
Zookeeper
1、概述
工作机制
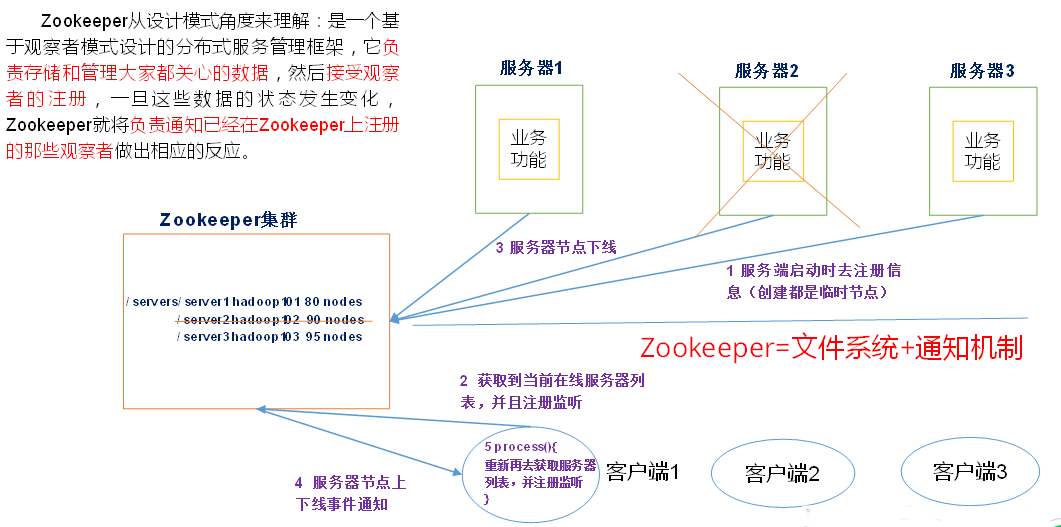
协调整个框架运行;但又处于背景版的角色;
Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目。
Zookeeper=文件系统+通知机制;
特点
集群的数量都是奇数个;(3台和4台的容错机制(挂几台机器还是可以照样运行)是一样的,都是1台;4台太消耗资源)
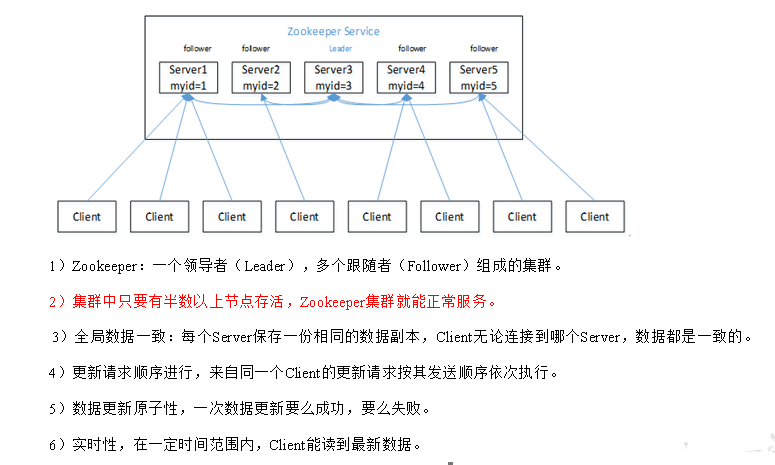
数据结构
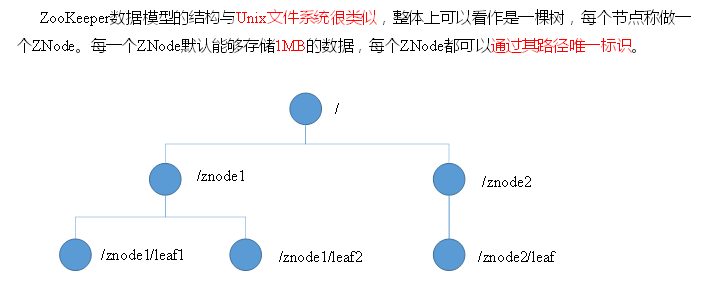
既是文件夹又是文件,叫znode;
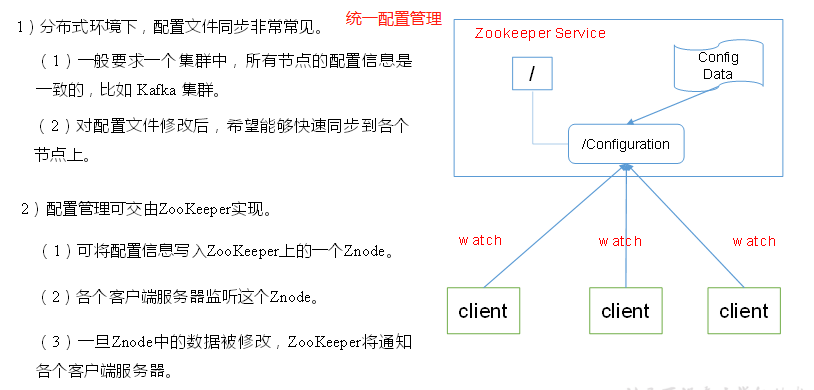
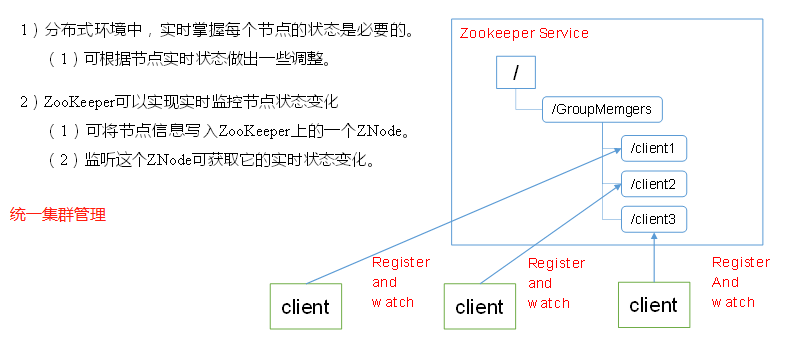
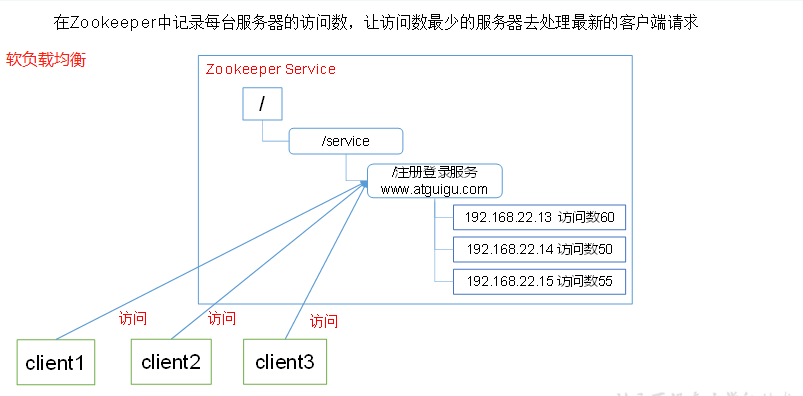
应用场景
提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。


source /etc/profile &&
2、搭建集群
https://zookeeper.apache.org/
ZooKeeper的部署方式有 单机模式、集群模式;
1. 解压到指定目录
[kris@hadoop101 software]$ tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/module/
2. 将/opt/module/zookeeper-3.4.10/conf这个路径下的zoo_sample.cfg修改为zoo.cfg;改名mv zoo_sample.cfg zoo.cfg
3. 打开zoo.cfg文件,修改dataDir路径: 改路径
dataDir=/opt/module/zookeeper-3.4.10/zkData
配置集群机器,每台机器分配一个不同的Serverid;在zoo.cfg文件末尾添加以下: 添加serverid
server.1=hadoop101:2888:3888
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
4. 在/opt/module/zookeeper-3.4.10/这个目录上创建zkData文件夹
[kris@hadoop101 zookeeper-3.4.10]$ mkdir zkData
5. 在zkData文件夹里新建一个myid文件,内容是本机的Serverid;依次在各个集群的服务器中添加serverid;
vim zkData/myid
1
6. 配置了一下Zookeeper的LogDIR:配置bin/zkEnv.sh文件
ZOO_LOG_DIR="."改为自定义的日志目录/opt/module/zookeeper-3.4.10/logs
7. 使用脚本群发;然后把各个server的id手动改了(hadoop102配置为 2,hadoop103配置为 3);在myid文件中:
xsync /opt/module/zookeeper-3.4.10
8. 启动:
bin/zkServer.sh start
查看进程是否启动
[kris@hadoop101 zookeeper-3.4.10]$ jps ##每个进程是来提供服务的;
4020 Jps
4001 QuorumPeerMain
查看状态:
[kris@hadoop101 zookeeper-3.4.10]$ bin/zkServer.sh status
9. 启动客户端:
[kris@hadoop101 zookeeper-3.4.10]$ bin/zkCli.sh ##客户端来连接集群;
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0]
[kris@hadoop101 zookeeper-3.4.10]$ jps
3248 ZooKeeperMain ##服务端
3076 QuorumPeerMain ##运行的客户端
3291 Jps
10. 退出客户端:
[zk: localhost:2181(CONNECTED) 0] quit
停止Zookeeper
[kris@hadoop101 zookeeper-3.4.10]$ bin/zkServer.sh stop
参数解读
Zookeeper中的配置文件zoo.cfg中参数含义解读如下:
1.tickTime =2000:通信心跳数,Zookeeper服务器与客户端心跳时间,单位毫秒
Zookeeper使用的基本时间,服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一个心跳,时间单位为毫秒。
它用于心跳机制,并且设置最小的session超时时间为两倍心跳时间。(session的最小超时时间是2*tickTime)
2.initLimit =10:LF初始通信时限
集群中的Follower跟随者服务器与Leader领导者服务器之间初始连接时能容忍的最多心跳数(tickTime的数量),用它来限定集群中的Zookeeper服务器连接到Leader的时限。
3.syncLimit =5:LF同步通信时限
集群中Leader与Follower之间的最大响应时间单位,假如响应超过syncLimit * tickTime,Leader认为Follwer死掉,从服务器列表中删除Follwer。
