
Spark |02 SparkCore| 算子
Spark 核心编程
Spark计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于处理不同的应用场景。三大数据结构分别是:
➢ RDD : 弹性分布式数据集
➢ 累加器:分布式共享只写变量
➢ 广播变量:分布式共享只读变量
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的
集合。 A Resilient Distributed Dataset (RDD), the basic abstraction in Spark. Represents an immutable;可类比String,它也是不可变的,但是可有很多方法,如切分...
1. RDD的属性
RDD是一种抽象,是Spark对于分布式数据集的抽象,它用于囊括所有内存中和磁盘中的分布式数据实体。用数组类比下RDD:
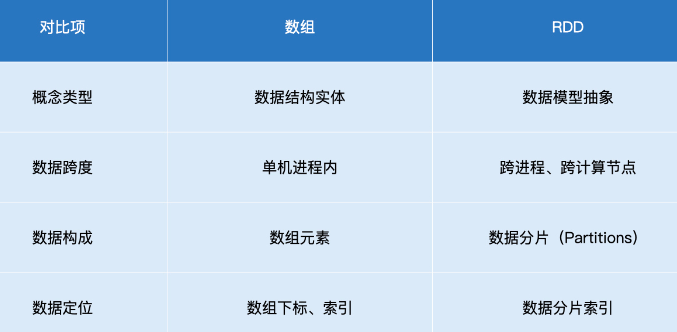
数组是实体,它是一种存储同类元素的数据结构,而RDD是一种抽象,它所囊括的是分布式计算环境中的分布式数据集。
因此,这两者第二方面的不同就是在活动范围,数组的“活动范围”很窄,仅限于单个计算节点的某个进程内,而RDD代表的数据集是跨进程、跨节点的,它的“活动范围”是整个集群。
至于数组和RDD的第三个不同,则是在数据定位方面。在数组中,承载数据的基本单元是元素,而RDD中承载数据的基本单元是数据分片。在分布式计算环境中,一份完整的数据集,会按照某种规则切割成多份数据分片。这些数据分片被均匀地分发给集群内不同的
计算节点和执行进程,从而实现分布式并行计算。
通过以上对比,不难发现,数据分片(Partitions)是RDD抽象的重要属性之一。
从RDD的重要属性出发,它有4大属性:
- partitions:数据分片
- partitioner:分片切割规则
- dependencies:RDD依赖
- compute:转换函数
类比薯片的加工流程,与RDD的概念和4大属性是一一对应的:
- 不同的食材形态,如带泥土豆、土豆片、即食薯片等等,对应的就是RDD概念;
- 同一种食材形态在不同流水线上的具体实物,就是 RDD 的 partitions 属性;
- 食材按照什么规则被分配到哪条流水线,对应的就是 RDD 的 partitioner 属性;
- 每一种食材形态都会依赖上一种形态,这种依赖关系对应的是 RDD 中的 dependencies 属性;
- 不同环节的加工方法对应 RDD的 compute 属性。
拿Word Count当中的wordRDD来举例,它的父RDD是lineRDD,因此,它的dependencies属性记录的是lineRDD。
从lineRDD到wordRDD的转换,其所依赖的操作是flatMap,因此,wordRDD的compute属性,记录的是flatMap这个转换函数。
RDD算子的第一个共性:RDD转换。
RDD是Spark对于分布式数据集的抽象,每一个RDD都代表着一种分布式数据形态。比如lineRDD,它表示数据在集群中以行(Line)的形式存在;而wordRDD则意味着数据的形态是单词,分布在计算集群中。
RDD的编程模型和延迟计算。编程模型指导我们如何进行代码实现,而延迟计算是Spark分布式运行机制的基础。
每个属性对应一个方法,
- getPartitions: Array[Partition]、
- compute、
- getDependencies、
- Partitioner、
- getPreferredLocations(每个分区对应一个Task,把Task发送到哪个位置记录下来)

* Internally, each RDD is characterized by five main properties: * 1) - A list of partitions;
RDD数据结构中存在分区列表,用于执行任务时并行计算是分布式计算的重要属性,而且分区之间的数据是没有关联的互不影响。* 2) - A function for computing each split;
Spark在计算时,是使用分区函数对每一个分区进行计算,每个分区中的计算逻辑是一样的,只是数据不一样; * 3) - A list of dependencies on other RDDs;
RDD是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个RDD建立依赖关系。 * 4) - Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned即Hash分区器)
分区器,当数据为KV类型时,可以通过设定分区器自定义数据的分区;只有键值对RDD才有分区器 * 5) - Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file);
(preferred location)优先位置,(每个Task任务发送到离数据最近的位置--节点的Executor上),如果一个节点的Executor由于内存cpu等原因不能执行,
spark会对它有个降级,给同一个节点的另外一个Executor去执行,它如果还是不能执行就去同一个机架上的其他机器上的Executor(跨节点传输数据了),这又是一个降级;
如果同一个机架上的都不行,则给同一个机房的其他机架上发,又是一个降级;
移动数据不如移动计算;
分区并行计算 task
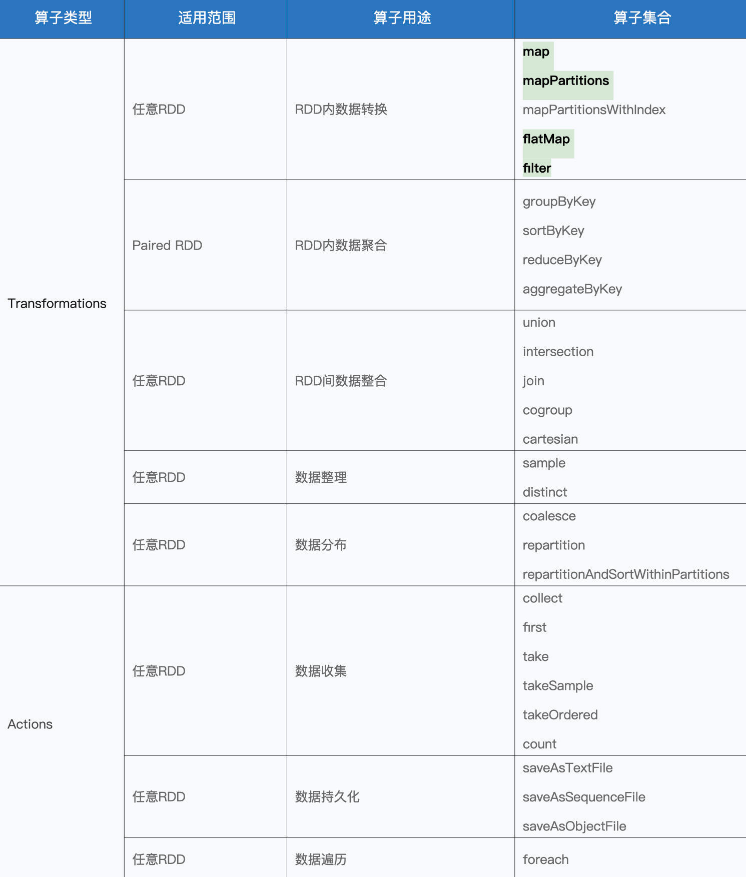
RDD算子分类
2. RDD特点
RDD表示只读的分区的数据集,对RDD进行改动,只能通过RDD的转换操作,由一个RDD得到一个新的RDD,新的RDD包含了从其他RDD衍生所必需的信息。RDDs之间存在依赖,
RDD的执行是按照血缘关系延时计算的。如果血缘关系较长,可以通过持久化RDD来切断血缘关系。
1)弹性
存储的弹性:内存与磁盘的自动切换;(可以基于内存也可以基于磁盘)
容错的弹性:数据丢失可以自动恢复;(RDD记录了数据怎么计算的,数据丢失了可在上一级自动恢复)
计算的弹性:计算出错重试机制;(Executor挂了,Driver可以转移到其他Executor)
分片的弹性:可根据需要重新分片。(总的数据量不变,分区数是可变的)
2)分区
RDD逻辑上是分区的,每个分区的数据是抽象存在的,计算的时候会通过一个compute函数得到每个分区的数据。如果RDD是通过已有的文件系统构建,则compute函数是读取(逻辑)指定文件系统中的数据,如果RDD是通过其他RDD转换而来,则compute函数是执行转换逻辑将其他RDD的数据进行转换。
3)只读
RDD是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创建新的RDD。
由一个RDD转换到另一个RDD,可以通过丰富的操作算子实现,不再像MapReduce那样只能写map和reduce了。
RDD的操作算子包括两类,一类叫做transformations,它是用来将RDD进行转化,构建RDD的血缘关系(懒加载、懒执行,只有遇到action才会真正的执行);另一类叫做actions,它是用来触发RDD的计算,得到RDD的相关计算结果或者将RDD保存的文件系统中。
4)依赖
RDDs通过操作算子进行转换,转换得到的新RDD包含了从其他RDDs衍生所必需的信息,RDDs之间维护着这种血缘关系,也称之为依赖。依赖包括两种,一种是窄依赖,RDDs之间分区是一一对应(从上游RDD看)的,(上游的某一个分区被下游的一个或多个分区所使用);
另一种是宽依赖,下游RDD的每个分区与上游RDD(也称之为父RDD)的每个分区都有关,是多对多的关系。
窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用,窄依赖我们形象的比喻为独生子女;
宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition,会引起shuffle,总结:宽依赖我们形象的比喻为超生
5)缓存
可以缓存到内存也可以缓存到磁盘,缓存没有删除依赖关系;任务执行完之后不管是缓存到内存还是磁盘,它都会被删除掉;
如果在应用程序中多次使用同一个RDD,可以将该RDD缓存起来,该RDD只有在第一次计算的时候会根据血缘关系得到分区的数据,在后续其他地方用到该RDD的时候,会直接从缓存处取而不用再根据血缘关系计算,这样就加速后期的重用。如下图所示,RDD-1经过一系列的转换后得到RDD-n并保存到hdfs,RDD-1在这一过程中会有个中间结果,如果将其缓存到内存,那么在随后的RDD-1转换到RDD-m这一过程中,就不会计算其之前的RDD-0了。
----->R5
R1--->R2--->R3----->R4 ,RDD3缓存到内存计算1次即可,这样子R5、R6从内存掉即可;缓存默认是没开启的,需要调方法;
----->R6
缓存有可能丢失,或者存储存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个
Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。
例如:


scala> val rdd = sc.makeRDD(Array("kris")) scala> val nocache = rdd.map(_.toString + System.currentTimeMillis) scala> nocache.collect res0: Array[String] = Array(kris1554979614968) scala> nocache.collect res1: Array[String] = Array(kris1554979627951) scala> nocache.collect res2: Array[String] = Array(kris1554979629257) scala> val cache = rdd.map(_.toString + System.currentTimeMillis).cache //将RDD转换为携带当前时间戳并做缓存 cache: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at map at <console>:26 scala> cache.collect // 多次打印做了相同的缓存结果 res3: Array[String] = Array(kris1554979702053) scala> cache.collect res4: Array[String] = Array(kris1554979702053)
RDD若缓存到磁盘(或者内存中),当任务跑完结束时,它会把整个缓存的目录都删除掉,以至于缓存不能被其他任务所使用;
6)RDD CheckPoint 检查点机制
缓存到HDFS上,文件一直都在;切断了依赖;
检查点(本质是通过将RDD写入Disk做检查点)是为了通过lineage做容错的辅助,lineage过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从做检查点的RDD开始重做Lineage,就会减少开销。检查点通过将数据写入到HDFS文件系统实现了RDD的检查点功能。
为当前RDD设置检查点。该函数将会创建一个二进制的文件,并存储到checkpoint目录中,该目录是用SparkContext.setCheckpointDir()设置的。在checkpoint的过程中,该RDD的所有依赖于父RDD中的信息将全部被移除。对RDD进行checkpoint操作并不会马上被执行,必须执行Action操作才能触发。同上CheckPoint也需要调用 rdd.checkpoint
虽然RDD的血缘关系天然地可以实现容错,当RDD的某个分区数据失败或丢失,可以通过血缘关系重建。但是对于长时间迭代型应用来说,随着迭代的进行,RDDs之间的血缘关系会越来越长,一旦在后续迭代过程中出错,则需要通过非常长的血缘关系去重建,势必影响性能。为此,RDD支持checkpoint将数据保存到持久化的存储中,这样就可以切断之前的血缘关系,因为checkpoint后的RDD不需要知道它的父RDDs了,它可以从checkpoint处拿到数据。
如果依赖链特别长,可把上游那个存起来缓存起来,直接从缓存里边拿即可,就不会从头开始计算;checkPoint,把依赖给切断,给它缓存起来,下游的RDD对上游也没有依赖,直接从缓存中去取; 而缓存是没有切断依赖的;如果新起一个jar包,CheckPoint是它执行时可直接从缓存(如缓存到了HDFS)中拿, 而缓存(缓存是只有一个jar包中可用,其他任务不可用)还要从头进行计算(它有依赖关系);
sc.setCheckpointDir("./checkPoint") checkpoint是会再启一个进程再计算一次,所以它会计算2次;
一般CheckPoint会和缓存结合使用,这样子CheckPoint就只是计算一次了;
def main(args: Array[String]): Unit = { //初始化sc val conf: SparkConf = new SparkConf().setAppName("WordCount").setMaster("local[*]") val sc = new SparkContext(conf) sc.setLogLevel("ERROR") sc.setCheckpointDir("./checkPoint") val rdd: RDD[Int] = sc.makeRDD(List(1)).map(x => { println("计算一次") x }) rdd.cache() //sCheckpoint和缓存结合使用,就只计算一次 // rdd.persist(StorageLevel.DISK_ONLY) rdd.checkpoint() rdd.collect() rdd.collect() }
CheckPoint和缓存都可以缓存到磁盘上,根本区别是CheckPoint切断了依赖,缓存的方式不管是缓存到内存还是磁盘,任务执行完之后Driver和Executor就会释放,它会把你缓存到磁盘的那个目录文件都删除;而CheckPoint会一直存在磁盘上;
缓存和checkpoint的区别
cache,persist:不会切断血缘关系,可以指定存储级别
checkpoint:切断血缘关系,持久化存储
3. RDD编程
在Spark中,RDD被表示为对象,通过对象上的方法调用来对RDD进行转换。经过一系列的transformations定义RDD之后,就可以调用actions触发RDD的计算,action可以是向应用程
序返回结果(count, collect等),或者是向存储系统保存数据(saveAsTextFile等)。在Spark中,只有遇到action,才会执行RDD的计算(即延迟计算),这样在运行时可以通过管道的方
式传输多个转换。
要使用Spark,开发者需要编写一个Driver程序,它被提交到集群以调度运行Worker。Driver中定义了一个或多个RDD,并调用RDD上的action,Worker则执行RDD分区计算任务。
4. RDD的创建
在Spark中创建RDD的创建方式可以分为三种:
- 从集合中(内存)创建RDD;
- 从外部存储(HDFS、本地磁盘、mysql等)创建RDD;
- 从其他RDD创建(转换算子、action算子)。
1)从集合内存中创建:
从集合中创建RDD,Spark主要提供了两个方法:parallelize和makeRDD,从底层代码实现来讲,makeRDD方法其实就是parallelize方法
/** Distribute a local Scala collection to form an RDD. * This method is identical to `parallelize`. */ def makeRDD[T: ClassTag]( seq: Seq[T], numSlices: Int = defaultParallelism): RDD[T] = withScope { parallelize(seq, numSlices) } def makeRDD[T: ClassTag](seq: Seq[(T, Seq[String])]): RDD[T] = withScope { 可指定位置,发送到哪个分区的task,这种方法一般不用; def parallelize[T: ClassTag]( seq: Seq[T], numSlices: Int = defaultParallelism): RDD[T] = withScope { assertNotStopped() new ParallelCollectionRDD[T](this, seq, numSlices, Map[Int, Seq[String]]()) }
scala> val x = sc.makeRDD(List(1,2,3,4))
x: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:24
scala> x.collect
res0: Array[Int] = Array(1, 2, 3, 4)
scala> val y = sc.parallelize(1 to 5).collect
y: Array[Int] = Array(1, 2, 3, 4, 5)
