
实时--1.2 日志数据| 日活DAU
1. 日活DAU
① SparkStreaming消费kafka数据
Kafka作为数据来源,从kafka中获取日志,kafka中的日志类型有两种,启动和事件,统计日活,只获取启动日志即可。
1. 从Redis中获取Kafka分区偏移量(将偏移量存储到redis中 ,手动维护kafka偏移量 )
2. 获取当前采集周期从Kafka中消费的数据的 起始偏移量以及结束偏移量值
3. 通过SparkStreaming程序从kafka中读取数据并转化结构
4. 通过Redis 对采集到的启动日志进行去重操作: 以分区为单位对数据进行处理,每一个分区获取一次Redis的连接
redis去重,使用 set存储结构,key为 dau:2020-10-23 value为 mid expire时间为3600*24
5. 将数据批量的保存到ES中; 实现幂等性操作,在批量向ES写数据的时候,指定Index的id; 最后向redis中提交偏移量
② 利用redis过滤当日已经计入的日活设备(对一个用户的多次访问进行去重)
每个用户每天可能启动多次。要想计算日活,我们只需要把当前用户每天的第一次启动日志获取即可,所以要对启动日志进行去重,相当于做了一次清洗。
实时计算中的去重是一个比较常见的需求,可以有许多方式实现,比如
- 将状态存在Redis中
- 存在关系型数据库中
- 通过Spark自身的updateStateByKey(checkPoint小文件等问题比较麻烦)等
这里结合Redis实现对当前用户启动日志去重操作
利用Redis保存今天访问过系统的用户清单
即SparkStreaming从Kafka中读取到用户的启动日志之后,将用户的启动日志保存到Redis中,进行去重
根据保存反馈得到用户是否已存在
Redis的五大数据类型中,String和Set都可以完成去重功能,但是String管理不适合整体操作,比如设置失效时间或者获取当天用户等操作, 所以我们项目中使用的是Set类型,处理批
量管理以外,还可以根据saddAPI 的返回结果判断用户是否已经存在
|
Key |
Value |
|
dau:2019-01-22 |
设备id |
③ 把每批次新增的当日日活信息保存到ES中
去重清洗后的数据如何处理
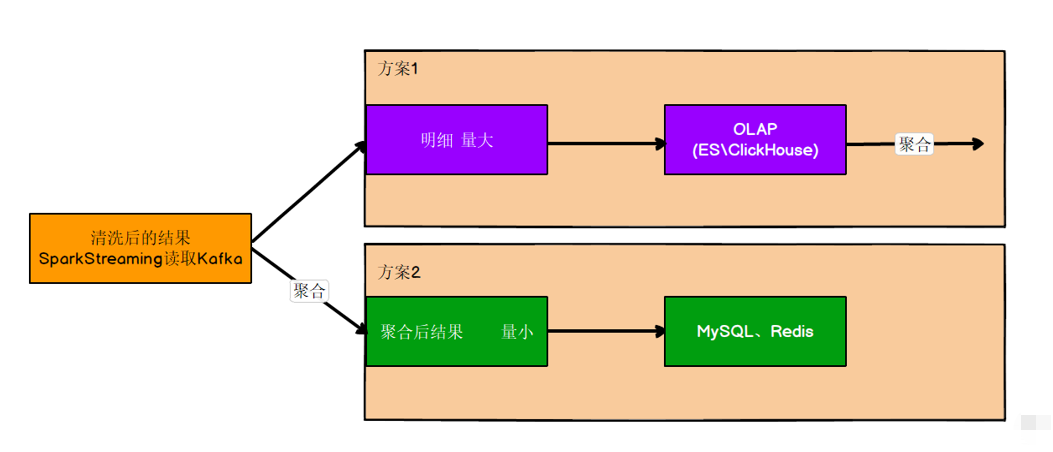
这里使用方案一
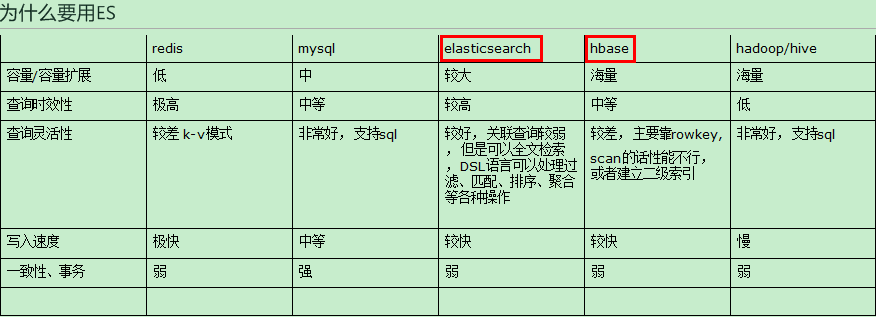
