
实时--1.3 业务数据| 采集| 事实表与维表关联
业务数据
需求分析:当日新增付费用户首单分析
按省份| 用户性别| 用户年龄段,统计当日新增付费用户首单平均消费及人数占比
无论是省份名称、用户性别、用户年龄,订单表中都没有这些字段,需要订单(事实表)和维度表(省份、用户)进行关联,形成宽表后将数据写入到ES,通过Kibana进行分析以及
图形展示。
思路分析
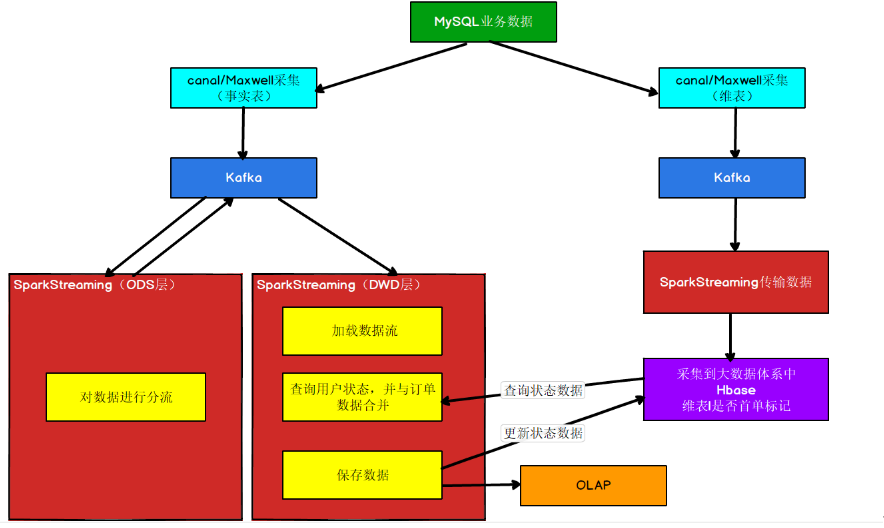
① 数据采集
从MySQL数据库中采集业务数据到Kafka,并对数据进行分流处理(ODS层),分流数据处理之后,将数据写回Kafka。可以使用canal或 Maxwell实现。
② 判断是否为首单用户
每笔订单都要判断是否是该用户的首单
判断是否首单的要点,在于该用户之前是否参与过消费(下单)。那么如何知道用户之前是否参与过消费,如果临时从所有消费记录中查询,是非常不现实的。那么只有将“用户是否
消费过”这个状态进行保存并长期维护起来。在有需要的时候通过用户id进行关联查询。
在实际生产中,这种用户状态是非常常见的比如“用户是否退过单”、“用户是否投过诉”、“用户是否是高净值用户”等等。我们要想保存状态,大家可能会想到在Redis中保存,Reids
可以实现,但是这个状态可能包含历史数据,数据量比较大,而且历史数据保存在内存中,对内存压力也比较大。所以考虑到
- 1、这是一个保存周期较长的数据。
- 2、必须可修改状态值。
- 3、查询模式基本上是k-v模式的查询。
所以综上这三点比较,状态适合保存在Hbase中。
③ 订单与维度表的关联
在查询订单的时候,订单与Hbase中省份和用户的维度表进行关联,才能获取省份名称、用户性别、用户年龄等对应字段,完成后面的统计。
④ 可视化展示
将订单关联后的宽表保存到ES,利用Kibana进行分析展示
数据采集
执行不同操作,Maxwell和canal数据格式对比
- 执行insert测试语句
INSERT INTO z_user_info VALUES(30, 'zhang3', '13810001010'),(31, 'li4', '1389999999');



Canal
{
"data": [{
"id": "30",
"user_name": "zhang3",
"tel": "13810001010"
}, {
"id": "31",
"user_name": "li4",
"tel": "1389999999"
}],
"database": "gmall-2020-04",
"es": 1589385314000,
"id": 2,
"isDdl": false,
"mysqlType": {
"id": "bigint(20)",
"user_name": "varchar(20)",
"tel": "varchar(20)"
},
"old": null,
"pkNames": ["id"],
"sql": "",
"sqlType": {
"id": -5,
"user_name": 12,
"tel": 12
},
"table": "z_user_info",
"ts": 1589385314116,
"type": "INSERT"
}
maxwell
{
"database": "gmall-2020-04",
"table": "z_user_info",
"type": "insert",
"ts": 1589385314,
"xid": 82982,
"xoffset": 0,
"data": {
"id": 30,
"user_name": "zhang3",
"tel": "13810001010"
}
}
{
"database": "gmall-2020-04",
"table": "z_user_info",
"type": "insert",
"ts": 1589385314,
"xid": 82982,
"commit": true,
"data": {
"id": 31,
"user_name": "li4",
"tel": "1389999999"
}
}
区别:
canal的 insert, 插入多条时,它的data 数据是以[{},{}]格式进行存储, 而maxwell是以一条数据一个{};
canal中比maxwell多"es"、 "isDdl"、 "mysqlType"、 "old"、 "pkNames"、"sql"、"sqlType"
共同的信息有:
"database"、 "table"、"type"、 "ts"、 "data" (canal中是以[{},{}], maxwell中是{}, {})
- 执行update操作
UPDATE z_user_info SET user_name='wang55' WHERE id IN(30, 31)
Canal
{
"data": [{
"id": "30",
"user_name": "wang55",
"tel": "13810001010"
}, {
"id": "31",
"user_name": "wang55",
"tel": "1389999999"
}],
"database": "gmall-2020-04",
"es": 1589385508000,
"id": 3,
"isDdl": false,
"mysqlType": {
"id": "bigint(20)",
"user_name": "varchar(20)",
"tel": "varchar(20)"
},
"old": [{
"user_name": "zhang3"
}, {
"user_name": "li4"
}],
"pkNames": ["id"],
"sql": "",
"sqlType": {
"id": -5,
"user_name": 12,
"tel": 12
},
"table": "z_user_info",
