
数据结构-06 |树 | 二叉树| 二叉搜索树
1. 树、链表和图的联系
树、链表和图它们之间都有相应的联系;
单链表 Linked List
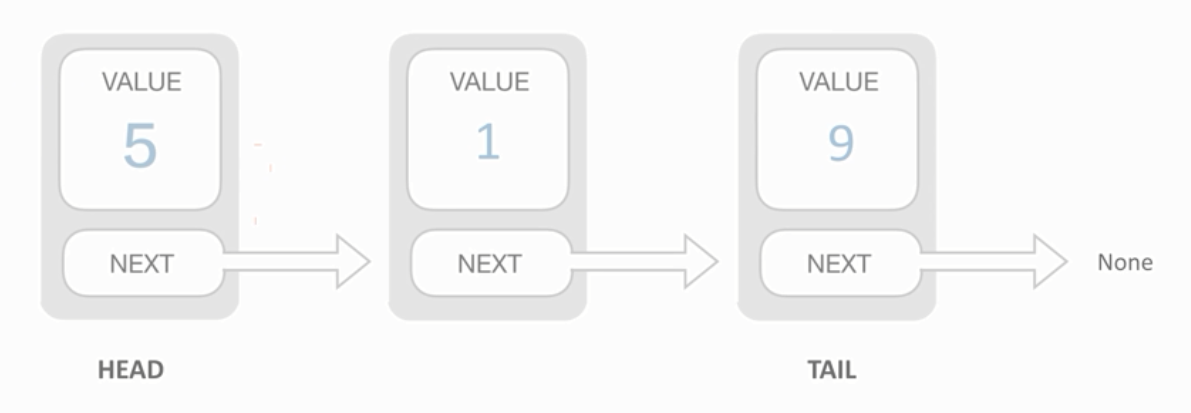
单链表:Value & Next ,每个Next都指向它的后续节点,HEAD头结点、TAIL尾节点。它最大的问题就是查询时太慢(如果要访问中间的或者倒数某个节点,必须从头节点一个个看)。
===> 加索引--跳表 (升维)
===> 二维的数据结构-树和图(多个next,next1、 next2、 next3等节点指向多个节点就变成一颗树)
Linked List链表就是特殊化的树Tree,Tree树就是特殊化的图Graph。(Graph是可以随便链,链回到它自己节点就可以,而树永远是单向链)
Tree(左节点和右节点或者认为一个树的节点有两个Next的指针)
2. 树 Tree概念
树结构的出现,
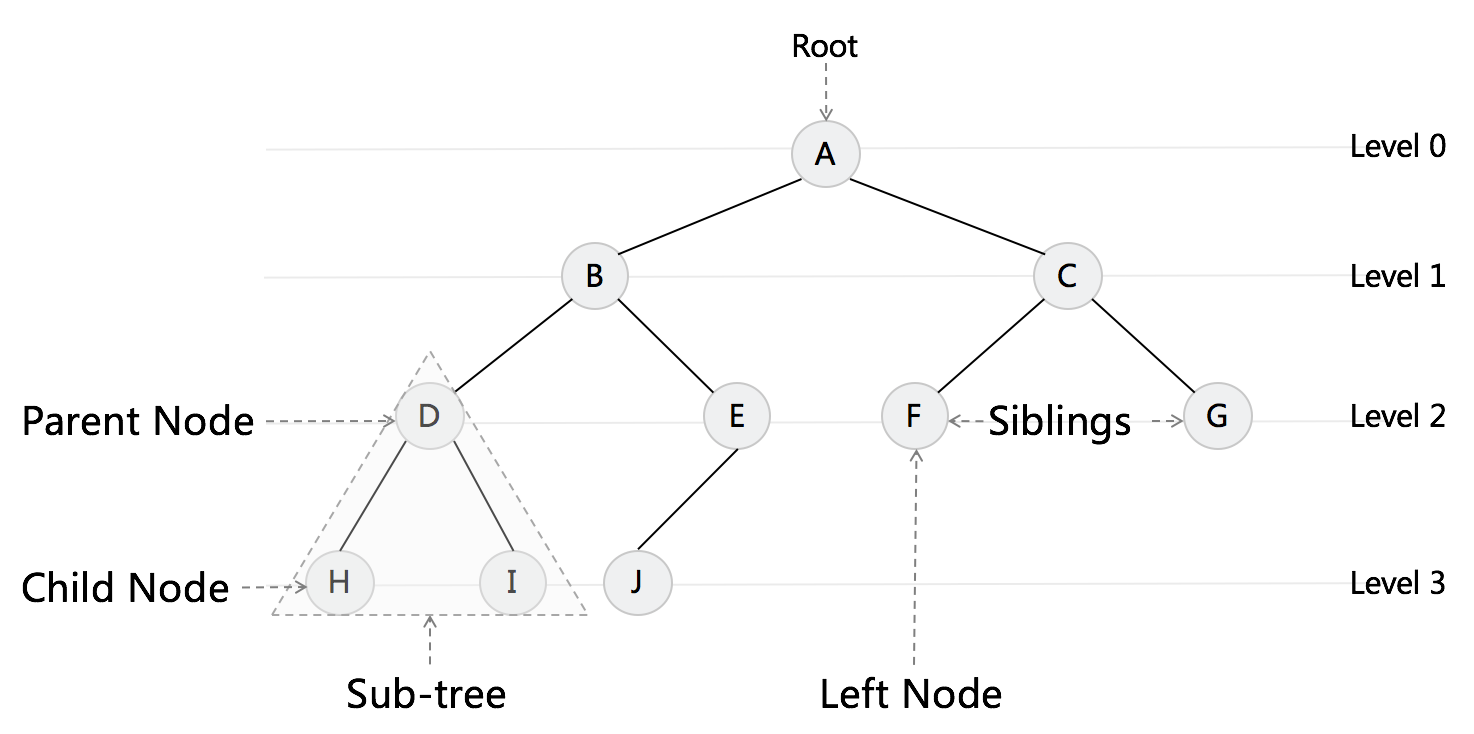
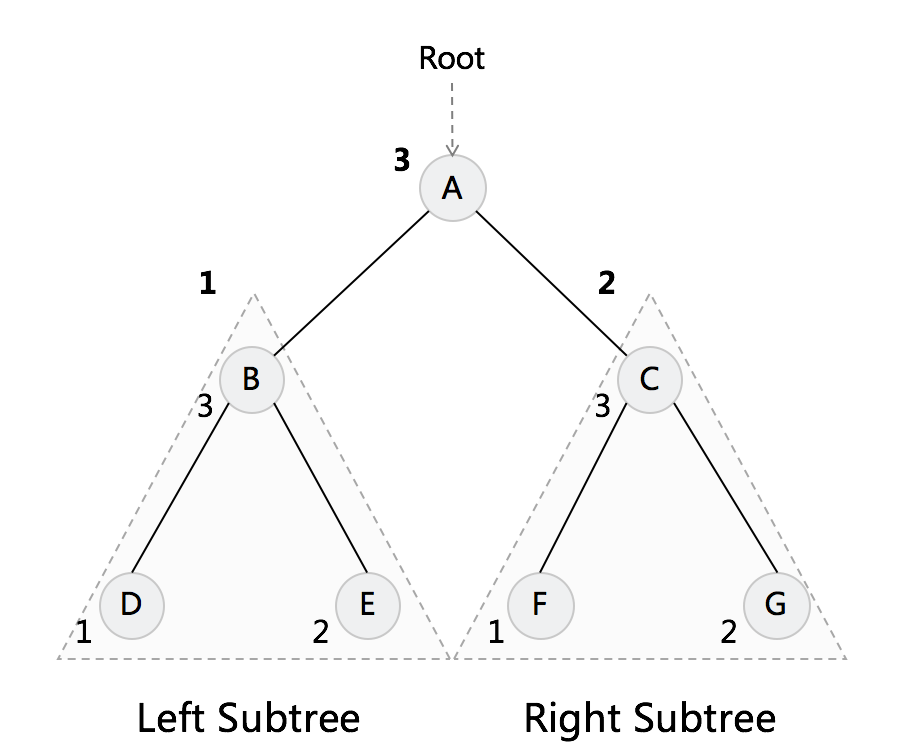
树,这个是二叉树(每个节点只有两个Next指针,或者只有一个左儿子和右儿子)。 每个元素叫作“节点”;用来连线相邻节点之间的关系叫作“父子关系”。
A 头Root节点(根节点,没有父节点),B或者C叫左儿子、 右儿子,左边任何一枝树叫左子数(比如DHI),右边任何一枝树叫右子树(比如CFG)。
树中有父节点,两边有左儿子和右儿子; 儿子之间叫兄弟节点(比如F和G,F叫左节点, G叫右节点,因为它们有同一个父节点)