--------------------------------------------------------------
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val rdd1 = sc.parallelize(
List(1,2,3,4)
)
val rdd2 = sc.makeRDD(
List(1,2,3,4)
)
rdd1.collect().foreach(println)
rdd2.collect().foreach(println)
sc.stop()
查看分区数
scala> x.getNumPartitions res2: Int = 8 scala> x.partitions.size res4: Int = 8
2) 从外部存储(文件)创建 RDD
由外部存储系统的数据集创建RDD包括:本地的文件系统,所有Hadoop支持的数据集,比如HDFS、HBase等。
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val fileRDD: RDD[String] = sc.textFile("input")
fileRDD.collect().foreach(println)
sc.stop()
3) 从其他 RDD 创建
主要是通过一个RDD 运算完后,再产生新的 RDD 。
4) 直接创建 RDD (new), 使用new 的方式直接构造 RDD ,一般由 Spark 框架自身使用。
RDD 并行度与分区
默认情况下,Spark可以将一个作业切分多个任务后,发送给Executor节点并行计算,而能够并行计算的任务数量我们称之为并行度。这个数量可以在构建RDD时指定。
这里的并行执行的任务数量,并不是指的切分任务的数量,不要混淆了。
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val dataRDD: RDD[Int] = sc.makeRDD(
List(1, 2, 3, 4), 4
)
val fileRDD: RDD[String] = sc.textFile("datas", 2)
fileRDD.collect().foreach(println)
sc.stop()
读取内存数据时,数据可以按照并行度的设定进行数据的分区操作,数据分区规则的Spark核心源码如下:
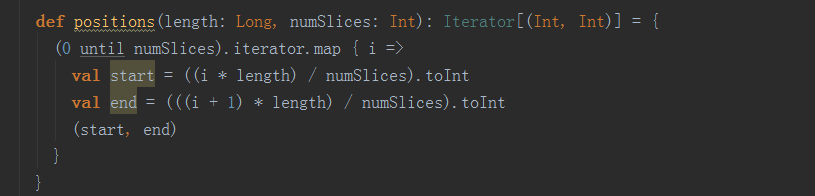
读取文件数据时,数据是按照Hadoop文件读取的规则进行切片分区,而切片规则和数据读取的规则有些差异,具体Spark核心源码如下
public InputSplit[] getSplits(JobConf job, int numSplits)throws IOException {
long totalSize = 0; // compute total size
for (FileStatus file: files) { // check we have valid files
if (file.isDirectory()) {
throw new IOException("Not a file: " + file.getPath());
}
totalSize += file.getLen();
}
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input.
FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize);
...
for (FileStatus file: files) {
...
if (isSplitable(fs, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(goalSize, minSize, blockSize);
...
}
protected long computeSplitSize ( long goalSize, long minSize, long blockSize){
return Math.max(minSize, Math.min(goalSize, blockSize));
}
3.2 默认分区规则:
① 从集合中创建默认分区规则:
在SparkContext中查找makeRDD
local模式分区数默认=核数;集群模式 math.max(totalCoreCount.get(),2)
numSlices: Int = defaultParallelism): RDD[T] = withScope taskScheduler.defaultParallelism def defaultParallelism(): Int ctrl+h 特质--看它的实现类 override def defaultParallelism(): Int = backend.defaultParallelism() def defaultParallelism(): Int 特质 override def defaultParallelism(): Int = scheduler.conf.getInt("spark.default.parallelism", totalCores) alt+<-返回;总核数totalCores 8个 def makeRDD[T: ClassTag]( seq: Seq[T], numSlices: Int = defaultParallelism): RDD[T] = withScope { ##defaultParallelism 8个 parallelize(seq, numSlices) #8个,如果从集合中创建RDD,Local模式的默认分区数是总核数 } CoarseGrainedSchedulerBackend yarn或standalone模式 override def defaultParallelism(): Int = { conf.getInt("spark.default.parallelism", math.max(totalCoreCount.get(), 2)) #总核数与2取最大值 }
② 从文件系统中读默认分区规则:
scala> val z = sc.textFile("./wc.txt") z: org.apache.spark.rdd.RDD[String] = ./wc.txt MapPartitionsRDD[6] at textFile at <console>:24 scala> z.getNumPartitions res6: Int = 2
def textFile( path: String, minPartitions: Int = defaultMinPartitions): RDD[String] = withScope { assertNotStopped() hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text], minPartitions).map(pair => pair._2.toString).setName(path) } def defaultMinPartitions: Int = math.min(defaultParallelism, 2) def defaultParallelism: Int = { assertNotStopped() taskScheduler.defaultParallelism } def defaultParallelism(): Int -->查看它的特质实现类 override def defaultParallelism(): Int = backend.defaultParallelism() def defaultParallelism(): Int -->查看它的特质实现类 override def defaultParallelism(): Int = scheduler.conf.getInt("spark.default.parallelism", totalCores) ##总核数 8 返回:def defaultMinPartitions: Int = math.min(defaultParallelism, 2) ##defaultParallelism为8 textFile中: minPartitions: Int = defaultMinPartitions): RDD[String] = withScope 这个值为2 hadoopFile中用到这个方法 hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text], minPartitions).map(pair => pair._2.toString).setName(path) def hadoopFile[K, V]( path: String, inputFormatClass: Class[_ <: InputFormat[K, V]], keyClass: Class[K], valueClass: Class[V], minPartitions: Int = defaultMinPartitions): RDD[(K, V)] = withScope { assertNotStopped() new HadoopRDD( this, confBroadcast, Some(setInputPathsFunc), inputFormatClass, keyClass, valueClass, minPartitions).setName(path) class HadoopRDD[K, V]( sc: SparkContext, broadcastedConf: Broadcast[SerializableConfiguration], initLocalJobConfFuncOpt: Option[JobConf => Unit], inputFormatClass: Class[_ <: InputFormat[K, V]], keyClass: Class[K], valueClass: Class[V], minPartitions: Int) override def getPartitions: Array[Partition] = { val inputSplits = inputFormat.getSplits(jobConf, minPartitions)} ## getSplits-->InputFormat-->FileInputFormat找getSplits方法 18 long goalSize = totalSize / (long)(numSplits == 0 ? 1 : numSplits); totalSize总大小wc.txt总共36字节,numSplits要传的参数2 1 long minSize = Math.max(job.getLong("mapreduce.input.fileinputformat.split.minsize", 1L), this.minSplitSize); --> private long minSplitSize = 1L; long blockSize = file.getBlockSize(); #块大小,HDFS上128M,windows是32M long splitSize = this.computeSplitSize(goalSize, minSize, blockSize); (18, 1, 128) -->18 return Math.max(minSize, Math.min(goalSize, blockSize)); 18 文件切片机制按1.1倍判断, (double)bytesRemaining / (double)splitSize > 1.1D; bytesRemaining -= splitSize 36/22 > 1.1 -->36-22=14/22 <1.1不切, 最终得到2片切片
5. RDD的转换算子
RDD根据数据处理方式的不同将算子整体上分为Value类型、双Value类型和Key-Value类型
Value类型
1.map(func)
作用:返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成。 f: T => U
将处理的数据逐条进行映射转换,这里的转换可以是类型的转换,也可以是值的转换。
/** * Return a new RDD by applying a function to all elements of this RDD. */ def map[U: ClassTag](f: T => U): RDD[U] = withScope { val cleanF = sc.clean(f) new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF)) }
map:
scala> val x = sc.makeRDD(1 to 4) #sc.parallelize(1 to 4)
x: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[9] at makeRDD at <console>:24
scala> x.map(x=>x.toString).collect
res9: Array[String] = Array(1, 2, 3, 4)
scala> x.map(x=>(x,1)).collect ##.map(_ * 2).collect()所有元素*2
res10: Array[(Int, Int)] = Array((1,1), (2,1), (3,1), (4,1))
scala> x.map((_,1)).collect
res12: Array[(Int, Int)] = Array((1,1), (2,1), (3,1), (4,1))
----------------------------------------------------------------------------------
val fileRdd: RDD[String] = sc.textFile("input")
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
//def func(num:Int): Int = {num * 2}
//scala中匿名函数,只关心逻辑不关心方法名 rdd.map(func) --将声明的函数使用匿名函数代替--> rdd.map((num:Int) => {num * 2})
//scala中的自简原则(能简单则简单,能简化则简化,能省则省) --函数的代码逻辑只有一行时{}可以省略,参数的类型可以自动推断出来类型可以省略,参数列表中的参数只有一个()可以省略,参数在逻辑当中只出现一次而且是按顺序出现的可以用_来代替--->
//rdd.map(_*2)
val mapRdd1: RDD[Int] = rdd.map(
num => {num * 2}
)
val mapRdd2: RDD[String] = mapRdd1.map(
num => {
" " + num
}
)
mapRdd2.collect().foreach(print)
从服务器日志数据apache.log中获取用户请求URL资源路径
// 83.149.9.216 - - 17/05/2015:10:05:03 +0000 GET /presentations/logstash-monitorama-2013/images/kibana-search.png def main(args: Array[String]): Unit = { val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Spark-Transform") val sc: SparkContext = new SparkContext(sparkConf) val rdd: RDD[String] = sc.textFile("datas/apache.log") val mapRdd: RDD[String] = rdd.map( line => { val datas: Array[String] = line.split(" ") datas(6) } ) mapRdd.collect().foreach(println) sc.stop() }
rdd的计算一个分区内的数据是一个一个执行逻辑,只有前面一个数据全部的逻辑执行完毕后,才会执行下一个数据; 分区内数据的执行是有序的。
不同分区之间数据的执行是无序的。
2.mapPartitions(func)
f: Iterator[T] => Iterator[U],
mapPartitions:作用:类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U]。
假设有N个元素,有M个分区,那么map的函数的将被调用N次,而mapPartitions被调用M次,一个函数一次处理所有分区。
将待处理的数据以分区为单位发送到计算节点进行处理,这里的处理是指可以进行任意的处理,哪怕是过滤数据。
/**
* Return a new RDD by applying a function to each partition of this RDD.