"ts": 1589385508676,
"type": "UPDATE"
}
Maxwell
{
"database": "gmall-2020-04",
"table": "z_user_info",
"type": "update",
"ts": 1589385508,
"xid": 83206,
"xoffset": 0,
"data": {
"id": 30,
"user_name": "wang55",
"tel": "13810001010"
},
"old": {
"user_name": "zhang3"
}
}
{
"database": "gmall-2020-04",
"table": "z_user_info",
"type": "update",
"ts": 1589385508,
"xid": 83206,
"commit": true,
"data": {
"id": 31,
"user_name": "wang55",
"tel": "1389999999"
},
"old": {
"user_name": "li4"
}
}
update时, 两者的区别:
canal的 update, 更新多条时,它的data 数据是以[{},{}]格式进行存储, 而maxwell是以一条数据一个{};
canal中比maxwell多"es"、 "isDdl"、 "mysqlType"、 "pkNames"、"sql"、"sqlType"
共同的信息有:
"database"、 "table"、"type"、"old"、 "ts"、 "data" (canal中是以[{},{}], maxwell中是{}, {})
- delete操作
DELETE FROM z_user_info WHERE id IN(30, 31)
canal
{
"data": [{
"id": "30",
"user_name": "wang55",
"tel": "13810001010"
}, {
"id": "31",
"user_name": "wang55",
"tel": "1389999999"
}],
"database": "gmall-2020-04",
"es": 1589385644000,
"id": 4,
"isDdl": false,
"mysqlType": {
"id": "bigint(20)",
"user_name": "varchar(20)",
"tel": "varchar(20)"
},
"old": null,
"pkNames": ["id"],
"sql": "",
"sqlType": {
"id": -5,
"user_name": 12,
"tel": 12
},
"table": "z_user_info",
"ts": 1589385644829,
"type": "DELETE"
}
maxwell
{
"database": "gmall-2020-04",
"table": "z_user_info",
"type": "delete",
"ts": 1589385644,
"xid": 83367,
"xoffset": 0,
"data": {
"id": 30,
"user_name": "wang55",
"tel": "13810001010"
}
}
{
"database": "gmall-2020-04",
"table": "z_user_info",
"type": "delete",
"ts": 1589385644,
"xid": 83367,
"commit": true,
"data": {
"id": 31,
"user_name": "wang55",
"tel": "1389999999"
}
}
delete 时, 两者的区别:
canal的 delete, 删除多条时,它的data 数据是以[{},{}]格式进行存储, 而maxwell是以一条数据一个{};
canal中比maxwell多"es"、 "isDdl"、 "mysqlType"、 "pkNames"、"sql"、"sqlType"
共同的信息有:
"database"、 "table"、"type"、 "ts"、 "data" (canal中是以[{},{}], maxwell中是{}, {})
总结数据特点
- 日志结构
canal 每一条SQL会产生一条日志,如果该条Sql影响了多行数据,则已经会通过集合的方式归集在这条日志中。(即使是一条数据也会是数组结构)
maxwell 以影响的数据为单位产生日志,即每影响一条数据就会产生一条日志。如果想知道这些日志是否是通过某一条sql产生的可以通过xid进行判断,相同的xid的日志来自同一sql。
- 数字类型
当原始数据是数字类型时,maxwell会尊重原始数据的类型不增加双引,变为字符串。canal一律转换为字符串。
- 带原始数据字段定义
canal数据中会带入表结构。maxwell更简洁。
SparkStreaming对Topic分流业务代码
基于Maxwell从Kafka中读取业务数据,进行分流
import com.alibaba.fastjson.{JSON, JSONObject}
import com.stream.gmall.util.{MyKafkaSink, MyKafkaUtil, OffsetManagerUtil}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{HasOffsetRanges, OffsetRange}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object BaseDBMaxwellApp {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("BaseDBMaxwellApp").setMaster("local[*]")