没有子节点的节点叫作叶子节点或者叶节点,比如H、 I、 J、F、G
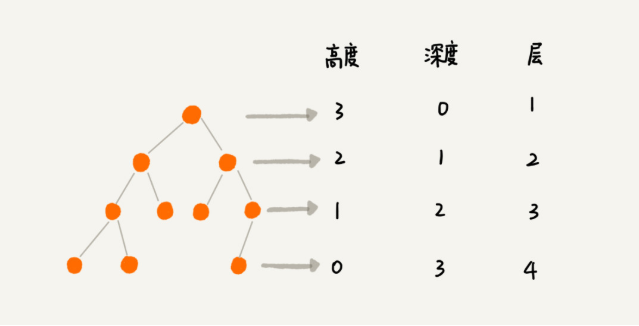
层级: 从level0 - 1 - 2 - 3
题目:分层来打印一个二叉树;
分类:
常用的为二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只有左子节点,有的节点只有右子节点。
以此类推,四叉树、八叉树等。
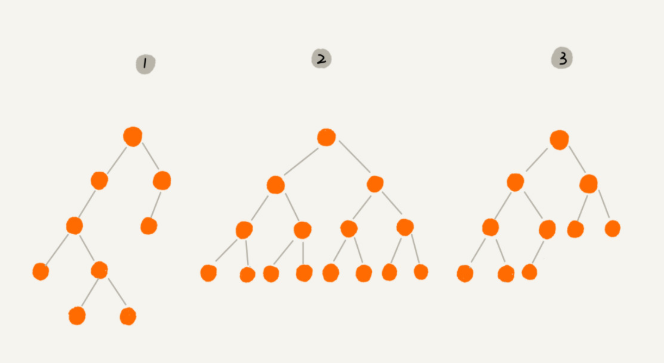
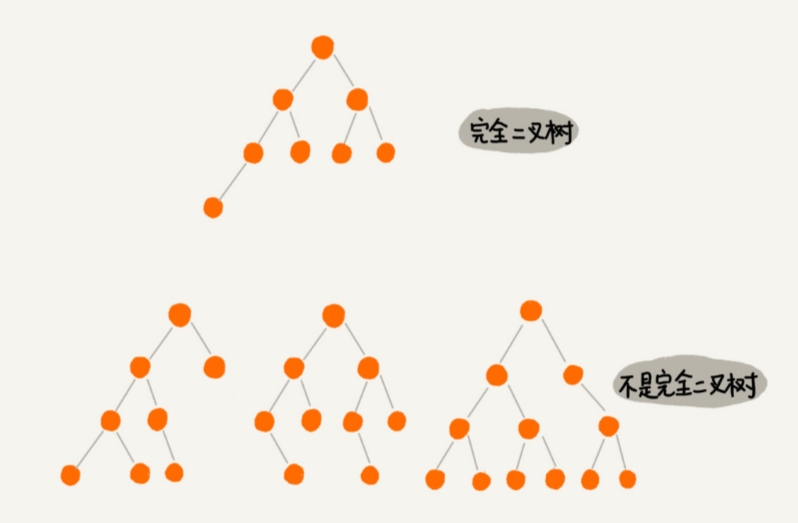
上图都是二叉树,其中,编号 2 的二叉树中,叶子节点全都在最底层,除了叶子节点之外,每个节点都有左右两个子节点,这种二叉树就叫作满二叉树。
编号 3 的二叉树中,叶子节点都在最底下两层,最后一层的叶子节点都靠左排列,并且除了最后一层,其他层的节点个数都要达到最大,这种二叉树叫作完全二叉树。
这里“最后一层的叶子节点都靠左排列”不是最后一层的子节点是左节点,而是指最后一层的子节点,从左数到右是连续,中间没有断开,缺少节点(如图例H、I、J是连续的)。(
1. 当这一层的节点未满时是不允许存在下一层节点的。
2. 每层节点填充的方式是从左到右。
)
为什么偏偏把最后一层的叶子节点靠左排列的叫完全二 叉树?如果靠右排列就不能叫完全二叉树吗 (它的由来查看二叉树的存储,为了省内存。)
3. 二叉树 Binary Tree
树结构多种多样,最常用是二叉树,即每个节点最多有两个“叉”,也就是两个子节点,分别是左子节点和右子节点。二叉树并不要求每个节点都有两个子节点,有的节点只有左子节点,有的节点只有右子节点。以此类推,可以想象一下四叉树、八叉树的样子。
