
Flink| 状态管理| 状态编程
状态后端(State Backends)
每传入一条数据,有状态的算子任务都会读取和更新状态;
由于有效的状态访问对于处理数据的低延迟至关重要,因此每个并行任务都会在本地内存维护其状态,以确保快速的状态访问。
状态的存储、访问以及维护,由一个可插入的组件决定,这个组件就叫做状态后端(State Backend)
状态后端主要负责两件事:本地的状态管理,以及将检查点(checkpoint)状态写入远程存储。
1. Flink中的状态
流式计算分为无状态和有状态两种情况
- 无状态的计算观察每个独立事件,并根据最后一个事件输出结果。
- 有状态的计算则会基于多个事件输出结果。
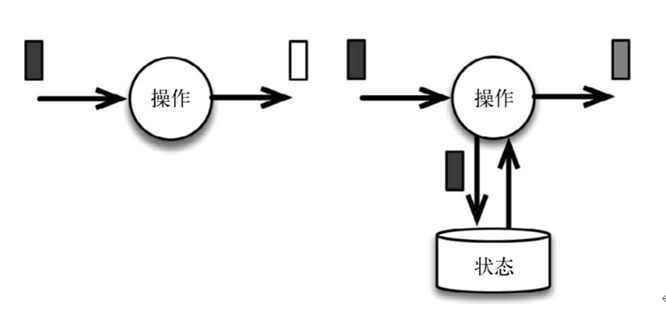
下图展示了无状态流处理和有状态流处理的主要区别: 无状态流处理分别接收每条数据记录(图中的黑条),然后根据最新输入的数据生成输出数据(白条)。有状态流处理会维护状态(根
据每条输入记录进行更新),并基于最新输入的记录和当前的状态值生成输出记录(灰条)。
图中输入数据由黑条表示。无状态流处理每次只转换一条输入记录,并且仅根据最新的输入记录输出结果(白条)。有状态 流处理维护所有已处理记录的状态值,并根据每条新输入的记
录更新状态,因此输出记录(灰条)反映的是综合考虑多个事件之后的结果。
尽管无状态的计算很重要,但是流处理对有状态的计算更感兴趣。旧的流处理系统并不支持有状态的计算,而新一代的流处理系统则将状态及其正确性视为重中之重。
流式处理(A. 可以是无状态(基于某个独立的事件计算出来后直接输出了,来一个处理一个不涉及到其他东西,如map、flatmap、filter;超过一定温度就报警 - 侧输出流;)、
B. 可以是有转态的(求和、wordcount计算))
- 状态是针对一个任务而言的,由一个任务维护,并且用来计算某个结果的所有数据,都属于这个任务的转态;
- 可以认为状态就是一个本地变量,可以被任务的业务逻辑直接访问;
- Flink会进行状态管理(状态做序列化以二进制的形式全部存储起来),包括状态一致性、故障处理以及高效存储和访问,以便开发人员可以专注于应用程序的逻辑。
在Flink中,状态始终与特定算子相关联;为了运行时的Flink了解算子的状态,算子需要预先注册其状态;

有状态的算子和应用程序
Flink内置的很多算子,数据源source,数据存储sink都是有状态的,流中的数据都是buffer records,会保存一定的元素或者元数据。例如: ProcessWindowFunction会缓存输入流的数
据,ProcessFunction会保存设置的定时器信息等等。
在Flink中,状态始终与特定算子相关联。总的来说,有两种类型的状态:
- 算子状态(operator state),算子状态的作用范围限定为算子任务,一个任务一个状态;
- 键控(分区)状态(keyed state),根据输入数据流中定义的键(Key)来维护和访问(基于KeyBy--KeyedStream上有任务出现的状态,定义的不同的key来维护这个状态;不同的key也是独立访问的,一个key只能访问它自己的状态,不同key之间也不能互相访问);
A. 算子状态
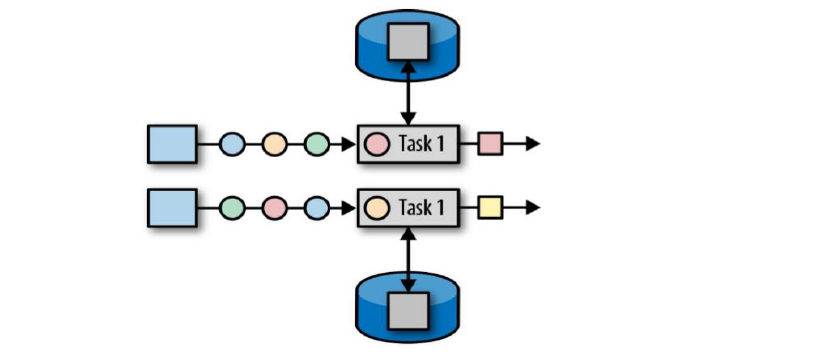
算子状态的作用范围限定为算子任务,由同一并行子任务所处理的所有数据都可以访问到相同的状态;
状态对于同一个任务而言是共享的(每一个并行的子任务共享一个状态);
算子状态不能由相同或不同算子的另一个任务访问(相同算子的不同任务之间也不能访问);
算子状态提供三种数据结构:
① 列表状态(List state),将状态表示为一组数据的列表;(会根据并行度的调整把之前的状态重新分组重新分配)
② 联合列表状态(Union list state),也将状态表示为数据的列表,它常规列表状态的区别在于,在发生故障时,或者从保存点(savepoint)启动应用程序时如何恢复(把之前的每一个状态广播到对应的每个算子中)。
③ 广播状态(Broadcast state),如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态(把同一个状态广播给所有算子子任务);
B. 键控状态(Keyed State)-- 更常用
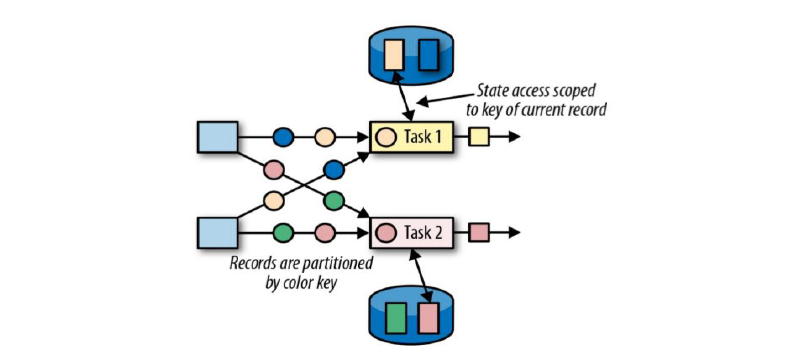
键控状态是根据输入数据流中定义的键(key)来维度和访问状态的;
Flink为每个key维护一个状态实例,并将具有相同键的所有数据,都分区到同一个算子任务中,这个任务会维护和处理这个key对应的状态;
当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的key;
键控状态Keyed State 数据结构:
① 值状态(ValueState<T>),将状态表示为单个值;(直接.value获取,Set操作是.update)
- get操作: ValueState.value()
- set操作: ValueState.update(T value)
② 列表状态(ListState<T>),将状态表示为一组数据的列表(存多个状态);(.get,.update,.add)
- ListState.add(T value)
- ListState.addAll(List<T> values)
- ListState.get()返回Iterable<T>
- ListState.update(List<T> values)