val ssc: StreamingContext = new StreamingContext(conf, Seconds(5))
var topic = "gmall_db"
var groupId = "base_db_maxwell_group"
//从redis中获取偏移量
val offsetMap: Map[TopicPartition, Long] = OffsetManagerUtil.getOffset(topic, groupId)
var recordDStream: InputDStream[ConsumerRecord[String, String]] = null
if (offsetMap != null && offsetMap.size > 0) {
recordDStream = MyKafkaUtil.getKafkaStream(topic, ssc, offsetMap, groupId)
} else {
recordDStream = MyKafkaUtil.getKafkaStream(topic, ssc, groupId)
}
//获取当前采集周期中读取的主题对应的分区以及偏移量
var offsetRanges: Array[OffsetRange] = Array.empty[OffsetRange]
val offsetDStream: DStream[ConsumerRecord[String, String]] = recordDStream.transform {
rdd => {
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}
}
//对读取的数据进行结构转换 ConsumerRecord[String, String] => V(jsonStr) => V(jsonObj)
val jsonObjDStream: DStream[JSONObject] = offsetDStream.map {
record => {
val jsonStr: String = record.value()
//将json字符串转换为json对象
val jsonObj: JSONObject = JSON.parseObject(jsonStr)
jsonObj
}
}
//分流
jsonObjDStream.foreachRDD{
rdd => {
rdd.foreach{
jsonObj => {
//获取操作类型
val opType: String = jsonObj.getString("type")
//获取操作的数据
val dataJsonObj: JSONObject = jsonObj.getJSONObject("data")
/*if (dataJsonObj != null && !dataJsonObj.isEmpty && "insert".equals(opType)) {
//获取表名
val tableName: String = jsonObj.getString("table")
//拼接要发送的主题
var sendTopic = "ods_" + tableName
MyKafkaSink.send(topic, dataJsonObj.toString)
}*/
//获取表名
val tableName: String = jsonObj.getString("table")
if (dataJsonObj != null && !dataJsonObj.isEmpty) {
if (
("order_info".equals(tableName) && "insert".equals(opType))
|| (tableName.equals("order_detail") && "insert".equals(opType))
|| (tableName.equals("base_province"))
|| (tableName.equals("user_info"))
|| (tableName.equals("sku_info"))
|| (tableName.equals("base_trademark"))
|| (tableName.equals("base_category3"))
|| (tableName.equals("spu_info"))
) {
//拼接要发送到的主题
var sendTopic = "ods_" + tableName
MyKafkaSink.send(sendTopic, dataJsonObj.toString())
}
}
}
}
//手动提交偏移量
OffsetManagerUtil.saveOffset(topic, groupId, offsetRanges)
}
}
ssc.start()
ssc.awaitTermination()
}
}
测试
- 启动Redis
- 启动Maxwell
- 运行BaseDBMaxwellApp程序
- 查看kafka下的主题 bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic ods_order_info
- 运行/opt/module/realtime_dw/rt_dblog模拟生成日志
判断是否为首单用户的实现
使用 phoenix在hbase中建表
(1) 执行建表以语句
create table user_status( user_id varchar primary key ,state.if_consumed varchar ) SALT_BUCKETS = 3
OrderInfo样例类
