
Spark |01 hadoop与spark的区别| 概述| 安装部署| 运行模式
1.Spark and Hadoop
在 Spark 出现之前,我们并没有对 MapReduce 的执行速度不满,我们觉得大数据嘛、分布式计算嘛,这样的速度也还可以啦。至于编程复杂度也是一样,一方面 Hive、Mahout 这些
工具将常用的 MapReduce 编程封装起来了;另一方面,MapReduce 已经将分布式编程极大地简化了,当时人们并没有太多不满。
真实的情况是,人们在 Spark 出现之后,才开始对 MapReduce 不满。原来大数据计算速度可以快这么多,编程也可以更简单。而且 Spark 支持 Yarn 和 HDFS,公司迁移到 Spark 上
的成本很小,于是很快,越来越多的公司用 Spark 代替 MapReduce。也就是说,因为有了 Spark,才对 MapReduce 不满;而不是对 MapReduce 不满,所以诞生了 Spark。真实的
因果关系是相反的。
这里有一条关于问题的定律分享给你:我们常常意识不到问题的存在,直到有人解决了这些问题。
Spark 比 MapReduce 快 100 多倍。
Hadoop,2013年10月发布2.X (Yarn)版本;Spark,2013年6月,Spark成为了Apache基金会下的项目。
Hadoop
- Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架。
- 作为Hadoop分布式文件系统,HDFS存储着所有的数据,支持着 Hadoop 的所有服务。它的理论基础源于 Google 的TheGoogleFileSystem 这篇论文,它是GFS 的开源实现。
- MapReduce是一种编程模型,Hadoop根据Google的MapReduce论文将其实现,作为Hadoop的分布式计算模型,是Hadoop的核心。基于这个框架,分布式并行程序的编写变得异常简单。综合了HDFS的分布式存储和MapReduce的分布式计算,Hadoop在处理海量数据时,性能横向扩展变得非常容易。
- HBase是对Google的Bigtable的开源实现,但又和Bigtable存在许多不同之处。HBase是一个基于HDFS的分布式数据库,擅长实时地随机读/写超大规模数据集。它也是Hadoop非常重要的组件。
Spark
- Spark是一种由Scala语言开发的快速、通用、可扩展的大数据分析引擎
- Spark Core中提供了Spark最基础与最核心的功能
- Spark SQL是Spark用来操作结构化数据的组件。通过Spark SQL,用户可以使用SQL或者Apache Hive版本的SQL方言(HQL)来查询数据。
- Spark Streaming是Spark平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API。
Hadoop的MR框架和Spark框架都是数据处理框架,两者的区别:
- Hadoop MapReduce其设计初衷并不是为了满足循环迭代式数据流处理,因此在多并行运行的数据可复用场景(如:机器学习、图挖掘算法、交互式数据挖掘算法)中存在诸多计算效率等问题。所以Spark应运而生,Spark就是在传统的MapReduce 计算框架的基础上,利用其计算过程的优化,从而大大加快了数据分析、挖掘的运行和读写速度,并将计算单元缩小到更适合并行计算和重复使用的RDD计算模型。
- 机器学习中ALS、凸优化梯度下降等。这些都需要基于数据集或者数据集的衍生数据反复查询反复操作。MR这种模式不太合适,即使多MR串行处理,性能和时间也是一个问题。数据的共享依赖于磁盘。另外一种是交互式数据挖掘,MR显然不擅长。而Spark所基于的scala语言恰恰擅长函数的处理。
- Spark是一个分布式数据快速分析项目。它的核心技术是弹性分布式数据集(Resilient Distributed Datasets),提供了比MapReduce丰富的模型,可以快速在内存中对数据集进行多次迭代,来支持复杂的数据挖掘算法和图形计算算法。
- Spark和Hadoop的根本差异是多个作业之间的数据通信问题 : Spark多个作业之间数据通信是基于内存,而Hadoop是基于磁盘。
- Spark Task的启动时间快。Spark采用fork线程的方式,而Hadoop采用创建新的进程的方式。
- Spark只有在shuffle的时候将数据写入磁盘,而Hadoop中多个MR作业之间的数据交互都要依赖于磁盘交互
- Spark的缓存机制比HDFS的缓存机制高效。
在绝大多数的数据计算场景中,Spark确实会比MapReduce更有优势。但是Spark是基于内存的,所以在实际的生产环境中,由于内存的限制,可能会由于内存资源不够导致Job执行失败,此时,MapReduce其实是一个更好的选择,所以Spark并不能完全替代MR。
Hadoop| Spark 其中蕴含的思想
顶尖的产品设计大师和问题解决专家,不会去询问人们想要什么,而是分析和观察人们的做事方式,从而思考到更好的产品设计和问题解决方案。
有个技巧可以在工作中慢慢练习:不要直接提出你的问题和方案,不要直接说“你的需求是什么?”“我这里有个方案你看一下”。
直向曲中求,对于复杂的问题,越是直截了当越是得不到答案。迂回曲折地提出问题,一起思考问题背后的规律,才能逐渐发现问题的本质。通过这种方式,既能达成共识,不会有违常识,又可能产生洞见,使产品和方案呈现闪光点。
-
你觉得前一个版本最有意思(最有价值)的功能是什么?
-
你觉得我们这个版本应该优先关注哪个方面?
-
你觉得为什么有些用户在下单以后没有支付?
理解了java8的lambda集合操作相比于传统集合操作的优势,就理解了spark相比于MapReduce的优势。
第一步,将集合对象封装成流式对象。
第二部,将函数传递给流式对象,在流式对象中执行内部循环。
spark之所以快,就是将外部循环替换成了内部循环。
传统的面向对象编程思想下,是将一个集合作为数据对象传递给一个方法,这个方法会return一个新的数据集,然后再把这个新的数据集作为入参传递给下一个方法。一趟接一趟,最终得到想要的数据处理结果。
函数式编程思想是,先把集合封装成流,我把上面两个方法改写成无状态函数丢给这个集合流,对于集合内的每一项会依次执行这两个函数,最终这个集合就是一个新的集合。只循环一趟。
原本需要做连续循环处理的次数越多,spark体现出的效率提升就越明显。
lambda里面叫Stream,spark里面叫RDD。
2. Spark概述
Spark 和 MapReduce 相比,还有更简单易用的编程模型。使用 Scala 语言在 Spark 上编写 WordCount 程序,主要代码只需要三行。
val textFile = sc.textFile("hdfs://...")
