
Flink| 容错机制| 检查点
一致性检查点(checkpoint)
从检查点恢复状态
Flink检查点算法
保存点(save point)
1. 一致性检查点(checkpoint)
Flink--有状态的流式处理
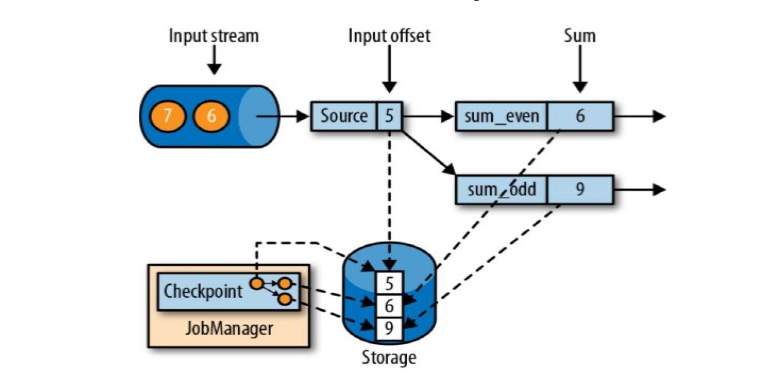
如上图sum_even (2+4),sum_odd(1 + 3 + 5),5这个数据之前的都处理完了,就出保存一个checkpoint;Source任务保存状态5,sum_event任务保存状态6,sum_odd保存状态是9;这三个保存到状态后端中就构成了CheckPoint;
Flink故障恢复机制的核心,就是应用状态的一致性检查点;
有状态流应用的一致性检查点(checkpoint),其实就是所有任务的状态,在某个时间点的一份拷贝(一份快照);这个时间点,应该是所有任务都恰好处理完一个相同的输入数据的时候 。(这个同一时间点并不是物理上的在同一时刻)
2. 从检查点恢复状态
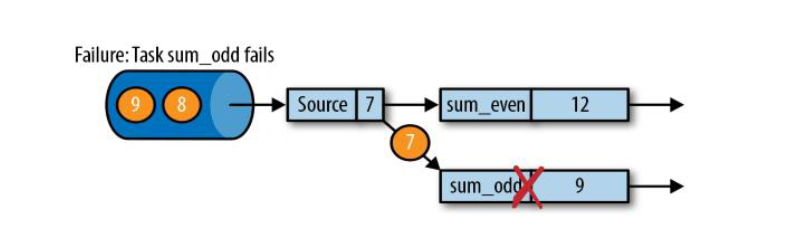
sum_even(2 + 4 + 6);sum_odd(1 + 3 + 5);
在执行应用程序期间,Flink会定期保存状态的一致性检查点;
如果发生故障,Flink将会使用最近的检查点来一致恢复应用程序的状态,并重新启动处理流程;
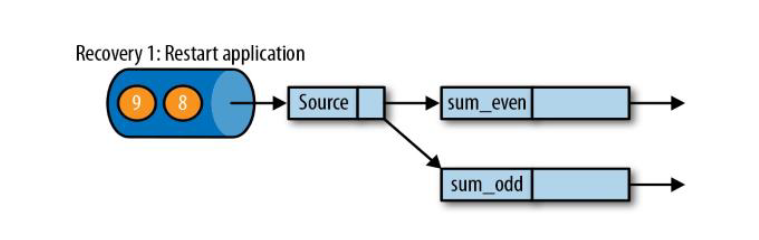
遇到故障之后,第一步就是重启应用;
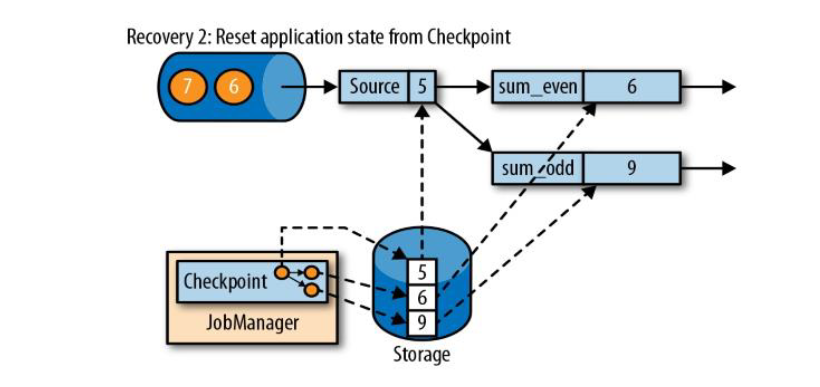
第二步是从checkpoint中读取状态,将状态重置;
从检查点重新启动应用程序后,其内部状态与检查点完成时的状态完全相同;
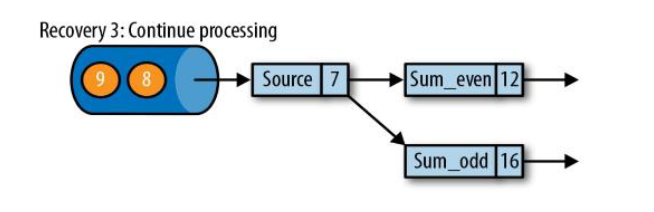
第三步 :开始消费并处理检查点到发生故障之间的所有数据;