/** * Desc: 订单样例类 */ case class OrderInfo( id: Long, //订单编号 province_id: Long, //省份id order_status: String, //订单状态 user_id: Long, //用户id final_total_amount: Double, //总金额 benefit_reduce_amount: Double, //优惠金额 original_total_amount: Double, //原价金额 feight_fee: Double, //运费 expire_time: String, //失效时间 create_time: String, //创建时间 operate_time: String, //操作时间 var create_date: String, //创建日期 var create_hour: String, //创建小时 var if_first_order:String, //是否首单 var province_name:String, //地区名 var province_area_code:String, //地区编码 var province_iso_code:String, //国际地区编码 var user_age_group:String, //用户年龄段 var user_gender:String //用户性别 )
UserStatus样例类
/**
* Desc: 用于映射用户状态表的样例类
*/
case class UserStatus(
userId:String, //用户id
ifConsumed:String //是否消费过 0首单 1非首单
)
读取订单信息,查询用户状态(判断是否首单)
创建业务类OrderInfoApp,读取订单、维护用户状态代码
将用户是否消费的状态保存到Hbase中
一个采集周期状态修正
漏洞
如果一个用户是首次消费,在一个采集周期中,这个用户下单了2次,那么就会把这同一个用户都会统计为首单消费
解决办法
应该将同一采集周期的同一用户的最早的订单标记为首单,其它都改为非首单
- 同一采集周期的同一用户-----按用户分组(groupByKey)
- 最早的订单-----排序,取最早(sortwith)
- 标记为首单-----具体业务代码
订单与维度表的关联
处理维度数据合并的策略
维度数据和状态数据非常像,但也有不同之处
相同点
- 长期保存维护
- 可修改
- 使用k-v方式查询
不同点
- 数据变更的时机不同
- 状态数据往往因为事实数据的新增变化而变更
- 维度数据只会受到业务数据库中的变化而变更
综上
根据共同点,维度数据也是非常适合使用hbase存储的,稍有不同的是维度数据必须启动单独的实时计算来监控维度表变化来更新实时数据。
维度表的读取
通过phoenix在Hbase中建表
(1) 创建省份表
create table gmall2020_province_info (id varchar primary key,info.name varchar,info.area_code varchar,info.iso_code varchar)SALT_BUCKETS = 3
(2) 创建用户表
create table gmall2020_user_info (id varchar primary key ,user_level varchar, birthday varchar,
gender varchar, age_group varchar , gender_name varchar)SALT_BUCKETS = 3
创建SparkStreaming读取省份维度数据
省份样例类ProviceInfo
用户样例类UserInfo
-
读取省份维度数据类ProvinceInfoApp
-
读取用户维度数据类UserInfoApp
利用maxwell-bootstrap 初始化数据
初始化省份表
bin/maxwell-bootstrap --user maxwell --password 123456 --host hadoop102 --database gmall --table base_province --client_id maxwell_1
初始化用户表
bin/maxwell-bootstrap --user maxwell --password 123456 --host hadoop102 --database gmall --table user_info --client_id maxwell_1
- --user maxwell 数据库分配的操作maxwell数据库的用户名
- --password 123456 数据库分配的操作maxwell数据库的密码
- --host 数据库主机名
- --database 数据库名
- --table 表名
- --client_id
maxwell-bootstrap不具备将数据直接导入kafka或者hbase的能力,通过--client_id指定将数据交给哪个maxwell进程处理,在maxwell的conf.properties中配置
测试
运行BaseDBMaxwellApp、ProvinceInfoApp、UserInfoApp同步数据, 在maxwell执行bin/maxwell-bootstrap脚本
随便修改Mysql数据库base_province,user_info表中的一条数据,查看hbase中的结果。
如果BaseDBMaxwellApp出现如下的异常:

是因为使用bin/maxwell-bootstrap同步原始数据的时候,会生成两条标记起始和结束的json字符串,这两条数据的data属性是null的,并且type属性也和原来的标记不一样,例如:插入
操作标记位bootstrap-insert
解决:修改BaseDBMaxwellApp分流的代码
//5.根据不同表名,将数据分别发送到不同的kafka主题中
jsonObjDStream.foreachRDD{
rdd=>{