val counts = textFile.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
RDD 是 Spark 的核心概念,是弹性数据集(Resilient Distributed Datasets)的缩写。RDD 既是 Spark 面向开发者的编程模型,又是 Spark 自身架构的核心元素。
大数据计算就是在大规模的数据集上进行一系列的数据计算处理。MapReduce 针对输入数据,将计算过程分为两个阶段,一个 Map 阶段,一个 Reduce 阶段,可以理解成是面向过
程的大数据计算。我们在用 MapReduce 编程的时候,思考的是,如何将计算逻辑用 Map 和 Reduce 两个阶段实现,map 和 reduce 函数的输入和输出是什么。
Spark 则直接针对数据进行编程,将大规模数据集合抽象成一个RDD对象,然后在这个 RDD 上进行各种计算处理,得到一个新的 RDD,继续计算处理,直到得到最后的结果数据。
所以 Spark 可以理解成是面向对象的大数据计算。我们在进行 Spark 编程的时候,思考的是一个 RDD 对象需要经过什么样的操作,转换成另一个 RDD 对象,思考的重心和落脚点都
在 RDD 上。
RDD 上定义的函数分两种:
- 一种是转换(transformation)函数,这种函数的返回值还是 RDD;
- 另一种是执行(action)函数,这种函数不再返回 RDD。
RDD 定义了很多转换操作函数,比如有计算map(func)、过滤filter(func)、合并数据集union(otherDataset)、根据 Key 聚合reduceByKey(func, [numPartitions])、连接数据集
join(otherDataset, [numPartitions])、分组groupByKey([numPartitions]) 等十几个函数。
我们再来看看作为Spark 架构核心元素的 RDD。跟 MapReduce 一样,Spark 也是对大数据进行分片计算,Spark 分布式计算的数据分片、任务调度都是以 RDD 为单位展开的,每个
RDD 分片都会分配到一个执行进程去处理。
RDD 上的转换操作又分成两种,一种转换操作产生的 RDD 不会出现新的分片,比如 map、filter 等,也就是说一个 RDD 数据分片,经过 map 或者 filter 转换操作后,结果还在当前
分片。就像你用 map 函数对每个数据加 1,得到的还是这样一组数据,只是值不同。实际上,Spark 并不是按照代码写的操作顺序去生成 RDD,比如rdd2 = rdd1.map(func)这样的
代码并不会在物理上生成一个新的 RDD。物理上,Spark 只有在产生新的 RDD 分片时候,才会真的生成一个 RDD,Spark 的这种特性也被称作惰性计算。
另一种转换操作产生的 RDD 则会产生新的分片,比如reduceByKey,来自不同分片的相同 Key 必须聚合在一起进行操作,这样就会产生新的 RDD 分片。实际执行过程中,是否会产
生新的 RDD 分片,并不是根据转换函数名就能判断出来的。
Spark 应用程序代码中的 RDD 和 Spark 执行过程中生成的物理 RDD 不是一一对应的,RDD 在 Spark 里面是一个非常灵活的概念,同时又非常重要,需要认真理解。
当然 Spark 也有自己的生态体系,以 Spark 为基础,有支持 SQL 语句的 Spark SQL,有支持流计算的 Spark Streaming,有支持机器学习的 MLlib,还有支持图计算的 GraphX。利
用这些产品,Spark 技术栈支撑起大数据分析、大数据机器学习等各种大数据应用场景。
Spark是一种基于内存的快速、通用、可扩展的大数据分析引擎;
内置模块:

Spark Core
提供了Spark最基础与最核心的功能,Spark其他的功能如:Spark SQL,Spark Streaming,GraphX, MLlib都是在Spark Core的基础上进行扩展的;(封装了rdd、任务调度、内存管理、错误恢复、与存储系统交互)。
Spark SQL(操作处理结构化数据的组件)
Spark Streaming(对实时数据进行流式计算) 、
Spark Mlib(机器学习算法库,分类、回归、聚合、协同过滤等)、
Spark GraghX(图计算);
独立调度器、Yarn、Mesos
特点:
快( 基于内存(而MR是基于磁盘)、多线程模型(而mapReduce是基于多进程的,每个MR都是独立的JVM进程)、可进行迭代计算(而hadoop需要多个mr串行) )、
易用(支持java、scala、python等API,支持80多种算法,支持交互式的 Python 和 Scala 的shell,可方便地在shell中用spark集群来验证解决问题,而不像以前需要打包上传验证)、