这种检查点的保存和恢复机制可以为应用程序状态提供“精确一次”(exactly-once)的一致性,因为所有算子都会保存检查点并恢复其所有状态,这样一来所有的输入流就都会被重置到检查点完成时的位置。
3. 检查点的实现算法
简单:暂停应用,保存状态到检查点,再重新恢复应用;
Flink的改进:基于Chandy-Lamport算法的分布式快照;将检查点的保存和数据处理分离开,不暂停整个应用;
检查点分界线(CheckPoint Barrier)
Flink的检查点算法用到了一种称为分界线(barrier)的特殊数据形式,用来把一条流上数据按照不同的检查点分开;
分界线之前到来的数据导致的状态更改,都会被包含在当前分界线所属的检查点中;而基于分界线之后的数据导致的所有更改,就会被包含在之后的检查点中;
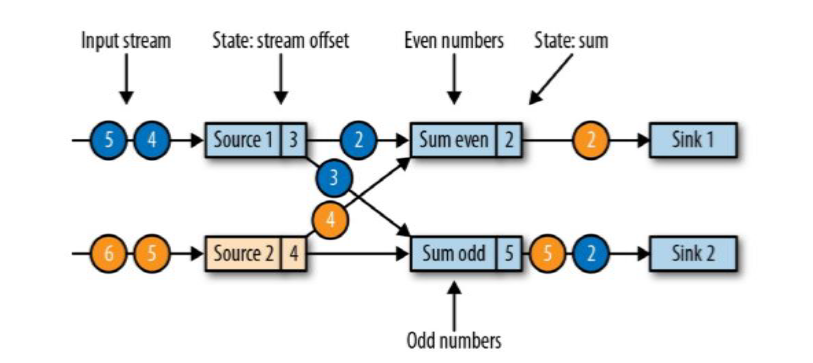
现在是一个有两个输入流的应用程序,用并行的两个Source任务来读取:
两个并行输入源按奇偶数来做sum,类似keyBy重分区map为二元组再做奇偶keyBy,Sum odd(1 + 1 + 3),Sum even(2)
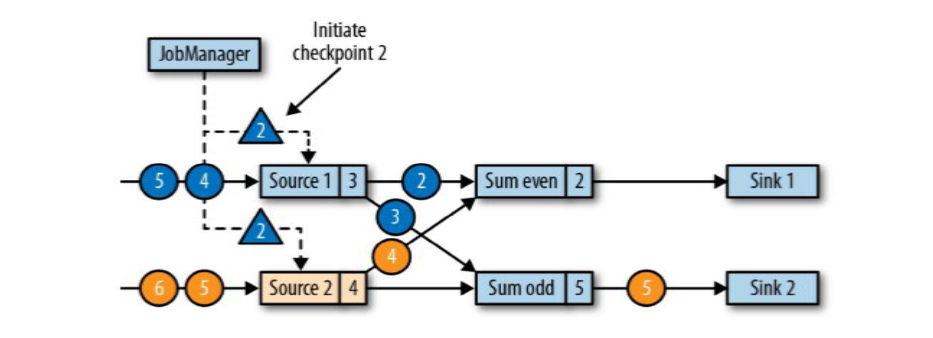
JobManager会向每个source任务发送一条带有新检查点ID的消息,通过这种方式来启动检查点;
数据源将它们的状态写入检查点,并发出一个检查点barrier;
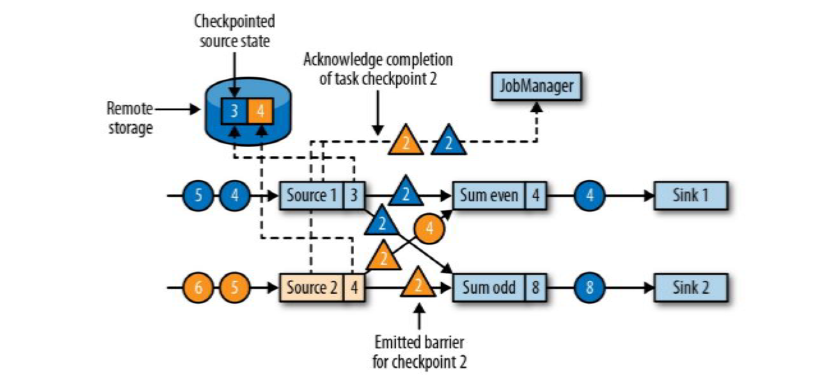
状态后端在状态存入检查点之后,会返回通知给source任务,source任务就会向JobManager确认检查点完成。
source1和source2收到检查点ID = 2时,分别存入自己的偏移量蓝3和黄4,存完之后返回一个ID2通知JobManager快照已保存好;(在保存快照时它会暂停发送和处理数据,同事它也会向下游发送带有检查点ID的barrier,发送的方式直接广播;这个过程中Sum和sink任务也没闲着都在处理数据)