* `preservesPartitioning` indicates whether the input function preserves the partitioner, which
* should be `false` unless this is a pair RDD and the input function doesn't modify the keys.
*/
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U] = withScope {
val cleanedF = sc.clean(f)
new MapPartitionsRDD(
this,
(context: TaskContext, index: Int, iter: Iterator[T]) => cleanedF(iter),
preservesPartitioning)
}
scala> val x = sc.makeRDD(1 to 8)
x: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[13] at makeRDD at <console>:24
scala> x.mapPartitions(x=>x.map((_,1))).collect ## x.mapPartitions((x=>x.map(_*2))).collect
res13: Array[(Int, Int)] = Array((1,1), (2,1), (3,1), (4,1), (5,1), (6,1), (7,1), (8,1))
scala> x.map((_, 1)).collect
res14: Array[(Int, Int)] = Array((1,1), (2,1), (3,1), (4,1), (5,1), (6,1), (7,1), (8,1))
scala> x.mapPartition(datas => {datas.filter(_==2)})
-------------------------------------------------------------------------------
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),2)
val mapParRdd: RDD[Int] = rdd.mapPartitions( //传入一个Iterator,输出一个Iterator
iter => {
println("====") //两个分区,它就会打印2次;
iter.map(_*2)
}
)
//mapPartitions可以以分区为单位进行数据转换操作,但是会把整个分区的数据加载到内存进行引用;如果处理完的数据是不会被释放掉的,存在对象的引用
//在数据量大,内存较小的情况下,容易发生内存溢出。
mapParRdd.collect().foreach(print)
sc.stop
输出:
====
====
2
4
6
8
小功能:获取每个数据分区的最大值
def main(args: Array[String]): Unit = { val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Spark-Transform") val sc: SparkContext = new SparkContext(sparkConf) val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4), 2) //分区一: 1 2 分区二: 3 4 val mappRdd: RDD[Int] = rdd.mapPartitions( iter => { List(iter.max).iterator //需要返回一个迭代器 } ) mappRdd.collect().foreach(println) sc.stop() }
需求:把Word Count的计数需求,从原来的对单词计数,改为对单词的哈希值计数;
map算子的实现: import java.security.MessageDigest val cleanWordRDD: RDD[String] = sc.textFile("./wd.txt").flatMap(line => line.split(" ")) val kvRDD: RDD[(String, Int)] = cleanWordRDD.map{ word => // 获取MD5对象实例 val md5 = MessageDigest.getInstance("MD5") // 使用MD5计算哈希值 val hash = md5.digest(word.getBytes).mkString // 返回哈希值与数字1的Pair (hash, 1) } mapPartitions 算子的实现: import java.security.MessageDigest val cleanWordRDD:RDD[String] = sc.textFile("./wd.txt").flatMap(line => line.split(" ")) val kvRDD: RDD[(String, Int)] = cleanWordRDD.mapPartitions( partition => { // 注意!这里是以数据分区为粒度,获取MD5对象实例 val md5 = MessageDigest.getInstance("MD5") val newPartition = partition.map( word => { // 在处理每一条数据记录的时候,可以复用同一个Partition内的MD5对象 (md5.digest(word.getBytes()).mkString,1) }) newPartition }) scala> cleanWordRDD.collect res7: Array[String] = Array(Spark, is, Cool, What, is, spark) kvRDD.collect res1: Array[(String, Int)] = Array((-116-34119771111155111746-4144-84-35-808138,1), (-94-9181-9069-118-115-303670-52118-4257-87-23,1), (34-703-100119-56-82-17-66-99-1063118510-50,1), (1868511121150117878-34-110120-102-99-125-17,1), (-94-9181-9069-118-115-303670-52118-4257-87-23,1), (-104-1527122120-12822-10059-4242908012357101,1))
mapPartitions,以数据分区为粒度,使用映射函数f对RDD进行数据转换;
mapPartitions以数据分区(匿名函数的形参partition)为粒度,对RDD进行数据转换。具体的数据处理逻辑,则由代表数据分区的形参partition进一步调用map(f)来完成。
partition. map(f)仍然是以元素为粒度做映射,把实例化MD5对象的语句挪到了map算子之外,以数据分区为单位,实例化对象的操作只需要执行一次,而同一个数据分区中所有的数据记录,都可以共享该MD5对象,从而完成单词到哈希值的转换。
以数据分区为单位,mapPartitions只需实例化一次MD5对象,而map算子却需要实例化多次,具体的次数则由分区内数据记录的数量来决定。
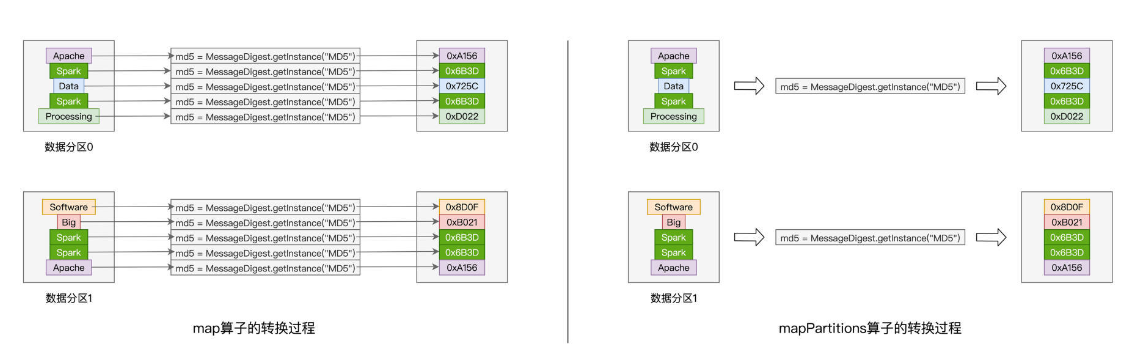
对于一个有着上百万条记录的RDD来说,其数据分区的划分往往是在百这个量级,因此,相比map算子,mapPartitions可以显著降低对象实例化的计算开销,这对于Spark作业端到端的执行性能来说,无疑是非常友好的。
除了计算哈希值以外,对于数据记录来说,凡是可以共享的操作,都可以用mapPartitions算子进行优化。比如创建用于连接远端数据库的Connections对象,或是用于连接Amazon S3的文件系统句柄,再比如用于在线推理的机器学习模型;
相比mapPartitions,mapPartitionsWithIndex仅仅多出了一个数据分区索引,这个数据分区索引可以为我们获取分区编号,当你的业务逻辑中需要使用到分区编号的时候,不妨考虑使用这个算子来实现代码。
除了这个额外的分区索引以外,mapPartitionsWithIndex在其他方面与mapPartitions是完全一样的。
map 和 mapPartitions 的区别?
- ① 传入函数执行次数不同;
- ② 效率不一样,map执行完一条内存就释放而mapPartition是一个分区的处理完内存也不释放
➢ 数据处理角度
Map 算子是分区内一个数据一个数据的执行(每次处理一条数据,处理完一条内存就释放了 ),类似于串行操作。
而 mapPartitions 是以分区为单位进行批处理(每次处理一个分区的数据,相当于批处理,一个分区数据批处理完它的内存不会释放,分区的数据处理完后,原RDD中分区的数据才释放,可能导致OOM)。
➢ 功能的角度
Map 算子主要目的将数据源中的数据进行转换和改变。但是不会减少或增多数据。 MapPartitions 算子需要传递一个迭代器,返回一个迭代器,没有要求的元素的个数保持不变, 所以可以增加或减少数据
➢ 性能的角度
Map 算子因为类似于串行操作,所以性能比较低,而是 mapPartitions 算子类似于批处 理,所以性能较高。但是 mapPartitions 算子会长时间占用内存,那么这样会导致内存可能不够用,出现内存溢出的错误。所以在内存有限的情况下,不推荐使用。使用 map 操作。
完成比完美更重要。
3. mapPartitionsWithIndex(func)
作用:类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是 (Int, Interator[T]) => Iterator[U];
将待处理的数据以分区为单位发送到计算节点进行处理,这里的处理是指可以进行任意的处理,哪怕是过滤数据,在处理时同时可以获取当前分区索引。
/** * Return a new RDD by applying a function to each partition of this RDD, while tracking the index * of the original partition. * `preservesPartitioning` indicates whether the input function preserves the partitioner, which * should be `false` unless this is a pair RDD and the input function doesn't modify the keys. */ def mapPartitionsWithIndex[U: ClassTag]( f: (Int, Iterator[T]) => Iterator[U], ##int分区号(从0开始的),分区数据---->转换为U类型 preservesPartitioning: Boolean = false): RDD[U] = withScope { val cleanedF = sc.clean(f) new MapPartitionsRDD( this, (context: TaskContext, index: Int, iter: Iterator[T]) => cleanedF(index, iter), preservesPartitioning) }
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
val rddPartWithInd: RDD[(Int, Int)] = rdd.mapPartitionsWithIndex(
(index, datas) => datas.map((index, _))
)
小功能:1)获取第二个数据分区的数据; 2)查看每个数据所在的分区:
def main(args: Array[String]): Unit = { val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Spark-Transform") val sc: SparkContext = new SparkContext(sparkConf) val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4), 2) //分区一: 1 2 分区二: 3 4 需求,判断下分区编号,如果是1号分区就要, 其他不要 val mapiRdd: RDD[Int] = rdd.mapPartitionsWithIndex( (index, iter) => { //它拿到的是分区index, 和这个分内的所有数据; 返回值是一个迭代器 if (index == 1) { iter } else { Nil.iterator //Nil是空集合 } } ) mapiRdd.collect().foreach(println) sc.stop() }
def main(args: Array[String]): Unit = { val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Spark-Transform") val sc: SparkContext = new SparkContext(sparkConf) val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4)) //查看每个数据所在的分区 //(1,1) (3,2) (5,3) (7,4) val mpiRdd: RDD[(Int, Int)] = rdd.mapPartitionsWithIndex( (index, iter) => { iter.map( num => { (index, num) } ) } ) mpiRdd.collect().foreach(println) sc.stop() }
4.flatMap(func)
整体拆成一个个的个体,打散
作用:类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素) (f: T => TraversableOnce[U])
/** * Return a new RDD by first applying a function to all elements of this * RDD, and then flattening the results. */ def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] = withScope { ##函数返回的必须是可迭代的 val cleanF = sc.clean(f) new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.flatMap(cleanF)) }
scala> x.map(x=>x).collect
scala> x.flatMap(x=>x).collect
found : Int
required: TraversableOnce[?] ##需要可迭代的
scala> x.flatMap(x=>x.toString).collect
scala> val x = sc.makeRDD(List(Array(1,2,3,4), Array(5,6,7))) x.flatMap(x=>x).collect
Array[Int] = Array(1, 2, 3, 4, 5, 6, 7)
========================================
val rdd: RDD[List[Int]] = sc.makeRDD(List(List(1, 2), List(3, 4)))
val rddFlatmap: RDD[Int] = rdd.flatMap(
x => x
)
val rdd: RDD[List[Int]] = sc.makeRDD(List(List(1,2), List(3,4)))
val flatRdd: RDD[Int] = rdd.flatMap( //把一个整体拆成一个个的个体, 但是给它返回还是要返回一个整体来封装下
list => list //前一个list是数据的原数 RDD[List[Int]] , 后一个list是用来作封装的 RDD[Int]
)
输出:
1 2 3 4
val rdd: RDD[String] = sc.makeRDD(List("Hello Scala", "Hello World"))
val flatRdd: RDD[String] = rdd.flatMap(
s => { //把字符串s拆成一个一个的单词
s.split(" ") //它返回的结果是一个可迭代的集合, 只要是一个可迭代的集合就是满足要求的
} //发现经过flatMap处理之后的数据类型都是RDD[String], 都是表示一个字符串, 前者是一个完整的字符串, 后者是一个个的单词了
)
输出:
Hello Scala Hello World
小功能:将List(List(1,2), 3, List(4,5))进行扁平化操作
def main(args: Array[String]): Unit = { val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Spark-Transform") val sc: SparkContext = new SparkContext(sparkConf) val rdd: RDD[Any] = sc.makeRDD(List(List(1,2), 3, List(4,5))) val flatRdd: RDD[Any] = rdd.flatMap( data => { //数据中的类型不一致了, 需要用模式匹配 data match { case list: List[_] => list //如果是集合的类型就返回集合 case dat => List(dat) //不是集合, 就给它包装成一个集合传进去 } } ) flatRdd.collect().foreach(println) sc.stop() } 输出: 1 2 3 4 5