4.dataDir:数据文件目录+数据持久化路径
主要用于保存Zookeeper中的数据。
5.clientPort =2181:客户端连接端口
监听客户端连接的端口。
3. Zookeeper内部原理
ZAB协议(Paxos算法在Zookeeper中的实现)
Paxos算法是一种基于消息传递且具有高度容错特性的一致性算法。多数原则。
分布式系统中的节点通信存在两种模型:共享内存(Shared memory)和消息传递(Messages passing)。
基于消息传递通信模型的分布式系统,不可避免的会发生以下错误:(消息传递有先后顺序,数据同步难以实现;)
进程可能会慢、被杀死或者重启,消息可能会延迟、丢失、重复,在基础Paxos场景中,先不考虑可能出现消息篡改即拜占庭错误的情况。
Paxos算法解决的问题是在一个可能发生上述异常的分布式系统中如何就某个值达成一致,保证不论发生以上任何异常,都不会破坏决议的一致性。
Zookeeper--Atomic-Broadcast
Zookeeper怎么保证数据的全局一致性?通过ZAB协议
① ZAB协议:崩溃恢复;正常执行写数据;
② 没leader选leader;有leader就干活;
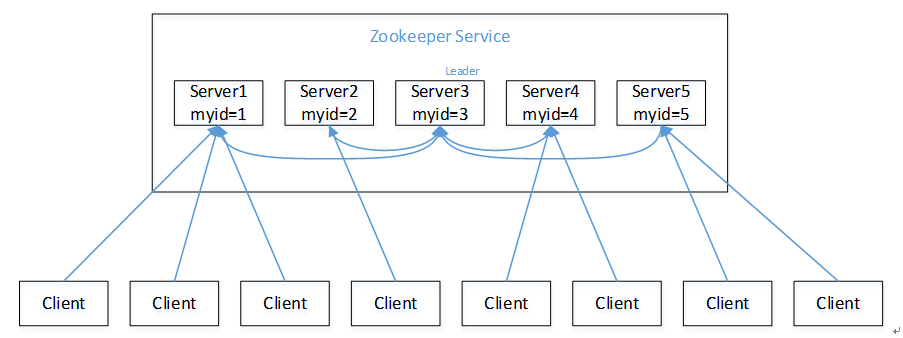
选举机制
1)半数机制:集群中半数以上机器存活,集群可用。所以Zookeeper适合安装奇数台服务器。
2)Zookeeper虽然在配置文件中并没有指定Master和Slave。但是,Zookeeper工作时,是有一个节点为Leader,其他则为Follower,Leader是通过内部的选举机制临时产生的。
3)以一个简单的例子来说明整个选举的过程。
假设有五台服务器组成的Zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的。假设这些服务器依序启动
(1)服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING;
(2)服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的ID比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING
(3)服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;
(4)服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING;
(5)服务器5启动,同4一样当小弟。
假设5台机器同时启动,5号当选;
选举时判断厉害的标准:
先比较 Zxid(服务器执行写数据的次数,最新的Zxid表示服务器数据新旧的程度,Zxid越大表示服务器数据越新;)
如果Zxid相同再比较myid;
写数据流程
读数据,zookeeper全局数据一致;
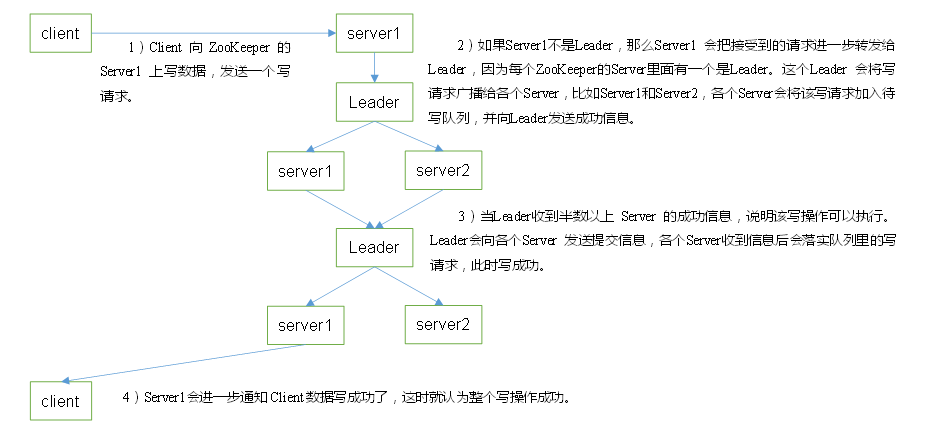
每个Server节点都维护了一个待写队列;有写请求不会立即写,会加入待写队列;这个写请求有可能成功也可能失败;
新加入的写操作的zxid 一定要大于服务器中原本有的zxid,之前写过留下的 --->写操作才能进入待写队列;(待写队列中都是没有写的;如原本的zxid为3,新zxid为6,再来一个zxid=5的会插入到6的前边,队列中是有序的)
算法推演过程
① 成功
Leader收到半数以上Server的成功信息,包括Leader自己;3台服务器,有2台同意了,则Leader就会广播,Server中待写队列的数据才会写成功;
(如执行set /data1 "Hello" ,在自己的Server节点zxid是最新,但在其他server中却不一定是最新的,因为网络通信有延迟,本地操作却是很快的)
② 失败
server1收到写请求,交给leader,leader发给server1和server2;同时server2也收到写请求,交给leader,leader也要发给server1和2;
按leader收到的顺序是1、2,由于网络原因,server1先收到1,再收到2;server2收到2、1;于是1就加入失败;
待写队列中有两条写请求zxid=6和zxid=7,同时转发给leader,leader广播给所有的server;结果7号大家先同意accept了;leader就让大家写;
由于网络原因,6才收到写请求,此时最新的zxid=7是大于6的 ==>写失败;
leader先发送写请求,再批准写请求;发送的过程不一定收到成功信息,假如收到半数以上失败的,写就失败了,leader就广播大家把这个数据从待写队列中移除;
③ 单个节点掉丢了
5个节点;leader发送写请求,有两个节点不同意,3个节点同意;leader广播所有的server开始写数据;原来不同意的两个节点原地自杀,它俩就不对外提供服务了,它俩数据出现不一致的问题,跟集群不同步了,然后它俩就去找leader按照它的zxid依次拉取数据把信息同步过来;
通过ZAB协议,在基于消息传递模型的情况下,zookeeper才能保持全局数据的一致性;
写请求先转发给leader ---> leader要把写请求转发给所有的server, --->它们开始投票,同意or不同意 --->leader统计票数发布结果; --->广播给各个server要么写要么让server把请求从队列中移除;
