
Hadoop| HDFS
HDFS
1. HDFS--写(上传)
NameNode:Master主管管理者,管理HDFS的名称空间、配置副本策略、管理数据块Block的映射信息、处理客户端读写请求;
DataNode:Slave,执行NN下达的命令,存储实际的数据块、执行数据块的读写操作;
Client:①文件切分,将文件切分成一个个Block再上传;②与NameNode交互,获取文件的位置信息;③与DataNode交互读取或写入数据;④Client提供一些命令来管理HDFS,如格式化NameNode;⑤通过一些命令来访问HDFS,如对HDFS的增删改查操作;
SecondaryNameNode:辅助NameNode,如定期合并FSimage和Edits并推送给NameNode;②紧急情况下辅助恢复NameNode;
块:HDFS中的文件在物理上分块存储Block,块的大小可通过配置参数 dfs.blocksize来规定,在Hadoop2.x中默认128M,如果寻址时间约为10ms(查找目标Block的时间10ms),寻址时间为传输时间的1%最佳,因此传输时间=10ms/0.01=1s;目前磁盘的传输普遍在100MB/S;则Block的大小为1s*100M/S=100M,凑个整数就是128M了。

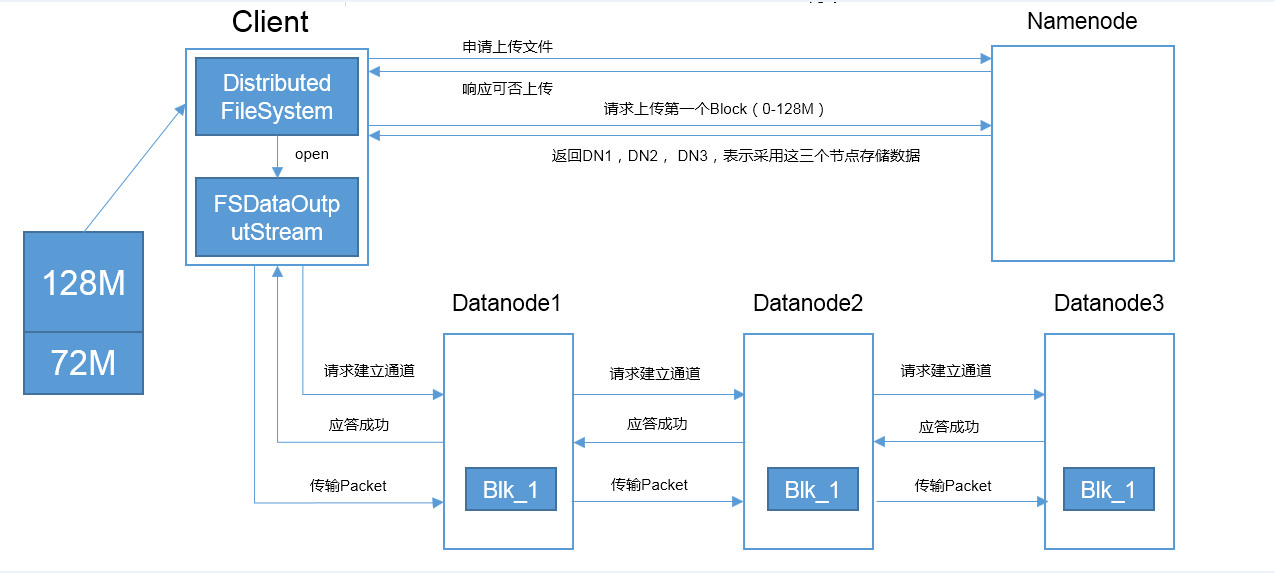

①客户端通过Distributed FileSystem向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
②NameNode返回是否可以上传;
③Client请求第一个Block上传到哪几个DataNode服务器上;
④NameNode返回3个DataNode节点DN1、DN2、DN3;
⑤Client通过FSDataOutputStream模块请求向DN1发起上传请求建立通信通道,DN1-->DN2-->DN3依次串行,DN3-->DN2-->DN1依次应答成功告知Client