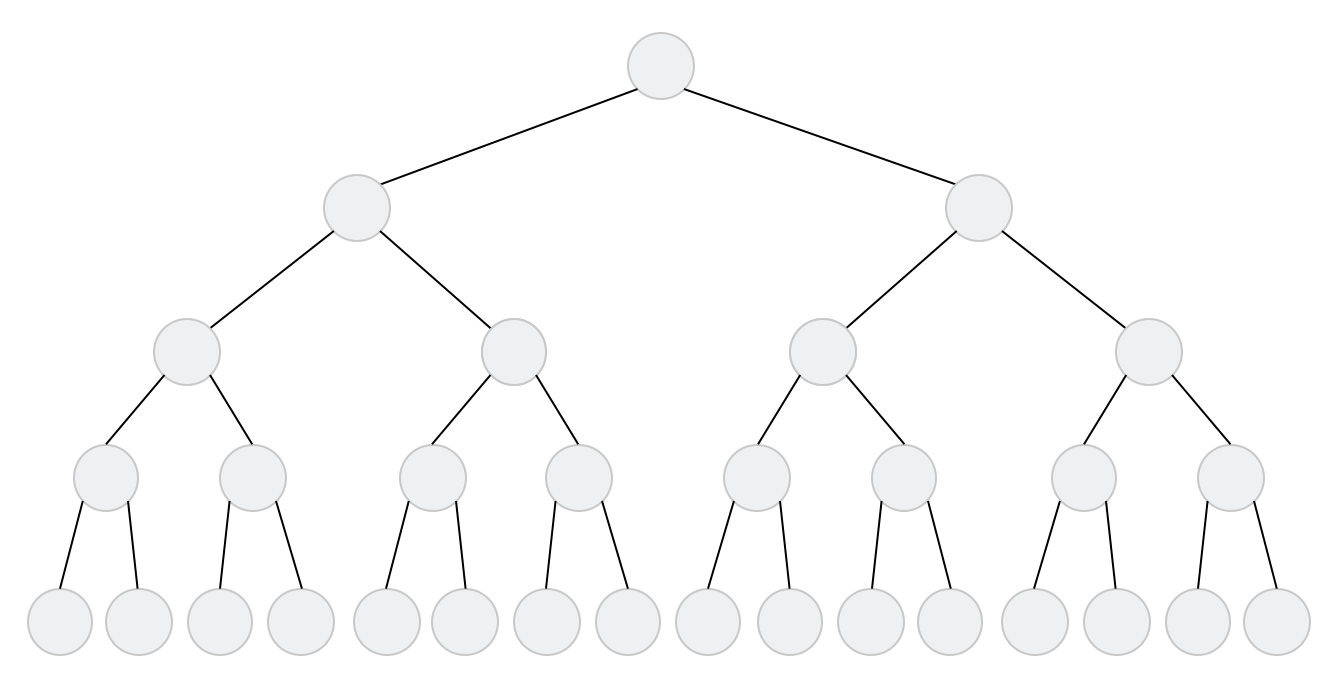
这张图是典型的二叉树,一个节点只有两个孩子(左孩子和右孩子),每个节点都有两个孩子而没有单个的情况,叫完全二叉树;除了Next节点,Next节点再指回去就是图graph。
树和图最关键的差别就是看它有没有环。如果节点只连了儿子节点,永远都不会走回去,比如第一个图中F节点指向了E或者C或者A就会形成一个环,就是图。
二叉树的存储
如何表示(或者存储)一棵二叉树:
- 一种是基于指针或者引用的二叉链式存储法,
- 一种是基于数组的顺序存储法。
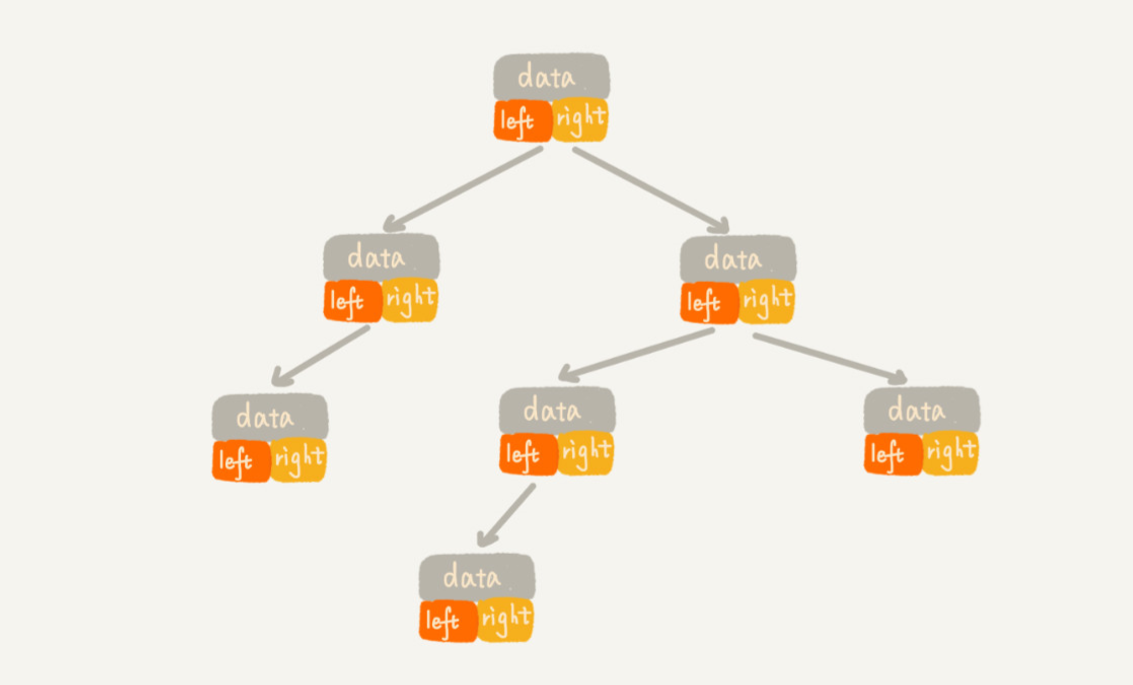
链式存储法
每个节点有三个字段,其中一个存储数据,另外两个是指向左右子节点的指针。我们只要拎住根节点,就可以通过左右子节点的指针,把整棵树都串起来。这种存储方式我们比较常用。大部分二叉树代码都是通过这种结构来实现的。
顺序存储法
顺序存储比较适合完全二叉树。
把根节点存储在下标 i = 1 的位置,那左子节点存储在下标 2 * i = 2 的位置,右子节点存储在 2 * i + 1 = 3 的位置。以此类推,B 节点的左子节点存储在 2 * i = 2 * 2 = 4 的位置,右子节点存储在 2 * i + 1 = 2 * 2 + 1 = 5 的位置。
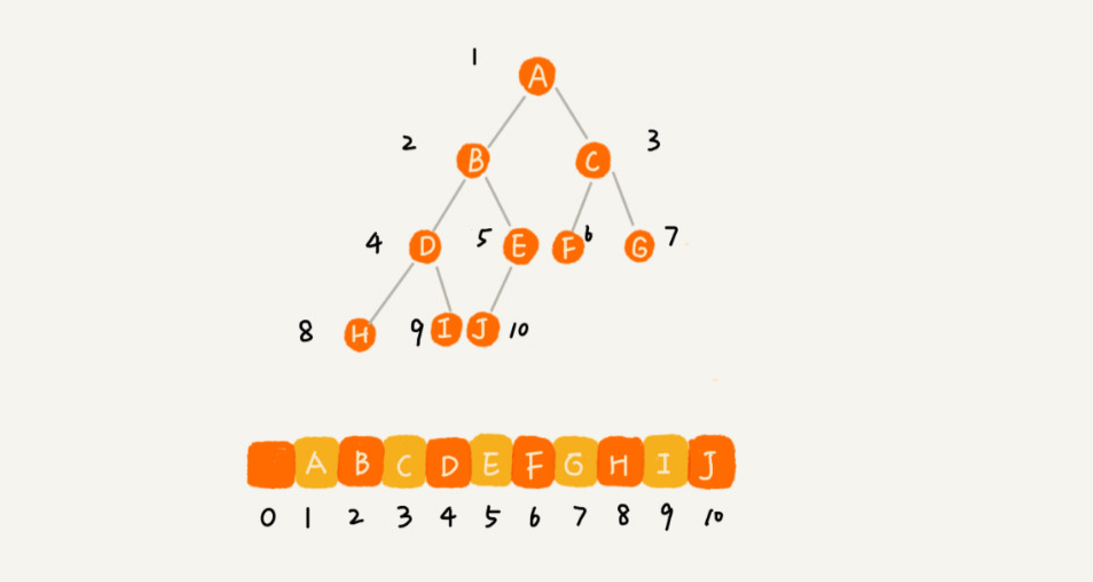