④ Observer
④.1 观察者;随着集群的扩张(数量| 横向),写数据愈来愈麻烦,写效率变慢,读服务的并发效率则是越来越高的;
为了解决这种矛盾引入observer,只听命令不投票; 对外可提供读服务,不投票(写请求是否成功它不管,它没有投票权其他都是一样的);;
如3台server,引入2台observer,写性能还是由原来的3个决定,写性能不能,可大幅度提升集群的并发读性能;
④.2 一般集群是搭在数据中心内部,但有些大公司zookeeper集群可能分布在不同的数据中心当中;
如三个数据中心DC1、DC2、DC3,各个中心中有3个server,DC1中有一个leader;
DC1中的3台中1台当leader,另外2个当fllower;DC2、DC3中的zookeeper6台server当observer,它们不参与投票;
监听器原理
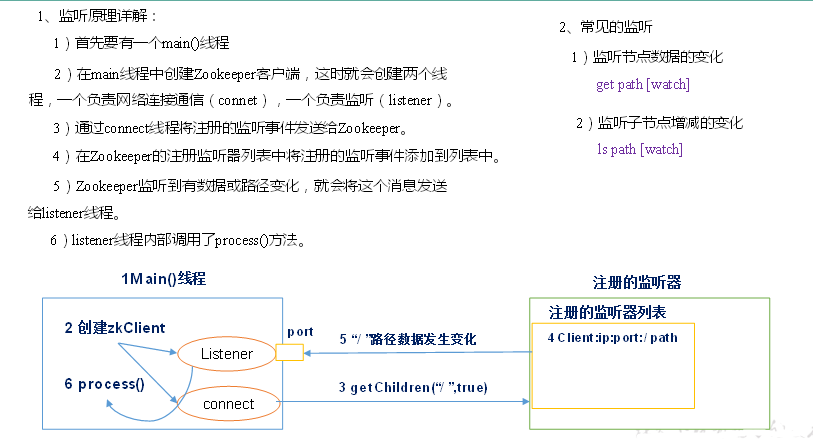
ClientCnxn.java:
sendThread = new SendThread(clientCnxnSocket); //connect就是sendThread负责网络连接通信;
eventThread = new EventThread(); //listener就是eventThread负责监听
这里创建了两个子线程;
class SendThread extends ZooKeeperThread
public class ZooKeeperThread extends Thread
public void start() {
sendThread.start(); 由客户端向zookeeper发送信息的线程;
eventThread.start(); zookeeper发生变化来通知,由eventThread负责接收事件的变化;eventThread负责调用的回调函数,zookeeper发生了变化它把这个变化发给eventThread
}
节点类型

Stat结构体
1)czxid-创建节点的事务zxid
每次修改ZooKeeper状态都会收到一个zxid形式的时间戳,也就是ZooKeeper事务ID。
事务ID是ZooKeeper中所有修改总的次序。每个修改都有唯一的zxid,如果zxid1小于zxid2,那么zxid1在zxid2之前发生。
2)ctime - znode被创建的毫秒数(从1970年开始)
3)mzxid - znode最后更新的事务zxid
4)mtime - znode最后修改的毫秒数(从1970年开始)
5)pZxid-znode最后更新的子节点zxid
6)cversion - znode子节点变化号,znode子节点修改次数
7)dataversion - znode数据变化号
8)aclVersion - znode访问控制列表的变化号
9)ephemeralOwner- 如果是临时节点,这个是znode拥有者的session id。如果不是临时节点则是0。
10)dataLength- znode的数据长度
11)numChildren - znode子节点数量
4、客户端命令行操作
ls create get delete set…
获取根节点下面的所有子节点,使用ls / 命令即可
也可以使用ls2 / 命令查看
获取节点的数据内容和属性,可使用如下命令:get
[zk: localhost:2181(CONNECTED) 15] ls /test1
[childNode, child1]
[zk: localhost:2181(CONNECTED) 16] ls2 /test1
[childNode, child1]
cZxid = 0xa00000014
ctime = Mon Jan 28 15:05:30 CST 2019
mZxid = 0xb00000044
mtime = Mon Jan 28 21:37:40 CST 2019
pZxid = 0xb00000046
cversion = 14
dataVersion = 4
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 9
numChildren = 2
[zk: localhost:2181(CONNECTED) 17] get /test1
zookeeper
cZxid = 0xa00000014
ctime = Mon Jan 28 15:05:30 CST 2019
mZxid = 0xb00000044
mtime = Mon Jan 28 21:37:40 CST 2019
pZxid = 0xb00000046
cversion = 14
dataVersion = 4
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 9
numChildren = 2
使用set命令,可以更新指定节点的数据内容; 相应的dataVersion会变
zookeeper 存数据+通知机制
1.
如果把服务器给kill了,它就会出现拒绝连接;默认连接的是本地的;如果启动的时候指定了服务器,把它的服务器kill掉,它就会直接跳转;
[zk: localhost:2181(CONNECTED) 1] ls /zookeeper ##这个是zookeeper自带的节点;
[quota]
2.
