
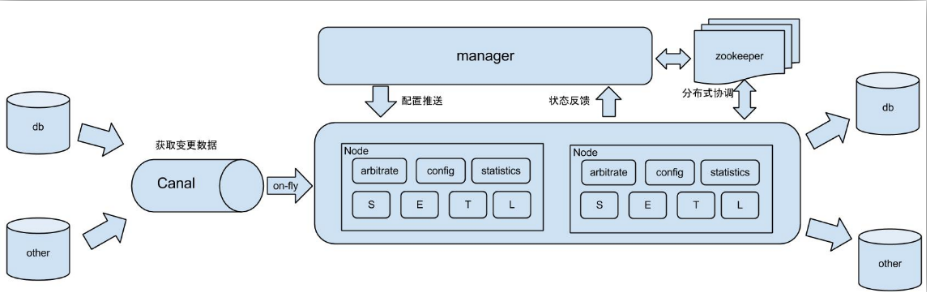
Canal-HA | 搭建| 配置| 使用
1.canal数据采集
Canal是用java开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。目前,Canal主要支持了MySQL的Binlog解析,解析完成后才利用Canal Client 用来处理获得的
相关数据。(数据库同步需要阿里的otter中间件,基于Canal)
同步mysql;做拉链表;更新redis
某些情况无法从日志中获取信息,而又无法利用sqoop等ETL工具对数据实时的监控
1.1 使用场景
1) 原始场景: 阿里otter中间件的一部分
otter是阿里用于进行异地数据库之间的同步框架,canal是其中一部分。
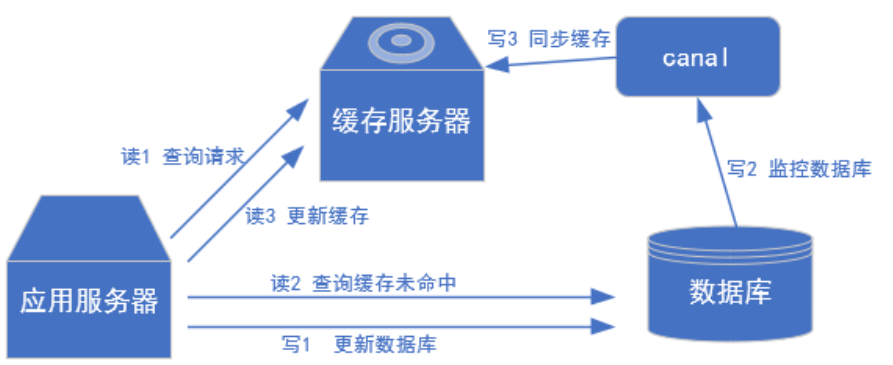
2) 常见场景1:更新缓存
3) 常见场景2:抓取业务数据新增变化表,用于制作拉链表。
4) 常见场景3:抓取业务表的新增变化数据,用于制作实时统计(我们就是这种场景)
1.2 工作原理
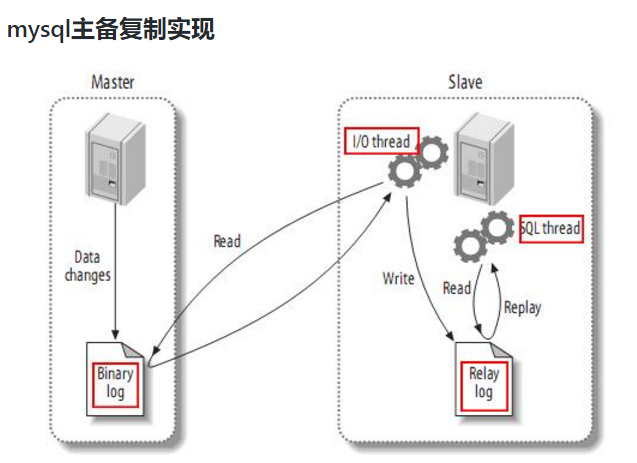
Mysql主从复制过程分成三步:
- 1)Master主库将改变记录写到二进制日志(binary log)中;
- 2)Slave从库向mysql master发送dump协议,将master主库的binary log events拷贝到它的中继日志(relay log);
- 3)Slave从库读取并重做中继日志中的事件,将改变的数据同步到自己的数据库。
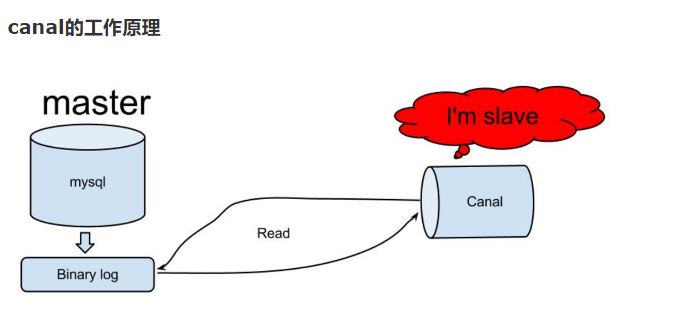
canal的工作原理很简单,就是把自己伪装成slave,假装从master复制数据。
1.3 开启Mysql的binlog
MySQL的二进制日志可以说是MySQL最重要的日志了,它记录了所有的DDL和DML(除了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间,MySQL的二进
制日志是事务安全型的。
一般来说开启二进制日志大概会有1%的性能损耗 。二进制有两个最重要的使用场景:
其一:MySQL Replication在Master端开启binlog,Master把它的二进制日志传递给slaves来达到master-slave数据一致的目的。
其二:自然就是数据恢复了,通过使用mysqlbinlog工具来使恢复数据。
二进制日志包括两类文件:
- 二进制日志索引文件(文件名后缀为.index)用于记录所有的二进制文件;
- 二进制日志文件(文件名后缀为.00000*)记录数据库所有的DDL和DML(除了数据查询语句)语句事件。
mysql binlog的格式分为三种,分别是STATEMENT, MIXED, ROW。在配置文件中可以选择配置binlog_format=row
它们的区别在于:
① statement
语句级,binlog会记录每次一执行写操作的语句。
相对row模式节省空间,但是可能产生不一致性,比如update tt set create_date=now()
如果用binlog日志进行恢复,由于执行时间不同可能产生的数据就不同。
优点: 节省空间;
缺点: 有可能造成数据不一致。
② row
行级, binlog会记录每次操作后每行记录的变化。
优点:保持数据的绝对一致性。因为不管sql是什么,引用了什么函数,他只记录执行后的效果。
缺点:占用较大空间。
③ mixed
statement的升级版,一定程度上解决了,因为一些情况而造成的statement模式不一致问题
在某些情况下譬如: 当函数中包含 UUID() 时; 包含 AUTO_INCREMENT 字段的表被更新时; 执行 INSERT DELAYED 语句时; 用 UDF 时;会按照 ROW的方式进行处理
优点:节省空间,同时兼顾了一定的一致性。
缺点:还有些极个别情况依旧会造成不一致,另外statement和mixed对于需要对binlog的监控的情况都不方便。
综合上面对比,Cannel想做监控分析,选择row格式比较合适
binlog的开启
在数据库服务器上将mysql binlog模式开启,并设置为row模式,因为canal对row模式支持较好,支持从指定的binlog的位置读取信息;
在[mysqld] 区块设置/添加 log-bin=mysql-bin
这个表示binlog日志的前缀是mysql-bin ,以后生成的日志文件就是 mysql-bin.123456 的文件后面的数字按顺序生成。 每次mysql重启或者到达单个文件大小的阈值时,新生一个文
件,按顺序编号。

找到mysql配置文件的位置
[kris@hadoop101 bin]$ which mysql
/usr/bin/mysql
[kris@hadoop101 bin]$ sudo find / -name my.cnf //mysql的my.cnf文件所在的目录 /usr/my.cnf
sudo vim /usr/my.cnf