如果节点 X 存储在数组中下标为 i 的位置,下标为 2 * i 的位置存储的就是左子节点,下标为 2 * i + 1 的位置存储的就是右子节点。反过来,下标为 i/2 的位置存储就是它的父节点。通过这种方式,我们只要知道
根节点存储的位置(一般情况下,为了方便计算子节点, 根节点会存储在下标为 1 的位置),这样就可以通过下标计算,把整棵树都串起来。
上例是一棵完全二叉树,所以仅仅“浪费”了一个下标为 0 的存储位置。如果是非完全二叉树,其实会浪费比较多的数组存储空间。
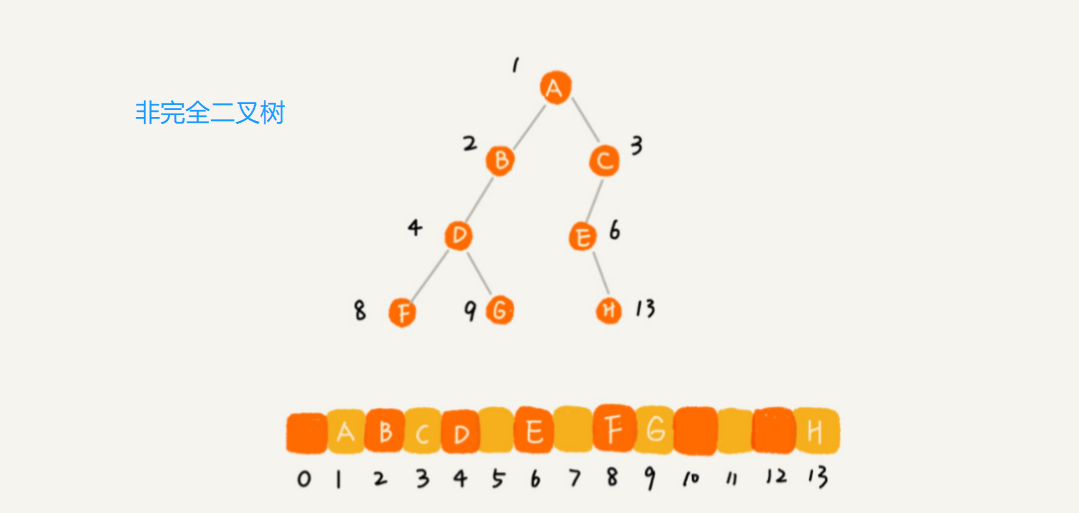
所以,如果某棵二叉树是一棵完全二叉树,那用数组存储无疑是最节省内存的一种方式。因为数组的存储方式并不需要像链式存储法那样,要存储额外的左右子节点的指针。
这也是为什么完全二叉树会单独拎出来的原因,也是为什么完全二叉树要求最后一层的子节点都靠左的原因。
堆和堆排序,堆其实就是一种完全二叉树,最常用的存储方式就是 数组。
4. 二叉树遍历 Pre-order/ In-order/ Post-order
前中后序遍历,在实际中使用的很少,真正的遍历使用的是深度优先、广度优先以及搜树

public class TreeNode {
public int val;
public TreeNode left, right;
public TreeNode(int val) {
this.val = val;
this.left = null;
this.right = null;
}
}
1.前序(Pre-order):根-左-右 (对于树中的任意节点来说,先打印这个节点,然后再打印它的左子树,最后打印它的右子树。)
2.中序(In-order):左-根-右