[zk: localhost:2181(CONNECTED) 2] ls / watch ##watch是监视\节点的变化,有效性为1次;
[test2, test40000000004, zookeeper, test1]
在另外一台客户端上create:
[zk: localhost:2181(CONNECTED) 0] create /data1 "heihei" ##创建节点的时候一定要告诉它数据是什么
Created /data1
[zk: localhost:2181(CONNECTED) 3]
WATCHER::
WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/
再创建第二个节点就没反应了;zookeeper的观察机制单次有效;
因为每个节点都有一个watchingList,这时服务端就有观察能力了;ls / watch注册观察的是根目录,客户端就会申请,zookeeper把数据仍进根目录的watchingList;
如果watchingList发生变化,它就要去通知所有注册过的客户端,每通知一个就从list名单中划掉;
3.
普通创建
-s 含有序列
-e 临时(重启或者超时消失)
[zk: localhost:2181(CONNECTED) 2] create -s /data2 1235
WATCHER::
watchedEvent state:SyncConnected type:NodeChildrenChanged path:/
Created /data20000000006
[zk: localhost:2181(CONNECTED) 3] create -e /linshi 001
Created /linshi
3.
[zk: localhost:2181(CONNECTED) 6] quit ###
Quitting...
2019-01-27 00:29:27,946 [myid:] - INFO [main:ZooKeeper@684] - Session: 0x1688adaecec0001 closed
2019-01-27 00:29:27,954 [myid:] - INFO [main-EventThread:ClientCnxn$EventThread@519] - EventThread shut down for session: 0x1688adaecec0001
不同客户端之间是互相独立的,只有从自己创建的节点quit了,在另外一个客户端上这个节点(2s内)才会消失;
4.
===>
一共4种节点类型:ephemeral sequential 两两组合;
有序持久-s;
[zk: localhost:2181(CONNECTED) 1] create -s /order 111
Created /order0000000009
有序短暂 -s -e;
[zk: localhost:2181(CONNECTED) 2] create -s -e /orderAndShort 222
Created /orderAndShort0000000010
无序持久;
[zk: localhost:2181(CONNECTED) 3] create /long 333
Created /long
无序短暂-e;
[zk: localhost:2181(CONNECTED) 4] create -e /short 444
Created /short
监听:监听节点的路径变化(set /test2 "zookeeper" ,改变它的值而监听收不到的;监听节点的增加、删除) ls /test2 watch
监听节点的内容 get /test2 watch 增加节点或删除节点监听是不会变化的,只有改变节点的内容如 set /test1 Hello才会触发watch
[zk: localhost:2181(CONNECTED) 2] get /test2 watch ##此时监听的是节点的内容; 而ls 是监听节点的路径变化(增加| 删除新节点了);
abcd
cZxid = 0x200000003
ctime = Sat Jan 26 15:23:14 CST 2019
mZxid = 0x200000003
mtime = Sat Jan 26 15:23:14 CST 2019
pZxid = 0x400000015
cversion = 1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 4
numChildren = 1
[zk: localhost:2181(CONNECTED) 3]
WATCHER::
WatchedEvent state:SyncConnected type:NodeDataChanged path:/test2
[zk: localhost:2181(CONNECTED) 4] create /test2/test0 123 ##改变节点的路径,创建一个子节点;子节点的值没变化;
Created /test2/test0
[zk: localhost:2181(CONNECTED) 5] set /test2 QQ ##set是改变节点的值
cZxid = 0x200000003
ctime = Sat Jan 26 15:23:14 CST 2019
mZxid = 0x400000016
mtime = Sun Jan 27 00:53:19 CST 2019
pZxid = 0x400000015
cversion = 1
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 2
numChildren = 1
[zk: localhost:2181(CONNECTED) 6] stat /test2
cZxid = 0x200000003 ##表示第几次操作节点;2表服务端第2次启动; 00000003当次启动下的第几次操作(16进制)创建了这个节点;
ctime = Sat Jan 26 15:23:14 CST 2019 ##创建时间,long型时间戳;
mZxid = 0x400000016 ##表服务器在第4次启动时的00000016次修改了这个节点的数据;
mtime = Sun Jan 27 00:53:19 CST 2019 #修改时间
pZxid = 0x400000015 ##表服务器在第4次启动时第00000015次创建了子节点;
cversion = 1 #子节点版本号;表test2节点下面子节点的变化号(删除| 增加),1表变化了1次;
dataVersion = 1 #表示子节点的数据变化号,修改的次数
aclVersion = 0 #access control list访问控制列表,网络版的权限控制;控制网络上哪些人可访问节点;0版本是都可以访问的acl
ephemeralOwner = 0x0 #非临时节点 =0; #假如是临时节点,0x0这里就不会是0了;如果是临时节点就会显示出所有者;当你的所有者离线后它就自然消失了;它的值就是此刻的sessionid: 如0x16893294b0c0000
dataLength = 2 #数据长度
numChildren = 1 #子节点的数量;
