
JavaSE| 集合
集合
l Collection 层次结构中的根接口。Collection 表示一组对象,这些对象也称为 collection 的元素。一些 collection 允许有重复的元素,而另一些则不允许。一些 collection 是有序的,而另一些则是无序的。JDK 提供更具体的子接口(如 Set 和 List、Queue)实现。此接口通常用来传递 collection,并在需要最大普遍性的地方操作这些 collection。
l List:有序的 collection(也称为序列)。此接口的用户可以对列表中每个元素的插入位置进行精确地控制。用户可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素。
l Queue:队列通常(但并非一定)以 FIFO(先进先出)的方式排序各个元素。不过优先级队列和 LIFO 队列(或堆栈)例外,前者根据提供的比较器或元素的自然顺序对元素进行排序,后者按 LIFO(后进先出)的方式对元素进行排序。
l Set:一个不包含重复元素的 collection。更确切地讲,set 不包含满足 e1.equals(e2) 的元素对 e1 和 e2,并且最多包含一个 null 元素。正如其名称所暗示的,此接口模仿了数学上的 set 抽象。
l SortedSet进一步提供关于元素的总体排序 的 Set。这些元素使用其自然顺序进行排序,或者根据通常在创建有序 set 时提供的 Comparator进行排序。该 set 的迭代器将按元素升序遍历 set。提供了一些附加的操作来利用这种排序。
l Map:将键映射到值(key,value)的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。 Map 接口提供三种collection 视图,允许以键集、值集或键-值映射关系集的形式查看某个映射的内容。映射顺序 定义为迭代器在映射的 collection 视图上返回其元素的顺序。某些映射实现可明确保证其顺序,如 TreeMap 类;另一些映射实现则不保证顺序,如 HashMap 类。
l SortedMap进一步提供关于键的总体排序 的 Map。该映射是根据其键的自然顺序进行排序的,或者根据通常在创建有序映射时提供的 Comparator 进行排序。

数组是一个容器,已经可以存储多个对象,逻辑结构是线性的,顺序的存储结构;
申请内存:一次申请一大段连续的空间,一旦申请到了,内存就固定了。
存储特点:所有数据存储在这个连续的空间中,数组中的每一个元素都是一个具体的数据(或对象),所有数据都紧密排布,不能有间隔。
数组的操作
查询:每一个元素都有一个数值下标,可以通过下标瞬间定位到某个元素
增加:
先使用total变量辅助记录实际存储元素个数
从尾部增加:数组名[total++]=新元素
从其他位置插入:先把index位置开始所有元素后移,然后数组名 [index]=新元素
删除:先把index后面的元素前移,然后数组名[total--]=null
改:直接数组名[index]=新元素
数组优点
按索引查询效率高
数组不足:(添加/ 删除效率低,都涉及到移动元素)
1)一旦确定就没发修改,如果修改要负责扩容代码;
2)无法直接获取实际存储了几个对象,需要类似于total的变量辅助。
集合:新的容器,只用来装对象,不能用来装基本数据类型的数据
集合比数组
(1)类型更丰富,它有各种特征的集合
(2)无需程序员来编写“扩容”等代码,也不用通过"total"来记录实际的元素的个数
分为两大类:
(1)Collection:存储一组对象,单身party
(2)Map:存储“映射关系”的,存储“键值对” (key,value),情侣party,家庭party
Collection:最常用的两个子接口
List:有序(添加的顺序)的可重复的
Set:无序(添加的顺序)的不可重复
1. java.util.Collection接口
java.util.Collection:接口
JDK 不提供此接口的任何直接 实现:它提供更具体的子接口(如 Set 和 List)实现
1、添加
* boolean add(Object obj)
* boolean addAll(Collection other):
* 当前集合 = 当前集合 ∪ other集合
Collection c = new ArrayList(); //多态引用; ArrayList是List接口的实现类,List接口是Collection的子接口
c.add( 对象 ); c.add(12); //因为12会自动装箱类Integer的对象
c1.add(c2); //增加另外一个集合; 如果有重复元素,也会添加进去。集合可以有重复元素;
c.add(c2);//把C2当成一个整体看; c.addAll(c2);//把c2中的元素,一个一个添加到c中
2、删除
* boolean remove(Object o)
* boolean removeAll(Collection other)
* 当前集合 = 当前集合 - (当前集合 ∩ other)
* void clear()
c.remove( );
//c.removeAll(c2);//会用c2中的元素,与c中的元素进行equals,如果相同的就把c集合中的元素删除,而c2中的元素不会改变不会被删除。如果移除成功就返回true,否则false
3、修改(没有提供)
4、查找:
* boolean contains(Object o)
* boolean containsAll(Collection c); c1.containsAll(c2); 如果c1中的元素全部都包含c2的元素,就返回true; c2是否是c1的子集。
* 判断c集合是否是当前集合的子集
* boolean isEmpty()
删除、查找等要依据元素的equals方法,如果元素没有重写equals,那么equals就等同于==,要注意元素是否重写equals。
像String,Integer...等重写了equals
5、获取元素的个数
* int size()
6、排序(没有提供)
* 没有提供的原因,某些集合自带排序功能,而且Collections工具类有排序功能
*
7、遍历
* Iterator<E> iterator() :获取集合自身的迭代器,用于遍历集合用的
* Object[] toArray()
*
//用迭代器迭代集合;用于按条件删除或修改等; Iterator接口
Iterator iter = c1.iterator(); A:boolean hasNext():是否还有元素可迭代
Object obj = iter.next(); B:Object next() 取出下一个元素
for (Object object : c1) { C:remove():删除刚刚迭代的元素
System.out.print(object);
}
//转成数组迭代;
Object[] objArray = c1.toArray();
for (Object object : objArray) {
System.out.print(object);
}
//直接用增强for循环; 只是查找和查看,用它更简洁更快
for (Object object : c1) {
System.out.println(object);
}
8、求两个集合的交集
* boolean retainAll(Collection<?> c)
当前集合 = 当前集合 ∩ other
c1.retainAll(c2);
1)如果两个集合元素完全一样 返回值为false;2)c1包含于c2中 返回值为false;3)其他 返回值为true。
实际上该方法是指:如果集合c1中的元素都在集合c2中,则c1中的元素不做移除操作,反之如果只要有一个不在c2中则会进行移除操作。
即:c1进行移除操作返回值为:true; 反之返回值则为false。
boolean retainAll = c1.retainAll(c2);
System.out.println(retainAll);
System.out.println("c的有效元素的个数:" + c1.size());//如果存在交集,有相同元素,c1中只保留相同的元素;
//如果不存在相同元素,则c1会变空;
2. java.util.Iterator接口
(1)boolean hasNext() :是否有下一个元素需要迭代
(2)Object next() :取出下一个元素
(3)void remove() :删除刚刚迭代的元素
Iterator iter = c.iterator();//在iterator()给我们创建了一个Iterator的实现类对象; iter的作用就是遍历、迭代集合;
while(iter.hasNext()){
Object object = iter.next();
Student stu = (Student) object;
if(stu.getScore() < 90){ // if("李四".equals(obj))
iter.remove();//调用的是迭代器自己的删除方法; //而foreach不允许在遍历是添加、删除元素
}
}//要在while循环结束后再迭代查看它
System.out.println("迭代删除后:---------------------");
for (Object object : c) {
System.out.println(object);
}
一、增加一个接口:java.lang.Iterable接口
* JDK1.5增加
* 它有一个抽象方法:Iterator iterator()
* 实现这个接口允许对象成为 "foreach" 语句的目标
* Collection从JDK1.5之后开始继承Iterable接口。
二、java.util.Iterator接口在哪里实现的?