综上 ,在实际环境中,需要一种能够容纳较大规模数据切交互性好的数据库。mysql虽然交互性好,但是容量扩展性有限。
hbase虽然能够支持海量数据,但是查询的灵活度不足。所以ES在容量及交互性上达到一个非常不错的平衡,而且还能支持全文检索。
在ES中创建索引模板
text 支持分词; keyword 只能全部内容匹配
保存数据之前一定要先定义好mapping: 每个字段的类型 ; 分清楚索引类型
1、需要索引 也需要分词:标题,商品名称,分类名称, type:“text”
2、需要索引,但不需要分词:类型id , 日期,数量 ,年龄 ,各种id, type:"keyword";
mid, uid,area,os ,ch ,vs,logDate,logHourMinute,ts
3、既不需要索引,也不需要分词: 不被会用于条件过滤,经过脱敏的字段,138****0101 index:false

PUT _template/gmall_dau_info_template
{
"index_patterns": ["gmall_dau_info*"],
"settings": {
"number_of_shards": 3
},
"aliases" : {
"{index}-query": {},
"gmall_dau_info-query":{}
},
"mappings": {
"_doc":{
"properties":{
"mid":{
"type":"keyword"
},
"uid":{
"type":"keyword"
},
"ar":{
"type":"keyword"
},
"ch":{
"type":"keyword"
},
"vc":{
"type":"keyword"
},
"dt":{
"type":"keyword"
},
"hr":{
"type":"keyword"
},
"mi":{
"type":"keyword"
},
"ts":{
"type":"date"
}
}
}
}
}
保证数据的精准一次性消费
- 精确一次消费(Exactly-once)
是指消息一定会被处理且只会被处理一次。不多不少就一次处理。
如果达不到精确一次消费,可能会达到另外两种情况:
- 至少一次消费(at least once)
主要是保证数据不会丢失,但有可能存在数据重复问题。
- 最多一次消费 (at most once)
主要是保证数据不会重复,但有可能存在数据丢失问题。
数据丢失与重复问题
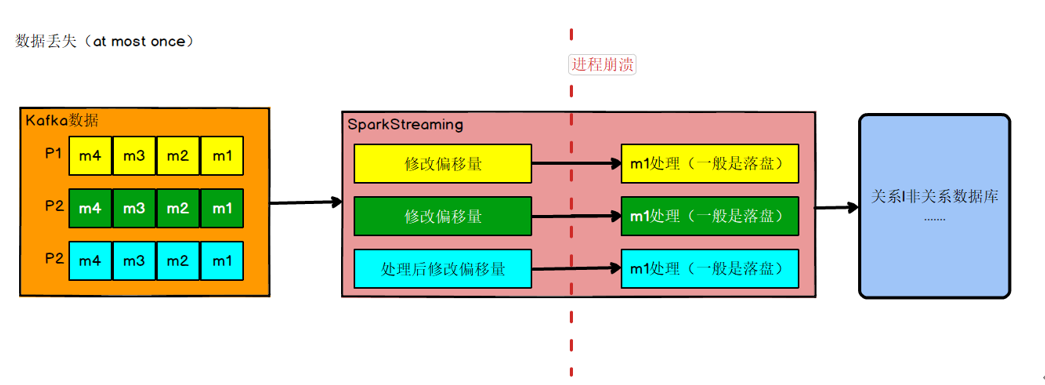