⑥Client客户端开始往DN1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,DN1收到一个Packet就会传给DN2,DN2传给DN3;DN1每传一个packet会放入一个应答队列等待应答。
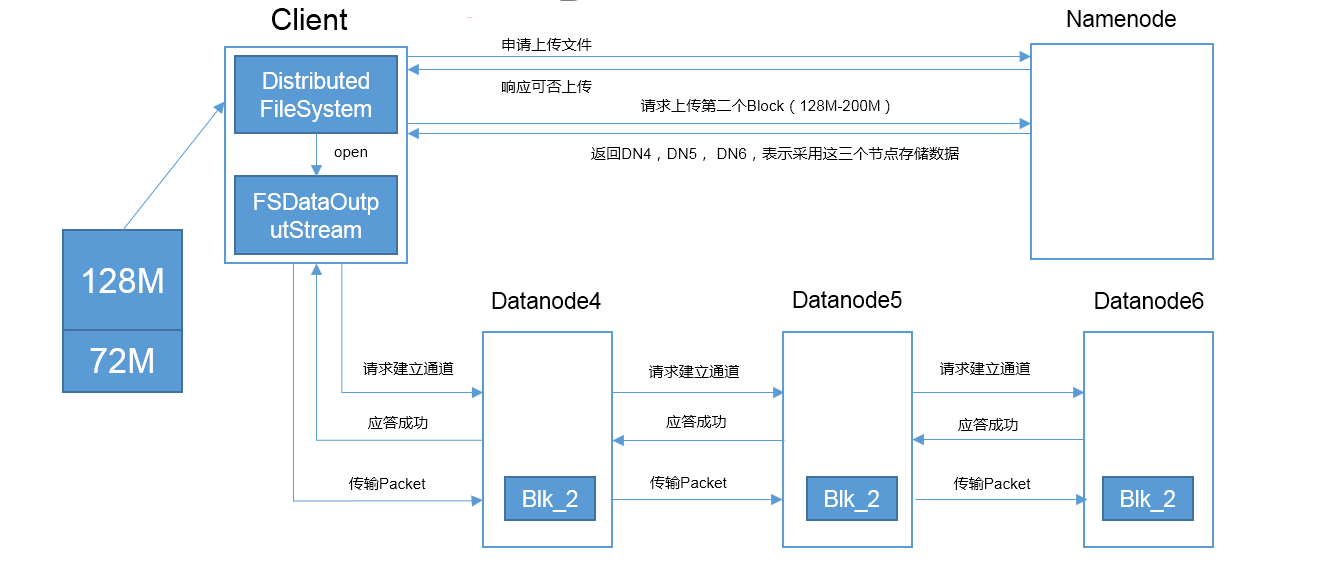
⑦当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。重复步骤⑤--⑦;
在HDFS写数据的过程中,NameNode会选择距离待上传数据最近距离的DataNode接收数据。那么这个最近距离怎么计算呢?
节点距离:两个节点到达最近的共同祖先的距离总和。
DN1是最近的,DN2和DN3是根据第一个节点DN1选出来的;
第二次的DN4、DN5、DN6可能跟第一次传输的DN一样,也可能不一样取决于内部集群的状况;两次返回的DN都是独立的。
网络拓扑图(只描述关系,不描述实体)
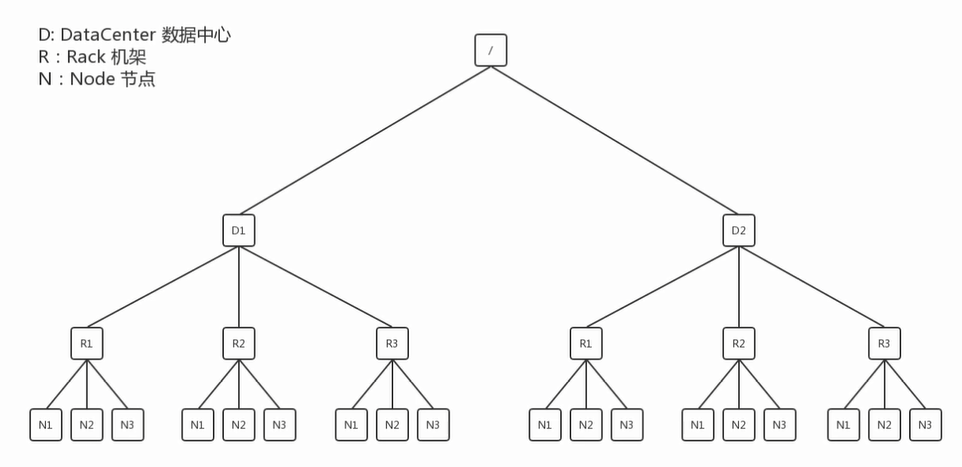
N1与N2之间的距离为2;(找线条数)
假设N1、N2、N3三台机器,从N1上传数据,则最短的节点就是它本身0;
后两个的选择是根据机架感知来选:
For the common case, when the replication factor is three, HDFS’s placement policy is to put one replica on one node in the local rack,
another on a different node in the local rack, and the last on a different node in a different rack.