* //左边是Iterator接口,说明右边一定创建了一个Iterator接口的实现类对象,否则iterator调用方法是没有方法体可以执行
Iterator iterator = list.iterator();
* 跟踪源代码:list.iterator()
* public Iterator<E> iterator() {
return new Itr();//Itr是一个内部类
}
* 跟踪每一种Collection的集合发现,所有的集合在内部都一个内部类来实现java.util.Iterator接口。
*
* 为什么?
* (1)每一种集合的内部实现物理结构不一样,有的是数组有的是链表等,迭代方式不一样,无法给出统一的实现
* (2)迭代的作用,为某个集合迭代,遍历元素,那么它只为某类集合服务,迭代时又需要访问集合的内部(private)的元素,
* 所以我们设计为内部类更合适。
*
* 我们可以把迭代器比喻成:公交车上的售票员,飞机上空姐,他只为本集合服务
*/
3. java.util.List接口
(比Collection多了和索引index相关的方法)
* 有序的 collection(也称为序列)。此接口的用户可以对列表中每个元素的插入位置进行精确地控制。
* 用户可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素。
* List是Collection的子接口,那么Collection中的方法它也有。* List增加了Collection接口没有的方法,和索引位置相关的方法:
1、添加 * boolean add(Object obj):List系列的,默认添加到最后 * boolean addAll(Collection other):List系列的,默认添加到最后 * * boolean add(int index ,Object obj):在指定位置index处,插入一个元素obj * boolean add(int index, Collection other):在指定位置index处,插入多个元素,other中的多个元素 * 2、删除 * boolean remove(Object o) ; 这个是指定元素。 * boolean removeAll(Collection other) * void clear() * * Object remove(int index):删除指定位置index的元素,删除的同时还返回了该元素,如果需要就接收,不需要就不接收。 //Object remove = list.remove(1); * 3、修改(有提供) * Object set(int index, Object element) :替换集合index位置的元为element,返回被替换的旧元素 ; lis.set( 1, 8 ); * 4、查找: * boolean contains(Object o) * boolean containsAll(Collection c) * 判断c集合是否是当前集合的子集 * boolean isEmpty() * * int indexOf(Object o) //int index = list.indexOf("李四"); * int lastIndexOf(Object o) //查找最后一个元素的索引位置 * Object get(int index) //list.get( 2 ) ; * 5、获取元素的个数 * int size() * 7、遍历 * Iterator<E> iterator() :获取集合自身的迭代器,用于遍历集合用的 * Object[] toArray() * 增加了: * ListIterator<E> listIterator(): ListIterator和Iterator有什么不同? Iterator只能从前往后遍历,而ListIterator可以从任意位置从前往后,从后往前。 ListIterator iter = lis.listIterator(); while(iter.hasNext()){ Object nex = iter.next(); System.out.println(nex); } ListIterator iterator = lis.listIterator(lis.size()); //从后边往前边迭代; int previousIndex();还增加了迭代的同时:set和add while(iterator.hasPrevious()){ Object pre = iterator.previous(); System.out.println(pre); } 8、截取列表的一部分 List<E> subList(int fromIndex, int toIndex) System.out.println(lis.subList(0, 3)); //[1, 2, 3]
List接口的实现类
java.util.List接口的实现类有:
- java.util.ArrayList:动态数组
- java.util.Vector:动态数组
- java.util.LinkedList:链表
- java.util.Stack:栈
① ArrayList和Vector
(它们底层都是数组--称为动态数组)
Vector:是旧版本,线程安全的,扩容机制为原来的2倍,支持旧版的Enumeration迭代器
ArrayList:是新版本,线程不安全的,扩容机制为原来的1.5倍,不支持Enumeration迭代器
ArrayList只用:foreach和Iterator或ListIterator
只看,不改:foreach
看,并且删除:从前往后:Iterator
看,并且删除、插入,从前往后,或从后往前:ListIterator
如果需要再细化:
ArrayList在JDK1.7之后,如果new ArrayList(),一开始初始化为一个长度为0的空数组,在第一次添加元素时,初始化为容量为10的数组。
Vector:new Vector()直接初始化为容量为10的数组。
ArrayList、 LinkedList、Vector三者的异同? 同: 3个类都实现了List接口,存储数据的特点相同,存储有序、可重复的数据 不同: Collection接口: 单列集合, 用来存储一个一个的对象 List接口: 存储有序的、可重复的数据。 -> "动态"数组, 替换原有的数组 ArrayList: 作为List接口的主要实现类, 线程不安全的, 效率高; 底层使用Object[] elementData存储 Vector: 作为List接口的古老实现类, 线程安全的,效率低; 底层Object[] elementData存储 LinkedList:对于频繁插入、删除操作,使用此类效率比ArrayList高; 底层使用双向链表存储。 ArrayList源码分析: JDK7: ArrayList list = new ArrayList();//底层创建了长度是10的object[]数组 elementData list.add(123) //elementData[0] = new Integer(123); .. list.add(11) //如果此次的添加导致底层elementData数组容量不够,则扩容。 默认情况下,扩容为原来容量的1.5倍,同时需要将原来数组中的数据复制到新的数组中。 JDK8: ArrayList list = new ArrayList();//底层object[] elementData 初始化为{},并没有创建长度为10的数组; list.add(123) //第一次调用add()时,底层才创建了长度10的数组,并将数据123添加到 elementData[0] ..后序的添加和扩容操作与JDK7一样。 jdk7中Arraylist的对象的创建类似于单列的饿汉式,而jdk8 Arraylist的对象的创建类似于单列的懒汉式,延迟了数组的创建,节省了内存。 LinkedList源码分析: List<Object> list = new LinkedList<>();内部声明了Node类型的first和last属性,默认值为null list.add(123) //将123封装到Node中,创建了Node对象。 其中,Node定义体现了LinkedList双向链表的说法。 其中,Node定义为: private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }
② 动态数组与链表LinkedList区别
它们底层的物理结构不同
动态数组底层的实现是数组;
优点:可以根据索引快速的遍历和查找元素
缺点:长度不够,需要扩容,影响性能
删除后,要移动元素,并且空出大量的空间,浪费空间
需要开辟连续的存储空间
LinkedList是链表结构。
* 优点:有几个元素,占几个空间,不需要连续的空间
* 添加时,比较快,不需要扩容
* 删除:删除时,比较快,不需要移动元素;只要修改前后元素的关系就可以,和其他元素无关,无需移动
缺点:无法索引快速定位,如果要按索引操作,效率比较低,从头遍历
③ Stack栈
一种“先进后出FILO”或“后进先出LIFO”数据结构的集合。
Stack s = new Stack();
(1)push(Object obj) s.push("张三");
(2)Object peek():查看栈顶元素是什么 Object peek = s.peek();
(3)Object pop():取出栈顶元素
LinkedList:双向链表(即记录第一个结点first,又记录最后一个结点last)
队列Queue:先进先出(FIFO)
双端队列Deque:就可以从队头出去,也可以从队尾出去
从JDK1.6开始LinkedList又实现了Deque接口。
LinkedList把栈、队列、双向链表、双端队列所有方法都集为一身,只要调用对应的方法就可以实现各种需求。
自己设计一个MyArrayList,类似于ArrayList
MyArrayList对象作为容器使用:
添加、获取有效元素的个数、根据索引删除; 从索引位置,把右边的元素移动到左边;根据对象删除;根据对象查找下标;返回数组中实际存储的元素;判断某个元素是否存在
在指定位置添加,从index位置起它后边的元素都往右边移动;替换指定位置的元素,并返回被替换的旧元素;返回指定位置的元素


import java.util.Arrays; public class MyArrayList { private Object[] arr; private int total; public MyArrayList() { super(); //给数组初始化; arr = new Object[10]; } public MyArrayList(Object[] arr, int total) { super(); this.arr = arr; this.total = total; } //1. 添加方法 public void add(Object obj){ if(total == arr.length){ //判断数组是否满了,满了就扩容 //扩容 arr = Arrays.copyOf(arr, arr.length * 2); } arr[total++] = obj; } //2.获取有效元素的个数; public int size(){ return total; } //3.根据索引删除; 从索引位置,把右边的元素移动到左边; public void remove(int index){ if(index < 0 || index > total){ throw new IndexOutOfBoundsException("下标越界了"); } // 1,2,3,4,5,6,null ;要把index=1的小标删除,从index+1的位置移动,需要移动3,4,5,6 System.arraycopy(arr, index+1, arr, index, total-index-1); arr[total-1] = null; total--; } //4.根据对象删除 public void remove(Object obj){ int index = indexOf(obj);//调用找下标的方法 if(index != -1){ remove(index); } } //5.根据对象查找下标 public int indexOf(Object obj){ int index = -1; if(obj == null){ for(int i = 0; i < total; i++){ if(obj == arr[i]){ index = i; break; } } }else{ for(int i = 0; i < total; i++){ if(obj.equals(arr[i])){ index = i; break; } } } return index; } //6.返回数组中实际存储的元素 public Object[] toArray(){ return Arrays.copyOf(arr, total); } //7.判断某个元素是否存在 public boolean contains(Object obj){ int index = indexOf(obj); return index != -1; } //8.在指定位置添加,从index位置起它后边的元素都往右边移动; public void add(int index, Object obj){ if(index < 0 || index > total ){ throw new IndexOutOfBoundsException("下标越界了"); } if(total == index){ //扩容 arr = Arrays.copyOf(arr, arr.length * 2); } // 1,2,3,4,5,null; total=5,在index=2的位置插入一个新的 System.arraycopy(arr, index, arr, index+1, total-index); arr[index] = obj; total++; } //9.替换指定位置的元素,并返回被替换的旧元素 public Object set(int index, Object value){ if(index < 0 || index > total ){ throw new IndexOutOfBoundsException("下标越界了"); } Object old = arr[index]; arr[index] = value; return old; } //10.返回指定位置的元素 public Object get(int index){ if(index < 0 || index > total ){ throw new IndexOutOfBoundsException("下标越界了"); } return arr[index]; } }
单链表的添加和删除方法
package com.atguigu.testlink; public class MyLinked { //单链表 private Node first; //第一个节点的地址,节点就包含了数据data和next节点; private int total; class Node{ Object data; Node next; public Node(Object data, Node next) { super(); this.data = data; this.next = next; } } //1、添加方法 public void add(Object obj){ Node newNode = new Node(obj, null); //1)创建新节点newNode,它就包含数据对象和记录下一节点的地址 if(first == null){ //2)如果链表是空的; first = newNode; // }else{ Node last = first;// 1)先找到最后一个节点的地址 while(last.next != null){ last = last.next; } //如果为空了循环就退出来了,就把新节点赋值给它 last.next = newNode; //2)然后最后一个节点.next = newNode; } total++; } //2、获取有效元素个数 public int size(){ return total; } //返回链表所有的数据 public Object[] toArray(){ Object[] all = new Object[total]; //遍历链表,把Node的data放到all[i]中; Node node = first; // for (int i = 0; i < total; i++) { all[i] = node.data; node = node.next; } return all; } //4、删除 public void remove(Object obj){ if(first == null){ //1)链表是空的,直接结束 return; }else{ //2)要删除的就是第一个节点;//判断first是否是被删除目标 boolean isRemove = false; if(obj == null && first.data == null){ //分为obj是否为空 isRemove = true; }else if(obj != null && obj.equals(first.data)){ isRemove = true; } if(isRemove == true){ //isRemove是true说明第一个结点就是要删除的结点 first = first.next; }else{ //说明第一个结点不是要删除的目标结点 Node lastNode = first; Node node = lastNode.next; Node removeNode = null; // 遍历查找第二个结点到最后一个结点是否有被删除的目标结点 while(node.next != null){//把条件修改为node!=null,因为node = lastNode.next,说明node为空的话,lastNode就是最后一个节点,我们已经全部都找过 //分为obj是否为空 if(obj == null){ //如果node.data也为空,那么node就是被删除结点 if(node.data == null){ removeNode = node; break; }else{ //否则node和lastNode都往右移动 lastNode = node; node = node.next; } }else{ if(obj.equals(node.data)){ removeNode = node; break; }else{ lastNode = node; node = node.next; } } } if(node.next == null){ //最后一个节点 if(obj == null){ if(node.data == null){ removeNode = node; } }else{ if(obj.equals(node.data)){ removeNode = node; } } } if(removeNode == null){ return; }else{ lastNode.next = removeNode.next; removeNode.data = null;//使得它尽快被回收 removeNode.next = null;//使得它尽快被回收 } } } total--; } }
public class TestMyLinked {
public static void main(String[] args) {
MyLinked my = new MyLinked();
System.out.println(my.size()); //第一个节点为空,first == null; total==0