数据何时会丢失
比如实时计算任务进行计算,到数据结果存盘之前,进程崩溃,假设在进程崩溃前kafka调整了偏移量,那么kafka就会认为数据已经被处理过,即使进程重启,kafka也会从新的偏移量开始,所以之前没有保存的数据就被丢失掉了。
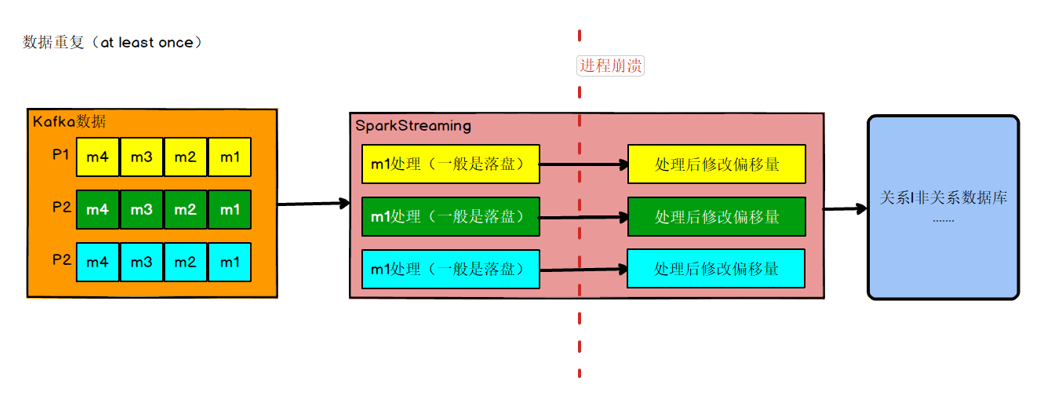
数据何时会重复
如果数据计算结果已经存盘了,在kafka调整偏移量之前,进程崩溃,那么kafka会认为数据没有被消费,进程重启,会重新从旧的偏移量开始,那么数据就会被2次消费,又会被存盘,数据就被存了2遍,造成数
据重复。
如果同时解决了数据丢失和数据重复的问题,那么就实现了精确一次消费的语义了。
目前Kafka默认每5秒钟做一次自动提交偏移量,这样并不能保证精准一次消费
enable.auto.commit 的默认值是 true;就是默认采用自动提交的机制。
auto.commit.interval.ms 的默认值是 5000,单位是毫秒。
如何解决
策略一:利用关系型数据库的事务进行处理
出现丢失或者重复的问题,核心就是偏移量的提交与数据的保存,不是原子性的。如果能做成要么数据保存和偏移量都成功,要么两个失败,那么就不会出现丢失或者重复了。
这样的话可以把存数据和修改偏移量放到一个事务里。这样就做到前面的成功,如果后面做失败了,就回滚前面那么就达成了原子性,这种情况先存数据还是先修改偏移量没影响。
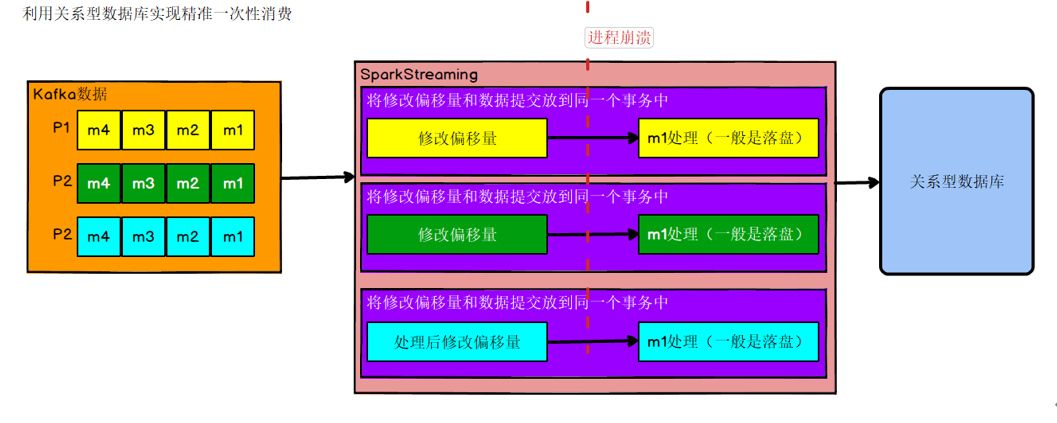
好处
事务方式能够保证精准一次性消费
问题与限制
- 数据必须都要放在某一个关系型数据库中,无法使用其他功能强大的nosql数据库;
- 事务本身性能不好;
- 如果保存的数据量较大一个数据库节点不够,多个节点的话,还要考虑分布式事务的问题。分布式事务会带来管理的复杂性,一般企业不选择使用,有的企业会把分布式事务变成本地事务,例如把Executor上的数据通过rdd.collect算子提取到Driver端,由Driver端统一写入数据库,这样会将分布式事务变成本地事务的单线程操作,降低了写入的吞吐量
使用场景
数据足够少(通常经过聚合后的数据量都比较小,明细数据一般数据量都比较大),并且支持事务的数据库
策略二:手动提交偏移量+幂等性处理
我们知道如果能够同时解决数据丢失和数据重复问题,就等于做到了精确一次消费。那就各个击破。
首先解决数据丢失问题,办法就是要等数据保存成功后再提交偏移量,所以就必须手工来控制偏移量的提交时机。
