
CDH| Spark升级
升级之Spark升级
在CDH5.12.1集群中,默认安装的Spark是1.6版本,这里需要将其升级为Spark2.1版本。经查阅官方文档,发现Spark1.6和2.x是可以并行安装的,也就是说可以不用删除默认的1.6版本,可以直接安装2.x版本,它们各自用的端口也是不一样的。
Cloudera发布Apache Spark 2概述(可以在这里面找到安装方法和parcel包的仓库)
cloudera的官网可以下载相关的parcel 的离线安装包:
https://www.cloudera.com/documentation/spark2/latest/topics/spark2_installing.html
Cloudera Manager及5.12.0版本的介绍:
升级过程
1 离线包下载
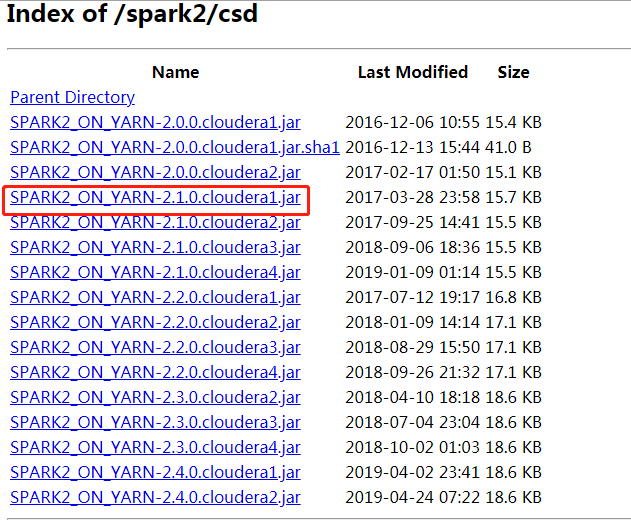
1)所需软件:http://archive.cloudera.com/spark2/csd/
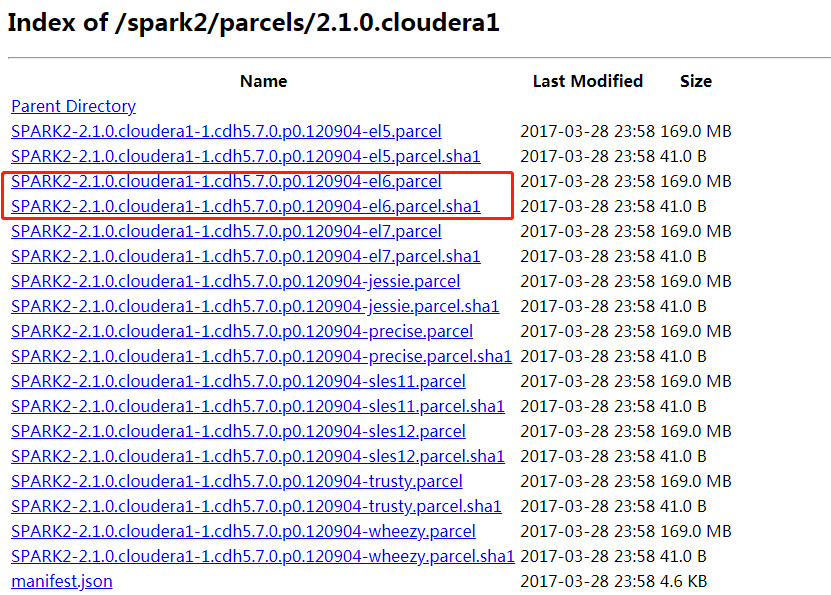
2)Parcels 包的下载地址:http://archive.cloudera.com/spark2/parcels/2.1.0.cloudera1/
2 离线包上传
1)上传文件SPARK2_ON_YARN-2.1.0.cloudera1.jar到/opt/cloudera/csd/下面
2)上传文件SPARK2-2.1.0.cloudera1-1.cdh5.7.0.p0.120904-el6.parcel和SPARK2-2.1.0.cloudera1-1.cdh5.7.0.p0.120904-el6.parcel.sha1 到/opt/cloudera/parcel-repo/
3)将SPARK2-2.1.0.cloudera1-1.cdh5.7.0.p0.120904-el6.parcel.sha1重命名为SPARK2-2.1.0.cloudera1-1.cdh5.7.0.p0.120904-el6.parcel.sha
[root@hadoop101 parcel-repo]# mv /opt/cloudera/parcel-repo/SPARK2-2.1.0.cloudera1-1.cdh5.7.0.p0.120904-el6.parcel.sha1 /opt/cloudera/parcel-repo/SPARK2-2.1.0.cloudera1-1.cdh5.7.0.p0.120904-el6.parcel.sha

