
Kylin |1.麒麟架构及原理
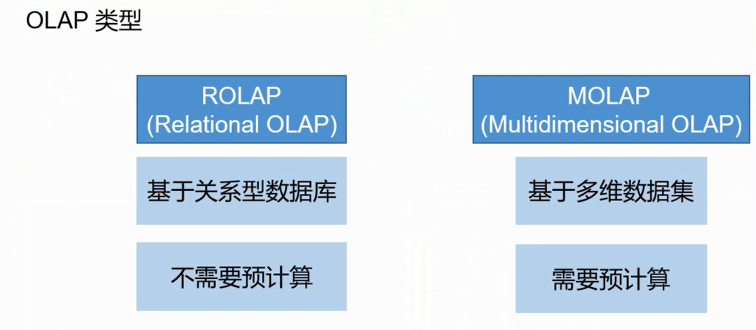
OLAP(online analytical processing)
OLAP是一种软件技术,它使分析人员迅速、一致、交互地从各个方面观察信息,以达到深入理解数据的目的,从各方面观察信息,也就是从不同的维度分析数据,因为OLAP也称为多维分析。
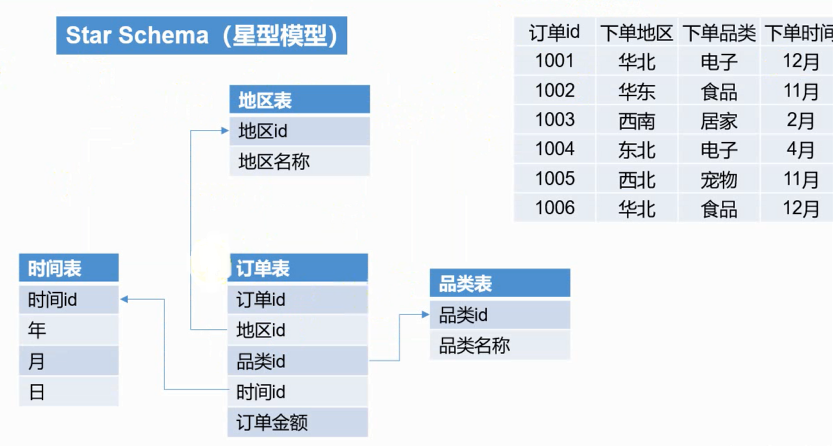
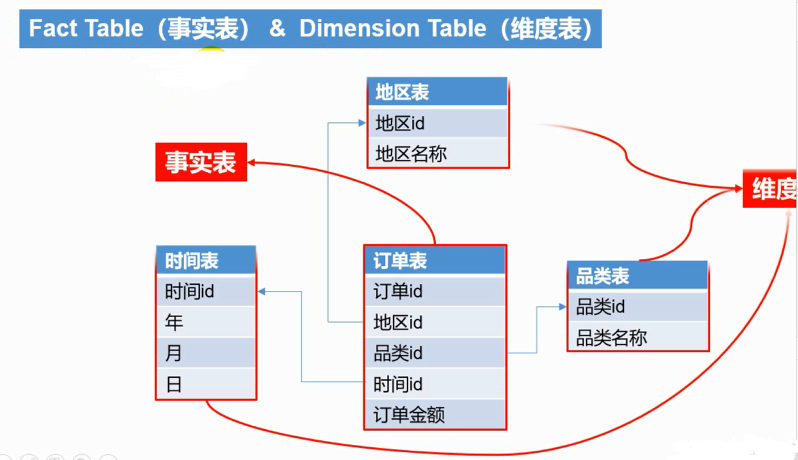
Kylin对接的就是数仓中的dwd层星型模型 或雪花模型。
1. Kylin架构
官网地址 http://kylin.apache.org/cn/
官方文档 http://kylin.apache.org/cn/docs/
下载地址 http://kylin.apache.org/cn/download/
开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(MOLAP)能力以支持超大规模数据,能在亚秒内查询巨大的Hive表;
Kylin的主要特点包括支持SQL接口、支持超大规模数据集、亚秒级响应、可伸缩性、高吞吐率、BI工具集成等。
MR Hive
M(多维)OLAP连接分析处理的引擎
Hive--->Kylin--->Hbase

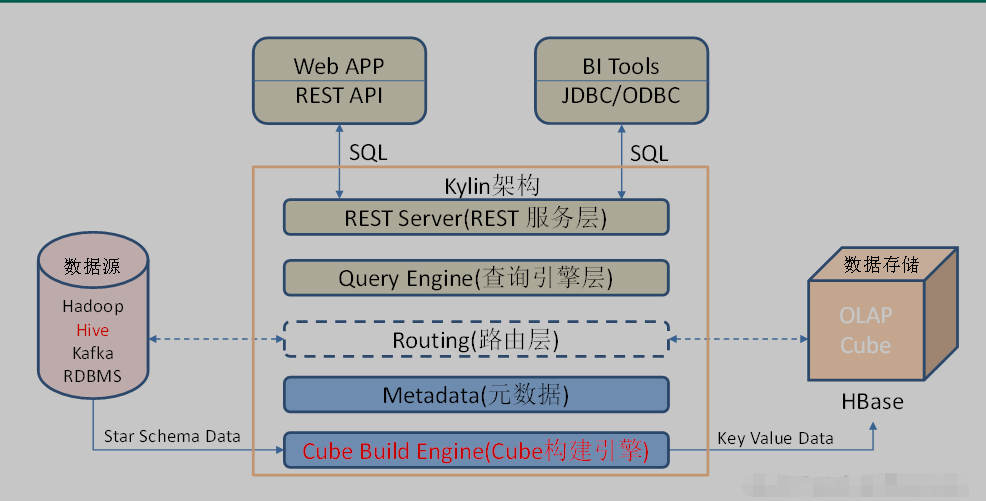
第一部分:
Metadata(元数据管理工具)和Cube Build Engine构建引擎(做分析运算),离线-提前算-预计算。
Metadata 元数据管理工具是一大关键性组件,用于对保存在Kylin当中的所有元数据进行管理,其中包括最为重要的cube元数据。其它全部组件的正常运作都需以元数据管理工具为基础。 Kylin的元数据存储在hbase中。
构建引擎设计目的在于处理所有离线任务,其中包括shell脚本、Java API以及Map Reduce任务等等。任务引擎对Kylin当中的全部任务加以管理与协调,从而确保每一项任务都能得到切实执行并解决其间出现的故障。
第二部分:对外查询(实时)输出:
REST Server(接收请求)-->
REST Server是一套面向应用程序开发的入口点,旨在实现针对Kylin平台的应用开发工作。 此类应用程序可以提供查询、获取结果、触发cube构建任务、获取元数据以及获取用户权限等等。另外可以通过Restful接口实现SQL查询。
Query Engine(sql语法解析)
当cube准备就绪后,查询引擎就能够获取并解析用户查询。它随后会与系统中的其它组件进行交互,从而向用户返回对应的结果。
Routing(连接HBase)
在最初设计时曾考虑过将Kylin不能执行的查询引导去Hive中继续执行,但在实践后发现Hive与Kylin的速度差异过大,导致用户无法对查询的速度有一致的期望,很可能大多数查询几秒内就返回结果了,而有些查询则要等几分钟到几十分钟,因此体验非常糟糕。最后这个路由功能在发行版中默认关闭。
Metadata(元数据管理工具)
需要调用使用的场景:
第三方App REST-API-->基于http协议
BI tools:Tableau..企业级商业智能-可视化界面-->基于jdbc、ODBC(windows/ linux)
Kylin的主要特点
支持SQL接口、支持超大规模数据集、亚秒级响应、可伸缩性、高吞吐率、BI工具集成等。
1)标准SQL接口:Kylin是以标准的SQL作为对外服务的接口。
2)支持超大数据集:Kylin对于大数据的支撑能力可能是目前所有技术中最为领先的。早在2015年eBay的生产环境中就能支持百亿记录的秒级查询,之后在移动的应用场景中又有了千亿记录秒级查询的案例。
3)亚秒级响应:Kylin拥有优异的查询相应速度,这点得益于预计算,很多复杂的计算,比如连接、聚合,在离线的预计算过程中就已经完成,这大大降低了查询时刻所需的计算量,提高了响应速度。
4)可伸缩性和高吞吐率:单节点Kylin可实现每秒70个查询,还可以搭建Kylin的集群。
5)BI工具集成
Kylin可以与现有的BI工具集成,具体包括如下内容。
- ODBC:与Tableau、Excel、PowerBI等工具集成
- JDBC:与Saiku、BIRT等Java工具集成
- RestAPI:与JavaScript、Web网页集成
Kylin开发团队还贡献了Zepplin的插件,也可以使用Zepplin来访问Kylin服务。
2. Kylin工作原理
本质上是MOLAP(Multidimension On-Line Analysis Processing)Cube,也就是多维立方体分析;
维度和度量
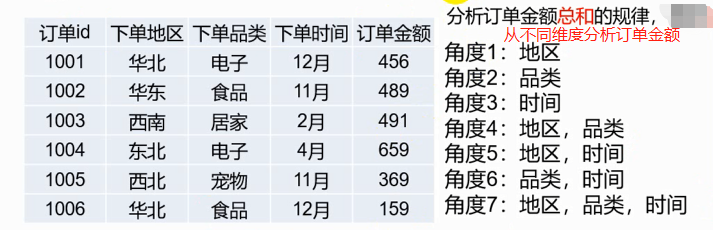
23 - 1 = 7 种维度,假如有n种维度,一种有2n - 1 种组合维度。 订单金额为度量,下单地区、下单品类、下单时间为维度。
确定分析角度-即维度(观察数据的角度)
具体聚合运算:count, avg, sum-即度量(被聚合(观察)的统计值,也就是聚合运算的结果)
维度:即观察分析数据的角度。比如员工数据,可以从性别角度来分析,也可以更加细化,从入职时间或者地区的维度来观察。
维度是一组离散的值,比如说性别中的男和女,或者时间维度上的每一个独立的日期。因此在统计时可以将维度值相同的记录聚合在一起,然后应用聚合函数做累加、平均、最大和最小值等聚合计算。
度量:即被聚合分析(观察)的指标值,也就是聚合运算的结果。比如说员工数据中不同性别员工的人数,又或者说在同一年入职的员工有多少。
Cube和Cuboid
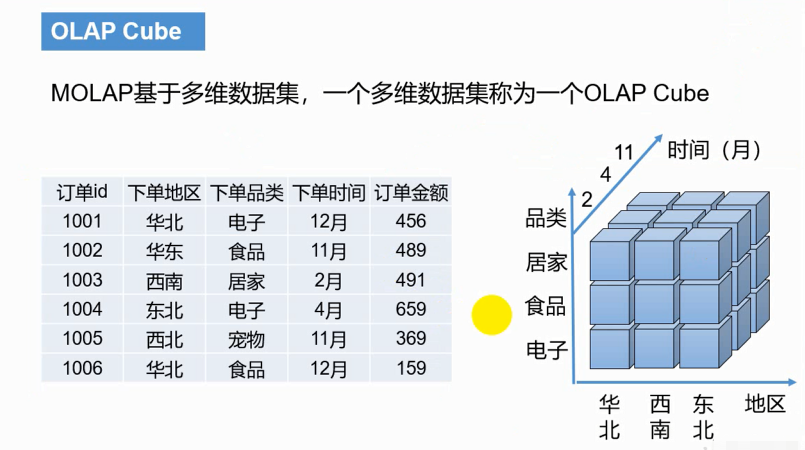
一个小方块叫cubeid,比如居家、东北坐标对应的方块cubeid,它代表的是多行数据,
有了维度跟度量,一个数据表或者数据模型上的所有字段就可以分类了,它们要么是维度,要么是度量(可以被聚合)。于是就有了根据维度和度量做预计算的Cube理论。
给定一个数据模型,我们可以对其上的所有维度进行聚合,对于N个维度来说,组合的所有可能性共有2n种。对于每一种维度的组合,将度量值做聚合计算,然后将结果保存为一个物
化视图,称为Cuboid。所有维度组合的Cuboid作为一个整体,称为Cube。