第二个副本和第一个副本位于相同机架,随机节点;
第三个副本位于不同机架的随机节点;前提都是在相同数据中心的。
串行而不是并行;在于集群的性能限制,第一是NameNode的内存;第二个限制是IO(网络IO| 磁盘IO ),串行每个都是一进一出,而并行全部集中在client上导致传输的性能下降;
2. HDFS读数据流程(下载)


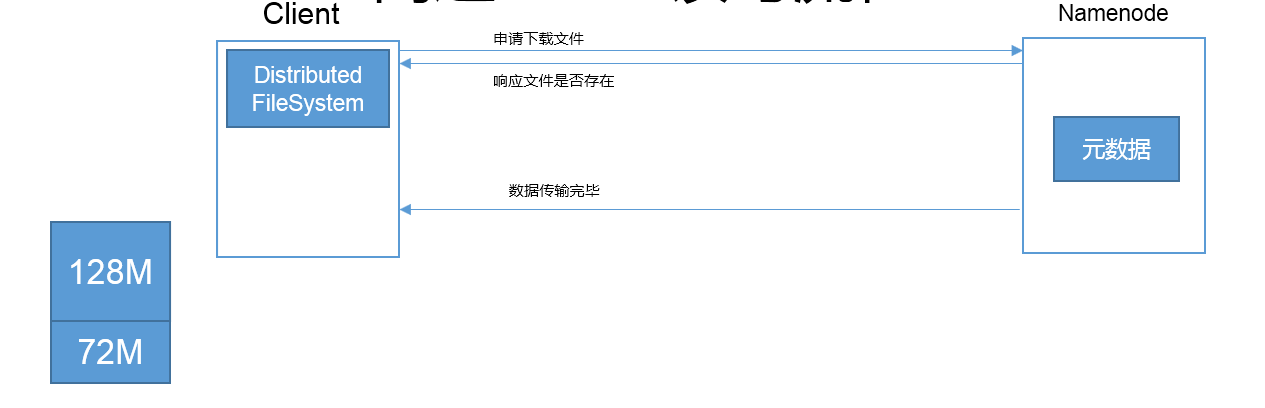
1)客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。给Client响应;
2)Client发起请求下载第一块Block数据;NameNode返回DN1、DN2、DN3表示用这3个节点存储的数据;
3)Client挑选一台DataNode(就近原则,然后随机)服务器,发起建立通信通道请求,DN1回应应答成功;
4 )Client打开一个流FSDataInoutStream 请求读取数据,DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
4)客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
5 )依次重复 2)--4)直到全部下载完成;NameNode响应数据传输完毕,流FSDataInputStream关闭;
3. NN和2NN的工作机制
NameNode的元数据需要存放在内存中,因为经常需要进行随机访问还有响应客户请求,为了提高效率;
同时在磁盘中备份元数据的FsImage,为了数据的安全性防止断电等导致元数据的丢失;
引入Edits文件(只进行追加操作,效率很高),(是为了解决内存中元数据更新时,若同时更新FsImage导致效率降低;若不更新产生一致性问题一旦NameNode节点断电导致数据丢失)每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到Edits中。这样,一旦NameNode节点断电,可以通过FsImage和Edits的合并,合成元数据。
引入一个新的节点SecondaryNamenode,专门用于FsImage和Edits的合并。(如果长时间添加数据到Edits中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行FsImage和Edits的合并,如果这个操作由NameNode节点完成,又会效率过低。)
这种保存机制类似在Redis的RDB和AOF:
RDB保存的快,读取的慢;AOF保存的快安全性高,读取慢;
类似AOF的保存是edits.log(每一个对元数据的变动,增删改查,都会立即持久化到edits.log)
类似RDB的是FSimage,随着NN的操作,每隔一段时间存一个档; 启动的时候先加载这个存档,然后再加载很短的一段edits.log;
NN是只写edits.log这个文件并且负责edits.log和FSimage的合并;
先加载fsimage(存档),再加载edits.log(过程);
先写edits,再读写到内存(为了数据的安全性);
edits-inprogress_002这种的都不会删除,而fsimage是只保留最新的2份;
Fsimage:NameNode内存中元数据序列化后形成的文件。包含HDFS文件系统的所有目录和文件inode的序列化信息;是HDFS文件系统元数据的永久性检查点;
Edits:记录客户端更新--增删改元数据信息的每一步操作。
NameNode启动时,先滚动Edits并生成一个空的edits.inprogress,然后加载Edits和Fsimage到内存中,此时NameNode内存就持有最新的元数据信息。
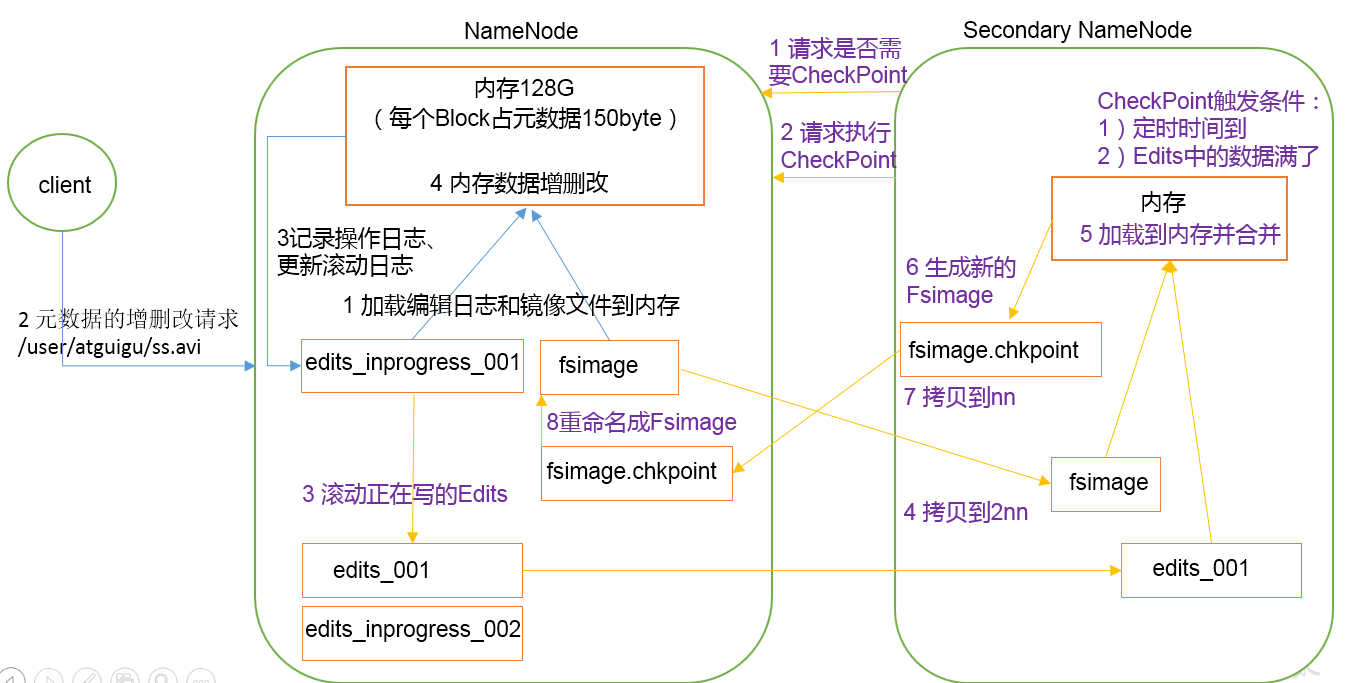
第一阶段:NameNode启动
1 )第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志eidts_inprogress_001和镜像文件Fsimage到内存(先加载Fsimage--存档,再加载edits_inprogress_001;)。
2 )客户端对元数据进行增删改的请求。(先记录在edits_inprogress_001再加载到内存为了数据的安全性;)
3 )记录操作日志edits_inprogress_001和更新滚动日志;这些请求的操作首先会被记录到edits.inprogress中(查询元数据的操作不会被记录在Edits中,因为查询操作不会更改元数据信息); 如果此时NameNode挂掉,重启后会从Edits中读取元数据的信息。
4 )然后,NameNode会在内存中执行元数据的增删改的操作。
第二阶段:Secondary NameNode工作
1 )Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
2 )Secondary NameNode请求执行CheckPoint。
3 )NameNode滚动正在写的Edits日志,并生成一个空的edits_inprogress_002,滚动Edits的目的是给Edits打个标记,以后所有新的操作都写入edits_inprogress_002
