高度, 只需要将每个节点的高度求和,得出的就是建堆的时间复杂度。
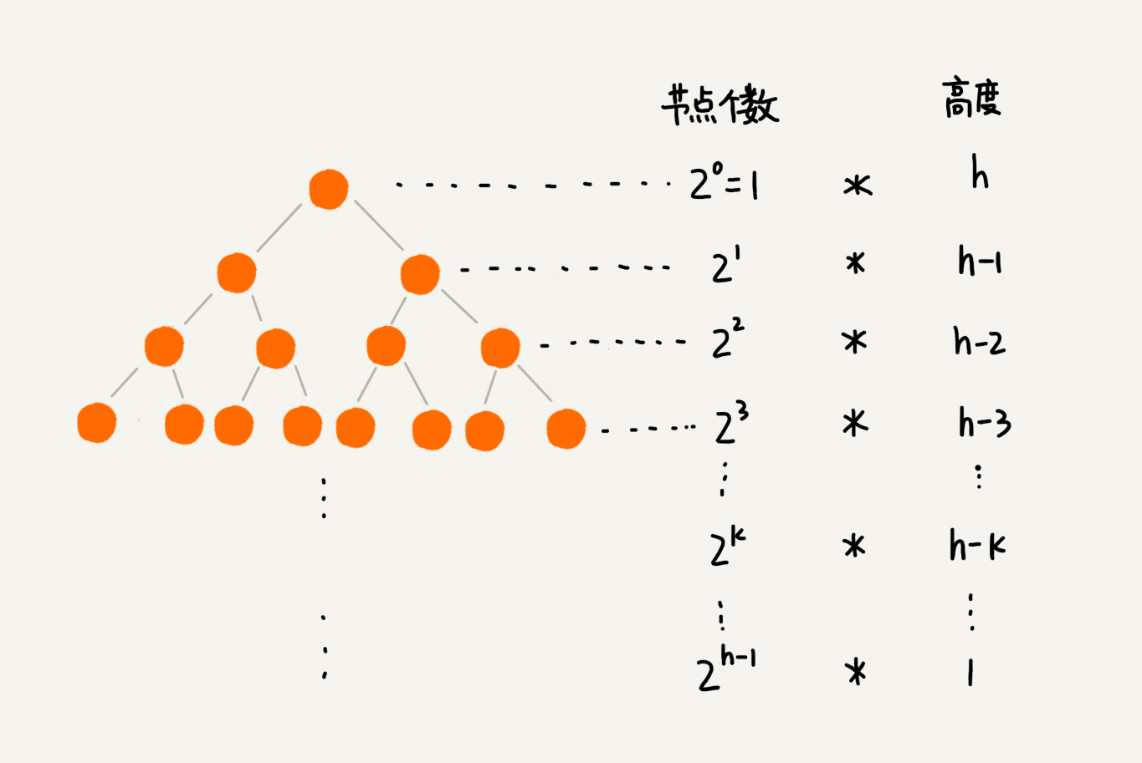
将每个非叶子节点的高度求和 S1 = 1 * h + 21 * (h-1) + 22 * (h-2) + ... + 2k * (h-k) + ....+ 2h-1 * 1

