
OLAP分析工具之Presto
Presto
Presto是一个开源的分布式SQL查询引擎,数据量支持GB到PB字节,主要用来处理秒级查询的场景。
虽presto可以解析SQL,但它不是一个标准的数据库,不是MySQL、Oracle的代替品,也不能用来处理在线事务(OLTP);

Presto、Impala性能比较
测试结论:Impala性能稍领先于Presto,但是Presto在数据源支持上非常丰富,包括Hive、图数据库、传统关系型数据库、Redis等。
下载安装
官网: https://prestodb.github.io/
1)下载地址
https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.196/presto-server-0.196.tar.gz
Presto Server安装

2)将presto-server-0.196.tar.gz导入hadoop101的/opt/software目录下,并解压到/opt/module目录
[kris@hadoop101 software]$ tar -zxvf presto-server-0.196.tar.gz -C /opt/module/
3)修改名称为presto
[kris@hadoop101 module]$ mv presto-server-0.196/ presto
4)进入到/opt/module/presto目录,并创建存储数据文件夹
[kirs@hadoop101 presto]$ mkdir data
5)进入到/opt/module/presto目录,并创建存储配置文件文件夹
[kirs@hadoop101 presto]$ mkdir etc
6)配置在/opt/module/presto/etc目录下添加jvm.config配置文件
[kirs@hadoop101 etc]$ vim jvm.config


-server -Xmx16G -XX:+UseG1GC -XX:G1HeapRegionSize=32M -XX:+UseGCOverheadLimit -XX:+ExplicitGCInvokesConcurrent -XX:+HeapDumpOnOutOfMemoryError -XX:+ExitOnOutOfMemoryError
7)Presto可以支持多个数据源,在Presto里面叫catalog,这里我们配置支持Hive的数据源,配置一个Hive的catalog
[kirs@hadoop101 etc]$ mkdir catalog
[kirs@hadoop101 catalog]$ vim hive.properties
connector.name=hive-hadoop2
hive.metastore.uri=thrift://hadoop101:9083
8)将hadoop101上的presto分发到hadoop102、hadoop103
[kirs@hadoop101 module]$ xsync presto
9)分发之后,分别进入hadoop101、hadoop102、hadoop103三台主机的/opt/module/presto/etc的路径。配置node属性,node id每个节点都不一样。
[kirs@hadoop101 etc]$vim node.properties
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir=/opt/module/presto/data
[kirs@hadoop102 etc]$vim node.properties
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-fffffffffffe
node.data-dir=/opt/module/presto/data
[kirs@hadoop103 etc]$vim node.properties
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-fffffffffffd
node.data-dir=/opt/module/presto/data
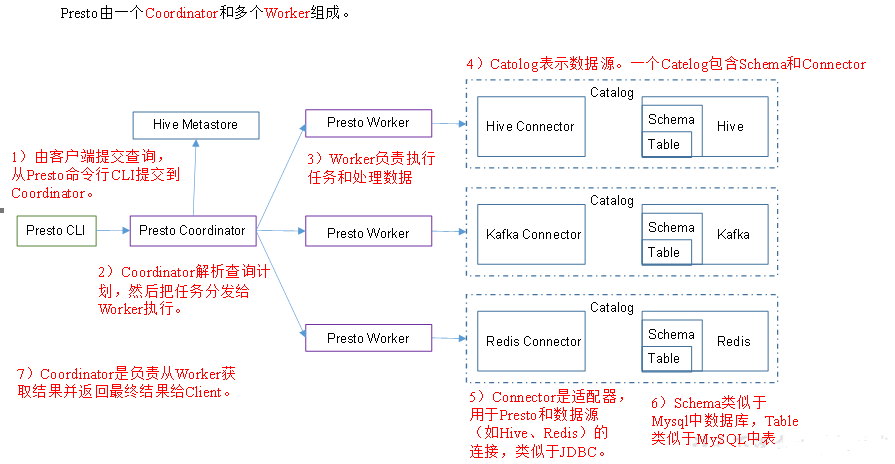
10)Presto是由一个coordinator节点和多个worker节点组成。在hadoop101上配置成coordinator,在hadoop102、hadoop103上配置为worker。
(1)hadoop101上配置coordinator节点
[kirs@hadoop101 etc]$ vim config.properties
