
Impala
1. 概述
Cloudera公司推出,提供对HDFS、Hbase数据的高性能、低延迟的交互式SQL查询功能。基于Hive,使用内存计算,兼顾数据仓库、具有实时、批处理、多并发等优点。
是CDH平台首选的PB级大数据实时查询分析引擎。
1.1 优点
1) 基于内存运算,不需要把中间结果写入磁盘,省掉了大量的I/O开销。
2) 无需转换为Mapreduce,直接访问存储在HDFS,HBase中的数据进行作业调度,速度快。
3) 使用了支持Data locality的I/O调度机制,尽可能地将数据和计算分配在同一台机器上进行,减少了网络开销。
4) 支持各种文件格式,如TEXTFILE 、SEQUENCEFILE 、RCFile、Parquet。
5) 可以访问hive的metastore,对hive数据直接做数据分析。
1.2 缺点
1) 对内存的依赖大,且完全依赖于hive。
2) 实践中,分区超过1万,性能严重下降。
3) 只能读取文本文件,而不能直接读取自定义二进制文件。
4) 每当新的记录/文件被添加到HDFS中的数据目录时,该表需要被刷新。
1.3 Impala的架构
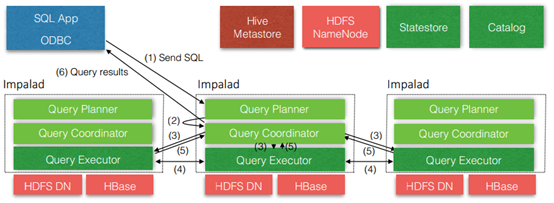
Impala自身包含三个模块:Impalad(Impalad-deamon守护进程)、Statestore和Catalog,除此之外它还依赖Hive Metastore(访问)和HDFS(hive、impala、hbase等的数据都是存储在hdfs)。
1) Impala daemon:
接收client的请求、Query执行(分析处理这些sql语句)并返回给中心协调节点;子节点上的守护进程,负责向statestore保持通信,汇报工作。
处理sql语句的机制:接收到请求,把sql语句转为Query Planner查询计划----->Query Coordinator协调器(它会把相关的计划交给执行器Query Executor执行具体交给哪个就体现了数据本地化的特点),数据在哪个节点上它就会把执行计划给哪个协调器;Executor之间也会进行交互;处理完之后再交给中心协调器Query Coordinator----->>客户端。
与DataNode运行在同一节点上,是Impala的核心组件,在每个节点上这个进程的名称为Impalad。该进程负责读写数据文件;接受来自Impala-shell、Hue、JDBC、ODBC等客 户端的查询请求(接收查询请求的Impalad为Coordinator),Coordinator通过JNI调用java前端解释SQL查询语句,生成查询计划树,再通过调度器把执行计划分发给具有相应 数据的其它节点分布式并行执行,并将各节点的查询结果返回给中心协调者节点Coordinator,再由该节点返回给客户端。同时Impalad会与State Store保持通信,以了解其 他节点的健康状况和负载。
2) Catalog Server:
分发表的元数据信息到各个impalad中(对元数据的同步,与Hive Metastore进行交互拿到元数据同步给各个inpalad deamon节点);接收来自statestore的所有请求。
把impala表的metadata分发到各个impalad 中,说他是基于hive 的,所以就需要metadata数据分到impalad 中,以前没有此进程,就是手动来进行同步的。虽然之后加入了, 但是也没有那么智能,并不是保证所有的数据都能同步,比如你插入一些数据,他可以把数据发到其他节点,但是比如创建表ddl 语句,建议去手动做一下。接收来自 statestore 的所有请求,当impala deamon节点插入或者查询数据时候(数据改变的时候),他把自己的操作结果汇报给state deamon,然后state store 请求catelog deamon,告知重 新更新元数据信息给impalad 中,所以catalog deamon 与statedeamon 放到一台机器上,而且不建议在此机器上再去安装impala deamon 进程,避免造成提供查询造成集群管 理出问题;
3) Statestore daemon:
负责收集分布在集群中各个impalad进程的资源信息、各节点健康状况,进行整合汇总;同步节点信息;负责query的协调调度。
该进程负责搜集集群中Impalad进程节点的健康状况,它通过创建多个线程来处理Impalad的注册订阅,并与各节点保持心跳连接,不断地将健康状况的结果转发给所有的 Impalad进程节点。一个Impala集群只需一个statestored进程节点,当某一节点不可用时,该进程负责将这一信息传递给所有的Impalad进程节点,再有新的查询时不会把请 求发送到不可用的Impalad节点上。 statestored也是允许挂掉的,不会影响集群运行,因为impalad节点之间也会保持通信,但是当statestored和某一部分impalad都挂掉了,就会出问题,因为没有了statestored, 而impalad节点之间并不能识别出是否有某些impalad挂了,依然会与挂掉的impalad通信,此时就会出问题;
2. 自动化安装
注意:
1) 关闭(修改hdfs的配置dfs.permissions为false)或修改hdfs的权限,否则impala没有写的权限; 2)Impala不支持将本地文件导入到表中
[hdfs@hadoop104 ~]$ hadoop fs -chmod -R 777 /
[hdfs@hadoop104 init.d]$ su - hdfs ##su用户切换时 加 - 是会把环境也切换过来;建议用这种形式; [hdfs@hadoop104 init.d]$ hadoop fs -chmod -R 777 / [hdfs@hadoop104 init.d]$ exit ###不要直接su套用户,先exit结束掉 exit [root@hadoop104 init.d]#
进入客户端进行读写(这些命令都在/opt/cloudera/parcels/CDH/bin)
[root@hadoop104 ~]# impala-shell 在hadoop104上启动客户端连不上,去连接impalad-deamon进行处理; 但104没有这个节点;
impala-shell -help

[root@hadoop104 ~]# impala-shell -i hadoop105 ##默认连接的是本地;让它去连接别的加 -i ,默认端口号是21000,可不写
Starting Impala Shell without Kerberos authentication
Connected to hadoop105:21000
create table student(id int, name string) row format delimited fields terminated by "\t";
desc formatted student;
insert into table student select。。。