my.add("李四");//first:
data:hash==0、value[0]李 [1]四;
next:null
my.add("王五");//first:
data:hash==0、value[0]李 [1]四;
next: data:hash==0、value[0]王 [1]五;
next:null
my.add("赵六");//first:
data:hash==0、value[0]李 [1]四;
next: data:hash==0、value[0]王 [1]五;
next:data:hash==0、value[0]赵 [1]六;
next:null
my.add("Hello");
System.out.println(my.size());
my.remove("赵六");
System.out.println(my.size());
}
}
4. java.util.Set接口
(Collection另一个接口)
一个不包含重复元素的 collection
- 更确切地讲,set 不包含满足 e1.equals(e2) 的元素对 e1 和 e2,并且最多包含一个 null 元素。
- 正如其名称所暗示的,此接口模仿了数学上的 set 抽象。
- Set的方法都是继承自Collection。
Set的实现类们
① HashSet
对于HashSet而言,它是基于HashMap,哈希表来实现的,底层采用HashMap来保存元素;
不保证set 的迭代顺序,元素是完全无序的,它的顺序是由hash值来决定的。允许使用null元素。
HashSet:元素的存储和是否重复要依赖于元素的:hashCode()和equals()方法。
仅仅是存储不重复的元素,不是key value结构,HashSet里面的HashMap的value则存储了一个PRESENT,它是一个静态的Object对象,因此HashSet也是非线程安全的,HashSet就是个简化的HashMap。
在HashSet中添加一个新元素时, 其实这个值是存储在底层Map的key中,而众所周知,HashMap的key值是不能重复的, 所以这里就可以达到去重的目的了。
根据 seriesId 和 listMonth 这两个字段去重,必须重写equals和hashCode方法。
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof NewListedCarDTO)) return false;
NewListedCarDTO that = (NewListedCarDTO) o;
if (seriesId != that.seriesId) return false;
if (listYear != that.listYear) return false;
return listMonth == that.listMonth;
}
@Override
public int hashCode() {
int result = (int) (seriesId ^ (seriesId >>> 32));
result = 31 * result + listYear;
result = 31 * result + listMonth;
return result;
}
② TreeSet
元素是按照“大小”顺序排列的(字母小的在前),和添加顺序无关。
TreeSet:元素的存储和是否重复要依赖于元素的比较大小的方法:int compareTo(Object o)或 指定的比较器的int compare(Object o1,Object o2)
@Test
public void test(){
HashSet set = new HashSet();/*set.add("kk");
set.add("alex");
set.add("dd");
set.add("java");
set.add("java");*///String重写了hashCode()和equals()方法,所以只能添加进去一个
//String实现了java.lang.Comparable接口
TreeSet set = new TreeSet();
set.add(2);
set.add(1); //Integer实现了java.lang.Comparable接口
set.add(8);//Integer也重写了hashCode()和equals()方法,所以只能添加进去一个
set.add(8);
for (Object object : set) {
System.out.println(object);
}
}
TreeSet set = new TreeSet();
set.add(new Student(2, "kk", 99));
set.add(new Student(3, "alx", 69));
set.add(new Student(4, "hk", 69)); //失败的原因,Student没有java.lang.Comparable,无法添加;
//Student cannot be cast to java.lang.Comparable
for (Object object : set) {
System.out.println(object);
}
③ LinkedHashSet
LinkedHashSet是HashSet的子类,但是比HashSet要多一个“记录元素添加顺序的功能”,因此它添加和删除的效率比HashSet相对低。
当你既想要元素不重复,又想要按照添加的顺序时,选择LinkedHashSet。如果你只是想要不重复,那么选择HashSet,如果你执行想要添加顺序,选ArrayList等。
String 、Integer都重写了hashCode()和equals()方法。
- LinkedHashSet 是 Set 的一个具体实现,其维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可为插入顺序或是访问顺序。
- LinkedHashSet 继承与 HashSet,并且其内部是通过 LinkedHashMap 来实现的。有点类似于LinkedHashMap 其内部是基于 Hashmap 实现一样
- 如果我们需要迭代的顺序为插入顺序或者访问顺序,那么 LinkedHashSet 是需要首先考虑的。
TreeSet:
(1) 按照元素的自然顺序排列:要求元素必须实现java.lang.Comparable接口
例如:String实现了java.lang.Comparable接口,它是按照字符的Unicode编码值来排序。
(2) 按照指定的定制比较器的规则排序,要求指定一个java.util.Comparator接口的实现类对象
例如:专门为比较String对象,定制了一个比较器java.text.Collator实现了java.util.Comparator接口
实现Comparable接口
public class TestMap2 {
@Test
public void test(){
TreeSet set = new TreeSet();
set.add(new Student(2,"kk",800));
set.add(new Student(1,"gk",100));
set.add(new Student(4,"alx",180));
for (Object object : set) {
System.out.println(object);
}
}
class Student implements Comparable{
private int id;
private String name;
private int score;
public Student() {
super();
}
public Student(int id, String name, int score) {
super();
this.id = id;
this.name = name;
this.score = score;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
@Override
public String toString() {
return "Student [id=" + id + ", name=" + name + ", score=" + score + "]";
}
@Override
public int compareTo(Object o) { //自然排序,按照员工的
Student stu = (Student) o;
//return this.score - stu.score; //按照成绩排序
//return this.id - stu.id; //自然顺序,按照学生id的编号排序
return this.name.compareTo(stu.getName()); //String有它自己的排序方法
}
}
指定一个comparator接口的实现类对象
public class TestMap2 {
@Test
public void Test1(){
TreeSet set = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
Student stu1 = (Student) o1;
Student stu2 = (Student) o2;
if(stu1.getScore() > stu2.getScore()){
return 1;
}else if(stu1.getScore() < stu2.getScore()){
return -1;
}else{
return 0;
} //因为double类型不精确,建议使用如下方法比较大小
/*long d1 = Double.doubleToLongBits(stu1.getScore());
long d2 = Double.doubleToLongBits(stu2.getScore());
if(d1 > d2){