③ 映射状态(MapState<K, V>),将状态表示为一组Key-Value对;(.get,.put ,类似HashMap)
- MapState.get(UK key)
- MapState.put(UK key, UV value)
- MapState.contains(UK key)
- MapState.remove(UK key)
④ 聚合状态(ReducingState<T> & AggregatingState<I, O>),将状态表示为一个用于聚合操作的列表;(.add不像之前添加到列表,它是直接聚合到之前的结果中)
Reduce输入输出类型是不能变的,Aggregate可得到数据类型完全不一样的结果;
State.clear()是清空操作。
键控状态的使用:

声明一个键控状态:
lazy val lastTemp: ValueState[Double] = getRuntimeContext.getState(
new ValueStateDescriptor[Double]("lastTemp", classOf[Double])
)
读取状态:
val prevTemp = lastTemp.value()
对状态赋值:
lastTemp.update(value.temperature)
案例,利用KeyedState,实现这样一个需求:检测传感器的温度值,如果连续的两个温度差值超过10度,就输出报警。代码见下
状态一致性
检查点(checkpoint)
状态后端(State Backends)
-- 状态管理(存储、访问、维护和检查点)
每传入一条数据,有状态的算子任务都会读取和更新状态;
由于有效的状态访问对于处理数据的低效迟至关重要,因此每个并行任务都会在本地维度其状态,以确保快速的状态访问;
状态的存储、访问以及维度,由一个可插入的组件决定,这个组件就叫做状态后端(State Backends);
状态后端主要负责两件事:本地的状态管理,以及将检查点(checkpoint)状态写入远程存储;
状态后端的分类
① MemoryStateBackend: 一般用于开发和测试
- 内存级的状态后端,会将键控状态作为内存中的对象进行管理,将它们存储在TaskManager的JVM堆上,而将checkpoint存储在JobManager的内存中;
- 特点快速、低延迟,但不稳定;
② FsStateBackend(文件系统状态后端):生产环境
- 将checkpoint存到远程的持久化文件系统(FileSystem),HDFS上,而对于本地状态,跟MemoryStateBackend一样,也会存到TaskManager的JVM堆上。
- 同时拥有内存级的本地访问速度,和更好的容错保证;(如果是超大规模的需要保存还是无法解决,存到本地状态就可能OOM)
③ RocksDBStateBackend:
- 将所有状态序列化后,存入本地的RocksDB(本地数据库硬盘空间,序列化到磁盘)中存储,全部序列化存储到本地。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.12</artifactId>
<version>1.10.1</version>
</dependency>
设置状态后端为FsStateBackend,并配置检查点和重启策略:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 1. 状态后端配置
//env.setStateBackend(new MemoryStateBackend());
env.setStateBackend(new FsStateBackend("", true))
//env.setStateBackend(new RocksDBStateBackend(""))
// 2. 检查点配置 开启checkpoint
env.enableCheckpointing(1000);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500L);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
env.getCheckpointConfig().setPreferCheckpointForRecovery(true);
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(0);
env.getCheckpointConfig().setCheckpointInterval(10000L)
// 3. 重启策略配置
// 固定延迟重启(隔一段时间尝试重启一次)
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 尝试重启次数
100000L // 尝试重启的时间间隔,也可org.apache.flink.api.common.time.Time
));
env.setRestartStrategy(RestartStrategies.failureRateRestart(5, Time.minutes(5), Time.seconds(10)))
2. 状态编程
利用Keyed State,实现这样一个需求:检测传感器的温度值,如果连续的两个温度差值超过10度,就输出报警。