通用(spark提供了统一解决方案,可用于批处理、交互式查询(spark sql)\ 实时流式处理(spark streaming)\机器学习和图计算,可在同一应用中无缝使用)
兼容性(与其他开源产品的融合,如hadoop的yarn、Mesos、HDFS、Hbase等);
http://spark.apache.org/ 文档查看地址 https://spark.apache.org/docs/2.1.1/
工作原理
和 MapReduce 一样,Spark 也遵循移动计算比移动数据更划算这一大数据计算基本原则。但是和 MapReduce 僵化的 Map 与 Reduce 分阶段计算相比,Spark 的计算框架更加富有
弹性和灵活性。
和 MapReduce 一个应用一次只运行一个 map 和一个 reduce 不同,Spark 可以根据应用的复杂程度,分割成更多的计算阶段(stage),这些计算阶段组成一个有向无环图 DAG,
Spark 任务调度器可以根据 DAG 的依赖关系执行计算阶段。
某些机器学习算法可能需要进行大量的迭代计算,产生数万个计算阶段,这些计算阶段在一个应用中处理完成,而不是像 MapReduce 那样需要启动数万个应用,因此极大地提高了运
行效率。
DAG即有向无环图,就是说不同阶段的依赖关系是有向的,计算过程只能沿着依赖关系方向执行,被依赖的阶段执行完成之前,依赖的阶段不能开始执行,同时,这个依赖
关系不能有环形依赖,否则就成为死循环了。下面这张图描述了一个典型的 Spark 运行 DAG 的不同阶段。
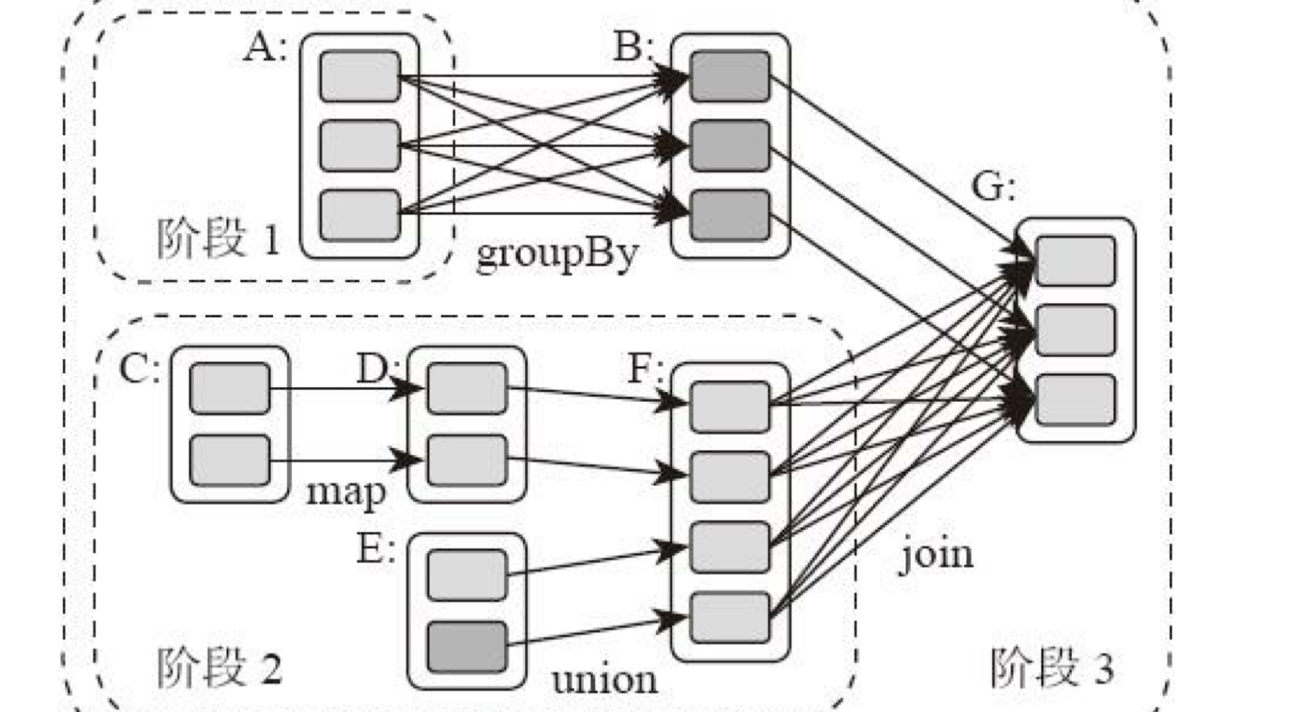
从图上看,整个应用被切分成 3个阶段,阶段 3 需要依赖阶段 1 和阶段 2,阶段 1 和阶段 2 互不依赖。Spark 在执行调度的时候,先执行阶段 1 和阶段 2,完成以后,再执行阶段 3。
如果有更多的阶段,Spark 的策略也是一样的。只要根据程序初始化好DAG,就建立了依赖关系,然后根据依赖关系顺序执行各个计算阶段,Spark 大数据应用的计算就完成了。
上图这个 DAG 对应的 Spark 程序伪代码如下。
rddB = rddA.groupBy(key)
rddD = rddC.map(func)
rddF = rddD.union(rddE)
rddG = rddB.join(rddF)
Spark 作业调度执行的核心是 DAG,有了 DAG,整个应用就被切分成哪些阶段,每个阶段的依赖关系也就清楚了。之后再根据每个阶段要处理的数据量生成相应的任务集合
(TaskSet),每个任务都分配一个任务进程去处理,Spark 就实现了大数据的分布式计算。
具体来看的话,负责Spark应用DAG生成和管理的组件是DAGScheduler,DAGScheduler 根据程序代码生成 DAG,然后将程序分发到分布式计算集群,按计算阶段的先后关系调度
执行。
阶段划分
Spark划分计算阶段的依据是什么呢?
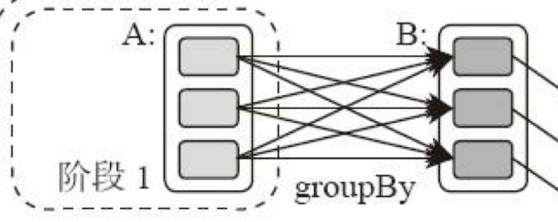
显然并不是RDD上的每个转换函数都会生成一个计算阶段,比如上面的例子有 4 个转换函数,但是只有3个阶段。
观察上面的 DAG 图,关于计算阶段的划分从图上就能看出规律,当 RDD之间的转换连接线呈现多对多交叉连接的时候,就会产生新的阶段。一个 RDD 代表一个数据集,图中每个
RDD 里面都包含多个小块,每个小块代表 RDD 的一个分片。
一个数据集中的多个数据分片需要进行分区传输,写入到另一个数据集的不同分片中,这种数据分区交叉传输的操作,我们在 MapReduce 的运行过程中也看到过。
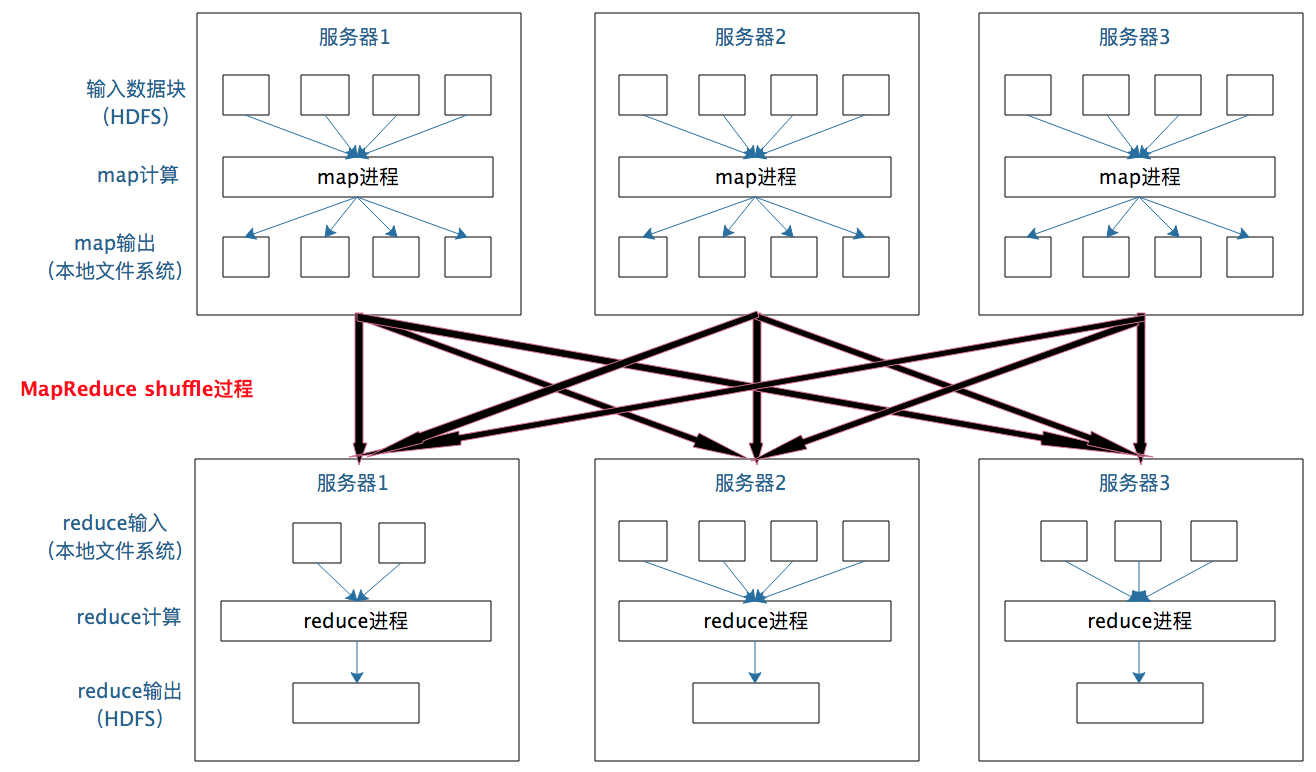
这就是 shuffle 过程,Spark 也需要通过 shuffle 将数据进行重新组合,相同 Key 的数据放在一起,进行聚合、关联等操作,因而每次shuffle都产生新的计算阶段。这也是为什么计算阶
段会有依赖关系,它需要的数据来源于前面一个或多个计算阶段产生的数据,必须等待前面的阶段执行完毕才能进行shuffle,并得到数据。
这里需要你特别注意的是,计算阶段划分的依据是shuffle,不是转换函数的类型,有的函数有时候有shuffle,有时候没有。比如上图例子中 RDDB 和 RDDF 进行 join,得到RDDG,
这里的RDDF需要进行shuffle,RDDB就不需要。
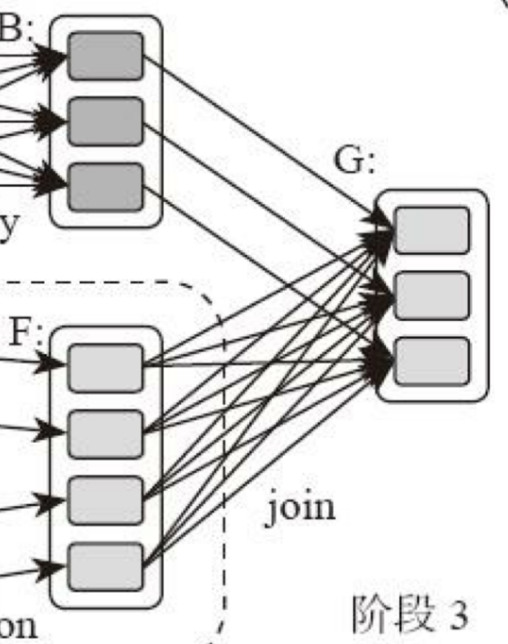
因为RDDB在前面一个阶段,阶段1的 shuffle 过程中,已经进行了数据分区。分区数目和分区 Key 不变,就不需要再进行 shuffle。
这种不需要进行 shuffle 的依赖,在 Spark 里被称作窄依赖;相反的,需要进行 shuffle 的依赖,被称作宽依赖。跟 MapReduce 一样,shuffle 也是 Spark 最重要的一个环节,只有通
过 shuffle,相关数据才能互相计算,构建起复杂的应用逻辑。
同样都要经过shuffle,为什么 Spark可以更高效呢?