需求: 改变Word Count的计算逻辑,由原来统计单词的计数,改为统计相邻单词共现的次数
flatMap:从元素到集合、再从集合到元素
flatMap其实和map与mapPartitions算子类似,在功能上,与map和mapPartitions一样,flatMap也是用来做数据映射的,在实现上,对于给定映射函数f,flatMap(f)以元素为粒度,对RDD进行数据转换。
与前两者相比,flatMap的映射函数f有着显著的不同。对于map和mapPartitions来说,其映射函数f的类型,都是(元素)=>(元素),即元素到元素。
而flatMap映射函数f的类型,是(元素)=>(集合),即元素到集合(如数组、列表等)。因此,flatMap的映射过程在逻辑上分为两步:
以元素为单位,创建集合;
去掉集合“外包装”,提取集合元素。
scala> val lineRdd: RDD[String] = sc.textFile("./wd.txt") lineRdd: org.apache.spark.rdd.RDD[String] = ./wd.txt MapPartitionsRDD[1] at textFile at <console>:24 scala> scala> val wordPairRDD:RDD[String] = lineRdd.flatMap( line => { | // 将行转换为单词数组 | val words: Array[String] = line.split(" ") | // 将单个单词数组,转换为相邻单词数组 | for (i <- 0 until words.length - 1) yield words(i) + "-" + words(i+1) | }) wordPairRDD: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at flatMap at <console>:24 scala> wordPairRDD.collect res0: Array[String] = Array(Spark-is, is-Cool, What-is, is-spark)
采用匿名函数的形式,来提供映射函数f。这里f的形参是String类型的line,也就是源文件中的一行文本,而f的返回类型是Array[String],也就是String类型的数组。在映射函数f的函数体中,我们先用split语句把line转化为单词数组,然后再用for循环结合yield语
句,依次把单个的单词,转化为相邻单词词对。
注意,for循环返回的依然是数组,也即类型为Array[String]的词对数组。由此可见,函数f的类型是(String) => (Array[String]),即从元素到集合。但我们去观察转换前后的两个RDD,也就是lineRDD和wordPairRDD,会发现它们的类型都是RDD[String],换句
话说,它们的元素类型都是String。
回顾map与mapPartitions这两个算子,我们会发现,转换前后RDD的元素类型,与映射函数f的类型是一致的。但在flatMap这里,却出现了RDD元素类型与函数类型不一致的情况。
其实呢,这正是flatMap的“奥妙”所在:
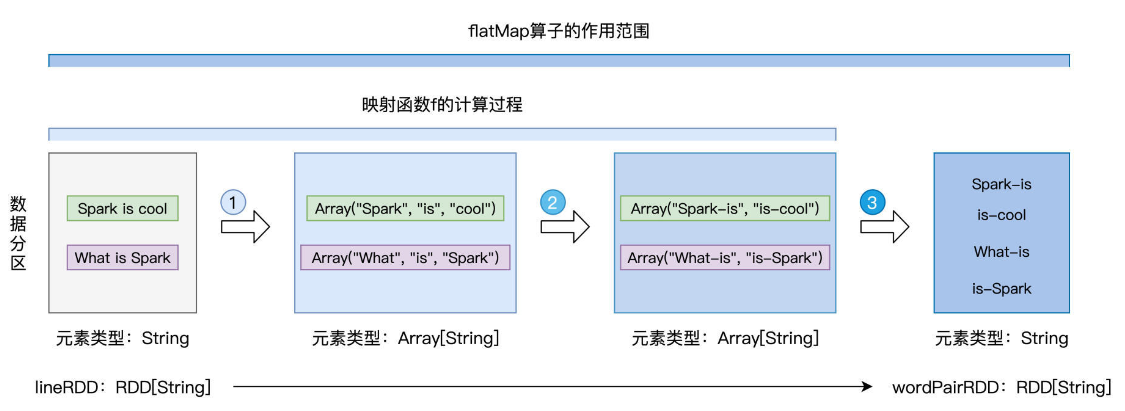
映射函数f的计算过程,对应着图中的步骤1与步骤2,每行文本都被转化为包含相邻词对的数组。紧接着,flatMap去掉每个数组的“外包装”,提取出数组中类型为String的词对元素,然后以词对为单位,构建新的数据分区,如图中步骤3所示。这就是flatMap映射
过程的第二步:去掉集合“外包装”,提取集合元素。
得到包含词对元素的wordPairRDD
5.glom
实际开发中用的并不是很多
作用:将每一个分区形成一个数组,形成新的RDD类型时RDD[Array[T]]
将同一个分区的数据直接转换为相同类型的内存数组进行处理,分区不变
/** * Return an RDD created by coalescing all elements within each partition into an array. */ def glom(): RDD[Array[T]] = withScope { new MapPartitionsRDD[Array[T], T](this, (context, pid, iter) => Iterator(iter.toArray)) }
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4), 2)
//List => Int flatMap
//Int => List glom
val glomRdd: RDD[Array[Int]] = rdd.glom()
glomRdd.collect().foreach(data => println(data.mkString(",")))
输出:
1,2 3,4
小功能:计算所有分区最大值求和(分区内取最大值,分区间最大值求和)
def main(args: Array[String]): Unit = { val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Spark-Transform") val sc: SparkContext = new SparkContext(sparkConf) val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4), 2) //1,2 3,4 // 2 + 4 val glomRDD: RDD[Array[Int]] = rdd.glom() val glomMapRdd: RDD[Int] = glomRDD.map( array => { array.max } ) println(glomMapRdd.collect.sum) sc.stop() }
6. groupBy(func)
作用:分组,按照传入函数的返回值进行分组。将相同的key对应的值放入一个迭代器。 (f: T => K, p: Partitioner)
将数据根据指定的规则进行分组, 分区默认不变,但是数据会被打乱重新组合,我们将这样的操作称之为 shuffle。
极限情况下,数据可能被分在同一个分区中 一个组的数据在一个分区中,但是并不是说一个分区中只有一个组。
scala> val x = sc.makeRDD(1 to 5)
x: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[26] at makeRDD at <console>:24
scala> x.groupBy(_%2).collect
res23: Array[(Int, Iterable[Int])] = Array((0,CompactBuffer(2, 4)), (1,CompactBuffer(1, 3, 5)))
scala> x.groupBy(x => x>1).collect
res24: Array[(Boolean, Iterable[Int])] = Array((false,CompactBuffer(1)), (true,CompactBuffer(2, 3, 4, 5)))
CompactBuffer
* An append-only buffer similar to ArrayBuffer, but more memory-efficient for small buffers.
private[spark] class CompactBuffer[T: ClassTag] extends Seq[T] with Serializable { }
指定在spark包下使用,似有的
----------------------------------------------
val groupByRDD: RDD[(Int, Iterable[Int])] = rdd.groupBy(_%2)
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4), 2)
//groupBy会将数据源中的每一个数据进行分组判断, 根据返回的分组key进行分组
//相同key值的数据会放置在一个组内
def groupFunction(num: Int): Int = {
num % 2
}
val groupByRdd: RDD[(Int, Iterable[Int])] = rdd.groupBy(groupFunction)
groupByRdd.collect.foreach(println)
输出:
(0,CompactBuffer(2, 4))
(1,CompactBuffer(1, 3))
val rdd: RDD[String] = sc.makeRDD(List("Hello", "Spark", "Scala", "Hadoop"), 2)
//分组和分区没有必然的联系
val groupByRdd: RDD[(Char, Iterable[String])] = rdd.groupBy(_.charAt(0)) //以首字符进行分组
groupByRdd.collect.foreach(println)
输出:
(H,CompactBuffer(Hello, Hadoop))
(S,CompactBuffer(Spark, Scala))
小功能:从服务器日志数据apache.log中获取每个时间段访问量。
def main(args: Array[String]): Unit = { val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Spark-Transform") val sc: SparkContext = new SparkContext(sparkConf) val rdd: RDD[String] = sc.textFile("datas/apache.log") val timeRddGroupByRdd: RDD[(String, Iterable[(String, Int)])] = rdd.map( //RDD[(String, Iterable[(String, Int)])] 返回的是相同时间内所形成的集合 line => { val datas: Array[String] = line.split(" ") val time: String = datas(3) //time.substring(0,) val sdf: SimpleDateFormat = new SimpleDateFormat("dd/MM/yyyy:HH:mm:ss") val date: Date = sdf.parse(time) val sdf1: SimpleDateFormat = new SimpleDateFormat("HH") val hour: String = sdf1.format(date) (hour, 1) } ).groupBy(_._1) //我们需要的不是它的迭代器, 而是它的数量; 用模式匹配 timeRddGroupByRdd.map{ case (hour, iter) => { (hour, iter.size) } }.collect.foreach(println) sc.stop() } 输出: (06,366) (20,486) (19,493) (15,496) (00,361)
7. filter(func)
作用:过滤。返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成。 (f: T => Boolean)
将数据根据指定的规则进行筛选过滤,符合规则的数据保留,不符合规则的数据丢弃。当数据进行筛选过滤后,分区不变,但是分区内的数据可能不均衡,生产环境下,可能会出现数
据倾斜。(比如0号分区,过滤剩下1w条,1号分区过滤剩下100条)
/** * Return a new RDD containing only the elements that satisfy a predicate. */ def filter(f: T => Boolean): RDD[T] = withScope { val cleanF = sc.clean(f) new MapPartitionsRDD[T, T]( this, (context, pid, iter) => iter.filter(cleanF), preservesPartitioning = true) }
scala> val x = sc.makeRDD(List("Hello Kris", "baidu", "jd")) x: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[37] at makeRDD at <console>:24 scala> x.filter(x => x.contains("Kris")).collect Array[String] = Array(Hello Kris) scala> val x = sc.makeRDD(1 to 4) x: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[39] at makeRDD at <console>:24 scala> x.filter(x => x>1).collect ## x.filter(x=>x%2).collect 这样子写就不可以了,它的返回值不是Boolean类型 res29: Array[Int] = Array(2, 3, 4)
-------------------------------------------------
val filterRDD: RDD[Int] = rdd.filter(_%2==0)
rdd.filter(num => num%2 != 0)
❖ 小功能:从服务器日志数据apache.log中获取2015年5月17日的请求路径
def main(args: Array[String]): Unit = { val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Spark-Transform") val sc: SparkContext = new SparkContext(sparkConf) val rdd: RDD[String] = sc.textFile("datas/apache.log") val filterRdd: RDD[String] = rdd.filter( line => { val datas: Array[String] = line.split(" ") val times: String = datas(3) times.startsWith("17/05/2015") } ) filterRdd.collect.foreach(println) sc.stop() }
8. sample
(withReplacement, fraction, seed)
放回和不放回抽样
作用:以指定的随机种子随机抽样出数量为fraction的数据,withReplacement表示是抽出的数据是否放回,true为有放回的抽样,false为无放回的抽样,seed用于指定随机数生成器种子。 不放回的抽样,每个元素被抽中的概率[0,1]; 有放回的抽样,每个元素抽中的次数 >=0
源码如下
/** * Return a sampled subset of this RDD. * * @param withReplacement can elements be sampled multiple times (replaced when sampled out) * @param fraction expected size of the sample as a fraction of this RDD's size * without replacement: probability that each element is chosen; fraction must be [0, 1] * with replacement: expected number of times each element is chosen; fraction must be greater * than or equal to 0 * @param seed seed for the random number generator * * @note This is NOT guaranteed to provide exactly the fraction of the count * of the given [[RDD]]. */ def sample( withReplacement: Boolean, fraction: Double, seed: Long = Utils.random.nextLong): RDD[T] = { #它如果是固定的,产生的随机数也是固定的 require(fraction >= 0, s"Fraction must be nonnegative, but got ${fraction}") withScope { require(fraction >= 0.0, "Negative fraction value: " + fraction) if (withReplacement) { new PartitionwiseSampledRDD[T, T](this, new PoissonSampler[T](fraction), true, seed) } else { new PartitionwiseSampledRDD[T, T](this, new BernoulliSampler[T](fraction), true, seed) } } }
根据指定的规则从数据集中抽取数据抽取数据不放回: false(伯努利算法); 伯努利算法:又叫 0、1 分布。例如扔硬币,要么正面,要么反面。
具体实现:根据种子和随机算法算出一个数和第二个参数设置几率比较,小于第二个参数要,大于不要