3.后序(Post-order):左-右-根
二叉树的前、中、后序遍历就是一个递归的过程。
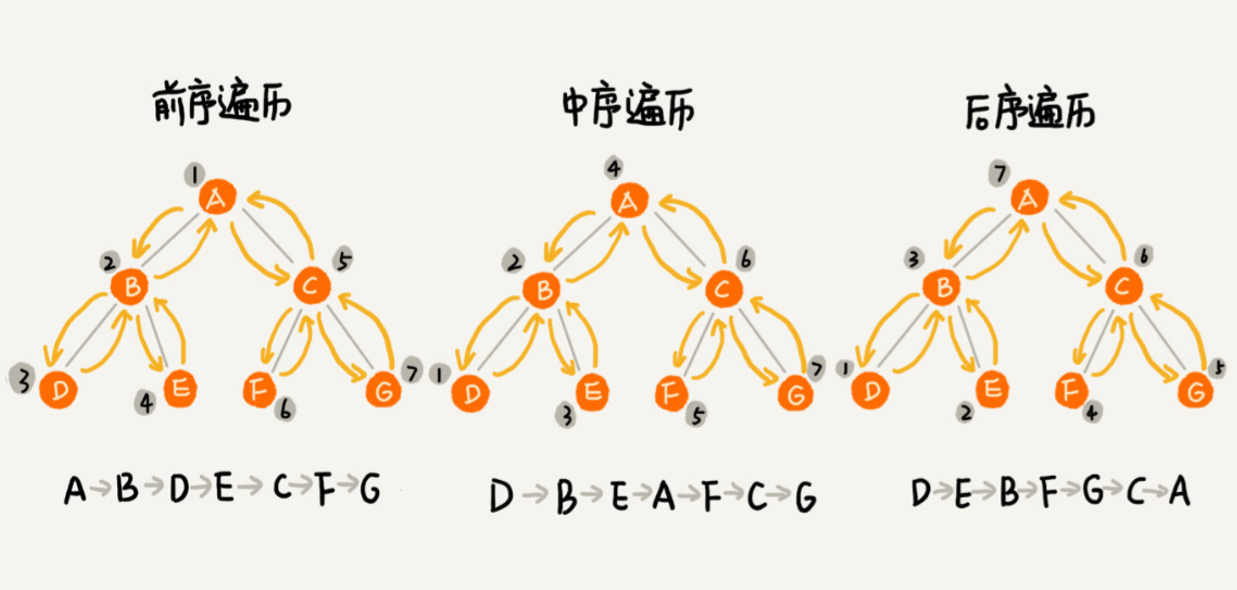
前序Pre-order
根-左-右, 先根结点,后左子树,再右子树;
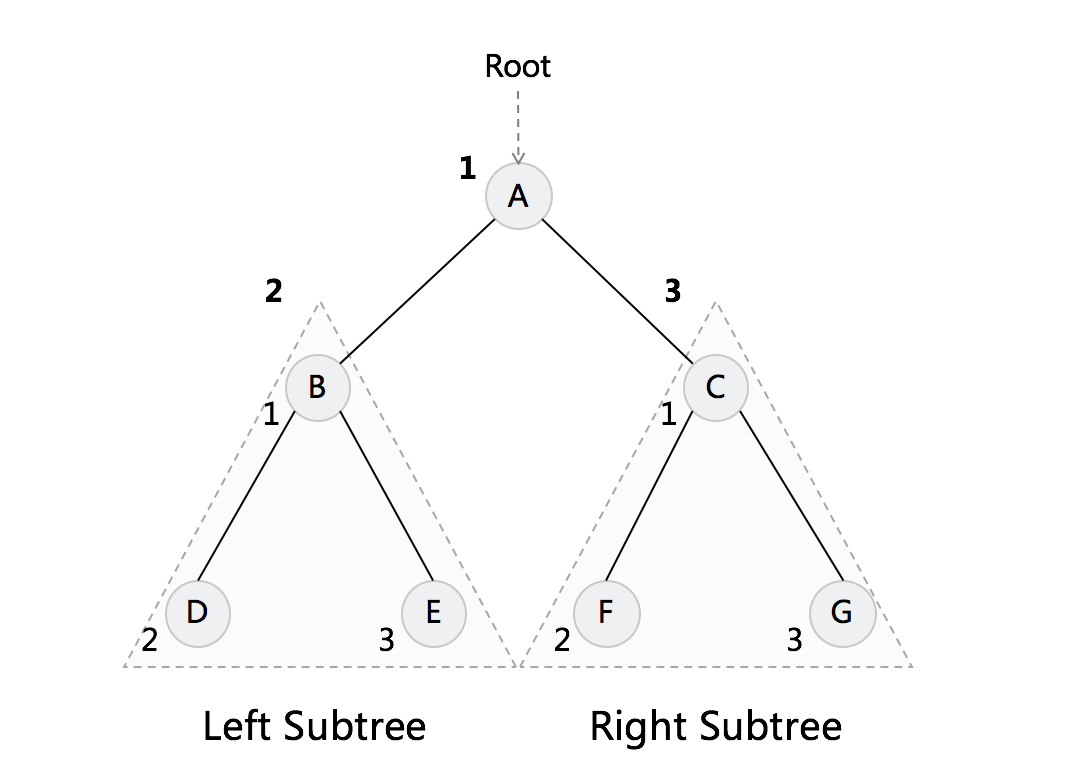
中序 In-order
左-根-右
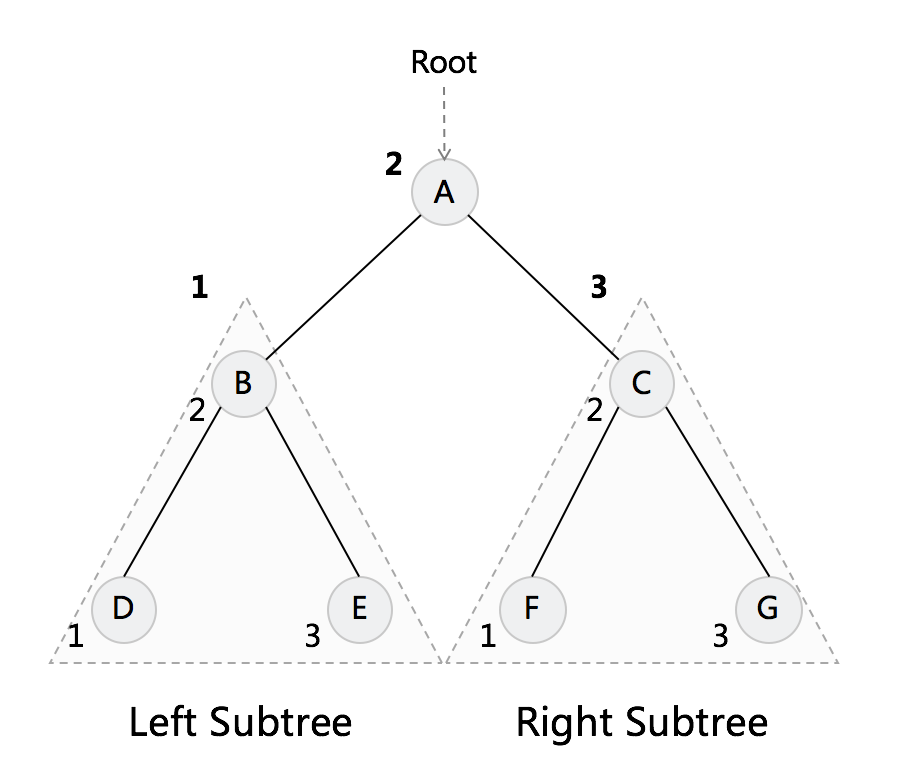
后序 Post-order
左-右-根
前序遍历的递推公式:
preOrder(r) = print r->preOrder(r->left)->preOrder(r->right)
中序遍历的递推公式:
inOrder(r) = inOrder(r->left)->print r->inOrder(r->right)
后序遍历的递推公式:
postOrder(r) = postOrder(r->left)->postOrder(r->right)->print r
层次遍历
层次遍历为:A --> B --> C --> D --> E --> F --> G
5. 二叉搜索树 Binary Search Tree的遍历
二叉搜索树,也称二叉搜索树、有序二叉树(Ordered Binary Tree)、 排序二叉树(Sorted Binary Tree),是指一棵空树或者具有下列性质的 二叉树:
1. 左子树上所有结点的值均小于它的根结点的值;
2. 右子树上所有结点的值均大于它的根结点的值;
3. 且以此类推:左、右子树也分别为二叉查找树。 (这就是 重复性!)