其实从本质上看,Spark 可以算作是一种 MapReduce计算模型的不同实现。Hadoop MapReduce 简单粗暴地根据 shuffle 将大数据计算分成 Map 和 Reduce 两个阶段,然后就算完
事了。而 Spark 更细腻一点,将前一个的 Reduce 和后一个的 Map 连接起来,当作一个阶段持续计算,形成一个更加优雅、高效地计算模型,虽然其本质依然是 Map 和 Reduce。
但是这种多个计算阶段依赖执行的方案可以有效减少对 HDFS 的访问,减少作业的调度执行次数,因此执行速度也更快。
并且和 Hadoop MapReduce 主要使用磁盘存储 shuffle过程中的数据不同,Spark 优先使用内存进行数据存储,包括 RDD 数据。除非是内存不够用了,否则是尽可能使用内存, 这也
是 Spark 性能比 Hadoop 高的另一个原因。
Spark作业管理
Spark 里面的 RDD 函数有两种,一种是转换函数,调用以后得到的还是一个 RDD,RDD 的计算逻辑主要通过转换函数完成。
另一种是 action 函数,调用以后不再返回 RDD。比如count() 函数,返回 RDD 中数据的元素个数;saveAsTextFile(path),将 RDD 数据存储到 path 路径下。Spark 的 DAGScheduler 在遇到 shuffle 的时候,会生成一个计算阶段,在遇到 action 函数的时候,会生成一个作业(job)。
RDD 里面的每个数据分片,Spark 都会创建一个计算任务去处理,所以一个计算阶段会包含很多个计算任务(task)。
关于作业、计算阶段、任务的依赖和时间先后关系你可以通过下图看到。
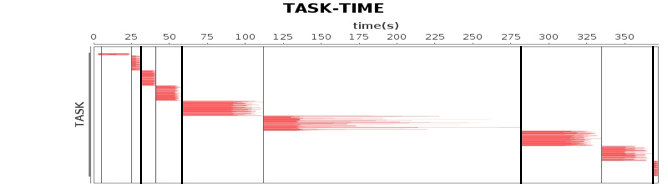
图中横轴方向是时间,纵轴方向是任务。两条粗黑线之间是一个作业,两条细线之间是一个计算阶段。一个作业至少包含一个计算阶段。水平方向红色的线是任务,每个阶段由很多个任务组成,这些任务组成一个任务集合。
DAGScheduler 根据代码生成 DAG 图以后,Spark 的任务调度就以任务为单位进行分配,将任务分配到分布式集群的不同机器上执行。
Spark 的执行过程
Spark 支持 Standalone、Yarn、Mesos、Kubernetes 等多种部署方案,几种部署方案原理也都一样,只是不同组件角色命名不同,但是核心功能和运行流程都差不多。
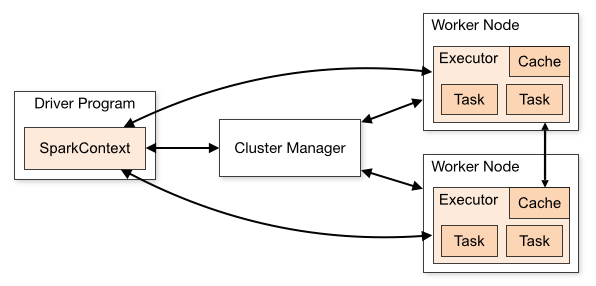
首先,Spark 应用程序启动在自己的 JVM 进程里,即 Driver 进程,启动后调用 SparkContext 初始化执行配置和输入数据。SparkContext 启动 DAGScheduler 构造执行的 DAG 图,切分成最小的执行单位也就是计算任务。
然后 Driver 向 Cluster Manager 请求计算资源,用于 DAG 的分布式计算。Cluster Manager 收到请求以后,将 Driver 的主机地址等信息通知给集群的所有计算节点 Worker。
Worker 收到信息以后,根据 Driver 的主机地址,跟 Driver 通信并注册,然后根据自己的空闲资源向 Driver 通报自己可以领用的任务数。Driver 根据 DAG 图开始向注册的 Worker 分配任务。
Worker 收到任务后,启动 Executor 进程开始执行任务。Executor 先检查自己是否有 Driver 的执行代码,如果没有,从 Driver 下载执行代码,通过 Java 反射加载后开始执行。
Spark 有三个主要特性:RDD 的编程模型更简单,DAG 切分的多阶段计算过程更快速,使用内存存储中间计算结果更高效。这三个特性使得 Spark 相对 Hadoop MapReduce 可以有更快的执行速度,以及更简单的编程实现。
wordCount
shell中

scala> sc.textFile("./wc.txt") //lineRdd:RDD[String]
.flatMap(line => line.split(" ")) //wordRDD:RDD[String]
.filter(word => !word.equals("")) //cleanWordRDD:RDD[String]
.map(word => (word,1)) //kvRDD:RDD[(String, Int)]
.reduceByKey((x,y) => x+y) //wordCounts:RDD[(String, Int)]
.map{case (k,v) => (v,k)}
.sortByKey(false)
.take(3) res14: Array[(Int, String)] = Array((4,Hello), (3,Spark), (2,Flink))
调用textFile API生成lineRDD (RDD[String]),
然后用flatMap算子把lineRDD转换为wordRDD (RDD[String]);
filter算子对wordRDD做过滤,并把它转换为不带空串的cleanWordRDD (RDD[String]),
map算子把cleanWordRDD又转换成元素为(Key,Value)对的kvRDD (RDD[(String, Int)]);
最终调用reduceByKey做分组聚合,把kvRDD中的Value从1转换为单词计数。
RDD代表的是分布式数据形态,RDD到RDD之间的转换,本质上是数据形态上的转换(Transformations)。
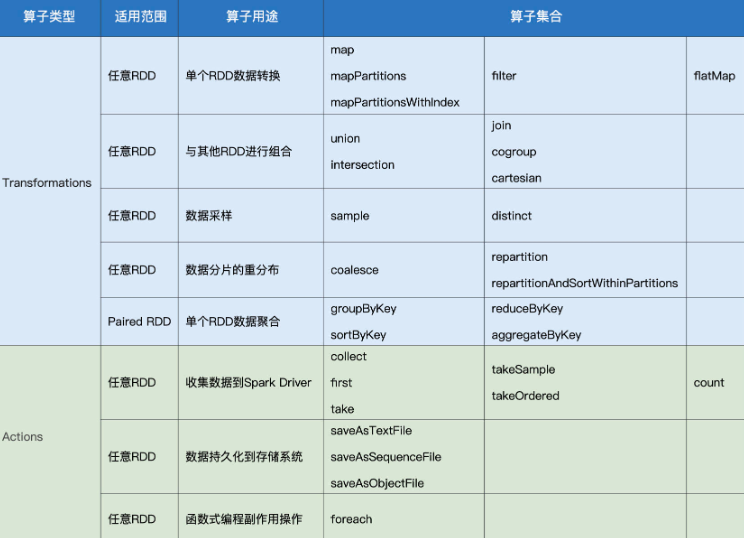
在RDD的编程模型中,一共有两种算子,Transformations类算子和Actions类算子。
开发者需要使用Transformations类算子,定义并描述数据形态的转换过程,然后调用Actions类算子,将计算结果收集起来、或是物化到磁盘。
在这样的编程模型下,Spark在运行时的计算被划分为两个环节:
基于不同数据形态之间的转换,构建计算流图(DAG,Directed Acyclic Graph);
通过Actions类算子,以回溯的方式去触发执行这个计算流图。
换句话说,开发者调用的各类Transformations算子,并不立即执行计算,当且仅当开发者调用Actions算子时,之前调用的转换算子才会付诸执行。在业内,这样的计算模式叫作“延迟计算”(Lazy Evaluation)。
代码中:
//创建Spark运行配置对象
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WorrdCount")
//创建Spark上下文环境对象
val sc : SparkContext = new SparkContext(sparkConf)
//读取文件 获取一行行的数据
val lines: RDD[String] = sc.textFile("datas")
val words: RDD[String] = lines.flatMap(_.split(" ")) // "Hello word Hello spark" => Hello word Hello spark
val wordToOne: RDD[(String, Int)] = words.map(
word => (word, 1)
)
//reduceByKey: 相同key的数据, 可以对value进行reduce聚合
//wordToOne.reduceByKey((x,y) => {x + y})