4)将滚动前的编辑日志Edits_001和镜像文件fsimage 拷贝到Secondary NameNode。
5)加载到内存,并合并。(所谓合并,就是将Edits和Fsimage加载到内存中,照着Edits中的操作一步步执行,最终形成新的Fsimage。)
6)生成新的镜像文件fsimage.chkpoint。
7)拷贝fsimage.chkpoint到NameNode。
8)NameNode将fsimage.chkpoint重新命名成fsimage,替换掉原来的Fsimage。
hdfs oiv查看Fsimage文件



[kris@hadoop101 current]$ ll 总用量 7256 -rw-rw-r--. 1 kris kris 1048576 1月 17 17:10 edits_0000000000000000001-0000000000000000001 -rw-rw-r--. 1 kris kris 42 1月 18 11:08 edits_0000000000000000002-0000000000000000003 -rw-rw-r--. 1 kris kris 1048576 1月 18 17:12 edits_0000000000000000004-0000000000000000020 -rw-rw-r--. 1 kris kris 1048576 1月 18 18:27 edits_0000000000000000021-0000000000000000021 -rw-rw-r--. 1 kris kris 42 1月 18 18:29 edits_0000000000000000022-0000000000000000023 -rw-rw-r--. 1 kris kris 3869 1月 18 19:29 edits_0000000000000000024-0000000000000000074 -rw-rw-r--. 1 kris kris 922 1月 18 20:29 edits_0000000000000000075-0000000000000000090 -rw-rw-r--. 1 kris kris 1048576 1月 18 20:37 edits_0000000000000000091-0000000000000000107 -rw-rw-r--. 1 kris kris 42 1月 19 11:28 edits_0000000000000000108-0000000000000000109 -rw-rw-r--. 1 kris kris 42 1月 19 12:28 edits_0000000000000000110-0000000000000000111 -rw-rw-r--. 1 kris kris 42 1月 19 13:28 edits_0000000000000000112-0000000000000000113 -rw-rw-r--. 1 kris kris 1276 1月 19 14:28 edits_0000000000000000114-0000000000000000127 -rw-rw-r--. 1 kris kris 42 1月 19 15:28 edits_0000000000000000128-0000000000000000129 -rw-rw-r--. 1 kris kris 42 1月 19 16:28 edits_0000000000000000130-0000000000000000131 -rw-rw-r--. 1 kris kris 1048576 1月 19 16:28 edits_0000000000000000132-0000000000000000132 -rw-rw-r--. 1 kris kris 1048576 1月 19 20:45 edits_0000000000000000133-0000000000000000133 -rw-rw-r--. 1 kris kris 14290 1月 20 12:24 edits_0000000000000000134-0000000000000000254 -rw-rw-r--. 1 kris kris 42 1月 20 13:24 edits_0000000000000000255-0000000000000000256 -rw-rw-r--. 1 kris kris 42 1月 20 14:24 edits_0000000000000000257-0000000000000000258 -rw-rw-r--. 1 kris kris 1048576 1月 20 14:24 edits_inprogress_0000000000000000259 -rw-rw-r--. 1 kris kris 2465 1月 20 13:24 fsimage_0000000000000000256 -rw-rw-r--. 1 kris kris 62 1月 20 13:24 fsimage_0000000000000000256.md5 -rw-rw-r--. 