insert into table student values(1001, "alex"), (1002, "kris"); ##into是往后边追加;在HDFS上是追加到一个新文件;
insert overwrite table student values (1003, "jing"), (1004, "zk"); ##它会把之前的内容给覆盖掉;
3. Impala的shell命令
3.1 Impala的外部shell命令
shell -e+sql语句 -f+sql脚本
[root@hadoop104 ~]# impala-shell -help
① impala-shell -i hadoop105 -q 'select * from student'
vim impala.sql
select * from student; ##可以插入多条语句
② impala-shell -i hadoop105 -f impala.sql
③ impala-shell -i hadoop105 -f impala.sql -o resulet.txt ##-o 是执行结果存储到本地文件夹result.txt中
④ impala-shell -i hadoop105 -f impala.sql -o resulet.txt -B
-B格式化,tab分隔符,把外边的框框去掉了;
⑤ impala-shell -i hadoop105 -f impala.sql -o resulet.txt -B --print_header ##把标题头打印出来
⑥ impala-shell -i hadoop105 -f impala.sql -o resulet.txt -B --print_header --output_delimiter='|' 分隔符
⑦ --verbose 默认true,打印信息;
[hadoop105:21000] > select * from student;
Query: select * from student
Query submitted at: 2019-02-26 18:33:32 (Coordinator: http://hadoop105:25000)
Query progress can be monitored at: http://hadoop105:25000/query_plan?query_id=154d54075a0ed555:f84f23ee00000000
+------+------+
| id | name |
+------+------+
| 1003 | jing |
| 1004 | zk |
| 1002 | kris |
+------+------+
⑧ impala-shell -i hadoop105 --quiet 不打印详细信息;本次有效,重启下就还是默认的;
[hadoop105:21000] > select * from student;
+------+------+
| id | name |
+------+------+
| 1002 | kris |
| 1003 | jing |
| 1004 | zk |
+------+------+
[hadoop105:21000] > quit;
⑨ [root@hadoop104 ~]# impala-shell -i hadoop105 -v #版本
Impala Shell v2.9.0-cdh5.12.1 (5131a03) built on Thu Aug 24 09:27:32 PDT 2017
impala-shell -i hadoop105 -f impala.sql
11. impala-shell -i hadoop105 -f impala.sql -c #-c是忽略查询错误,直接跳过去执行其他的;错误的那行必须加;不然后边正确的也执行不了;
从hive中先student表中插入一条语句:
select * from student;
quit;
12. impala-shell -i hadoop105 -r ##--refresh_after_connect;所有表数据都会更新;退出重新进入,不刷新还是没有更新之前的,必须要加-r
select * from student;
-d DEFAULT_DB, --database=DEFAULT_DB
13. impala-shell -i hadoop105 -p ##--show_profiles
select * from student; ##查询的每一条语句都会出现底层详细信息
详细底层信息; hive的执行计划explain
3.2 Impala的内部shell
查看执行计划,也可以对集群进行优化
① explain select * from student; #-p更详细;
② profile; 跟-p是一样的;直接打印出profile,它显示出上一个命令的详细信息
[hadoop105:21000] > select * from student profile; #加不加没有区别
Query: select * from student profile
Query submitted at: 2019-02-28 10:54:27 (Coordinator: http://hadoop105:25000)
Query progress can be monitored at: http://hadoop105:25000/query_plan?query_id=f0403144672a4e51:8138224900000000
+----+------+
| id | name |
+----+------+
| 4 | dd |
| 1 | aa |
| 2 | bb |
| 3 | cc |
+----+------+
Fetched 4 row(s) in 0.13s
hive> dfs -ls /; #查看hdfs上的文件 ##等同于 !sh hadoop fs -ls /; ### ! hadoop fs -ls /;
Found 3 items
-rw-r--r-- 3 root supergroup 346 2019-02-26 08:51 /log4j.log
drwxrwxrwt - hdfs supergroup 0 2019-02-25 22:45 /tmp
drwxrwxrwx - hdfs supergroup 0 2019-02-26 10:04 /user
0: jdbc:hive2://hadoop104:10000> !sh hadoop fs -ls / ##hdfs上的文件信息
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=512M; support was removed in 8.0
Found 3 items
-rw-r--r-- 3 root supergroup 346 2019-02-26 08:51 /log4j.log
drwxrwxrwt - hdfs supergroup 0 2019-02-25 22:45 /tmp
