
maxwell实时同步mysql中binlog
概述
Maxwell是一个能实时读取MySQL二进制日志binlog,并生成 JSON 格式的消息,作为生产者发送给 Kafka,Kinesis、RabbitMQ、Redis、Google Cloud Pub/Sub、文件或其它平台的应用程序。它的常见应用场景有ETL、维护缓存、收集表级别的dml指标、增量到搜索引擎、数据分区迁移、切库binlog回滚方案等。
特征
- 支持 SELECT * FROM table 的方式进行全量数据初始化
- 支持在主库发生failover后,自动恢复binlog位置(GTID)
- 可以对数据进行分区,解决数据倾斜问题,发送到kafka的数据支持database、table、column等级别的数据分区
- 工作方式是伪装为Slave,接收binlog events,然后根据schemas信息拼装,可以接受ddl、xid、row等各种event
Canal |Maxwell| mysql_streamer
除了Maxwell外,目前常用的MySQL Binlog解析工具主要有阿里的canal、mysql_streamer,三个工具对比如下:
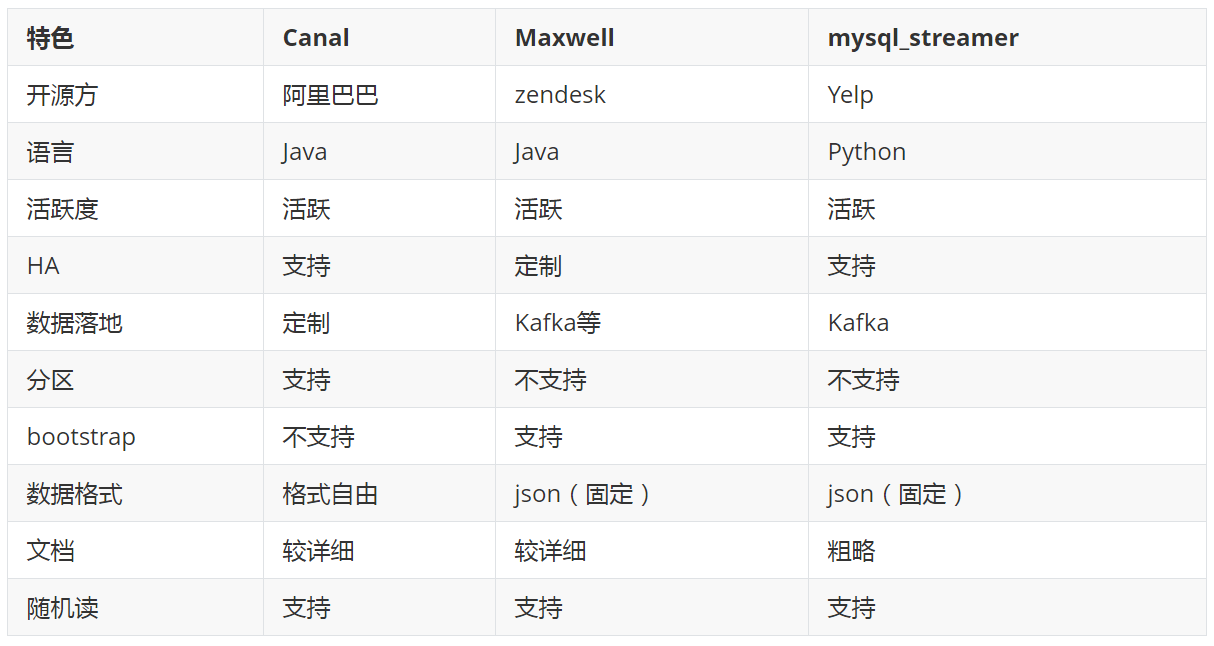
canal 由Java开发,分为服务端和客户端,拥有众多的衍生应用,性能稳定,功能强大;canal 需要自己编写客户端来消费canal解析到的数据。
maxwell相对于canal的优势是使用简单,它直接将数据变更输出为json字符串,不需要再编写客户端。
Maxwell和canal工具对比
- Maxwell没有canal那种server+client模式,只有一个server把数据发送到消息队列或redis。如果需要多个实例,通过指定不同配置文件启动多个进程。
- Maxwell有一个亮点功能,就是canal只能抓取最新数据,对已存在的历史数据没有办法处理。而Maxwell有一个bootstrap功能,可以直接引导出完整的历史数据用于初始化,非常好用。
- Maxwell不能直接支持HA,但是它支持断点还原,即错误解决后重启继续上次点儿读取数据。
- Maxwell只支持json格式,而Canal如果用Server+client模式的话,可以自定义格式。
- Maxwell比Canal更加轻量级。
安装地址
1.Maxwell官网地址 http://maxwells-daemon.io/
2.安装包下载地址 https://github.com/zendesk/maxwell
安装MaxWell
(1)上传maxwell-1.22.4.tar.gz 并进行解压
tar -zxvf maxwell-1.22.4.tar.gz -C /opt/module/
修改config.properties.example为config.properties
MySql配置
需要mysql开启binlog,而binlog默认是关闭的,需要开启,并且为了保证同步数据的一致性,使用的日志格式为row-based replication(RBR),新建或修改my.conf开启binlog。
(1)修改my-default.cnf
[kris@hadoop101 maxwell-1.22.5]$ cd /usr/share/mysql/ [kris@hadoop101 mysql]$ sudo cp my-default.cnf /etc/my.cnf [kris@hadoop101 mysql]$ sudo vim /etc/my.cnf
提示:如果是rpm的方式安装MySql的那么则没有my.cnf文件,则需要修改mysql-default.cnf然后复制到/etc/路径下,如果/etc/路径下有my.cnf则直接修改my.cnf即可。
(2)修改my.cnf,添加如下配置。
[kris@hadoop101 mysql]$ sudo vim /etc/my.cnf
[mysqld]
server_id=1 #随机指定一个不能和其他集群中机器重名的字符串,如果只有一台机器,那就可以随便指定了
log-bin=master
binlog_format=row #选择row模式
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
启动MySql设置参数
mysql> set global binlog_format=ROW;
mysql> set global binlog_row_image=FULL;
创建maxwell库(maxwell启动时候会自动创建,不需手动创建;另外不能在maxwell库里边创建表,maxwell不会监听到)和用户
添加权限:
mysql> CREATE USER 'maxwell'@'%' IDENTIFIED BY '123456';