1 kris kris 2465 1月 20 14:24 fsimage_0000000000000000258 -rw-rw-r--. 1 kris kris 62 1月 20 14:24 fsimage_0000000000000000258.md5 -rw-rw-r--. 1 kris kris 4 1月 20 14:24 seen_txid -rw-rw-r--. 1 kris kris 206 1月 20 11:36 VERSION [kris@hadoop101 current]$ [kris@hadoop101 current]$ cat seen_txid //文件保存的是一个数字,就是最后一个edit_数字 259 [kris@hadoop101 current]$ hdfs oiv -p XML -i fsimage_0000000000000000258 -o /opt/module/hadoop-2.7.2/fsimage.xml [kris@hadoop101 current]$ sz /opt/module/hadoop-2.7.2/fsimage.xml
可以看出,Fsimage中没有记录块所对应DataNode
在集群启动后,要求DataNode上报数据块信息,并间隔一段时间后再次上报。
[kris@hadoop101 current]$ hdfs oev -p XML -i edits_0000000000000000257-0000000000000000258 -o /opt/module/hadoop-2.7.2/edits.xml
[kris@hadoop101 current]$ sz /opt/module/hadoop-2.7.2/edits.xml
NameNode如何确定下次开机启动的时候合并哪些Edits
CheckPoint时间设置
1)通常情况下,SecondaryNameNode每隔一小时执行一次。
2)一分钟检查一次操作次数;
3 )当操作次数达到1百万时,SecondaryNameNode执行一次。
NameNode故障处理
方法一
将SecondaryNameNode中数据拷贝到NameNode存储数据的目录;
这样做有隐患,会使得数据有丢失,2NN有一部分数据还没合并(没到合并触发机制)
[kris@hadoop103 dfs]$ ll
总用量 8
drwx------. 3 kris kris 4096 1月 20 11:37 data
drwxrwxr-x. 3 kris kris 4096 1月 20 11:37 namesecondary
[kris@hadoop103 dfs]$ scp -r namesecondary hadoop101:/opt/module/hadoop-2.7.2/data/tmp/dfs
[kris@hadoop101 dfs]$ ll
总用量 8
drwx------. 2 kris kris 4096 1月 20 15:51 data
drwxrwxr-x. 3 kris kris 4096 1月 20 15:52 namesecondary
[kris@hadoop101 dfs]$ mv namesecondary/ name
[kris@hadoop101 dfs]$ ll
总用量 8
drwx------. 2 kris kris 4096 1月 20 15:51 data
drwxrwxr-x. 3 kris kris 4096 1月 20 15:52 name
kris@hadoop101 dfs]$ start-dfs.sh
Starting namenodes on [hadoop101]
hadoop101: starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-kris-namenode-hadoop101.out
bin/hadoop fs 具体命令 OR bin/hdfs dfs 具体命令
dfs是fs的实现类。
bin/hadoop fs 可得到所有的命令
可直接创建并写入文件;ctrl+c结束;>>是追加
[kris@hadoop101 ~]$ cat >> 1
a
f
d
>是把之前的覆盖掉了
[kris@hadoop101 ~]$ cat > 1
2 3 4
方法二
1.修改hdfs-site.xml中的
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>120</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp/dfs/name</value>
</property>
2.kill -9 NameNode进程
[kris@hadoop101 hadoop]$ kill -9 5553
3. 删除NameNode存储的数据(/opt/module/hadoop-2.7.2/data/tmp/dfs/name)
rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/*