drwxrwxrwx - hdfs supergroup 0 2019-02-26 10:04 /user
0: jdbc:hive2://hadoop104:10000> !sh ls ./ #当前linux目录下的文件
impala.sql
log4j.log
result.txt
student.txt
公共的
模板
视频...
[hadoop105:21000] > ! ls ./; #当前linux目录下;跟linux命令是一样的;
impala.sql log4j.log result.txt student.txt 公共的 模板 视频 图片 文档 下载 音乐 桌面
beeline
0: jdbc:hive2://hadoop104:10000> help ##jdbc这种连接方式它的命令都是带有!的,不用加;,执行sql语句时才加;
!help
!quiet
!sh hadoop fs -ls / ##查看本地linux中的目录文件
!sh ls /
③ shell跟进入内部!sh一样
[hadoop105:21000] > shell hadoop fs -ls /; ##查看hdfs上文件;查看本地直接跟linux系统的命令
version; ##版本要一致或要兼容 Impala Shell和server version要兼容
④ connect hadoop106;跟-i是一样的
⑤ history;
⑥ set COMPRESSION_CODEC=gzip;
⑦ unset COMPRESSION_CODEC;
⑧ set
⑨ refresh student; 增量刷新元数据库
invalidate metadata 全量刷新元数据库(慎用)(同于 impala-shell -r)
创建数据库
Impala不支持alter database语法
创建数据库:
不支持 with dbproperties数据库的属性,但hive支持WITH DBPROPERTIES ("creator"="ruoze", "date"="2018-08-08");
[hadoop105:21000] > create database impaladb comment "impala_db" location '/impala_db';
Query: create database impaladb comment "impala_db" location '/impala_db'
location '/' 不要这样写;删除时会把根目录下的全部删掉;
drop database impala_db; #正在使用(use 它了)的库不能删,有数据的也删不了,要加cascade;
创建表
--内部表
create table if not exists stu(id int, name string)
row format delimited fields terminated by '\t'
stored as textfile
location '/impala_db';
impala不支持load(本地)数据,支持从HDFS上load数据
插入数据方式一: [hadoop105:21000] > insert into table stu select * from student; 以select这种方式插入数据
插入数据方式二: [hadoop105:21000] > load data inpath "/student.txt" into table stu;
Query: load data inpath "/student.txt" into table stu
+----------------------------------------------------------+
| summary |
+----------------------------------------------------------+
| Loaded 1 file(s). Total files in destination location: 4 |
+----------------------------------------------------------+
--外部表
create external table if not exists stu_external(id int, name string)
row format delimited fields terminated by '\t'
location '/impala_db';
[hadoop105:21000] > select * from stu_external; ##location位置中有数据就可以查询到;
分区表
--分区表| 支持分区 create table stu_pro(id int, name string) partitioned by(month string) row format delimited fields terminated by '\t' location '/impala_db'; ##注意这里是partitioned,而不是partition 增加分区数,可同时创建多个分区 [hadoop105:21000] > alter table stu_pro add partition(month="201903"); [hadoop105:21000] > alter table stu_pro add partition(month="201904") partition(month="201905");#支持增加多个分区,中间用空格; 在impala中要先创建好分区如month="201903",才能导入数据,只能从hdfs上导入数据,不支持从本地导入; impala导入数据时不支持本地导入,只支持从hdfs上导入到普通表中,支持从hdfs上导入(剪切)到已经创建好分区的表中;
导入数据方式一: [hadoop105:21000] > load data inpath "/student.txt" into table stu_pro partition(month="201903");##是剪切的方式导入的 Query: load data inpath "/student.txt" into table stu_pro partition(month="201903") +----------------------------------------------------------+ | summary | +----------------------------------------------------------+ | Loaded 1 file(s). Total files in destination location: 1 | +----------------------------------------------------------+ Fetched 1 row(s) in 0.16s 删除分区,只能删除一个,不能一块删多个分区: alter table stu_pro drop partition(month="201904") partition(month="201905"); [hadoop105:21000] > alter table stu_pro drop partition(month="201903"); Query: alter table stu_pro drop partition(month="201903") +-------------------------+ | summary | +-------------------------+ | Dropped 1 partition(s). | +-------------------------+