coordinator=true
node-scheduler.include-coordinator=false
http-server.http.port=8881
query.max-memory=50GB
discovery-server.enabled=true
discovery.uri=http://hadoop101:8881
(2)hadoop102、hadoop103上配置worker节点
[kirs@hadoop102 etc]$ vim config.properties
coordinator=false
http-server.http.port=8881
query.max-memory=50GB
discovery.uri=http://hadoop101:8881
[kirs@hadoop103 etc]$ vim config.properties
coordinator=false
http-server.http.port=8881
query.max-memory=50GB
discovery.uri=http://hadoop101:8881
启动
11)在/opt/module/hive目录下,启动Hive Metastore,用kris角色
[kris@hadoop101 hive] nohup bin/hive --service metastore >/dev/null 2>&1 &
12)分别在hadoop101、hadoop102、hadoop103上启动presto server
(1)前台启动presto,控制台显示日志
[kirs@hadoop101 presto]$ bin/launcher run
[kirs@hadoop102 presto]$ bin/launcher run
[kirs@hadoop103 presto]$ bin/launcher run
(2)或者后台启动presto
[kirs@hadoop101 presto]$ bin/launcher start
[kirs@hadoop102 presto]$ bin/launcher start
[kirs@hadoop103 presto]$ bin/launcher start

日志查看路径/opt/module/presto/data/var/log
Presto命令行Client安装
用的少
1)下载Presto的客户端
https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.196/presto-cli-0.196-executable.jar
2)将presto-cli-0.196-executable.jar上传到hadoop101的/opt/module/presto文件夹下 3)修改文件名称 [kirs@hadoop101 presto]mv presto−cli−0.196−executable.jar prestocli
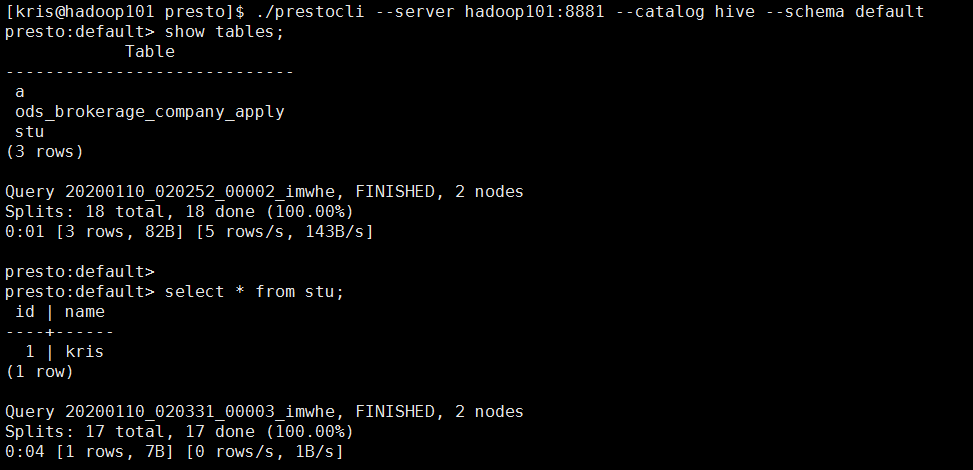
4)增加执行权限[kirs@hadoop101presto] chmod +x prestocli 5)启动prestocli [kirs@hadoop101 presto]$ ./prestocli --server hadoop101:8881 --catalog hive --schema default 6)Presto命令行操作 Presto的命令行操作,相当于hive命令行操作。每个表必须要加上schema。 例如:select * from schema.table limit 100
Presto可视化Client安装
1)将yanagishima-18.0.zip上传到hadoop101的/opt/module目录
2)解压缩yanagishima
[kirs@hadoop101 module]$ unzip yanagishima-18.0.zip
cd yanagishima-18.0
3)进入到/opt/module/yanagishima-18.0/conf文件夹,编写yanagishima.properties配置
[kirs@hadoop101 conf]$ vim yanagishima.properties
jetty.port=7080
presto.datasources=kris-presto
presto.coordinator.server.kris-presto=http://hadoop101:8881
catalog.kris-presto=hive
schema.kris-presto=default
sql.query.engines=presto