[zk: localhost:2181(CONNECTED) 1] create -e /testXXX 123
Created /testXXX
[zk: localhost:2181(CONNECTED) 2] stat /testXXX
cZxid = 0x400000019
ctime = Sun Jan 27 01:19:06 CST 2019
mZxid = 0x400000019
mtime = Sun Jan 27 01:19:06 CST 2019
pZxid = 0x400000019
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x1688adaecec0006 #sessionid = 0x1688adaecec0006 客户端和服务器之后的会话id;
dataLength = 3
numChildren = 0
[zk: localhost:2181(CONNECTED) 3]
delete删除没有子节点的;
rmr 是可以删除带有子节点的;
rmr /test2
使用ssh启动集群
两种方法:
①是 source /etc/profile && ②zkEnv.sh文件夹中 配置下JAVA_HOME的环境变量(需要放在zkEnv.sh文件的最前边):
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
[kris@hadoop101 zookeeper-3.4.10]$ ssh hadoop103 /opt/module/zookeeper-3.4.10/bin/zkServer.sh status
ZooKeeper JMX enabled by default Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg Error contacting service. It is probably not running. ###source这里注意要有空格 [kris@hadoop101 zookeeper-3.4.10]$ ssh hadoop103 source /etc/profile && /opt/module/zookeeper-3.4.10/bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg Mode: follower [kris@hadoop101 zookeeper-3.4.10]$ hadoop103要在zookeeper-3.4.10/bin目录下的zkEnv.sh文件夹中 配置下JAVA_HOME的环境变量:
[kris@hadoop103 bin]$ vim zkEnv.sh #JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_144 export PATH=$PATH:$JAVA_HOME/bin [kris@hadoop101 zookeeper-3.4.10]$ ssh hadoop103 /opt/module/zookeeper-3.4.10/bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg Mode: follower
5、API应用
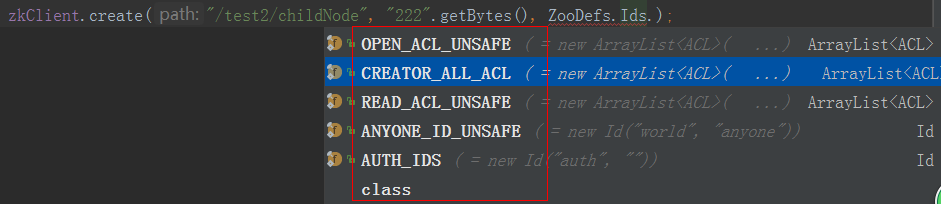
节点访问权限:
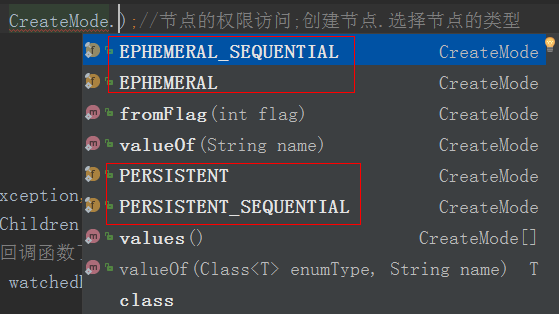
节点的类型选择:ephemeral_sequential 、ephemeral、 persistent、persistent_sequential
public class Zookeeper{
private ZooKeeper zkClient;
public static final String CONNECT_STRING = "hadoop101:2181,hadoop102:2181,hadoop103:2181";
public static final int SESSION_TIMEOUT = 2000;
@Before
public void before() throws IOException {
//集群地址;会话过期时间; 匿名内部类, 回调函数; 主进程不会停,根节点有变化通过回调函数告知
zkClient = new ZooKeeper(CONNECT_STRING, SESSION_TIMEOUT, new Watcher() { //创建ZooKeeper客户端时
public void process(WatchedEvent event) {
System.out.println("默认的回调函数"); //没有监视任何节点,可写可不写
}
});
}
//1. 创建节点:
@Test
public void create() throws KeeperException, InterruptedException {
String s = zkClient.create("/APITest", "123".getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);//节点的权限访问;临时有序节点
System.out.println(s);
Thread.sleep(Long.MAX_VALUE);
}
@Test//2. 监听只一次有效;监听的是节点的变化--增加或删除节点
public void getChildren() throws KeeperException, InterruptedException {
//sendThread负责通信; eventThread负责监听;当节点有变化eventThread调用默认的回调函数, 可自定义;
List<String> children = zkClient.getChildren("/test1",true); //只监听一次;
for (String child : children) {
System.out.println(child);
}
System.out.println("===============");
Thread.sleep(Long.MAX_VALUE);
}
//3. 递归--> 可实现反复调用watch( )
@Test
public void getChildren() throws KeeperException, InterruptedException {
List<String> children = zkClient.getChildren("/", new Watcher() { //watch: true 会监听,调用默认的回调函数,监听一次有效;
// 还可以写new Watch 就不用默认的回调函数了;
public void process(WatchedEvent watchedEvent) {
try {
System.out.println("自己的回调函数");
getChildren(); //可反复监听;监听根目录 watcher.process(pair.event);
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
for (String child : children) {