return 1;
}else if(d1 < d2){
return -1;
}else{
return 0;
}*/
}
});
set.add(new Student(2,"kk",800));
set.add(new Student(1,"gk",100));
set.add(new Student(4,"alx",180));
for (Object object : set) {
System.out.println(object);
}
}
}
java.text.Collator类型比较字符串,可指定语言比较
//指定一个实现了java.util.Comparator接口的实现类的对象
//而且这个比较器还要比较两个“字符串”的大小
//java.text.Collator类型就符合要求
Collator instance = Collator.getInstance(Locale.CHINA);//Locale.CHINA指定语言环境
TreeSet set = new TreeSet(instance);
set.add("张三");
set.add("李四");
set.add("王五");
for (Object object : set) {
System.out.println(object);
}
5. java.util.Map接口
将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值(一个key只能对应一个value, 一个key, put多个value以最后put的为准; )。
Map接口的常用方法:
1、添加
put(Object key, Object value)
* 任意Java的引用数据类型都可以作为key和value的类型,但是最常见的是Integer和String比较多的作为key的类型。
* putAll(Map map):把另一个map集合的映射关系添加到当前Map中
Map map = new HashMap();
map.put("smile", 78);
map.put("kris", 78); //value可以一样,key不能一样;
2、获取映射关系的对数
* int size() //map.size();
3、查找
* boolean containsKey(Object key)
* boolean containsValue(Object value)
* V get(Object key) :根据key获取value; map.get("key");
* boolean isEmpty()
4、删除
* V remove(Object key) :根据key移除一对映射关系,并且返回对应的value
* void clear()
5、遍历
(1)Set keySet():因为Set不允许有重复元素,因为Map的所有key也是要求不允许重复的。
Set keys = map.keySet();
for (Object object : keys) {
System.out.println(object);
}
(2)Collection values() 因为value是可以重复的,所以这里不能用Set
Collection values = map.values();
for (Object object : values) {
System.out.println(object);
}
(3)Set entrySet() 因为key不重复,所以entry是不重复的 Entry类型是Map中的一个内部接口类型,映射项(键-值对)。它的实现类在Map的实现类中,以内部类的形式存在。
Set entrySet = map.entrySet();
for (Object object : entrySet) { //Entry接口,可以拿到K, V getKey() getValue()
System.out.println(object);
}
//Can only iterate over an array or an instance of java.lang.Iterable
//只有数组和Collection系列的集合
//map不能直接foreach
Map接口的实现类
Map结构的理解:
Map中的key:无序、不可重复的,使用Set存储所有的key -->key所在的类要重写equals()和hashCode() (以HashMap为例)
Map中的value:无序的、可重复的,使用Collection存储所有的value -->value所在的类重写equals()
一个键值对:key - value构成了一个Entry对象。
Map中的Entry:无序的、不可重复的,使用Set存储所有的entry;
① HashMap哈希表
Map的主要实现类,线程不安全的,效率高,存储null的key 和value
如何确定key的不重复和顺序的:依据key的 hashCode 方法和 equals 方法
② LinkedHashMap
保证在遍历map元素时,可以按照添加的顺序实现遍历;原因在原有的HashMap底层结构基础上,添加了一对指针,指向前一个和后一个元素;对于频繁的遍历操作,此类执行效率高于HashMap。
LinkedHashMap是HashMap的子类,比HashMap多维护了“添加”的顺序。
③ TreeMap
保证按照添加的key-value对进行排序,实现排序遍历。要按照key进行排序:自然排序、定制排序,底层使用红黑树。
如何确定key的不重复和顺序的:依据key的自然顺序或定制比较器的规则
因此要求要么key类型实现了java.lang.Comparable接口,并重写int compareTo(Object obj)
要么在创建TreeMap时指定定制比较器对象(它是实现java.util.Comparator接口,并重写int compare(Object o1, Object o2)的对象)
④ Hashtable哈希表
古老的实现类,线程安全的,效率低;不能存储null的key和value 。
如何确定key的不重复和顺序的: hashCode 方法和 equals 方法
⑤ Properties
常用来处理配置文件,key和value都是String类型。
Properties是Hashtable的子类,是一种特殊的集合,特殊在它的key和value的类型都是String
HashMap和Hashtable都是哈希表:
(判断两个key相等的标准:两个key的hashcode值相等且equals方法返回true)
Hashtable:旧版的,线程安全的,不允许key和value为null值;
HashMap:新版的,线程不安全的,允许key和value为null值;
关系:
HashSet和HashMap:HashSet其实就是一个HashMap,通过HashMap实现
添加到HashSet中的元素是作为HashMap的key,他们的value是共享了一个PRESENT(是Object类型的常量对象)
TreeSet和TreeMap: TreeSet其实就是一个TreeMap
添加到TreeSet中的元素是作为TreeMap的key,他们的value是共享了一个PRESENT(是Object类型的常量对象)
LinkedHashSet和LinkedHashMap:LinkedHashSet其实就是一个LinkedHashMap
面试题:1.Hash的底层实现原理? 2.HashMap和HashTable的异同 ? 3. CurrentHashMap与Hashtable的异同
练习
@Test public void test1(){ TreeMap map = new TreeMap(); //第一组 ArrayList list = new ArrayList(); list.add(new Student1("kris", 99)); list.add(new Student1("jing", 89)); list.add(new Student1("smile", 79)); map.put("第一组", list); //第二组 ArrayList list2 = new ArrayList(); list2.add(new Student1("张三",56)); list2.add(new Student1("李四",78)); map.put("第二组", list2); //第三组 ArrayList list3 = new ArrayList(); list3.add(new Student1("王五",99)); list3.add(new Student1("嘿嘿",45)); map.put("第三组", list3); Set entrySet = map.entrySet(); /*for (Object object : entrySet) { System.out.println(object); }*/ double max = -1; for (Object object : entrySet) { Entry entry = (Entry) object; // Entry类型是Map中的一个内部接口类型,映射项(键-值对)。它的实现类在Map的实现类中,以内部类的形式存在 Object group = entry.getKey(); System.out.println(group); System.out.print("该组学员有:"); ArrayList listvalue = (ArrayList)entry.getValue(); for (Object stu : listvalue) { System.out.println(stu); Student1 s = (Student1) stu; if(s.getScore() > max){ max = s.getScore(); } } }System.out.println("最高分为:" + max); }
6. HashMap底层实现