它的遍历是 中序遍历:升序排列
如果只是个普通的二叉树,前中后遍历只是知道如何遍历即可,但如果是二叉搜索树,中序遍历左-根-右,它遍历出来的是一个有序的数组。
二叉搜索树常见操作
1. 查询 遍历(前| 中| 后遍历),它的时间复杂度为 O(n) 的; 二分搜索,每次减半,所以二叉搜索树它的查询时间复杂度为 log2n
我们先取根节点,如果它等于我们要查找的数 据,那就返回。 如果要查找的数据比根节点的值小,那就在左子树中递归查找;
如果要查找的数 据比根节点的值大,那就在右子树中递归查找。
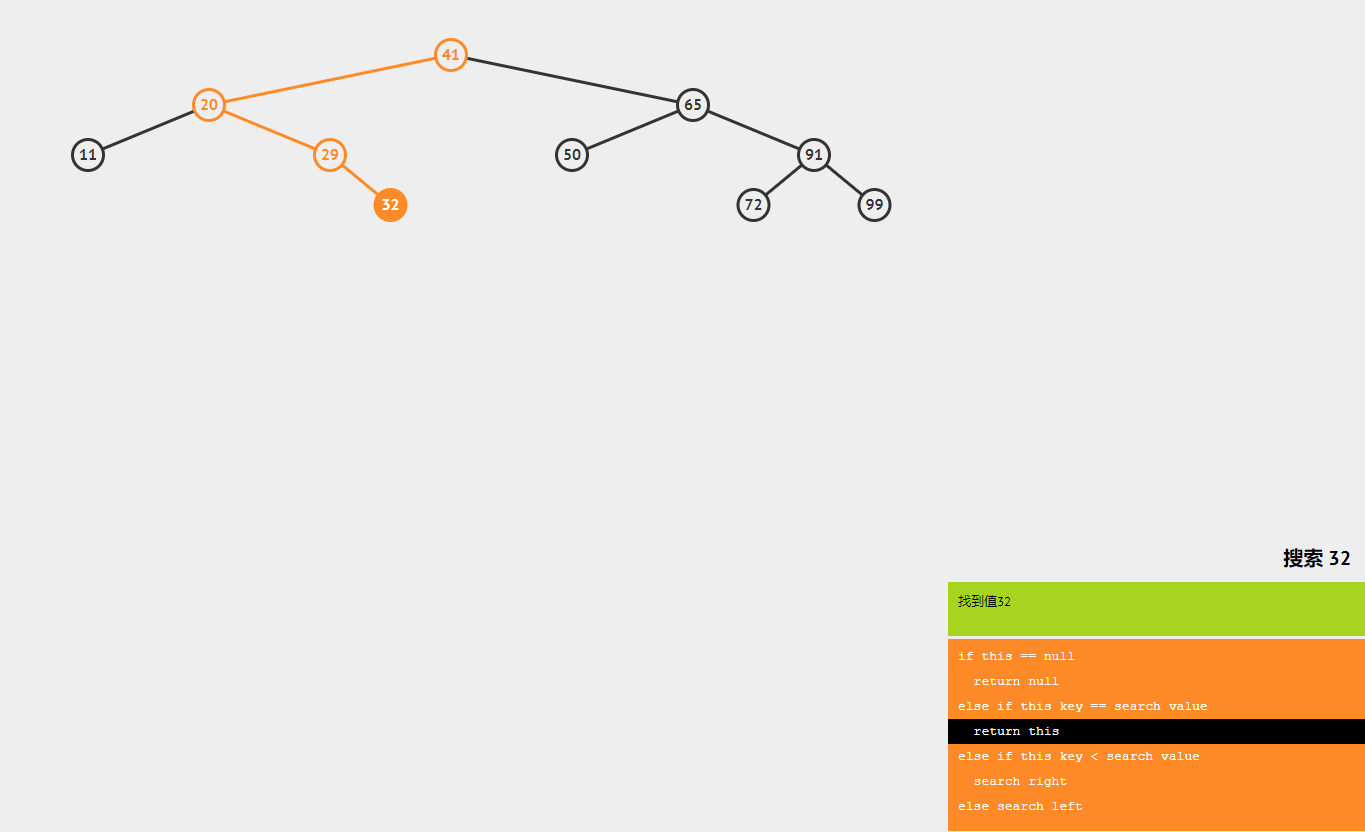
2. 插入新结点(创建)
类似查找操作。新插入的数据一般都是在叶子节点上,所以只需从根节点开始,依次比较要插入的数据和节点的大小关系。
如果要插入的数据比节点的数据大,并且节点的右子树为空,就将新数据直接插到右子节点的位 置;
如果不为空,就再递归遍历右子树,查找插入位置。
同理,如果要插入的数据比节点数值小,并且节点的左子树为空,就将新数据插入到左子节点的位置;
如果不为空,就再递归遍历左 子树,查找插入位置。

3. 删除
( ①在叶子上,直接删除,树的形状没有发生任何变化。 ②关键性的节点--如根结点或某个子树的根结点 ) 时间复杂度 O(long(n))
针对要删除节点的子节点个数的不同,分三种情况:
- 一,如果要删除的节点没有子节点,只需要直接将父节点中指向要删除节点的指针置为 null。
- 二,如果要删除的节点只有一个子节点(只有左子节点或者右子节点),只需更新父节点中,指向要删除节点的指针,让它指向要删除节点的子节点就可以了。
- 三,如果要删除的节点有两个子节点,这就比较复杂了。需要找到这个节点的右子树中的小节点,把它替换到要删除的节点上。然后再删除掉这个小节点,因为小节点肯定没有左子节点(如果有左子结点,那就不是小节点了),所以,我们可以应用上面两条规则 来删除这个小节点。
实际上,关于二叉查找树的删除操作,还有个非常简单、取巧的方法,就是单纯将要删除的节点 标记为“已删除”,但是并不真正从树中将这个节点去掉。这样原本删除的节点还需要存储在内 存中,比较浪费内存
空间,但是删除操作就变得简单了很多。而且,这种处理方法也并没有增加 插入、查找操作代码实现的难度。


4. 二叉查找树的其他操作
除了插入、删除、查找操作之外,二叉查找树中还可以支持快速地查找大节点和小节点、前驱节点和后继节点。
二叉查找树除了支持上面几个操作之外,还有一个重要的特性,就是中序遍历二叉查找树,可以 输出有序的数据序列,时间复杂度是 O(n),非常高效。因此,二叉查找树也叫作二叉排序树。
一种特殊情况是:
这个树退化成了一根根子,只有右结点,即变成了一个单链表。时间复杂度退化为 O(n)的。 加速的办法变成平衡的二叉树。
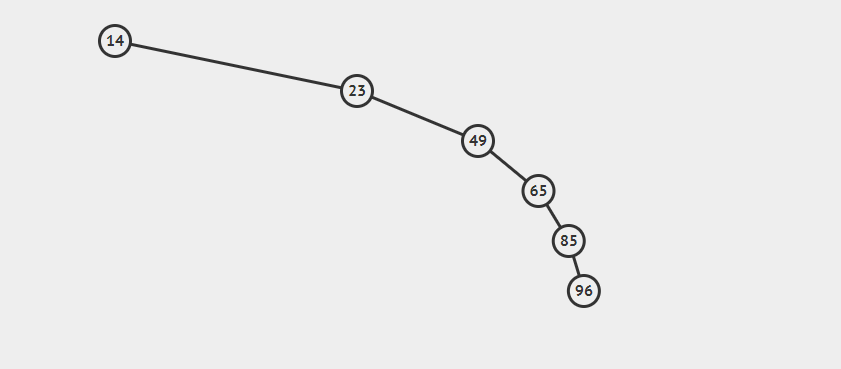
Demo:
支持重复数据的二叉查找树
默认树中节点存储的都是数字。很多时候,在实际的软件开发 中,在二叉查找树中存储的,是一个包含很多字段的对象。利用对象的某个字段作为键 值(key)来构建二叉查找树。
我们把对象中的其他字段叫作卫星数据。
前面二叉查找树的操作,针对的都是不存在键值相同的情况。那如果存储的两个对象键 值相同,这种情况该怎么处理呢?两种解决方法:
- 第一种方法比较容易。二叉查找树中每一个节点不仅会存储一个数据,通过链表和支持动态扩容的数组等数据结构,把值相同的数据都存储在同一个节点上。
- 第二种方法比较不好理解,不过更加优雅。每个节点仍然只存储一个数据。在查找插入位置的过程中,如果碰到一个节点的值,与要插入数据的值相同,就将这个要插入的数据放到这个节点的右子树,也就是说,把这个新插入的数据当作大于这个节点的值来处理。
二叉查找树的复杂度分析
二叉查找树的插入、删除、查找操作的时间复杂度。
实际上,二叉查找树的形态各式各样。比如这个图中,对于同一组数据,我们构造了三种二叉查找树。它们的查找、插入、删除操作的执行效率都是不一样的。
第一种二叉查找树,根节点 的左右子树极度不平衡,已经退化成了链表,所以查找的时间复杂度就变成了 O(n)。

理想的情况,二叉查找树是一棵完 全二叉树(或满二叉树)。这时,插入、删除、查找的时间复杂度是多少呢?
从前面例子不管操作是插入、删除还是查找,时间复杂度其实都跟树的高度成正比,也就是 O(height)。现在问题就转变成另外一个了,即如何求一棵包含n 个节点的完全二叉树的高度?
树的高度就等于大层数减一,为了方便计算,转换成层来表示。从图中可以看出,包含n个节点的完全二叉树中,第一层包含1 个节点,第二层包含2 个节点,第三层包含4 个节点,依次类推,下面一层节点个数是上一层的2 倍,第K 层包含的节点个数就是 2(K-1)。
不过,对于完全二叉树来说,后一层的节点个数有点儿不遵守上面的规律了。它包含的节点个数在1个到 2(L-1) 个之间(假设大层数是 L)。把每一层的节点个数加起来就是总的节点个数n。也即如果节点的个数是n,那么n 满足这样一个关系:
n >= 1+2+4+8+...+2(L-2)+1 n <= 1+2+4+8+...+2(L-2)+2(L-1) 借助等比数列的求和公式,可计算出,L 的范围是 [log(n+1), log n +1]。 完全二叉树 的层数小于等于 log n +1,也就是说,完全二叉树的高度小于等于 log n。
对于极度不平衡的二叉查找树,它的查找性能肯定不能满足我们的需求。
需要构建一种不管怎么删除、插入数据,在任何时候,都能保持任意节点左右子树都比较平衡的二叉查找树,
一种特殊的二叉查找树,平衡二叉查找树。平衡二叉查找树的高度接近logn,所以插入、删除、查找操作的时间复杂度也比较稳定,是 O(logn)。
它的查询和插入不再是O(n), 而是log n, 就相当于加速了。(二维结构,排好序)
树,本质上是到了这个节点有两个Next指针,指向左子树或指向右子树,如果左右子树没有任何关系的话这种结构是很低效的。
左子树和右子树会有一个先后顺序的关系,即二叉搜索树。
一棵没有任何特点的二叉树很少有实际高效实用的办法,用的最高的是二叉搜索树、在普通二叉树上发展出来的平衡二叉搜索树、红黑树
二叉搜索树:Search指的是在树中这些节点之间有一个序列关系,搜索的时候更便捷,也称为有序二叉树(排序二叉树)。
特征:如果是空树也是二叉排序树;如果不是空树则:
1. 左子树上所有结点的值均小于它的根结点的值;
2. 右子树上所有结点的值均大于它的根结点的值; (这里是左右子树去做)
3. Recursively, 左、右子树也分别为二叉查找树。