server-id=1
log-bin=mysql-bin
binlog_format=row
##binlog-do-db=gmall //可指定监控某个库
重启MySql服务,查看配置是否生效,并添加canal用户赋权限。
sudo service mysql restart
mysql -uroot -p123456
mysql> show variables like 'binlog_format';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| binlog_format | ROW |
+---------------+-------+
mysql> show variables like 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | ON |
+---------------+-------+
配置起效果后,创建canale用户,并赋予权限
mysql> CREATE USER canal IDENTIFIED BY 'canal';
mysql> GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
mysql> FLUSH PRIVILEGES;
mysql> show grants for 'canal' ;
+----------------------------------------------------------------------------------------------------------------------------------------------+
| Grants for canal@% |
+----------------------------------------------------------------------------------------------------------------------------------------------+
| GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%' IDENTIFIED BY PASSWORD '*E3619321C1A937C46A0D8BD1DAC39F93B27D4458' |
+----------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
查看Mysql的mysql-bin文件


[kris@hadoop101 mysql]$ pwd /var/lib/mysql 重启mysql [kris@hadoop101 mysql]$ sudo service mysql restart Shutting down MySQL.... [确定] Starting MySQL..... 在mysql中更新数据: CALL init_data('2019-05-04',10,20,10,TRUE) 可以看到mysql-bin.000001文件大小发生的变化 [kris@hadoop101 mysql]$ ll //sudo ls -l 总用量 176448 -rw-rw---- 1 mysql mysql 56 3月 15 01:11 auto.cnf drwx------ 2 mysql mysql 4096 3月 20 19:15 azkaban drwx------ 2 mysql mysql 4096 5月 4 22:42 gmall -rw-r----- 1 mysql root 253742 5月 4 22:38 hadoop101.err -rw-rw---- 1 mysql mysql 5 5月 4 22:37 hadoop101.pid -rw-rw---- 1 mysql mysql 79691776 5月 4 22:42 ibdata1 -rw-rw---- 1 mysql mysql 50331648 5月 4 22:42 ib_logfile0 -rw-rw---- 1 mysql mysql 50331648 3月 15 01:10 ib_logfile1 drwx------ 2 mysql mysql 4096 4月 23 01:32 metastore drwx--x--x 2 mysql mysql 4096 3月 15 01:10 mysql -rw-rw---- 1 mysql mysql 19755 5月 4 22:42 mysql-bin.000001 -rw-rw---- 1 mysql mysql 19 5月 4 22:37 mysql-bin.index srwxrwxrwx 1 mysql mysql 0 5月 4 22:37 mysql.sock drwx------ 2 mysql mysql 4096 3月 15 01:10 performance_schema -rw-r--r-- 1 root root 125 3月 15 01:10 RPM_UPGRADE_HISTORY -rw-r--r-- 1 mysql mysql 125 3月 15 01:10 RPM_UPGRADE_MARKER-LAST drwx------ 2 mysql mysql 4096 4月 19 16:16 sparkmall drwxr-xr-x 2 mysql mysql 4096 3月 15 01:10 test