第一个参数:抽取的数据是否放回,false:不放回
第二个参数:抽取的几率,范围在[0,1]之间,0:全不取;1:全取;
第三个参数:随机数种子
抽取数据放回:true(泊松算法)
第一个参数:抽取的数据是否放回,true:放回;false:不放回
第二个参数:重复数据的几率,范围大于等于 0.表示每一个元素被期望抽取到的次数
第三个参数:随机数种子
val rdd: RDD[Int] = sc.makeRDD(1 to 10)
// sample算子需要传递三个参数:
// 第一个参数表示, 抽取数据后是否将数据返回true(放回), false(丢弃)
// 第二个参数表示,
// 如果抽取不放回的场合:数据源中每条数据被抽取的概率
// 如果抽取放回的场合: 表示数据源中的每条数据被抽取的可能次数
// 基准值的概念
// 第三个参数表示, 抽取数据时随机算法种子
// 如果不传递第三个参数, 那么使用的是当前系统时间
println(rdd.sample(false,0.4, 1).collect().mkString(","))
println(rdd.sample(true,2, 1).collect().mkString(",")) //2表示每条数据可能被抽取2次
输出:
1,2,6,10
1,1,1,1,2,3,3,3,3,3,4,4,5,5,6,6,6,6,7,7,9,9,10
分区数据是均衡的, shuffle会打乱重新组合,可能就会产生数据倾斜; 哪个分区的数据导致的倾斜的呢?从分区中抽取数据, 就用到sample了。
9. distinct([numTasks]))
作用:对源RDD进行去重后返回一个新的RDD。
scala> val x = sc.makeRDD(List(1,2,1,1,2,1))
scala> x.distinct().collect
res49: Array[Int] = Array(1, 2)
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4,1,2,3,4))
val disRdd: RDD[Int] = rdd.distinct()
disRdd.collect.foreach(println)
//List(1,2,3,4,1,2,3,4).distinct //scala中的去重是用的HashSet
//spark中的distinct的原理是:
//map(x => (x, null)).reduceByKey((x, _) => x, numPartitions).map(_._1)
//(1, null), (2, null), (3, null), (4, null), (1, null), (2, null), (3, null), (4, null)
//(1, null) (1, null) --reduceBykey 相同的key分组, value做聚合
//(null, null) => null --两个null做聚合
//(1, null) => 1 --再做map操作
10. coalesce(numPartitions)
作用: 根据数据量缩减分区,用于大数据集过滤后,提高小数据集的执行效率。
当spark程序中,存在过多的小任务时,可以通过 coalesce 方法,收缩合并分区,减少分区的个数,减小任务调度成本。缩减分区,默认为false 不产生shuffle(可能导致数据不均衡),true是产生shuffle。
def coalesce(numPartitions: Int, shuffle: Boolean = false, #shuffle是打乱重组
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
不产生shuffle想把它的分区数变多是不可以的,变少是可以的; 合并为一个分区不需要打乱重组,而拆分必须打乱重组
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4,5,6), 3)
//coalesce方法默认情况下不会将分区的数据打乱重新组合
//这种情况下的缩减分区可能会导致数据不均衡,出现数据倾斜
//如果想要让数据均衡,可以进行shuffle处理
//val repRdd: RDD[Int] = rdd.coalesce(2) //缩减分区, 不产生shuffle, 则1 2 3 4 5 6
val repRdd2: RDD[Int] = rdd.coalesce(2, true) //缩减分区, 产生shuffle 则1 4 5 2 3 6
repRdd2.saveAsTextFile("output")
11.repartition(numPartitions)
改变分区数,肯定会产生shufle
作用:根据分区数,重新通过网络随机洗牌所有数据。
该操作内部其实执行的是 coalesce 操作,参数 shuffle 的默认值为 true。无论是将分区数多的 RDD 转换为分区数少的 RDD,还是将分区数少的 RDD 转换为分区数多的 RDD,repartition 操作都可以完成,因为
无论如何都会经 shuffle 过程。
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
scala> x.repartition(10).getNumPartitions
res58: Int = 10
----------------------------------------------
coalesce算子可以扩大分区的,但是如果不进行shuffle操作,是没有意义的,不起作用
所以如果想要实现扩大分区的效果,需要使用shuffle操作
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4,5,6), 2)
//spark提供了一个简化操作:
//缩减分区: coalesce,如果想要数据均衡, 可以采用shuffle
//扩大分区: repartition, 它的底层就是coalesce(3, true)
//val repRdd2: RDD[Int] = rdd.coalesce(3, true) //3 5 1 6 2 4
val repRdd2: RDD[Int] = rdd.repartition(3) //3 5 1 6 2 4
repRdd2.saveAsTextFile("output")
coalesce与repartition两个算子的作用以及区别与联系。(①都可改变rdd分区数;②repartition是coalesce的一种特殊情况,肯定产生shuffle)
1. coalesce重新分区,可以选择是否进行shuffle过程。由参数shuffle: Boolean = false/true决定。
2. repartition实际上是调用的coalesce,进行shuffle。
12. sortBy(func,[ascending], [numTasks])
作用;使用func先对数据进行处理,按照处理后的数据比较结果排序,默认为正序。
在排序之前,可以将数据通过 f 函数进行处理,之后按照 f 函数处理的结果进行排序,默认为升序排列。
排序后新产生的 RDD 的分区数与原 RDD 的分区数一 致。中间存在 shuffle 的过程
/** * Return this RDD sorted by the given key function. */ def sortBy[K]( f: (T) => K, ascending: Boolean = true, numPartitions: Int = this.partitions.length) (implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T] = withScope { this.keyBy[K](f) .sortByKey(ascending, numPartitions) .values }
//val rdd: RDD[Int] = sc.makeRDD(List(1,3,5,2,6,4), 2)
//val sortRdd: RDD[Int] = rdd.sortBy(num => num)// 1 2 3 4 5 6
// rdd.sortBy(x => x%2)
//sortBy方法可以根据指定的规则对数据源中的数据进行排序,默认为升序,第二个参数可以改变排序的方式
//sortBy默认情况下,不会改变分区, 但是中间存在shuffle操作
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("1", 1),("11", 2), ("2", 3)))
val sortRdd: RDD[(String, Int)] = rdd.sortBy(t => t._1 , false)
sortRdd.collect.foreach(println)
13. pipe(command, [envVars])
作用:管道,针对每个分区,都执行一个shell脚本,返回输出的RDD。
注意:脚本需要放在Worker节点可以访问到的位置
/** * Return an RDD created by piping elements to a forked external process. */ def pipe(command: String): RDD[String] = withScope { // Similar to Runtime.exec(), if we are given a single string, split it into words // using a standard StringTokenizer (i.e. by spaces) pipe(PipedRDD.tokenize(command)) }
[kris@hadoop101 spark-local]$ vim pipe.sh
#!/bin/bash
echo "AA"
while read LINE; do
echo ">>>"${LINE}
done
## while是默认读取整行,for是默认以空格切割
scala> val x = sc.makeRDD(1 to 4, 1)
x: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[90] at makeRDD at <console>:24
scala> x.collect
res63: Array[Int] = Array(1, 2, 3, 4)
scala> x.pipe("./pipe.sh").collect
res65: Array[String] = Array(AA, >>>1, >>>2, >>>3, >>>4)
scala> val x = sc.makeRDD(1 to 4, 3)
x: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[92] at makeRDD at <console>:24
scala> x.pipe("./pipe.sh").collect
res66: Array[String] = Array(AA, >>>1, AA, >>>2, AA, >>>3, >>>4) ##在每个分区前都会打印AA
scala> x.pipe("./pipe.sh").getNumPartitions
res45: Int = 8
scala> x.pipe("./pipe.sh").collect
res46: Array[String] = Array(AA, AA, >>>1, AA, AA, >>>2, AA, AA, >>>3, AA, AA, >>>4)
双Value类型交互
intersection、union、subtract、zip、cartesian
双value即两个数据源之间的操作。
val rdd1: RDD[Int] = sc.makeRDD(List(1,2,3,4))
val rdd2: RDD[Int] = sc.makeRDD(List(3,4,5,6))
//交集、并集和差集 要求两个数据源数据类型保持一致
//拉链操作两个数据源可以不一致
//intersection 交集 3,4
val interRdd: RDD[Int] = rdd1.intersection(rdd2)
println(interRdd.collect().mkString(","))
//union 并集 1,2,3,4,3,4,5,6 ,union没有shuffle,直接把结果拿来做并集,不会去重(区别于sql中的union,sql中的union可去重)
val unionRdd: RDD[Int] = rdd1.union(rdd2)
println(unionRdd.collect().mkString(","))
//subtract 差集 1,2 ,去重两个RDD中相同的元素,不同的RDD将留下来
val subtraRdd: RDD[Int] = rdd1.subtract(rdd2)
println(subtraRdd.collect().mkString(","))
//zip 拉链 (1,a),(2,b),(3,5),(4,6) 将两个RDD组成key/ value形式的RDD
// Can't zip RDDs with unequal numbers of partitions: List(3, 2)
//两个数据源要求分区数量要保持一致
// Can only zip RDDs with same number of elements in each partition
//两个数据源要求分区中数据量保持一致
val rdd3: RDD[Int] = sc.makeRDD(List(1,2,3,4),2)
val rdd4: RDD[Any] = sc.makeRDD(List("a","b",5,6),2)
val zipRdd: RDD[(Int, Any)] = rdd3.zip(rdd4)
println(zipRdd.collect().mkString(","))
rdd1.cartesian(rdd2) //笛卡尔积
Key-Value类型
键值对RDD,只有kv键值对RDD才有分区器这个概念
1 partitionBy (partitioner: Partitioner)
伴生对象里边的方法 rddToPairRDDFunctions,它会把 RDD =变成=> PairRDDFunctions ,有关键词implicit,称为隐式函数,它可以将一个类型变成另外一种类型来调用它的方法。
这种方式遵循OCP开发原则。
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4), 2)
val mapRdd: RDD[(Int, Int)] = rdd.map((_, 1)) //将Int类型转成K, V类型 就可以使用partitionBy这个方法
//partitionBy由PairRDDFunctions提供, RDD => PairRDDFunctions使用的是 隐式转换 (二次编译)
//partitionBy根据指定的分区规则对数据进行重分区(把数据改变所在的位置), coalesce和repartition改变的是分区的数量;
val parByRdd: RDD[(Int, Int)] = mapRdd.partitionBy(new HashPartitioner(2))
parByRdd.saveAsTextFile("output")

如果重分区的分区器和当前RDD的分区器一样怎么办?
val parByRdd: RDD[(Int, Int)] = mapRdd.partitionBy(new HashPartitioner(2))
parByRdd.partitionBy(new HashPartitioner(2))
它会判断传入的分区器和它自己的分区器是否相同 equals,看是否都是HashPartitioner,然后再看分区数量numPartitions是否相等;
(如果是相同分区器、相同分区数量,它上面都不会做,直接返回self,不会产生新的RDD)
Spark其他分区器:
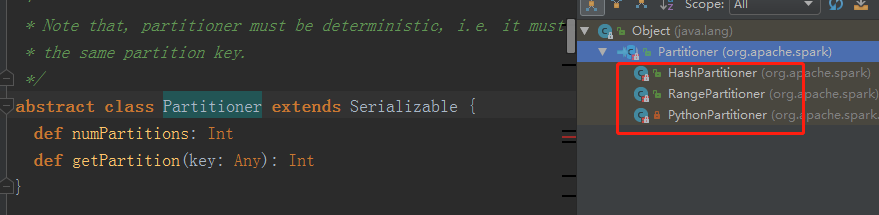
如果想按照自己的方法进行数据分区需要 自定义一个分区器
必须是key,value类型的才有分区器, 并不是一创建就会有默认分区器 HashPartitioner
scala> val x = sc.textFile("./wc.txt").flatMap(_.split(" ")).map((_,1))
x: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[130] at map at <console>:24
scala> x.partitioner
res91: Option[org.apache.spark.Partitioner] = None
scala> val x = sc.textFile("./wc.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_) ##这样才会产生默认分区器
x: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[135] at reduceByKey at <console>:24
scala> x.partitioner
res92: Option[org.apache.spark.Partitioner] = Some(org.apache.spark.HashPartitioner@2)
分区器有HashPartitioner、RangePartitioner
abstract class Partitioner extends Serializable
class HashPartitioner(partitions: Int) extends Partitioner
作用:对pairRDD进行分区操作,如果原有的partionRDD和现有的partionRDD是一致的话就不进行分区, 否则会生成ShuffleRDD,即会产生shuffle过程。
源码:
/**
* Return a copy of the RDD partitioned using the specified partitioner.