System.out.println(child);
}
System.out.println("==================");
}
@Test //4. 可反复调用,反复监听;
public void testGet() throws KeeperException, InterruptedException {
getChildren();
Thread.sleep(Long.MAX_VALUE); //主线程被阻塞,说明回调的时候不是主线程
}
// 5. 判断znode是否存在
@Test
public void exist() throws KeeperException, InterruptedException {
Stat stat = zkClient.exists("/zookeeper1", false);
if (stat == null){
System.out.println("节点不存在");
}else{
System.out.println(stat.getDataLength());
}
}
}
ZooKeeper如何保证数据一致性
在分布式系统里的多台服务器要对数据状态达成一致,其实是一件很有难度和挑战的事情,因为服务器集群环境的软硬件故障随时会发生,多台服务器对一个数据的记录保持一致,需要一些技巧和设计。
HDFS 为了保证整个集群的高可用,需要部署两台 NameNode 服务器,一台作为主服务器,一台作为从服务器。当主服务器不可用的时候,就切换到从服务器上访问。但是如果不同的应用程序(Client)或者 DataNode 做出的关于主服务器是否可用的判断不同,那么就会导致 HDFS 集群混乱。
这种不同主服务器做出不同的响应,在分布式系统中被称作“脑裂”。引入一个专门进行判断的服务器当“裁判”,让“裁判”决定哪个服务器是主服务器。
这个做出判断决策的服务器也有可能会出现故障不可访问,同样整个服务器集群也不能正常运行。所以这个做出判断决策的服务器必须由多台服务器组成,来保证高可用,任意一台服务器宕机都不会影响系统的可用性。
那么问题又来了,这几台做出判断决策的服务器又如何防止“脑裂”,自己不会出现混乱状态呢?
常用的多台服务器状态一致性的解决方案就是 ZooKeeper。
Paxos算法与ZooKeeper架构
比如一个提供锁服务的分布式系统,它是由多台服务器构成一个集群对外提供锁服务,应用程序连接到任意一台服务器都可以获取或者释放锁,因此这些服务器必须严格保持状态一致,不能一台服务器将锁资源交给一个应用程序,而另一台服务器将锁资源交给另一个应用程序,所以像这种分布式系统对数据一致性有更高的要求。
Paxos 算法就是用来解决这类问题的,多台服务器通过内部的投票表决机制决定一个数据的更新与写入。Paxos 的基本思路请看下面的图。
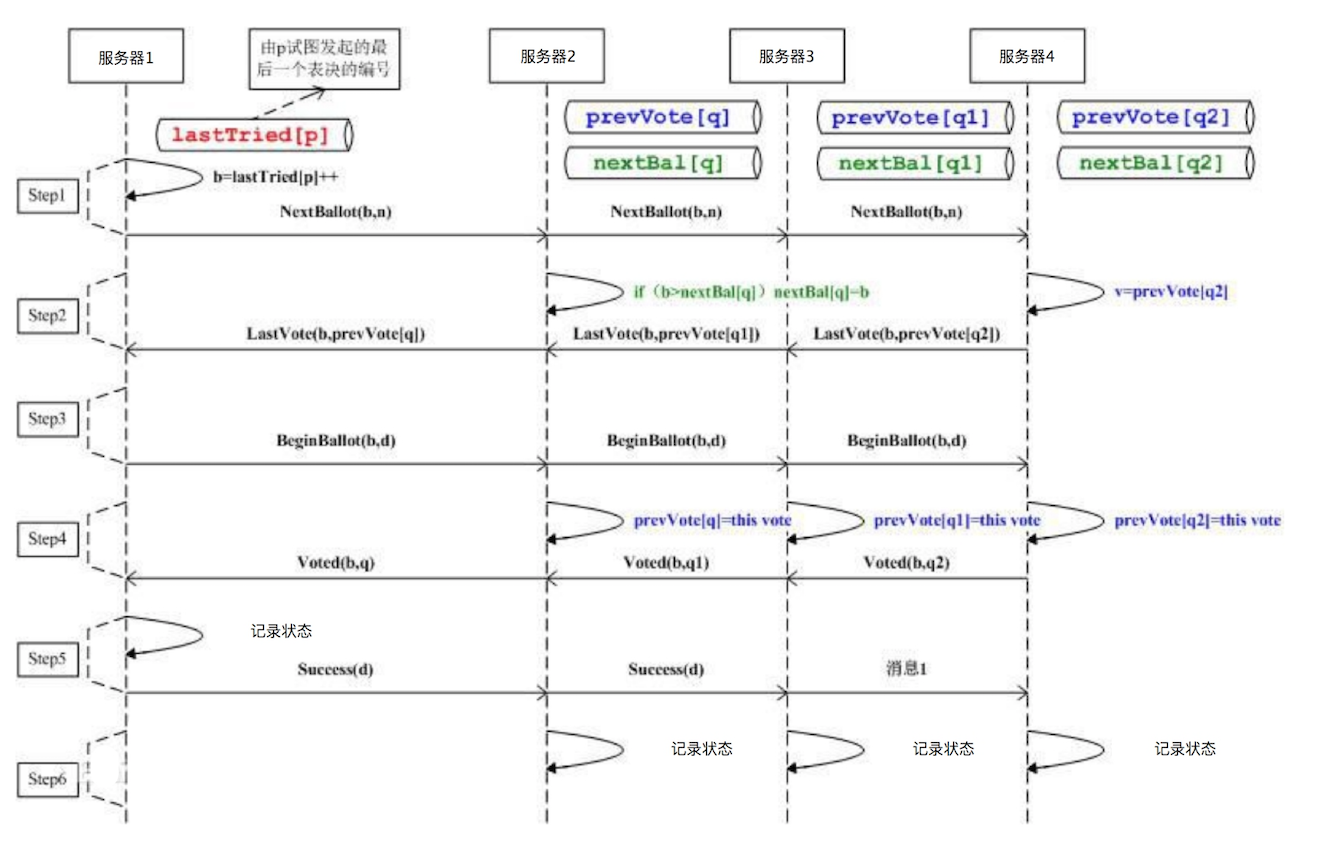
应用程序连接到任意一台服务器后提起状态修改请求(也可以是获得某个状态锁的请求),从图上看也就是服务器 1,会将这个请求发送给集群中其他服务器进行表决。如果某个服务器同时收到了另一个应用程序同样的修改请求,它可能会拒绝服务器 1 的表决,并且自己也发起一个同样的表决请求,那么其他服务器就会根据时间戳和服务器排序规则进行表决。
表决结果会发送给其他所有服务器,最终发起表决的服务器也就是服务器 1,会根据收到的表决结果决定该修改请求是否可以执行,从而在收到请求的时候就保证了数据的一致性。
Paxos 算法比较复杂,为了简化实现,ZooKeeper 使用了一种叫 ZAB(ZooKeeper Atomic Broadcast,ZooKeeper 原子消息广播协议)的算法协议。基于 ZAB 算法,ZooKeeper 集群保证数据更新的一致性,并通过集群方式保证 ZooKeeper 系统高可用。但是 ZooKeeper 系统中所有服务器都存储相同的数据,也就是数据没有分片存储,因此不满足分区耐受性。
ZooKeeper 通过一种树状结构记录数据,如下图所示。
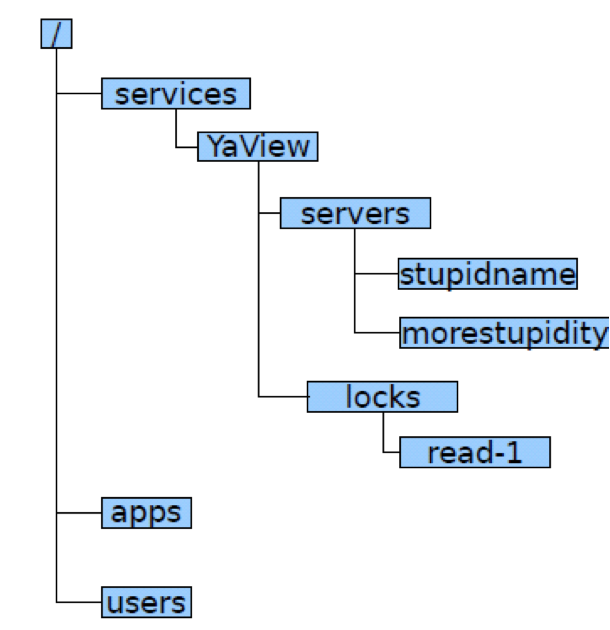
应用程序可以通过路径的方式访问 ZooKeeper 中的数据,比如 /services/YaView/services/stupidname 这样的路径方式修改、读取数据。
ZooKeeper 还支持监听模式,当数据发生改变的时候,通知应用程序。
因为大数据系统通常都是主从架构,主服务器管理集群的状态和元信息(meta-info),为了保证集群状态一致防止“脑裂”,所以运行期只能有一个主服务器工作(active master),但是为了保证高可用,必须有另一个主服务器保持热备(standby master)。那么应用程序和集群其他服务器如何才能知道当前哪个服务器是实际工作的主服务器呢?
所以很多大数据系统都依赖 ZooKeeper 提供的一致性数据服务,用于选举集群当前工作的主服务器。一台主服务器启动后向 ZooKeeper 注册自己为当前工作的主服务器,因此另一
台服务器就只能注册为热备主服务器,应用程序运行期都和当前工作的主服务器通信。
如果当前工作的主服务器宕机(在 ZooKeeper 上记录的心跳数据不再更新),热备主服务器通过 ZooKeeper 的监控机制发现当前工作的主服务器宕机,就向 ZooKeeper 注册自己成
为当前工作的主服务器。应用程序和集群其他服务器跟新的主服务器通信,保证系统正常运行。
因为ZooKeeper系统多台服务器存储相同数据,且每次数据更新都要所有服务器投票表决,所以和一般的分布式系统相反,ZooKeeper集群性能会随着服务器数量的增加而下降。
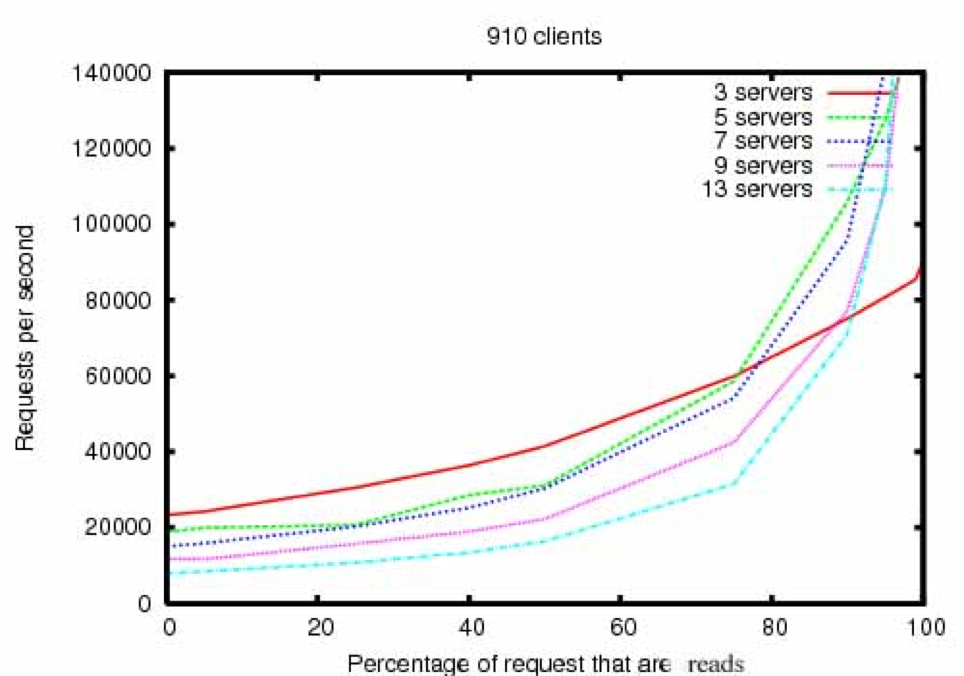
ZooKeeper 通过 Paxos 选举算法实现数据强一致性,并为各种大数据系统提供主服务器选举服务。虽然 ZooKeeper 并没有什么特别强大的功能,但是在各类分布式系统和大数据系
统中,ZooKeeper 的出镜率非常高,因此也是很多系统的基础设施。
CAP原则
CAP法则:强一致性、高可用性、分区容错性; Zookeeper符合CP
分区中的少数节点会进入leader选举状态,这个状态不能处理读写操作,因此不符合A,如果不考虑实时一致性,zk基本满足CP
CAP原则指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。
- 一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
- 可用性(A):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
- 分区容忍性(P):以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
一致性
一致性是指从系统外部读取系统内部的数据时,在一定约束条件下相同,即数据变动在系统内部各节点应该是同步的。根据一致性的强弱程度不同,可以将一致性级别分为如下几种:
①强一致性(strong consistency)。任何时刻,任何用户都能读取到最近一次成功更新的数据。
②单调一致性(monotonic consistency)。任何时刻,任何用户一旦读到某个数据在某次更新后的值,那么就不会再读到比这个值更旧的值。也就是说,可 获取的数据顺序必是单调递增的。