2.Canal-HA模式搭建
2.1 环境准备
(1)启动zookeeper
(2)启动kafka
Canal架构
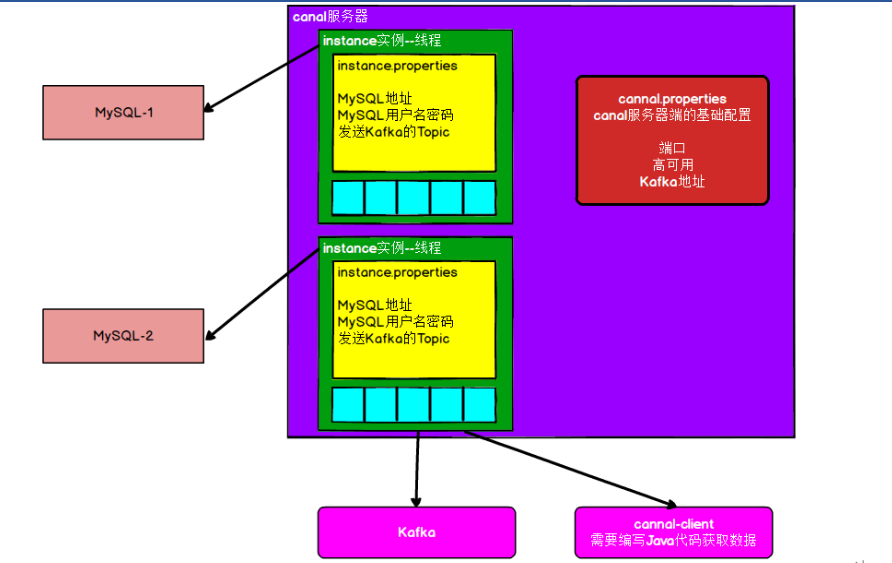
下载安装 https://github.com/alibaba/canal/releases
2.2 canal-server
在hadoop101和hadoop102上安装canal-server
在两台节点机器都安装部署:
mkdir -p /opt/module/canal-server tar -zxvf canal.deployer-1.1.4.tar.gz -C /opt/module/canal-server/
在hadoop101和hadoop102上的canal-server上各配置如下:
1)添加zookeeper地址,将file-instance.xml注释,解开default-instance.xml注释。修改两个canal-server节点的配置
vim conf/canal.properties ##默认端口号为1111,可以修改
canal.zkServers =hadoop101:2181,hadoop102:2181,hadoop103:2181
#canal.instance.global.spring.xml = classpath:spring/file-instance.xml
canal.instance.global.spring.xml = classpath:spring/default-instance.xml
2)在进入conf/example目录修改instance配置,instance.properties是针对要追踪的mysql的实例配置
[kris@hadoop101 canal-server] vim conf/example/instance.properties //hadoop101机器配置 canal.instance.mysql.slaveId = 100 //不能与mysql的server-id重复
canal.instance.master.address = hadoop101:3306
[kris@hadoop102 canal-server] vim conf/example/instance.properties //hadoop102机器的配置 canal.instance.mysql.slaveId = 101 canal.instance.master.address = hadoop101:3306
3)启动两台canal-server
[kris@hadoop101 canal-server]$ sh bin/startup.sh
[kris@hadoop102 canal-server]$ sh bin/startup.sh
查看日志,无报错便启动成功,一台节点有日志,一台节无日志
tail -f logs/example/example.log
通过zookeeper查看当前工作节点,可以看出当前活动节点为101
[kris@hadoop101 canal-server]$ /opt/module/zookeeper-3.4.10/bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /
[kafa_2.11, zookeeper, yarn-leader-election, hadoop-ha, otter, rmstore]
[zk: localhost:2181(CONNECTED) 1] get /otter/canal/destinations/example/running
{"active":true,"address":"192.168.1.101:11111"}
关闭canal
[kris@hadoop101 canal-server]$ sh bin/stop.sh
[kris@hadoop102 canal-server]$ sh bin/stop.sh
2.3 对接Kafka
canal 1.1.1版本之后, 默认支持将canal server接收到的binlog数据直接投递到MQ, 目前默认支持的MQ系统有:
- kafka: https://github.com/apache/kafka
- RocketMQ : https://github.com/apache/rocketmq
(1)修改instance配置文件 (两台节点)
[kris@hadoop101 canal-server]$ vim conf/example/instance.properties