*/
def partitionBy(partitioner: Partitioner): RDD[(K, V)] = self.withScope {
if (keyClass.isArray && partitioner.isInstanceOf[HashPartitioner]) {
throw new SparkException("HashPartitioner cannot partition array keys.")
}
if (self.partitioner == Some(partitioner)) {
self
} else {
new ShuffledRDD[K, V, V](self, partitioner)
}
}
scala> x.partitioner
res92: Option[org.apache.spark.Partitioner] = Some(org.apache.spark.HashPartitioner@2)
scala>
scala> x.getNumPartitions
res93: Int = 2
scala> val y = x.partitionBy(new org.apache.spark.HashPartitioner(4)) ##如果要改变RDD的分区数或分区器,都可以直接调用partitionBy; 重写分区;
y: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[136] at partitionBy at <console>:26
scala> y.getNumPartitions
res96: Int = 4
如果原有的partionRDD和现有的partionRDD是一致的话就不进行分区, 否则会生成ShuffleRDD,即会产生shuffle过程。
我们传进去的分区器是自己的分区器就不会产生shuffle
scala> y.partitionBy(y.partitioner)
<console>:29: error: type mismatch;
found : Option[org.apache.spark.Partitioner]
required: org.apache.spark.Partitioner
y.partitionBy(y.partitioner)
^
scala> y.partitionBy(y.partitioner.get)
res98: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[136] at partitionBy at <console>:26
scala> res98.partitioner
res99: Option[org.apache.spark.Partitioner] = Some(org.apache.spark.HashPartitioner@4)
scala> res98.getNumPartitions
res100: Int = 4
scala> y.partitionBy(y.partitioner.get)
res101: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[136] at partitionBy at <console>:26
scala> y.partitionBy(y.partitioner.get).collect
res102: Array[(String, Int)] = Array(("",1), (spark,1), (Hello,3), (World,1), (java,1))
scala> y.partitionBy(y.partitioner.get).count
res103: Long = 5
scala> val x = sc.textFile("./wc.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey
reduceByKey reduceByKeyLocally
scala> val x = sc.textFile("./wc.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
x: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[141] at reduceByKey at <console>:24
scala> x.getNumPartitions
res105: Int = 2
scala> x.partitionBy(new org.apache.spark.HashPartitioner(2)).collect
res106: Array[(String, Int)] = Array((Hello,3), ("",1), (World,1), (java,1), (spark,1))
只有传进去的是当前对象的partition才不会产生shuffle; scala> y.partitionBy(new org.apache.spark.HashPartitioner(4)).count res104: Long = 5 链太长了它会走缓存的
2.reduceByKey(func, [numTasks])
在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,reduce任务的个数可以通过第二个可选的参数来设置。
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("d", 4)))
//reduceByKey: 相同key的数据进行value数据的聚合操作
//scala语言中一般的聚合操作都是两两聚合, spark基于scala开发,所以它的聚合也是两两聚合
//[1,2,3]
//[3,3] 1+2 +3
//reduceByKey中如果key的数据只有一个, 是不会参与运算的
val reduceRdd: RDD[(String, Int)] = rdd.reduceByKey((x:Int, y: Int) => { //两两进行计算,分区内和分区间规则相同。
println(s"x=${x}, y=${y}") //x=1, y=2
x + y //x=3, y=3
})
reduceRdd.collect.foreach(println) //(a,6) (d,4)
scala> val rdd = sc.parallelize(List(("female", 1), ("male", 6), ("female", 5), ("male", 2)))
rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[143] at parallelize at <console>:24
scala> rdd.reduceByKey(_+_).collect
res108: Array[(String, Int)] = Array((female,6), (male,8))
scala> rdd.reduceByKey(_*_).collect
res110: Array[(String, Int)] = Array((female,5), (male,12))
scala> rdd.reduceByKey(_ max _).collect #先在分区内进行计算,最终分区之间也要做计算;
res111: Array[(String, Int)] = Array((female,5), (male,6))
reduceByKey支持分区内预聚合功能,可以有效减少shuffle时落盘的数据量,提升性能。
reduceByKey在分区内和分区间计算的规则是相同的。而aggregateByKey在分区内和内区间的计算规则可以独立开。
3. groupByKey
作用:groupByKey也是对每个key进行操作,但只生成一个seq
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("d", 4)))
//groupByKey: 将数据源中的数据, 相同key的数据分在一个组中, 形成一个对偶元组
//元组中的第一个元素就是key
//元组中的第二个元素就是相同的value的集合
val groupByKeyRdd: RDD[(String, Iterable[Int])] = rdd.groupByKey() //key是确定的, value单独拿出来
groupByKeyRdd.collect.foreach(println) //(a,CompactBuffer(1, 2, 3))
// (d,CompactBuffer(4))
val groupRdd: RDD[(String, Iterable[(String, Int)])] = rdd.groupBy(_._1) //不会把单独value拿出来, 它分组的key是不固定的,它会把整体分组
groupRdd.collect.foreach(println) //(a,CompactBuffer((a,1), (a,2), (a,3)))
//(d,CompactBuffer((d,4)))
scala> val rdd = sc.parallelize(List(("female", 1), ("male", 6), ("female", 5), ("male", 2), ("male", 3)))
scala> rdd.groupByKey().collect
Array[(String, Iterable[Int])] = Array((female,CompactBuffer(1, 5)), (male,CompactBuffer(6, 2, 3)))
groupByKey与reduceByKey的区别
- 1. reduceByKey:按照key进行聚合,在shuffle之前有combine(预聚合)操作,返回结果是RDD[k,v]。先在分区内部进行聚合,
- 2. groupByKey:按照key进行分组,直接进行shuffle。 有多少条数据直接进行shuffle,打乱重组直接发到下游
- 3. 开发指导:reduceByKey比groupByKey性能高,建议使用。但是需要注意是否会影响业务逻辑。
groupByKey会导致数据打乱重组,存在shuffle操作;spark中,shuffle操作必须落盘处理,不能在内存中数据等待,会导致内存溢出,shuffle操作的性能非常低。
reduceByKey,在分组之前就聚合了,分区内就先聚合了(即分区内预聚合),预聚合功能、效率比较高。
从shuffle的角度:reduceByKey和groupByKey都存在shuffle的操作,但是reduceByKey可以在shuffle前对分区内相同key的数据进行预聚合(combine)功能,这样会减少落盘的数据 量,而groupByKey只是进行分组,不存在数据量减少的问题,reduceByKey性能比较高。
从功能的角度:reduceByKey其实包含分组和聚合的功能。GroupByKey只能分组,不能聚合,所以在分组聚合的场合下,推荐使用reduceByKey,如果仅仅是分组而不需要聚合。那么还是只能使用groupByKey

4. aggregateByKey
参数:(zeroValue:U,[partitioner: Partitioner]) (seqOp: (U, V) => U,combOp: (U, U) => U)
1. 作用:在kv对的RDD中,按key将value进行分组合并,合并时,将每个value和初始值作为seq函数的参数,进行计算,返回的结果作为一个新的kv对,然后再将结果按照key进行合并,最后将每个分组的value传递给combine函数进行计算(先将前两个value进行计算,将返回结果和下一个value传给combine函数,以此类推),将key与计算结果作为一个新的kv对输出。
2. 参数描述:
(1)zeroValue:给每一个分区中的每一种key一个初始值;
(2)seqOp:函数用于在每一个分区中用初始值逐步迭代value;##values与初始化迭代聚合
(3)combOp:函数用于合并每个分区中的结果。 #分区之间的聚合
def aggregateByKey[U: ClassTag](zeroValue: U, partitioner: Partitioner)(seqOp: (U, V) => U,combOp: (U, U) => U): RDD[(K, U)] = self.withScope { // Serialize the zero value to a byte array so that we can get a new clone of it on each key val zeroBuffer = SparkEnv.get.serializer.newInstance().serialize(zeroValue) val zeroArray = new Array[Byte](zeroBuffer.limit) zeroBuffer.get(zeroArray) lazy val cachedSerializer = SparkEnv.get.serializer.newInstance() val createZero = () => cachedSerializer.deserialize[U](ByteBuffer.wrap(zeroArray)) // We will clean the combiner closure later in `combineByKey` val cleanedSeqOp = self.context.clean(seqOp) combineByKeyWithClassTag[U]((v: V) => cleanedSeqOp(createZero(), v), cleanedSeqOp, combOp, partitioner) }
def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U,combOp: (U, U) => U): RDD[(K, U)]
初始值zeroValue: U, 分区内计算时seqOp: (U, V), 这个V就是在调用这个方法之前的那个K,V中的V,
说明分区内计算是初始值和V操作, 返回的结果是和U的类型是一样的;
分区间是combOp: (U, U), 最终的结果是初始值在执行的
val rdd: RDD[(String, Int)] = sc.makeRDD(List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5),("a", 6)
), 2)
//aggregateByKey存在函数柯里化, 有两个参数列表:
//第一个参数列表, 需要传递一个参数, 表示为初始值
// 主要用于当碰见第一个key的时候, 和value进行分区内计算
//第二个参数列表需要传递2个参数
// 第一个参数表示分区内计算规则
// 第二个参数表示分区间计算规则
//1. 求每个分区内相同key的最大值之和。
// (a, [1, 2]),(b,[3]) (a, [6]),(b, [4, 5]) 初始值0与1做比较,1大;1与2做比较,2大...