导入数据方式二: 也可以以这种方式插入数据: insert into table stu_pro partition(month="201902") select * from stu; 查询分区表中数据: select * from stu_pro; [hadoop105:21000] > select * from stu_pro where month="201902"; +----+------+--------+ | id | name | month | +----+------+--------+ | 1 | a | 201902 | | 2 | b | 201902 | | 3 | c | 201902 | | 4 | d | 201902 | +----+------+--------+
查看分区数
show partitions stu_pro;
4. 数据的导入和导出
4.1 数据导入(基本同hive类似)
注意:impala不支持load data local inpath…
insert语句:插入数据时每条数据产生一个数据文件,不建议用此方式; load data方式:在进行批量插入时使用这种方式比较合适; 来自中间表:此种方式使用于从一个小文件较多的大表中读取文件并写入新的表生产少量的数据文件。也可以通过此种方式进行格式转换。
空值处理:
impala将“\n” 表示为NULL,在结合sqoop使用是注意做相应的空字段过滤, 也可以使用以下方式进行处理: alter table name set tblproperties (“serialization.null.format” = “null”)
4.2 数据的导出
1. impala不支持insert overwrite…语法导出数据; 2. impala 数据导出一般使用 impala -o
[root@hadoop104 ~]# impala-shell -i hadoop105 -q "select * from stu" -o result.txt -B --output_delimiter='\t'
[root@hadoop104 ~]# cat result.txt
1 a
2 b
3 c
4 d
5. 查询
- 基本的语法跟hive的查询语句大体一样
- Impala不支持CLUSTER BY, DISTRIBUTE BY, SORT BY
- Impala中不支持分桶表
- Impala不支持COLLECT_SET(col)和explode(col)函数
- Impala支持开窗函数
impala SQL支持的数据类型: INT、TINYINT、SMALLINT、BIGINT、BOOLEAN、CHAR、VARCHAR、STRING、FLOAT、DOUBLE、REAL、DECIMAL、TIMESTAMP CDH5.5版本以后才支持一下类型:ARRAY、MAP、STRUCT、Complex Impala不支持HiveQL以下特性: 可扩展机制,例如:TRANSFORM、自定义文件格式、自定义SerDes – XML、JSON函数 – 某些聚合函数: covar_pop, covar_samp, corr, percentile,percentile_approx, histogram_numeric, collect_set Impala仅支持:AVG,COUNT,MAX,MIN,SUM – 多Distinct查询 – HDF、UDAF --以下语句: ANALYZE TABLE (impala: COMPUTE STATS), DESCRIBE COLUMN, DESCRIBE DATABASE, EXPOR TABLE, IMPORT TABLE, SHOW TABLE EXTENDED, SHOW INDEXES, SHOW COLUMNS. impala SQL支持视图: 视图 – 创建视图:create view v1 as select count(id) as total from tab_3 ; – 查询视图:select * from v1; – 查看视图定义:describe formatted v1 注意: 不能向impala的视图进行插入操作 insert 表可以来自视图
create table score(
name string, subject string, scores int)
row format delimited fields terminated by "\t";
load data inpath "/score.txt" into table score;
求每个科目的前3名:
select name, subject, rank from
(select name, subject, scores, rank() over(partition by subject order by scores) rank from score) t1
where t1.rank <= 3;
5.1 自定义函数
1.创建一个Maven工程Hive
2.导入依赖


<dependencies> <!-- https://mvnrepository.com/artifact/org.apache.hive/hive-exec --> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>1.2.1</version> </dependency> </dependencies>
3. 创建一个类 重写evaluate方法;方法名只能叫这个,叫别的识别不了的;
package com.atguigu.udf; import org.apache.hadoop.hive.ql.exec.UDF; public class Lower extends UDF{ public String evaluate (final String s){ if (s == null){ return null; } return s.toLowerCase(); } }
打成jar包上传到linux的/root下面
将jar包上传到hdfs的指定目录
[root@hadoop104 ~]# hadoop fs -put UDF-1.0-SNAPSHOT.jar /
创建自定义函数