方法一: class TempChangeAlert(threshold: Double) extends KeyedProcessFunction[String, SensorReading, (String, Double, Double)] { } //底层API processFunction API
方法二: class TempChangeAlert2(threshold: Double) extends RichFlatMapFunction[SensorReading, (String, Double, Double)]{ } //利用富函数
方法三: dataStream.keyBy(_.id)
.flatMapWithState[(String, Double, Double), Double]{ } //FlatMap with keyed ValueState 的快捷方式,带状态的flatMap
import akka.pattern.BackoffSupervisor.RestartCount
import com.xxx.fink.api.sourceapi.SensorReading
import org.apache.flink.api.common.functions.RichFlatMapFunction
import org.apache.flink.api.common.restartstrategy.RestartStrategies
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.util.Collector
import org.apache.flink.api.scala._
import org.apache.flink.configuration.Configuration
import org.apache.flink.contrib.streaming.state.RocksDBStateBackend
import org.apache.flink.runtime.executiongraph.restart.RestartStrategy
import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanup
import org.apache.flink.streaming.api.{CheckpointingMode, TimeCharacteristic}
/**
*状态编程
* 检测两次温度变化如果超过某个范围就报警,比如超过10°就报警;
*/
object StateTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//env.setStateBackend(new RocksDBStateBackend(""))
val stream: DataStream[String] = env.socketTextStream("hadoop101", 7777)
val dataStream: DataStream[SensorReading] = stream.map(data => {
val dataArray: Array[String] = data.split(",")
SensorReading(dataArray(0).trim, dataArray(1).trim.toLong, dataArray(2).trim.toDouble)
})
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[SensorReading](Time.seconds(1)) {
override def extractTimestamp(element: SensorReading): Long = element.timestamp * 1000
})
//方法一:
val processedStream1: DataStream[(String, Double, Double)] = dataStream.keyBy(_.id)
.process(new TempChangeAlert(10.0))
//方法二: 除了processFunction,其他也可以有状态
val processedStream2: DataStream[(String, Double, Double)] = dataStream.keyBy(_.id)
.flatMap(new TempChangeAlert2(10.0))
//方法三: 带状态的flatMap
val processedStream3: DataStream[(String, Double, Double)] = dataStream.keyBy(_.id)
.flatMapWithState[(String, Double, Double), Double]{
//如果没有状态的话,也就是没有数据过来,那么就将当前数据湿度值存入状态
case (input: SensorReading, None) => (List.empty, Some(input.temperature))
//如果有状态,就应该与上次的温度值比较差值,如果大于阈值就输出报警
case(input: SensorReading, lastTemp: Some[Double]) =>
val diff = (input.temperature - lastTemp.get).abs
if (diff > 10.0){
(List((input.id, lastTemp.get, input.temperature)), Some(input.temperature))