4. 如果SecondaryNameNode不和NameNode在一个主机节点上,需要将SecondaryNameNode存储数据的目录拷贝到NameNode存储数据的平级目录,并删除in_use.lock文件
[kris@hadoop103 dfs]$ scp -r namesecondary hadoop101:/opt/module/hadoop-2.7.2/data/tmp/dfs
[kris@hadoop101 namesecondary]$ rm -rf in_use.lock
[atguigu@hadoop101 dfs]$ pwd
/opt/module/hadoop-2.7.2/data/tmp/dfs
[atguigu@hadoop101 dfs]$ ls
data name namesecondary
[kris@hadoop101 hadoop-2.7.2]$ hdfs namenode -importCheckpoint
[kris@hadoop101 hadoop-2.7.2]$ hadoop-daemon.sh start namenode
starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-kris-namenode-hadoop101.out
集群安全模式

集群处于安全模式,不能执行重要操作(写操作)。集群启动完成后,自动退出安全模式。
(1)bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态)
(2)bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
(3)bin/hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态)
(4)bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式状态)
4. DataNode
工作机制
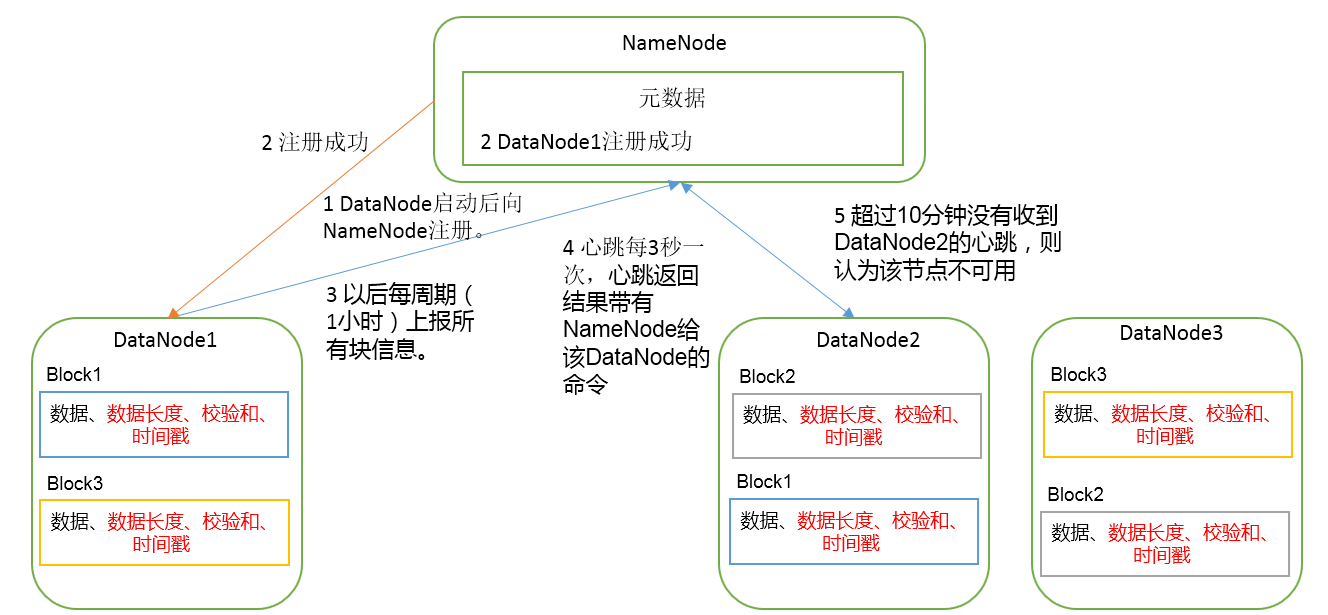
1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是数据块的元数据包括数据块的长度,块数据的校验和,以及时间戳。
2)DataNode启动后向NameNode注册(拜山头)来获取集群的ID,通过后,周期性(1小时)的向NameNode上报所有的块信息。首次上报是集群刚刚启动时安全模式下;块所在位置的信息并不由NameNode
来维护,因为要求块的信息是动态(周期性的汇报)的而不能是静态的,这也是触发自动备份机制的条件。
3)心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
4)集群运行中可以安全加入和退出一些机器。
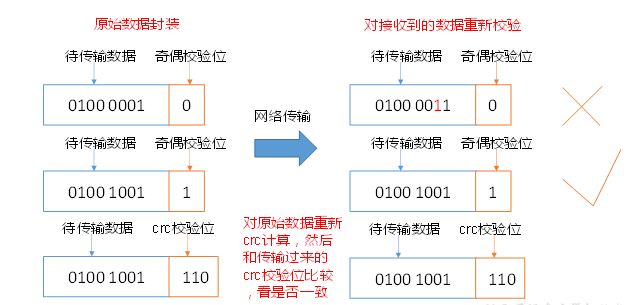
校验和(crc 、md5、sha1)用小的数据段来表示长的数据段的特征
DataNode节点保证数据完整性的方法。
1)当DataNode读取Block的时候,它会计算CheckSum。
2)如果计算后的CheckSum,与Block创建时值不一样,说明Block已经损坏。
3)Client读取其他DataNode上的Block。
4)DataNode在其文件创建后周期验证CheckSum
掉线时限参数设置
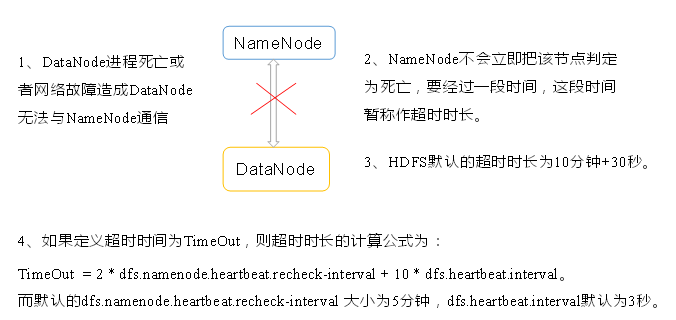
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。
服役新数据节点
环境准备
(1)在hadoop103主机上再克隆一台hadoop104主机
(2)修改IP地址和主机名称
(3)删除原来HDFS文件系统留存的文件(/opt/module/hadoop-2.7.2/data和log)
(4)source一下配置文件
[kris@hadoop104 hadoop-2.7.2]$ source /etc/profile
服役新节点具体步骤 (1)直接启动DataNode,即可关联到集群 [kris@hadoop104 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode [atguigu@hadoop104 hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager
退役旧数据节点
添加白名单
添加到白名单的主机节点,都允许访问NameNode,不在白名单的主机节点,都会被退出。
配置白名单的具体步骤如下:
1)在NameNode的/opt/module/hadoop-2.7.2/etc/hadoop目录下创建dfs.hosts文件
[kris@hadoop101 hadoop]$ pwd
/opt/module/hadoop-2.7.2/etc/hadoop
[kris@hadoop101 hadoop]$ touch dfs.hosts
[kris@hadoop101 hadoop]$ vi dfs.hosts