[kris@hadoop101 parcel-repo]$ ll
total 2673860
-rw-r--r-- 1 kris kris 364984320 Jul 2 2019 APACHE_PHOENIX-4.14.0-cdh5.14.2.p0.3-el7.parcel
-rw-r--r-- 1 kris kris 41 Jul 2 2019 APACHE_PHOENIX-4.14.0-cdh5.14.2.p0.3-el7.parcel.sha
-rw-r----- 1 root root 14114 Jul 2 2019 APACHE_PHOENIX-4.14.0-cdh5.14.2.p0.3-el7.parcel.torrent
-rw-r--r-- 1 cloudera-scm cloudera-scm 2108071134 Jun 27 2019 CDH-5.14.2-1.cdh5.14.2.p0.3-el7.parcel
-rw-r--r-- 1 cloudera-scm cloudera-scm 41 Jun 27 2019 CDH-5.14.2-1.cdh5.14.2.p0.3-el7.parcel.sha
-rw-r----- 1 cloudera-scm cloudera-scm 80586 Jun 27 2019 CDH-5.14.2-1.cdh5.14.2.p0.3-el7.parcel.torrent
-rw-r--r-- 1 cloudera-scm cloudera-scm 72851219 Jun 29 2019 KAFKA-3.1.1-1.3.1.1.p0.2-el7.parcel
-rw-r--r-- 1 cloudera-scm cloudera-scm 41 Jun 29 2019 KAFKA-3.1.1-1.3.1.1.p0.2-el7.parcel.sha
-rw-r----- 1 root root 2940 Jun 29 2019 KAFKA-3.1.1-1.3.1.1.p0.2-el7.parcel.torrent
-rw-r--r-- 1 cloudera-scm cloudera-scm 74062 Jun 27 2019 manifest.json
-rw-r--r-- 1 cloudera-scm cloudera-scm 191904064 Jun 29 2019 SPARK2-2.3.0.cloudera4-1.cdh5.13.3.p0.611179-el7.parcel