③会话一致性(session consistency)。任何用户在某次会话中,一旦读到某个数据在某次更新后的值,那么在本次会话中就不会再读到比这值更旧的值 会话一致性是在单调一致性的基础上进一步放松
约束,只保证单个用户单个会话内的单调性,在不同用户或同一用户不同会话间则没有保障。示例case:php的 session概念。
④ 最终一致性(eventual consistency)。用户只能读到某次更新后的值,但系统保证数据将最终达到完全一致的状态,只是所需时间不能保障。
⑥弱一致性(weak consistency)。用户无法在确定时间内读到最新更新的值。
zookeeper是一种提供强一致性的服务,在分区容错性和可用性上做了一定折中,这和CAP理论是吻合的。但实际上zookeeper提供的只是单调一致性。
原因:
1. 假设有2n+1个server,在同步流程中,leader向follower同步数据,当同步完成的follower数量大于 n+1时同步流程结束,系统可接受client的连接请求。如果client连接的并非同步完成的follower,那么得到
的并非最新数据,但可以保证单调性。
2. follower接收写请求后,转发给leader处理;leader完成两阶段提交的机制。向所有server发起提案,当提案获得超过半数(n+1)的server认同后,将对整个集群进行同步,超过半数(n+1)的server同步
完成后,该写请求完成。如果client连接的并非同步完成follower,那么得到的并非最新数据,但可以保证单调性。
用分布式系统的CAP原则来分析Zookeeper:
(1)C: Zookeeper保证了最终一致性,在十几秒可以Sync到各个节点.
(2)A: Zookeeper保证了可用性,数据总是可用的,没有锁.并且有一大半的节点所拥有的数据是最新的,实时的. 如果想保证取得是数据一定是最新的,需要手工调用Sync()
(2)P: 有2点需要分析的.
① 节点多了会导致写数据延时非常大,因为需要多个节点同步.
② 节点多了Leader选举非常耗时, 就会放大网络的问题. 可以通过引入 observer节点缓解这个问题.
分布式存储系统的一致性与可用性的决择
-
数据库事务一致性需求
很多web实时系统并不要求严格的数据库事务,对读一致性的要求很低,有些场合对写一致性要求并不高。允许实现最终一致性。 -
数据库的写实时性和读实时性需求
对关系数据库来说,插入一条数据之后立刻查询,是肯定可以读出来这条数据的,但是对于很多web应用来说,并不要求这么高的实时性,比方说发一条消息之 后,过几秒乃至十几秒之后,我的订阅者才看到这条动态是完全可以接受的。 -
对复杂的SQL查询,特别是多表关联查询的需求
任何大数据量的web系统,都非常忌讳多个大表的关联查询,以及复杂的数据分析类型的报表查询,特别是SNS类型的网站,从需求以及产品设计角 度,就避免了这种情况的产生。往往更多的只是单表的主键查询,以及单表的简单条件分页查询,SQL的功能被极大的弱化了。
CAP三个特性只能满足其中两个,那么取舍的策略就共有三种:
CA without P:如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但放弃P的同时也就意味着放弃了系统的扩展性,也就是分布式节点受限,没办法部署子节点,这是违背分布式系统设计的初衷的。传统的关系型数据库RDBMS:Oracle、MySQL就是CA。
CP without A:如果不要求A(可用),相当于每个请求都需要在服务器之间保持强一致,而P(分区)会导致同步时间无限延长(也就是等待数据同步完才能正常访问服务),一旦发生网络故障或者消息丢失等情况,就要牺牲用户的体验,等待所有数据全部一致了之后再让用户访问系统。设计成CP的系统其实不少,最典型的就是分布式数据库,如Redis、HBase等。对于这些分布式数据库来说,数据的一致性是最基本的要求,因为如果连这个标准都达不到,那么直接采用关系型数据库就好,没必要再浪费资源来部署分布式数据库。
AP wihtout C:要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。典型的应用就如某米的抢购手机场景,可能前几秒你浏览商品的时候页面提示是有库存的,当你选择完商品准备下单的时候,系统提示你下单失败,商品已售完。这其实就是先在 A(可用性)方面保证系统可以正常的服务,然后在数据的一致性方面做了些牺牲,虽然多少会影响一些用户体验,但也不至于造成用户购物流程的严重阻塞。
BASE理论
BASE是Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)三个短语的简写,BASE是对CAP中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的结论,是基于CAP定理逐步演化而来的,其核心思想是即使无法做到强一致性(Strong consistency),但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)。接下来我们着重对BASE中的三要素进行详细讲解。
基本可用
基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性——但请注意,这绝不等价于系统不可用,以下两个就是“基本可用”的典型例子。
- 响应时间上的损失:正常情况下,一个在线搜索引擎需要0.5秒内返回给用户相应的查询结果,但由于出现异常(比如系统部分机房发生断电或断网故障),查询结果的响应时间增加到了1~2秒。
- 功能上的损失:正常情况下,在一个电子商务网站上进行购物,消费者几乎能够顺利地完成每一笔订单,但是在一些节日大促购物高峰的时候,由于消费者的购物行为激增,为了保护购物系统的稳定性,部分消费者可能会被引导到一个降级页面。
弱状态也称为软状态,和硬状态相对,是指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据听不的过程存在延时。
最终一致性
最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性
亚马逊首席技术官Werner Vogels在于2008年发表的一篇文章中对最终一致性进行了非常详细的介绍。他认为最终一致性时一种特殊的弱一致性:系统能够保证在没有其他新的更新操作的情况下,数据最终一定能够达到一致的状态,因此所有客户端对系统的数据访问都能够胡渠道最新的值。同时,在没有发生故障的前提下,数据达到一致状态的时间延迟,取决于网络延迟,系统负载和数据复制方案设计等因素。
在实际工程实践中,最终一致性存在以下五类主要变种。
因果一致性:
因果一致性是指,如果进程A在更新完某个数据项后通知了进程B,那么进程B之后对该数据项的访问都应该能够获取到进程A更新后的最新值,并且如果进程B要对该数据项进行更新操作的话,务必基于进程A更新后的最新值,即不能发生丢失更新情况。与此同时,与进程A无因果关系的进程C的数据访问则没有这样的限制。
读己之所写:
读己之所写是指,进程A更新一个数据项之后,它自己总是能够访问到更新过的最新值,而不会看到旧值。也就是说,对于单个数据获取者而言,其读取到的数据一定不会比自己上次写入的值旧。因此,读己之所写也可以看作是一种特殊的因果一致性。