// (a,2),(b,3) (a,6),(b,5) 分区内计算
// (a,2+6) (b,3+5) 分区间计算
val aggregateByKeyRdd: RDD[(String, Int)] = rdd.aggregateByKey(0)(
(x, y) => math.max(x, y),
(x, y) => x + y
)
aggregateByKeyRdd.collect.foreach(println)//(a,8) (b,8)
//简化为如下:
rdd.aggregateByKey(0)(_ max _, _+_).collect()
//2. 求每个分区key的和即分组求和; 也可以在分区内和分区间做相同的计算
rdd.aggregateByKey(0)(
(x, y) => x + y,
(x, y) => x + y
).collect.foreach(println) //(b,12) (a,9)
rdd.aggregateByKey(0)(_+_, _+_).collect.foreach(println) //(b,12) (a,9)
//3. 如果聚合计算时, 分区内和分区间计算规则相同, spark提供了简化的方法,详细见下
rdd.foldByKey(0)(_+_).collect.foreach(println) // (b,12) (a,9)
小功能:获取相同key的数据的平均值
val rdd: RDD[(String, Int)] = sc.makeRDD(List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5),("a", 6)
), 2)
//RDD[(String, String)] 它的数据类型要看初始值的类型
//val aggregateByKeyRdd: RDD[(String, String)] = rdd.aggregateByKey("")(_+_,_+_)
//aggregateByKeyRdd.collect.foreach(println) //(b,345) (a,126)
//获取相同key的数据的平均值 => (a, 3) (b, 4)
//需要数据和key的累加 (Int, Int)分别表示总的数量和总的次数
val newRdd: RDD[(String, (Int, Int))] = rdd.aggregateByKey((0, 0))( //第一个0表示value的初始值, 第二个0表示key出现的次数, (0,0)表示相同key的初始值
(t, v) => { //初始值跟value进行的分区内的计算
(t._1 + v, t._2 + 1)//t._1 + v 数据相加, t._2 + 1是次数相加
},
(t1, t2) => { //分区间的计算
(t1._1 + t2._1, t1._2 + t2._2)
}
)
//mapValues, 当key保持不变, 只对value做转换时
val resultRdd: RDD[(String, Int)] = newRdd.mapValues {
case (num, cnt) => {
num / cnt
}
}
resultRdd.collect.foreach(println) //(b,4) (a,3)
简化如下:
val result = rdd.aggregateByKey((0,0))((init,v)=>(init._1+v,init._2+1),(x,y)=>(x._1+y._1,x._2+y._2))
result.mapValues(x=>x._1.toDouble/x._2).collect
//(0,0)代表和,次数; init 是k的初始值,v 是同一种k的v,和相加,次数也相加;init是元组类型,访问它的k即_1 和它的个数v
//每一个分区的每一种key--->初始值元组(0,0)
//每个分区之间做运行也需要传两个参数,(x,y)是每个分区之间做处理,每个x是代表元组类型,每个分区的每种key会得到一个元组;x,y都是k v对
5 foldByKey案例
参数:(zeroValue: V) (func: (V, V) => V): RDD[(K, V)]
- 作用:aggregateByKey的简化操作,seqop和combop相同
scala> val rdd = sc.parallelize(List((1,3),(1,2),(1,4),(2,3),(3,6),(3,8)),3)
计算相同key对应值的相加结果
rdd.foldByKey(0)(_+_).collect
Array[(Int, Int)] = Array((3,14), (1,9), (2,3))
求平均值:
rdd.map(x => (x._1, (x._2, 1))).foldByKey((0, 0)) ((x, y) => (x._1+y._1, x._2+y._2)).mapValues(x => x._1.toDouble/x._2).collect
Array[(Int, Double)] = Array((3,7.0), (1,3.0), (2,3.0))
6 combineByKey[C] 案例
参数:(createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C)
- 作用:针对相同K,将V合并成一个集合。
- 参数描述:
- (1)createCombiner: combineByKey() 会遍历分区中的所有元素,因此每个元素的键要么还没有遇到过,要么就和之前的某个元素的键相同。如果这是一个新的元素,combineByKey()会使用一个叫作createCombiner()的函数来创建那个键对应的累加器的初始值
- (2)mergeValue: 如果这是一个在处理当前分区之前已经遇到的键,它会使用mergeValue()方法将该键的累加器对应的当前值与这个新的值进行合并
- (3)mergeCombiners: 由于每个分区都是独立处理的, 因此对于同一个键可以有多个累加器。如果有两个或者更多的分区都有对应同一个键的累加器, 就需要使用用户提供的 mergeCombiners() 方法将各个分区的结果进行合并。
小功能:获取相同key的数据的平均值 与aggregateByKey 实现相同的功能
val rdd: RDD[(String, Int)] = sc.makeRDD(List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5),("a", 6)
), 2)
//combineByKey: 方法需要三个参数
//第一个参数表示: 将相同key的第一个数据进行结构的转换, 实现操作
//第二个参数表示: 分区内的计算规则
//第三个参数表示: 分区间的计算规则
//不需要初始值了, 第一个值就不用分区内计算了
val newRdd: RDD[(String, (Int, Int))] = rdd.combineByKey(
v => (v, 1), //将分区内的value转换结构 <===> t: (Int, Int)
(t: (Int, Int), v) => { //t: (Int, Int) 这个结构是动态变化的, 不是编译时自动识别的
(t._1 + v, t._2 + 1)
},
(t1: (Int, Int), t2: (Int, Int)) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
)
newRdd
//mapValues, 当key保持不变, 只对value做转换时
val resultRdd: RDD[(String, Int)] = newRdd.mapValues {
case (num, cnt) => {
num / cnt
}
}
resultRdd.collect.foreach(println) //(b,4) (a,3)
(先计算每个key出现的次数以及可以对应值的总和,再相除得到结果)
rdd.combineByKey((_,1), (acc:(Int, Int), v) => (acc._1 + v, acc._2 + 1), (x: (Int, Int), y: (Int, Int)) => (x._1 + y._1, x._2 + y._2))
.mapValues(x => x._1.toDouble / x._2).collect
7 sortByKey([ascending], [numTasks]) 案例
1. 作用:在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD
2. 需求:创建一个pairRDD,按照key的正序和倒序进行排序
val rdd = sc.parallelize(Array((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd")))
rdd.sortByKey().collect //默认正序
Array[(Int, String)] = Array((1,dd), (2,bb), (3,aa), (6,cc))
rdd.sortByKey(false).collect //倒序排
Array[(Int, String)] = Array((6,cc), (3,aa), (2,bb), (1,dd))
8 mapValues案例
1. 针对于(K,V)形式的类型只对V进行操作
2. 需求:创建一个pairRDD,并将value添加字符串"|||"
val rdd = sc.parallelize(Array((1,"a"),(1,"d"),(2,"b"),(3,"c")))
rdd.mapValues(_+"|").collect
Array[(Int, String)] = Array((1,a|), (1,d|), (2,b|), (3,c|))
9 join leftOuterJoin rightOuterJoin
1. 作用:在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD
2. 需求:创建两个pairRDD,并将key相同的数据聚合到一个元组。
join
val rdd: RDD[(String, Int)] = sc.makeRDD(List(
("a", 1), ("b", 2), ("c", 3)
))
val rdd2: RDD[(String, Int)] = sc.makeRDD(List(
("b", 4), ("c", 5), ("a", 6),("d", 4),("a", 0)
))
//join: 两个不同数据源的数据,相同的key的value会连接在一起,形成元组
// 如果两个数据源中的kye没有匹配上,那么数据不会出现在结果中
// 如果两个数据源中的key有多个相同的,会依次匹配,可能会出现笛卡尔乘积,数据会导致几何增长,会导致性能降低
val joinRdd: RDD[(String, (Int, Int))] = rdd.join(rdd2)
joinRdd.collect.foreach(println) //(a,(1,6)) (a,(1,0)) (b,(2,4)) (c,(3,5))
leftOuterJoin、 rightOuterJoin
val rdd: RDD[(String, Int)] = sc.makeRDD(List(
("a", 1), ("b", 2), ("c", 3),("d", 4)
))
val rdd2: RDD[(String, Int)] = sc.makeRDD(List(
("a", 4), ("b", 5), ("c", 6),("e", 7)
))
val leftJoinRdd: RDD[(String, (Int, Option[Int]))] = rdd.leftOuterJoin(rdd2)
val rightJoinRdd: RDD[(String, (Option[Int], Int))] = rdd.rightOuterJoin(rdd2)
leftJoinRdd.collect.foreach(println) //(a,(1,Some(4))) (b,(2,Some(5))) (c,(3,Some(6))) (d,(4,None))
println()
rightJoinRdd.collect.foreach(println) //(a,(Some(1),4)) (b,(Some(2),5)) (c,(Some(3),6)) (e,(None,7))
10 cogroup(otherDataset, [numTasks]) 案例
- 1. 作用:在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable<V>,Iterable<W>))类型的RDD
- 2. 需求:创建两个pairRDD,并将key相同的数据聚合到一个迭代器。
val rdd: RDD[(String, Int)] = sc.makeRDD(List(
("a", 1), ("b", 2), ("c", 3),("d", 4)
))
val rdd2: RDD[(String, Int)] = sc.makeRDD(List(
("a", 4), ("b", 5), ("c", 6),("c", 7),("e", 8)
))
//cogroup: connect + group (分组, 连接)
val cogroupRdd: RDD[(String, (Iterable[Int], Iterable[Int]))] = rdd.cogroup(rdd2)
cogroupRdd.collect.foreach(println)
//(a,(CompactBuffer(1),CompactBuffer(4)))
//(b,(CompactBuffer(2),CompactBuffer(5)))
//(c,(CompactBuffer(3),CompactBuffer(6, 7)))
//(d,(CompactBuffer(4),CompactBuffer()))
//(e,(CompactBuffer(),CompactBuffer(8)))
reduceByKey| aggregateByKey| foldByKey| combineByKey区别
val rdd: RDD[(String, Int)] = sc.makeRDD(List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5),("a", 6)
), 2)
/**
reduceByKey:
combineByKeyWithClassTag[V](
(v: V) => v, //第一个值不会参与计算
func, //表示分区内计算规则
func, //表示分区间计算规则
)
aggregateByKey:
combineByKeyWithClassTag[U](
(v: V) => cleanedSeqOp(createZero(), v), //初始值和第一个key的value值进行的分区内数据操作
cleanedSeqOp, //表示分区内计算规则
combOp, //表示分区间计算规则
)
foldByKey:
combineByKeyWithClassTag[V](
(v: V) => cleanedFunc(createZero(), v), //初始值和第一个key的value值进行的分区内数据操作
cleanedFunc, //表示分区内计算规则
cleanedFunc, //表示分区间计算规则
)
combineByKey:
combineByKeyWithClassTag(
createCombiner, //相同key的第一条数据进行的处理
mergeValue, //表示分区内数据的处理函数
mergeCombiners,//表示分区间数据的处理函数
*/
rdd.reduceByKey(_+_) //wordcount
rdd.aggregateByKey(0)(_+_, _+_)//wordcount
rdd.foldByKey(0)(_+_) //wordcount
rdd.combineByKey(v => v, (x:Int, y) => x+y, (x:Int, y:Int)=>x+y) //wordcount
求平均值的几个方法
求平均值 ① def aggregateByKey[U: ClassTag] (zeroValue: U) 给每一个分区中的每一种key一个初始值; (seqOp: (U, V) => U, combOp: (U, U) => U): RDD[(K, U)] = self.withScope seqOp函数用于在每一个分区中用初始值逐步迭代value; combOp:函数用于合并每个分区中的结果 combineByKeyWithClassTag[U]((v: V) => cleanedSeqOp(createZero(), v),cleanedSeqOp, combOp, partitioner) ② def foldByKey 它是aggregateByKey的简化操作,seqop和combop相同 (zeroValue: V) 初始值要跟rdd 的 V一致; (func: (V, V) => V): RDD[(K, V)] = self.withScope combineByKeyWithClassTag[V]((v: V) => cleanedFunc(createZero(), v), cleanedFunc, cleanedFunc, partitioner) ③ def combineByKey[C]( createCombiner: V => C, //给每个分区内部的每一种key一个初始函数 mergeValue: (C, V) => C, //合并每个分区内部同种key的值,返回类型跟初始函数返回类型相同 mergeCombiners: (C, C) => C, //分区之间,相同的key的值进行聚合 partitioner: Partitioner, //分区器 mapSideCombine: Boolean = true, //是否进行预聚合 serializer: Serializer = null): RDD[(K, C)] = self.withScope { combineByKeyWithClassTag(createCombiner, mergeValue, mergeCombiners, partitioner, mapSideCombine, serializer)(null) } ④ def reduceByKey(func: (V, V) => V): RDD[(K, V)] = self.withScope combineByKeyWithClassTag[V]((v: V) => v, func, func, partitioner) aggregateByKey,reduceByKey, foldByKey def combineByKeyWithClassTag[C]( createCombiner: V => C, 给每个分区内部每一种k一个初始函数,得到一个初始值 mergeValue: (C, V) => C, 分区内部同种key不同值进行合并,第一个参数,是是一个函数的返回值 mergeCombiners: (C, C) => C, 分区之间,同种k的value合并 partitioner: Partitioner, 分区器 mapSideCombine: Boolean = true, 是否进行预聚合 serializer: Serializer = null) val rdd = sc.parallelize(List((1,3),(1,2),(1,4),(2,3),(3,6),(3,8)),3) ①aggregateByKey rdd.aggregateByKey((0,0)) ((init,v) => (init._1+v, init._2+1), (x,y) => (x._1+y._1, x._2+y._2)).collect Array[(Int, (Int, Int))] = Array((3,(14,2)), (1,(9,3)), (2,(3,1))) ②foldByKey 初始值必须要跟rdd的v一样, rdd.map(x => (x._1, (x._2, 1))).foldByKey((0,0)) ((x,y) => (x._1+y._1, x._2+y._2)).collect Array[(Int, (Int, Int))] = Array((3,(14,2)), (1,(9,3)), (2,(3,1))) ③combineByKey rdd.combineByKey(x => (x,1), (acc:(Int,Int),newValue) => (acc._1+newValue, acc._2+1),(x:(Int, Int), y:(Int, Int))=>(x._1+y._1, x._2+y._2)).collect Array[(Int, (Int, Int))] = Array((3,(14,2)), (1,(9,3)), (2,(3,1))) ④reduceByKey rdd.map(x=>(x._1, (x._2, 1))).reduceByKey((x,y)=>(x._1+y._1,x._2+y._2)).collect Array[(Int, (Int, Int))] = Array((3,(14,2)), (1,(9,3)), (2,(3,1))) rdd.map(x=>(x._1, (x._2, 1))).reduceByKey((x,y)=>(x._1+y._1,x._2+y._2)).mapValues(x => x._1.toDouble/x._2).collect Array[(Int, Double)] = Array((3,7.0), (1,3.0), (2,3.0))