//wordToOne.reduceByKey((x,y) => x + y) //逻辑代码中就一行 {}可以省略的
val wordToCount = wordToOne.reduceByKey(_+_) //参数类型可以推断出来, 顺序执行的可以用_代替
val array: Array[(String, Int)] = wordToCount.collect()
array.foreach(println)
sc.stop()
log4j.properties


log4j.rootCategory=ERROR, console log4j.appender.console=org.apache.log4j.ConsoleAppender log4j.appender.console.target=System.err log4j.appender.console.layout=org.apache.log4j.PatternLayout log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n # Set the default spark-shell log level to ERROR. When running the spark-shell, the # log level for this class is used to overwrite the root logger's log level, so that # the user can have different defaults for the shell and regular Spark apps. log4j.logger.org.apache.spark.repl.Main=ERROR # Settings to quiet third party logs that are too verbose log4j.logger.org.spark_project.jetty=ERROR log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR log4j.logger.org.apache.parquet=ERROR log4j.logger.parquet=ERROR # SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
集群角色
Master和Workers
1)Master
Spark特有资源调度系统的Leader。掌管着整个集群的资源信息,类似于Yarn框架中的ResourceManager,主要功能:
(1)监听Worker,看Worker是否正常工作;
(2)Master对Worker、Application等的管理(接收worker的注册并管理所有的worker,接收client提交的application,(FIFO)调度等待的application并向worker提交)。
2)Worker
Spark特有资源调度系统的Slave,有多个。每个Slave掌管着所在节点的资源信息,类似于Yarn框架中的NodeManager,主要功能:
(1)通过RegisterWorker注册到Master;
(2)定时发送心跳给Master;
(3)根据master发送的application配置进程环境,并启动StandaloneExecutorBackend(执行Task所需的临时进程)
Driver和Executor
1)Driver(驱动器)
Spark的驱动器是执行开发程序中的main方法的进程。它负责开发人员编写的用来创建SparkContext、创建RDD,以及进行RDD的转化操作和行动操作代码的执行。如果你是用spark shell,那么当你启动Spark shell的时候,系统后台自启了一个Spark驱动器程序,就是在Spark shell中预加载的一个叫作 sc的SparkContext对象。如果驱动器程序终止,那么Spark应用也就结束了。主要负责:
(1)把用户程序转为任务
(2)跟踪Executor的运行状况
(3)为执行器节点调度任务
(4)UI展示应用运行状况
2)Executor(执行器)
Spark Executor是一个工作进程,负责在 Spark 作业中运行任务,任务间相互独立。Spark 应用启动时,Executor节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有Executor节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他Executor节点上继续运行。主要负责:
(1)负责运行组成 Spark 应用的任务,并将状态信息返回给驱动器进程;
(2)通过自身的块管理器(Block Manager)为用户程序中要求缓存的RDD提供内存式存储。RDD是直接缓存在Executor进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
总结:Master和Worker是Spark的守护进程,即Spark在特定模式下正常运行所必须的进程。Driver和Executor是临时进程,当有具体任务提交到Spark集群才会开启的进程。
3. Spark运行环境
①. Local模式-本地单机
Linux中查看有多少核数: [kris@hadoop101 ~]$ cat /proc/cpuinfo ... [kris@hadoop101 ~]$ cat /proc/cpuinfo | grep 'processor' | wc -l 8
Local模式
在一台计算机,可以设置Master; (提交任务时需要指定--master)Local模式又分为:
① Local所有计算都运行在一个线程中(单节点单线程),没有任何并行计算;
②Local[K] ,如local[4]即运行4个Worker线程(单机也可以并行有多个线程),可指定几个线程来运行计算,通常CPU有几个Core就执行几个线程,最大化利用cpu的计算能力;
③Local[*], 直接帮你安装Cpu最多Cores来设置线程数,这种是默认的;
1.安装:
tar zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
mv spark-3.0.0-bin-hadoop3.2.tgz spark-local
2.启动local环境:
[kris@hadoop101 spark-local]$ bin/spark-shell
Spark context Web UI available at http://192.168.1.101:4040
Spark context available as 'sc' (master = local[*], app id = local-1554255531204). ##spark core的入口sc
Spark session available as 'spark'. ##它是spark sql程序的入口
3.再起一个spark-shell会报错:
spark sql也有一个默认的元数据也是存在derby数据库里边
Failed to start database 'metastore_db' with class loader org.apache.spark.sql.hive.client.IsolatedClientLoader$$anon$1@63e5b8aa, see the next exception for details.