S的中间部分是一个等比数列,所以最后可以用等比数列的求和公式来计算,最终的结果如下:
S = -h + (2h - 2) + 2h = 2h+1 - h - 2
因为 h= log2n ,代入公式 S,就能得到 S=O(n),所以,建堆的时间复杂度就是 O(n)。
4.2 排序
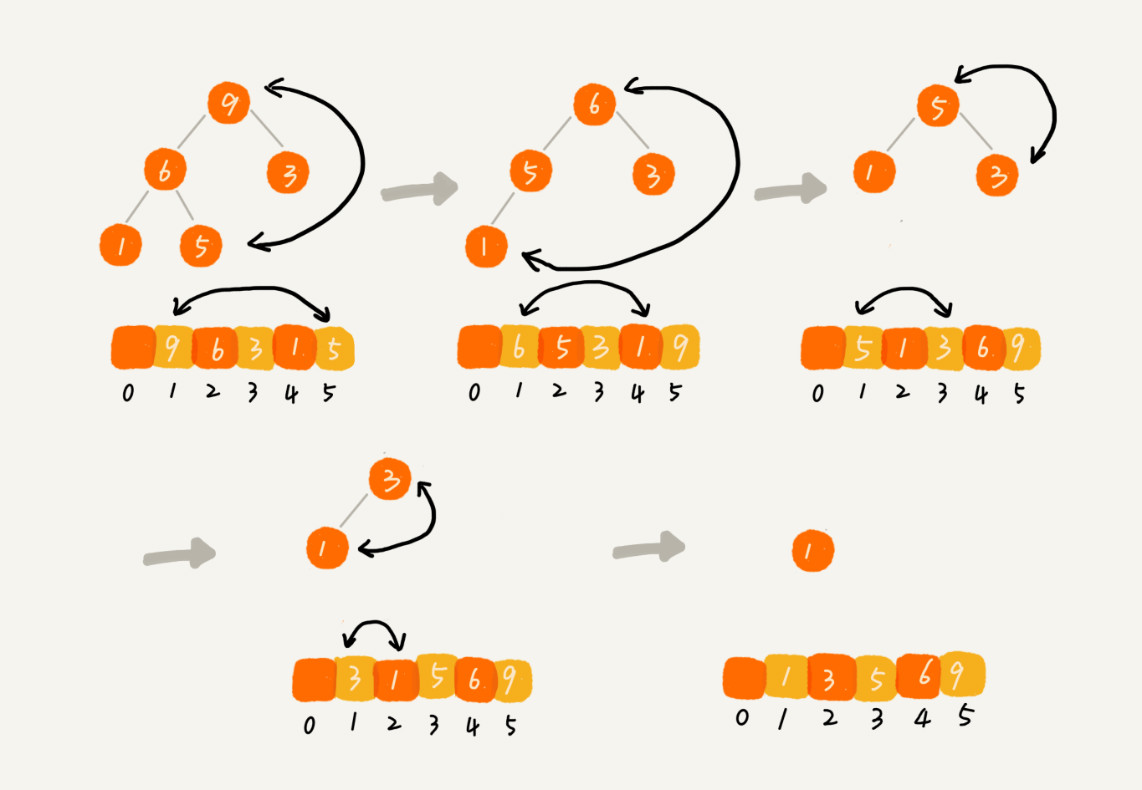
建堆结束后,数组中的数据已经是按照大顶堆的特性来组织。数组中的第一个元素就是堆顶,也就是最大的元素。把它跟最后一个元素交换,那最大元素就放到了下标为 n 的位置。
这个过程有点类似“删除堆顶元素”的操作,当堆顶元素移除之后,我们把下标为 n 的元素放到堆顶,然后再通过堆化的方法,将剩下的 n−1 个元素重新构建成堆。堆化完成之后,我们再取堆顶的元素,放到下标是 n−1 的位置,一直重复这个过程,直到最后堆中只剩下标为 1 的一个元素,排序工作就完成了。
堆排序的时间复杂度、空间复杂度以及稳定性
整个堆排序的过程,都只需要极个别临时存储空间,所以堆排序是原地排序算法。
堆排序包括建堆和排序两个操作,建堆过程的时间复杂度是 O(n),排序过程的时间复杂度是 O(nlogn),所以,堆排序整体的时间复杂度是 O(nlogn)。
堆排序不是稳定的排序算法,因为在排序的过程,存在将堆的最后一个节点跟堆顶节点互换的操作,所以就有可能改变值相同数据的原始相对顺序。
代码实现如下:



private int[] array; // 数组,从下标 1 开始存储数据 private int n; // 堆可以存储的最大数据个数 private int count; // 堆中已经存储的数据个数 public Heap(int capacity) { array = new int[capacity + 1]; n = capacity; count = 0; } /** * 插入操作 自下往上堆化 * @param data */ public void insert(int data) { if (count >= n) return; // 堆满了 count++; array[count] = data; int i = count; //i当前节点下标, i/2父节点下标, 堆中每一个节点的值都必须小于等于其子树中每个节点的值(大顶堆)。 while (i/2 > 0 && array[i] > array[i/2]) { // 自下往上堆化 swap(array, i, i/2); // swap() 函数作用: 交换下标为 i 和 i/2 的两个元素 i = i/2; } } private void swap(int[] array, int i, int j) { int temp = array[i]; array[i] = array[j]; array[j] = temp; } /** * 删除操作 自上往下堆化 */ public void removeMax() { if (count == 0) return; // 堆中没有数据 array[1] = array[count]; count--; heapify(array, count, 1); // 自上往下堆化 } private void heapify(int[] array, int n, int i) { while (true) { int maxPos = i; //i当前节点下标, i*2 为其左子节点下标 if (i*2 <= n && array[i] < array[i*2]) maxPos = i*2; //i当前节点下标, i*2+1 为其右子节点下标 if (i*2+1 <= n && array[maxPos] < array[i*2+1]) maxPos = i*2+1; if (maxPos == i) break; swap(array, i, maxPos); i = maxPos; } } /** * 构建一个堆 * 叶子节点不需要堆化, 下标是 [n/2 + 1, n]的节点是叶子节点 ; * 下标是 [n/2, 1]的数据进行堆化. * @param array 数组 * @param n 下标 */ private void buildHeap(int[] array, int n) { for (int i = n/2; i >= 1; --i) { heapify(array, n, i); } } /** * 基于堆实现排序: * 1. 构建一个堆(大顶堆); * 2. 堆顶元素即最大的元素, 把它跟最后一个元素交换, 那最大元素就放到了下标为 n 的位置。 * 3. 然后再通过堆化的方法, 将剩下的 n−1 个元素重新构建成堆。 * 4. 重复这个过程, 直到堆中元素只剩下下标为1 的一个元素, 排序完成。 * n 表示数据的个数, 数组 array 中的数据从下标 1 到 n 的位置。 * 先堆化 * @param array 数组 * @param n 下标 */ public void sort(int[] array, int n) { buildHeap(array, n); int k = n; while (k > 1) { swap(array, 1, k); k--; heapify(array, k, 1); } }
代码中,堆的数据是从数组下标为 1 的位置开始存储。那如果从 0 开始存储,实际上处理思路是没有任何变化的,唯一变化的,可能就是,代码实现的时候,计算子节点和父节点的下标的公式改变了。
如果节点的下标是 i,那左子节点的下标就是 2 ∗ i + 1,右子节点的下标就是 2 ∗ i + 2,父节点的下标就是 (i−1) / 2
5. 应用
在实际开发中,为什么快速排序要比堆排序性能好?
第一点,堆排序数据访问的方式没有快速排序友好。
对于快速排序来说,数据是顺序访问的。而对于堆排序来说,数据是跳着访问的。 比如,堆排序中,最重要的一个操作就是数据的堆化。比如下面这个例子,对堆顶节点进行堆化,会依次访问数组下标是 1,2,4,8的元素,而不是像快速排序那样,局部顺序访问,所以,这样对 CPU 缓存是不友好的。

第二点,对于同样的数据,在排序过程中,堆排序算法的数据交换次数要多于快速排序。
有序度和逆序度。对于基于比较的排序算法来说,整个排序过程就是由两个基本的操作组成的,比较和交换(或移动)。快速排序数据交换的次数不会比逆序度多。
但是堆排序的第一步是建堆,建堆的过程会打乱数据原有的相对先后顺序,导致原数据的有序度降低。比如,对于一组已经有序的数据来说,经过建堆之后,数据反而变得更无序了。

堆的应用除了堆排以外,还有如下一些应用:
1. 从大数量级数据中筛选出top n 条数据; 比如:从几十亿条订单日志中筛选出金额靠前的1000条数据
2. 在一些场景中,会根据不同优先级来处理网络请求,此时也可以用到优先队列(用堆实现的数据结构);比如:网络框架Volley就用了Java中PriorityBlockingQueue,当然它是线程安全的
3. 可以用堆来实现多路归并,从而实现有序,leetcode上也有相关的一题:Merge K Sorted Lists



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人