mysql> GRANT ALL ON maxwell.* TO 'maxwell'@'%';
mysql> GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell'@'%';
重启MySql服务
[kris@hadoop101 ~]$ sudo service mysql restart
重启mysql, 查询是否已开启
show global variables like '%log_bin%'

查看binlog: show binlog events;
查看最新一个binlog日志文件名称 show master status;
查找binlog日志 find / -name mysql-bin -type f
查看详细的日志配置信息SHOW GLOBAL VARIABLES LIKE '%log%';
mysql数据存储目录 show variables like '%dir%';
Maxwell 使用
需要首先启动 zookeeper和 kafka
max的启动方式有:
(1)基于命令行的启动方式 [kris@hadoop101 maxwell-1.22.5]$ cd /opt/module/ [kris@hadoop101 maxwell-1.22.5]$ bin/maxwell --user='maxwell' --password='123456' --host='hadoop101' --producer=stdout (2)基于kafka的启动方式 [kris@hadoop101 maxwell-1.22.5]$ bin/maxwell --user='maxwell' --password='123456' --host='hadoop101' --producer=kafka --kafka.bootstrap.servers=hadoop102:9092 --kafka_topic=maxwell (3)基于RabbitMQ的启动方式 [kris@hadoop101 maxwell-1.22.5]$ bin/maxwell --user='maxwell' --password='123456' --host='hadoop101' --producer=rabbitmq --rabbitmq_host='rabbitmq.hostname' (4)基于Redis的启动方式 [kris@hadoop101 maxwell-1.22.5]$ bin/maxwell --user='maxwell' --password='123456' --host='hadoop101' --producer=redis --redis_host=redis.hostname 提示:maxwell 支持端点续传功能,如果maxwell不慎挂掉了,重启会从上次的消费位置继续读取。
另外,maxwell如果和Mysql不在同一台机器上只需要修改 --host=hostname即可。
1. 输出信息到命令行
(1)启动MaxWell
kris@hadoop101 maxwell-1.22.5]$ bin/maxwell --user='maxwell' --password='123456' --host='hadoop101' --producer=stdout Using kafka version: 1.0.0 17:20:11,351 WARN MaxwellMetrics - Metrics will not be exposed: metricsReportingType not configured. 17:20:11,813 INFO SchemaStoreSchema - Creating maxwell database 17:20:12,367 INFO Maxwell - Maxwell v1.22.5 is booting (StdoutProducer), starting at Position[BinlogPosition[master.000001:3816], lastHeartbeat=0] 17:20:12,625 INFO AbstractSchemaStore - Maxwell is capturing initial schema 17:20:13,733 INFO BinlogConnectorReplicator - Setting initial binlog pos to: master.000001:3816 17:20:13,828 INFO BinaryLogClient - Connected to hadoop101:3306 at master.000001/3816 (sid:6379, cid:5) 17:20:13,829 INFO BinlogConnectorLifecycleListener - Binlog connected.
