
数据清洗
hadoop fs -rm -r -skipTrash /flumu //删除跳过垃圾回收站
导入数据到HDFS
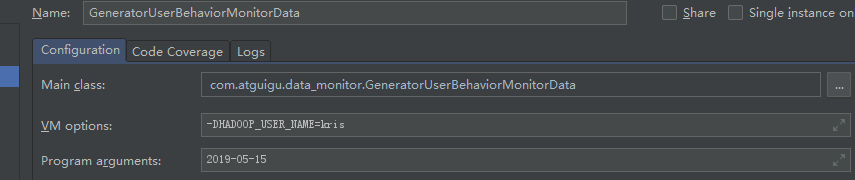
[kris@hadoop102 ~]$ hadoop fs -mkdir -p /user/hive/warehouse/ods.db/origin_user_behavior/2019-05-14 把数据上传到ods层 [kris@hadoop101 datas]$ hadoop fs -put *.txt /user/hive/warehouse/ods.db/origin_user_behavior/2019-05-14
[kris@hadoop101 spark]$ bin/spark-submit --total-executor-cores 2 --class com.atguigu.data_monitor.GeneratorUserBehaviorMonitorData Online-Edu-1.0-SNAPSHOT.jar 2019-05-20 [kris@hadoop101 spark]$ hadoop fs -mkdir -p /user/hive/warehouse/ods.db/origin_user_behavior/2019-05-20 [kris@hadoop101 spark]$ hadoop fs -put *.txt /user/hive/warehouse/ods.db/origin_user_behavior/2019-05-20 [kris@hadoop101 spark]$ rm -r *.txt
数据清洗和加载
Hive字段如下:



uid STRING comment "用户唯一标识", username STRING comment "用户昵称", gender STRING comment "性别", level TINYINT comment "1代表小学,2代表初中,3代表高中", is_vip TINYINT comment "0代表不是会员,1代表是会员", os STRING comment "操作系统:os,android等", channel STRING comment "下载渠道:auto,toutiao,huawei", net_config STRING comment "当前网络类型", ip STRING comment "IP地址", phone STRING comment "手机号码", video_id INT comment "视频id", video_length INT comment "视频时长,单位秒", start_video_time BIGINT comment "开始看视频的时间缀,秒级", end_video_time BIGINT comment "退出视频时的时间缀,秒级", version STRING comment "版本", event_key STRING comment "事件类型", event_time BIGINT comment "事件发生时的时间缀,秒级"
1) 用SparkCore将数据清洗,清洗需求如下:
a) 手机号脱敏:187xxxx2659
b) 过滤重复行(重复条件,uid,event_key,event_time三者都相同即为重复)
c) 最终数据保存到dwd.user_behavior分区表,以dt(天)为分区条件,表的文件存储格式为ORC,数据总量为xxxx条
整体流程(使用调度系统调度)
a) SparkCore清洗数据,写入到/user/hive/warehouse/tmp.db/user_behavior_${day}目录
b) 建立tmp.user_behavior_${day}临时表,并加载上面清洗后的数据
c) 使用hive引擎,并用开窗函数row_number,将tmp.user_behavior_${day}表数据插入到dwd.user_behavior表中
d) 删除tmp.user_behavior_${day}临时表
在IDEA中配置参数;在resources在拷贝core-site.xml、hdfs-site.xml、hive-site.xml文件
数据清洗代码实现:
/** * 用户行为数据清洗 * 1、验证数据格式是否正确,切分后长度必须为17 * 2、手机号脱敏,格式为123xxxx4567 * 3、去掉username中带有的\n,否则导致写入HDFS时会换行 */ object UserBehaviorCleaner { def main(args: Array[String]): Unit = { if (args.length != 2){ println("Usage:please input inputPath and outputPath") System.exit(1) } val inputPaht = args(0) val outputPath = args(1) val conf: SparkConf = new SparkConf().setAppName(getClass.getSimpleName) //.setMaster("local[*]") val sparkContext = new SparkContext(conf) // 通过输入路径获取RDD val eventRDD: RDD[String] = sparkContext.textFile(inputPaht) // 清洗数据,在算子中不要写大量业务逻辑,应该将逻辑封装到方法中 eventRDD.filter(event => checkEventValid(event)).map(event => maskPhone(event)) .map(event => repairUsername(event)) .coalesce(3) .saveAsTextFile(outputPath) sparkContext.stop() } def repairUsername(event:String)= { val field: Array[String] = event.split("\t") //取出用户昵称 val username: String = field(1) if (username != null && "".equals(username)){ field(1) = username.replace("\n", "") } field.mkString("\t") } def maskPhone(event:String): String ={ var maskPhone = new StringBuilder val fields: Array[String] = event.split("\t") //取出手机号 var phone: String = fields(9) // 手机号不为空时做掩码处理 if (phone != null && !"".equals(phone)){ maskPhone = maskPhone.append(phone.substring(0,3)).append("xxxx").append(phone.substring(7,11)) fields(9) = maskPhone.toString() } fields.mkString("\t") } def checkEventValid(event:String) ={ event.split("\t").length == 17 } }
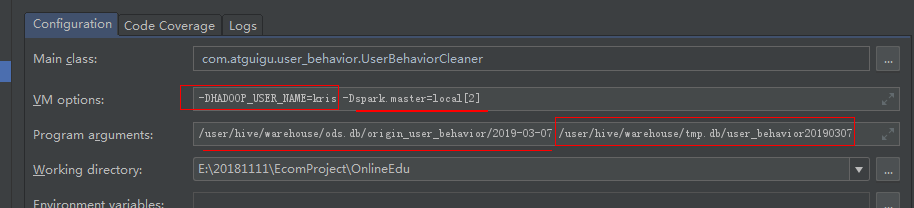
-DHADOOP_USER_NAME=kris -Dspark.master=local[2]
输入路径:/user/hive/warehouse/ods.db/origin_user_behavior2019-05-14
输出路径:/user/hive/warehouse/tmp.db/user_behavior20190514
Spark on yarn完整提交命令 输入:HDFS中ODS目录; 输出: HDFS中tmp目录
java -cp mainClass需要指定全类名; java -jar 就不需要指定了,指定jar包即可
spark-submit --master yarn --deploy-mode cluster \ --num-executors 8 \ --executor-cores 4 \ --executor-memory 12G \ --class com.kris.user_behavior.UserBehaviorCleaner UserBehaviorCleaner.jar \ hdfs://hadoop101:9000/user/hive/warehouse/ods.db/origin_user_behavior/${day} \ hdfs://hadoop101:9000/user/hive/warehouse/tmp.db/user_behavior_${day}
创建临时--内部表:
路径为刚刚输入清洗后的输出路径,就可直接在Hive表中查询出数据;
创建内部表: //数据已经导入了; create database tmp; drop table if exists tmp.user_behavior20190514;
create table if not exists tmp.user_behavior20190514( uid STRING comment "用户唯一标识", username STRING comment "用户昵称", gender STRING comment "性别", level TINYINT comment "1代表小学,2代表初中,3代表高中", is_vip TINYINT comment "0代表不是会员,1代表是会员", os STRING comment "操作系统:os,android等", channel STRING comment "下载渠道:auto,toutiao,huawei", net_config STRING comment "当前网络类型", ip STRING comment "IP地址", phone STRING comment "手机号码", video_id INT comment "视频id", video_length INT comment "视频时长,单位秒", start_video_time BIGINT comment "开始看视频的时间缀,秒级", end_video_time BIGINT comment "退出视频时的时间缀,秒级", version STRING comment "版本", event_key STRING comment "事件类型", event_time BIGINT comment "事件发生时的时间缀,秒级") row format delimited fields terminated by "\t" location "/user/hive/warehouse/tmp.db/user_behavior20190514"; //数据所在的目录;
创建orc格式的外部表
.txt文件不能直接load成orc格式文件
Caused by: java.io.IOException: Malformed ORC file
原因:
ORC格式是列式存储的表,不能直接从本地文件导入数据,只有当数据源表也是ORC格式存储时,才可以直接加载,否则会出现上述报错。
解决办法:
要么将数据源表改为以ORC格式存储的表,要么新建一个以textfile格式的临时表先将源文件数据加载到该表,然后在从textfile表中insert数据到ORC目标表中。
通过insert overwrite将txt格式转换成orc格式;
create database dwd; drop table if exists dwd.user_behavior;
create external table if not exists dwd.user_behavior( uid STRING comment "用户唯一标识", username STRING comment "用户昵称", gender STRING comment "性别", level TINYINT comment "1代表小学,2代表初中,3代表高中", is_vip TINYINT comment "0代表不是会员,1代表是会员", os STRING comment "操作系统:os,android等", channel STRING comment "下载渠道:auto,toutiao,huawei", net_config STRING comment "当前网络类型", ip STRING comment "IP地址", phone STRING comment "手机号码", video_id INT comment "视频id", video_length INT comment "视频时长,单位秒", start_video_time BIGINT comment "开始看视频的时间缀,秒级", end_video_time BIGINT comment "退出视频时的时间缀,秒级", version STRING comment "版本", event_key STRING comment "事件类型", event_time BIGINT comment "事件发生时的时间缀,秒级") partitioned by(dt INT) row format delimited fields terminated by "\t" stored as ORC