}else{
(List.empty, Some(input.temperature))
}
}
dataStream.print("Input data:")
processedStream3.print("process data:")
env.execute("Window test")
}
}
class TempChangeAlert(threshold: Double) extends KeyedProcessFunction[String, SensorReading, (String, Double, Double)] {
//定义一个状态变量,保存上次的温度值
lazy val lastTempState: ValueState[Double] = getRuntimeContext.getState(new ValueStateDescriptor[Double]("lastTemp", classOf[Double]))
override def processElement(value: SensorReading, ctx: KeyedProcessFunction[String, SensorReading, (String, Double, Double)]#Context, out: Collector[(String, Double, Double)]): Unit = {
//获取上次的温度值
val lastTemp = lastTempState.value()
//用当前的温度值和上次的做差,如果大于阈值,则输出报警
val diff = (value.temperature - lastTemp).abs
if (diff > threshold){
out.collect(value.id, lastTemp, value.temperature)
}
lastTempState.update(value.temperature) //状态更新
}
}
class TempChangeAlert2(threshold: Double) extends RichFlatMapFunction[SensorReading, (String, Double, Double)]{
//flatMap本身是无状态的,富函数版本的函数类都可以去操作状态也有生命周期
private var lastTempState: ValueState[Double] = _ //赋一个空值;
//初始化的声明state变量
override def open(parameters: Configuration): Unit = {
//可以定义一个lazy;也可以在声明周期中拿;
lastTempState = getRuntimeContext.getState(new ValueStateDescriptor[Double]("lastTemp", classOf[Double]))
}
override def flatMap(value: SensorReading, out: Collector[(String, Double, Double)]): Unit = {
//获取上次的温度值
val lastTemp = lastTempState.value()
//用当前温度值和上次的求差值,如果大于阈值,输出报警信息
val diff = (value.temperature - lastTemp).abs
if (diff > threshold){
out.collect(value.id, lastTemp, value.temperature)
}
lastTempState.update(value.temperature)
}
}
测试:
###方法二测试: Input data:> SensorReading(sensor_1,1547718199,35.8) process data:> (sensor_1,0.0,35.8) Input data:> SensorReading(sensor_1,1547718199,32.0) Input data:> SensorReading(sensor_1,1547718199,25.0) Input data:> SensorReading(sensor_1,1547718199,35.1) process data:> (sensor_1,25.0,35.1) Input data:> SensorReading(sensor_1,1547718199,12.0) process data:> (sensor_1,35.1,12.0) ###方法三: Input data:> SensorReading(sensor_1,1547718199,35.8) Input data:> SensorReading(sensor_1,1547718199,25.0) process data:> (sensor_1,35.8,25.0) Input data:> SensorReading(sensor_1,1547718199,28.8) Input data:> SensorReading(sensor_1,1547718199,39.8) process data:> (sensor_1,28.8,39.8)



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人