#添加如下主机名称(不添加hadoop104)
hadoop101
hadoop102
hadoop103
2)在NameNode的hdfs-site.xml配置文件中增加dfs.hosts属性
<property>
<name>dfs.hosts</name>
<value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts</value>
</property>
3)配置文件分发
[kris@hadoop101 hadoop]$ xsync hdfs-site.xml
4)刷新NameNode
[kris@hadoop101 hadoop]$ hdfs dfsadmin -refreshNodes Refresh nodes successful 5)更新ResourceManager节点 [kris@hadoop101 hadoop]$ yarn rmadmin -refreshNodes 19/01/20 20:29:10 INFO client.RMProxy: Connecting to ResourceManager at hadoop102/192.168.1.102:8033 如果数据不均衡,可以用命令实现集群的再平衡 [kris@hadoop101 sbin]$ ./start-balancer.sh starting balancer, logging to /opt/module/hadoop-2.7.2/logs/hadoop-atguigu-balancer-hadoop102.out Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved
黑名单退役
在黑名单上面的主机都会被强制退出。
1.在NameNode的/opt/module/hadoop-2.7.2/etc/hadoop目录下创建dfs.hosts.exclude文件
[kris@hadoop101 hadoop]$ touch dfs.hosts.exclude [kris@hadoop101 hadoop]$ vi dfs.hosts.exclude
添加如下主机名称(要退役的节点)
hadoop105
2.在NameNode的hdfs-site.xml配置文件中增加dfs.hosts.exclude属性
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts.exclude</value>
</property>
3.刷新NameNode、刷新ResourceManager
[kris@hadoop101 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes Refresh nodes successful [kris@hadoop101 hadoop-2.7.2]$ yarn rmadmin -refreshNodes 17/06/24 14:55:56 INFO client.RMProxy: Connecting to ResourceManager at hadoop102/192.168.1.103:8033
4. 检查Web浏览器,退役节点的状态为decommission in progress(退役中),说明数据节点正在复制块到其他节点,如图
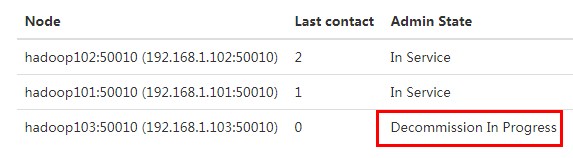
5. 等待退役节点状态为decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。注意:如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役。

[kris@hadoop105 hadoop-2.7.2]$ sbin/hadoop-daemon.sh stop datanode stopping datanode [kris@hadoop105 hadoop-2.7.2]$ sbin/yarn-daemon.sh stop nodemanager stopping nodemanager
6. 如果数据不均衡,可以用命令实现集群的再平衡
[kris@hadoop102 hadoop-2.7.2]$ sbin/start-balancer.sh starting balancer, logging to /opt/module/hadoop-2.7.2/logs/hadoop-atguigu-balancer-hadoop102.out Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved
注意:不允许白名单和黑名单中同时出现同一个主机名称。
5. HDFS的客户端命令行操作