查询并在外部表中插入数据:
create table if not exists tmp.user_behavior20190307( uid STRING comment "用户唯一标识", username STRING comment "用户昵称", gender STRING comment "性别", level TINYINT comment "1代表小学,2代表初中,3代表高中", is_vip TINYINT comment "0代表不是会员,1代表是会员", os STRING comment "操作系统:os,android等", channel STRING comment "下载渠道:auto,toutiao,huawei", net_config STRING comment "当前网络类型", ip STRING comment "IP地址", phone STRING comment "手机号码", video_id INT comment "视频id", video_length INT comment "视频时长,单位秒", start_video_time BIGINT comment "开始看视频的时间缀,秒级", end_video_time BIGINT comment "退出视频时的时间缀,秒级", version STRING comment "版本", event_key STRING comment "事件类型", event_time BIGINT comment "事件发生时的时间缀,秒级") row format delimited fields terminated by "\t" location "/user/hive/warehouse/tmp.db/user_behavior20190307";
insert overwrite table dwd.user_behavior partition(dt=20190307) select uid,username,gender,level,is_vip,os,channel,net_config,ip,phone,video_id, video_length,start_video_time,end_video_time,version,event_key,event_time from ( select uid,username,gender,level,is_vip,os,channel,net_config,ip,phone,video_id, video_length,start_video_time,end_video_time,version,event_key,event_time, row_number() OVER (PARTITION BY uid,event_key,event_time ORDER BY event_time) u_rank from tmp.user_behavior20190307 ) temp where u_rank = 1;
远程调试
在IDEA中进行调试:
场景:以后工作中经常会遇到在本地执行没有问题,到了服务器跑的数据就是错误的
IDEA设置:Run --> Edit Configurations添加Remote
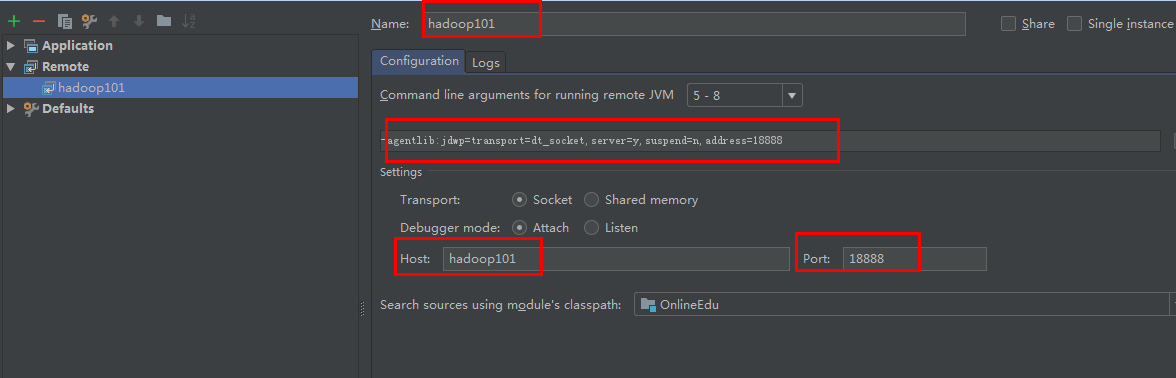
[kris@hadoop101 spark]$ bin/spark-submit --master local[2] --driver-java-options "-Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=y,address=18888"
--class com.atguigu.user_behavior.UserBehaviorCleaner Online-Edu-1.0-SNAPSHOT.jar
hdfs://hadoop101:9000/user/hive/warehouse/ods.db/origin_user_behavior/2019-05-14
hdfs://hadoop101:9000/user/hive/warehouse/tmp.db/user_behavior20190514 Listening for transport dt_socket at address: 18888
在IDEA中就可以进行EDBUG:
使用spark-shell进行调试
[kris@hadoop101 spark]$ bin/spark-shell --master local[2] --jars Online-Edu-1.0-SNAPSHOT.jar scala> sc.textFile("/user/hive/warehouse/ods.db/origin_user_behavior/2019-05-14") res0: org.apache.spark.rdd.RDD[String] = /user/hive/warehouse/ods.db/origin_user_behavior/2019-05-14 MapPartitionsRDD[1] at textFile at <console>:25 scala> def checkEventValid(event:String) ={ | event.split("\t").length == 17 | } checkEventValid: (event: String)Boolean



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2018-05-19 Jquery框架1.选择器|效果图|属性、文档操作