案例实操:
1) 数据准备
agent.log:时间戳,省份,城市,用户,广告,中间字段使用空格分隔。
2) 需求描述
统计出每一个省份每个广告被点击数量排行的Top3
// 1516609143867 6 7 64 16 def main(args: Array[String]): Unit = { val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Spark-Transform") val sc: SparkContext = new SparkContext(sparkConf) // TODO 案例实操 // 1. 获取原始数据:时间戳,省份,城市,用户,广告 val dataRDD = sc.textFile("datas/agent.log") // 2. 将原始数据进行结构的转换。方便统计 // 时间戳,省份,城市,用户,广告 // => // ( ( 省份,广告 ), 1 ) val mapRDD = dataRDD.map( line => { val datas = line.split(" ") (( datas(1), datas(4) ), 1) } ) // 3. 将转换结构后的数据,进行分组聚合 // ( ( 省份,广告 ), 1 ) => ( ( 省份,广告 ), sum ) val reduceRDD: RDD[((String, String), Int)] = mapRDD.reduceByKey(_+_) // 4. 将聚合的结果进行结构的转换 // ( ( 省份,广告 ), sum ) => ( 省份, ( 广告, sum ) ) val newMapRDD = reduceRDD.map{ case ( (prv, ad), sum ) => { (prv, (ad, sum)) } } // 5. 将转换结构后的数据根据省份进行分组 // ( 省份, 【( 广告A, sumA ),( 广告B, sumB )】 ) val groupRDD: RDD[(String, Iterable[(String, Int)])] = newMapRDD.groupByKey() // 6. 将分组后的数据组内排序(降序),取前3名 val resultRDD = groupRDD.mapValues( iter => { iter.toList.sortBy(_._2)(Ordering.Int.reverse).take(3) } ) // 7. 采集数据打印在控制台 resultRDD.collect().foreach(println) sc.stop() }
RDD行动算子 Action
//TODO - 行动算子 所谓行动算子其实就是触发作业(job)执行的方法
//底层代码调用的是环境对象runJob方法 --> dagScheduler有向无环图的调度器 -> submitJob -> activeJob并提交执行
action算子
行动算子都调了sc.runjob
1 reduce(func)案例
def reduce(f: (T, T) => T): T
1. 作用:通过func函数聚集RDD中的所有元素,先聚合分区内数据,再聚合分区间数据。
2. 需求:创建一个RDD,将所有元素聚合得到结果
scala> val rdd = sc.makeRDD(1 to 10, 2)
scala> rdd.reduce(_+_)
res77: Int = 55
scala> rdd.map((_,1)).reduce((x,y) => (x._1+y._1, x._2+y._2))
(Int, Int) = (55,10)
scala> rdd.reduce(_ max _)
Int = 10
val rdd2 = sc.makeRDD(Array(("a",1),("a",3),("c",3),("d",5)))
rdd2.reduce((x,y) => (x._1 + y._1, x._2+y._2))
(String, Int) = (caad,12)
2 collect()案例
collect不要随意用,少用
1. 作用:在驱动程序中,以数组的形式返回数据集的所有元素。
val datasRdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//collect: 将不同分区的数据按照分区顺序 采集到Driver端内存中形成数组
val ints: Array[Int] = datasRdd.collect()
println(ints.mkString(","))
3 count()案例
- 1. 作用:返回RDD中元素的个数
- 2. 需求:创建一个RDD,统计该RDD的条数
scala> rdd.count
res88: Long = 10
4 first()案例 --底层调用了take
- 1. 作用:返回RDD中的第一个元素
- 2. 需求:创建一个RDD,返回该RDD中的第一个元素
scala> rdd.first
res89: Int = 1
5 take(n)案例
take 和collect一样都是把数据弄到driver内存里,慎用
1. 作用:返回一个由RDD的前n个元素组成的数组
scala> val rdd = sc.parallelize(Array(2,5,4,6,8,3))
scala> rdd.take(3)
res91: Array[Int] = Array(2, 5, 4)
6 takeOrdered(n)案例
1. 作用:返回该RDD排序后的前n个元素组成的数组
val datasRdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//count: 数据源中数据的个数
val cnt: Long = datasRdd.count()
println(cnt)
//first: 获取数据源中数据的第一个
val first: Int = datasRdd.first()
println(first)
//take: 获取N个数据
val take: Array[Int] = datasRdd.take(3)
println(take.mkString(","))
//takeOrdered: 数据排序后, 取N个数据
val rdd: RDD[Int] = sc.makeRDD(List(4,3,2,1))
val ints: Array[Int] = rdd.takeOrdered(3) //默认升序
println(ints.mkString(",")) //1 2 3
7 aggregate案例
1. 参数:(zeroValue: U)(seqOp: (U, T) ⇒ U, combOp: (U, U) ⇒ U)
2. 作用:aggregate函数将每个分区里面的元素通过seqOp和初始值进行聚合,然后用combine函数将每个分区的结果和初始值(zeroValue)进行combine操作。这个函数最终返回的类型不需要和RDD中元素类型一致。
3. 需求:创建一个RDD,将所有元素相加得到结果
aggregate()分区内部元素一个初始值()分区内部元素初始值进行合并()分区之间,同种k的value合并
aggregate(0)(_+_, _+_)求和
scala> var rdd1 = sc.makeRDD(1 to 10,2)
scala> rdd1.aggregate(0)(_ max _, _+_)
Int = 15
scala> rdd1.aggregate(0)(_+_, _+_)
Int = 55
aggregateByKey和aggregate的区别和联系:①参数个数一样; ②分区内部和分区之间聚合对象不一样;
aggregateByKey:对同种key的值; aggregate是对rdd的元素
8 fold(num)(func)案例
1. 作用:折叠操作,aggregate的简化操作,seqop和combop一样。
2. 需求:创建一个RDD,将所有元素相加得到结果
scala> rdd1.fold(0)(_+_)
Int = 55
scala> rdd1.fold(0)(_ max _)
Int = 10
scala中 x.reduce(_+_)
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4), 2)
//aggregateByKey: 初始值只会参与分区内计算
//aggregate: 初始值会参与分区内计算, 并且和参与分区间计算
val aggregateRdd: Int = rdd.aggregate(10)(_+_, _+_)
println(aggregateRdd) //40 = 10 + 13 + 17
//当分区内和分区间的计算规则一样时可以使用fold ; 就像aggregateByKey当它的分区内和分区间的计算规则相同时可以采用foldByKey进行简化
val fold: Int = rdd.fold(10)(_+_)
println(fold) //40
9 countByKey() countByValue案例
1. 作用:针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。
2. 需求:创建一个PairRDD,统计每种key的个数
val rdd: RDD[Int] = sc.makeRDD(List(1,1,1,2,3), 2)
val intToLong: collection.Map[Int, Long] = rdd.countByValue()
println(intToLong) // Map(2 -> 1, 1 -> 3, 3 -> 1)
val rdd2: RDD[(String, Int)] = sc.makeRDD(List(("a",1), ("a",2), ("a", 3)))
val stringToLong: collection.Map[String, Long] = rdd2.countByKey()
println(stringToLong) // Map(a -> 3)
wordCount的不同实现方式
//groupBy def wordCount1(sc: SparkContext): Unit = { val rdd: RDD[String] = sc.makeRDD(List("Hello Scala", "Hello Spark")) val words: RDD[String] = rdd.flatMap(_.split(" ")) val group: RDD[(String, Iterable[String])] = words.groupBy(word => word) val wordCount: RDD[(String, Int)] = group.mapValues(iter => iter.size) } //groupByKey 效率不高会产生shuffle def wordCount2(sc: SparkContext): Unit = { val rdd: RDD[String] = sc.makeRDD(List("Hello Scala", "Hello Spark")) val words: RDD[String] = rdd.flatMap(_.split(" ")) val wordOne: RDD[(String, Int)] = words.map((_, 1)) val group: RDD[(String, Iterable[Int])] = wordOne.groupByKey() val wordCount: RDD[(String, Int)] = group.mapValues(iter => iter.size) } //reduceByKey 直接分组聚合, 效率高 def wordCount3(sc: SparkContext): Unit = { val rdd: RDD[String] = sc.makeRDD(List("Hello Scala", "Hello Spark")) val words: RDD[String] = rdd.flatMap(_.split(" ")) val wordOne: RDD[(String, Int)] = words.map((_, 1)) val wordCount: RDD[(String, Int)] = wordOne.reduceByKey(_+_) } //aggregateByKey def wordCount4(sc: SparkContext): Unit = { val rdd: RDD[String] = sc.makeRDD(List("Hello Scala", "Hello Spark")) val words: RDD[String] = rdd.flatMap(_.split(" ")) val wordOne: RDD[(String, Int)] = words.map((_, 1)) val wordCount: RDD[(String, Int)] = wordOne.aggregateByKey(0)(_+_, _+_) } //foldByKey def wordCount5(sc: SparkContext): Unit = { val rdd: RDD[String] = sc.makeRDD(List("Hello Scala", "Hello Spark")) val words: RDD[String] = rdd.flatMap(_.split(" ")) val wordOne: RDD[(String, Int)] = words.map((_, 1)) val wordCount: RDD[(String, Int)] = wordOne.foldByKey(0)(_+_) } //combineByKey def wordCount6(sc: SparkContext): Unit = { val rdd: RDD[String] = sc.makeRDD(List("Hello Scala", "Hello Spark")) val words: RDD[String] = rdd.flatMap(_.split(" ")) val wordOne: RDD[(String, Int)] = words.map((_, 1)) val wordCount: RDD[(String, Int)] = wordOne.combineByKey( v => v, (x: Int, y) => x + y, (x: Int, y: Int) => x + y ) } //countByKey def wordCount7(sc: SparkContext): Unit = { val rdd: RDD[String] = sc.makeRDD(List("Hello Scala", "Hello Spark")) val words: RDD[String] = rdd.flatMap(_.split(" ")) val wordOne: RDD[(String, Int)] = words.map((_, 1)) val stringToLong: collection.Map[String, Long] = wordOne.countByKey() } //countByValue def wordCount8(sc: SparkContext): Unit = { val rdd: RDD[String] = sc.makeRDD(List("Hello Scala", "Hello Spark")) val words: RDD[String] = rdd.flatMap(_.split(" ")) val stringToLong: collection.Map[String, Long] = words.countByValue() } //reduce aggregate fold 类似 def wordCount9(sc: SparkContext): Unit = { val rdd: RDD[String] = sc.makeRDD(List("Hello Scala", "Hello Spark")) val words: RDD[String] = rdd.flatMap(_.split(" ")) //[ (word, count), (word, count) ] //word => Map[(word, 1)] val mapWord: RDD[mutable.Map[String, Long]] = words.map( word => { mutable.Map[String, Long]((word, 1)) } ) val wordCount: mutable.Map[String, Long] = mapWord.reduce( (map1, map2) => { map2.foreach { case (word, count) => { val newCount: Long = map1.getOrElse(word, 0L) + count } } map1 } ) println(wordCount) }
Save相关算子
saveAsTextFile(path)
作用:将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本
scala> rdd.saveAsTextFile("./textFile.txt")
saveAsSequenceFile(path)
作用:将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。
saveAsObjectFile(path)
作用:用于将RDD中的元素序列化成对象,存储到文件中。
foreach(func)案例
1. 作用:在数据集的每一个元素上,运行函数func进行更新。
2. 需求:创建一个RDD,对每个元素进行打印
var rdd = sc.makeRDD(1 to 5,2)
rdd.foreach(println(_))
1
2
3
4
5
def foreachPartition(f: Iterator[T] => Unit): Unit = withScope
可以控制它的链接数,(可写数据库连接池等);每个记录创建一次;(跟map和mapPartition类似)
rdd.foreachPartition(x => {
x.foreach(println(_))
})
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//foreach 其实是Driver端内存集合的循环遍历方法
rdd.collect().foreach(println) //1 2 3 4
println("================")
//foreach 其实是Executor端内存数据打印
rdd.foreach(println) //3 1 4 2
//算子: Operator(操作)
// RDD的方法和Scala集合对象的方法不一样
// 集合对象的方法都是在同一个节点的内存中完成的。
// RDD的方法可以将计算逻辑发送到Executor端(分布式节点)执行
// 为了区分不同的处理效果, 所以将RDD的方法称之为算子。
// RDD的方法外部的操作都是在Driver端执行,而方法内部的逻辑代码是在Executor端执行。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2018-04-05 第五章| 5.1面向对象-继承 |封装 |多态
2018-04-05 函数| 常用模块总结练习
2018-04-05 ATM+购物车商城