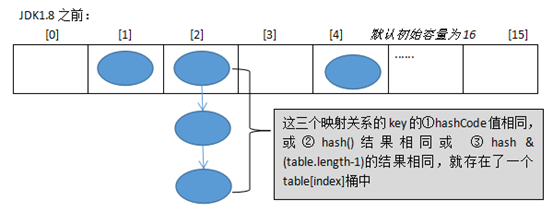
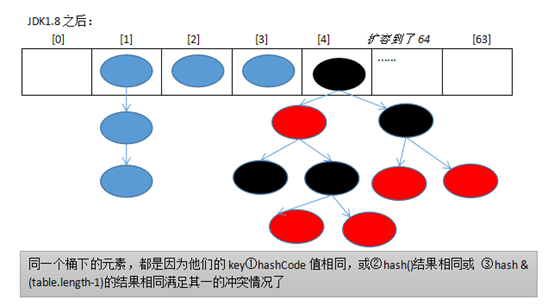
HashMap的底层实现原理? 以jdk7为例: HashMap map = new HashMap(); 在实例化以后,底层创建了长度是16的一维数组Entry[] table ...可能已经执行过很多次put... map.put(key1, value1): 首先,调用key1所在类的hashCode()计算key1哈希值,此哈希值经过某种算法计算以后,得到Entry数组中的存放位置。 如果此位置上的数据为空,此时key1-value1添加成功。 --情况1 如果此位置上的数据不为空,意味着此位置存在一个或多个数据(以链表形式存在),比较key1和已经存在的一个或多个数据的哈希值: 如果key1的哈希值与已经存在的数据的哈希值都不相同,此时key1-value1添加成功。 --情况2 如果key1的哈希值和已经存在的某一个数据(key2-value2)的哈希值相同,继续比较:调用key1所在类的equals(key2)方法 如果equals()返回false:此时key1-value1添加成功。 --情况3 如果equals()返回true:使用value1替换value2. 情况2和情况3:此时key1-value1和原来的数据以链表的方式存储。 在不断添加过程中,会涉及到扩容问题,默认的扩容方式:扩容为原来容量的2倍,并将原有的数据复制过来。 jdk8和jdk7在底层实现方面的不同: 1.new HashMap() 底层没有创建一个长度16的数组 2.jdk8底层的数组是 Node[], 而非Entry[] 3.首次调用put()方法时, 底层创建长度16的数组 4.jdk7底层结构只有 数组+链表; jdk8底层结构:数组 + 链表 + 红黑树 当数组的某一个索引位置上的元素以链表形式存放的数据个数 > 8且当前数组长度 > 64时,此时索引位置上的所有数据改为红黑树存储。
存储到HashMap中的映射关系(key,value),其中的key的hashCode值和equals方法非常重要。
单向链表,如果查找n个元素中的最后一个元素会遍历n遍;如5个元素,查找5遍;
而二叉树分left和right,5个元素查找最后一个则只查找3遍;
* HashMap的底层实现:
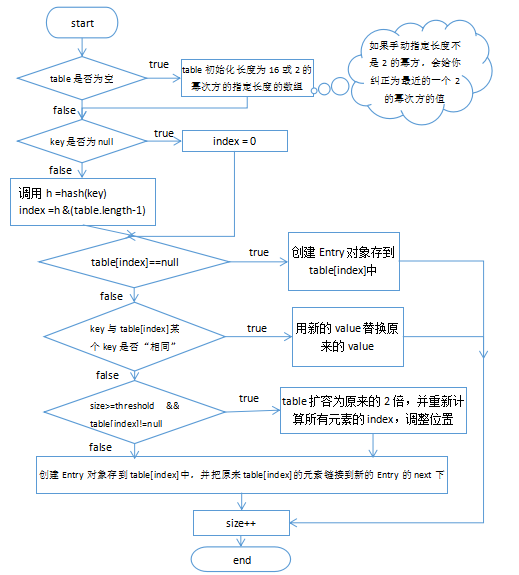
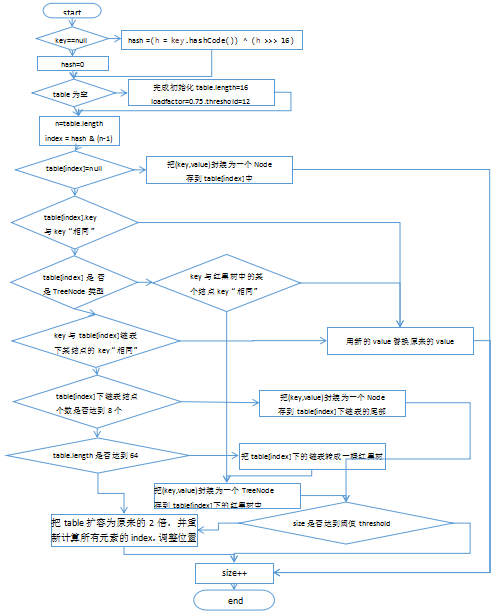
HashMap map = new HashMap(); * 1、简单版 * JDK1.7:HashMap的底层实现是:数组+单向链表 * JDK1.8:HashMap的底层实现是:数组+单向链表/红黑树 为什么要红黑树? * 红黑树:一个自平衡的二叉树 * 当结点多了用红黑树,少了用链表 * 因为少的话用红黑树太复杂,多了话用红黑树可以提高查询效率。 * 红黑树:(自动调整根结点,保证左右两边的结点数差不多),它会左旋,右旋来实现。 2、复杂v1.0版 * JDK1.7:HashMap的底层实现是:数组(初始长度为16)+单向链表 * 每一个对映射关系的存储位置: * 存储的位置:存储的位置和顺序是否重复,是依据key的hashCode()和equal()决定的; (1)先计算key的hash值,通过hashCode()就可以得到, (2)再用hash值经过各种(异或^)操作,得到一个int数字,目的是使得更均匀的分布在数组的每一个元素中。 (3)再用刚才的int值,与table数组的长度-1(int & table.length)做一个“按位与&"运算,目的是得到一个[i] 因为数组的长度是2的n次方,长度-1的数的二进制是前面都是0,后面都是1,任何数与它做“&”,结果一定是[0,该数]之间 为什么会出现链表? * (1)两个不同的key对象,仍然可能出现hashCode值一样 * (2)就算hashCode不一样,经过刚才的计算,得到[i]是一样的 * (3)而我们的数组的元素table[i]本来只能放一个元素,那么现在有多个元素需要存储到table[i]中,只能把这几个元素用链表连接起来 * 简单比喻: * y = f(x) * 两个不一样的x,可能得到一样的y; 那么存储到HashMap中的是什么样的元素呢? * (1)首先是Map.Entry类型:映射项(键-值对)。 * (2)其次HashMap有一个内部类HashMap.Entry实现了Map.Entry接口类型 * 内部类Entry由四部分组成: * (1)key * (2)value * (3)下一个Entry:next * (4)hash值计算的整数值,为了后面查询快一点 如何避免重复?(hash值取的是整数在内存中做比较比较快,而equals重写可能会比较很多次) * 如果两个key的hash值是一样的,还要调用一下equlas()方法,如果返回true,就会把新的value替换旧的value。 * 如果两个key的hash值是一样的,还要调用一下equlas()方法,如果返回false,就会把新的Entry连接到旧的Entry所在链表的头部(first) * 如果两个key的hash值是不一样的,但是[i]是一样的,就会把新的Entry连接到旧的Entry所在链表的头部(first) * 如果两个key的hash值是不一样的,并且[i]不一样的,肯定存在不同table[i]中 * 我们把table[i]称为“桶bucket”。 回忆:两个对象的hash值: * (1)如果两个对象是“相等”,他们的hash值一定是一样 * (2)如果两个对象的hash值是一样,他们可能是相同的对象,也可能是不同的对象;。 * * 3、复杂追踪源代码v2.0版 (1)什么时候扩容 * 当①元素的个数达到“阈值”,②并且新添加的映射关系计算出来的table[i]位置是非空的情况下,再扩容;(如果table[i]是空的就不扩容直接放进去,若是非空说明是连接到别的下面了;) * 默认加载因子 (0.75):DEFAULT_LOAD_FACTOR,也可自己手动赋值 * 阈值 = table.length * 加载因子(loadFactor) * 第一次阈值:16 * 0.75 = 12 默认初始容量:DEFAULT_INITIAL_CAPACITY:16 (1<<4即2^4) 第二次阈值:32 * 0.75 = 24 * ... * * HashMap中table的长度有一个要求:必须是2的n次方(如果你给的值不是2^n,它也会给你纠正一个最接近的值),是为了让2^n-1的二进制是11111... (2)跟踪一下put方法的源代码 * 第一步:先判断table是否为空数组,如果table是空的,会先把table初始化为一个长度为16的数组(在默认的构造器中创建);
如果你指定的长度不是2的n次方,会往上纠正为最接近的2的n次方(int capacity = roundUpToPowerOf2(toSize)),
并且把阈值threshold = table.length * 加载因子(loadFactor) = 12。 * 第二步:如果key是null,(空的就直接添加进去) 首先确定的位置是table[0], * 如果原来table[0]已经有key为null的Entry,用新的value替换旧的value * 如果原来table[0]没有key为null的Entry,那么创建一个新的Entry对象,作为table[0]桶下面的链表的头,原来的那些作为它next。 * * 第三步:如果key不是null(要先看看key是否相同),先计算hash(key),用key的hashCode值,通过hash()函数算出一个int值称为"hash" * 第四步:通过刚才的“hash”的int值与table.length-1做&运算,得到一个下标index,表示新的映射关系即将存入table[index] * 第五步:循环判断table[index]位置是否为空,并且是否有Entry的key与我新添加的key是否“相同”,如果相同,就用新的value替换旧的value * 第六步:添加新的映射关系 * (1)判断是否要扩容: * 当元素的个数达到“阈值”,并且新添加的映射关系计算出来的table[i]位置是非空的情况下,table再扩容为原来的2倍长 * 如果扩容了,那么要重新计算hash和index * (2)把新的映射关系创建为一个Entry的对象放到table[index]的头部。 */
@SuppressWarnings("all")
public class TestHashMapSource17 {
@Test
public void test1(){
HashMap map = new HashMap();
map.put(1, "哈哈");
map.put(2, "嘻嘻");
map.put(3, "呵呵");
map.put(4, "嘿嘿");
}
@Test
public void test2(){
HashMap map = new HashMap();
map.put( "哈哈",1);
map.put( "嘻嘻",2);
map.put("呵呵",3);
map.put("嘿嘿",4);
}
@Test
public void test3(){
HashMap map = new HashMap();
map.put(new MyData(1), "哈哈");
map.put(new MyData(2), "嘻嘻");
map.put(new MyData(3), "呵呵");
map.put(new MyData(4), "嘿嘿");
}
@Test
public void test4(){
HashMap map = new HashMap();
for (int i = 1; i <= 35; i++) {
map.put(i, "第" + i + "个value值");
}
}
@Test
public void test5(){
HashMap map = new HashMap();