[kris@hadoop101 hadoop-2.7.2]$ hadoop fs -ls / Found 3 items -rw-r--r-- 3 kris supergroup 6 2019-01-18 17:09 /t1.txt -rw-r--r-- 3 kris supergroup 6 2019-01-18 17:12 /t2.txt drwxr-xr-x - kris supergroup 0 2019-01-18 17:05 /test hadoop fs -mkdir -p /sanguo/shuguo -p可以创建多级目录,不加-p只能创建单级 从本地到远程 剪切 [kris@hadoop101 hadoop-2.7.2]$ hadoop fs -moveFromLocal 1.txt /test 复制 [kris@hadoop101 hadoop-2.7.2]$ hadoop fs -copyFromLocal 2.txt /test <==> hadoop fs -put 1.txt /test 追加 追加一个文件到已经存在的文件末尾 [kris@hadoop101 hadoop-2.7.2]$ hadoop fs -appendToFile 2.txt /test/1.txt 查看 [kris@hadoop101 hadoop-2.7.2]$ hadoop fs -cat /test/1.txt
从远程到本地
剪切
-moveToLocal 功能:从hdfs剪切粘贴到本地
hadoop fs - moveToLocal /aaa/bbb/cc/dd /home/hadoop/a.txt
复制 从HDFS拷贝到本地
[kris@hadoop101 hadoop-2.7.2]$ hadoop fs -copyToLocal /test ./ <==等效==> hadoop fs -get /test ./ #将hdfs上的test目录复制到本机当前目录
复制 从HDFS的一个路径拷贝到HDFS的另一个路径
[kris@hadoop101 hadoop-2.7.2]$ hadoop fs -cp /test/1.txt /
移动 在HDFS目录中移动文件
[kris@hadoop101 hadoop-2.7.2]$ hadoop fs -mv /test/2.txt /
获取并合并
[kris@hadoop101 hadoop-2.7.2]$ ll
-rw-r--r--. 1 kris kris 61 1月 18 19:00 1.txt
[kris@hadoop101 hadoop-2.7.2]$ hadoop fs -getmerge /test/* ./1.txt ###不能合并到一个目录文件夹
[kris@hadoop101 hadoop-2.7.2]$ ll
-rw-r--r--. 1 kris kris 96 1月 18 19:14 1.txt
-cat 显示文件内容
hadoop fs -cat /hello.txt
查看尾部 [kris@hadoop101 hadoop-2.7.2]$ hadoop fs -tail /test/jpsall
-text 以字符形式打印一个文件的内容
hadoop fs -text /weblog/access_log.1
rmdir:删除空目录 hadoop fs -rmdir /test 删除文件夹 [kris@hadoop101 hadoop-2.7.2]$ hadoop fs -rm /test/1.txt 19/01/18 19:22:53 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes. Deleted /test/1.txt 递归删除 [kris@hadoop101 hadoop-2.7.2]$ hadoop fs -rm -r /bigdata 19/01/18 19:27:26 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes. Deleted /bigdata du统计文件夹的大小信息 [kris@hadoop101 hadoop-2.7.2]$ hadoop fs -du -s -h /test 35 /test [kris@hadoop101 hadoop-2.7.2]$ hadoop fs -du -h /test 29 /test/2.txt 6 /test/t1.txt 设置HDFS中文件的副本数量 [kris@hadoop101 hadoop-2.7.2]$ hadoop fs -setrep 10 /1.txt Replication 10 set: /1.txt
-chgrp 、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限
#循环 往HDFS路径下 追加字符串
for file in `hadoop fs -ls /user/xxxx/ | awk '{print $8}'`;
do echo "hello world" | hadoop fs -put - $file;
done
[kris@hadoop101 hadoop-2.7.2]$ sudo yum install -y lrzsz
sz 是下载到本地; rz -E是从本地上传文件



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人