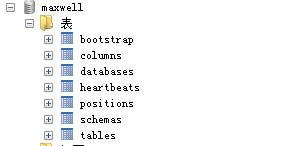 自动创建的maxwell库,往里边创建表它是不会监听到的;
自动创建的maxwell库,往里边创建表它是不会监听到的;
该库记录了maxwell同步的状态,最后一次同步的id等等信息,在主库失败或同步异常后,只要maxwell库存在,下次同步会根据最后一次同步的id。如果没有生成maxwell库或报错,可能config.properties中配置的mysql用户权限不够。
maxwell会在对应的数据库上建立一个maxwell数据库用来记录binlog的position, 如果maxwell因为某个原因失败了,下次根据数据库里保存的position去重新获取binlog,第一次连接是从最新的log position获取数据,当然,你也可以手动去更新数据库position位置。
对mysql的test测试库进行增删改操作:
INSERT INTO stu1 VALUES(1003,'kris',22); //增、删、改
查看MaxWell 阻塞窗口

{"database":"test","table":"stu1","type":"delete","ts":1576747370,"xid":454,"commit":true,"data":{"id":1003,"name":"wangwu","age":23}}
{"database":"test","table":"stu1","type":"insert","ts":1576747481,"xid":622,"commit":true,"data":{"id":1003,"name":"kris","age":22}}
{"database":"test","table":"stu1","type":"update","ts":1576747522,"xid":695,"commit":true,"data":{"id":1002,"name":"lisi","age":30},"old":{"age":18}}
2. 输出信息到kafka
启动kafka集群:
[kris@hadoop101 kafka]$ bin/kafka-server-start.sh config/server.properties & [1] 3459 [kris@hadoop102 kafka]$ bin/kafka-server-start.sh config/server.properties & [1] 6320 [kris@hadoop103 kafka]$ bin/kafka-server-start.sh config/server.properties & [1] 5823
创建kafka的maxwell topic主题
[kris@hadoop101 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server Hadoop101:9092 --topic maxwell
启动kafka消费者命令行监听maxwell:
[kris@hadoop101 bin]$ ./kafka-console-consumer.sh --bootstrap-server hadoop101:9092 --topic maxwell --from-beginning [2019-12-19 18:59:14,209] INFO [Group Metadata Manager on Broker 0]: Removed 0 expired offsets in 0 milliseconds. (kafka.coordinator.group.GroupMetadataManager) [2019-12-19 19:03:38,595] INFO Updated PartitionLeaderEpoch. New: {epoch:0, offset:0}, Current: {epoch:-1, offset-1} for Partition: maxwell-1. Cache now contains 0 entries. (kafka.server.epoch.LeaderEpochFileCache)
启动maxwell
[kris@hadoop101 maxwell-1.22.4]$ bin/maxwell --user='maxwell' --password='123456' --host='hadoop101' --producer=kafka --kafka.bootstrap.servers=hadoop101:9092 --kafka_topic=maxwell
对test库中的stu1表进行增删改的操作,查看kafka命令行消费者的监听数据:

kafka DML、kafka DDL
再写一个中间件,用来转义这些JSON,就可以用于其它任何系统了。 实际上我这里有个很大的疑问,kafka partition只能保证单个partition有序,多个partition实际上是无序的,但是在应用binlog的时候,大家知道,这个SQL顺序极其重要,我先update再delete和先delete再update是决然不同的结果。
因此如果kafka是多个partition, 如何保证SQL的应用是有顺序的呢? 我实际上只能想到,只能用一个partition来操作。
过滤指定规则的库:http://maxwells-daemon.io/filtering/
全量同步--使用maxwell-bootstrap命令
./bin/maxwell-bootstrap --database test--table stu1 --host hadoop101 --user maxwell --password 123456 --client_id maxwell_dev
同步test.stu1表的所有数据,并指定client_id示maxwell_dev的maxwell执行同步
上一个命令先开着,然后再启动client_id=maxwell_dev的maxwell
./bin/maxwell --client_id maxwell_dev
等待执行完成即可

 浙公网安备 33010602011771号
浙公网安备 33010602011771号