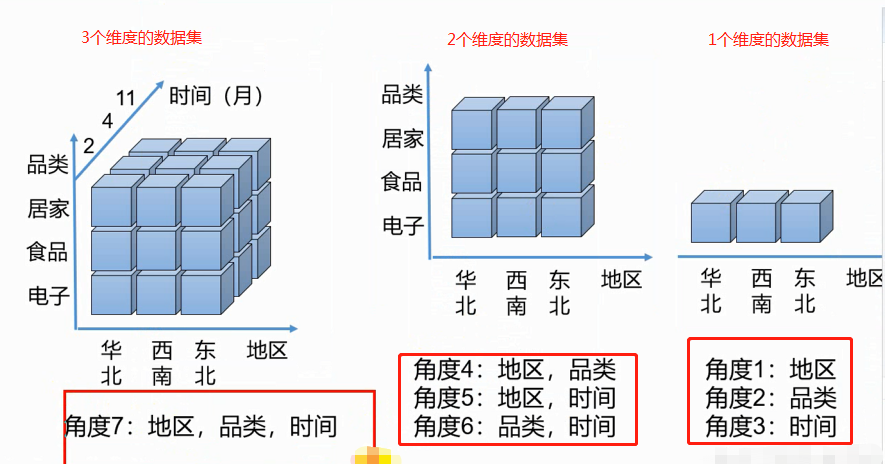
4个维度组合: abcd abc abc bcd ab cd ac bd a b c d 零维... n个维度---组合--->2^n个cuboid
一个N维的Cube,是由1个N维子立方体、N个(N-1)维子立方体、N*(N-1)/2个(N-2)维子立方体、......、N个1维子立方体和1个0维子立方体构成,总共有2^N个子立方体组成
每种维度组合--->cuboid,所有维度组合的cuboid作为一个整体---->cube(立方体)。
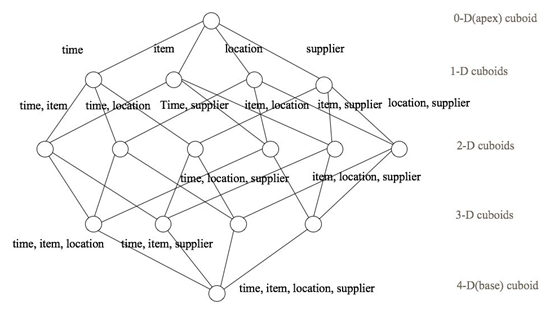
假设有一个电商的销售数据集,其中维度包括时间[time]、商品[item]、地区[location]和 供应商[supplier],度量为销售额。那么所有维度的组合就有24 = 16种
(0维度)不算维度,只计算销售额 C40 = 1;
(1个维度)C41 有4种;
(2个维度)任意两两组合C42 = 6 种;
(3个维度)C43 = 4
(4个维度)C44 = 1
注意:每一种维度组合就是一个Cuboid,16个Cuboid整体就是一个Cube。
核心算法
Kylin的工作原理就是对数据模型做Cube预计算,并利用计算的结果加速查询:
1)指定数据模型,定义维度和度量;
2)预计算Cube,计算所有Cuboid并保存为 物化视图;
预计算过程是Kylin从Hive中读取原始数据,按照我们选定的维度进行计算,并将结果集保存到Hbase中,默认的计算引擎为MapReduce,可以选择Spark作为计算引擎。一次build的
结果,我们称为一个Segment。构建过程中会涉及多个Cuboid的创建,具体创建过程由kylin.cube.algorithm参数决定,参数值可选 auto,layer 和 inmem, 默认值为 auto,即
Kylin 会通过采集数据动态地选择一个算法 (layer or inmem),如果用户很了解 Kylin 和自身的数据、集群,可以直接设置喜欢的算法。
3)执行查询,读取Cuboid,运行,产生查询结果。
①分层算 MR--逐层构建算法(layer)

一个N维的Cube,是由1个N维子立方体、N个(N-1)维子立方体、N*(N-1)/2个(N-2)维子立方体、......、N个1维子立方体和1个0维子立方体构成,总共有2^N个子立方体组成,在逐层算
法中,按维度数逐层减少来计算,每个层级的计算(除了第一层,它是从原始数据聚合而来),是基于它上一层级的结果来计算的。比如,[Group by A, B]的结果,可以基于[Group
by A, B, C]的结果,通过去掉C后聚合得来的;这样可以减少重复计算;当 0维度Cuboid计算出来的时候,整个Cube的计算也就完成了。
每一轮的计算都是一个MapReduce任务,且串行执行;一个N维的Cube,至少需要N次MapReduce Job。
算法优点:
1)此算法充分利用了MapReduce的能力,处理了中间复杂的排序和洗牌工作,故而算法代码清晰简单,易于维护;
2)受益于Hadoop的日趋成熟,此算法对集群要求低,运行稳定;在内部维护Kylin的过程中,很少遇到在这几步出错的情况;即便是在Hadoop集群比较繁忙的时候,任务也能完成。