-rw-r--r-- 1 cloudera-scm cloudera-scm 41 Oct 5 2018 SPARK2-2.3.0.cloudera4-1.cdh5.13.3.p0.611179-el7.parcel.sha
-rw-r----- 1 cloudera-scm cloudera-scm 7521 Jun 29 2019 SPARK2-2.3.0.cloudera4-1.cdh5.13.3.p0.611179-el7.parcel.torrent
[kris@hadoop101 parcel-repo]$ pwd
/home/kris/apps/usr/webserver/cloudera/parcel-repo
[kris@hadoop101 csd]$ pwd
/home/kris/apps/usr/webserver/cloudera/csd
[kris@hadoop101 csd]$ ll
total 28
-rw-r--r-- 1 cloudera-scm cloudera-scm 5670 Feb 22 2018 KAFKA-1.2.0.jar
-rw-r--r-- 1 cloudera-scm cloudera-scm 19037 Oct 5 2018 SPARK2_ON_YARN-2.3.0.cloudera4.jar
[kris@hadoop101 csd]$ ll
total 28
-rw-r--r-- 1 cloudera-scm cloudera-scm 5670 Feb 22 2018 KAFKA-1.2.0.jar
-rw-r--r-- 1 cloudera-scm cloudera-scm 19037 Oct 5 2018 SPARK2_ON_YARN-2.3.0.cloudera4.jar
页面操作
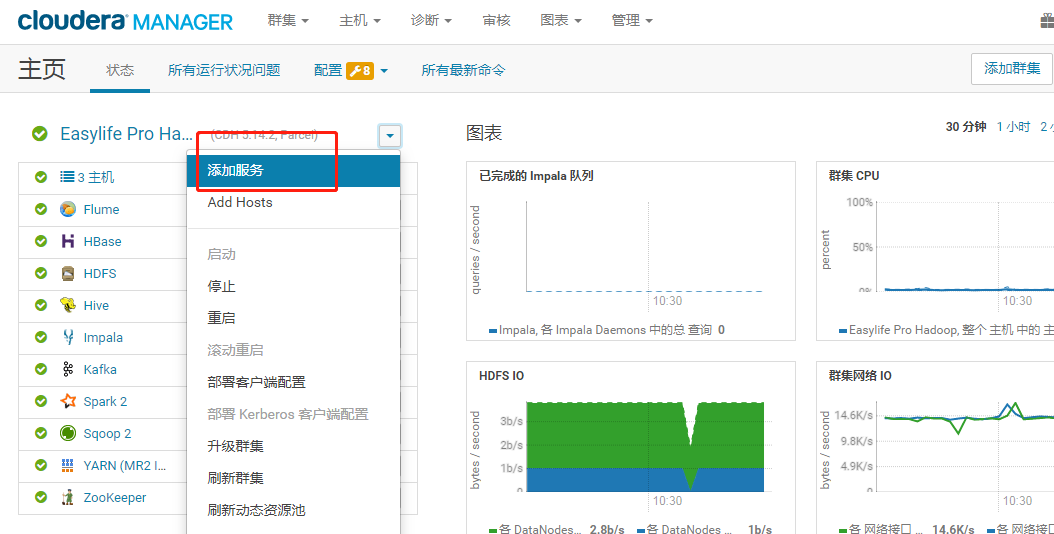
更新Parcel
在cm首页点击Parcel,再点击检查新Parcel

点击分配、点击激活、回到首页点击添加服务
如果没有Spark2,则重启server:
[root@hadoop101 ~]# /opt/module/cm/cm-5.12.1/etc/init.d/cloudera-scm-server restart
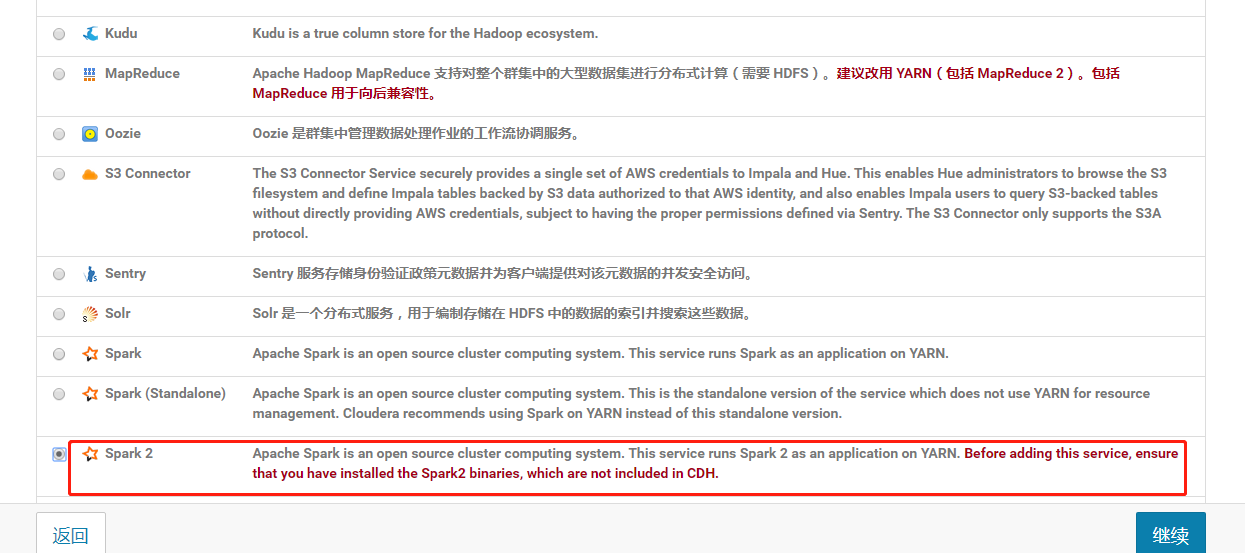
选择一组依赖关系

角色分配、 部署并启动
注意:这里我报了一个错:客户端配置 (id=12) 已使用 1 退出,而预期值为 0