canal.mq.topic=test ##将数据发送到指定的topic
canal.mq.partition=0
(2)修改canal.properties(两台节点)
[kris@hadoop101 canal-server]$ vim conf/canal.properties
canal.serverMode = kafka
canal.mq.servers = hadoop101:9092,hadoop102:9092,hadoop103:9092
canal.mq.retries = 0
canal.mq.batchSize = 16384
canal.mq.maxRequestSize = 1048576
canal.mq.lingerMs = 100
canal.mq.bufferMemory = 33554432
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
canal.mq.flatMessage = true
canal.mq.compressionType = none
canal.mq.acks = all
#canal.mq.properties. =
canal.mq.producerGroup = test
(3)启动canal
[kris@hadoop101 canal-server]$ sh bin/startup.sh [kris@hadoop102 canal-server]$ sh bin/startup.sh
(4)启动kafka消费者监听topic test
[kris@hadoop103 ~]$ /opt/module/kafka/bin/kafka-console-consumer.sh --bootstrap-server hadoop101:9092 --topic test
(5)向MySql数据库插入条数据 测试
插入: id = 4,name = smile,sex = femal
修改: id = 4,name = smile,sex = male
删除:id = 4的这条数据。
Kafka中接收到的数据格式如下:
[kris@hadoop101 ~]$ /opt/module/kafka/bin/kafka-console-consumer.sh --bootstrap-server hadoop101:9092 --topic test
增 {"data":[{"id":"4","name":"smile","sex":"female"}],
"database":"company","es":1598197042000,"id":1,"isDdl":false,
"mysqlType":{"id":"int(4)","name":"varchar(255)","sex":"varchar(255)"},
"old":null,"pkNames":["id"],"sql":"",
"sqlType":{"id":4,"name":12,"sex":12},
"table":"staff","ts":1598197042255,
"type":"INSERT"} 改 {"data":[{"id":"4","name":"smile","sex":"male"}],
"database":"company","es":1598197317000,"id":2,"isDdl":false,
"mysqlType":{"id":"int(4)","name":"varchar(255)","sex":"varchar(255)"},
"old":[{"sex":"female"}],
"pkNames":["id"],"sql":"",
"sqlType":{"id":4,"name":12,"sex":12},
"table":"staff","ts":1598197318118,
"type":"UPDATE"} 删 {"data":[{"id":"4","name":"smile","sex":"male"}],
"database":"company","es":1598197330000,"id":3,"isDdl":false,
"mysqlType":{"id":"int(4)","name":"varchar(255)","sex":"varchar(255)"},
"old":null,"pkNames":["id"],"sql":"",
"sqlType":{"id":4,"name":12,"sex":12},
"table":"staff","ts":1598197330144,
"type":"DELETE"}
2.4 canal-admin安装
准备
canal-admin的限定依赖:
(1)MySQL,用于存储配置和节点等相关数据
(2)canal版本,要求>=1.1.4 (需要依赖canal-server提供面向admin的动态运维管理接口)
安装
(1)解压安装
wget https://github.com/alibaba/canal/releases/download/canal-1.1.4/canal.admin-1.1.4.tar.gz