但是如果数据保存了,没等偏移量提交进程挂了,数据会被重复消费。怎么办?那就要把数据的保存做成幂等性保存。即同一批数据反复保存多次,数据不会翻倍,保存一次和保存一
百次的效果是一样的。如果能做到这个,就达到了幂等性保存,就不用担心数据会重复了。

难点
话虽如此,在实际的开发中手动提交偏移量其实不难,难的是幂等性的保存,有的时候并不一定能保证,这个需要看使用的数据库,如果数据库本身不支持幂等性操作,那只能优
先保证的数据不丢失,数据重复难以避免,即只保证了至少一次消费的语义。
一般有主键的数据库都支持幂等性操作upsert。
使用场景
处理数据较多,或者数据保存在不支持事务的数据库上
手动提交偏移流程
- 偏移量保存在哪
本身kafka 0.9版本以后consumer的偏移量是保存在kafka的__consumer_offsets主题中。但是如果用这种方式管理偏移量,有一个限制就是在提交偏移量时,数据流的元素结构不能
发生转变,即提交偏移量时数据流,必须是InputDStream[ConsumerRecord[String, String]] 这种结构。但是在实际计算中,数据难免发生转变,或聚合,或关联,一旦发生转变,就
无法在利用以下语句进行偏移量的提交:
xxDstream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
因为offset的存储于HasOffsetRanges,只有kafkaRDD继承了他,所以假如我们对KafkaRDD进行了转化之后,其它RDD没有继承HasOffsetRanges,所以就无法再获取offset了。
所以实际生产中通常会利用ZooKeeper,Redis,Mysql等工具手动对偏移量进行保存
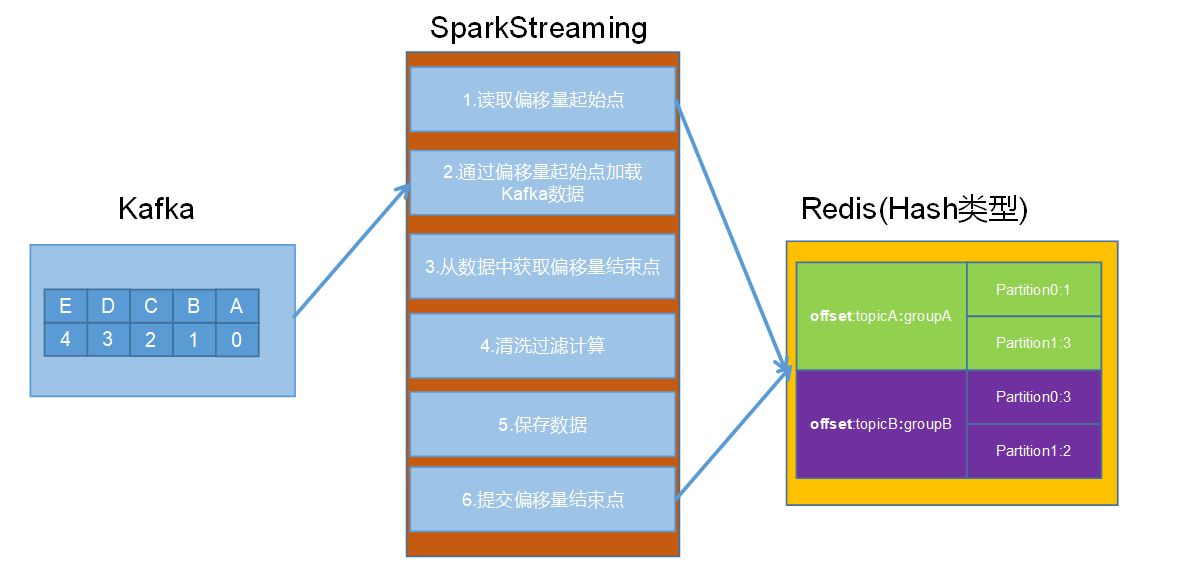
幂等性操作
其实我们前面已经使用Redis进行了去重操作,基本上是可以保证幂等性的。如果更严格的保证幂等性,那我们在批量向ES写数据的时候,指定Index的id即可
- 修改MyESUtil
关于去重
我们是通过Redis完成的去重,其实也可以在ES中进行去重操作
但是通过Redis去重,保留的是前面的数据,有就不向里加
通过ES或者其他数据库去重,是完成的替换,保留的是后面的数据
根据实际的需求选择合适的实现
④ 从ES中查询出数据,发布成数据接口,可视化工程进行调用



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人