会话一致性:
会话一致性将对系统数据的访问过程框定在了一个会话当中:系统能保证在同一个有效的会话中实现“读己之所写”的一致性,也就是说,执行更新操作之后,客户端能够在同一个会话中始终读取到该数据项的最新值。
单调读一致性:
单调读一致性是指如果一个进程从系统中读取出一个数据项的某个值后,那么系统对于该进程后续的任何数据访问都不应该返回更旧的值。
单调写一致性:
单调写一致性是指,一个系统需要能够保证来自同一个进程的写操作被顺序地执行。
以上就是最终一致性的五类常见的变种,在时间系统实践中,可以将其中的若干个变种互相结合起来,以构建一个具有最终一致性的分布式系统。事实上,可以将其中的若干个变种相互结合起来,以构建一个具有最终一致性特性的分布式系统。事实上,最终一致性并不是只有那些大型分布式系统才设计的特性,许多现代的关系型数据库都采用了最终一致性模型。在现代关系型数据库中,大多都会采用同步和异步方式来实现主备数据复制技术。在同步方式中,数据的复制国耻鞥通常是更新事务的一部分,因此在事务完成后,主备数据库的数据就会达到一致。而在异步方式中,备库的更新往往存在延时,这取决于事务日志在主备数据库之间传输的时间长短,如果传输时间过长或者甚至在日志传输过程中出现异常导致无法及时将事务应用到备库上,那么狠显然,从备库中读取的的数据将是旧的,因此就出现了不一致的情况。当然,无论是采用多次重试还是认为数据订正,关系型数据库还是能搞保证最终数据达到一致——这就是系统提供最终一致性保证的经典案例。
总的来说,BASE理论面向的是大型高可用可扩展的分布式系统,和传统事务的ACID特性使相反的,它完全不同于ACID的强一致性模型,而是提出通过牺牲强一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。但同时,在实际的分布式场景中,不同业务单元和组件对数据一致性的要求是不同的,因此在具体的分布式系统架构设计过程中,ACID特性与BASE理论往往又会结合在一起使用。
小结
计算机系统从集中式向分布式的变革随着包括分布式网络、分布式事务和分布式数据一致性等在内的一系列问题与挑战,同时也催生了一大批诸如ACID、CAP和BASE等经典理论的快速发展。
与NoSQL的关系
传统的SQL数据库的事务通常都是支持ACID的强事务机制。A代表原子性,即在事务中执行多个操作是原子性的,要么事务中的操作全部执行,要么一个都不执行; C代表一致性,即保证进行事务的过程中整个数据加的状态是一致的,不会出现数据花掉的情况;I代表隔离性,即两个事务不会相互影响,覆盖彼此数据等; D表示持久化,即事务一量完成,那么数据应该是被写到安全的,持久化存储的设备上(比如磁盘)。
NoSQL系统仅提供对行级别的原子性保证,也就是说同时对同一个Key下的数据进行的两个操作,在实际执行的时候是会串行的执行,保证了每一个Key-Value对不会被破坏。
CAP的是什么关系
It states, that though its desirable to have Consistency, High-Availability and Partition-tolerance in every system, unfortunately no system can achieve all three at the same time.
在分布式系统的设计中,没有一种设计可以同时满足一致性,可用性,分区容错性 3个特性
注意:不要将弱一致性,最终一致性放到CAP理论里混为一谈(混淆概念的坑真多)
弱一致性,最终一致性 你可以认为和CAP的C一点关系也没有,因为CAP的C是更新操作完成后,任何节点看到的数据完全一致, 弱一致性。最终一致性本身和CAP的C一致性是违背的,所以你可以看到那些谎称自己系统同时具备CAP 3个特性是多么的可笑,可能国内更多的场景是:一个开放人员一旦走上讲台演讲,就立马转变为了营销人员,连最基本的理念也不要了。
这里有一篇标题很大的文章 cap-twelve-years-later-how-the-rules-have-changed ,实际上本文的changed更多的是在思考方式上,而本身CAP理论是没有changed的
为什么会是这样
我们来看一个简单的问题, 一个DB服务 搭建在两个机房(北京,广州),两个DB实例同时提供写入和读取

1. 假设DB的更新操作是同时写北京和广州的DB都成功才返回成功
在没有出现网络故障的时候,满足CA原则,C 即我的任何一个写入,更新操作成功并返回客户端完成后,分布式的所有节点在同一时间的数据完全一致, A 即我的读写操作都能够成功,但是当出现网络故障时,我不能同时保证CA,即P条件无法满足
2. 假设DB的更新操作是只写本地机房成功就返回,通过binlog/oplog回放方式同步至侧边机房
这种操作保证了在出现网络故障时,双边机房都是可以提供服务的,且读写操作都能成功,意味着他满足了AP ,但是它不满足C,因为更新操作返回成功后,双边机房的DB看到的数据会存在短暂不一致,且在网络故障时,不一致的时间差会很大(仅能保证最终一致性)
3. 假设DB的更新操作是同时写北京和广州的DB都成功才返回成功且网络故障时提供降级服务
降级服务,如停止写入,只提供读取功能,这样能保证数据是一致的,且网络故障时能提供服务,满足CP原则,但是他无法满足可用性原则
选择权衡
通过上面的例子,我们得知,我们永远无法同时得到CAP这3个特性,那么我们怎么来权衡选择呢?
选择的关键点取决于业务场景
对于大多数互联网应用来说(如网易门户),因为机器数量庞大,部署节点分散,网络故障是常态,可用性是必须需要保证的,所以只有设置一致性来保证服务的AP,通常常见的高可用服务吹嘘5个9 6个9服务SLA稳定性就本都是放弃C选择AP
对于需要确保强一致性的场景,如银行,通常会权衡CA和CP模型,CA模型网络故障时完全不可用,CP模型具备部分可用性,实际的选择需要通过业务场景来权衡(并不是所有情况CP都好于CA,只能查看信息不能更新信息有时候从产品层面还不如直接拒绝服务)
延伸
BASE(Basically Available, Soft State, Eventual Consistency 基本可用、软状态、最终一致性) 对CAP AP理论的延伸, Redis等众多系统构建与这个理论之上
ACID 传统数据库常用的设计理念, ACID和BASE代表了两种截然相反的设计哲学,分处一致性-可用性分布图谱的两极。
分布式系统的典型应用
但如果以算法划分,到能分出几类:
1.以Leader选举为主的一类算法,比如paxos、viewstamp,就是现在zookeeper、Chuby等工具的主体
2.以分布式事务为主的一类主要是二段提交,这些分布式数据库管理器及数据库都支持
3.以若一致性为主的,主要代表是Cassandra的W、R、N可调节的一致性
4.以租赁机制为主的,主要是一些分布式锁的概念,目前还没有看到纯粹“分布式”锁的实现
5.以失败探测为主的,主要是Gossip和phi失败探测算法,当然也包括简单的心跳
6.以弱一致性、因果一致性、顺序一致性为主的,开源尚不多,但大都应用在Linkedin、Twitter、Facebook等公司内部
7当然以异步解耦为主的,还有各类Queue

 浙公网安备 33010602011771号
浙公网安备 33010602011771号