分界线对齐(barrier对齐):barrier向下游传递,sum任务会等待所有输入分区的的barrier到达;
对于barrier已经到达的分区,继续到达的数据会被缓存;
而barrier尚未到达的分区,数据会被正常处理;
(比如蓝2通知给了Sum even,它会等黄2的barrier到达,这时处理的数据4来了,会先被缓存因为它数据下一个checkpoint的数据; 黄2的checkpoint还没来这时它如果来数据还会正常处理更改状态,如上图的在黄2的barrier还没来之前,source2的数据来了条4,它会正常处理Sum event(2 + 2 + 4))

当收到所有输入分区的barrier时,任务就将其状态保存到状态后端的检查点中,然后将barrier继续向下游转发。
barrier对齐之后(Sum even和Sum odd都接收到了两个source发来的barrier),将它们各自的8状态存入checkpoint中;接下来继续向下游Sink广播barrier;

向下游转发检查点的barrier后,任务继续正常的数据处理;
先处理缓存的数据,蓝4加载进来Sum event 12,黄6进来Sum event 18。
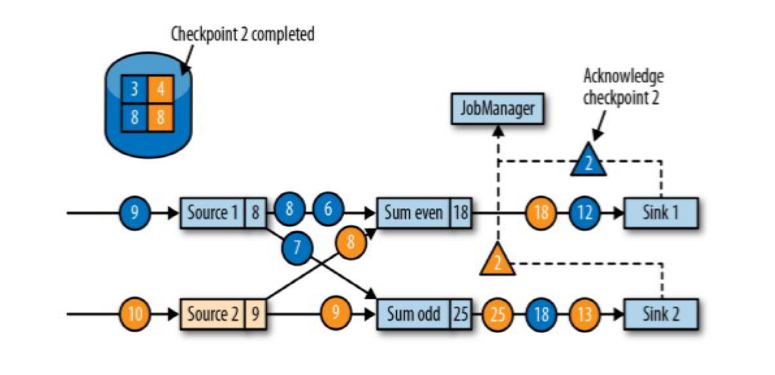
Sink任务向JobManager确认状态保存到checkpoint完毕;(Sink接收到barrier后先保存状态到checkpoint,然后向JobManager汇报)
当所有任务都确认已成功将状态保存到检查点时,检查点就真正完成了。
4. 保存点(Savepoints)
Flink还提供了可以自定义的镜像保存功能,就是保存点(savepoints);
原则上,创建保存点使用的算法与检查点完全相同,因此保存点可以认为就是具有一些额外元数据的检查点;
Flink不会自动创建保存点,因此用户(或者外部调度程序)必须明确地触发创建操作;
保存点是一个强大的功能,除了故障恢复外,保存点可以用于:有计划的手动备份,更新应用程序,版本迁移,暂停或重启应用,等等
代码中checkpoint

val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//默认是不开启的
env.enableCheckpointing(60000) //1分钟checkpoint一次
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.AT_LEAST_ONCE)
env.getCheckpointConfig.setCheckpointTimeout(100000L) //超时时间
env.getCheckpointConfig.setFailOnCheckpointingErrors(false) //checkpoint发生异常是否停止整个任务,默认是true
env.getCheckpointConfig.setMaxConcurrentCheckpoints(2) //同时这几个checkpoint,可能一个没起来另外一个就起来,有可能影响性能;默认1
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(100) //两个checkpoint的间隔
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION) //开启外部持久化,即使job失败也不会清洗checkpoint
env.setRestartStrategy(RestartStrategies.failureRateRestart(3, org.apache.flink.api.common.time.Time.seconds(300), org.apache.flink.api.common.time.Time.seconds(10))) //重启策略



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人