4)在/opt/module/yanagishima-18.0路径下启动yanagishima
[kirs@hadoop101 yanagishima-18.0]$ nohup bin/yanagishima-start.sh >y.log 2>&1 &
5)启动web页面
http://hadoop101:7080 看到界面,进行查询了。
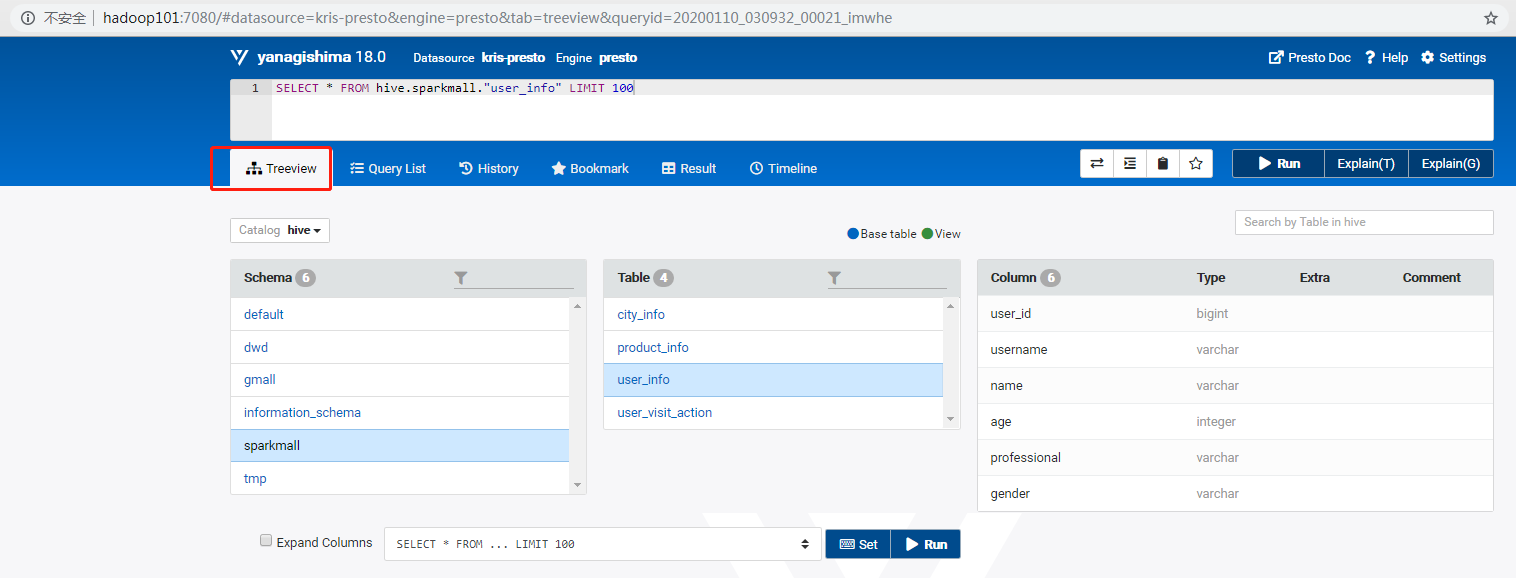
这里有个Tree View,可以查看所有表的结构,包括Schema、表、字段等。
比如执行select * from hive.sparkmall.user_info limit 10,这个句子里Hive这个词可以删掉,是上面配置的Catalog。
每个表后面都有个复制键,点一下会复制完整的表名,然后再上面框里面输入sql语句,ctrl+enter键执行显示结果
Presto的优化
数据存储的优化
1 合理设置分区
与Hive类似,Presto会根据元数据信息读取分区数据,合理的分区能减少Presto数据读取量,提升查询性能。
2 使用列式存储
Presto对ORC文件读取做了特定优化,因此在Hive中创建Presto使用的表时,建议采用ORC格式存储。相对于Parquet,Presto对ORC支持更好。
3 使用压缩
数据压缩可以减少节点间数据传输对IO带宽压力,对于即席查询需要快速解压,建议采用Snappy压缩。
查询SQL的优化
1 只选择使用的字段
由于采用列式存储,选择需要的字段可加快字段的读取、减少数据量。避免采用*读取所有字段。
[GOOD]: SELECT time, user, host FROM tbl
[BAD]: SELECT * FROM tbl
2 过滤条件必须加上分区字段
对于有分区的表,where语句中优先使用分区字段进行过滤。acct_day是分区字段,visit_time是具体访问时间。
[GOOD]: SELECT time, user, host FROM tbl where acct_day=20171101
[BAD]: SELECT * FROM tbl where visit_time=20171101
3 Group By语句优化
合理安排Group by语句中字段顺序对性能有一定提升。将Group By语句中字段按照每个字段distinct数据多少进行降序排列。
[GOOD]: SELECT GROUP BY uid, gender
[BAD]: SELECT GROUP BY gender, uid
4 Order by时使用Limit
Order by需要扫描数据到单个worker节点进行排序,导致单个worker需要大量内存。如果是查询Top N或者Bottom N,使用limit可减少排序计算和内存压力。
[GOOD]: SELECT * FROM tbl ORDER BY time LIMIT 100
[BAD]: SELECT * FROM tbl ORDER BY time
5 使用Join语句时将大表放在左边
Presto中join的默认算法是broadcast join,即将join左边的表分割到多个worker,然后将join右边的表数据整个复制一份发送到每个worker进行计算。如果右边的表数据量太大,则可能会报内存溢出错误。
[GOOD] SELECT ... FROM large_table l join small_table s on l.id = s.id
[BAD] SELECT ... FROM small_table s join large_table l on l.id = s.id
注意事项
1 字段名引用
避免和关键字冲突:MySQL对字段加反引号`、Presto对字段加双引号分割
当然,如果字段名称不是关键字,可以不加这个双引号。
2 时间函数
对于Timestamp,需要进行比较的时候,需要添加Timestamp关键字,而MySQL中对Timestamp可以直接进行比较。
/*MySQL的写法*/
SELECT t FROM a WHERE t > '2017-01-01 00:00:00';
/*Presto中的写法*/
SELECT t FROM a WHERE t > timestamp '2017-01-01 00:00:00';
3 不支持INSERT OVERWRITE语法
Presto中不支持insert overwrite语法,只能先delete,然后insert into。
4 PARQUET格式
Presto目前支持Parquet格式,支持查询,但不支持insert。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人