rdd.foreach{
jsonObj=>{
//5.0 获取类型
val opType = jsonObj.getString("type")
//5.1 获取表名
val tableName: String = jsonObj.getString("table")
val dataObj: JSONObject = jsonObj.getJSONObject("data")
if(dataObj!=null && !dataObj.isEmpty){
if(
("order_info".equals(tableName)&&"insert".equals(opType))
|| (tableName.equals("order_detail") && "insert".equals(opType))
|| tableName.equals("base_province")
|| tableName.equals("user_info")
|| tableName.equals("sku_info")
|| tableName.equals("base_trademark")
|| tableName.equals("base_category3")
|| tableName.equals("spu_info")
){
//5.3 拼接发送到kafka的主题名
var sendTopic :String = "ods_" + tableName
//5.4 发送消息到kafka
MyKafkaSink.send(sendTopic,dataObj.toString)
}
}
}
}
因为前面产生了空数据,那么ProvinceInfoApp和UserInfoApp在保存到Hbase的时候,可能会报错,可以先注释掉saveToPhoenix的操作,运行程序,消费kafka的错误数据,改变偏移
量。
订单表和维度表的关联
OrderInfoApp代码 查询订单信息,判断是否为首单消费
1.从kafka主题ods_order_info 中读取数据
2. 判断是否为首单 if_first_order首单为1, 否则为0
3.同一批次中状态修正
应该将同一采集周期的同一用户的最早的订单标记为首单,其它都改为非首单
同一采集周期的同一用户-----按用户分组(groupByKey)
最早的订单-----排序,取最早(sortwith)
标记为首单-----具体业务代码
5.和省份维度表进行关联 以采集周期为单位对数据进行处理 --->通过SQL将所有的省份查询出来
6.和用户维度表进行关联 以分区为单位对数据进行处理,每个分区拼接一个sql 到phoenix上查询用户数据
7. 维护首单用户状态|||保存订单到ES中
//如果当前用户为首单用户(第一次消费),那么我们进行首单标记之后,应该将用户的消费状态保存到Hbase中,等下次这个用户
//再下单的时候,就不是首单了
测试
- 运行BaseDBMaxwellApp和OrderInfoApp同步数据
- 运行模拟生成数据的jar包
- 查看控制台输出的OrderInfoApp是否和省份以及用户进行了关联

可视化展示
在ES中创建索引接收关联的数据
PUT _template/gmall_order_info_template { "index_patterns": ["gmall_order_info*"], "settings": { "number_of_shards": 3 }, "aliases" : { "{index}-query": {}, "gmall_order_info-query":{} }, "mappings": { "_doc":{ "properties":{ "id":{ "type":"long" }, "province_id":{ "type":"long" }, "order_status":{ "type":"keyword" }, "user_id":{ "type":"long" }, "final_total_amount":{ "type":"double" }, "benefit_reduce_amount":{ "type":"double" }, "original_total_amount":{ "type":"double" }, "feight_fee":{ "type":"double" }, "expire_time":{ "type":"keyword" }, "create_time":{ "type":"keyword" }, "create_date":{ "type":"date" }, "create_hour":{ "type":"keyword" }, "if_first_order":{ "type":"keyword" }, "province_name":{ "type":"keyword" }, "province_area_code":{ "type":"keyword" }, "province_iso_code":{ "type":"keyword" }, "user_age_group":{ "type":"keyword" }, "user_gender":{ "type":"keyword" } } } } }
在OrderInfoApp中,将关联后的数据写到ES中
当日首单用户,不同省份的平均消费
是否首单作为查询条件,以省份进行分组,取平均值
创建IndexPatterns,确定数据源和数据范围
Kibana->Index Patterns->Create index pattern
当日首单用户,不同性别的人数占比
是否首单作为查询条件,以性别进行分组,取count
当日首单用户,不同年龄段的人数占比
是否首单作为查询条件,以年龄段进行分组,取count



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人