算法缺点:
1)当Cube有较多维度时,所需要的MapReduce任务也相应增加;由于Hadoop的任务调度需耗费额外资源,特别是集群较庞大时,反复递交任务造成的额外开销会相当可观;
2)由于Mapper不做预聚合,此算法会对Hadoop MapReduce输出较多数据; 虽然使用了Combiner来减少从Mapper端到Reducer端的数据传输,所有数据依然需要通过Hadoop
MapReduce来排序和组合才能被聚合,无形之中增加了集群的压力;
3)对HDFS的读写操作较多:由于每一层计算的输出会用做下一层计算的输入,这些Key-Value需要写到HDFS上;当所有计算都完成后,Kylin还需要额外的一轮任务将这些文件转成
HBase的HFile格式,以导入到HBase中去;
总体而言,该算法的效率较低,尤其是当Cube维度数较大的时候。
高维---->低维; 数据基于高维,递进过程
缺点:每层都有mr; 每层都要从hdfs读取,大量IO; 简单繁琐
在逐层算法中,按维度数逐层减少来计算,每个层级的计算(除了第一层,它是从原始数据聚合而来),是基于它上一层级的结果来计算的。
每一轮的计算都是一个MapReduce任务,且串行执行;一个N维的Cube,至少需要N次MapReduce Job。
②快速构建算法(inmem)
也被称作“逐段”(By Segment) 或“逐块”(By Split) 算法,从1.5.x开始引入该算法,利用Mapper端计算先完成大部分聚合,再将聚合后的结果交给Reducer,从而降低对网络瓶颈的压
力。该算法的主要思想是,对Mapper所分配的数据块,将它计算成一个完整的小Cube 段(包含所有Cuboid);每个Mapper将计算完的Cube段输出给Reducer做合并,生成大
Cube,也就是最终结果;如图
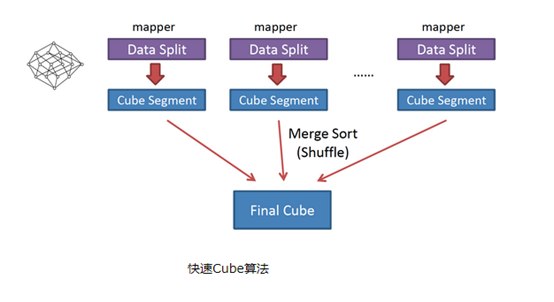
需要算所有维度,一次mr 即可; 多个切片-->多个map数; 做所有keyboid运算; 所有map汇总及cube结果
省去mr资源调度;减少了io; map已经没重复的key, reducer只需对每个map去重减少了reducer的工作量;
与旧算法相比,快速算法主要有两点不同:
1) Mapper会利用内存做预聚合,算出所有组合;Mapper输出的每个Key都是不同的,这样会减少输出到Hadoop MapReduce的数据量,Combiner也不再需要;
2)一轮MapReduce便会完成所有层次的计算,减少Hadoop任务的调配。
关于这两个算法麒麟会自动选择;
3. Kylin环境搭建
需要在/etc/profile文件中配置HADOOP_HOME,HIVE_HOME,HBASE_HOME并source使其生效
/etc/profile


#JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_144 export PATH=$PATH:$JAVA_HOME/bin #HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-2.7.2 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin #HIVE_HOME export HIVE_HOME=/opt/module/hive export PATH=$PATH:$HIVE_HOME/bin ##HBASE_HOME export HBASE_HOME=/opt/module/hbase-1.3.1 export PATH=$PATH:$HBASE_HOME/bin #KYLIN_HOME export KYLIN_HOME=/opt/module/kylin export PATH=$PATH:$KYLIN_HOME/bin
1)将apache-kylin-2.5.1-bin-hbase1x.tar.gz上传到Linux
2)解压apache-kylin-2.5.1-bin-hbase1x.tar.gz到/opt/module
[kris@hadoop101 sorfware]$ tar -zxvf apache-kylin-2.5.1-bin-hbase1x.tar.gz -C /opt/module/
注意:需要在/etc/profile文件中配置HADOOP_HOME,HIVE_HOME,HBASE_HOME并source使其生效。
3)启动
[kris@hadoop101 kylin]$ bin/kylin.sh start
启动Kylin之前要保证HDFS,YARN,ZK,HBASE相关进程是正常运行的。
--------------------- hadoop101 ----------------
3360 JobHistoryServer
31425 HMaster
3282 NodeManager
3026 DataNode
53283 Jps
2886 NameNode
44007 RunJar
2728 QuorumPeerMain
31566 HRegionServer
--------------------- hadoop102 ----------------
5040 HMaster
2864 ResourceManager
9729 Jps
2657 QuorumPeerMain
4946 HRegionServer
2979 NodeManager
2727 DataNode
--------------------- hadoop103 ----------------
4688 HRegionServer
2900 NodeManager
9848 Jps
2636 QuorumPeerMain
2700 DataNode
2815 SecondaryNameNode
http://hadoop101:7070/kylin 查看Web页面
用户名为:ADMIN,密码为:KYLIN(系统已填)



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2018-03-13 第二章| python数据类型| 基本数据类型| 数据集列表元组字典集合
2018-03-13 第一模块总结