mkdir -p /opt/module/canal-admin
tar -zxvf canal.admin-1.1.4.tar.gz -C /opt/module/canal-admin/
(2)初始化元数据库
[kris@hadoop101 canal-admin]$ vim conf/application.yml
server:
port: 8089
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
spring.datasource:
address: hadoop101:3306
database: canal_manager
username: root
password: 123456
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
canal:
adminUser: admin
adminPasswd: admin
[kris@hadoop101 software]$ cd /opt/module/canal-admin/
[kris@hadoop101 canal-admin]$ mysql -uroot -p123456
mysql> source conf/canal_manager.sql
启动canal-admin
[kris@hadoop101 canal-admin]$ sh bin/startup.sh
查看日志
[kris@hadoop101 canal-admin]$ tail -f logs/admin.log
访问hadoop101 8089端口, 默认账号密码是admin /123456进行登录
[kris@hadoop101 bin]$ rm -rf canal.pid
启动之后jps 9239 CanalLauncher 检查 vim /bigdata/canal/logs/example.log 中是否有报错
3.Canal-admin使用
3.1 配置启动
配置启动
(1)修改配置填写Canal-damin地址 (两台节点都改)
[kris@hadoop101 canal-server]$ vim conf/canal.properties
canal.admin.manager = hadoop101:8089
# admin auto register
canal.admin.register.auto = true
canal.admin.register.cluster =
(2)启动Canal-admin
[kris@hadoop101 canal-admin]$ sh bin/startup.sh
(3)启动Canal-server
[kris@hadoop101 canal-server]$ sh bin/startup.sh
[kris@hadoop102 canal-server]$ sh bin/startup.sh
(4)登录页面查看 hadoop101:8089
3.2 集群运维

点击主配置后可以对canal.properies设计出一份全局的配置集群共享,可以创建多个集群
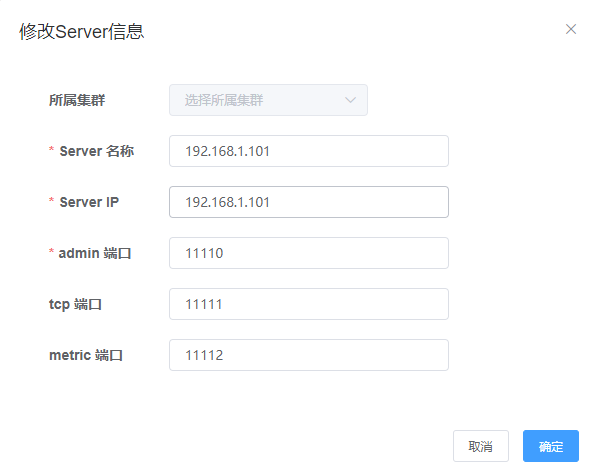
3.3 Server运维
配置项:
- 所属集群,可以选择为单机 或者 集群。一般单机Server的模式主要用于一次性的任务或者测试任务
- Server名称,唯一即可,方便自己记忆
- Server Ip,机器ip
- admin端口,canal 1.1.4版本新增的能力,会在canal-server上提供远程管理操作,默认值11110
- tcp端口,canal提供netty数据订阅服务的端口
- metric端口, promethues的exporter监控数据端口 (未来会对接监控)


3.4 Instance运维
创建instance



Canal和Zookeeper对应节点的关系
/otter/canal:canal的根目录
/otter/canal/cluster:整个canal server的集群列表
/otter/canal/destinations:destination的根目录
/otter/canal/destinations/example/running:服务端当前正在提供服务的running节点
/otter/canal/destinations/example/cluster:针对某个destination的工作集群列表
/otter/canal/destinations/example/1001/running:客户端当前正在读取的running节点
/otter/canal/destinations/example/1001/cluster:针对某个destination的客户端列表
/otter/canal/destinations/example/1001/cursor:客户端读取的position信息



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人