1)问题原因:最后找到原因是因为CM安装Spark不会去环境变量去找Java,需要将Java路径添加到CM配置文件
2)解决方法1(需要重启cdh):
[root@hadoop101 java]# vim /opt/module/cm/cm-5.12.1/lib64/cmf/service/client/deploy-cc.sh
在文件最后加上
JAVA_HOME= /opt/module/jdk1.8.0_104
export JAVA_HOME= /opt/module/jdk1.8.0_104
3)解决方法2(无需重启cdh):
查看/opt/module/cm/cm-5.12.1/lib64/cmf/service/common/cloudera-config.sh
找到java8的home目录,会发现cdh不会使用系统默认的JAVA_HOME环境变量,而是依照bigtop进行管理,因此我们需要在指定的/usr/java/default目录下安装jdk。当然我们已经在/opt/module/jdk1.8.0_104下安装了jdk,因此创建一个连接过去即可
[root@hadoop101 ~]# mkdir /usr/java
[root@hadoop101 ~]# ln -s /opt/module/jdk1.8.0_104/ /usr/java/default
[root@hadoop102 ~]# mkdir /usr/java
[root@hadoop102 ~]# ln -s /opt/module/jdk1.8.0_104/ /usr/java/default
[root@hadoop103 ~]# mkdir /usr/java
[root@hadoop103 ~]# ln -s /opt/module/jdk1.8.0_104/ /usr/java/default
3)解决方法3(需要重启cdh):
找到hadoop101、hadoop102、hadoop103三台机器的配置,配置java主目录
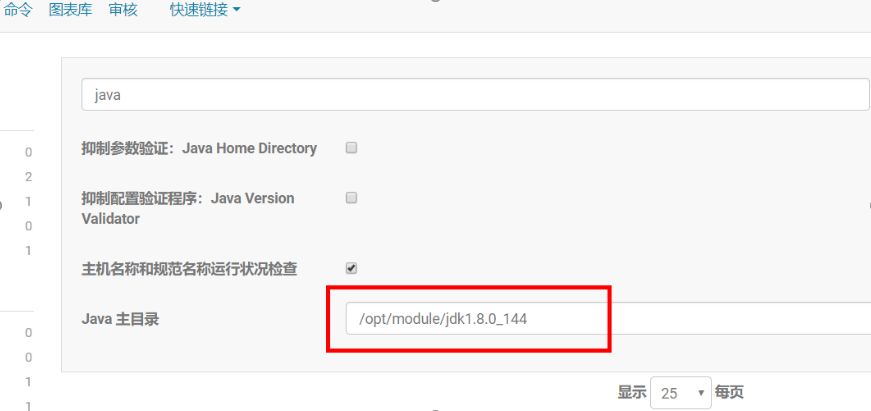
命令行查看命令
[hdfs@hadoop101 ~]$ spa
spark2-shell spark2-submit spark-shell spark-submit spax



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2019-04-22 常见异常