Caused by: org.apache.derby.iapi.error.StandardException: Another instance of Derby may have already booted the datab
4.启动成功后,可以输入网址进行Web UI监控页面访问 hadoop101:4040
5.在解压缩文件夹下的data目录中,添加word.txt文件
sc.textFile("data/word.txt").flatMap( _.split(" ") ).map((_,1)).reduceByKey(_+_).collect
6.任务的提交
提交任务(或者开启spark-shell)的时候会有driver和executor进程,Local模式下它被封装到了SparkSubmit中
bin/spark-submit \ //提供任务的命令
--class org.apache.spark.examples.SparkPi \ //指定运行jar的主类
--master local[*] \ //它有默认值是local[*] =>spark://host:port, mesos://host:port, yarn, or local.
--executor-memory 1G \ //指定每个executor可用内存
--total-executor-cores 2 \ //指定executor总核数
./examples/jars/spark-examples_2.11-2.1.1.jar \ \\jar包
100 //main方法中的args参数,程序的入口参数,用于设定当前应用的的任务数量
提交任务分析

driver和executor是干活的;
① Client提交任务--->②起一个Driver ---> ③注册应用程序,申请资源--资源管理者有 (Master(Standalone模式)、ResourceManage(yarn模式))-
④ 拿到资源后去其他节点启动Executor----> ⑤Executor会反向注册给Driver汇报;
⑥(把提交的jar包做任务切分,把任务发给具体执行的节点Executor)--->Driver会进行初始化sc、任务划分、任务调度
<===>Executor具体执行任务(负责具体执行任务、textFile、flatMap、map...)
⑦ Driver把任务发到Executor不一定会执行,有可能资源cpu或内存不够了或者executor挂了,spark会有一个容错机制,某一个挂了可转移到其他的Executor;
最后任务跑完了,Driver会向资源管理者申请注销(Executor也会注销)
数据流程
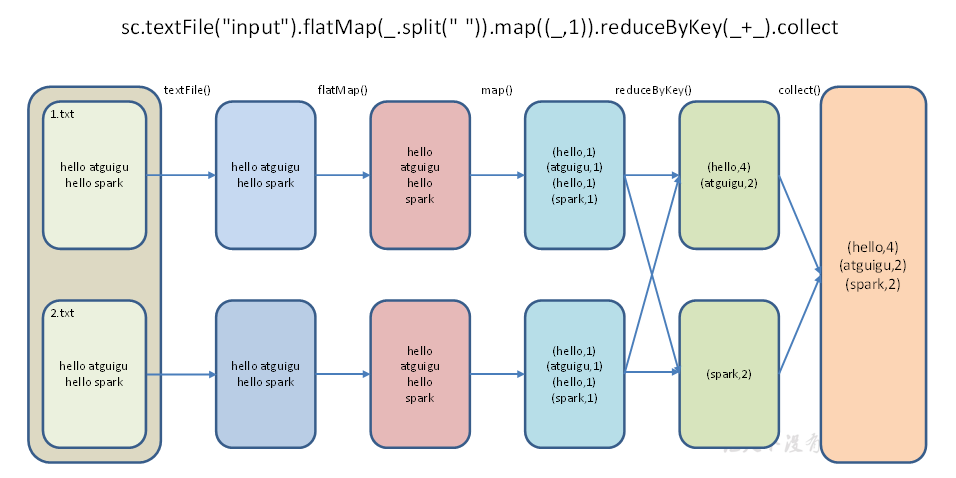
textFile("input") :读取本地文件input文件夹数据;
flatMap(_.split(" ")):压平操作,按照空格分割符将一行数据映射成一个个单词;
map((_,1)) :对每一个元素操作,将单词映射为元组;
reduceByKey(_+_) :按照key将值进行聚合,相加;
collect :将数据收集到Driver端展示。
②. Standalone模式--完全分布式
构建一个由Master+Slave构成的Spark集群,Spark运行在集群中;它的调度器是其实就是Master
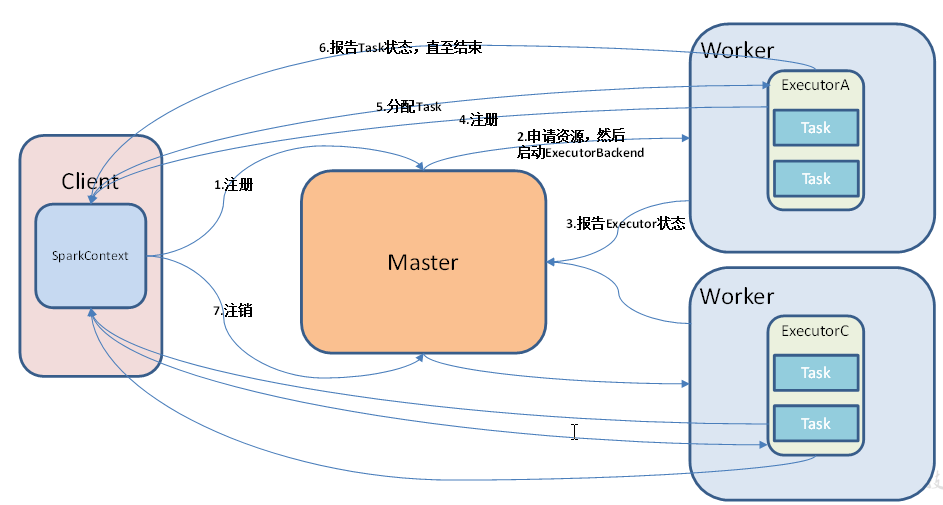
提交任务时需要有一个客户端Client,Master和Worker是守护进程它们是资源管理系统,提交任务(运行spark-shell或者spark-submit)之前它们就已经启动了;
①提交--->起Driver就是初始化SparkContext,然后启动Executor时需要资源;②向Master申请资源(即注册),启动ExecutorBackend
启动Executor---->反向注册给Driver汇报信息;
③ Driver划分切分任务把Task发送给Executor,如果Executor会有一个容错机制,Executor运行时会给Driver发送报告Task运行状态直至结束;
④最后任务运行完之后driver向master申请注销,Executor也会注销掉;
不一定非要在Client中起Driver(SparkContext),cluster模式,具体在哪个节点起sc由Master决定,随机的在worker节点上选择一个一个;
Driver在哪个节点起的原因:driver和executor之间是有通讯,每个 executor都要向driver汇报信息,互相通讯(消耗内存、资源+cpu数); 所有的executor节点都去跟driver做通讯,客户端的压力就会特别大;
Client是本地调试用,输入之后马上能看到输入的结果;
1.解压安装
tar zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-standalone
2.修改slave文件,添加work节点:
[kris@hadoop101 conf]$ vim slaves
hadoop101
hadoop102
hadoop103
3.修改spark-env.sh.template文件名为spark-env.sh, 修改spark-env.sh文件,
添加JAVA_HOME环境变量和集群对应的master节点修改spark-env.sh文件,添加如下配置:
[kris@hadoop101 conf]$ vim spark-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
#SPARK_MASTER_HOST=hadoop101
#SPARK_MASTER_PORT=7077 ##7077端口,相当于hadoop内部通信的8020端口,此处的端口需要确认自己的Hadoop配置
#配置历史服务
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080 #WEB UI访问的端口号为18080
-Dspark.history.retainedApplications=30 #指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
-Dspark.history.fs.logDirectory=hdfs://hadoop101:8020/directory" #指定历史服务器日志存储路径
#配置高可用时, 需要注释如下内容, 不配高可用时打开即可。
#SPARK_MASTER_HOST hadoop101
#SPARK_MASTER_PORT=7077export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop101,hadoop102,hadoop103
-Dspark.deploy.zookeeper.dir=/spark"
4. 配置历史服务
由于spark-shell停止后, 集群监控hadoop101:4040页面就看不到历史任务的的运行情况, 所以开发中都配置历史服务器记录任务运行情况。
修改spark-default.conf文件,开启Log
[kris@hadoop101 conf]$ vi spark-default.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop101:8020/directory
#注意:需要启动hadoop集群, HDFS上的目录需要提前存在。 hadoop fs -mkdir /directory
#注意:高可用情况下, 需要启动zookeeper
5.分发
xsync spark-standalone
6.启动集群
1) 在hadoop101上执行启动脚本命令:
sbin/start-all .sh
sbin/start-history-server.sh
2)在hadoop102中启动单独的Master节点,此时hadoop102中节点Master状态处于备用状态
sbin/start-master.sh
可查看页面hadoop101:8080
如果端口号8080冲突就修改下spark-env.sh
SPARK_MASTER_WEBUI_PORT= 8989 ##Master 监控页面默认访问端口为8080 ,但是可能会和Zookeeper冲突,所以改成8989 ,也可以自定义,访问UI监控页面时请注意
官方求PI案例
##运行之前上边的① ② ③步都要启动其他; 默认的是client模式
[kris@hadoop101 spark]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop101:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
./examples/jars/spark-examples_2.11-2.1.1.jar \
100
===>>
Pi is roughly 3.1417439141743913 启动spark shell /opt/module/spark/bin/spark-shell \ --master spark://hadoop101:7077 \ --executor-memory 1g \ --total-executor-cores 2 只要提交了任务就可以看到driver和executor,driver被封装在了SparkSubmit里边;CoarseGrainedExecutorBackend就是启动的executor 提交任务提交给哪个executor都是有可能的
执行WordCount程序 scala>sc.textFile("./wc.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
res0: Array[(String, Int)] = Array((Hello,2), (World,1), (java,2), (sbase,1), (spark,2), (Hi,1))
[kris@hadoop101 ~]$ jpsall
-------hadoop101-------
6675 DataNode
5971 Master
6100 Worker
7463 CoarseGrainedExecutorBackend #executor
7895 Jps
7368 SparkSubmit #driver
6527 NameNode
5855 QuorumPeerMain
-------hadoop102-------
4647 CoarseGrainedExecutorBackend #executor
4075 QuorumPeerMain
4875 Jps
4380 DataNode
4188 Worker
-------hadoop103-------
4432 SecondaryNameNode
4353 DataNode
4085 QuorumPeerMain
4198 Worker
4778 Jps
在Standalone--cluster模式下
[kris@hadoop101 spark-standalone]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop101:7077 \
--deploy-mode cluster \
--executor-memory 1G \
--total-executor-cores 2 \
./examples/jars/spark-examples_2.11-2.1.1.jar \
100
任务未执行完时的进程:
[kris@hadoop101 spark-standalone]$ jpsall
-------hadoop101-------
16740 CoarseGrainedExecutorBackend
16404 HistoryServer
16006 NameNode
15686 Master
16842 Jps
15805 Worker
16127 DataNode
-------hadoop102-------
10240 CoarseGrainedExecutorBackend
10021 DataNode
9911 Worker
10334 Jps
-------hadoop103-------
9824 DataNode
9714 Worker
9944 SecondaryNameNode
10299 Jps
10093 DriverWrapper ##cluster 模式下的Driver
任务执行完的进程:
[kris@hadoop101 spark-standalone]$ jpsall
-------hadoop101-------
16404 HistoryServer
16006 NameNode
15686 Master
15805 Worker
17166 Jps
16127 DataNode
-------hadoop102-------
10021 DataNode
9911 Worker
10447 Jps
-------hadoop103-------
10416 Jps
9824 DataNode
9714 Worker
9944 SecondaryNameNode
spark-shell的 spark HA集群访问,前提是另外一个Master启起来了;
/opt/module/spark/bin/spark-shell \ --master spark://hadoop101:7077,hadoop102:7077 \ --executor-memory 1g \ --total-executor-cores 2
把其中ACTIVE状态节点的kill掉,另外一个Master的状态将从standby模式--->active状态;
可验证下:
scala>sc.textFile("./wc.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
res0: Array[(String, Int)] = Array((Hello,2), (World,1), (java,2), (sbase,1), (spark,2), (Hi,1))
提交任务时:
--deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or
on one of the worker machines inside the cluster ("cluster")
(Default: client).
client和cluster的区别:
SparkContext的位置不同(也就是运行Driver的位置不一样),由Master决定,随机的在其他节点初始化一个sc
Driver和Executor之间会有通信,通信需要消耗资源内存cpu等,所有的executor去和客户端(如果是client模式,Driver是启在Client上的)去通信,
客户端的压力会非常大,如果有大量的executor再加上提交多个任务就启动多个Driver,那么Client单点就挂掉被拖垮;
cluster模式,每次提交任务时的sc的位置分散在不同节点上,分担了压力,
Client本地调试时候用,可以看到输出的结果,如可看到打印的π
--deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or
on one of the worker machines inside the cluster ("cluster")
(Default: client).
--executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode,
or all available cores on the worker in standalone mode)
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop101:7077 \
--deploy-mode cluster \
--executor-memory 1G \
--total-executor-cores 2 \ ##总的是2,默认1个cores/executor--->推导出有2/1个executor;可控制executor的数量;
./examples/jars/spark-examples_2.11-2.1.1.jar \
100
cluster模式下,driver叫DriverWrapper
③. Yarn模式
概述
之前的standalone模式,是自己Master和worker管理资源,分发是为了在各个节点启进程;yarn模式资源由RM、NM来管理
Spark客户端直接连接Yarn,不需要额外构建Spark集群。有yarn-client和yarn-cluster两种模式,主要区别在于:Driver程序的运行节点。
yarn-client:Driver程序运行在客户端,适用于交互、调试,希望立即看到app的输出;
yarn-cluster:Driver程序运行在由RM(ResourceManager)启动的AM(APPMaster)适用于生产环境。分担压力不会拖垮某个节点;
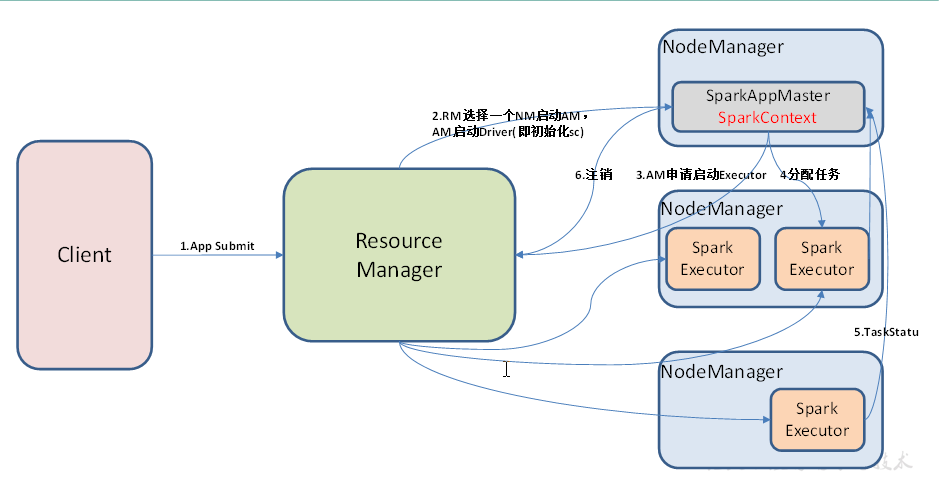
提交任务之前,客户端Client、ResourceManager、NodeManager都是要启动好的;
提交任务,App Submit; RM选择一个NM启动AM,AM来启动Driver(即初始化sc),yarn的cluster模式SparkAppMaster(用来申请资源,启动driver)和SparkContext在一个进程里边;
AM(SparkAppMaster)向RM申请启动Executor;(默认情况下一个节点启一个executor这样子负载比较均衡,也可以启两个),executor也是有个反向注册的过程;
切分分配任务,同时executor上报集群状况;跑完之后申请注销;
安装使用
1)修改hadoop配置文件yarn-site.xml,添加如下内容:
[kris@hadoop101 hadoop]$ vim yarn-site.xml
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
2)配置历史服务JobHistoryServer| 配置日志查看功能
修改spark-env.sh,添加如下配置:
[kris@hadoop101 conf]$ vim spark-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144 YARN_CONF_DIR=/opt/module/hadoop-2.7.2/etc/hadoop # 配置JobHistoryServer 注意:HDFS上的目录需要提前存在。 export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=30 -Dspark.history.fs.logDirectory=hdfs://hadoop101:9000/directory"
从这里看到历史日志:http://hadoop102:8088/cluster点击直接跳转到spark中 http://hadoop101:18080/history/application_1554294467331_0001/jobs/
[kris@hadoop101 conf]$ vim spark-defaults.conf
#修改spark-default.conf文件,开启Log: spark.eventLog.enabled true spark.eventLog.dir hdfs://hadoop101:9000/directory # 日志查看 spark.yarn.historyServer.address=hadoop101:18080 spark.history.ui.port=18080
Yarn-client 模式
提交任务到Yarn执行 [kris@hadoop101 spark-yarn]$ bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode client \ ./examples/jars/spark-examples_2.11-2.1.1.jar \ 100
[kris@hadoop101 spark-yarn]$ bin/spark-shell --master yarn ##shell只能用client模式启动,默认的也是这种模式;
Spark context Web UI available at http://192.168.1.101:4040
Spark context available as 'sc' (master = yarn, app id = application_1554290192113_0004).
Spark session available as 'spark'.
-------hadoop101-------
25920 NodeManager
25751 DataNode
28075 SparkSubmit ##Driver还是被封装到这里边的
28252 Jps
25469 QuorumPeerMain
25630 NameNode
-------hadoop102-------
14995 CoarseGrainedExecutorBackend
15076 Jps
13447 DataNode
13672 NodeManager
13369 QuorumPeerMain
13549 ResourceManager
14942 ExecutorLauncher #Executor启动器,就是AppMaster,Cluster模式,AM和sc在一个进程里边的,这种模式AM的任务是:既可以申请资源又可以做任务切分和调度;
Client模式它们就不在一个进程了,由RM随机选择一个节点来启动AM,这种模式它的作用仅仅是用来申请资源去启动Executor;
-------hadoop103-------
13536 DataNode
14610 CoarseGrainedExecutorBackend
14691 Jps
13638 NodeManager
13464 QuorumPeerMain
13710 SecondaryNameNode
yarn--cluster模式
[kris@hadoop101 spark-yarn]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.11-2.1.1.jar
在任务未完成之前的进程:
[kris@hadoop101 spark-yarn]$ jpsall
-------hadoop101-------
13328 SparkSubmit
12146 NodeManager
13706 CoarseGrainedExecutorBackend
12555 NameNode
12702 DataNode
13951 Jps
-------hadoop102-------
6864 ResourceManager
8101 Jps
7403 DataNode
6990 NodeManager
-------hadoop103-------
7984 ApplicationMaster ## Yarn-Cluster模式下SparkAppMaster和Sparkcontext即Driver是在一个进程的
8432 Jps
7560 SecondaryNameNode
8158 CoarseGrainedExecutorBackend
7230 NodeManager
7438 DataNode
任务完成之后的进程:
[kris@hadoop101 spark-yarn]$ jpsall
-------hadoop101-------
12146 NodeManager
12555 NameNode
12702 DataNode
14031 Jps
-------hadoop102-------
6864 ResourceManager
8153 Jps
7403 DataNode
6990 NodeManager
-------hadoop103-------
7560 SecondaryNameNode
8537 Jps
7230 NodeManager
7438 DataNode
[kris@hadoop101 spark-yarn]$ sbin/start-history-server.sh ##开启历史服务
提交任务到Yarn执行 [kris@hadoop101 spark-yarn]$ bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode client \ ./examples/jars/spark-examples_2.11-2.1.1.jar \ 100


Mesos模式
Spark客户端直接连接Mesos;不需要额外构建Spark集群。国内应用比较少,更多的是运用yarn调度。
几种模式对比

package com.atguigu.spark import org.apache.spark.{SparkConf, SparkContext} object WordCount { def main(args: Array[String]): Unit = { //1.创建SparkConf并设置App名称 val conf = new SparkConf().setAppName("WordCount") //2.创建SparkContext,该对象是提交Spark App的入口 val context = new SparkContext(conf) //3.使用sc创建RDD并执行相应的transformation和action context.textFile(args(0)).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_, 1).sortBy(_._2, false).saveAsTextFile(args(1)) //4.关闭连接 context.stop() } }
/wc.txt必须在HDFS上有这个文件
[kris@hadoop101 spark-yarn]$ hadoop fs -put wc.txt / [kris@hadoop101 spark-yarn]$ bin/spark-submit --class com.atguigu.spark.WordCount --master yarn --deploy-mode client /opt/module/spark/spark-yarn/WordCount.jar /wc.txt /out 结果: (Hello,3) (smile,2) (kris,2) (alex,1) (hi,1)



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2018-04-05 第五章| 5.1面向对象-继承 |封装 |多态
2018-04-05 函数| 常用模块总结练习
2018-04-05 ATM+购物车商城