for (int i = 1; i <= 35; i++) {
map.put(new MyData(i), "哈哈" + i);
}
}
}
class MyData{
private int num;
public MyData(int num) {
super();
this.num = num;
}
@Override
public int hashCode() {
/*final int prime = 31;
int result = 1;
result = prime * result + num;
return result;*/
return 1;//所有对象的hash值都是1,这个时候肯定会出现链表
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
MyData other = (MyData) obj;
if (num != other.num)
return false;
return true;
}
}
* JDK1.8:HashMap的底层实现是:数组+链表/红黑树 * * 1、复杂回答v1.0
jdk1.7和jdk1.8的异同点: * (1)映射关系的类型 TreeNode-->Entry-->Node-->Object * 添加到HashMap1.8种的映射关系的对象是HashMap.Node类型(原来是HashMap.Entry),
或者是HashMap.TreeNode类型。 * (2)映射关系添加到table[i]中时,如果里面是链表,新的映射关系是作为原来链表的尾部; JDK1.7是只要是新添加的就放在首位; * “七上八下”:JDK1.7在上,JDK1.8在下。 为什么要在下面? 因为如果是红黑树,那么是在叶子上,保持一致,都在下面。 * (3)扩容的时机不同 * 第一种扩容:元素个数size达到阈值threshod = table.length * 加载因子 并且table[i]是非空的;(这种情况(都存在数组中均匀分布,不涉及链表)跟JDK1.7是一样的;) * 第二种扩容:当某个桶table[index]下面的结点的总数原来已经达到了8个,这个时候,要添加第9个时(由16变成32),会检查 * table.length是否达到64(基本上我们的元素很少达到64个),如果没达到就扩容; 如果添加第10个时,也会检查table.length是否达到64,如果没达到就扩容。 * 为什么? 因为一旦扩容,所有的映射关系要重新计算hash和index,一计算原来table[index]下面(单向链表)可能就没有8个,或新的映射关系也可能不在table[index], * 如果链表特别长是不利于查找的,如果均匀分布在数组中查找会很快(通过hash马上就找到了);这样就可能均匀分布。 ---------------------------------------------------------------------- * (4)什么时候从链表HashMap$Node(hash key next value)变成红黑树HashMap$TreeNode(left parent right) * 当table[index]下面结点的总数已经达到8个,并且table.length也已经达到64,(添加第11个时)那么再把映射关系添加到table[index]下时,就会把原来的链表修改红黑树 * (5)什么时候会从红黑树变为链表? * 当删除映射关系时table[index]下面结点的总数少于6个,会把table[index]下面的红黑树变回链表。 * 2、put的源代码v2.0 * 第一步:计算key的hash,用了一个hash()函数,目的得到一个比hashCode更合理分布的一个int值;(return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);) * 第二步:如果table是空的,那么把table初始化为长度为16的数组,阈值初始化为= 默认的长度16 * 默认的加载因子0.75 = 12 DEFAULT_INITIAL_CAPACITY:默认的初始化容量16 DEFAULT_LOAD_FACTOR:默认加载因子 0.75 * 第三步:查看table[index]是否为空,如果为空,就直接(添加到数组这种情况)new一个Node放进去 index = hash的int值 & table.length-1 * 第四步:不为空,先查看table[index]的根节点的key是否与新添加的映射关系的key是否“相同”(单向链表这种情况),如果相同,就用新的value替换原来的value。 * 第五步:如果table[index]的根节点的key与新添加的映射关系的key不同, 还要看table[index]根结点的类型是Node还是TreeNode类型, 如果是Node类型,那么就查看链表下的所有节点是否有key与新添加的映射关系的key是否“相同”,如果相同,就用新的value替换原来的value。 如果是TreeNode类型,那么就查看红黑树下的所有叶子节点的key是否与新添加的映射关系的key是否“相同”,如果相同,就用新的value替换原来的value。 * 第六步:如果没有找到table[index]有结点与新添加的映射关系的key“相同”,那么 如果是TreeNode类型,那么新的映射关系就创建为一个TreeNode,连接到红黑树中 如果是Node类型,那么要查看链表的结点的个数,是否达到8个,如果8个,并且table.length小于64(最小树化容量),那么先扩容,一旦扩容就会进行重写计算。 TREEIFY_THRESHOLD:树化阈值8,达到TREEIFY_THRESHOLD - 1 = 7时就准备树化; MIN_TREEIFY_CAPACITY:最小树化容量64 UNTREEIFY_THRESHOLD:反树化,从树变为链表的阈值6
几个常量和变量值的作用:
①默认负载因子static final float DEFAULT_LOAD_FACTOR = 0.75f;
②负载因子final float loadFactor;
③阈值int threshold;当size达到threshold阈值时,会扩容;
④树化阈值static final int TREEIFY_THRESHOLD = 8;
该阈值的作用是判断是否需要树化,树化的目的是为了提高查询效率;当某个链表的结点个数达到这个值时,可能会导致树化。
⑤树化最小容量值static final int MIN_TREEIFY_CAPACITY = 64;当某个链表的结点个数达到8时,还要检查table的长度是否达到64,如果没有达 到,先扩容解决冲突问题
⑥反树化阈值static final int UNTREEIFY_THRESHOLD = 6;
@SuppressWarnings("all")
public class TestHashMapSource18 {
@Test
public void test1(){
HashMap map = new HashMap();
map.put(1, "哈哈");
map.put(2, "嘻嘻");
map.put(3, "呵呵");
map.put(4, "嘿嘿");
}
@Test
public void test2(){
HashMap map = new HashMap();
map.put( "哈哈",1);
map.put( "嘻嘻",2);
map.put("呵呵",3);
map.put("嘿嘿",4);
}
@Test
public void test3(){
HashMap map = new HashMap();
map.put(new MyData(1), "哈哈");
map.put(new MyData(2), "嘻嘻");
map.put(new MyData(3), "呵呵");
map.put(new MyData(4), "嘿嘿");
}
@Test
public void test4(){
HashMap map = new HashMap();
for (int i = 1; i <= 35; i++) {
map.put(i, "第" + i + "个value值");
}
}
@Test
public void test5(){
HashMap map = new HashMap();
for (int i = 1; i <= 35; i++) {
map.put(new MyData(i), "哈哈" + i);
}
}
}
class MyData{
private int num;
public MyData(int num) {
super();
this.num = num;
}
@Override
public int hashCode() {
/*final int prime = 31;
int result = 1;
result = prime * result + num;
return result;*/
return 1;//所有对象的hash值都是1,这个时候肯定会出现链表
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
MyData other = (MyData) obj;
if (num != other.num)
return false;
return true;
}
}
@Test
public void test1(){
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "kris");
map.put(2, "alex");
map.put(3, "smile");
}
put的过程:
 [1],int算完的hash=1 & 15 --> 1,所以下标为1
[1],int算完的hash=1 & 15 --> 1,所以下标为1
以字符串作为key,数字为value;----->>

HashMap和TreeMap、LinkedHashMap的内部实现类型,每个版本分别是什么?