[hadoop105:21000] > create function my_lower(string) returns string location '/UDF-1.0-SNAPSHOT.jar' symbol='com.atguigu.udf.Lower';
Query: create function my_lower(string) returns string location '/UDF-1.0-SNAPSHOT.jar' symbol='com.atguigu.udf.Lower'
使用自定义函数
[hadoop105:21000] > select id, name, my_lower(name) from stu;
通过show functions查看自定义的函数
[hadoop105:21000] > show functions;
Query: show functions
+-------------+------------------+-------------+---------------+
| return type | signature | binary type | is persistent |
+-------------+------------------+-------------+---------------+
| STRING | my_lower(STRING) | JAVA | false |
+-------------+------------------+-------------+---------------+
6 . 优化
1、 尽量将StateStore和Catalog单独部署到同一个节点,保证他们正常通信。在它俩部署的节点上最好不要部署impala-deamon;
2、 通过对Impala Daemon内存限制-参数(默认256M,可以把它改大点)及StateStore工作线程数-参数(默认4个),来提高Impala的执行效率。


3、 SQL优化,使用之前调用执行计划 explain 根据执行计划去优化
4、 选择合适的文件格式进行存储压缩,提高查询效率。
5、 避免产生很多小文件(如果有其他程序产生的小文件,可以使用中间表,将小文件数据存放到中间表。然后通过insert . into …select…方式把中间表的数据插入到最终表中)
insert into每执行一次它就会在hdfs相当于的文件夹下生成一个文件--->很多小文件;占用namenode过多空间
6、 使用合适的分区技术,根据分区粒度测算;提高查询效率;
7、 使用compute stats进行表信息搜集,当一个内容表或分区明显变化,重新计算统计相关数据表或分区。因为行和不同值的数量差异可能导致impala选择不同的连接顺序时进行查询。主要涉及两个表的join时,10M join 10G,10M慢慢变多100M, 100G join 10G,如果不对表的统计信息进行更新,它还会认为现在这个100G是之前的10M然后把它加载到内存中;在表的连接顺序优化;
[hadoop105:21000] > show table stats student; ##显示表的统计信息;多少行、大小、
Query: show table stats student
+-------+--------+------+--------------+-------------------+--------+-------------------+---------------------------------------------------+
| #Rows | #Files | Size | Bytes Cached | Cache Replication | Format | Incremental stats | Location |
+-------+--------+------+--------------+-------------------+--------+-------------------+---------------------------------------------------+
| -1 | 2 | 117B | NOT CACHED | NOT CACHED | TEXT | false | hdfs://hadoop104:8020/user/hive/warehouse/student |
+-------+--------+------+--------------+-------------------+--------+-------------------+---------------------------------------------------+
Fetched 1 row(s) in 2.42s
[hadoop105:21000] > compute stats student; ##对表中数据进行重新的收集
Query: compute stats student
+-----------------------------------------+
| summary |
+-----------------------------------------+
| Updated 1 partition(s) and 2 column(s). |
+-----------------------------------------+
Fetched 1 row(s) in 0.63s
[hadoop105:21000] > show table stats student;
Query: show table stats student
+-------+--------+------+--------------+-------------------+--------+-------------------+---------------------------------------------------+
| #Rows | #Files | Size | Bytes Cached | Cache Replication | Format | Incremental stats | Location |
+-------+--------+------+--------------+-------------------+--------+-------------------+---------------------------------------------------+
| 14 | 2 | 117B | NOT CACHED | NOT CACHED | TEXT | false | hdfs://hadoop104:8020/user/hive/warehouse/student |
+-------+--------+------+--------------+-------------------+--------+-------------------+---------------------------------------------------+
Fetched 1 row(s) in 0.01s
8、 网络io的优化:
–a.避免把整个数据发送到客户端
–b.尽可能的做条件过滤
–c.使用limit字句;结合order by
–d.输出文件时,避免使用美化输出| 边框,给它格式化
–e.尽量少用全量元数据的刷新;
9、 使用profile输出底层信息计划,在做相应环境优化
存储和压缩
ORC默认的压缩类型是:zlib,默认的压缩算法是deflate算法(gzip也是这种压缩算法);ORC File其实就是对RCFile做了一些优化
deflate、GZIP、BZIP2、LZO、snappy等它们的特点
常用的LZO( 可切割split,前提要建立索引,速度相当于gzip、bzip2相对来说快 )和snappy( 速度快,但不能切 )
文件格式(Parquet、TextFile、RCFile、SequenceFile)结合压缩使用;
parquet和orc这两种文件格式进行存储时默认都会进行压缩;
parquet默认的压缩是snappy,它也支持gzip,压缩方式也可以通过参数来修改; parquet可直接创建表,也可以直接查询这种类型的数据表;
TextFile创建表、直接insert插入数据、查询表;它支持LZO,gzip,bzip2,snappy;把它的压缩方式改了就不能直接插入数据了;
RCFile支持直接创建这种类型的表,也支持查询,不支持直接加载数据需要在hive中加载;
sequenceFile支持直接创建这种类型的表,也支持查询,但需要设置那个参数 set allow_unsupported_formats=true;
[hadoop105:21000] > create table student2(id int, name string) row format delimited fields terminated by '\t' stored as parquet;
[hadoop105:21000] > insert into table student2 values (1, "alex");
[hadoop105:21000] > select * from student2;
parquet这种存储类型的可以更改它的默认压缩方式(snappy),把它改为gzip;也可以直接创建表,直接插入数据,直接查询表中数据;
[hadoop105:21000] > set COMPRESSION_CODEC=gzip; ##可以更改压缩方式
COMPRESSION_CODEC set to gzip
[hadoop105:21000] > create table student_gzip(id int, name string) row format delimited fields terminated by '\t' stored as textfile;
[hadoop105:21000] > insert into table student_gzip values (1, "AAA");
WARNINGS: Writing to compressed text table is not supported. Use query option ALLOW_UNSUPPORTED_FORMATS to override.##默认false即0
[hadoop105:21000] > set ALLOW_UNSUPPORTED_FORMATS=true; ##它默认是0即false
ALLOW_UNSUPPORTED_FORMATS set to true
[hadoop105:21000] > insert into table student_gzip values (1, "AAA");
[hadoop105:21000] > create table student3(id int, name string) row format delimited fields terminated by '\t' stored as sequenceFile;
[hadoop105:21000] > insert into table student3 values(1001,'zhangsan');
Query: insert into table student3 values(1001,'zhangsan')
Query submitted at: 2019-02-28 17:06:21 (Coordinator: http://hadoop105:25000)
Query progress can be monitored at: http://hadoop105:25000/query_plan?query_id=834a6b44d1d07fc6:d9270b4e00000000
WARNINGS: Writing to table format SEQUENCE_FILE is not supported. Use query option ALLOW_UNSUPPORTED_FORMATS to override.
[hadoop105:21000] > set allow_unsupported_formats=true;
ALLOW_UNSUPPORTED_FORMATS set to true
[hadoop105:21000] > insert into table student3 values(1001,'zhangsan');
[hadoop105:21000] > select * from student3;
+------+----------+
| id | name |
+------+----------+
| 1001 | zhangsan |
+------+----------+
7. Impala与Hbase的整合
因为impala是基于hive的,和hive使用同样的元数据,hive与hbase整合以后,impala也就可以使用hbase了;
Impala可以通过Hive外部表方式和HBase进行整合,步骤如下:
步骤1:创建hbase表,向表中添加数据
create 'test info','info'
put 'test info','1','info:name','zhangsan'
put 'test info','2','info:name','lisi'
步骤2:创建hive表
CREATE EXTERNAL TABLE test_info(key string,name string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.hbase.HBaseSerDe'
STORED by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping"=":keyinfo:name")
TBLPROPERTIES
(hbase.table.name" = "test info");
步骤3:刷新Impala表
invalidate metadata



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人