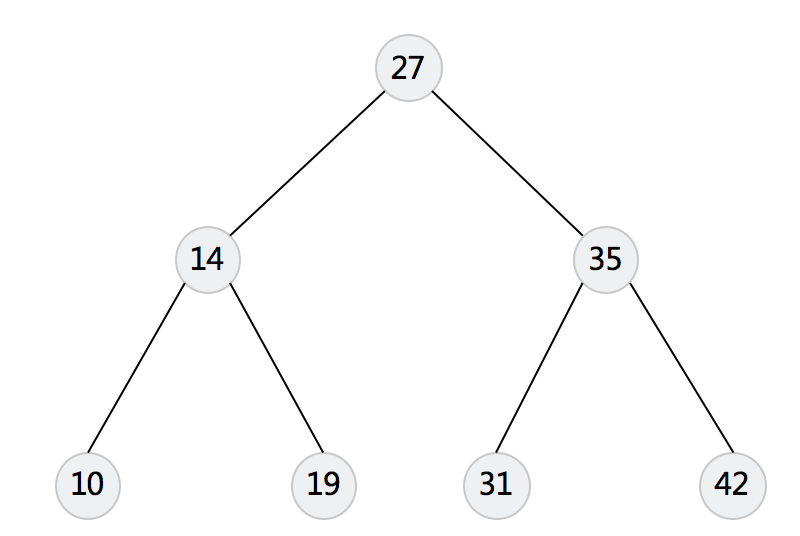
二叉搜索树,
左子树上的所有节点都要 < 根节点;
右子树上的所有节点都要 > 根节点
比如上图中, 左子树14|10|19都要 < 27, 右子树35|31|42都要 > 27;
同理, 14 > 10, 14 < 19;
搜索查找效率很高,LogN
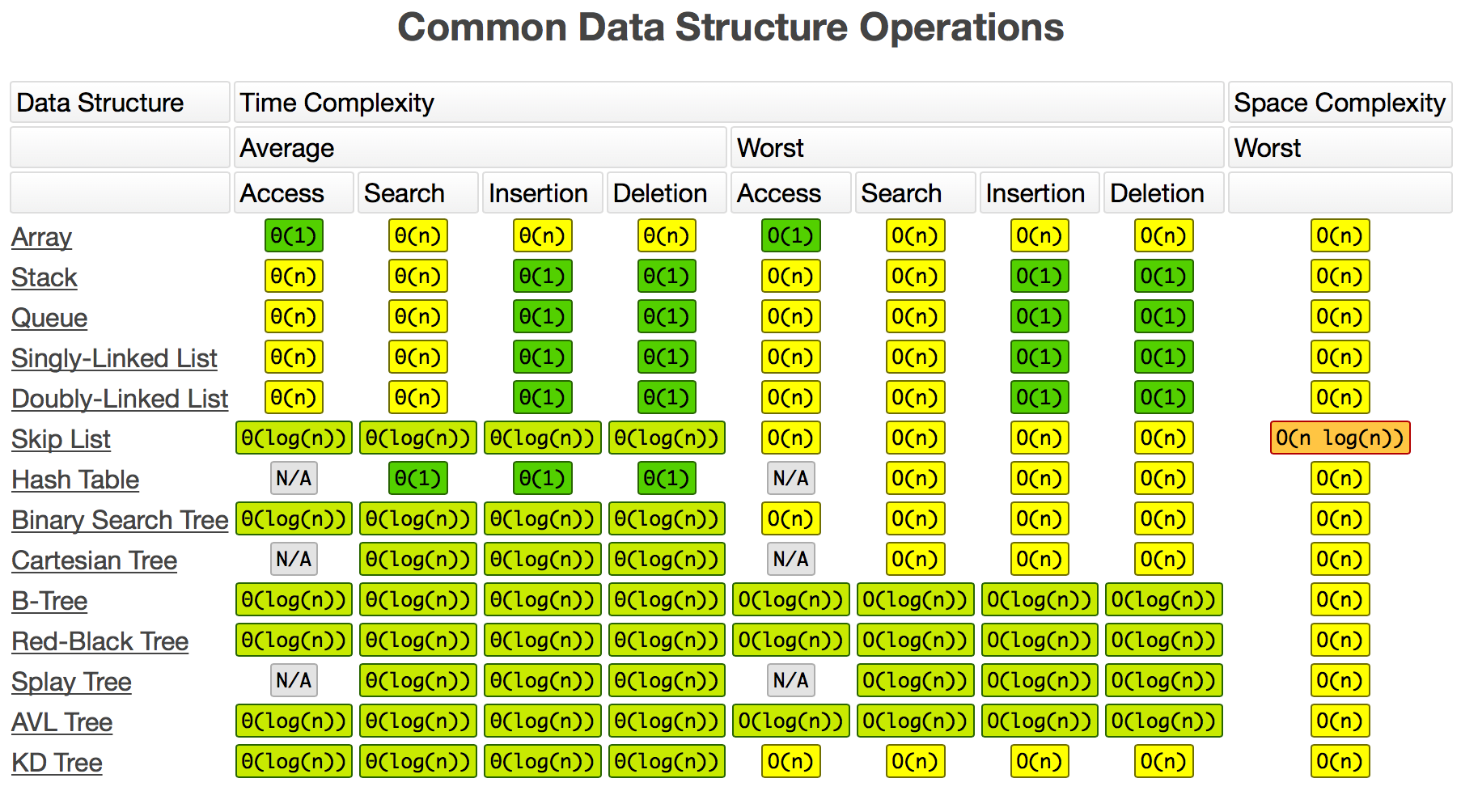
https://www.bigocheatsheet.com/
1. 给定一组数据,比如 1,3,5,6,9,10。你来算算,可以构建出多少种不同的二叉树?
如果是完全二叉树,则问题可简化为数组内的元素有多少种组合方式,n! 种方法。
C[n,2n] / (n+1)种形状,c是组合数,节点的不同又是一个全排列,一共就是n!*C[n,2n] / (n+1)个二叉树。 https://en.wikipedia.org/wiki/Catalan_number
散列表与二叉树的对比
散列表的插入、删除、查找操作的时间复杂度可以做到常量级的 O(1),非常高效。而二叉查找树在比较平衡的情况下,插入、删除、查找操作时间复杂度才是 O(logn),
相对散列表,好像并没有什么优势,那我们为什么还要用二叉查找树呢?
原因如下:
第一,散列表中的数据是无序存储的,如果要输出有序的数据,需要先进行排序。而对于二叉查 找树来说,只需要中序遍历,就可以在 O(n) 的时间复杂度内,输出有序的数据序列。
第二,散列表扩容耗时很多,而且当遇到散列冲突时,性能不稳定,尽管二叉查找树的性能不稳定,但是在工程中,常用的平衡二叉查找树的性能非常稳定,时间复杂度稳定在 O(logn)。
第三,笼统地来说,尽管散列表的查找等操作的时间复杂度是常量级的,但因为哈希冲突的存 在,这个常量不一定比 logn 小,所以实际的查找速度可能不一定比 O(logn) 快。加上哈希函数耗时,也不一定就比平衡二叉查找树的效率高。
第四,散列表的构造比二叉查找树要复杂,考虑的东西很多。比如散列函数的设计、冲突解决办法、扩容、缩容等。平衡二叉查找树只需要考虑平衡性这一个问题,而且这个问题的解决方 案比较成熟、固定。
最后,为了避免过多的散列冲突,散列表装载因子不能太大,特别是基于开放寻址法解决冲突的 散列表,不然会浪费一定的存储空间。
综合这几点,平衡二叉查找树在某些方面还是优于散列表的,所以,这两者的存在并不冲突。我 们在实际的开发过程中,需要结合具体的需求来选择使用哪一个。
二叉树高度如何通过编程,求出一棵给定二叉树的确切高度呢?
确定二叉树高度有两种思路:
第一种是深度优先思想的递归,分别求左右子树的高度。当前节点的高度就是左右子树中较大的那个+1;(根节点高度 = max(左子树高度,右子树高度)+1 )
第二种可以采用层次遍历的方式,每一层记录都记录下当前队列的长度,这个是队尾,每一层队头从0开始。然后每遍历一个元素,队头下标 +1。直到队头下标等于队尾下标。这个时候表示当前层遍历完成。每
一层刚开始遍历的时候,树的高度+1。后队列为空,就能得到树的高度。
图Graph
最短的时间内用最低的费用到达相应的目标。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2018-06-15 11.Django|中间件