HashMap的key的hashCode值的作用是什么?hash()方法的作用是什么?
hashCode值的作用是为了计算table[index]索引位置,协助equals方法保证key的不重复。
hash()方法的作用是得到一个int值,这个int值可以使得映射关系更均匀的分布在table数组中。
HashMap的key的equals()方法的作用是什么?
key的equals()方法的作用是确保key的不重复
HashMap和CurrentHashMap的区别?
HashMap的初始容量和加载因子会影响它的性能;初始容量默认值是16,加载因子(是hash表在增加前可以达到多满的尺度)默认值是0.75,容量(hash表中桶的数量);
当hash表中容量 > 16*0.75=12,会进行扩容resize;
HashMap的寻址方式:对于新插入或者读取的数据,key-->hash值对数组长度取模,结果作为它在数组中查找的index,取模的代价在计算机中比较高,所以数组长度要是2^n;
key的hash值 和2^-1做与运行,结果与取模操作是相同的;
HashMap是线程不安全的;体现在resize时可能出现死循环,使用迭代器;扩容时创建一个新的是原来容量2倍的新数组,将原来的重新插入到新数组;
多线程rehash就可能出现问题;
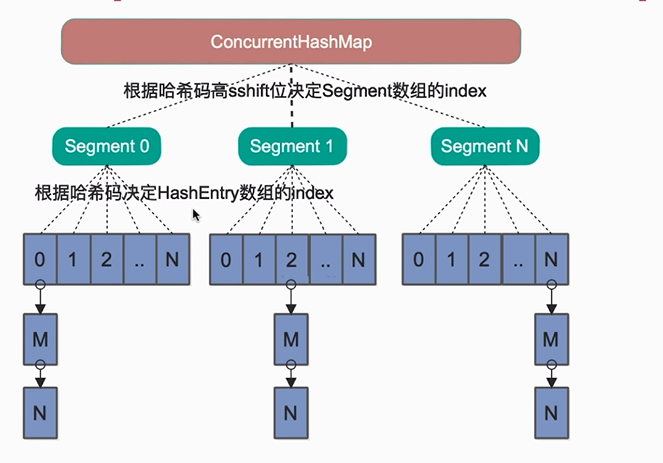
currentHashMap底层仍然是数组+链表,与hashmap不同的是它的外层不是一个大的数组,而是一个三维的数组,每个数组包含与hashmap类似的链表;
在读取某个key的hash值,对Segment的N位取模得到该key属于哪个segment;接着就像操作hashmap时操作segment,保证不同的值分布均匀,segment时继承JUC里边的
可以很方便的对segment上锁;
不同点:线程安全;hashmap允许key value为空,而currenthashmap则不允许;hash不允许在遍历时修改,currenthashmao运行并且时可见的;
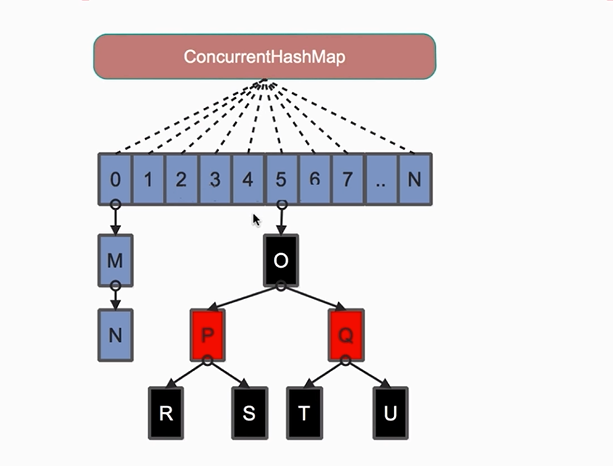
java8废弃了分段锁,并且使用了一个大的数组,为了提高碰撞、寻址做了性能优化;数组长度默认是8,链表换成了红黑树,寻址时间复杂度由On变成OLogn,key的hash与数组长度取模得到key在数组中索引;
jdk1.8
7. 集合工具类
java.util.Collections:
* (1)public static <T> boolean addAll(Collection<? super T> c,T... elements)
将后面可变参数传递的实参对象全部都添加到c集合中
* (2)public static <T> int binarySearch(List<? extends Comparable<? super T>> list,T key)
在list集合中,查找key的索引
* (3)public static <T> void copy(List<? super T> dest, List<? extends T> src) -- >>既有上限又有下线,T相当于是它俩的交集。
把src的集合中的元素复制到dest集合
* (4)public static <T extends Object & Comparable<? super T>> T min(Collection<? extends T> coll)
在coll集合中找最小值
* 这里为什么要写Object?因为当泛型擦除时,按照上限的第一个类型处理,泛型是JDK1.5才有的,
JDK1.5之前,没有泛型这个方法,返回值类型是按照Object处理的,为了当泛型擦除时与低版本保持一致
* (5)public static <T extends Comparable<? super T>> void sort(List<T> list)
这个T的要求必须实现Comparable接口,也可以是T的父类实现了Comparable接口
* (6)public static <T> void sort(List<T> list, Comparator<? super T> c)
要指定定制比较器,这个定制比较器中的T,必须是T或T的父类
*
* (7)synchronizedXxx开头的方法:表示把一个集合对象转成线程安全的
* (8)unmodifiableXxx开头的方法:表示把一个集合对象变成只读的
*
* java.util.Arrays
* public static <T> List<T> asList(T... a):把可变参数的实参,都放到一个List的集合并返回
@Test public void test1(){ ArrayList<String> list1 = new ArrayList<>(); ArrayList<Object> list2 = new ArrayList<>(); //传它的父类Object也可以 Collections.addAll(list1, "Hello", "World"); int binarySearch = Collections.binarySearch(list1, "Hello"); //这个集合的泛型(1)看T的类型(2)它必须实现java.lang.Comparable接口; 因为String实现了Comparable方法 System.out.println(binarySearch);//0 for (String object : list1) { System.out.println(object); } } @Test public void test2(){ List<Number> src = new ArrayList<>(); List<Number> dest = new ArrayList<>(); List<Object> dest2 = new ArrayList<>();//看把Number放到Object或者Integer中行不行 // List<Integer> dest1 = new ArrayList<>();//错误的 Collections.copy(dest, src); //把src复制到dest ArrayList<String> list = new ArrayList<>(); ArrayList<Object> list2 = new ArrayList<>(); //因为Object没有实现Comparable接口 ArrayList<Integer> list3 = new ArrayList<>(); // ArrayList<xx> list = new ArrayList<>(); Collections.min(list); } public void test3(){ List<String> list = Arrays.asList("Hello", "kris","java"); //list.add("k"); //UnsupportedOperationException //这个返回的是一个内部的Arrays.ArrayList,不是我们平时的ArrayList它是只读的。 for (String string : list) { System.out.println(string); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号